
正直なところ、インターネットはまるで日々広がり続けるジャングルのようなもの。毎日25万以上の新しいウェブサイトが生まれ、Googleの検索インデックスには300億ページ以上が登録されています。こんな膨大な情報を検索エンジンはどうやって管理しているのか、企業はどうやって必要な情報を見つけているのか、不思議に思ったことはありませんか?SaaSや自動化の現場で長く働いてきた私も、「web crawlerとweb crawlingって何が違うの?」とよく聞かれます。実はこの2つ、似ているようで全然違うんです。混同すると、思わぬトラブルに巻き込まれることも。
営業でリードを探している人、ECサイトで価格調査をしている人、あるいは次の会議でちょっと知的に見せたい人も、web crawlerの仕組みやスクレイパーとの違い、そしてThunderbitのような最適なツール選びがどれだけ業務効率を左右するか、一緒に見ていきましょう。
web crawlerの基本:web crawlerとは?

イメージしてみてください。毎日すべての本棚を巡回して新しい本がないかチェックする、超几帳面な図書館司書。web crawlerはまさにそんな存在です。ただし、対象は本ではなく世界中のウェブページ。web crawler(スパイダーやボットとも呼ばれます)は、自動でウェブ上を巡回し、リンクをたどってページを発見・記録していくプログラムです。GoogleやBingなどの検索エンジンは、このクローラーによって膨大なインデックスを作り、私たちがウェブ検索できるようにしています。
「Googlebot」や「Bingbot」という名前を聞いたことがある人も多いはず。これらは有名なweb crawlerです。最近ではFirecrawlのように、開発者や企業が自社サイトをクローリングし、AIや分析用の構造化データに変換できる新しいツールも登場しています。
ここで大事なのは、web crawlingはページの発見・インデックス化が目的で、特定のデータを抜き出すことではないという点。データ抽出はウェブスクレイピングの役割です(このあと詳しく説明します)。
web crawlingの仕組み
web crawlerの一日を追いかけてみましょう。クローラーは「シードURL」と呼ばれる出発点のリストを持ったデジタル探検家のようなもの。流れはこんな感じです:
- シードURL: 既知のウェブアドレスからスタート。
- 取得&解析: 各URLにアクセスし、ページを取得してリンクを抽出。
- リンクの追跡: 新たに見つけたリンクを「次に巡回するリスト」に追加。
- インデックス化: ページの内容やメタデータを保存。
- ポライトネス: robots.txtを確認し、サーバーに負荷をかけないようリクエスト間隔を調整。
- 継続的な更新: ウェブは常に変化するため、定期的にページを再訪問して最新情報を保つ。
まるで街中を歩き回り、すべての通りや新しいお店を地図に書き加え、変化があればその都度アップデートするようなイメージです。
web crawlerの主な構成要素
技術に詳しくなくても、基本構造を知っておくと役立ちます:
- URLフロンティア(キュー): 次に巡回するURLのリスト。
- フェッチャー/ダウンローダー: 実際にウェブページを取得する部分。
- パーサー: ページからリンクや情報を抽出する役割。
- 重複排除&URLフィルター: 同じページを何度も巡回しないように管理。
- データ保存/インデックス: 発見したコンテンツを保存する場所。
新聞を集める人、見出しをマークする人、切り抜きをファイリングする人、次に読む新聞を管理する人——そんな分業体制をイメージすると分かりやすいです。
サイトのクローリング方法とツール
ビジネスユーザーの中には「自分でクローラーを作ろう」と考える人もいるかもしれませんが、正直おすすめしません。Googleのような検索エンジンを作るのでなければ、既存のツールを使うのが賢い選択です。
代表的なweb crawlingツール:
- Scrapy: オープンソースで開発者向け、大規模案件に最適。
- Apache Nutch: ビッグデータのインデックスや研究用途で利用。
- Heritrix: インターネットアーカイブの公式クローラー。
- Screaming Frog SEO Spider: SEO担当者に人気のサイト監査ツール。
- Firecrawl: APIベースで、サイト全体の構造化データ抽出も可能な最新ツール。
注意点: これらの多くは技術的な設定が必要です。ノーコードツールでも、HTML要素の選択やサイト構造の変化、動的コンテンツへの対応など、慣れるまで少し学習が必要な場合があります。数ページだけデータを取得したい場合は、フル機能のクローラーは不要かもしれません。
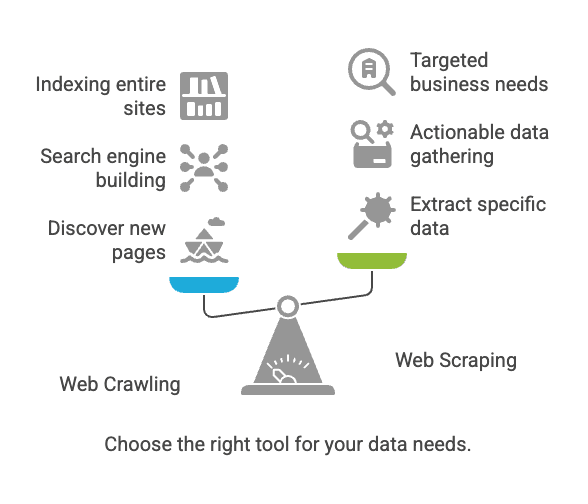
web crawlingとウェブスクレイピングの違い
ここで多くの人が混乱しがちですが、クローリングとスクレイピングは似て非なるものです。
| 項目 | ウェブクローリング | ウェブスクレイピング |
|---|---|---|
| 目的 | ページの発見・インデックス化 | ページから特定データを抽出 |
| 例え | すべての本をカタログ化する司書 | 必要な情報だけを抜き書きする人 |
| 出力 | URLリスト、ページ内容、サイトマップ | 構造化データ(CSV、Excel、JSONなど) |
| 主な利用者 | 検索エンジン、SEOツール、アーカイブ | 営業、EC、アナリスト、リサーチャー |
| 規模 | 数十億ページ(広範囲) | 数十〜数千ページ(ターゲット型) |
簡単に言うと: クローリングはページを見つける作業、スクレイピングは必要なデータを抜き出す作業です(nimbleway.com)。
web crawling・スクレイピングの課題とベストプラクティス
主な課題
- サイト構造の変化: ちょっとしたデザイン変更でもツールが動かなくなることも(octoparse.com)。
- 動的コンテンツ: JavaScriptで表示されるデータは、基本的なクローラーでは取得できない場合が多い。
- アンチボット対策: CAPTCHAやIPブロック、ログイン必須などでアクセス制限されることも。
- スケール: 数千ページを巡回するとPCに負荷がかかったり、IPがブロックされるリスクも。
- 法的・倫理的配慮: 公開データの取得は多くの場合問題ありませんが、利用規約やプライバシー法の確認は必須(web.instantapi.ai)。
ベストプラクティス
- 最適なツール選び: コーディング不要ならノーコード型スクレイパーから始めましょう。
- データの目的を明確に: 何のために、どんなデータが必要かを事前に整理。
- サイトポリシーの遵守: robots.txtや利用規約を必ず確認。
- サーバーへの配慮: リクエスト間隔を空け、過度なアクセスは避ける。
- メンテナンスを前提に: サイトは変化するもの。定期的な設定見直しを想定。
- データの品質管理: 結果は安全に保存し、重複やエラーもチェック。
クローリングとスクレイピングの主な活用例
web crawling
- 検索エンジンのインデックス作成: GooglebotやBingbotがウェブ全体を巡回し、検索結果を最新に保つ(en.wikipedia.org)。
- ウェブアーカイブ: インターネットアーカイブがWayback Machine用にサイトを保存。
- SEO監査: サイト内のリンク切れやタグ漏れをチェック。
ウェブスクレイピング
- 価格調査: 小売業者が競合商品の価格を自動取得(nextgeninvent.com)。
- リード獲得: 営業チームがディレクトリから連絡先を抽出。
- コンテンツ集約: ニュースや求人サイトが複数ソースから情報を集約。
- 市場調査: レビューやSNS投稿を分析し、消費者の声を収集。
豆知識: EC企業の8割以上が外部データ取得にウェブスクレイピングを活用しています。もし未導入なら、競合はすでに始めているかもしれません。
クローリングとスクレイピング、どちらを使うべき?
判断のポイントは以下の通り:
-
新しいページやサイト全体を発見・インデックス化したい?
→ web crawlingを選択。
-
取得したいデータのページがすでに分かっている?
→ ウェブスクレイピングが最適。
-
検索エンジンやアーカイブを構築したい?
→ クローリングが必要。
-
営業や価格調査、リサーチなど、実用的なデータが欲しい?
→ スクレイピングが最適。
-
迷ったら?
→ まずはスクレイピングから始めましょう。多くのビジネス用途はクローリング不要です。
ビジネスユーザーの多くは、スクレイピング——すぐに使える構造化データの取得——が求められているはずです。
ビジネスユーザー向けウェブスクレイピング:Thunderbitの強み
ここからは、特に非エンジニアのビジネスユーザーにとって、なぜスクレイピングが重要なのか、そしてThunderbitがどのように役立つのかを解説します。
「簡単」と謳うスクレイピングツールに何日も悩まされた経験、ありませんか?Thunderbitは、ウェブデータの抽出を“2クリック”で完結できるよう設計されています。
Thunderbitの主な特長:
- 2クリック操作: 「AIで項目を自動検出」→「スクレイピング開始」だけ。コーディングや複雑な設定は不要。
- URL・PDF一括対応: 複数URLやPDFからのデータ抽出も簡単。
- 多彩な出力先: Google Sheets、Airtable、Notionへの直接出力やCSV/JSONダウンロードも追加料金なし。
- サブページ自動取得: 商品詳細などの下層ページも自動で巡回し、データを拡充。
- AI自動入力: フォーム入力や繰り返し作業も自動化。面倒な作業はAIにお任せ。
- 無料のメール・電話番号抽出: ページ内の連絡先情報もワンクリックで取得。
- クラウド・ブラウザ両対応: クラウド高速処理と、ログインページ対応のブラウザスクレイピングを選択可能。
- 学習不要: 営業・EC・マーケティング担当者向けに直感的な設計。
さらに詳しい活用例は、Amazon商品データの取得、Google検索結果のスクレイピング、Excelへのデータ抽出などのガイドもご覧ください。
Thunderbitと従来型ウェブスクレイパーの比較
ビジネスユーザー目線で、従来型ツールと比較してみましょう:
| 機能/ニーズ | Thunderbit | 従来型ウェブスクレイパー(例:Scrapy, Nutch) |
|---|---|---|
| 導入 | 2クリック、コーディング不要 | 技術的なセットアップ・スクリプト作成が必要 |
| 習得難易度 | ほぼ不要 | 非エンジニアには難しい場合も |
| サブページ対応 | AIで自動巡回 | 手動スクリプトや高度な設定が必要 |
| 一括URL/PDF | 標準対応 | 標準では非対応が多い |
| 出力形式 | Google Sheets、Airtable、Notion、CSV | CSV、JSON(連携は手動が多い) |
| 変化対応力 | AIがサイト変更に自動対応 | サイト変更時は手動で修正 |
| ビジネス用途 | 営業、EC、SEO、業務効率化 | 検索エンジン、研究、アーカイブ |
| スケジューリング | 自然言語で簡単設定 | Cronや外部ツールが必要 |
| 価格 | 月額1,500円〜、無料プランあり | 無料/OSSだが導入・保守コスト高め |
| サポート | ユーザー重視の最新UI | コミュニティ中心、開発者向け |
Thunderbitなら「このデータが欲しい」と思った瞬間から、IT部門に頼らずすぐにスプレッドシート化できます。
まとめ:ビジネスに最適なアプローチを選ぼう

ポイントを整理しましょう:
- web crawlingはページの発見・インデックス化向け(検索エンジンやサイト監査など)。
- ウェブスクレイピングは特定データの抽出向け(リード獲得、価格調査、コンテンツ集約など)。
- 多くのビジネスユーザーにはスクレイピングが最適。コーディング不要で始められます。
インターネットは今後もどんどん巨大化・複雑化していきますが、正しいアプローチとツールがあれば、膨大な情報もビジネスの武器に変えられます。複雑なスクレイパーに悩まされたり、IT部門の手を借りるのに時間がかかっているなら、Thunderbitをぜひ試してみてください。2クリックで驚くほど簡単にデータ取得ができ、週末の時間も取り戻せるかもしれません。
Thunderbitの実際の動きを見てみたい人は、Chrome拡張機能をインストールするか、Thunderbitブログで最新の活用法をチェックしてみてください。
スクレイピングを楽しんでください(クローリングは、もし次のGoogleを作るなら…)!
よくある質問
1. ビジネスでクローラーとスクレイパー両方必要ですか?
必ずしも両方必要ではありません。取得したいデータのページが分かっていれば、Thunderbitのようなウェブスクレイパーだけで十分です。新しいページの発見やサイト全体のマッピング、SEO監査などが必要な場合はクローラーが役立ちます。
2. ウェブスクレイピングは合法ですか?
一般的に、公開データの取得は合法です(ログイン回避や利用規約違反、機密情報の収集を除く)。ただし、商用利用の場合はrobots.txtやプライバシーポリシーの確認をおすすめします。
3. Thunderbitは他のウェブスクレイピングツールと何が違う?
Thunderbitは非エンジニアのビジネスユーザー向けに設計されています。従来のスクレイパーのようなHTML知識や手動設定は不要。AIが項目抽出やサブページ巡回、出力形式の選択まで2クリックで完結します。
4. Thunderbitは動的サイトやログインページにも対応していますか?
はい。Thunderbitは、ログインが必要なページや動的コンテンツにも対応したブラウザベースのスクレイピングと、高速なクラウドスクレイピングの両方を提供しています。用途に応じて最適なモードを選べます。
さらに詳しく知りたい方へ
AIウェブスクレイパーを無料で試す Get Started Free




