
競合サイトを何百件も調査する業務を手作業のコピー&ペーストだけで進めると、情報収集に多くの時間がかかります。営業、マーケティング、リサーチ、オペレーションの担当者にとって、ウェブ上の情報を継続的に収集し、比較できる形に整えることは重要な業務課題です。
scrap.ioが紹介するデータでは、**アメリカの小売業者の81%**が価格調査に自動スクレイパーを導入しているとされています(scrap.io)。こうしたデータ収集を支える仕組みの一つが、ウェブクローラーです。
多くの開発チームは、ウェブで広く使われているJavaScriptを利用できるNode.jsでクローラーを構築しています。私自身、SaaSや自動化の現場に長年携わり、ThunderbitのCEOとして、適切なツールの選択によってウェブデータ収集を業務上の成果につなげる事例を見てきました。
本記事では、Nodeウェブクローラーの基本的な仕組み、処理の流れ、ビジネスでの活用例を解説します。あわせて、Node.jsで自作する方法と、プログラミングを必要としないツールを利用する方法の選定基準も整理します。
Nodeウェブクローラーの基本を押さえよう
データスクレイピングとは?2026年に実践する方法 Get Started Free
Nodeウェブクローラーは、Node.jsで構築され、指定したウェブページを自動で巡回しながらリンクをたどり、必要な情報を収集するプログラムです。通常は開始地点となるURLを指定し、取得対象のページとデータ項目、巡回の終了条件を設定して使用します。
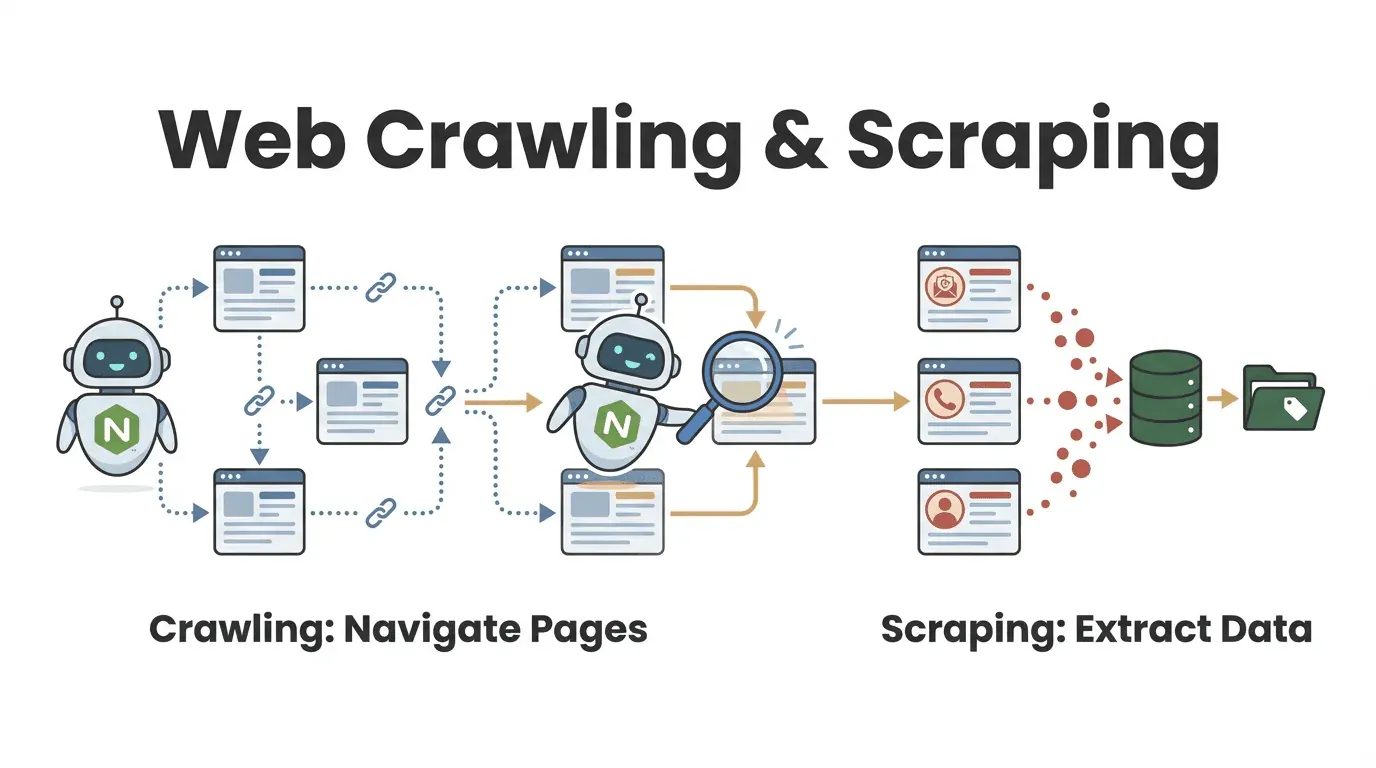
混同されやすい用語に、ウェブクローリングとウェブスクレイピングがあります。
- ウェブクローリングは、複数のページを発見して巡回する処理です。リンクをたどりながら、取得対象となるページを広げていきます。
- ウェブスクレイピングは、ページから特定の情報を抽出する処理です。商品名、価格、連絡先など、あらかじめ定めた項目を取り出します。
実際のNodeウェブクローラーでは、両方の処理を組み合わせることが一般的です。たとえば営業チームがディレクトリサイトから企業情報を集める場合、企業ページをクローリングで特定し、各ページから連絡先情報をスクレイピングします(oxylabs.io)。
Nodeウェブクローラーの動き方
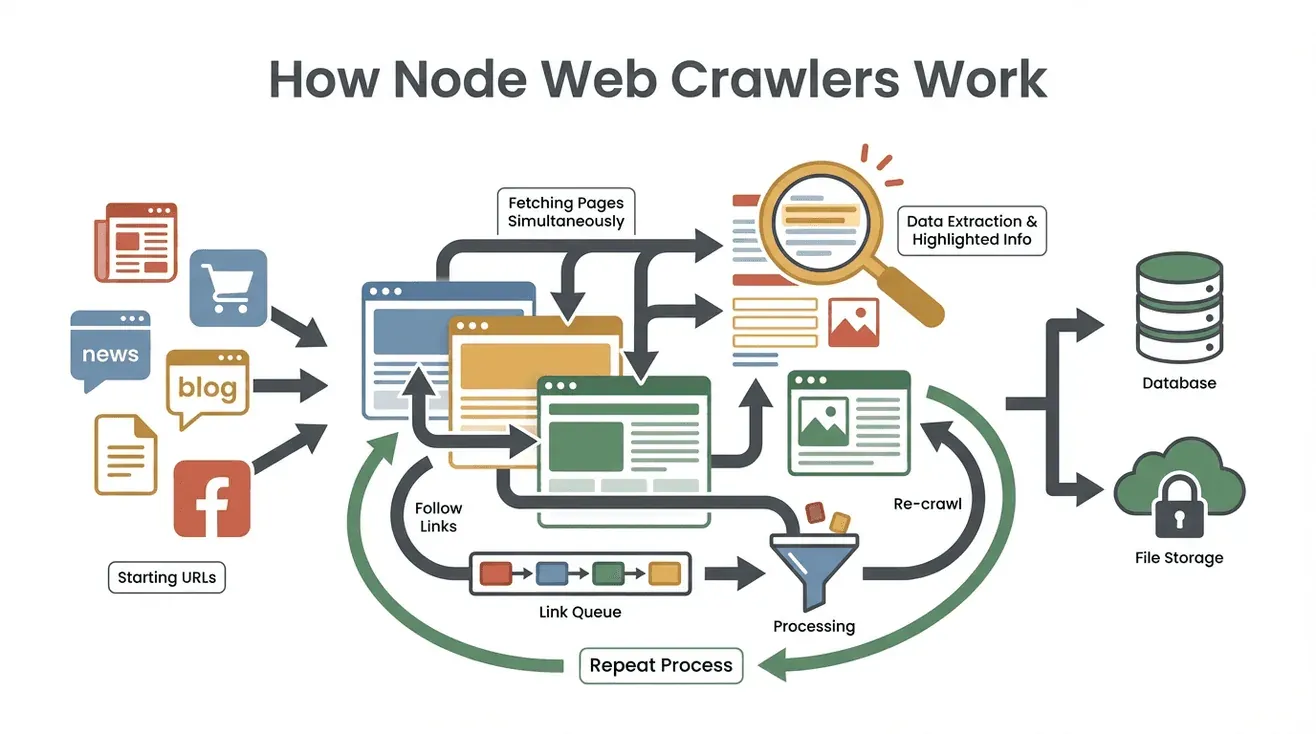 Nodeウェブクローラーの基本的な処理は、次の順序で進みます。
Nodeウェブクローラーの基本的な処理は、次の順序で進みます。
- シードURLの指定:巡回を開始するURLを決めます。トップページや商品一覧ページなどが該当します。
- ページ内容の取得:各ページのHTMLをダウンロードし、解析対象となるデータを取得します。
- 必要なデータの抽出:Cheerioなどのツールを使い、名前、価格、メールアドレスなど、指定した情報を取り出します。Cheerioは、Node.jsでjQueryに近い記法を利用できるHTML解析ライブラリです。
- 新しいリンクの発見とキューイング:ページ内の「次へ」リンクや詳細ページへのリンクを検出し、巡回リストであるクロールフロンティアに追加します。
- 繰り返し処理:巡回リストのURLを順番に処理し、データ抽出とリンク探索を繰り返します。
- 結果の保存:収集したデータをCSV、JSON、またはデータベースに保存します。
- 終了条件でストップ:新しいリンクがなくなるか、設定したページ数や処理時間などの上限に達した時点で終了します。
求人サイトから求人情報を収集する場合は、一覧ページから各求人のリンクを抽出し、詳細ページで必要な項目を取得した後、「次へ」をたどって処理対象を広げます。
この処理を支えるのが、Node.jsのイベント駆動・ノンブロッキングI/Oです。ページからの応答を待っている間に別のリクエストを処理できるため、複数ページからのデータ収集を効率化しやすくなります。
Node.jsがウェブクローラーで選ばれる理由
Node.jsがウェブクローラー開発で利用される主な理由は、複数のネットワークリクエストを扱いやすい実行モデルと、JavaScript向けライブラリの充実にあります。
- イベント駆動・ノンブロッキングI/O:多数のページリクエストを並行して処理し、応答待ちの時間を別の処理に利用できます(blog.apify.com)。
- 処理性能:Chromeでも使われているGoogleのV8エンジン上で動作し、取得したデータの解析や整形を効率よく実行できます。実際の性能は、処理内容や実行環境によって異なります。
- ライブラリが豊富:HTML解析のCheerio、HTTPリクエストのGot、ヘッドレスブラウジングのPuppeteer、大規模クロール管理のCrawleeなど、用途に応じたライブラリがあります(scrapingdog.com)。
- JavaScriptとの親和性:JavaScriptで構築されたウェブサイトの処理を同じ言語環境で実装でき、JSONデータも扱いやすい点が特徴です。
- 継続的な監視への適用:価格変動やニュース更新など、短い間隔でデータを取得する処理にも利用できます。実行頻度は対象サイトの条件や負荷を考慮して設定します。
Node.js向けには、CrawleeやCheerioなど、クローラー開発を支えるライブラリが複数提供されています。利用するライブラリは、対象サイトの構造、必要な処理、保守体制に合わせて選ぶことが重要です。
Nodeウェブクローラーの主な機能とビジネス活用例
Nodeウェブクローラーは、巡回、抽出、整形、保存を組み合わせてウェブデータ収集を自動化します。主な機能と、それぞれが対応する業務用途を次の表に整理します。
| 機能・役割 | Nodeクローラーでの動作 | ビジネス活用例 |
|---|---|---|
| 自動ナビゲーション | リンクやページ送りを自動でたどる | リード獲得:オンラインディレクトリ全ページを巡回 |
| データ抽出 | セレクタやパターンで特定項目(名前、価格、連絡先など)を取得 | 価格調査:競合サイトの商品価格を抽出 |
| 複数ページ同時処理 | 非同期処理で多数のページを並行取得 | リアルタイム更新:複数ニュースサイトを同時監視 |
| 構造化データ出力 | CSVやJSON、データベースに保存 | 分析:BIダッシュボードやCRMへのデータ連携 |
| カスタムロジック・フィルタ | コードで独自ルールやデータ整形処理を追加 | 品質管理:古いページを除外、データ形式を変換 |
たとえばマーケティングチームでは、業界ブログから記事タイトルとURLを収集し、Googleスプレッドシートに整理してコンテンツ企画の調査資料として利用できます。
Thunderbit:Nodeウェブクローラーのノーコードな選択肢
Thunderbit AIウェブスクレイパーを試す 2クリックでどんなサイトからもデータ抽出—コーディング不要。 Get Started Free
Node.jsでクローラーを実装せず、ブラウザ上のデータを表形式で取得したい場合は、ノーコードツールも選択肢になります。Thunderbitは、AIを活用したChrome拡張型のAIウェブスクレイパーで、営業リスト作成、商品情報の整理、価格調査など、非エンジニアがウェブデータ収集を試したい場面に向いています。
基本操作では、拡張機能を開いて「AIで項目を提案」をクリックし、AIが提示した抽出項目を用途に合わせて調整してから処理を実行します。たとえば「商品名と価格を取得したい」と日本語で指定し、出力された列と元ページを照合します。サブページの巡回やページ送りは、対象ページの構造と利用できる機能の範囲内で設定できます。
Thunderbitの主な特徴は次のとおりです。
- 自然言語インターフェース:日本語で取得したい項目を記述し、AIによる設定候補を利用できます。抽出結果は対象ページの構造によって異なります。
- AIによる項目提案:ページを解析し、カラムの候補を提示します。実行前に必要な列へ絞り込めます。
- ノーコードでサブページ巡回:対応するページ構成では、商品やプロフィールなどの詳細ページを巡回し、一覧データと統合できます。
- 構造化エクスポート:利用可能な出力先の範囲で、Excel、Googleスプレッドシート、Airtable、Notionなどへエクスポートできます。
- 無料データエクスポート:対応する出力先へのダウンロードは追加料金なしで利用できる仕様とされていますが、利用条件はプランによって異なります。
- 自動化・スケジューリング:利用中のプランと実行条件に応じて、「毎週月曜9時に」などの定期実行を設定できます。
- 連絡先抽出:ページ上に公開されているメール、電話番号、画像を抽出できます。対象ページ、取得目的、利用条件を踏まえて使用します。
短時間でスプレッドシート化したい業務では有力な候補ですが、対象サイトとの相性、抽出精度、必要な処理規模を実データで検証することが重要です。ユーザーレビューには、非エンジニアがリードリスト作成、価格監視、リサーチに利用した事例が紹介されています。
NodeウェブクローラーとThunderbitの比較(ビジネスユーザー向け)
選定時は、初期設定の速さだけでなく、必要なカスタマイズ、処理規模、保守体制、対象サイトとの相性を比較します。
| 比較項目 | Node.jsウェブクローラー(カスタム開発) | Thunderbit(ノーコードAIスクレイパー) |
|---|---|---|
| セットアップ時間 | 数時間〜数日(コーディング・デバッグ・環境構築。要件により変動) | 小規模な試行は数分で開始できる場合がある(対象ページと設定内容により変動) |
| 技術スキル | プログラミング(Node.js、HTML、セレクタ)が必要 | 基本操作はコーディング不要。日本語指示やクリック操作を利用できるが、結果の検証は必要 |
| カスタマイズ性 | 実装可能な範囲で独自ロジックやワークフローに対応 | 内蔵機能とAIの範囲内で対応 |
| スケーラビリティ | サーバーやプロキシを設計することで大規模処理に対応可能 | クラウドスクレイピングに対応。処理規模はプランや対象サイトにより異なる |
| メンテナンス | サイト変更時のコード修正やエラー対応が必要 | コード保守は不要だが、サイト変更時は抽出項目と結果の見直しが必要 |
| アンチボット対策 | プロキシ・遅延・ヘッドレスブラウザ等を許可された範囲で実装 | バックエンド機能の対応範囲内。CAPTCHA等は対象サイトや条件により処理できない場合がある |
| 外部連携 | APIやDB、ワークフローなど深い連携が可能 | 利用可能な範囲でSheets、Notion、Airtable、Excel、CSVにエクスポート |
| コスト | ツール自体は無料だが、開発・サーバー運用コストが発生 | 無料枠あり。プランまたは使用量に応じた料金が発生 |
Node.jsが向いているケース:
- 独自ロジックや高度なシステム連携が必要な場合
- 開発と保守を担当できるリソースがあり、処理を細かく制御したい場合
- 大規模なデータ収集や自社サービスへの組み込みを計画している場合
Thunderbitが向いているケース:
- 小さな対象から短期間で抽出結果を検証したい場合
- プログラミングを前提とせず、業務担当者が操作する場合
- 日常業務で複数のサイトから表形式のデータを取得したい場合
- 独自実装よりも初期設定のしやすさを重視する場合
実務では、まずノーコードツールで対象ページとの相性、抽出精度、出力形式を検証し、内蔵機能では対応できない独自要件が明確になった段階で、Node.jsによるカスタム開発を比較すると判断しやすくなります。
Nodeウェブクローラー利用時の主な課題と対策
Nodeウェブクローラーを安定して運用するには、取得処理だけでなく、対象サイトの条件、エラー対応、データ品質、保守方法を事前に設計する必要があります。
- アンチスクレイピング対策:CAPTCHA、IPブロック、ボット検知などにより処理が停止する場合があります。アクセス頻度や待機時間を調整し、必要に応じてPuppeteerなどのヘッドレスブラウザを利用します(blog.apify.com)。プロキシやヘッダー変更を含む対策は、対象サイトの利用条件と許可された範囲内で実施します。
- 動的コンテンツ:JavaScriptで後から読み込まれるデータや無限スクロールには、単純なHTML解析だけでは対応できない場合があります。ブラウザ操作の再現や、利用可能な公式APIを検討します。
- パース・データ整形:ページごとに構造が異なる場合は、欠損値、文字コード、表記ゆれを処理するルールを設け、サンプルデータと照合します。
- メンテナンス:サイト構造の変更でコードが動作しなくなる可能性があります。エラーログと監視を用意し、変更を検知した時点でセレクタや処理条件を更新します。
- 法的・倫理的配慮:robots.txt、利用規約、関連法令、著作権、個人情報、サーバー負荷を検討します。個人情報、著作物、非公開情報を扱う場合は、取得方法だけでなく利用目的と保存方法も整理し、必要に応じて専門家へ相談します。
ベストプラクティス:
- Crawleeなどのフレームワークを利用し、リクエスト管理やエラー処理を標準化する
- リトライ回数、待機時間、エラーログを設定する
- 取得結果とサイト構造を定期的に見直す
- 対象サイトへの負荷と利用条件を踏まえて、アクセス頻度を設定する
Nodeウェブクローラーとクラウドサービスの連携
継続的なデータ収集や複数の処理を並行して実行する場合は、ローカルPCだけでなくクラウド環境への配置も検討します。
- サーバーレス関数:NodeクローラーをAWS LambdaやGoogle Cloud Functionsとしてデプロイし、設定したスケジュールで実行して、S3やBigQueryなどのクラウドストレージへ保存します(docs.aws.amazon.com)。
- コンテナ化クローラー:Dockerでパッケージ化し、AWS Fargate、Google Cloud Run、Kubernetesなどで複数の処理を実行します。必要な規模に応じて、同時実行数とリソースを設計します。
- 自動化ワークフロー:AWS EventBridgeなどのスケジューラーを使い、定期実行、クラウド保存、BIや機械学習処理への連携を構成します。
クラウド連携により、実行環境の拡張、障害時の再実行、定期処理を管理しやすくなります。一方で、クラウド利用料、認証情報、監視、同時実行制限も設計に含める必要があります。scrap.ioが紹介するデータでは、ウェブスクレイピングの68%がクラウド上で実行されているとされています。
Nodeウェブクローラーとノーコードツールの選定基準
選定時は、必要なカスタマイズ、実行頻度、処理規模、利用者、保守体制を順に整理します。
-
独自のカスタマイズや社内システム連携が必要な場合
→ Node.jsウェブクローラーが候補になります。 -
コードを書かず、短期間でデータ抽出を試したい場合
→ Thunderbitまたは他のノーコードツールが候補になります。 -
単発または頻度の低い作業の場合
→ 初期設定の負担が小さいThunderbitを検討できます。 -
大規模かつ継続的なミッションクリティカル用途の場合
→ Node.jsとクラウド環境を組み合わせ、監視と保守を含めて設計します。 -
開発リソースとメンテナンス体制がある場合
→ Node.jsで細かな処理条件を実装しやすくなります。 -
非エンジニアのチームメンバーが利用する場合
→ 操作方法と出力結果を検証したうえで、Thunderbitを候補にできます。
最初にノーコードツールで対象ページとの相性、必要項目、抽出精度を検証し、その結果からカスタム開発の必要性を判断する方法が現実的です。Thunderbitの紹介では、多くのチームが同製品で業務の9割をカバーし、時間と手間を削減しているとされていますが、実際の範囲は対象サイト、業務要件、利用プランによって異なります。
まとめ:要件に合うウェブデータ収集方法を選ぶ
 ウェブデータの抽出は、開発者がクローラーを構築する方法だけでなく、業務担当者がノーコードツールを利用する方法でも進められます。Nodeウェブクローラーを自作する場合も、AI搭載のThunderbitのようなツールを使う場合も、目的はウェブ上の情報を業務で利用できる形に整えることです。
ウェブデータの抽出は、開発者がクローラーを構築する方法だけでなく、業務担当者がノーコードツールを利用する方法でも進められます。Nodeウェブクローラーを自作する場合も、AI搭載のThunderbitのようなツールを使う場合も、目的はウェブ上の情報を業務で利用できる形に整えることです。
Node.jsは、独自ロジック、大規模処理、社内システムとの連携を細かく設計したい場合に向いています。一方、ノーコードAIツールは、開発環境を用意せずに小規模なデータ抽出を試したい業務担当者にとって候補になります。抽出の可否や精度は、対象ページの構造、利用条件、ツールのプランによって異なります。
97%の企業がビッグデータやAIに投資しているというデータも紹介されていますが、導入判断では投資の有無よりも、取得したデータをどの業務判断に使うかを明確にすることが重要です。
まずは実際の業務から対象ページを1つ選び、必要な項目、抽出精度、出力形式を検証します。ノーコードで試す場合は、Thunderbitを無料でダウンロードし、結果を元ページと照合してから対象範囲を広げるとよいでしょう。関連する手順や活用例は、Thunderbitブログでも紹介しています。
AIウェブスクレイパーを無料で試す Get Started Free
よくある質問(FAQ)
1. Nodeウェブクローラーとウェブスクレイパーの違いは?
Nodeウェブクローラーはウェブページを自動で巡回し、対象となるページを見つける仕組みです。ウェブスクレイパーは、そのページから指定したデータを抽出します。多くのNodeクローラーは、両方の処理を組み合わせています。
2. なぜNode.jsがウェブクローラー開発で人気なの?
Node.jsはイベント駆動・ノンブロッキングI/Oを採用しており、応答待ちを伴う複数のページリクエストを扱いやすい点が特徴です。関連ライブラリも豊富で、継続的な監視や大規模処理の構成にも利用できます。実際の性能は実装と実行環境によって異なります。
3. Nodeウェブクローラーの主な課題は?
CAPTCHAやIPブロックなどへの対応、動的コンテンツの取得、データ整形、サイト変更時の保守が主な課題です。さらに、対象サイトの利用規約、著作権、個人情報、サーバー負荷を踏まえて運用する必要があります。
4. ThunderbitはNodeウェブクローラーとどう違う?
Thunderbitは、Chrome拡張とAI支援を利用してウェブページからデータを抽出するノーコードツールです。コードを書かずに抽出項目を指定したい業務担当者に向いています。利用できる機能、処理規模、抽出結果は、対象ページ、設定、プランによって異なります。
5. NodeウェブクローラーとThunderbit、どちらを使うべき?
独自ロジック、大規模処理、APIや社内システムとの連携を重視する場合は、Node.jsが候補になります。日常的なデータ収集を非エンジニアが短期間で試す場合は、Thunderbitを候補にできます。最終的には、対象ページとの相性、必要な出力形式、保守体制を比較して選びます。
ウェブデータ活用を始める場合は、まず対象ページを1つ決め、Thunderbitで必要な項目を取得できるか試す方法があります。抽出結果と元ページを照合し、用途に合うと判断してから対象を広げてください。関連する実装方法や活用例はThunderbitブログで紹介しています。
さらに詳しく




