

少し前のことを思い出してください。私は机に座り、コーヒーを片手に、日曜の夜の冷蔵庫よりも空っぽなスプレッドシートを見つめていました。営業チームは競合の価格データを欲しがり、マーケティングは新しいリードを求め、運用チームは十数サイトの製品一覧を「昨日までに」必要としている。データがどこかにあるのはわかっている。でも、それをどうやって手に入れるか。そこが本当の難所です。サイトから毎回コピペを繰り返すデジタル版モグラたたきに疲れたことがあるなら、あなただけではありません。
それから時は進み、今では状況が大きく変わりました。ウェブスクレイピングは、いわばオタク向けの副業プロジェクトから、事業戦略の中核へと進化しました。JavaScript と Node.js は、単発スクリプトから本格的なデータパイプラインまでを支える存在として、いまや最前線にあります。ただし、ツールが強力になった一方で、学習曲線は依然としてフリップフロップでエベレストを登るように感じることもあるでしょう。だからこそ、このガイドは、ビジネスユーザーの方にも、データ好きの方にも、単純に手作業の入力にうんざりしている方にも役立つ内容にしています。エコシステム、必須ライブラリ、つまずきやすいポイント、そして時には AI に重い作業を任せるのが最善である理由まで、わかりやすく整理していきます。
JavaScript と Node.js を使ったウェブスクレイピングがビジネスで重要な理由
まずは「なぜやるのか」から始めましょう。2026年において、Web データは「あれば便利」ではなく、事業の生命線です。最近の調査によれば、73% の企業が公開 Web データのおかげで、より速く正確な意思決定ができると回答しており、企業のデータ予算の約42% が Web データ収集に割り当てられています。Web スクレイピングを含むオルタナティブデータ市場はすでに49億ドル規模に達しており、なおも急成長中です。
では、この「金鉱熱」を生み出しているものは何でしょうか。代表的なビジネス用途をいくつか挙げます。
- 競争力のある価格設定と E コマース: 小売業者は競合サイトから価格や在庫を取得し、売上を4%以上伸ばすこともあります。
- リード獲得と営業インテリジェンス: 営業チームは、ディレクトリやソーシャルプラットフォームからメールアドレス、電話番号、企業情報の収集を自動化します。
- 市場調査とコンテンツ集約: アナリストは、ニュース、レビュー、感情分析データを集めて、トレンドの把握や予測に活用します。
- 広告と Ad Tech: 広告テック企業は、広告枠や競合キャンペーンをリアルタイムで追跡します。
- 不動産と旅行: 代理店は、物件一覧、価格、レビューを取得し、査定モデルや市場分析に役立てます。
- コンテンツとデータの集約: 複数ソースのデータをまとめ、比較ツールやダッシュボードを動かします。
JavaScript と Node.js は、こうした用途の定番スタックになっています。特に、動的に JavaScript で描画されるサイトが増えている今、その存在感はさらに大きいです。Node.js は非同期処理が得意なので、大規模スクレイピングに自然にフィットします。そして、豊富なライブラリエコシステムがあるため、素早いスクリプトから本番運用レベルの堅牢なスクレイパーまで構築できます。
データスクレイピングとは何か、そのやり方とは 2025年版 Get Started Free
中核となるワークフロー: JavaScript と Node.js でのウェブスクレイピングの仕組み
典型的なウェブスクレイピングの流れを整理してみましょう。シンプルなブログを取る場合でも、JavaScript を多用する E コマースサイトを取る場合でも、手順はおおむね共通です。
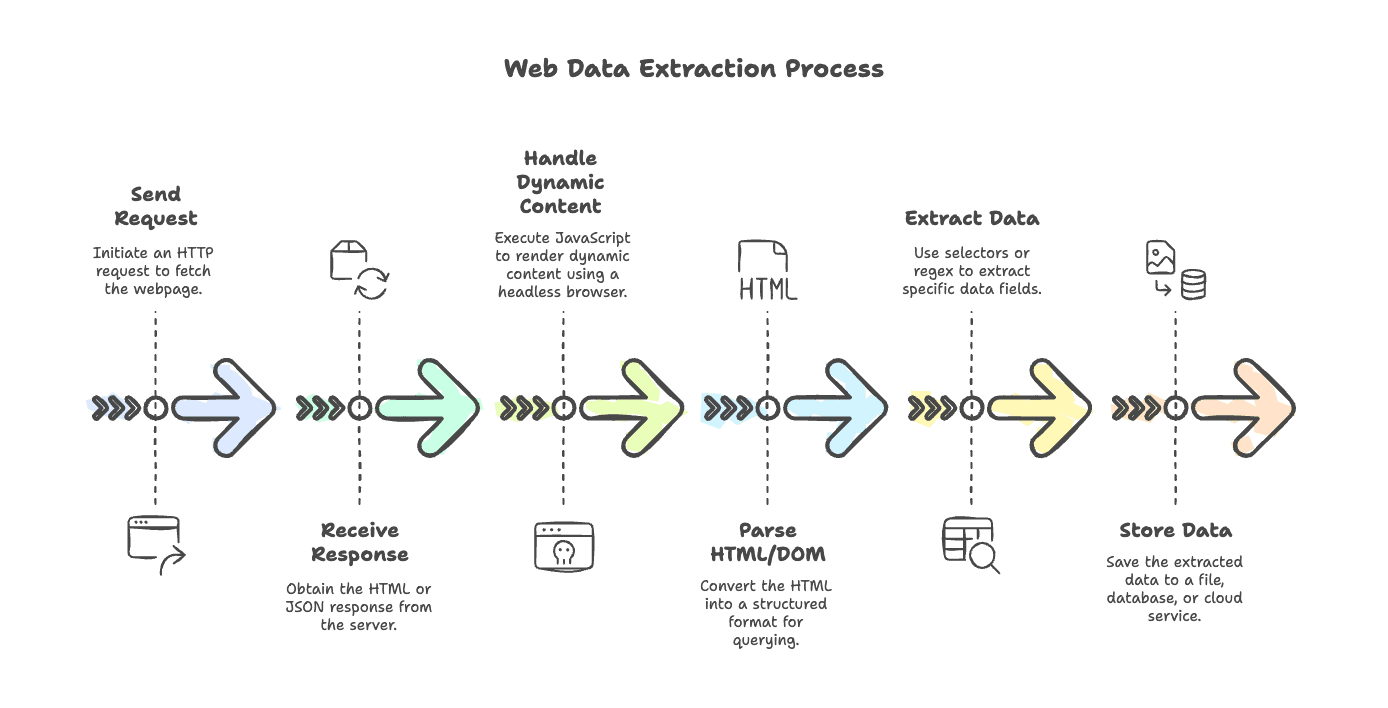
- リクエストを送信:
axios、node-fetch、gotなどの HTTP クライアントでページを取得します。 - レスポンスを受信: サーバーから HTML、または場合によっては JSON を受け取ります。
- 動的コンテンツを処理: ページが JavaScript でレンダリングされる場合は、Puppeteer や Playwright のようなヘッドレスブラウザでスクリプトを実行し、最終的な内容を取得します。
- HTML/DOM を解析:
cheerioやjsdomなどのパーサーで、HTML を検索可能な構造に変換します。 - データを抽出: セレクタや正規表現を使って、必要な項目を取り出します。
- データを保存: 結果をファイル、データベース、またはクラウドサービスに保存します。
それぞれのステップには、専用のツールとベストプラクティスがあります。次にその中身を見ていきましょう。
ウェブスクレイピング向けの必須 HTTP リクエストライブラリ
どのスクレイパーでも、最初の一歩は HTTP リクエストです。Node.js には、昔ながらのものから最新のものまで、選択肢が豊富にあります。ここでは代表的なライブラリを紹介します。
1. Axios
Node とブラウザ向けの、Promise ベースの HTTP クライアントです。多くのスクレイピング用途で「万能ツール」のように使えます。
const axios = require('axios');
const response = await axios.get('https://example.com/api/items', { timeout: 5000 });
console.log(response.data);
長所: 多機能、async/await 対応、自動 JSON 解析、インターセプター、プロキシ対応。
短所: やや重い、データ処理の挙動が少し「魔法っぽく」感じられることがある。
2. node-fetch
ブラウザの fetch API を Node.js で実装したものです。シンプルでモダンです。
import fetch from 'node-fetch';
const res = await fetch('https://api.github.com/users/github');
const data = await res.json();
console.log(data);
長所: 軽量、フロントエンド JavaScript に慣れている人にはおなじみの API。
短所: 機能は最小限、エラー処理は手動、プロキシ設定の記述がやや冗長。
3. SuperAgent
チェーン可能な API を持つ、老舗の HTTP ライブラリです。
const superagent = require('superagent');
const res = await superagent.get('https://example.com/data');
console.log(res.body);
長所: 成熟している、フォームやファイルアップロード、プラグインに対応。
短所: API がやや古く感じる、依存関係がやや大きい。
4. Unirest
シンプルで、言語に依存しない HTTP クライアントです。
const unirest = require('unirest');
unirest.get('https://httpbin.org/get?query=web')
.end(response => {
console.log(response.body);
});
長所: 書きやすい構文、短いスクリプトに向いている。
短所: 機能が少ない、コミュニティの活動はやや控えめ。
5. Got
Node.js 向けの、高速で堅牢な HTTP クライアントです。高度な機能も備えています。
import got from 'got';
const html = await got('https://example.com/page').text();
console.log(html.length);
長所: 高速、HTTP/2、リトライ、ストリームに対応。
短所: Node 専用、初心者には API がやや複雑に感じられることがある。
6. Node の標準 http/https
昔ながらのやり方ももちろん使えます。
const https = require('https');
https.get('https://example.com/data', (res) => {
let data = '';
res.on('data', chunk => { data += chunk; });
res.on('end', () => {
console.log('Response length:', data.length);
});
});
長所: 依存関係がない。
短所: 記述が冗長、コールバック中心、Promise 非対応。
詳しい機能比較とコード例はこちら。
プロジェクトに合った HTTP クライアントの選び方
どうやって適切なツールを選ぶべきでしょうか。私が重視しているのは次の点です。
- 使いやすさ: Axios と Got は、async/await とすっきりした構文が魅力です。
- パフォーマンス: Got と node-fetch は軽量で高速なので、高並列のスクレイピングに向いています。
- プロキシ対応: Axios と Got はプロキシの切り替えが簡単です。
- エラーハンドリング: Axios は HTTP エラーでデフォルトで例外を投げますが、node-fetch は手動チェックが必要です。
- コミュニティ: Axios と Got は利用者が多く、情報も豊富です。
私のざっくり推奨:
- 短いスクリプトや試作: node-fetch または Unirest
- 本番向けスクレイピング: Axios(機能重視)または Got(性能重視)
- ブラウザ自動化: Puppeteer または Playwright が内部でリクエストを処理します
HTML の解析とデータ抽出: Cheerio、jsdom、そのほか
HTML を取得したら、実際に扱える形へ変換する必要があります。そこで登場するのがパーサーです。
Cheerio
Cheerio は、サーバーサイド版の jQuery のような存在です。高速で軽量、静的な HTML に最適です。
const cheerio = require('cheerio');
const $ = cheerio.load('<ul><li class="item">Item 1</li></ul>');
$('.item').each((i, el) => {
console.log($(el).text());
});
長所: 圧倒的に速い、なじみのある API、崩れた HTML にも強い。
短所: JavaScript の実行はしないため、HTML に書かれている内容しか見えない。
jsdom
jsdom は、Node.js 上でブラウザに近い DOM を再現します。簡単なスクリプトを実行でき、Cheerio よりも「ブラウザらしさ」があります。
const { JSDOM } = require('jsdom');
const dom = new JSDOM(`<p id="greet">Hello</p><script>document.querySelector('#greet').textContent += ", world!";</script>`);
console.log(dom.window.document.querySelector('#greet').textContent);
長所: スクリプトを実行できる、DOM API をひと通り扱える。
短所: Cheerio より遅く重い、本物のブラウザではない。
正規表現や他の解析方法を使うべき場面
ウェブスクレイピングにおける正規表現は、ホットソースのようなものです。少量なら最高ですが、何にでもかけるものではありません。正規表現が役立つのはたとえば次のような場面です。
- テキストからパターンを抽出する場合(メール、電話番号、価格など)
- スクレイピングしたデータの整形や検証
- テキストの塊や script タグからデータを取り出す場合
例: テキストから数値を抽出する
const text = "Total sales: 1,234 units";
const match = text.match(/([\d,]+)\s*units/);
if (match) {
const units = parseInt(match[1].replace(/,/g, ''));
console.log("Units sold:", units);
}
ただし、HTML 全体を正規表現で解析しようとするのはやめましょう。そういう用途には DOM パーサーを使うべきです。スクレイピング向けの正規表現のヒントも参考になります。
動的サイトへの対応: Puppeteer、Playwright、ヘッドレスブラウザ
現代の Web サイトは JavaScript が大好きです。欲しいデータが初期 HTML に入っておらず、ページ読み込み後にスクリプトで描画されることも珍しくありません。そこで登場するのがヘッドレスブラウザです。
Puppeteer
Google が提供する Node.js ライブラリで、Chrome/Chromium を操作できます。まるでロボットがあなたの代わりにページをクリックし、スクロールして回ってくれるようなものです。
const puppeteer = require('puppeteer');
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://example.com');
const title = await page.$eval('h1', el => el.textContent);
console.log(title);
await browser.close();
長所: Chrome の描画をそのまま使える、API がわかりやすい、動的コンテンツに強い。
短所: Chromium 専用、リソース消費が大きい。
Playwright
Microsoft の新しめのライブラリで、Chromium、Firefox、WebKit をサポートします。Puppeteer の、より洗練されたクロスブラウザ版のいとこのような存在です。
const { chromium } = require('playwright');
const browser = await chromium.launch();
const page = await browser.newPage();
await page.goto('https://example.com');
const content = await page.textContent('h1');
console.log(content);
await browser.close();
長所: クロスブラウザ対応、並列コンテキスト、自動待機。
短所: 学習曲線はやや急、インストールサイズが大きめ。
Nightmare
何年も前に人気だった Electron ベースの自動化ツールです。リポジトリは segment-boneyard という GitHub 組織、つまり Segment がサポートを終了したプロジェクトの置き場へ移され、最後の npm リリースも2019年でした。2026年の新規案件でこれを選ぶことはありません。もし既存のスクリプトを引き継いで使っているなら話は別ですが、新規プロジェクトなら最初から Playwright か Puppeteer に進むべきです。
ヘッドレスブラウザの比較
| 項目 | Puppeteer(Chrome) | Playwright(マルチブラウザ) | Nightmare(Electron) |
|---|---|---|---|
| ブラウザ対応 | Chrome/Edge | Chrome、Firefox、WebKit | Chrome(旧) |
| パフォーマンスと規模 | 高速だが重い | 高速で並列性が高い | 遅く、安定性も低い |
| 動的スクレイピング | 非常に優秀 | 非常に優秀 + 機能が多い | 単純なサイトなら可 |
| 保守性 | きちんと保守されている | 非常に活発 | アーカイブ済み(segment-boneyard、最後の npm 公開は2019年) |
| 最適用途 | Chrome のスクレイピング | 複雑なクロスブラウザ処理 | 単純なレガシー案件 |
私のおすすめ: 新規で複雑な案件なら Playwright を使いましょう。Chrome 専用なら今でも Puppeteer は十分に優秀です。Nightmare は、ほぼ懐かしむためか、古いスクリプトのためのものです。
補助ツール: スケジューリング、環境管理、CLI、データ保存
実務のスクレイパーは、取得して解析するだけではありません。私が頼りにしている補助ツールを紹介します。
スケジューリング: node-cron
スクレイパーを自動実行するようにスケジュールできます。
const cron = require('node-cron');
cron.schedule('0 9 * * MON', () => {
console.log('毎週月曜の午前9時にスクレイピングしています');
});
環境管理: dotenv
秘密情報や設定をコードから分離できます。
require('dotenv').config();
const apiKey = process.env.API_KEY;
CLI ツール: chalk、commander、inquirer
- chalk: コンソール出力に色を付けます。
- commander: コマンドラインオプションを解析します。
- inquirer: ユーザー入力のための対話型プロンプトです。
データ保存
- fs: ファイルに書き込みます(JSON、CSV)。
- lowdb: 軽量な JSON データベース。
- sqlite3: ローカル SQL データベース。
- mongodb: 大きめの案件向けの NoSQL データベース。
例: データを JSON に保存する
const fs = require('fs');
fs.writeFileSync('output.json', JSON.stringify(data, null, 2));
JavaScript と Node.js による従来型ウェブスクレイピングの痛点
正直に言うと、従来型のスクレイピングはいいことばかりではありません。私がこれまで見てきて、そして実際に痛感してきた主な悩みは次のとおりです。

- 学習コストが高い: DOM、セレクタ、非同期ロジック、場合によってはブラウザ固有の癖まで理解する必要があります。
- 保守負担が大きい: Web サイトは変わり、セレクタは壊れ、そのたびにコードを直し続けることになります。
- スケールしにくい: サイトごとに個別スクリプトが必要で、真に「万能」なものはありません。
- データクレンジングが複雑: 取得データは汚れがちで、整形、書式調整、重複排除だけでも仕事になります。
- 性能の限界: ブラウザ自動化は、大規模処理では遅く、リソースも食います。
- ブロックとボット対策: サイトがスクレイパーをブロックしたり、CAPTCHA を出したり、ログインの向こう側にデータを隠したりします。
- 法的・倫理的なグレーゾーン: 利用規約、プライバシー、コンプライアンスをしっかり確認する必要があります。
Thunderbit と従来型ウェブスクレイピング: 生産性の革命
ここで、みなさんが気になっているであろう点に触れましょう。コードもセレクタも保守も、すべて飛ばせたらどうでしょうか。
そこで登場するのがThunderbitです。共同創業者兼 CEO として少し肩入れしているのは認めますが、でも本音です。Thunderbit は、頭を悩ませることなくデータを取りたいビジネスユーザーのために作られています。
Thunderbit の比較
| 項目 | Thunderbit(AI ノーコード) | 従来の JS/Node スクレイピング |
|---|---|---|
| セットアップ | 2クリック、コード不要 | スクリプト作成、デバッグ |
| 動的コンテンツ | ブラウザ内で処理 | ヘッドレスブラウザのスクリプト化 |
| 保守 | AI が変化に適応 | 手動でコード更新 |
| データ抽出 | AI が項目を提案 | 手動セレクタ |
| サブページのスクレイピング | 標準搭載、1クリック | サイトごとにループと実装が必要 |
| エクスポート | Excel、Sheets、Notion | 手動でファイル/DB 連携 |
| 後処理 | 要約、タグ付け、整形 | 追加のコードやツールが必要 |
| 使える人 | ブラウザが使えれば誰でも | 開発者のみ |
Thunderbit の AI はページを読み取り、項目を提案し、わずか数クリックでデータを抽出します。サブページにも対応し、レイアウト変更にも追従し、スクレイピングしながら要約、タグ付け、翻訳までこなせます。Excel、Google Sheets、Airtable、Notion にエクスポートでき、技術的なセットアップは不要です。
Thunderbit が特に活躍する用途:
- 競合の SKU と価格を追跡する E コマースチーム
- リードや連絡先情報を収集する営業チーム
- ニュースやレビューを集約する市場調査担当
- 物件一覧や詳細情報を取得する不動産仲介業者
高頻度で業務上重要なスクレイピングでは、Thunderbit は大幅な時間短縮になります。カスタムで大規模、あるいは深い連携が必要な案件では従来のスクリプトにも出番がありますが、多くのチームにとっては、「データが欲しい」から「データを手に入れた」まで最短で進める方法が Thunderbit です。
Thunderbit の Chrome 拡張機能の動作を見るか、Thunderbit ブログで他の活用例もご覧ください。
早見表: 人気の JavaScript & Node.js ウェブスクレイピングライブラリ
2026年時点の JavaScript スクレイピングエコシステムのチートシートです。
HTTP リクエスト
- Axios: Promise ベースで多機能な HTTP クライアント。
- node-fetch: Node.js 用の Fetch API。
- Got: 高速で高機能な HTTP クライアント。
- SuperAgent: 成熟したチェーン可能な HTTP リクエスト。
- Unirest: シンプルで言語非依存のクライアント。
HTML 解析
動的コンテンツ
- Puppeteer: ヘッドレス Chrome 自動化。
- Playwright: マルチブラウザ自動化。
- Nightmare: Electron ベースのレガシーブラウザ自動化。
スケジューリング
- node-cron: Node.js の cron ジョブ。
CLI とユーティリティ
保存
フレームワーク
- Crawlee: Apify による高レベルのクロール&スクレイピングフレームワーク。2026年5月時点では JavaScript/TypeScript 版が v3.16 で、こちらの方が成熟しています(Python 版はより新しいです)。Puppeteer、Playwright、Cheerio、JSDOM を 1 つの API の背後にまとめ、プロキシのローテーションやキューイングも標準搭載です。スクレイパーの周辺で同じ土台を何度も作り直しているなら、特に便利です。
(最新の情報は、必ず公式ドキュメントと GitHub リポジトリで確認してください。)
JavaScript でのウェブスクレイピングを極めるためのおすすめリソース
さらに深く学びたいですか。スキルを一段引き上げるための厳選リソースを紹介します。
公式ドキュメントとガイド
- MDN Web Docs: Web Scraping
- Puppeteer Documentation
- Playwright Documentation
- Crawlee Documentation
- Apify Web Scraping Academy
チュートリアルとコース
- freeCodeCamp: The Ultimate Guide to Web Scraping with Node.js
- YouTube: Web Scraping with Node.js (freeCodeCamp)
- DigitalOcean: Node.js と Puppeteer を使って Web サイトをスクレイピングする方法
オープンソースプロジェクトと例
コミュニティとフォーラム
書籍と包括的ガイド
- O’Reilly の「Web Scraping with Python」(言語をまたぐ概念の理解に役立ちます)
- Udemy/Coursera の「Web Scraping in Node.js」コース
(最新版と更新状況は、必ず確認してください。)
AI を使ってあらゆる Web サイトをスクレイピングする方法 Get Started Free
まとめ: チームに最適なアプローチを選ぶ
結論をひとことで言うと、JavaScript と Node.js は、ウェブスクレイピングに驚くほどの力と柔軟性を与えてくれます。雑に作った短いスクリプトから、堅牢でスケーラブルなクローラーまで、何でも作れます。ただし、大きな力には大きな……保守が伴います。従来型のスクリプティングは、完全な制御が必要で、継続的なメンテナンスも受け入れられる、エンジニアリング色の強いカスタム案件に最適です。
それ以外の人、つまりビジネスユーザー、アナリスト、マーケター、そして単にデータが欲しい人にとっては、Thunderbit のような最新のノーコードソリューションが、まさに息をつくような存在です。Thunderbit の AI 搭載 Chrome 拡張機能なら、数日ではなく数分でデータをスクレイピングし、構造化し、エクスポートできます。コードなし、セレクタなし、悩みなしです。
では、どちらが正解でしょうか。チームに十分なエンジニアリング力があり、要件も独自性が高いなら、Node.js のツール群に飛び込んでください。スピード、シンプルさ、そしてインフラではなく分析に集中できる自由を求めるなら、Thunderbit を試してみてください。どちらにしても、Web はあなたのデータベースです。さあ、データを取りに行きましょう。
そして、行き詰まったときは思い出してください。最高のスクレイパーだって、最初は白紙のページと一杯の濃いコーヒーから始まったのです。スクレイピング、楽しんでください。
AI 搭載スクレイピングについてもっと知りたい、または Thunderbit の動作を見てみたいですか?
- Thunderbit 公式サイト
- Thunderbit Chrome 拡張機能をダウンロード
- Thunderbit ブログ
- AI を使ってあらゆる Web サイトをスクレイピングする方法
- データスクレイピングとは何か、そのやり方とは 2025年版
質問、体験談、お気に入りの失敗談があれば、コメント欄に書くか、直接ご連絡ください。私は、人々が Web を自分だけのデータ遊び場に変えていく話を聞くのが大好きです。
好奇心を忘れず、カフェインを切らさず、そしてもっと賢くスクレイピングしていきましょう。大変にする必要はありません。
AI ウェブスクレイパーを試す Get Started Free
FAQ:
1. 2025年に JavaScript と Node.js でウェブスクレイピングを行う理由は何ですか?
現代の Web サイトの多くが JavaScript で構築されているからです。Node.js は高速で非同期処理に強く、Axios、Cheerio、Puppeteer などの豊富なエコシステムにより、単純な取得から動的コンテンツの大規模スクレイピングまで幅広く対応できます。
2. Node.js で Web サイトをスクレイピングする典型的な流れは?
通常は次のような流れです。
リクエスト → レスポンス処理 → (必要なら JS 実行)→ HTML 解析 → データ抽出 → 保存またはエクスポート
各ステップは、axios、cheerio、puppeteer などの専用ツールで処理できます。
3. 動的で JavaScript レンダリングのページはどうスクレイピングしますか?
Puppeteer や Playwright のようなヘッドレスブラウザを使います。ページ全体(JS を含む)を読み込めるので、ユーザーが実際に見ている内容を取得できます。
4. 従来型スクレイピングの最大の課題は何ですか?
- サイト構造の変更
- ボット検知・対策
- ブラウザのリソースコスト
- 手作業のデータクレンジング
- 長期的な保守負担の大きさ
これらのため、大規模処理や非開発者向けのスクレイピングは継続しにくくなります。
5. コードの代わりに Thunderbit のようなツールを使うべきなのはいつですか?
スピードとシンプルさが必要で、コードを新しく書いたり保守したりしたくないなら Thunderbit を使ってください。営業、マーケティング、リサーチのチームが、特に複雑なサイトや複数ページにまたがるサイトから素早くデータを抽出し、構造化したいときに最適です。




