

ECサイトの商品情報や不動産ポータルの物件情報は、一覧ページだけでなく、詳細ページ、ページネーション、動的に読み込まれる領域に分かれていることがあります。こうしたサイトから必要なデータを集める場合、最初に表示されたページだけを対象とする方法では、取得範囲が不足しやすくなります。
ディープクローラーは、サイト内のリンクや複数階層をたどり、サブページや動的コンテンツからもデータを取得するための仕組みです。本記事では、営業、マーケティング、リサーチ、EC運用の担当者に向けて、ディープクローラーの定義、従来型クローラーとの違い、主な仕組み、ビジネスでの活用例、利用時の注意点を解説します。Thunderbitのようなノーコードツールを使う場合の進め方と選定ポイントも紹介します。
ディープクローラーとは?基本をやさしく解説
AIでどんなウェブサイトからもデータ抽出 Get Started Free
ディープクローラーとは、サイト内のリンクをたどり、一覧ページから詳細ページへと複数階層を巡回しながら、必要なデータを抽出するクローラー兼スクレイパーです。クローリングがページを巡回する処理、スクレイピングが特定の情報を抽出・整形する処理であり、ディープクローラーでは両者を組み合わせて使います。
設定された範囲を中心に巡回する従来型の方法と比べ、ページネーション、タブ、展開式セクション、サブページなど、初期画面には表示されない領域まで取得対象を広げられる点が特徴です。
ウェブスクレイピングでは、主に次の処理に使われます。
- ウェブサイトの複数階層を巡回(カテゴリ、サブカテゴリ、詳細ページなど)
- JavaScriptで動的に表示されるコンテンツや、ユーザー操作で現れる情報を抽出
- ページネーションや無限スクロールを処理
- 内部リンクをたどり、複数ページのデータを1つの形式にまとめる
2024年には世界のデータ量が149ゼタバイトに達したとされています。サイト構造が複雑になるなか、一覧と詳細の両方からデータを集めたい業務では、ディープクローリングが選択肢になります。
ディープクローラーと従来型クローラーの違い
比較のポイントは、巡回する深さ、動的要素への対応、取得できるデータの範囲です。
従来型クローラー:表面だけをなぞる
ここでいう従来型クローラーは、トップページや主要ページなど、あらかじめ限定した範囲を短時間で巡回する方法です。広い範囲からページ情報を集めたい場合に向いています。検索エンジン向けのクローラーにも、短時間で多くのページをインデックス化することを重視した設計があります。一方、深い階層や操作後に表示される情報は、設定や実装によって取得できない場合があります。
従来型クローラーの主な制約:
- ナビゲーションやタブ、動的要素の裏にあるデータを取得できない場合がある
- JavaScriptで後から表示される情報には追加の処理が必要になる
- 複数ステップのナビゲーションや複雑なページ構造への対応が限られる
- 対象範囲によっては、取得データが断片的になる
ディープクローラー:隠れた情報まで徹底的に取得
一方、ディープクローラーは、設定した起点から関連リンクをたどり、ページネーション、サブページ、ポップアップ、動的コンテンツへ取得範囲を広げます。処理速度だけでなく、対象ページの網羅性と取得結果の正確性を重視する場面に向いています。
ディープクローラーの主な特徴:
- 高度なナビゲーション機能: リンクを再帰的にたどり、複数階層の構造を巡回します。巡回済みURLを記録し、重複や行き止まりを避ける設計も可能です(SEO-Wiki)。
- 動的コンテンツの抽出: JavaScriptで表示される情報や、ユーザー操作で展開されるセクションを取得対象にできます(Scientific Reports)。
- 効率的なデータ収集: 優先するページや項目を設定し、重複や不要なデータを抑えながら巡回できます(Medium)。
- 複数階層のデータ統合: メインリスト、詳細ページ、関連ドキュメントなどから取得した情報をまとめられます。
商品レビューを一覧と詳細ページから集める場合や、物件情報と担当者の連絡先を同じ表に整理する場合など、情報が複数ページに分かれている業務で役立ちます。
ディープクローラーによる多層データ取得と高度なページ巡回
ディープクローラーの強みは、リンク追跡・再帰的な巡回・動的コンテンツの処理を組み合わせられる点です。
サブページのスクレイピングと多層ナビゲーション
ディープクローラーは、最初のページだけで止まりません。
- 内部リンク(「詳細を見る」「次へ」「もっと見る」など)を自動検出
- それらのリンクをたどってサブページや詳細画面、ポップアップまで巡回
- 各階層のデータを抽出し、1つの構造化データセットにまとめる
このやり方は「再帰的クローリング」「多層スクレイピング」とも呼ばれ、情報が複数ページに分かれたサイト(商品リスト+詳細ページ、ディレクトリ型など)で力を発揮します。
ページネーションや動的コンテンツへの対応
現在のサイトでは、「もっと見る」ボタン、無限スクロール、JavaScriptで切り替わるタブなど、初期表示には含まれない領域にデータが置かれることがあります。対応機能を持つディープクローラーでは、次の処理を組み合わせます。
- ページネーションや動的要素を検出して操作する
- スクロールやクリックでデータを表示させてから抽出する
- コンテンツの読み込み完了を待ってデータを取得する
これにより、最初に表示されている情報だけでなく、操作後に読み込まれる領域まで取得範囲を広げられます(Thunderbit Blog)。
ディープリンク追跡と多層スクレイピング
ディープクローリングでは、入れ子になったページをたどりながら、取得済みのURLと未処理のURLを管理する必要があります。主な仕組みは次のとおりです。
- すでに巡回したリンクを記録し、重複や無限ループを防止
- 詳細画面やダウンロード資料など、優先するページから取得
- ポップアップ、展開式セクション、AJAXで読み込まれる情報などを個別に処理
ビジネス用途では、連絡先や商品スペックの取りこぼしが、データの品質や後工程に影響することがあります。巡回済みURLの管理とページの優先順位付けにより、こうした取得漏れを抑えられます。ただし、実際の取得範囲は対象サイトの構造と設定によって異なります(Simplescraper)。
Thunderbit:AI搭載ツールでディープクローリングをもっと手軽に
ディープクローリングを独自に実装する場合、巡回用のスクリプト、例外処理、サイト構造の変更に合わせた保守が必要になります。Thunderbitは、商品一覧から詳細ページの情報を追加するなど、非エンジニアがWebデータを表形式にまとめたい場面で使えるノーコードツールです。
一方、取得結果は対象サイトの構造や表示方式によって変わるため、導入時には必要な項目を取得できるか、元ページと照合してから運用範囲を広げることが重要です。
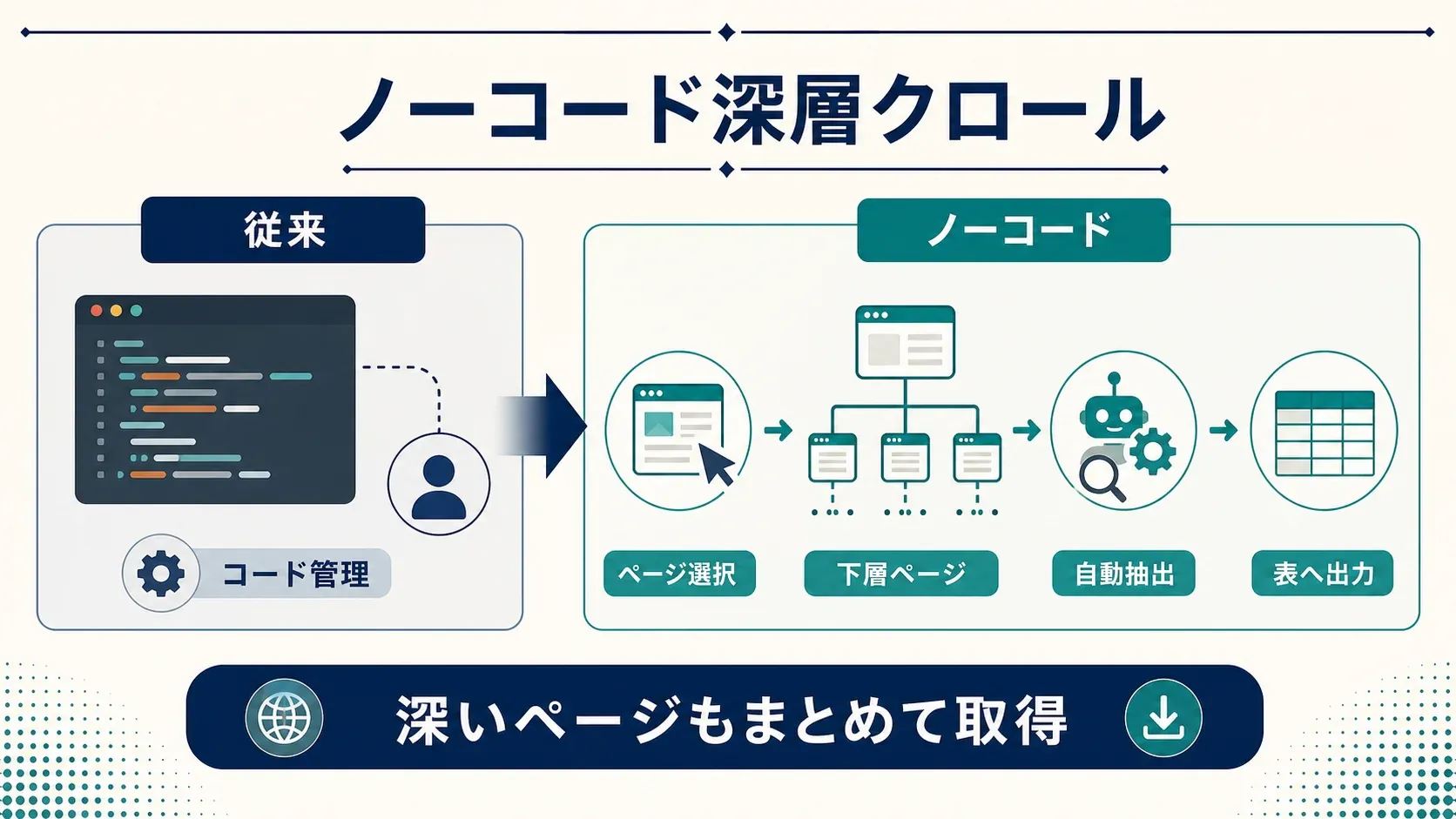
Thunderbitのディープクローラー機能
Thunderbitでは、ディープクローリングの設定を次の機能で簡素化します。
- AIフィールド提案: 「AIフィールド提案」をクリックするとページを解析し、抽出するカラムの候補と各項目の抽出プロンプトを生成します。利用者は必要な列を選び、内容を調整してから実行できます。
- サブページスクレイピング: 商品詳細、担当者プロフィール、レビュータブなどのサブページを巡回し、取得した情報をメインテーブルに追加します。
- 動的コンテンツ対応: ページネーション、無限スクロール、動的要素を処理対象にできます。実際の動作は対象サイトの構造によって異なります。
- ノーコード・2ステップ: 欲しい内容を説明して「スクレイピング」をクリックする流れで操作できます。データはExcel、Google Sheets、Notion、Airtableへ直接エクスポートでき、追加料金や制限もないとThunderbit Blogで案内されています。
導入時は、代表的な1ページで抽出列、値の精度、出力形式を検証してから、サブページ全体へ対象を広げると運用しやすくなります。
実践例:Thunderbitでディープクローリング
たとえば、不動産サイトから物件リストと、サブページにある担当者情報を取得する場合は、次の流れで進めます。
- Chromeでリストページを開く
- Thunderbit拡張機能をクリック
- 「AIフィールド提案」で「物件名」「価格」「住所」「担当者リンク」などを抽出カラムに設定
- 「スクレイピング」をクリックし、メインリストを一括取得
- 「サブページをスクレイピング」をクリック。各担当者プロフィールにアクセスし、電話番号やメールアドレスを抽出してメインテーブルに統合
- Google SheetsやExcelにエクスポートし、営業やオペレーションチームの業務に活用
基本操作では、コードやテンプレートを用意せずに設定できます。ただし、対象サイトの構造によっては抽出項目や操作手順の調整が必要です。サイト構造が変わった後は、取得件数と値を元ページに照合してから運用を継続します(Thunderbit Docs)。
営業・マーケティング業務でのディープクローラー活用
ディープクローラーは、複数ページに分かれたデータを集約し、営業、マーケティング、リサーチの判断材料を整える用途で活用できます。
EC・不動産・競合サイトでの活用例
営業・マーケティング部門では、取得するデータと利用目的を対応させると、ディープクローリングの用途を判断しやすくなります。
- ECサイトの商品・価格・レビューを一覧ページと詳細ページから収集し、価格調査や商品情報の整理に使う
- 不動産リスト、物件詳細、担当者情報を集約し、営業対象や物件情報を同じ形式で管理する
- 競合サイトの新商品や価格変動、マーケット動向をモニタリングし、変更履歴を比較する(GetMonetizely)
- ディレクトリ、イベントサイト、専門ポータルから候補情報を収集し、リードリストの作成に活用する
取得したデータを業務で使う前に、対象項目の欠落や重複を検証し、用途に合う形式へ整えることが重要です。
競合分析・マーケットインテリジェンスでの活用
新商品をリリースした企業を営業対象として調べる場合、ディープクローラーを次の流れで利用できます。
- 競合サイトの新商品ページを検出
- プレスリリースや投資家向け情報までリンクをたどる
- 発売日、価格、特徴などの必要項目を抽出
- 利用するツールが対応している場合は、CRMや分析ツールへの連携を自動化
収集した情報を時系列で比較し、営業やマーケティングの担当者に共有すれば、新商品の把握や対応方針の判断を早めやすくなります。
ディープクローラー利用時の注意点とコンプライアンス
強力なクローリング機能には、責任も伴います。大量のデータにアクセスできても、何でも取得していいわけではありません。次の点に注意しましょう。
データのプライバシーと著作権
- サイトの利用規約を照合する: スクレイピングや自動アクセスに関する条件が記載されている場合があります。規約に反する利用は、利用停止や法的な問題につながる可能性があります(Apify Blog)。
- 個人情報や機密データを慎重に扱う: 取得・利用の可否は、データの種類、利用目的、適用法令、必要な許可や同意を踏まえて判断します。
- 著作権と利用範囲を見直す: 取得できることと、再配布や販売が認められることは同じではありません。利用前に権利関係を確かめます。
責任あるクローリング
- リクエスト数を調整する: アクセス間隔や同時実行数を設定し、対象サイトに過剰な負荷をかけないようにします。
- robots.txtを読む: robots.txtはサイト側のクロール方針を示すもので、法的な許諾そのものではありません。記載内容をアクセス方針に反映します。
- 適用法令を調べる: 個人情報保護法、GDPR、CCPAなど、データの取得・利用に関係する法令は、対象地域と利用目的によって適用範囲が異なります(Octoparse)。
詳しくは2025年版ウェブスクレイピングの合法性も参考にしてみてください。
用途に合うディープクローラーの選び方
Thunderbitの料金を見る どんな規模のチームにも手頃なディープクローリングを。 Get Started Free
ディープクローラーを選ぶ際は、取得対象、運用規模、担当者の技術スキルを基準に比較します。
- 使いやすさ: 非エンジニアが抽出項目や巡回範囲を設定できるか
- スケーラビリティ: 大規模サイト、大量ページ、動的コンテンツに必要な範囲で対応できるか
- コンプライアンス機能: アクセス間隔や実行範囲を調整できるか。機能があっても適法性が保証されるわけではない
- 連携性: Excel、Sheets、Notion、Airtableなど、業務で使う出力先に対応しているか
- メンテナンス性: サイト構造の変更後にどの程度の調整が必要か
ノーコードツールは、開発環境を用意せずに業務データ収集を試したい場合に向いています。一方、大規模処理や独自の連携要件がある場合は、コードベースのクローラーと開発・保守工数も比較します。
Thunderbitは、非エンジニアがサブページを含むデータ抽出を試したい場合の候補です。世界20万人以上のユーザーに利用され、月額15ドルからとされています。導入前に、現在の料金、対象機能、ページ数やクレジットの上限を料金ページと照合してください。
まとめ:ディープクローリングを業務で活用するために
最後にポイントを整理します。
- ディープクローラーは、一覧から詳細ページまで複数階層を巡回し、必要なデータをまとめる方法です
- ページネーション、動的コンテンツ、操作後に表示される情報を取得対象にできます
- 営業、マーケティング、リサーチでは、商品情報、物件情報、競合動向などの整理に活用できます
- 利用時は、対象サイトの利用規約、著作権、個人情報、サーバー負荷を考慮する必要があります
- Thunderbitは、非エンジニアがノーコードでサブページを含むデータ抽出を試す際の選択肢です
まずは対象ページを1つ選び、必要な項目が取得できるか、値が元ページと一致するか、業務で使う形式に出力できるかを検証します。その結果を踏まえて、巡回するページ数や運用頻度を広げると導入判断がしやすくなります。
表面のデータ取得から一歩進んで、詳細ページの情報も収集したい場合は、ThunderbitのChrome拡張機能で実際の対象ページを試せます。詳しいノウハウや最新情報は、Thunderbitブログで紹介しています。
よくある質問
1. ディープクローラーって何?普通のウェブクローラーとどう違う?
ディープクローラーは、サイト内のリンクをたどり、複数階層のサブページや動的コンテンツから必要なデータを抽出する仕組みです。巡回範囲を限定した従来型の方法と比べ、一覧ページから詳細ページまで取得対象を広げやすい点が異なります。
2. ビジネスでディープクローラーが必要になるのはどんな場合?
商品一覧と詳細情報、物件と担当者情報など、必要なデータが複数ページや動的要素に分かれている場合です。営業、マーケティング、リサーチ、競合分析で、ページをまたいだ情報を同じ形式に整理したいときに役立ちます。
3. Thunderbitは非エンジニアでもディープクローリングを簡単にできる?
Thunderbitは、AIによるフィールド提案、サブページ巡回、動的コンテンツの処理を支援します。コードを書かずに抽出項目を設定し、結果を業務ツールへエクスポートできます。ただし、対象サイトによって取得結果が異なるため、代表的なページで項目と値を検証してから運用します。
4. ディープクローラー利用時のコンプライアンス上の注意点は?
対象サイトの利用規約、著作権、個人情報の取り扱い、アクセス頻度を事前に見直します。個人情報や機密データを扱う場合は、利用目的、適用法令、必要な許可や同意を踏まえて取得・利用の可否を判断してください。
5. ディープクローラーは営業・マーケティングの成果向上に役立つ?
複数ページに分かれた商品、物件、競合情報を集約することで、リード候補の整理や市場分析、意思決定を支援できます。成果は取得するデータの品質と運用方法によって変わるため、重複や欠落を検証し、担当者が判断できる形に整えることが重要です。
まずは実際の対象ページを1つ使い、抽出精度と出力形式が用途に合うかを試すと、導入範囲を判断しやすくなります。
ThunderbitでAIディープクローラーを体験 Get Started Free
さらに詳しく知りたい人はこちらもチェック!




