
CRMを同期したり、配送状況を取得したり、2つのSaaSツールを連携したりするたびに、裏側ではREST APIが重要な役割を果たしています。普段はあまり意識しませんが、何か壊れたときに初めてその存在を思い出す、そんな存在です。
おもしろいのは、開発者の間ですら、API が「RESTful」である条件についてかなり混乱があることです。この言葉はあまりにも雑に使われるため、あるRedditスレッドでは率直にこう書かれていました。「Roy Fieldingの定義に基づいて、本当にRESTfulなAPIを1つでも作ったとは思えない。」 しかもこれは、ビジネスユーザーではなく開発者の発言です。この概念は、UC IrvineでのRoy Fieldingによるに由来し、RESTをアーキテクチャスタイル、つまり設計上の制約の集合として説明していました。プロトコルでも、製品でも、ダウンロードして使う仕様書でもありません。
それでもによると、API担当者の93%がRESTを使っています。つまり、ほぼ全員が使っているのに、実際に何が必要なのかを誤解しているチームが驚くほど多いのです。この記事では、REST APIの6つの基本特性をわかりやすく解説し、多くのチームが誤りやすいポイントを示し、自己診断に使える成熟度モデルを紹介し、SOAP・GraphQL・gRPCといった代替手段と比較します。
REST APIとは?(平易な定義)
REST(Representational State Transfer)は、ソフトウェア同士がネットワーク越しにどう通信すべきかを定める設計ルールの集合です。
より正確には、RESTはアーキテクチャスタイルであり、ステートレス性、キャッシュ可能性、統一インターフェースなどの制約を定義します。これらが、クライアント(ブラウザ、モバイルアプリ、自動化ツールなど)がサーバー(データが置かれている場所)とどうやり取りするかを導きます。RESTは通常HTTP上で動作し、返却形式はJSONであることが多いですが、REST自体は特定のプロトコルやデータ形式に縛られません。
たとえるなら、ディナーパーティーの作法のようなものです。RESTは、何を出すか、何語を話すかまでは決めません。代わりに、どう料理を渡すか、どうおかわりを頼むか、どう食事を終えたことを伝えるかを定めます。同じ作法に従う2つのシステムは、会ったことがなくても予測可能にやり取りできます。
RESTではないもの: RESTはインストールする製品ではありません。HTTPやSOAPのようなプロトコルでもありません。また、APIを「RESTful」と呼んだからといって、Fieldingの元の制約に完全準拠しているわけではありません。多くの場合、リソースURLとHTTPメソッドを使っている、という意味にとどまります。「RESTっぽい」と「本当にRESTful」の差は、業界でも最大級の混乱ポイントのひとつです。このあと詳しく見ていきます。
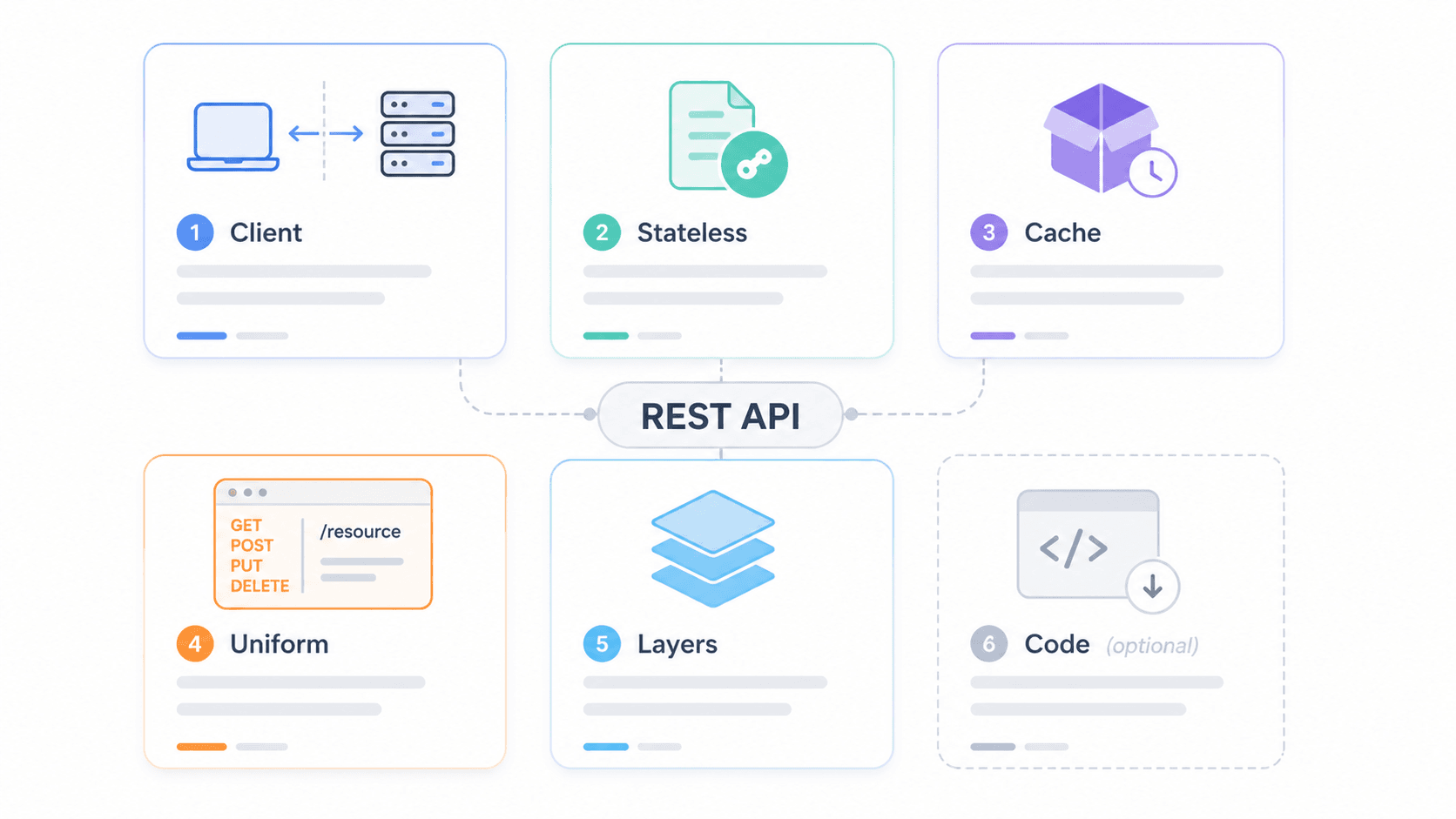
REST APIの6つの特性を一覧で見る
深掘りする前に、まずは早見表です。Fieldingは、APIがRESTfulとみなされるために従うべき6つの制約を定義しました。うち5つは必須で、1つは任意です。
This paragraph contains content that cannot be parsed and has been skipped.
これらの制約が実際のシステムでどう組み合わさるかをイメージするには、次のような階層型アーキテクチャを思い浮かべてください。
1Client / Mobile App
2 ↓
3CDN / Edge Cache (e.g., Cloudflare)
4 ↓
5API Gateway (rate limiting, auth, CORS)
6 ↓
7Load Balancer
8 ↓
9Application Servers
10 ↓
11Database / Internal Servicesクライアントが直接やり取りするのはCDN層だけです。その先に何層あるのか、クライアントは知りません。これがレイヤードシステムの制約の働き方であり、セキュリティ、キャッシュ、スケーリングをクライアントに意識させずに実現できる理由でもあります。
では、ここから各項目を詳しく見ていきましょう。
REST APIの特性を1つずつ解説
クライアント・サーバー分離
Fieldingが最初に挙げた制約は、クライアント(ユーザーが触れる部分)とサーバー(データがあり、ロジックが動く部分)を分けることです。彼はこれを関心の分離と呼びました。
なぜ実務で重要なのでしょうか。たとえばモバイル銀行アプリは、銀行側が口座データベースや取引エンジンをいじらなくても、画面全体を作り直せます。は、コンタクト、キャンペーン、ジャーニー、プッシュ通知をリソースエンドポイントとして提供しています。カスタムダッシュボードを作る場合でも、モバイルアプリを作る場合でも、サードパーティツールを接続する場合でも、バックエンドは同じです。
ビジネスチームにとっては、これは開発のスピード向上につながります。フロントエンドのデザイナーとバックエンドのエンジニアが、同じリリースサイクルに縛られる必要はありません。API契約が安定している限り、両者は独立して前進できます。
ステートレス性
リクエスト間に記憶を持たないこと。クライアントからサーバーへの各呼び出しには、その処理に必要な情報がすべて含まれていなければならず、サーバーは前回のやり取りを保持しません。
私はこれを、サポート窓口に電話するたびに毎回最初から事情を説明し直すようなものだと考えています。面倒ですか? もちろんです。でも利点は大きいのです。対応可能などの担当者でも助けられますし、コールセンターは設計を変えずに担当者を500人増やせます。これが水平スケーリングです。
技術的には、ステートレスとは sticky session がないことを意味します。ロードバランサーは次のリクエストを、正常な任意のサーバーに振り分けられます。1台のサーバーが落ちても、別のサーバーが即座に引き継ぎます。Fieldingの論文は、ステートレス性が可観測性(監視ツールが各リクエストを独立して理解できる)、信頼性(障害が共有セッション状態を壊さない)、拡張性(サーバーがリクエスト間でリソースを解放できる)を高めると述べています。
ただし実際のシステムには、認証トークン、ショッピングカート、OAuthフローなどがあります。重要なのは「どこにも状態が存在しない」ことではありません。サーバーが自分のメモリ内にクライアントのセッション状態をリクエスト間で保持しない、という点です。その役割はトークン、データベース、共有キャッシュが担います。
キャッシュ可能性
このレスポンスは再利用できるのか? それがキャッシュ可能性の問いです。レスポンスは、キャッシュできるかどうかを明示的に示すべきで、もし可能ならクライアントや中間層(CDNなど)は、同等の将来リクエストにそれを再利用します。これによりサーバー負荷を減らし、速度を上げられます。
HTTPの仕組みは単純です。Cache-Control、ETag、Last-Modified、Expires といったヘッダーが、レスポンスの有効期限と再確認のタイミングをキャッシュに伝えます。ビジネス視点では、「この回答は次の1時間は有効です」「毎回最新のものを確認してください」と書かれたラベルのようなものだと考えるとわかりやすいでしょう。
性能面の効果は実際に大きいです。の試験では、キャッシュヒットの末端応答時間が50〜100ms改善したと報告されています。さらにFielding自身の論文でも、Webトラフィックが1994年の1日10万リクエストから、1999年には1日6億リクエストへ拡大したことが記録されており、その成長要因としてキャッシュが重要だったとされています。
典型的にキャッシュしやすいもの: 商品カタログ、公開ブログ記事、国・通貨一覧、APIドキュメント。
典型的にキャッシュしにくいもの: 個人ダッシュボード、チェックアウト合計、銀行残高、管理者レポート。
統一インターフェース
Fielding自身が、RESTを他のアーキテクチャスタイルから区別する中心的な特徴だと呼んだのがこの制約です。クライアントがリソースとやり取りする方法を標準化し、APIを予測しやすくします。
この大枠の中には、4つの下位制約があります。
- リソース識別: すべてのリソースに安定したURIを付ける。
/customers/123は顧客、/orders/456は注文です。 - 表現による操作: クライアントはサーバー内部のオブジェクトではなく、リソースの表現(JSON、XML、HTML)を扱います。
- 自己記述的メッセージ: リクエストとレスポンスには、メソッド、ステータスコード、コンテンツタイプ、エラー詳細など、中間層やクライアントが理解できる十分なメタデータが含まれます。
- HATEOAS(Hypermedia as the Engine of Application State): レスポンスに関連アクションやリソースへのリンクを含め、クライアントが次に何をすべきかを各エンドポイントを固定せずに発見できるようにします。
HTTPメソッドとCRUDの対応は、統一インターフェースの中で最も目に見えやすい部分です。
This paragraph contains content that cannot be parsed and has been skipped.
では、GETは安全であるべきで、GET・PUT・DELETEは冪等であるべきだと明記されています。GitHub、Stripe、Spotifyなどの有名APIはこのパターンにかなり忠実で、1つ覚えれば別のAPIもすぐに理解できる理由になっています。
レイヤードシステム
クライアントは、オリジンサーバーに接続しているのか、CDNキャッシュなのか、APIゲートウェイなのか、ロードバランサーなのかを知りません。そこが重要なのです。各コンポーネントは隣の層だけを見ればよいからです。
これによって次のようなことが可能になります。
- CloudflareのようなCDNをAPIの前段に置いて、レスポンスをキャッシュし高速化する
- APIゲートウェイ(AWS API Gateway、Kong、Apigeeなど)が認証、レート制限、クォータ管理を担当する
- ロードバランサーがステートレスなリクエストを複数のアプリサーバーに分散する
では、がAWS API Gatewayを使い、26%がAzureのゲートウェイを使い、31%が複数のゲートウェイを同時に使っているとされています。階層型アーキテクチャは理論ではなく、本番システムが実際に動く仕組みそのものです。
トレードオフとして、層が増えるほどレイテンシも少し増えます。ただしFieldingは、多くの実システムでは、中間層での共有キャッシュがそのオーバーヘッドを十分に補うと主張しました。
コードオンデマンド(任意)
これは少し変わり種です。コードオンデマンドは、RESTの6つの制約の中で唯一の任意項目で、サーバーがJavaScriptのような実行可能コードを送って、その場でクライアント機能を拡張できます。
現実世界で最もよくある例は、WebページがサーバーからJavaScriptを読み込むケースです。ただし、モバイルアプリ、バックエンドジョブ、自動化ツールが使う典型的なJSON REST APIでは、コードオンデマンドはほとんど使われません。APIクライアントは、リモートサーバーから任意のコードを実行したいわけではないのです。
多くの読者にとって、この制約は脚注のようなものです。Fieldingのモデルには完全性のために含まれていますが、日々のAPI評価ではほとんど論点になりません。
多くの人が誤解していること:本当にRESTfulなAPIは少ないのか?
誰もあまり語りたがらない点があります。自分たちを「RESTful」と呼ぶ本番APIの多くは、実際にはRESTっぽい慣習を持ったHTTP JSON APIにすぎません。リソースURL、HTTPメソッド、ステータスコードを使っているだけで、それ以上ではないのです。r/softwarearchitecture のRedditスレッドでは、Fielding準拠のREST APIを本当に作ったことはないと認める開発者もいました。r/learnprogramming の別の議論では、「RESTful」の意味について誰も合意できるのか、という争いにまで発展していました。
2026年のある調査では、16人のREST API専門家にインタビューしたところ、ガイドラインは使いやすさを向上させる一方で、開発者は厳格なRESTルールにかなり抵抗を示し、ガイドラインの多さや自分たちの組織への適合性の低さを障壁として挙げていました。
では、実務では制約はどう扱われているのでしょうか。
This paragraph contains content that cannot be parsed and has been skipped.
多くのチームがHATEOASを省く理由: クライアント開発者は、実行時に動的にリンクをたどるより、OpenAPIドキュメントを読んだりSDKを使ったりするほうを好みます。HATEOASには、安定したメディアタイプ、リンク関係の定義、ワークフローのモデリングが必要です。短期的なコストは高く、多くのチームにとって見返りがはっきりしません。
実務的な結論は、APIが100% Fielding準拠でなくても十分役立つ、ということです。ただし、どの制約を省いたのか、そして省くことで何を失うのかを理解していれば、設計や統合の判断はもっと良くなります。
Richardson成熟度モデル:あなたのAPIは本当はどれくらいRESTfulか?
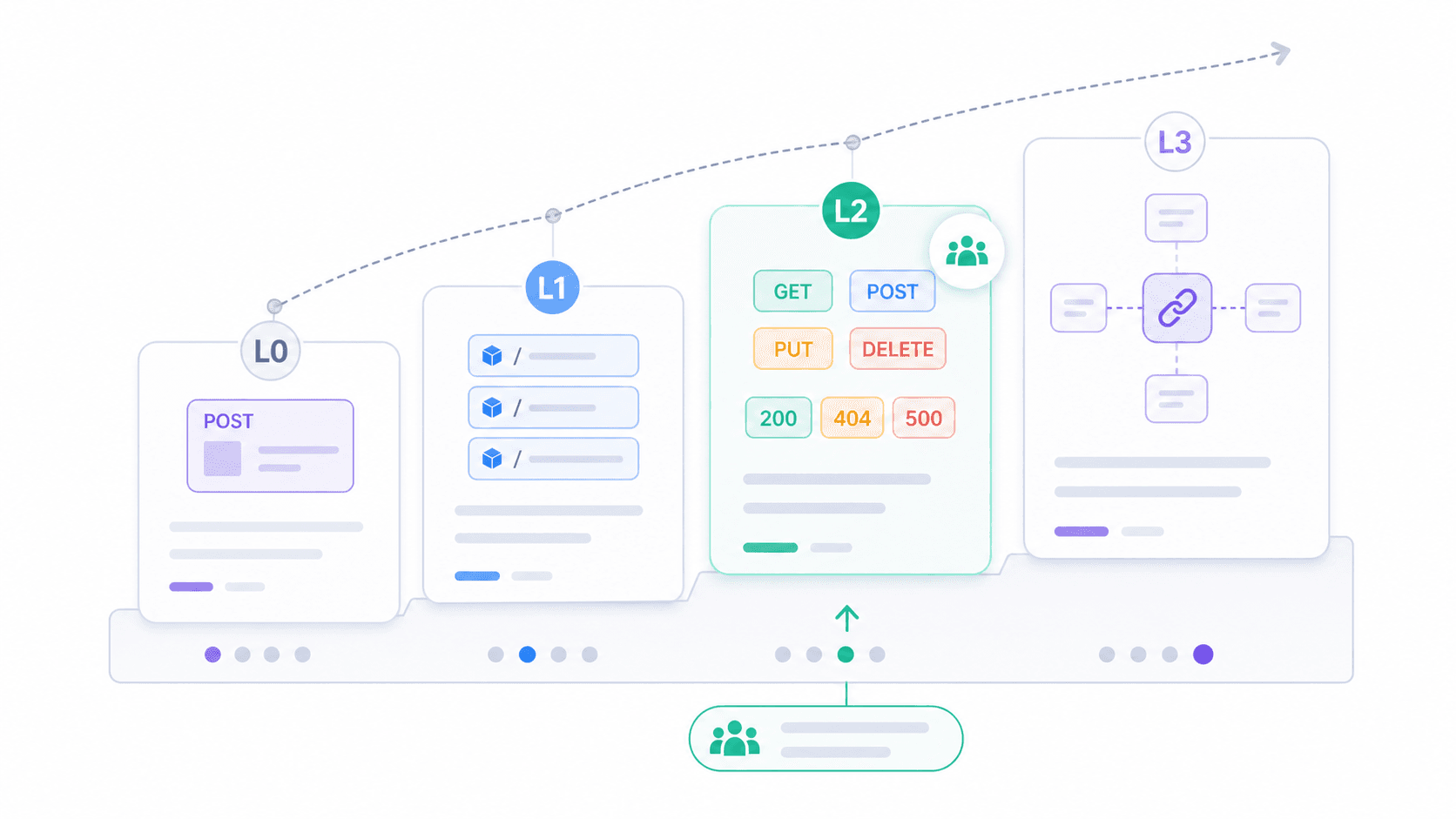
「RESTfulか、そうでないか?」という二択が役に立たないと感じるなら、Richardson成熟度モデルのほうが実践的です。Leonard Richardsonが提唱し、このモデルは、RESTの採用度を4段階に分けます。
This paragraph contains content that cannot be parsed and has been skipped.
実際に遭遇するAPIの多くは、レベル2にあります。リソース、動詞、ステータスコードを正しく使っているのです。それで十分に実用的で、相互運用性も高く、ツールのサポートも充実しています。レベル3はFieldingが思い描いた完全な姿ですが、採用はまだ少ないままです。
あなたのAPIはどこにある? 次のように自問してみてください。
- すべてを1つのエンドポイントで扱っていますか?(レベル0)
- それぞれの業務オブジェクトに個別のURIがありますか?(レベル1以上)
- HTTPメソッドとステータスコードを正しく使っていますか?(レベル2)
- 外部ドキュメントに頼らず、レスポンスだけで次にできることがわかりますか?(レベル3)
このモデルは、「RESTかどうか」論争を整理するうえで、私が見つけた中で最も役立つツールです。二択の判断を、連続した段階に置き換えてくれます。
よくあるREST APIのミスと、その避け方
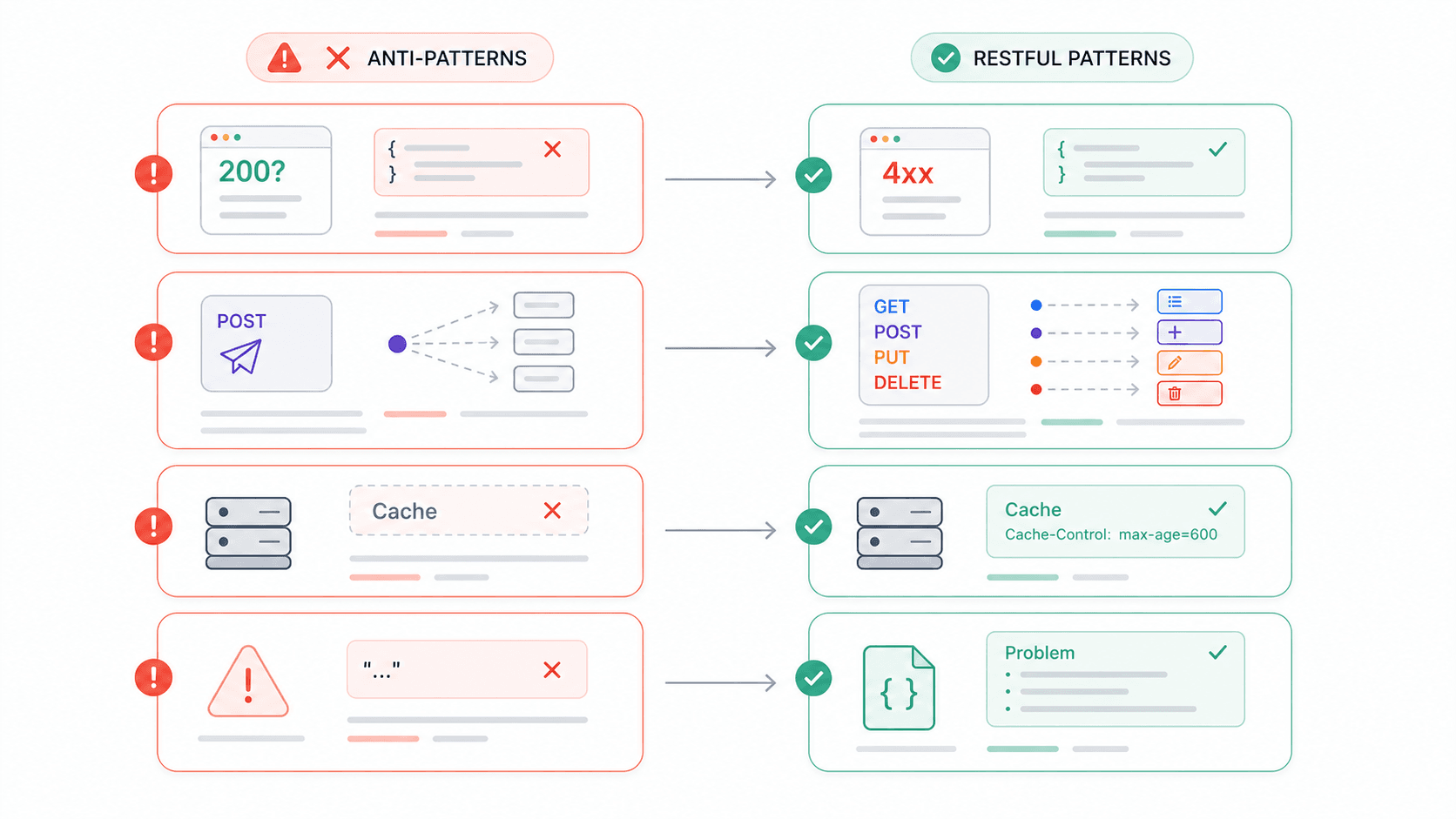
私は第三者APIの統合作業にかなりの時間を費やしてきたので、不満のリストには事欠きません。開発者フォーラムを見ると、同じ思いをしている人は多いようです。ここでは、よく見かけるアンチパターンを挙げます。どれもRESTの制約違反に直接つながっています。
This paragraph contains content that cannot be parsed and has been skipped.
では、公式HTTPステータスコードの使用が必須で、エラー応答には Problem JSON を推奨しています。では、Problem Detail は4xx/5xxにのみ使うべきで、2xxと混在させてはいけないと定めています。これは学術的なお作法ではなく、大規模にAPIを運用しているチームの本番基準です。
r/learnprogramming のRedditスレッドでは、エラーでも常にHTTP 200を返してよいのか、と本気で質問する開発者がいました。2026年になってもこの疑問が出てくること自体、こうしたアンチパターンがいかに根強いかを示しています。
REST vs SOAP vs GraphQL vs gRPC:REST APIの特性を比較する
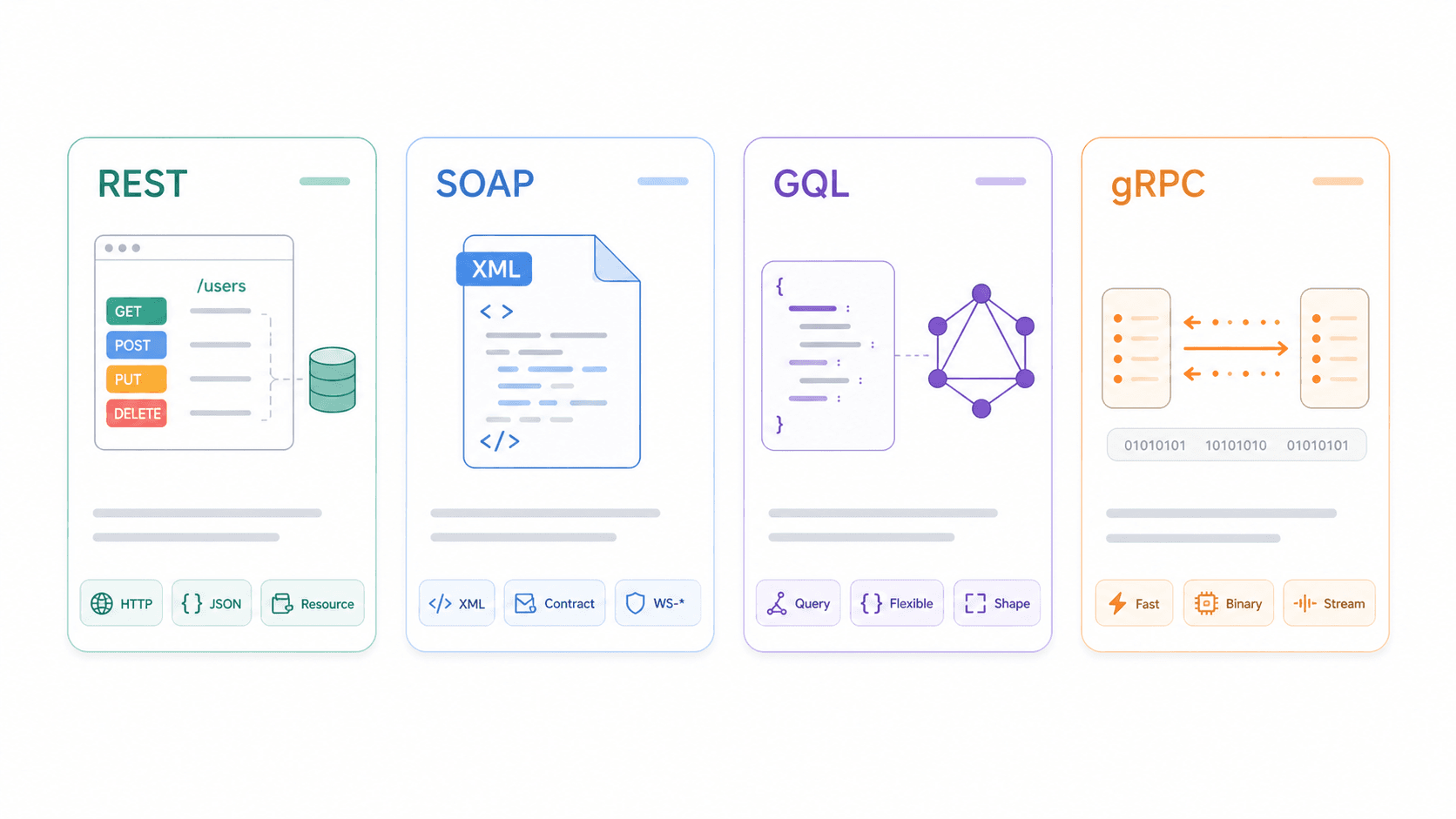
RESTを単体で理解することも有益ですが、代替手段との違いで捉えるとさらにわかりやすくなります。
| 観点 | REST | SOAP | GraphQL | gRPC |
|---|---|---|---|---|
| プロトコル / 伝送 | アーキテクチャスタイル、通常はHTTP | XMLベースのメッセージングプロトコル、HTTP、SMTPなど | クエリ言語 / ランタイム、通常はHTTP上 | HTTP/2上のRPCフレームワーク |
| データ形式 | 通常はJSON、XML/HTMLも可 | XMLのみ(WSDL契約) | クエリ形状に一致するJSON | Protocol Buffers(バイナリ) |
| キャッシュ | ✅ 設計次第でHTTPキャッシュを素直に使える | ❌ 複雑で、HTTPキャッシュに向かない | ⚠️ 難しい(POST + 単一エンドポイント + クエリ差分) | ❌ HTTPキャッシュ向きではない |
| リアルタイム対応 | ❌ ポーリング / webhook | ❌ エンタープライズ向けメッセージング | ✅ Subscriptions | ✅ ストリーミング、低レイテンシ |
| 学習コスト | 低〜中 | 高 | 中 | 中〜高 |
| 向いている用途 | 公開API、CRUD、Web/モバイル連携 | エンタープライズ / レガシー、厳格な契約、コンプライアンス | 複雑なクエリ、柔軟なフロントエンド、モバイルアプリ | マイクロサービス間、高性能な内部通信 |
では、互換性、データ形状、操作、利用者向けツールを基準に選ぶことが推奨されています。
どれを選ぶべきか:
- REST は、広い互換性、シンプルなCRUD操作、HTTPキャッシュが必要なときに強いです。公開APIやWeb/モバイル連携の定番です。
- SOAP は、厳格な契約、WS-Security要件、今後もなくならないレガシー連携があるエンタープライズシステムで今でも有効です。
- GraphQL は、フロントエンドが柔軟で入れ子の深いクエリを必要とし、過剰取得や不足取得を避けたいときに向いています。複雑なモバイルアプリでよく使われます。
- gRPC は、低レイテンシとバイナリシリアライズが重要で、ブラウザ互換性がそれほど重要でない内部マイクロサービス通信向けです。
実際のREST例としては、がわかりやすいでしょう。シンプルなPOSTエンドポイント(/distill と /extract)を使い、JSONのリクエスト/レスポンスボディ、Bearerトークン認証、標準HTTPステータスコード(400、401、402、408、422、429、500、502、503、504)を採用しています。SOAP契約やgRPCの複雑さを必要とせずに、本番のAI製品でRESTの特性を示しています。HATEOASの見本ではありませんが、ビジネスチームと開発者のどちらにとっても統合しやすい、実用的なレベル2のAPIです。
REST APIの特性がビジネスチームにとって重要な理由
営業、オペレーション、Eコマース——こうしたチームの多くはAPIコードを書きません。それでも、ベンダーを選び、ツールをつなぎ、自動化ワークフローを組み立てているはずです。そしてREST APIの品質は、その連携がどれだけ面倒か、あるいは楽かに直結します。
ツール連携: CRMがマーケティング自動化プラットフォームと同期するとき、REST APIの設計次第で、その同期は安定にも脆弱にもなります。は、コンタクト、キャンペーン、ジャーニー、プッシュ通知を予測しやすいリソースエンドポイントで管理します。これらがRESTの慣習に従っていれば、RevOpsチームは独自の回避策なしで自動化できます。
Eコマース運用: は、フルフィルメント注文、追跡番号、配送状態を管理します。配送アプリやフルフィルメントツールはこの層に依存しています。APIが適切に設計されていれば——正しいステータスコード、キャッシュ可能なカタログデータ、明確なエラーメッセージ——物流パイプラインはスムーズに流れます。そうでなければ、午前2時に原因不明の障害が起きます。
ベンダー評価: 6つの制約を知っていれば、実務的なチェックリストになります。
- APIは標準ステータスコードを使っていますか、それとも失敗がすべて200 OKに見えますか?
- エラーは、自動化ツールが復旧できるほど具体的ですか?
- レート制限、ページネーション、認証について明確なドキュメントがありますか?
- よく使うレスポンスをキャッシュして負荷を減らせますか?
データ抽出と自動化: のようなツールは、RESTベースのアーキテクチャを使い、ビジネスユーザーがWebサイト、PDF、画像から構造化データを抽出し、Google Sheets、Airtable、Notion、Excelへ出力できるようにします。は、2クリックのUIの裏で複雑な処理を担いますが、その下を支えているのは、ステートレスなリクエスト、JSONレスポンス、標準エラーといったRESTの原則です。これが統合層の信頼性を高めています。
もう1つ、見逃せないデータがあります。Postmanの2025年レポートでは、AIエージェントを前提にAPIを設計している開発者はわずかで、51%はAIエージェントからの不正または過剰なAPI呼び出しを懸念しているとされました。自動化とAI主導のワークフローがビジネスチームの標準になるにつれ、予測可能なRESTパターン、最小権限のAPIキー、レート制限は、単なる開発者の関心事ではなく、運用リスクそのものになります。
Thunderbitがビジネスユーザー向けにREST原則をどう活かしているか
私たちはを、「ほとんどのユーザーはREST仕様書を読む必要がないし、読むべきでもない」という前提で作りました。ただし、Thunderbitを使いやすくしている設計は、この記事で紹介しているREST特性と同じ考え方に根ざしています。
実際の流れを簡単に見てみましょう。
- からChrome拡張機能をインストールし、データを抽出したいWebサイト、PDF、画像を開きます。
- 「AI Suggest Fields」をクリックすると、ThunderbitのAIがページを読み取り、列の構造化テーブルを提案します。たとえば商品名、価格、メールアドレス、ページにあるあらゆる項目です。
- 必要なら列を調整してから、「Scrape」をクリックします。Thunderbitがページネーション、サブページ、動的コンテンツを自動で処理します。
- データをエクスポートします。Google Sheets、Airtable、Notion、CSV、Excelに、無料で、課金壁なしで出力できます。
開発者や自動化ワークフロー向けには、Thunderbitのが、/distill(Markdownのクリーン抽出)と/extract(構造化データ抽出)を、JSONボディと標準HTTPエラーコードを持つREST風のPOSTエンドポイントとして公開しています。Richardson成熟度モデルでいえば、これはしっかりしたレベル2です。リソース、適切なメソッド、意味のあるステータスコードを備えています。
Webスクレイピングやデータ抽出をさらに深く知りたい方には、、、についての詳しいガイドもあります。
重要なポイント
- RESTはプロトコルではなく、アーキテクチャスタイルです。 API設計を導く6つの制約、つまりクライアント・サーバー、ステートレス、キャッシュ可能、統一インターフェース、レイヤードシステム、そして任意のコードオンデマンドを定義します。
- 「RESTful」なAPIの多くは、完全な意味ではRESTfulではありません。 大半はRichardsonレベル2(リソース + HTTP動詞 + ステータスコード)にとどまります。HATEOASとコードオンデマンドは、実装されることがほとんどありません。
- Richardson成熟度モデルは、自己評価に最適なツールです。 「RESTか否か」という二択を、実用的な段階(レベル0〜3)に置き換えられます。
- エラーに200 OKを返す、全部POSTで済ませる、キャッシュヘッダーがない、といったミスは今も多いです。 制約を知っていれば、こうしたアンチパターンを見つけて直しやすくなります。
- REST vs SOAP vs GraphQL vs gRPC は「どれが一番か」ではなく、「どれが合うか」です。 RESTは公開APIとCRUD連携で主流です。GraphQLは複雑なフロントエンド向き。gRPCは内部マイクロサービスで強い。SOAPはエンタープライズやレガシーの文脈で残っています。
- ビジネスチームも、REST特性を理解すると得をします。 ベンダー評価、ツール接続、自動化ワークフロー構築の判断が良くなるからです。のようなツールは、REST原則を活用して、技術的な専門知識がなくてもデータ抽出を使いやすくしています。
よくある質問
REST APIの6つの特性とは何ですか?
RESTの6つの制約は、(1) クライアント・サーバー分離、(2) ステートレス性、(3) キャッシュ可能性、(4) 統一インターフェース、(5) レイヤードシステム、(6) コードオンデマンド(任意)です。最初の5つは、Fieldingの元の定義ではAPIがRESTfulとみなされるための必須条件です。
RESTとRESTfulの違いは何ですか?
RESTは、Roy Fieldingが定義した設計制約の集合であるアーキテクチャスタイルです。「RESTful」は、その制約に従うAPIを指します。実際には、「RESTful」と呼ばれるAPIの多くは部分的にしか準拠しておらず、たいていはリソース、HTTPメソッド、ステータスコードは使っていても、HATEOASやコードオンデマンドは省かれています。
すべてのREST APIは、すべてのREST制約に従っていますか?
いいえ。実際の本番APIの多くは、クライアント・サーバー分離、ステートレス性、基本的な統一インターフェース(リソース + HTTP動詞)には従っています。キャッシュ可能性とレイヤードシステムの設計は実装がまちまちです。HATEOASはまれで、JSON APIでコードオンデマンドが使われることはほぼありません。
RESTとGraphQLの違いは何ですか?
RESTは、標準HTTPメソッド(GET、POST、PUT、DELETE)を使って複数のエンドポイントでリソースを公開します。GraphQLは通常1つのエンドポイントを使い、クエリで欲しいフィールドをクライアントが正確に指定します。RESTはHTTPキャッシュとの相性がより良く、GraphQLは複雑で入れ子の多いデータ要件に対して柔軟で、過剰取得を減らせます。
HATEOASとは何ですか?実際に使っている人はいますか?
HATEOAS(Hypermedia as the Engine of Application State)とは、APIレスポンスに次に使える操作を示すリンクを含めることで、クライアントが各エンドポイントをハードコードせずにAPIをたどれるようにする考え方です。Fieldingが描いたREST像では中心的な要素(Richardsonレベル3)ですが、実際にこれを実装している公開APIはごくわずかです。多くのチームはレベル2で止まり、代わりにドキュメントやSDKに頼っています。
さらに詳しく