
Pythonで웹 스크래핑을 해본 적이 있다면, 한 번쯤 이런 상황을 겪어봤을 거야. 처음엔 상품 가격이나 영업 리드 데이터를 잘 뽑아오다가, 갑자기 스크립트가 막히고, IP가 차단되고, 끝도 없는 CAPTCHA 화면에 갇혀버리는 그 순간 말이지. 2025년 현재, 이건 단순한 해프닝이 아니라, 영업·마케팅·오퍼레이션 등 공개 웹 데이터를 활용하는 사람들에게는 일상이 되어버린 골칫거리야.
놀랍게도, 이 IP 차단이나 CAPTCHA 같은 안티봇 시스템 때문이고, 가 이런 벽에 자주 부딪히고 있어. 이제 인터넷 트래픽의 절반 가까이가 봇에서 나오고, 각 웹사이트도 방어를 강화하는 중이야. 그래도 걱정하지 마. Python 고수든, 간편하게 데이터만 뽑고 싶은 사람이든, 이 글에서는 차단을 피하는 방법, 프록시 똑똑하게 쓰는 법, 그리고 AI 툴 로 효율적으로 스크래핑하는 팁까지, 쉽게 풀어서 알려줄게.
Python으로 차단 없이 웹 스크래핑하는 기본
먼저 기본부터 짚고 가자. 웹 스크래핑은 웹사이트에서 데이터를 자동으로 수집하는 거야. Python은 이 분야에서 가장 인기 있는 언어고, 가 Python 기반 툴을 쓰고 있어. 하지만 웹사이트 입장에선 봇의 접근을 반기지 않아. 자동 요청이 너무 많으면 서버에 부담을 주거나, 콘텐츠 도용·경쟁력 손실로 이어질 수 있거든.
그럼 사이트들은 어떤 식으로 막고 있을까? 대표적인 안티 스크래핑 방법은 이래:
- IP 차단 및 요청 제한: 같은 IP에서 너무 많이 접속하면 바로 차단.
- CAPTCHA: 사람이 맞는지 확인하는 퍼즐. 봇도, 사람도 귀찮지.
- User-Agent·헤더 필터링: 스크립트가 "python-requests/2.x"라고 밝히면 바로 봇으로 찍힘.
- JavaScript 체크·브라우저 핑거프린트: JS 실행이나 세세한 브라우저 정보까지 확인하는 사이트도 많아.
- 허니팟: 봇만 반응하는 숨겨진 링크나 필드를 심어둠.
이런 걸 모르고 Python 스크립트를 돌리면, 순식간에 "403 Forbidden" 에러를 만나게 돼.
왜 Python 스크래핑에서 IP 차단을 피해야 할까
차단은 단순한 기술 문제가 아니라, 비즈니스 리스크로 직결돼. 예를 들어, 영업팀이 신규 리드를 못 구하거나, 가격 조사 담당이 경쟁사 가격 변동을 놓치거나, 시장 조사가 불완전한 데이터에 의존하게 되면, 기회 손실이나 매출 감소로 이어질 수 있어.
구체적으로 보면:
| 활용 사례 | 구체적 예시 | 차단 시 리스크 | 안정적 스크래핑의 장점 |
|---|---|---|---|
| 영업 리드 확보 | 디렉터리나 LinkedIn에서 연락처 추출 | 리스트 불완전, 영업 기회 손실 | 항상 최신 리드로 어프로치 가능 |
| 가격 모니터링 | 경쟁사 가격 매일 체크 | 데이터 노후, 가격 변동 놓침 | 빠른 가격 전략, 실시간 인텔리전스 |
| 경쟁사 분석 | 상품 정보·리뷰 수집 | 정보 누락, 신제품 놓침 | 경쟁 상황 전체 파악, 전략 수립에 활용 |
| 시장 조사·SEO | 뉴스·포럼·검색 결과 집계 | 편향된 분석, 애널리스트 시간 낭비 | 폭넓고 시의적절한 데이터로 정밀 분석 |
에겐 웹 데이터가 "있으면 좋은" 게 아니라 "없으면 안 되는" 자산이야.
Python 스크래핑이 차단되는 주요 원인
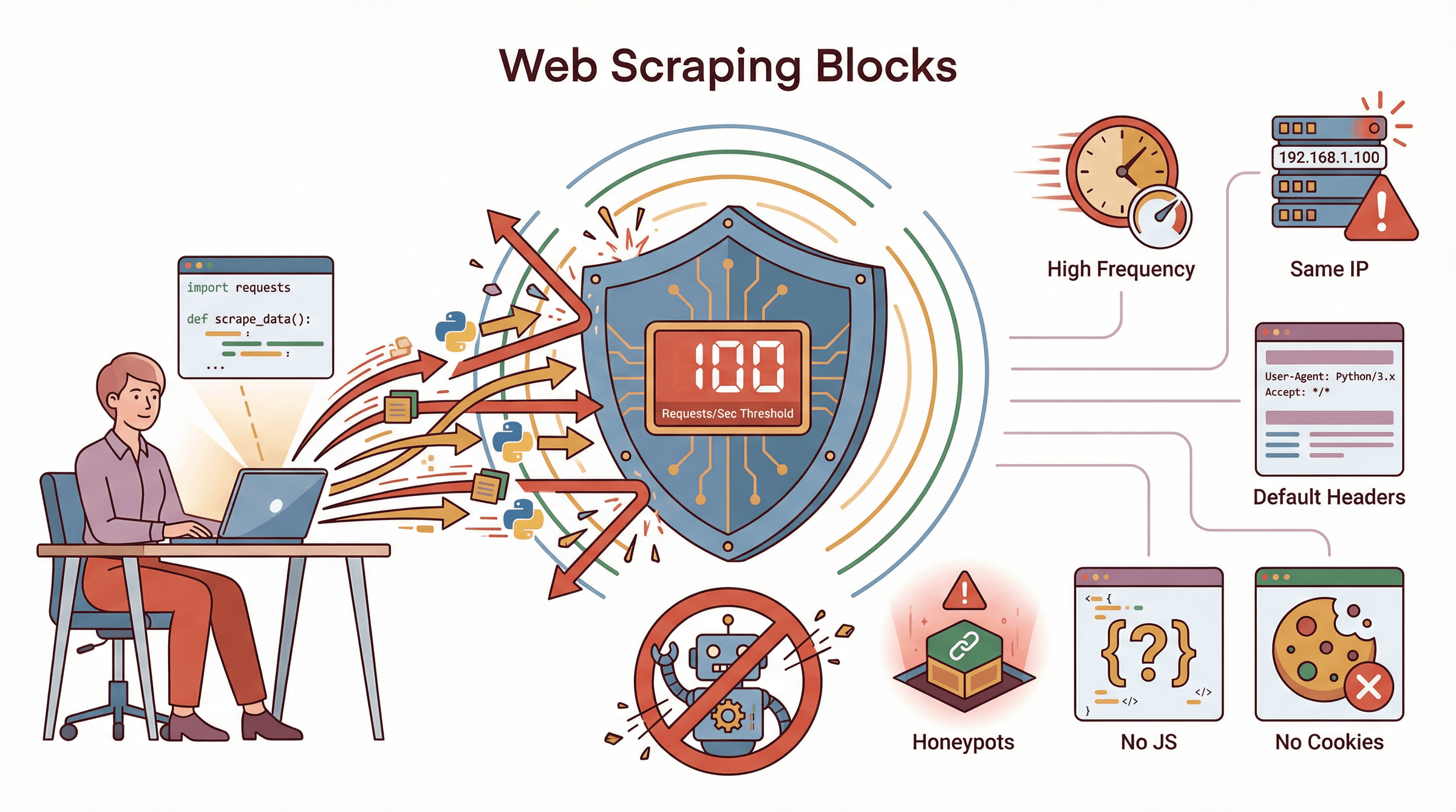 실제로 어떤 행동이 차단의 트리거가 될까? 대표적인 패턴은 이래:
실제로 어떤 행동이 차단의 트리거가 될까? 대표적인 패턴은 이래:
- 요청 빈도가 너무 높음: 사람이 1초에 100페이지 보는 일 없어. 이러면 바로 플래그.
- 같은 IP로 연속 접속: 모든 요청이 한 IP에서 오면, 특히 데이터센터 IP면 더 위험.
- 기본 헤더 사용: Python 기본 User-Agent·헤더 그대로면 바로 들킴.
- 쿠키·세션 미사용: 진짜 유저는 브라우징 중 쿠키를 받는데, 이게 없으면 수상해 보여.
- JavaScript 미지원: JS 실행 안 되면 데이터 못 받거나, 봇으로 찍힐 수도.
- robots.txt 무시: 기술적 차단은 아니지만, 눈에 띄는 원인.
- 허니팟: 숨겨진 링크·폼에 반응하면 바로 차단.
초보자들이 자주 하는 실수는, 요청을 너무 자주 보내거나, 프록시를 돌려쓰거나, User-Agent·딜레이를 랜덤화하지 않는 거야. 실제로 대학 전체 IP 대역이 NASDAQ에서 차단된 사례도 있어.
Python에서 IP 차단을 피하는 프록시 활용법
여기서 등장하는 게 프록시야. 프록시는 요청을 다른 IP로 중계해주는 역할. 웹사이트에선 접속지가 다른 곳으로 보이지.
프록시 종류
- 데이터센터 프록시: 저렴하고 빠르지만, 탐지 쉬움. 간단한 용도에 적합.
- 레지덴셜 프록시: 실제 가정용 IP. 차단 덜 되지만, 약간 비싸고 느림.
- 로테이션 프록시: 요청마다 IP 자동 변경. 대규모 스크래핑에 최적.
- 모바일 프록시: 통신사 IP. 가장 빡센 사이트용, 일반적으론 필요 없음.
비즈니스 목적이라면, 로테이션형 레지덴셜 프록시가 신뢰도·안정성 모두 최고야.
Python Requests·Selenium·Beautiful Soup에서 프록시 설정 예시
실제 스크립트 예시를 볼게:
Requests 사용 시:
1import requests
2proxy = "http://USERNAME:PASSWORD@PROXY_IP:PORT"
3proxies = {"http": proxy, "https": proxy}
4headers = {"User-Agent": "Mozilla/5.0 ..."}
5response = requests.get("https://target-website.com/data", proxies=proxies, headers=headers)
6html = response.textBeautiful Soup 사용 시:
1from bs4 import BeautifulSoup
2soup = BeautifulSoup(html, 'html.parser')
3data_items = soup.find_all('div', class_='item')Selenium 사용 시:
1from selenium import webdriver
2proxy = "PROXY_IP:PORT"
3chrome_options = webdriver.ChromeOptions()
4chrome_options.add_argument(f'--proxy-server=http://{proxy}')
5driver = webdriver.Chrome(options=chrome_options)
6driver.get("https://target-website.com")로테이션 프록시를 쓸 땐, 리스트를 돌리거나 서비스에서 자동 변경 기능을 활용하면 돼. 프록시가 실패하면 에러를 잡아서 다른 IP로 재시도하는 게 포인트야.
프록시 관리·로테이션 베스트 프랙티스
- 프록시 많이 확보: 많을수록 안전. 요청마다, 혹은 배치마다 교체.
- 프록시 상태 모니터링: 불량은 제외, 실패 땐 새 IP로 재시도.
- 한 프록시에 부하 몰지 않기: 요청 분산.
- 타겟 국가 맞춤 IP 사용: 필요하면 지역 지정.
- 프록시 종류 적절히 사용: 처음엔 데이터센터, 막히면 레지덴셜로.
- 무료 프록시는 피하기: 느리고 불안정, 이미 블랙리스트일 수도.
- 제공업체 사용 제한 준수: 쿼터 초과 주의.
프록시 관리는 거의 장인정신이 필요해. 하지만 프록시만으론 부족할 때도 많아.
프록시 외 차단 회피 테크닉 (Python 편)
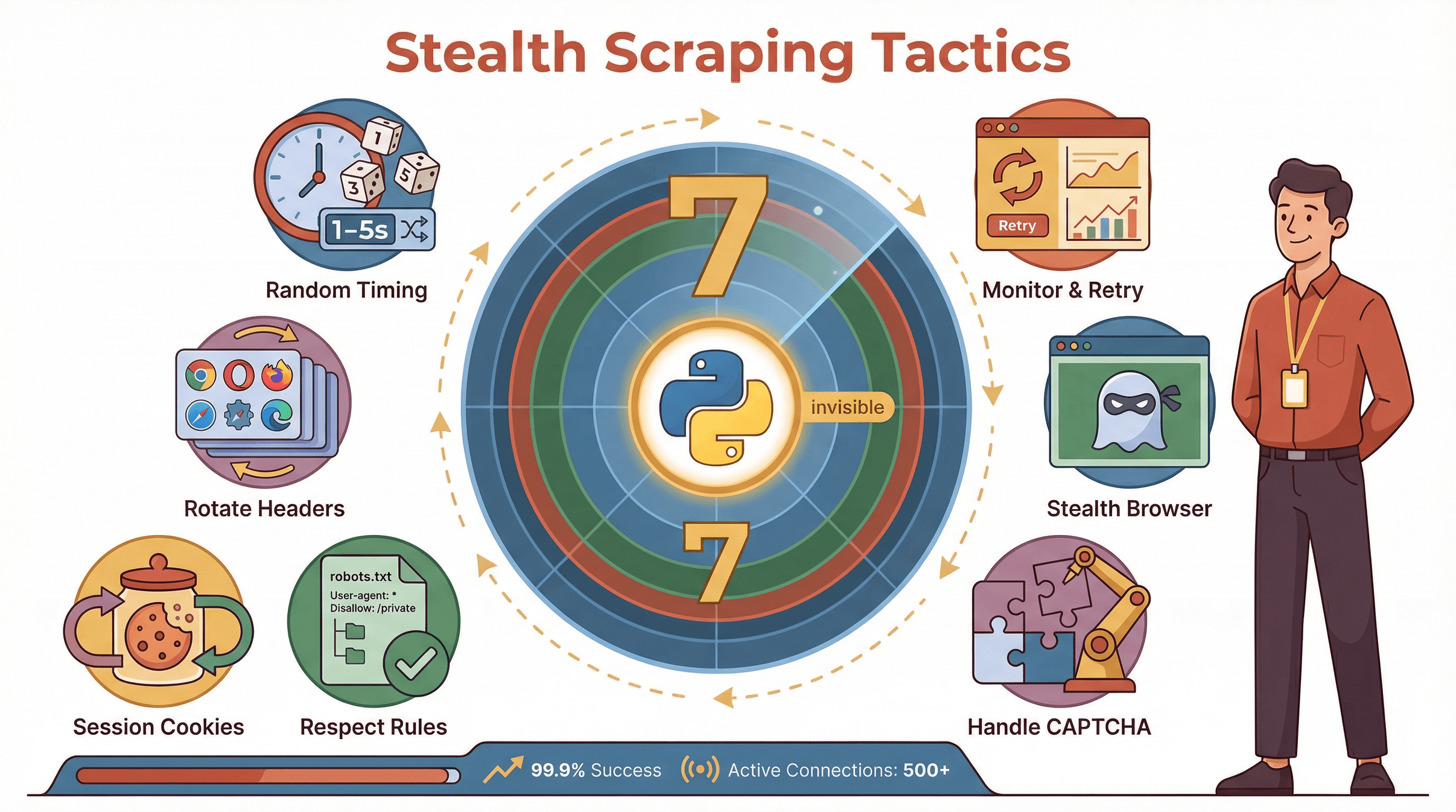 더 안전하게 스크래핑하려면, 이런 팁도 챙기자:
더 안전하게 스크래핑하려면, 이런 팁도 챙기자:
- 요청 간격 랜덤화: 일정 간격 대신 1~5초 등 랜덤 딜레이.
- User-Agent·헤더 로테이션: 실제 브라우저 정보 여러 개 준비, Accept-Language·Referer도 바꿔주기.
- 세션·쿠키 활용: 요청 간 쿠키 유지, 실제 브라우징처럼 흉내.
- robots.txt 존중, 에러 땐 속도 줄이기: 429·503 에러 나오면 요청 줄이기.
- CAPTCHA 대응: CAPTCHA 해결 서비스 쓰거나, 벽 만나면 새 프록시로 재시도.
- 스텔스 헤드리스 브라우저: undetected-chromedriver, Playwright 스텔스 플러그인 활용.
- 모니터링·자동 재시도: 로그 남기고, 실패 늘면 자동 프록시 교체.
fake-useragent, requests.Session(), 각종 스텔스 브라우저 플러그인 등 Python엔 쓸만한 라이브러리도 많아.
스크래핑을 가속하는 AI 툴 vs. 전통 Python+프록시
이제 본론으로 들어가자. 만약 프록시 관리, 헤더 조정, 차단 대응 같은 귀찮은 작업을 다 생략할 수 있다면 어떨까? 그걸 가능하게 해주는 게 바로 야.
Thunderbit는 AI가 탑재된 웹 스크래퍼 크롬 확장 프로그램으로, 어떤 웹사이트든 2번 클릭만으로 데이터 추출이 가능해. 코딩도, 프록시 설정도 필요 없어. "AI로 필드 제안"을 누르면 AI가 자동으로 추출 항목을 골라주고, "스크래핑 시작"만 누르면 데이터가 쏙쏙. 프록시·차단 회피·페이지 넘김·서브페이지 순회까지 전부 자동 처리돼.
기존 방식과 비교하면:
| 항목 | Python 스크래핑(프록시) | Thunderbit AI 웹 스크래퍼 |
|---|---|---|
| 세팅 시간 | 몇 시간(코드·프록시·파싱) | 몇 분(포인트&클릭으로 끝) |
| 기술 스킬 | 높음(코딩·HTTP·프록시 지식) | 낮음(누구나 사용 가능) |
| 차단 회피 | 수동(프록시·헤더 직접 관리) | 자동(AI+내장 프록시 관리) |
| 유지보수 | 지속적(코드·프록시 계속 업데이트) | 최소(AI가 적응, 템플릿도 자동 업데이트) |
| 페이지 넘김·서브페이지 | 직접 코드 추가 필요 | 원클릭, AI가 자동 처리 |
| 데이터 내보내기 | 수동(CSV·Excel 출력 코드 구현) | 원클릭으로 Sheets·Excel·Notion·Airtable로 |
| 확장성 | 인프라·프록시 따라 다름 | 높음(클라우드로 병렬 스크래핑 가능) |
| 비용 | 프록시 비용+개발 인건비 | 무료 플랜 있음, 이후엔 저렴한 유료 플랜 |
| 신뢰성 | 세팅에 따라 다름 | 높음(비즈니스용 최적화) |
Thunderbit는 특히 비개발자 팀이나 "빨리 데이터만 뽑고 싶다"는 사람들에게 딱이야.
Thunderbit로 차단 없이 스크래핑하는 방법
Thunderbit로 Python 스크립트가 막히는 사이트에서도 데이터를 뽑는 흐름은 이래:
- Thunderbit 크롬 확장 설치:
- 타겟 사이트 접속: 필요하면 로그인도 OK. Thunderbit는 브라우저 세션을 그대로 활용해.
- "AI로 필드 제안" 클릭: Thunderbit가 페이지를 분석해서 "이름", "가격", "이메일" 등 추출 항목을 자동 추천.
- "스크래핑 시작" 클릭: 데이터가 구조화된 테이블로 정리돼.
- 페이지 넘김 지원: "모든 페이지 스크래핑"을 켜면 Thunderbit가 자동으로 페이지를 돌며 데이터 수집.
- 서브페이지도 추출: "서브페이지 스크래핑"으로 상세 페이지까지 순회, 데이터 확장.
- 내보내기: 원클릭으로 Google Sheets, Excel, Notion, Airtable로 내보내기.
Thunderbit는 IP 로테이션, 요청 간격 조정, 간단한 CAPTCHA 자동 해결까지 백그라운드에서 처리해주니, 비즈니스 유저도 부담 없이 쓸 수 있어.
Thunderbit의 페이지 넘김·서브페이지 지원
Thunderbit는 1페이지뿐 아니라,
- 사람처럼 스크롤&클릭: 무한 스크롤이나 "다음" 버튼도 자연스럽게 조작.
- 세션 유지: 로그인 상태도 페이지 이동하며 계속 유지.
- 부하 분산: 클라우드 모드에선 여러 IP로 병렬 스크래핑.
- 동적 콘텐츠 대응: JavaScript 실행으로 나중에 뜨는 데이터도 추출.
- 서브페이지 순회: 각 아이템의 상세 페이지까지 들어가서 추가 정보도 메인 테이블에 합침.
웹사이트 입장에선, 여러 명의 진짜 사용자가 자연스럽게 둘러보는 것처럼 보여.
Python+프록시와 Thunderbit의 비즈니스 활용 비교
어떤 게 내 상황에 맞을지 간단 비교해볼게:
| 비교 항목 | Python+프록시 | Thunderbit |
|---|---|---|
| 속도 | 세팅에 시간 걸림 | 바로 결과 얻음 |
| 유지보수 | 높음(코드·프록시 관리) | 낮음(AI가 적응, 템플릿 자동 업데이트) |
| 필요 스킬 | 개발자용 | 누구나 사용 가능 |
| 차단 리스크 | 중(대응 안 하면 위험) | 낮음(AI+자동 프록시 관리) |
| 비용 | 프록시 비용+개발 인건비 | 무료 플랜 있음, 이후 월 15달러~ |
| 최적 용도 | 커스텀·복잡한 스크래핑 | 영업·마케팅·리서치팀용 |
세밀한 커스터마이즈나 코딩이 취미인 개발자라면 Python+프록시도 좋지만, 대부분의 비즈니스 유저에겐 Thunderbit가 훨씬 효율적이야.
정리: 똑똑하게 스크래핑하자
내 경험에서 얻은 교훈을 정리하면:
- Python으로 IP 차단 피하려면 프록시 필수지만, 관리가 꽤 번거로워.
- 요청 간격·헤더 랜덤화, 세션 유지 등 꼼꼼한 세팅만으로도 차단 확률은 크게 줄어.
- Thunderbit 같은 AI 툴을 쓰면, 프록시·차단 대응·페이지 넘김·서브페이지·내보내기까지 자동화돼서 데이터 수집에만 집중할 수 있어.
- 내 팀에 맞는 툴을 고르자: 속도·신뢰성 중시라면 Thunderbit, 커스텀 중시라면 Python+프록시.
스크래핑의 새로운 시대를 경험하고 싶다면, 해서 다음 프로젝트에 꼭 써봐. 더 자세한 노하우는 도 참고해봐.
쾌적한 스크래핑 라이프! IP 차단 걱정 없이, 항상 신선한 데이터를 손에 넣자.
자주 묻는 질문
1. Python 웹 스크래퍼가 차단되는 가장 큰 이유는?
가장 흔한 건, 한 IP에서 대량 요청을 보내거나, 기본 헤더를 써서 "나 봇이야"라고 티내는 거야. 이런 패턴은 금방 감지돼서 차단 대상이 돼.
2. 프록시는 Python 스크래핑에서 IP 차단 회피에 어떻게 도움돼?
프록시를 쓰면, 여러 IP에서 요청이 들어오는 것처럼 보이게 할 수 있어. 특히 로테이션 프록시는 대규모 데이터 수집에 효과적이야.
3. Python에서 프록시 관리할 때 베스트 프랙티스는?
프록시를 많이 준비하고, 자주 교체하며, 실패 시 자동 재시도. 무료 프록시는 피하고, 타겟 국가에 맞는 IP를 골라. 요청 간격·헤더도 꼭 랜덤화해야 해.
4. Thunderbit는 왜 프록시 수동 설정 없이도 차단 안 당해?
Thunderbit는 프록시 로테이션, 요청 간격 조정, 안티 차단 기술을 자동으로 돌려. AI 에이전트가 진짜 유저처럼 행동하고, 페이지 넘김·서브페이지도 자동 처리, 원클릭으로 데이터 내보내기까지 가능해.
5. 비즈니스용 스크래핑엔 Python과 Thunderbit 중 뭐가 더 좋아?
복잡한 커스텀 작업이 필요한 개발자라면 Python+프록시가 유연하지만, 영업·마케팅·리서치 등 빠르고 확실한 데이터가 필요한 팀엔 Thunderbit가 훨씬 추천할 만해.
똑똑하게 스크래핑하고 싶다면, , 차단 스트레스에서 벗어나자.
더 알고 싶다면