

2025年のウェブは、かなり混沌としています。目にするトラフィックの半分は、実は人間ではありません。そう、ボットやクローラーは今やインターネット活動全体の50%超を占めています(Thales Group)。そして、そのうち「良い」ボットといえるのはごく一部です。たとえば、検索エンジン、SNSのプレビュー生成、分析の補助などですね。残りは? まあ、必ずしも助けになる存在ばかりではない、ということです。私はThunderbitで自動化とAIツールの開発に長年携わってきましたが、適切な(あるいは不適切な)クローラーが、SEOを左右し、分析指標をゆがめ、帯域幅を食い尽くし、最悪の場合は本格的なセキュリティインシデントを引き起こすことを、身をもって見てきました。
ビジネスを運営している人、ウェブサイトを管理している人、あるいは自分のデジタル環境をきちんと整えたい人にとって、いまサーバーの扉をノックしている相手を把握することは、これまで以上に重要です。そこで本記事では、2025年版として、知っておくべき主要クローラーをまとめました。何をするのか、どう見分けるのか、そしてどのようにして良いボットには開かれたサイトを保ちつつ、悪いボットは寄せつけないかを解説します。
クローラーが「既知」だとどう分かるのか? User-Agent、IP、そして検証
まずは基本から見ていきましょう。「既知」のクローラーとは、正確には何でしょうか? もっともシンプルに言えば、一定のuser-agent文字列(たとえばGooglebot/2.1やbingbot/2.0)で自分を名乗り、さらに理想的には公開されているIPレンジやASNブロックからクロールしていて、その情報を検証できるボットのことです(Googlebot verification)。Google、Microsoft、Baidu、Yandex、DuckDuckGoといった主要プレイヤーは、自社ボットのドキュメントを公開しており、多くの場合、公式IPを一覧化したツールやJSONファイルも提供しています(Googlebot IP list, Bingbot IP list, DuckDuckBot IPs)。
ただし、注意点があります。user-agentだけに頼るのは危険です。なりすましは非常に多く、悪意あるボットは防御をすり抜けるためにGooglebotやBingbotを装うことがよくあります(SecurityWeek)。そのため、信頼できる方法は二重検証です。user-agentとIPアドレス(またはASN)の両方を、逆引きDNS検索や公開リストを使って確認します。Thunderbitのようなツールを使えば、この作業を自動化できます。ログを抽出し、user-agentを照合し、IPを突き合わせて、あなたのサイトをクロールしている相手の信頼できるリアルタイム一覧を作成できます。
このクローラー一覧の使い方
では、既知クローラーの一覧を実際にどう使えばよいのでしょうか? 私がおすすめする活用法は次のとおりです。
- 許可リスト化: 検索エンジンやSNSプレビュー用のボットが、ファイアウォール、CDN、WAFで誤ってブロックされないようにします。公式IPとuser-agentを使えば、精度の高い許可リストを作れます。
- 分析のフィルタリング: ボットのトラフィックを分析ツールから除外し、数値が実際の人間の訪問者を反映するようにします。GooglebotやAhrefsBotがサイト内をぐるぐる回っている分まで含める必要はありません(SecurityWeek)。
- ボット管理: 攻撃的なSEOツールにはcrawl-delayやスロットリングのルールを設定し、未知または悪意のあるボットはブロックするか、チャレンジを出します。
- ログの自動分析: ThunderbitのようなAIツールを使って、ログ内のクローラー活動を抽出・分類・ラベル付けし、傾向の把握、なりすましの特定、ポリシー更新をしやすくします。
クローラー一覧は、一度作って終わりではありません。新しいボットは次々に現れ、古いものは挙動を変え、攻撃者は年々ずる賢くなっています。Thunderbitで公式ドキュメントやGitHubリポジトリをスクレイピングして更新を自動化すれば、時間も手間も大きく節約できます。
1. Thunderbit: AI搭載のクローラー識別とデータ管理
ThunderbitによるAI搭載クローラー管理 Get Started Free
Thunderbitは単なるAIウェブスクレイパーではありません。クローラートラフィックを理解し、管理したいチームのためのデータアシスタントです。Thunderbitの強みは次のとおりです。
- 意味ベースの前処理: データ抽出の前に、ThunderbitはウェブページやログをMarkdown形式の構造化コンテンツに変換します。この「意味レベル」の前処理によって、AIは読み込む内容の文脈、項目、ロジックを実際に理解できます。従来のDOMベースのスクレイパーが苦手な、複雑で動的なページやJavaScript中心のページ(Facebook Marketplaceや長いコメントスレッドなど)で特に威力を発揮します。
- 二重検証: Thunderbitは公式のクローラーIPドキュメントやASN一覧を素早く収集し、それをサーバーログと照合できます。その結果、手作業の突き合わせが不要な、実用的な「信頼済みクローラー許可リスト」を作れます。
- ログ抽出の自動化: 生のログをThunderbitに読み込ませると、Excel、Sheets、Airtableなどの構造化テーブルに変換してくれます。頻繁な訪問者、不審なパス、既知のボットにラベルを付けることも可能です。そこからWAFやCDNに結果を連携し、自動ブロック、スロットリング、CAPTCHAチャレンジへつなげられます。
- コンプライアンスと監査: Thunderbitの意味ベース抽出は、誰がいつ何にアクセスしたか、そしてその情報をどう扱ったかの監査証跡を明確に残します。これはGDPR、CCPA、その他のコンプライアンス対応で大きな助けになります。
私は、Thunderbitを使ってクローラー管理の作業負荷を80%削減し、どのボットが役に立ち、どのボットが害になり、どのボットが単に偽装しているだけなのかを、ようやく把握できたチームを何度も見てきました。
2. Googlebot: 検索エンジンの基準
Googlebotは、ウェブクローラーのゴールドスタンダードです。Google検索向けにあなたのサイトをインデックスする役割を担っており、これをブロックするのは、デジタル店舗に「営業終了」の札を下げるのとほぼ同じです。
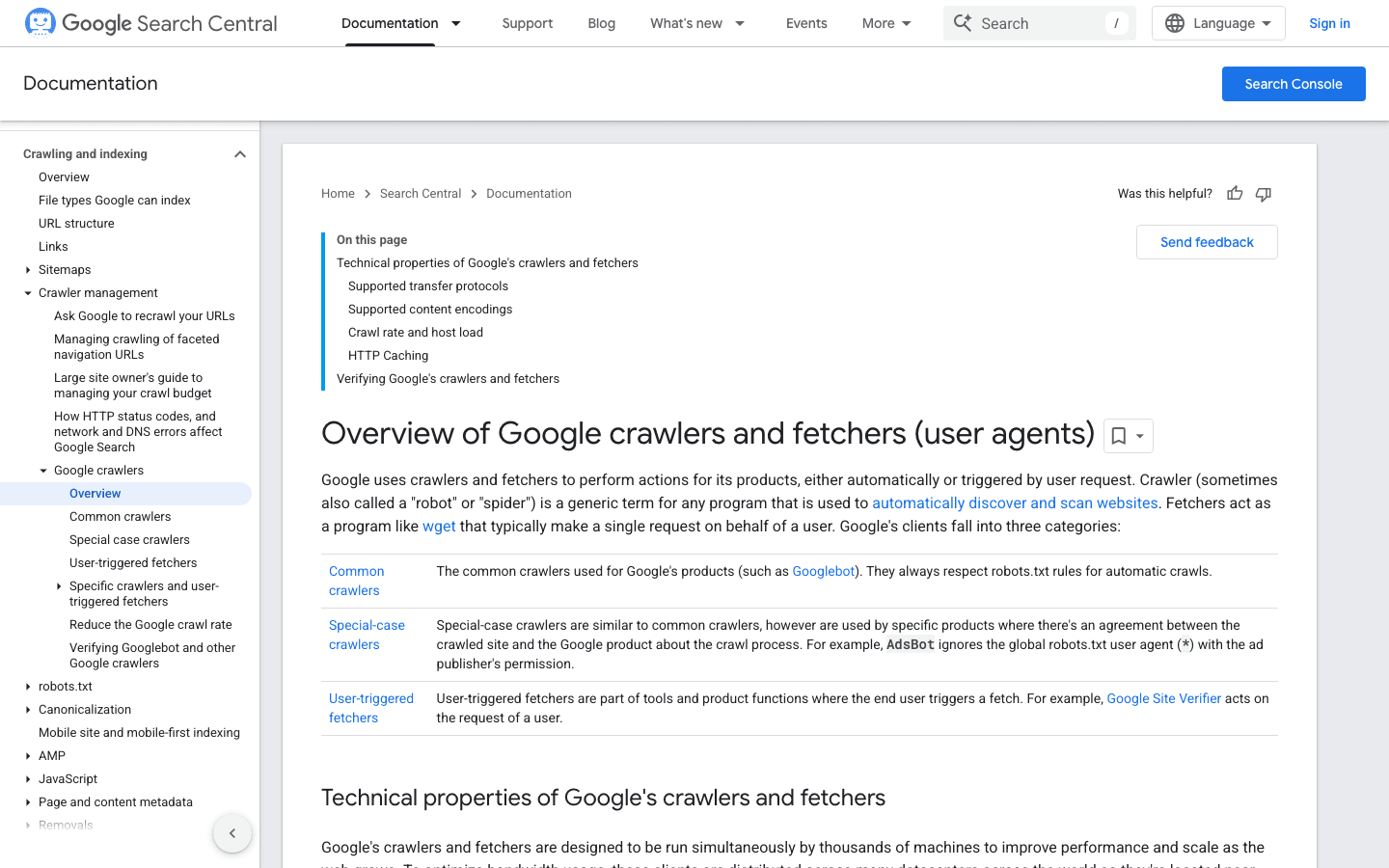
- User-Agent:
Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html) - 検証方法: Googleの逆引きDNS手法 か、公式IP一覧を使います。
- 管理のポイント: Googlebotは常に許可します。robots.txtはクロールを「ブロックする」ためではなく「導く」ために使い、必要に応じてGoogle Search Consoleでクロール速度を調整します。
3. Bingbot: Microsoftのウェブ探索クローラー
Bingbotは、BingとYahooの検索結果を支えています。多くのサイトにとって、2番目に重要なクローラーです。
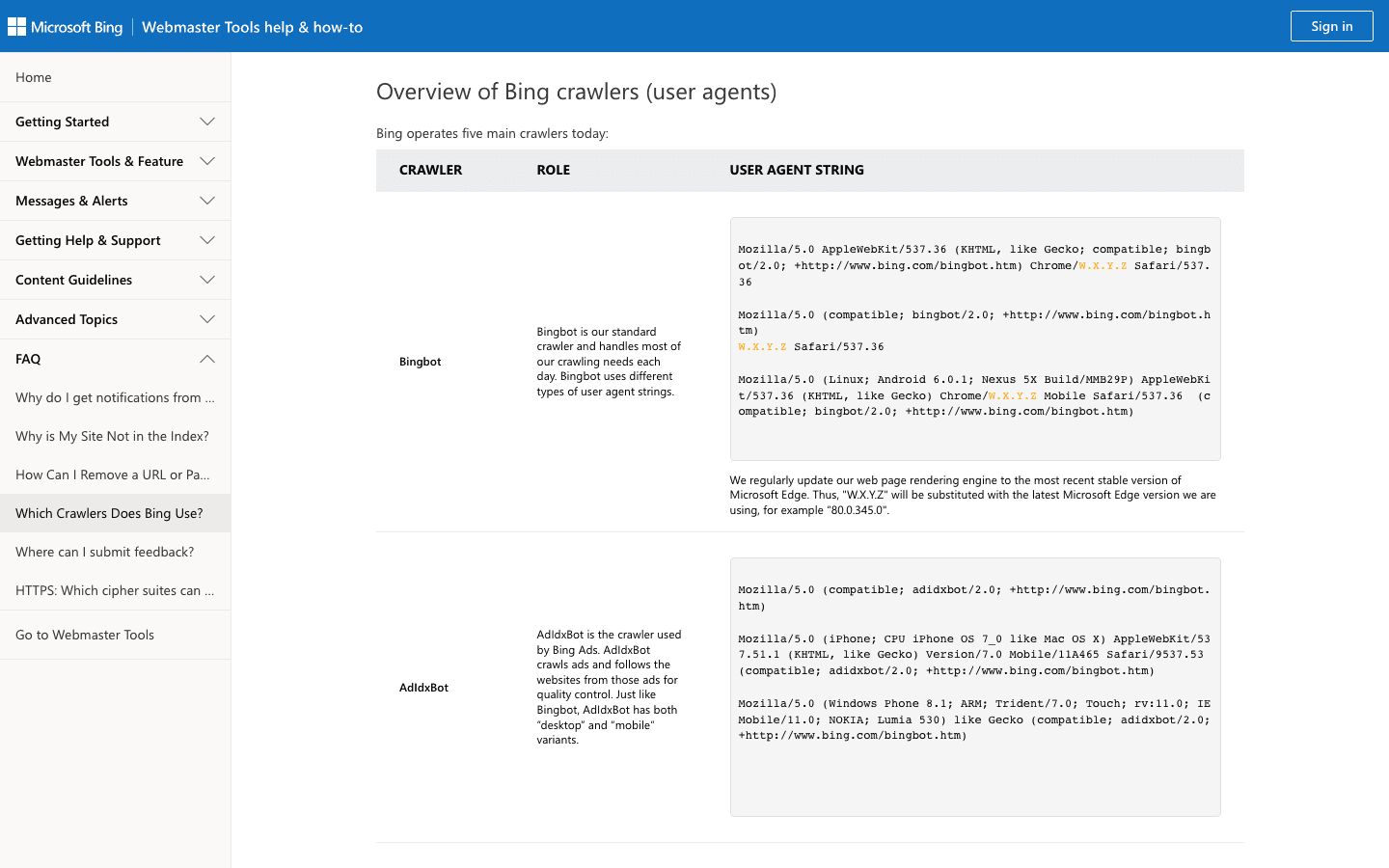
- User-Agent:
Mozilla/5.0 (compatible; bingbot/2.0; +http://www.bing.com/bingbot.htm) - 検証方法: Microsoftの検証ツール と 公式IP一覧を使います。
- 管理のポイント: Bingbotは許可し、Bing Webmaster Toolsでクロール速度を管理し、robots.txtで細かく調整します。
4. Baiduspider: 中国を代表する検索クローラー
Baiduspiderは、中国の検索トラフィックへの入り口です。
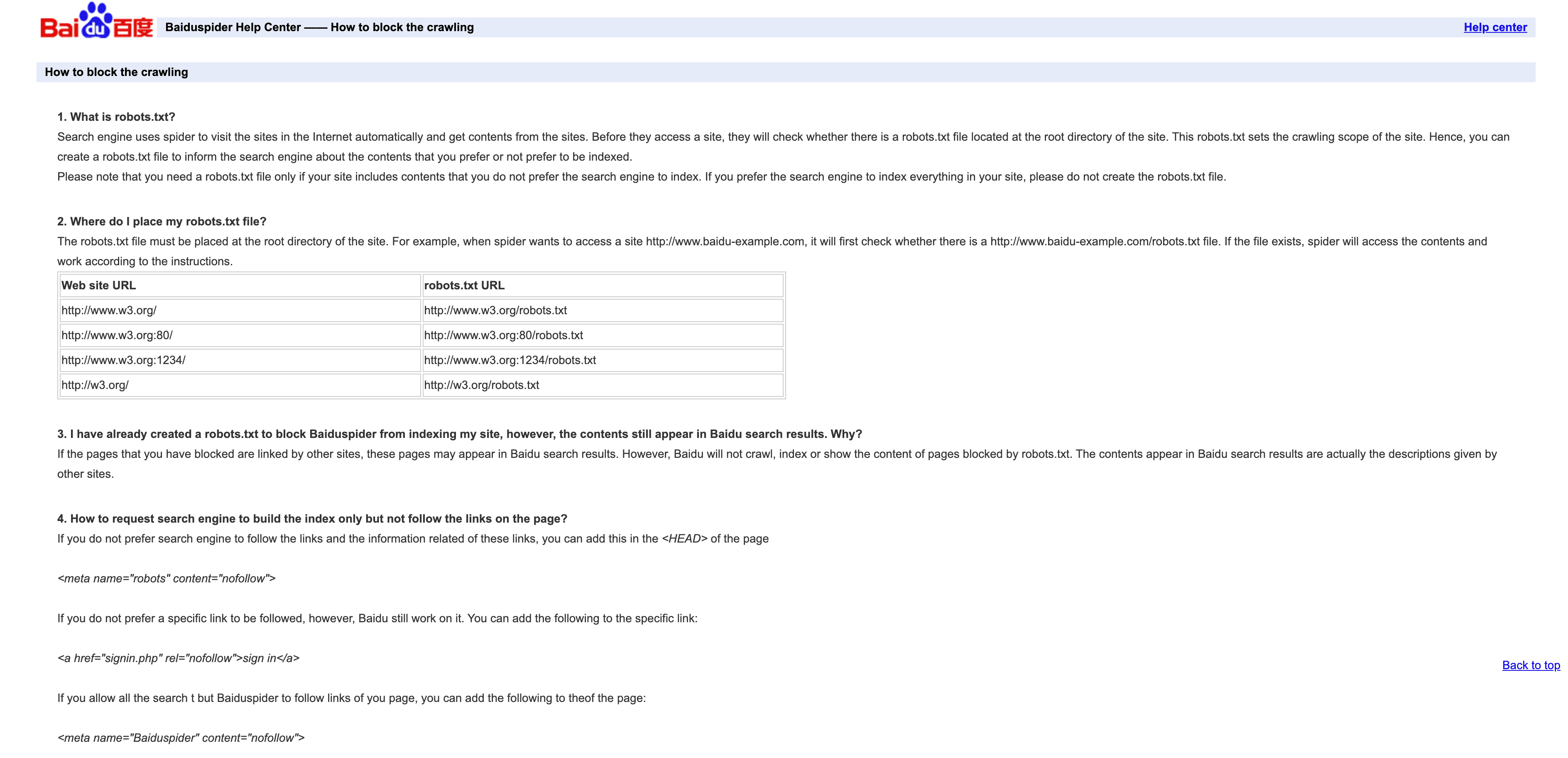
- User-Agent:
Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html) - 検証方法: 公式IP一覧はありません。逆引きDNSで
.baidu.comを確認できますが、限界がある点には注意してください。 - 管理のポイント: 中国向けトラフィックが必要なら許可します。robots.txtでルールは設定できますが、Baiduspiderはそれを無視することがある点に注意してください。中国向けSEOが不要なら、帯域幅節約のためにスロットリングやブロックを検討しましょう。
5. YandexBot: ロシアの検索エンジンクローラー
YandexBotは、ロシアおよびCIS市場で欠かせません。
- User-Agent:
Mozilla/5.0 (compatible; YandexBot/3.0; +http://yandex.com/bots) - 検証方法: 逆引きDNSは
.yandex.ru、.yandex.net、または.yandex.comで終わるはずです。 - 管理のポイント: ロシア語圏のユーザーを対象にしているなら許可します。クロール制御にはYandex Webmasterを使います。
6. DuckDuckBot: プライバシー重視の検索クローラー
DuckDuckBotは、DuckDuckGoのプライバシー重視の検索を支えています。
- User-Agent:
DuckDuckBot/1.1; (+http://duckduckgo.com/duckduckbot.html) - 検証方法: 公式IP一覧(JSON)
- 管理のポイント: プライバシー重視のユーザーに関心がない場合を除き、許可しておきましょう。クロール負荷は低く、管理も簡単です。
7. AhrefsBot: SEOと被リンク分析
AhrefsBotは主要なSEOツール系クローラーの1つで、被リンク分析に優れていますが、帯域幅を多く消費することがあります。
- User-Agent:
Mozilla/5.0 (compatible; AhrefsBot/7.0; +http://ahrefs.com/robot/) - 検証方法: 公開IP一覧はありません。UAと逆引きDNSで確認します。
- 管理のポイント: Ahrefsを使っているなら許可します。robots.txtでcrawl-delayを設定するか、ブロックします。メールでオプトアウトも可能です。
8. SemrushBot: 競合SEOのインサイト
SemrushBotも、主要なSEOクローラーの1つです。
- User-Agent:
Mozilla/5.0 (compatible; SemrushBot/1.0; +http://www.semrush.com/bot.html)(ほかにSemrushBot-BA、SemrushBot-SIなどの変種あり) - 検証方法: user-agentで確認します。公開IP一覧はありません。
- 管理のポイント: Semrushを使っているなら許可し、そうでないならrobots.txtやサーバールールでスロットリングまたはブロックします。
9. FacebookExternalHit: SNSプレビュー用ボット
FacebookExternalHitは、FacebookやInstagramのリンクプレビュー用にOpen Graphデータを取得します。
- User-Agent:
facebookexternalhit/1.1 (+http://www.facebook.com/externalhit_uatext.php) - 検証方法: user-agentで確認します。IPはFacebookのASNに属します。
- 管理のポイント: リッチなSNSプレビューのために許可します。ブロックすると、Facebook/Instagramでサムネイルや要約が表示されません。
10. Twitterbot: X(Twitter)のリンクプレビュー用クローラー
Twitterbotは、X(Twitter)向けのTwitter Cardデータを取得します。
- User-Agent:
Twitterbot/1.0 - 検証方法: user-agentで確認します。TwitterのASN(AS13414)を使います。
- 管理のポイント: Twitterプレビューのために許可します。最適な結果を得るには、Twitter Cardのメタタグを使いましょう。
比較表: クローラー一覧をひと目で見る
| クローラー | 目的 | User-Agentの例 | 検証方法 | ビジネスへの影響 | 管理のポイント |
|---|---|---|---|---|---|
| Thunderbit | AIによるログ/クローラー分析 | N/A(ボットではなくツール) | N/A | データ管理、ボット分類 | ログ抽出と許可リスト作成に活用 |
| Googlebot | Google検索のインデックス作成 | Googlebot/2.1 | DNSとIP一覧 | SEOに不可欠 | 常に許可し、Search Consoleで管理 |
| Bingbot | Bing/Yahoo検索 | bingbot/2.0 | DNSとIP一覧 | Bing/Yahoo SEOで重要 | 許可し、Bing Webmaster Toolsで管理 |
| Baiduspider | Baidu検索(中国) | Baiduspider/2.0 | 逆引きDNS、UA文字列 | 中国向けSEOの要 | 中国を対象にするなら許可、帯域幅を監視 |
| YandexBot | Yandex検索(ロシア) | YandexBot/3.0 | .yandex.ruへの逆引きDNS | ロシア/東欧向けの要 | RU/CIS向けなら許可、Yandexツールを使用 |
| DuckDuckBot | DuckDuckGo検索 | DuckDuckBot/1.1 | 公式IP一覧 | プライバシー重視のユーザー層 | 許可、影響は小さい |
| AhrefsBot | SEO/被リンク分析 | AhrefsBot/7.0 | UA文字列、逆引きDNS | SEOツール、帯域幅を多く使うことがある | robots.txtで許可/制限/ブロック |
| SemrushBot | SEO/競合分析 | SemrushBot/1.0(ほかの変種あり) | UA文字列 | SEOツール、動きが攻撃的なことがある | robots.txtで許可/制限/ブロック |
| FacebookExternalHit | SNSリンクプレビュー | facebookexternalhit/1.1 | UA文字列、Facebook ASN | SNSでのエンゲージメント | プレビュー用に許可、OGタグを使用 |
| Twitterbot | Twitterリンクプレビュー | Twitterbot/1.0 | UA文字列、Twitter ASN | Twitterでのエンゲージメント | プレビュー用に許可、Twitter Cardタグを使用 |
クローラー一覧を管理するためのベストプラクティス 2025
AIを使ったリストクロールをもっと知る Get Started Free
- 定期的に更新する: クローラーの状況はすぐに変わります。四半期ごとに見直しを行い、Thunderbitのようなツールで公式一覧をスクレイピングして比較しましょう(Human Security)。
- 信じる前に検証する: user-agentとIP/ASNの両方を必ず確認してください。なりすましに入り込まれて、分析をゆがめたりデータをスクレイピングされたりしないようにしましょう(FriendlyCaptcha)。
- 良いボットは許可する: 検索系やSNS系のクローラーが、ボット対策ルールやファイアウォールで誤って止められないようにします。
- 攻撃的なボットは制限またはブロックする: 強く当たってくるSEOツールには、robots.txt、crawl-delay、またはサーバールールを使います。
- ログ分析を自動化する: ThunderbitのようなAI搭載ツールでクローラー活動を抽出・分類・ラベル付けし、時間を節約しつつ見落としがちな傾向も拾いましょう。
- SEO、分析、セキュリティのバランスを取る: ビジネスを前進させるボットは止めず、悪いボットは野放しにしないことです。
結論: クローラー一覧を最新かつ実用的に保つ
2025年において、クローラー一覧の管理は単なるIT作業ではありません。SEO、分析、セキュリティ、コンプライアンスに関わる、事業上きわめて重要なタスクです。今やボットがウェブトラフィックの大半を占める以上、誰が、なぜ訪れていて、どう対処すべきかを把握する必要があります。リストは常に最新に保ち、可能なところは自動化し、Thunderbitのようなツールを使って一歩先を行きましょう。ボットが駆動する世界では、ウェブはますます忙しくなる一方です。だからこそ、賢く実行可能なクローラー戦略こそが、あなたにとって最良の防御であり、同時に攻めでもあります。
よくある質問
1. なぜクローラー一覧を最新に保つことが重要なのですか?
現在、ボットはウェブトラフィックの半分以上を占めており、そのうち有益なのはごく一部です。リストを最新に保てば、良いボット(SEOやSNSプレビュー用)を許可し、悪いボットはブロックまたは制限できるため、分析、帯域幅、データセキュリティを守れます。
2. クローラーが本物か偽物かはどう見分ければよいですか?
user-agentだけを信用してはいけません。必ず公式一覧や逆引きDNS検索を使って、IPアドレスやASNを確認してください。Thunderbitのようなツールなら、公開されているボットIPとuser-agentをログに照合することで、このプロセスを自動化できます。
3. 見覚えのないボットが自分のサイトをクロールしていたら、どうすればよいですか?
user-agentとIPを調査してください。許可リストに入っておらず、既知のボットとも一致しないなら、制限、チャレンジ、ブロックを検討します。AIツールを使えば、新しいクローラーが現れたときに分類・監視できます。
4. Thunderbitはクローラー管理にどう役立ちますか?
ThunderbitはAIを使って、ログからクローラー活動を抽出・構造化・分類し、許可リストの作成、なりすましの検出、ポリシー適用の自動化を簡単にします。特に、意味ベースの前処理は複雑なサイトや動的サイトで強力です。
5. GooglebotやBingbotのような大手クローラーをブロックすると、どんなリスクがありますか?
検索エンジンのクローラーをブロックすると、サイトが検索結果から外れ、オーガニックトラフィックが失われる可能性があります。ファイアウォール、robots.txt、ボット対策ルールを必ず再確認し、本当に重要なボットを誤って締め出していないか確認しましょう。
さらに詳しく:
- AIを使ってあらゆるウェブサイトをスクレイピングする方法
- WebスクレイピングPythonガイド:実例で学ぶ
- 2025年版 ウェブクローラーと良いボットの完全一覧:識別、例、ベストプラクティス
- 最も人気のあるウェブクローラーボット
AI搭載クローラー管理にThunderbitを試す Get Started Free




