

ウェブには価値あるデータがあふれています。営業、EC、マーケットリサーチのどれでも、ウェブスクレイピングはリード獲得、価格監視、競合分析に役立つ強力な手段です。ただし、ここでひとつ問題があります。スクレイピングを活用する企業が増えるほど、Webサイト側の対策もどんどん強化されているのです。その変化ははっきりしています。2024年のppc.landの分析では、上位1,000サイトのうち3分の1超がOpenAIのクローラーだけでもすでにブロックしていることが分かりました。さらに、IPブロック、CAPTCHA、ブラウザフィンガープリンティングといった対策も、今では例外ではなく標準になっています。
Pythonスクリプトが20分は順調に動いていたのに、突然403エラーの山にぶつかった。そんな経験があるなら、そのストレスはよく分かるはずです。
私はSaaSと自動化の分野で長く仕事をしてきましたが、スクレイピング案件が一瞬で「お、簡単だな」から「なんでどこでもブロックされるんだ?」に変わる場面を何度も見てきました。そこで本記事では、Pythonでブロックされずにウェブスクレイピングする方法を実践的に解説し、使えるテクニックやコード例を紹介します。さらに、ThunderbitのようなAI搭載の代替手段を検討すべきタイミングもお伝えします。Pythonに慣れた方でも、これから始める方でも、安定してブロックを回避しながらデータを抽出するための実用的なツールセットが手に入ります。
Pythonでブロックされずにウェブスクレイピングするとは?
本質的には、ブロックされずにウェブスクレイピングするとは、サイト側の自動化対策を作動させない形でデータを抽出することです。Pythonの世界では、単にrequests.get()をループで回すだけでは足りません。人間の利用者に紛れ込み、実際のブラウジングに近い振る舞いをし、検知システムより一歩先を行くことが重要です。
なぜPythonなのか。Pythonはウェブスクレイピングで最も人気のある言語です。理由は、シンプルな構文、巨大なエコシステム(requests、BeautifulSoup、Scrapy、Seleniumなど)、そして短いスクリプトから分散クローラーまで対応できる柔軟性にあります。ただし、その人気には代償もあります。多くの自動化対策は、Pythonベースのスクレイピングパターンを見抜くように調整されているのです。
つまり、安定してスクレイピングしたいなら、基本だけでは不十分です。サイトがどのようにボットを検知しているのかを理解し、その裏をかく必要があります。ただし、倫理面や法的な線は決して越えないようにしましょう。
Pythonのウェブスクレイピングでブロック回避が重要な理由
ブロックされるのは単なる技術的なつまずきではありません。業務フロー全体を止めてしまうこともあります。整理してみましょう。
| ユースケース | ブロックされた場合の影響 |
|---|---|
| リード獲得 | 見込み顧客リストが不完全・古いままになり、売上機会を逃す |
| 価格監視 | 競合の価格変更を見逃し、価格戦略の判断を誤る |
| コンテンツ集約 | ニュース、レビュー、調査データに抜けが出る |
| 市場インテリジェンス | 競合や業界の追跡に死角ができる |
| 不動産リスティング | 物件データが不正確または古くなり、機会損失につながる |
スクレイパーがブロックされると、失うのはデータだけではありません。リソースを浪費し、コンプライアンス上の問題を抱え、しかも不完全な情報に基づいて誤ったビジネス判断を下すリスクもあります。現在では企業の79%がリード獲得にウェブスクレイピングを活用していると言われており、信頼性は何より重要です。
サイトがPythonのウェブスクレイパーを検知・ブロックする仕組み
Webサイト側は、ボットを見抜く技術をかなり洗練させています。代表的な対策は次のとおりです(Medium、Bright Data)。
- IPアドレスのブラックリスト化: 1つのIPから大量のリクエストが来るとブロックされます。
- User-Agentとヘッダーのチェック: ヘッダーが欠けていたり、汎用的すぎたりすると目立ちます(Pythonのデフォルト
python-requests/2.25.1など)。 - レート制限: 短時間にリクエストを送りすぎると、速度制限やBANが発生します。
- CAPTCHA: ボットには簡単には解けない「人間であることの証明」です。
- 行動分析: 同じボタンを同じ間隔で押すような機械的な動きを監視します。
- ハニーポット: ボットだけが反応する隠しリンクや隠しフィールドです。
- ブラウザフィンガープリンティング: ブラウザや端末の情報を集めて、自動化ツールかどうかを判定します。
- Cookieとセッションの追跡: Cookieやセッションを正しく扱わないボットはフラグが立ちます。
空港のセキュリティチェックのようなものだと考えると分かりやすいでしょう。周りの人と同じように見え、同じように振る舞い、同じように動けば、すんなり通れます。トレンチコートにサングラスで現れたら、追加でいろいろ聞かれても不思議ではありません。
ブロックされずにウェブスクレイピングするための重要なPythonテクニック
ここからが本題です。Pythonでスクレイピングする際に、実際どうやってブロックを避けるのか。すべてのスクレイパーが知っておくべき基本戦略を紹介します。

プロキシとIPアドレスのローテーション
重要な理由: すべてのリクエストが同じIPから来ていると、IPブロックの格好の標的になります。プロキシをローテーションすれば、複数のIPにリクエストを分散でき、ブロックされにくくなります。
Pythonでの実装例:
import requests
proxies = [
"<http://proxy1.example.com:8000>",
"<http://proxy2.example.com:8000>",
# ...more proxies
]
for i, url in enumerate(urls):
proxy = {"http": proxies[i % len(proxies)]}
response = requests.get(url, proxies=proxy)
# process response
信頼性をさらに高めたいなら、有料のプロキシサービス(住宅用プロキシや回転プロキシなど)を使う方法もあります(ScrapingBee)。
User-Agentとカスタムヘッダーの設定
重要な理由: Pythonのデフォルトヘッダーは、いかにも「ボットです」と言っているようなものです。User-Agentやその他のヘッダーを設定して、実際のブラウザに近づけましょう。
サンプルコード:
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36",
"Accept-Language": "en-US,en;q=0.9",
"Accept-Encoding": "gzip, deflate, br",
"Connection": "keep-alive"
}
response = requests.get(url, headers=headers)
さらに目立ちにくくするなら、User-Agentもローテーションしましょう(ZenRows)。
リクエストのタイミングとパターンをランダム化する
重要な理由: ボットは速くて予測しやすく、人間は遅くてばらつきがあります。待機時間を入れ、アクセスの仕方を少しずつ変えましょう。
Pythonのヒント:
import time, random
for url in urls:
response = requests.get(url)
time.sleep(random.uniform(2, 7)) # 2~7秒待機
Seleniumを使う場合は、クリックの経路やスクロールのパターンもランダム化できます。
Cookieとセッションの管理
重要な理由: 多くのサイトでは、コンテンツにアクセスするためにCookieやセッショントークンが必要です。これを無視するボットはブロックされやすくなります。
Pythonでの管理方法:
import requests
session = requests.Session()
response = session.get(url)
# session will handle cookies automatically
より複雑な流れでは、Seleniumを使ってCookieを取得し、再利用します。
ヘッドレスブラウザで人間らしい挙動を再現する
重要な理由: 一部のサイトは、JavaScriptの動きやマウス移動、スクロールなどを実ユーザーのシグナルとして見ています。SeleniumやPlaywrightのようなヘッドレスブラウザなら、こうした動作を模倣できます。
Seleniumの例:
from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains
import random, time
driver = webdriver.Chrome()
driver.get(url)
actions = ActionChains(driver)
actions.move_by_offset(random.randint(0, 100), random.randint(0, 100)).perform()
time.sleep(random.uniform(2, 5))
これにより、行動分析や動的コンテンツへの対応がしやすくなります(ScrapingBee)。
さらに進んだ対策: PythonでCAPTCHAとハニーポットを回避する
CAPTCHAは、ボットをその場で止めるために設計されています。簡単なCAPTCHAならPythonライブラリで解ける場合もありますが、本格的なスクレイパーの多くは、2CaptchaやAnti-Captchaのような外部サービスに費用を払って解かせています(Medium)。
統合のサンプル:
# Pseudocode for using 2Captcha API
import requests
captcha_id = requests.post("<https://2captcha.com/in.php>", data={...}).text
# Wait for solution, then submit with your request
ハニーポットは、ボットだけが反応する隠しフィールドや隠しリンクです。実際のブラウザで見えないものはクリックしたり送信したりしないようにしましょう(ZenRows)。
Pythonライブラリで堅牢なリクエストヘッダーを設計する
User-Agent以外にも、Referer、Accept、Originなどのヘッダーをローテーション・ランダム化すると、さらに自然に見せられます。
Scrapyの場合:
class MySpider(scrapy.Spider):
custom_settings = {
'DEFAULT_REQUEST_HEADERS': {
'User-Agent': '...',
'Accept-Language': 'en-US,en;q=0.9',
# More headers
}
}
Seleniumの場合: ブラウザのプロファイルや拡張機能でヘッダーを設定するか、JavaScriptで注入します。
ヘッダー一覧は定期的に見直しましょう。ブラウザのDevToolsで実際のリクエストを確認すると参考になります。
それでもPythonスクレイピングが通用しないとき: 自動化対策の進化
現実として、スクレイピングが普及するほど、ボット対策も強化されます。大手サイトは今や、あからさまなボットだけでなく、高度なヘッドレスブラウザや回転プロキシまでブロックしています。AIによる検知、動的なリクエスト閾値、ブラウザフィンガープリンティングによって、上級者のPythonスクリプトでさえ検知を逃れ続けるのがますます難しくなっています(Medium)。
どれだけコードを工夫しても、壁にぶつかることがあります。そんなときは、別のアプローチを考えるタイミングです。
Thunderbit: Pythonスクレイピングの代わりになるAIウェブスクレイパー
Pythonで限界が見えてきたら、Thunderbitの出番です。Thunderbitは、開発者だけでなくビジネスユーザー向けに作られた、ノーコードのAI搭載ウェブスクレイパーです。プロキシ、ヘッダー、CAPTCHAと格闘する代わりに、ThunderbitのAIエージェントがWebサイトを読み取り、抽出すべき項目を提案し、サブページの巡回からデータのエクスポートまで一通り処理してくれます。
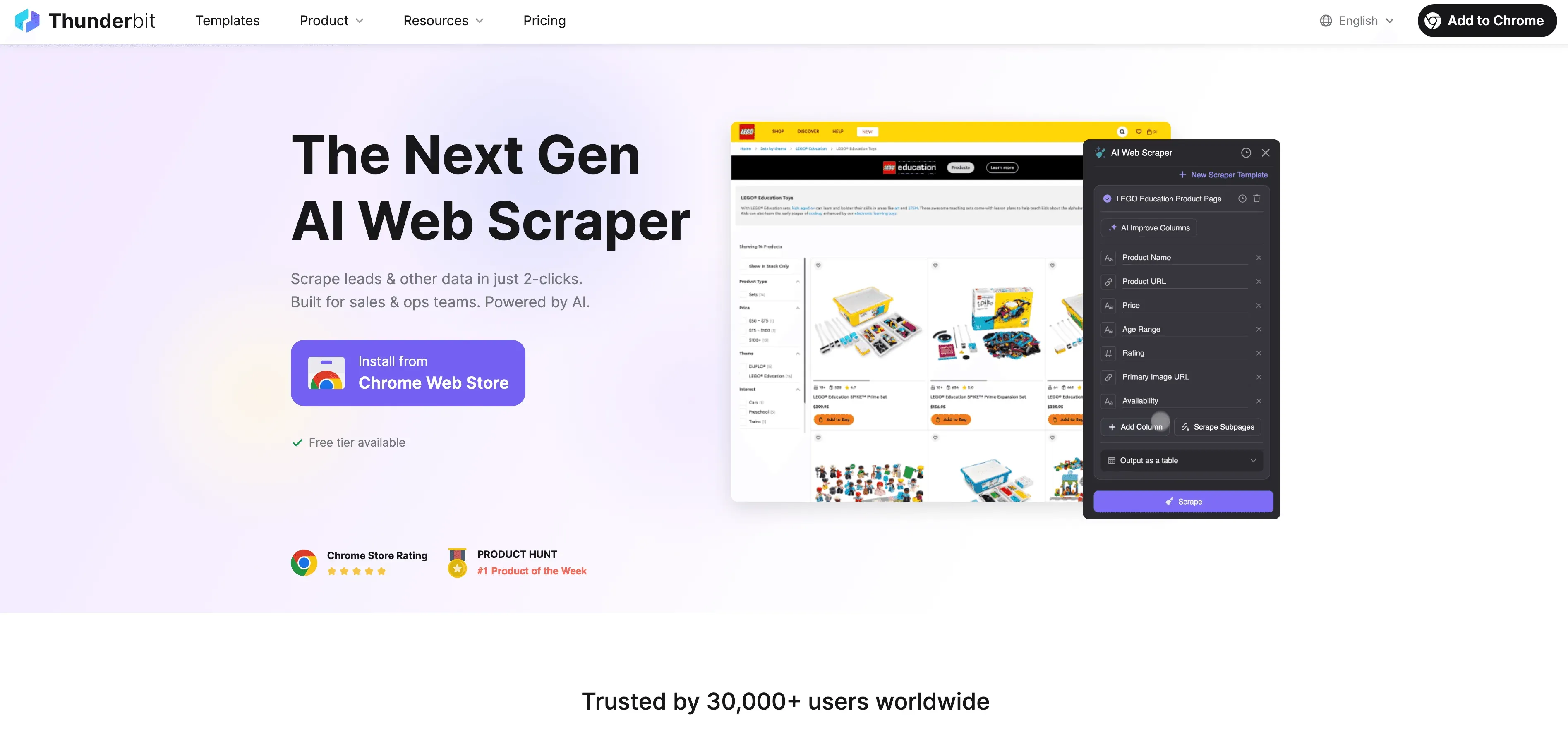
Thunderbitの違いは何か?
- AIによる項目提案: 「AIで列を提案」をクリックすると、Thunderbitがページを解析し、列を提案し、抽出手順まで生成します。
- サブページのスクレイピング: 商品詳細やLinkedInプロフィールのような各サブページに自動で移動し、表をそのまま拡張できます。
- クラウドまたはブラウザでのスクレイピング: 最速の方法を選べます。公開サイトならクラウド、ログインが必要なページならブラウザです。
- スケジュールスクレイピング: 一度設定すればあとはおまかせ。Thunderbitが定期実行し、データを常に最新に保ちます。
- 即利用できるテンプレート: Amazon、Zillow、Shopifyなど人気サイト向けに、ワンクリックで使えるテンプレートがあります。設定は不要です。
- 無料のデータエクスポート: Excel、Google Sheets、Airtable、Notionへ追加料金なしで出力できます。
Thunderbitは世界中で10万人以上のユーザーに信頼されており、コードを1行も書く必要はありません。
AIを使ってあらゆるWebサイトからデータを抽出 Get Started Free
Thunderbitがブロック回避とデータ抽出の自動化にどう役立つか
ThunderbitのAIは、単に人間らしく振る舞うだけではありません。各サイトにリアルタイムで適応するため、ブロックされるリスクを抑えられます。仕組みは次のとおりです。
- レイアウト変更にAIが追従: サイトのデザインが更新されても、毎週セレクターを調整し直す手間が減ります。
- サブページとページ送りの処理: Thunderbitがリンクやページネーションを自動でたどるので、人がクリックで進むのと同じように扱えます。
- クラウドでのバッチスクレイピング: ノートPCではなくThunderbitのクラウドでジョブを実行できます。バッチサイズはプランごとに設定されます(現在の上限は料金ページをご覧ください)。
- 保守するコードが少ない: サイト変更のたびに壊れたセレクターを夜中に追いかける必要はありません。AIがページを読み直してくれます。
さらに詳しく知りたい方は、AIを使ってあらゆるWebサイトをスクレイピングする方法をご覧ください。
PythonスクレイピングとThunderbitの比較: どちらを選ぶべき?
並べて比べてみましょう。
| 機能 | Pythonスクレイピング | Thunderbit |
|---|---|---|
| 設定時間 | 中〜高(スクリプト、プロキシなどが必要) | 低(2クリック、あとはAIが対応) |
| 技術スキル | コーディングが必要 | コーディング不要 |
| 信頼性 | ばらつきがある(壊れやすい) | 高い(AIが変更に適応) |
| ブロックのリスク | 中〜高 | 低い(AIがユーザーに近い動作をし、適応する) |
| 拡張性 | 独自コードやクラウド設定が必要 | クラウド/バッチスクレイピングを標準搭載 |
| 保守 | 頻繁に必要(サイト変更、ブロック対応) | 最小限(AIが自動調整) |
| エクスポート方法 | 手動(CSV、DB) | Sheets、Notion、Airtable、CSVへ直接出力 |
| コスト | 無料(ただし時間コストが大きい) | 無料枠あり、規模に応じて有料プラン |
Pythonを使うべき場面:
- 完全な制御や独自ロジック、ほかのPythonワークフローとの統合が必要なとき。
- 自動化対策がほとんどないサイトをスクレイピングするとき。
Thunderbitを使うべき場面:
- 速さ、信頼性、ゼロ設定を重視するとき。
- 複雑なサイトや頻繁に変わるサイトをスクレイピングするとき。
- プロキシ、CAPTCHA、コードの管理をしたくないとき。
ステップごとのガイド: Pythonでブロックされずにウェブスクレイピングを設定する
ここでは、サンプルサイトの商品データをスクレイピングしながら、ブロック回避のベストプラクティスを適用する実践例を見ていきます。
1. 必要なライブラリをインストールする
pip install requests beautifulsoup4 fake-useragent
2. スクリプトを準備する
import requests
from bs4 import BeautifulSoup
from fake_useragent import UserAgent
import time, random
ua = UserAgent()
urls = ["<https://example.com/product/1>", "<https://example.com/product/2>"] # Replace with your URLs
for url in urls:
headers = {
"User-Agent": ua.random,
"Accept-Language": "en-US,en;q=0.9"
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
soup = BeautifulSoup(response.text, "html.parser")
# Extract data here
print(soup.title.text)
else:
print(f"Blocked or error on {url}: {response.status_code}")
time.sleep(random.uniform(2, 6)) # Random delay
3. プロキシのローテーションを追加する(任意)
proxies = [
"<http://proxy1.example.com:8000>",
"<http://proxy2.example.com:8000>",
# More proxies
]
for i, url in enumerate(urls):
proxy = {"http": proxies[i % len(proxies)]}
headers = {"User-Agent": ua.random}
response = requests.get(url, headers=headers, proxies=proxy)
# ...rest of code
4. Cookieとセッションを処理する
session = requests.Session()
for url in urls:
response = session.get(url, headers=headers)
# ...rest of code
5. トラブルシューティングのヒント
- 403や429エラーが多い場合は、リクエストの間隔を空けるか、新しいプロキシを試してください。
- CAPTCHAに遭遇したら、SeleniumやCAPTCHA解決サービスの利用を検討しましょう。
- サイトの
robots.txtと利用規約は必ず確認してください。
まとめと重要ポイント
Pythonでのウェブスクレイピングは非常に強力ですが、自動化対策が進化するにつれて、ブロックされるリスクは常につきまといます。ブロックを避ける最善策は、技術的なベストプラクティス(プロキシのローテーション、適切なヘッダー、ランダムな遅延、セッション管理、ヘッドレスブラウザ)と、サイトのルールや倫理への配慮を組み合わせることです。
とはいえ、どんなに優れたPythonの工夫でも足りないことがあります。そんなときに登場するのが、ThunderbitのようなAIツールです。ノーコードで、レイアウト変更やページネーションにも対応しやすく、Rigidなスクリプトを苦しめる要因を吸収してくれます。Seleniumのジョブを夜通し見張り続けるより、ビジネスに集中したい人にぴったりです。
スクレイピングの手軽さを体験してみませんか?ThunderbitのChrome拡張機能をダウンロードして、ぜひ試してみてください。あるいは、さらに多くのスクレイピングのコツやチュートリアルを知りたい方は、ブログをご覧ください。
FAQ
1. なぜWebサイトはPythonのウェブスクレイパーをブロックするのですか?
Webサイトは、データを保護し、サーバーの過負荷を防ぎ、自動化ボットによる不正利用を止めるためにスクレイパーをブロックします。Pythonスクリプトは、デフォルトのヘッダーのまま、Cookieを適切に扱わず、短時間に大量のリクエストを送ると、すぐに見分けられてしまいます。
2. Pythonでスクレイピングするとき、ブロックされないための最も効果的な方法は何ですか?
ローテーションプロキシを使い、現実的なUser-Agentとヘッダーを設定し、リクエストのタイミングをランダム化し、Cookie/セッションを管理し、SeleniumやPlaywrightのようなツールで人間らしい挙動を再現します。
3. ThunderbitはPythonスクリプトと比べて、どのようにブロック回避に役立ちますか?
ThunderbitはAIを使ってサイトのレイアウトに適応し、人間のブラウジングに近い動きを再現し、サブページやページネーションを自動で処理します。コードやプロキシなしで、自然に見せながらリアルタイムで方法を更新することで、ブロックのリスクを下げます。
4. PythonスクレイピングとThunderbitのようなAIツールは、どう使い分ければいいですか?
カスタムロジックが必要なとき、ほかのPythonコードと統合したいとき、またはシンプルなサイトをスクレイピングするときはPythonを使いましょう。速く、信頼性が高く、拡張しやすいスクレイピングを求めるならThunderbitが向いています。特に、サイトが複雑、頻繁に変わる、あるいはスクリプトを強くブロックしてくる場合に有効です。
5. ウェブスクレイピングは合法ですか?
公開されているデータのスクレイピングは一般に合法ですが、各サイトの利用規約、プライバシーポリシー、関連法規を尊重しなければなりません。機微なデータや非公開データは絶対にスクレイピングせず、常に倫理的かつ責任ある方法で行ってください。
もっと賢く、もっと楽にスクレイピングしたいですか?Thunderbitを試して、ブロックとはもうお別れしましょう。
さらに詳しく:
- PythonでGoogleニュースをスクレイピングする方法: ステップごとのガイド
- Pythonを使ってBest Buyの価格追跡ツールを作成する
- ブロックされずにウェブスクレイピングする14の方法
- ウェブスクレイピングでブロックされないための10のベストヒント
AIウェブスクレイパーを試す Get Started Free




