

ターミナルを開いてコマンドをひとつ叩いただけで、まるでマトリックスの裏側をのぞき込んだかのように、生のWebデータがどっと流れ込んでくる——その感覚には、時代を問わず人を惹きつける何かがあります。開発者やテック寄りのパワーユーザーにとって、cURL はまさにその魔法の杖。地味なコマンドラインツールですが、クラウドサーバーからスマート冷蔵庫まで、何十億ものデバイスの裏で黙々と動き続けています。そして2026年の今もなお、ノーコードや AI スクレイピングツールがこれだけ揃った時代にあって、cURL を使ったウェブスクレイピングは、速度・制御性・スクリプト化のしやすさを重んじる人にとって、変わらぬ定番であり続けています。
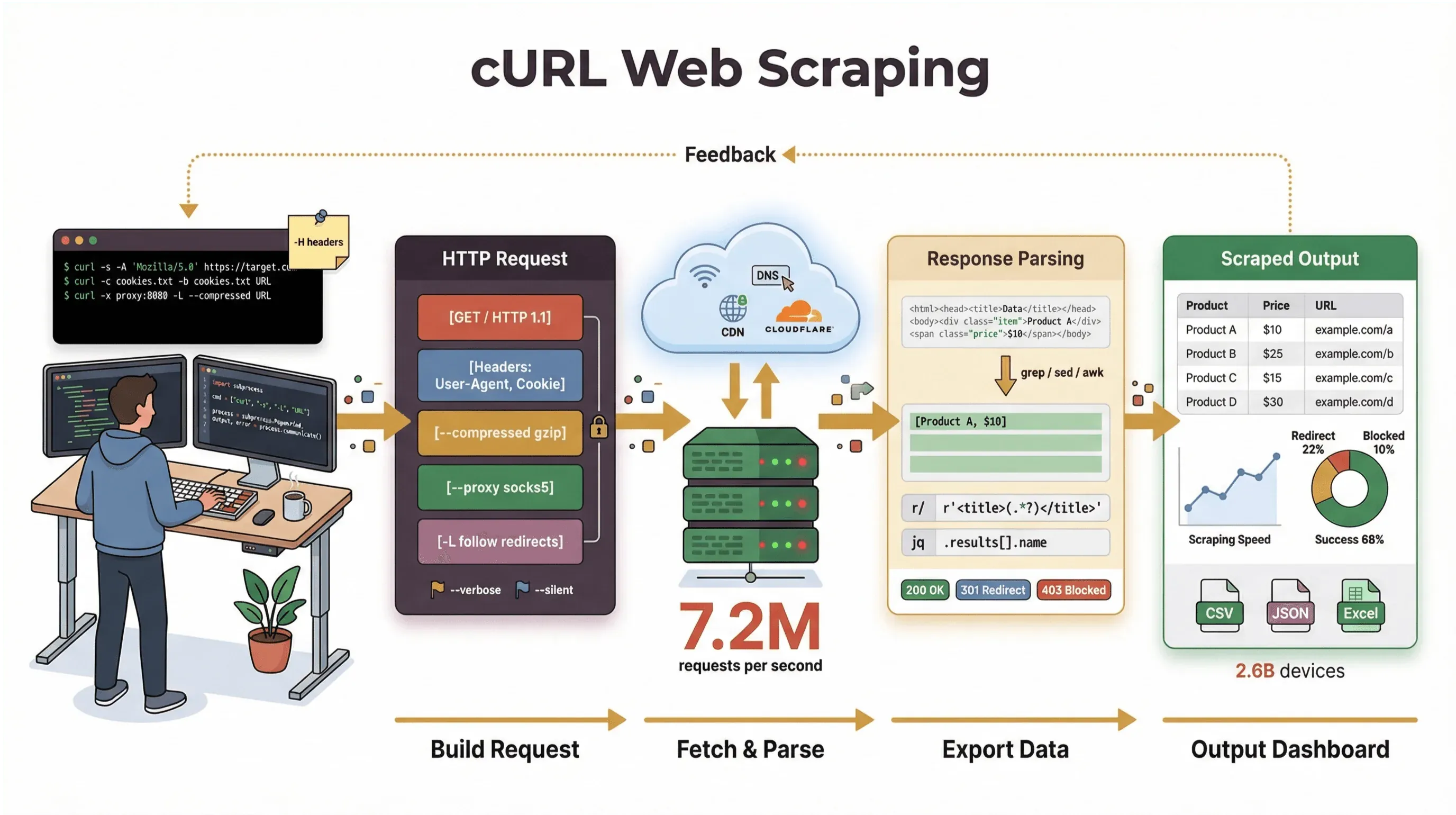 私は長年、自動化ツールを組み、チームの Web データ活用を手伝ってきましたが、ページをさっと取りたいとき、API をデバッグしたいとき、スクレイピングのワークフローを試作したいときには、今でも真っ先に cURL に手が伸びます。このガイドでは、基本から実践的な応用テクニックまでを一気通貫でカバーする cURL ウェブスクレイピングのチュートリアルを、実際のコマンド例、現場で効くヒント、そして cURL が強い場面と限界の両方を交えながらお届けします。コマンドラインには触れたくないというビジネスユーザーの方なら、私たちの AI 搭載ウェブスクレイパー Thunderbit を使えば、「このデータがほしい」から「はい、スプレッドシートです」まで、わずか2クリック。コードは一切いりません。
私は長年、自動化ツールを組み、チームの Web データ活用を手伝ってきましたが、ページをさっと取りたいとき、API をデバッグしたいとき、スクレイピングのワークフローを試作したいときには、今でも真っ先に cURL に手が伸びます。このガイドでは、基本から実践的な応用テクニックまでを一気通貫でカバーする cURL ウェブスクレイピングのチュートリアルを、実際のコマンド例、現場で効くヒント、そして cURL が強い場面と限界の両方を交えながらお届けします。コマンドラインには触れたくないというビジネスユーザーの方なら、私たちの AI 搭載ウェブスクレイパー Thunderbit を使えば、「このデータがほしい」から「はい、スプレッドシートです」まで、わずか2クリック。コードは一切いりません。
それでは、なぜ2026年の今でも cURL がウェブスクレイピングで通用するのか、どう使えば力を引き出せるのか、そしてどのタイミングでもっと強力なツールへ乗り換えるべきなのかを、順に見ていきましょう。
cURLとは? cURLを使ったウェブスクレイピングの基礎
cURL は、URL を介してデータを転送するためのコマンドラインツール兼ライブラリです。登場からかれこれ30年近く(本当の話です)、Linux にも macOS にも Windows にも、果ては組み込み機器にまで、ありとあらゆる場所に組み込まれています。数々のスクリプトを下支えし、200億以上のインストールで静かにデータ転送を担ってきました。Web ページをさっと取得したり、API をテストしたり、ファイルをダウンロードしたりしたことがあるなら、その裏で cURL が働いていた可能性は高いでしょう。
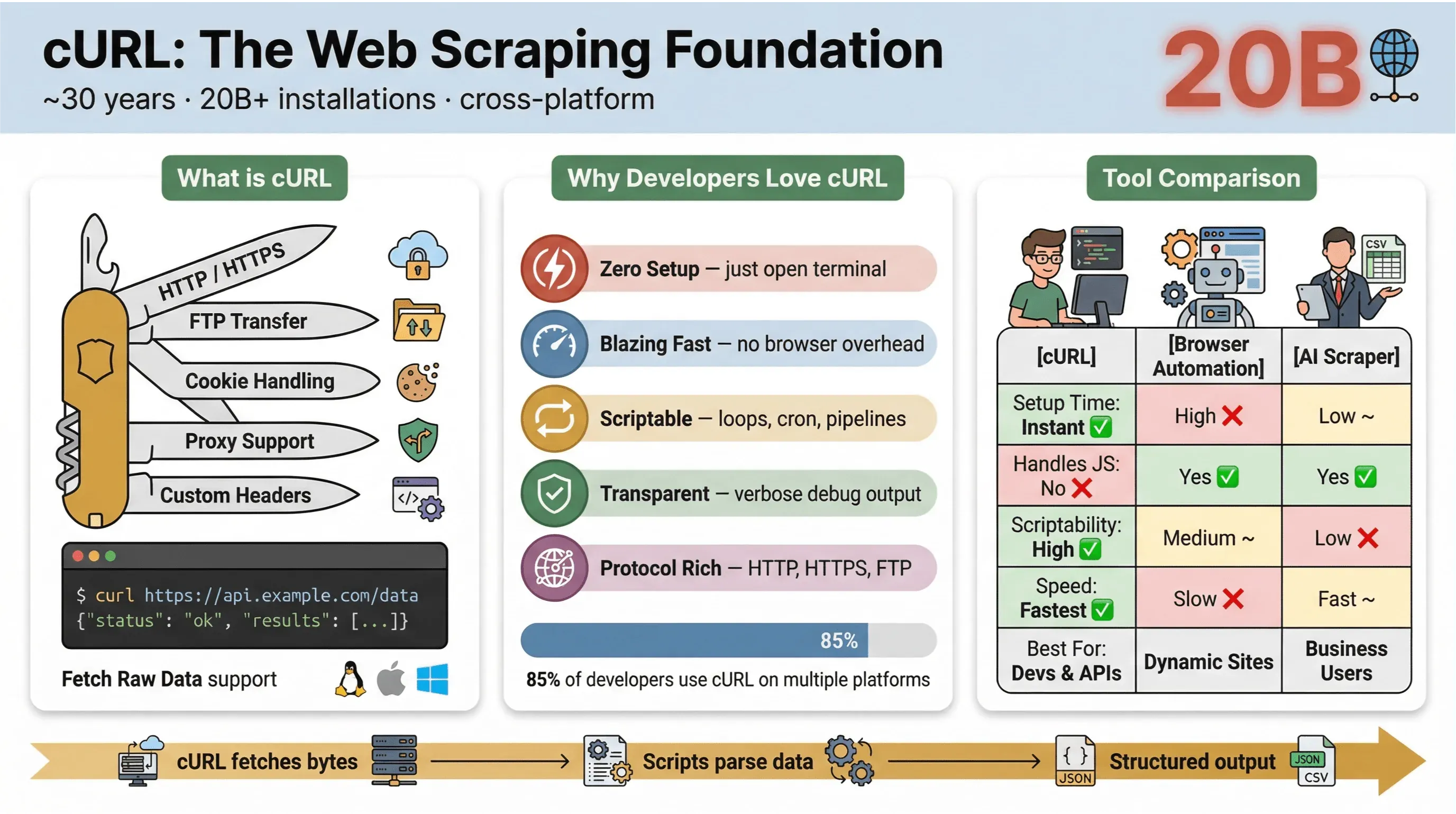 cURL がウェブスクレイピングでこれほど愛される理由は、こんなところにあります。
cURL がウェブスクレイピングでこれほど愛される理由は、こんなところにあります。
- 軽量でクロスプラットフォーム: Linux、macOS、Windows、さらには組み込みデバイスでも動きます。
- 多様なプロトコルに対応: HTTP、HTTPS、FTP などを扱えます。
- スクリプト化しやすい: 自動化、cronジョブ、つなぎ込みコードにうってつけです。
- ユーザー操作が不要: 非対話型の利用を前提に設計されており、バッチ処理やパイプラインに向いています。
ただ、ここははっきりさせておきましょう。cURL の本分は、HTML、JSON、画像といった生のデータを取ってくることにあります。取得したデータを解析したり、描画したり、構造化したりする機能は持っていません。cURL は、ウェブスクレイピングの「最初の一歩」だと捉えるのがちょうどいいのです。バイト列はしっかり運んできてくれますが、それを構造化データに仕立てるには、Python スクリプトや grep/sed/awk、あるいは AI ウェブスクレイパーのような別の道具が要ります。
公式のドキュメントにあたりたい方は、cURLのHTTPスクリプトガイドをどうぞ。
なぜウェブスクレイピングにcURLを使うのか?(cURLウェブスクレイピングチュートリアル)
新しいツールがこれだけあふれている中で、なぜ開発者やテックユーザーは今も cURL に戻ってくるのでしょう。その理由を挙げてみます。
- セットアップが最小限: インストールも依存関係も不要。ターミナルを開けば、もう使えます。
- 高速: ブラウザの読み込みを待つことなく、すぐにデータを取りに行けます。
- スクリプト化しやすい: URL のループ処理、リクエストの自動化、コマンドの連結が手軽です。
- プロトコルと機能の対応範囲が広い: Cookie、プロキシ、リダイレクト、カスタムヘッダーなどを扱えます。
- 透明性が高い: 詳細出力やデバッグ出力で、内部で何が起きているかを正確に追えます。
2025年のcURLユーザー調査では、回答者の85.7%が cURL のコマンドラインツールを使っていると答え、96.2%が Linux 上で利用していると報告しました。Linux は今もなお、cURL の主戦場として圧倒的な存在感を放っています。
--- ようするに、HTTP リクエスト、手早いデータ取得、トラブルシューティングを一手に引き受ける万能ツール、というわけです。
cURL と他のスクレイピング手法を、ざっと並べて比べると次のようになります。
| 機能 | cURL | ブラウザ自動化(例:Selenium) | AIウェブスクレイパー(例:Thunderbit) |
|---|---|---|---|
| セットアップ時間 | 即時 | 高い | 低い |
| スクリプト化しやすさ | 高い | 中程度 | 低い(コード不要) |
| JavaScript対応 | いいえ | はい | はい(Thunderbit: ブラウザ経由) |
| Cookie/セッション対応 | 手動 | 自動 | 自動 |
| データ構造化 | 手動(後で解析) | 手動(後で解析) | AI/テンプレートベース |
| 最適な用途 | 開発者、手早い取得 | 複雑で動的なサイト | ビジネスユーザー、構造化エクスポート |
要するに cURL は、静的ページや API、あるいはシンプルなワークフローの自動化といった、すばやくスクリプト化してデータを取りに行く用途では右に出るものがありません。一方で、込み入った HTML の解析や JavaScript への対応、構造化データのエクスポートが必要になった瞬間、もっと専門のツールが恋しくなります。
はじめ方:cURLで行う基本的なウェブスクレイピングのコマンド例
では、手を動かしてみましょう。ここでは、cURL を使った基本的なウェブスクレイピングを、ひとつずつ順を追って紹介していきます。
cURLで生のHTMLを取得する
いちばんシンプルな使い方は、Web ページの HTML をそのまま取得することです。
curl https://books.toscrape.com/
このコマンドは、ウェブスクレイピング練習用の公開デモサイト Books to Scrape のトップページを取りに行きます。ターミナルには生の HTML が流れ、<title> タグや “In stock.” といった断片が目に入るはずです。
出力をファイルに保存する
あとで解析するために HTML を取っておきたいなら、-o フラグを使います。
curl -o page.html https://books.toscrape.com/
これで、HTML コンテンツをまるごと収めた page.html ファイルができあがります。後続の分析や、別ツールでの解析にぴったりです。
cURLでPOSTリクエストを送る
フォームの送信や API とのやり取りが必要ですか? POST リクエストには -d フラグを使います。ここでは、HTTP テスト用に作られたサイト httpbin を例にとります。
curl -X POST https://httpbin.org/post -d "key1=value1&key2=value2"
送ったデータをそのまま返してくれる JSON レスポンスが返ってきます。テストや試作の場面で重宝します。
ヘッダーの確認とデバッグ
レスポンスヘッダーを覗きたいとき、あるいはリクエストをデバッグしたいときもあるでしょう。
-
ヘッダーのみ取得(HEADリクエスト):
curl -I https://books.toscrape.com/ -
本文と一緒にヘッダーも表示:
curl -i https://httpbin.org/get -
詳細なデバッグ出力:
curl -v https://books.toscrape.com/
これらのフラグは、内部で何が起きているかを把握するのに役立ちます。トラブルシューティングでは手放せません。
ここで、これらのコマンドをさっと見返せる表をまとめておきます。
| タスク | コマンド例 | 補足 |
|---|---|---|
| HTMLを取得する | curl URL | HTMLをターミナルに出力 |
| ファイルに保存する | curl -o file.html URL | 出力をファイルへ書き込み |
| ヘッダーを確認する | curl -I URL または curl -i URL | -I はHEADのみ、-i は本文と一緒にヘッダーも表示 |
| フォームデータをPOSTする | curl -d "a=1&b=2" URL | フォームエンコードされたデータを送信 |
| リクエスト/レスポンスをデバッグする | curl -v URL | 詳細なリクエスト/レスポンス情報を表示 |
もっと例を見たい方は、cURLの公式スクリプトドキュメントを参照してください。
一歩進んだ使い方:cURLによる高度なウェブスクレイピング(cURLを使ったウェブスクレイピング)
基本に慣れてきたら、cURL にはもっと複雑なスクレイピングで活きてくる高度な機能が、まだまだ控えています。
Cookieとセッションの扱い
多くのサイトは、ログインセッションの維持やユーザー追跡のために Cookie を使います。cURL なら、Cookie を保存しておいて次のリクエストで使い回せます。
# ログイン後にCookieを保存
curl -c cookies.txt https://example.com/login
# 続くリクエストでCookieを使用
curl -b cookies.txt https://example.com/account
こうすることでブラウザのセッションを再現でき、ログインで守られたページにもアクセスできます(JavaScript のチャレンジがない場合に限りますが)。
User-Agentやカスタムヘッダーを偽装する
サイトによっては、User-Agent やヘッダーに応じて返す中身を変えてきます。cURL はデフォルトで “curl/VERSION” と名乗るため、ブロックされたり、別の内容が返ってきたりすることがあります。ブラウザのふりをさせるには、こうします。
curl -A "Mozilla/5.0 (Windows NT 10.0; Win64; x64)" https://example.com/
言語設定のようなカスタムヘッダーも指定できます。
curl -H "Accept-Language: en-US,en;q=0.9" https://example.com/
これで、実際のブラウザが目にするのと同じ内容を取得しやすくなります。
ウェブスクレイピングでプロキシを使う
リクエストをプロキシ経由にしたいですか? 地域ごとの表示テストや IP ブロックの回避に使うなら、-x フラグを指定します。
curl -x http://proxy.example.org:4321 https://remote.example.org/
ただし、プロキシは責任を持って使い、サイトの利用規約はきちんと守ってください。
複数ページのスクレイピングを自動化する
商品一覧のページネーションのように、複数ページをまとめて取得したいときは、簡単なシェルループが役立ちます。
for p in $(seq 2 5); do
curl -s -o "books-page-${p}.html" \
"https://books.toscrape.com/catalogue/category/books_1/page-${p}.html"
sleep 1
done
この例では、Books to Scrape のカタログの2〜5ページ目を取得し、それぞれ別ファイルに保存します。(1ページ目はトップページにあたります。)
cURLを使ったウェブスクレイピングの限界:知っておくべきこと
cURL には惚れ込んでいますが、何でもこなせる万能選手ではありません。弱点を挙げておきます。
- JavaScriptを実行できない: JavaScript で中身を描画したり、ボット対策のチャレンジを解いたりする必要があるページには歯が立ちません(developers.cloudflare.com)。
- 手動での解析が必要: 取れるのは生の HTML や JSON で、解析は自分の手でやることになります。たいていは追加のスクリプトやツールが要ります。
- セッション管理が限定的: 複雑なログイン、トークン、多段階のフォームを扱おうとすると、あっという間に煩雑になります。
- データ構造化機能がない: Web ページを行や表、スプレッドシートに変える機能はありません。
- ボット検知に弱い: 多くのサイトは JavaScript、フィンガープリンティング、CAPTCHA といった高度なボット対策を敷いており、cURL 単体では突破できません(datadome.co)。
ざっくりした比較表はこちらです。
| 制約 | cURLだけの場合 | 最新のスクレイピングツール(例:Thunderbit) |
|---|---|---|
| JavaScript対応 | いいえ | はい |
| データ構造化 | 手動 | 自動(AI/テンプレート) |
| セッション管理 | 手動 | 自動 |
| ボット対策の回避 | 限定的 | 高度(ブラウザベース/AI) |
| 使いやすさ | 技術者向け | 非技術者向け |
静的なページや API が相手なら、cURL は実に頼れる存在です。けれども、もっと動的なサイトや防御の固いサイトに踏み込むなら、ツールチェーンを次の段階へ進める必要が出てきます。
ThunderbitとcURL:非技術ユーザーに最適なウェブスクレイピングの選択肢
ここで Thunderbit の出番です。Thunderbit は、AI 搭載のウェブスクレイパー Chrome 拡張機能。営業担当やマーケター、オペレーション担当など、コマンドラインに触れることなく、サイトから Excel、Google Sheets、Notion へデータを取り出したい人のために作られています。
Thunderbit と cURL を並べると、こうなります。
| 機能 | cURL | Thunderbit |
|---|---|---|
| ユーザーインターフェース | コマンドライン | ポイント&クリック(Chrome拡張機能) |
| AIによる項目提案 | いいえ | はい(AIがページを読み取り、列を提案) |
| ページネーション/サブページ対応 | 手動スクリプト | 自動(AIが検出してスクレイピング) |
| データエクスポート | 手動(解析+保存) | Excel、Google Sheets、Notion、Airtableへ直接出力 |
| JavaScript/保護ページ | いいえ | はい(ブラウザベースのスクレイピング) |
| ノーコード不要 | いいえ(スクリプトが必要) | はい(誰でも使える) |
| 無料プラン | 常に無料 | 6ページまで無料(トライアル増量で10ページ) |
Thunderbit では、拡張機能を開いて「AIで項目を提案」を押すだけ。あとは AI が、何を抜き出すべきかを自分で判断してくれます。表、リスト、商品詳細はもちろん、サブページまで自動でたどってくれるのです。集め終わったら、データはお気に入りの業務ツールへそのままエクスポート。解析の手間も、ひと手間もいりません。
Thunderbit は世界中で10万人以上のユーザーに使われており、とりわけ営業、EC、不動産チームのように、構造化データをスピーディに必要とする人たちから支持を集めています。
ウェブスクレイピングにThunderbitのChrome拡張機能を試す
試してみたくなりましたか? Chrome拡張機能はこちらからダウンロードできます。
cURLとThunderbitを組み合わせる:柔軟なウェブスクレイピング戦略
テックに強い方なら、どちらか片方に絞る必要はありません。実際、多くのチームは最大限の小回りを利かせるために、cURL と Thunderbit を両方使い分けています。
- cURLで試作する: エンドポイントをさっとテストし、ヘッダーを確かめ、サイトがどう応答するかをつかむのに向いています。
- Thunderbitでスケールする: 構造化データが欲しいとき、複数ページをまたいで取りたいとき、繰り返し回せるワークフローが必要なときは、Thunderbit のポイント&クリック抽出と直接エクスポートに切り替えましょう。
市場調査向けのワークフローを、一例として挙げてみます。
- cURLで数ページを取得し、HTML構造を確認する。
- 欲しいデータ項目(例:商品名、価格、レビュー)を特定する。
- Thunderbitを開き、「AIで項目を提案」をクリックして、AIにスクレイパーを組ませる。
- すべてのページ(サブページやページネーション付き一覧を含む)をスクレイピングし、Google Sheetsへエクスポートする。
- データを分析し、共有し、活用する。手動解析は不要です。
判断の目安になる簡単な表は、こちらです。
| シナリオ | cURLを使う | Thunderbitを使う | 両方使う |
|---|---|---|---|
| APIや静的ページをすばやく取得 | ✅ | ||
| スプレッドシート用の構造化データが必要 | ✅ | ||
| ヘッダーやCookieのデバッグ | ✅ | ||
| 動的/JavaScript主体のページをスクレイピング | ✅ | ||
| 繰り返し使えるノーコードのワークフローを作る | ✅ | ||
| 試作してからスケールアップする | ✅ | ✅ | ハイブリッド運用 |
cURLでのウェブスクレイピングでよくある課題と落とし穴
cURL を使いこなすまでに、実際につまずきやすいポイントを先に押さえておきましょう。
- ボット対策: 多くのサイトは JavaScript チャレンジ、CAPTCHA、フィンガープリンティングといった高度な防御を敷いており、cURL では突破できません(developers.cloudflare.com)。
- データ品質の問題: HTML の変更、項目の欠落、レイアウトのばらつきで、スクリプトが壊れることがあります。
- 保守コスト: サイトが変わるたびに、解析ロジックを更新しなければなりません。
- 法務・コンプライアンス上のリスク: スクレイピングの前に、必ずサイトの利用規約、robots.txt、関連法規を確認してください。公開データだからといって、好きに使ってよいとは限りません(calawyers.org、polsinelli.com)。
- スケーリングの限界: cURL は小規模な作業にはめっぽう強いものの、大規模スクレイピングではプロキシ、レート制限、エラーハンドリングの管理が必要になってきます。
トラブルシューティングとコンプライアンス遵守のコツ:
- まずは、許可のあるサイトやデモサイト(Books to Scrape など)から手をつける。
- レート制限を尊重し、エンドポイントを叩きすぎない。
- 法的根拠がない限り、個人データのスクレイピングは避ける。
- JavaScript や CAPTCHA の壁にぶつかったら、Thunderbit のようなブラウザベースのツールへの切り替えを検討する。
ステップ・バイ・ステップ要約:cURLでウェブサイトをスクレイピングする方法
cURL を使ったウェブスクレイピングの、そのまま使えるチェックリストはこちらです。
- 対象URLを特定する: 静的ページかAPIエンドポイントから始める。
- ページを取得する:
curl URL - 出力をファイルに保存する:
curl -o file.html URL - ヘッダーを確認/デバッグする:
curl -I URL,curl -v URL - POSTデータを送る:
curl -d "a=1&b=2" URL - Cookie/セッションを扱う:
curl -c cookies.txt ...,curl -b cookies.txt ... - カスタムヘッダー/User-Agentを設定する:
curl -A "..." -H "..." URL - リダイレクトに追従する:
curl -L URL - 必要ならプロキシを使う:
curl -x proxy:port URL - 複数ページのスクレイピングを自動化する: シェルループやスクリプトを使う。
- データを解析して構造化する: 必要に応じて追加のツールやスクリプトを使う。
- 構造化されたノーコードのスクレイピングや動的ページにはThunderbitへ切り替える。
結論と重要ポイント:最適なウェブスクレイピングツールの選び方
AIであらゆるWebサイトからデータをスクレイピング Get Started Free
cURL を使ったウェブスクレイピングは、2026年の今もテックユーザーにとって頼れるスキルです。とりわけ、手早いデータ取得、試作、自動化の場面で光ります。cURL の速さ、スクリプト化のしやすさ、そして普及率の高さは、どんな開発者の道具箱にも欠かせません。とはいえ、Web がより動的に、より防御を固めていき、ビジネスユーザーがコードなしで構造化データを求めるようになるにつれて、Thunderbit のようなツールが「できることの範囲」そのものを書き換えつつあります。
重要ポイント:
- 静的ページ、API、素早い試作には cURL を。とくに、すべてを自分の手で握りたいときに向いています。
- 構造化データが要るとき、動的/JavaScript 主体のページを扱うとき、ノーコードでビジネス向けのワークフローが欲しいときは、Thunderbit(や同種の AI ウェブスクレイパー)へ切り替えましょう。
- 小回りを最大化したいなら、両方を組み合わせて。cURL で試作し、Thunderbit で拡張・構造化する、という流れです。
- そして、いつでも責任あるスクレイピングを。サイトの規約、レート制限、法的な一線を尊重してください。
ウェブスクレイピングがどこまで手軽になり得るのか、気になりませんか? Thunderbitの無料Chrome拡張機能を試すことで、AI によるデータ抽出をその目で確かめてみてください。もっと掘り下げたい方は、Thunderbitブログで、さらに多くのチュートリアルやヒント、業界インサイトをご覧いただけます。こちらの記事もおすすめです。
スクレイピングを存分に楽しんでください。そしてあなたのデータが、いつでもきれいに整い、構造化され、コマンドひとつ(あるいはクリックひとつ)で手に入りますように。
スケーラブルなウェブスクレイピングのためのThunderbitプランを見る
よくある質問
1. cURLはJavaScriptでレンダリングされたWebページに対応できますか?
いいえ。cURL は JavaScript を実行できません。サーバーから返ってきた生の HTML を取得するだけです。ページの中身を描画したり、ボット対策のチャレンジを解いたりするのに JavaScript が必要な場合、cURL ではそのデータにたどり着けません。そうしたケースでは、Thunderbit のようなブラウザベースのツールを使ってください。
2. cURLの出力を直接ファイルに保存するにはどうすればよいですか?
-o フラグを使います:curl -o filename.html URL。これで、レスポンス本文がターミナルに表示される代わりに、ファイルへ書き込まれます。
3. ウェブスクレイピングにおけるcURLとThunderbitの違いは何ですか?
cURL は、生の Web データを取得するためのコマンドラインツールで、テックユーザーや自動化に向いています。Thunderbit は、どんなサイトからでも構造化データを抽出し、動的ページにも対応し、Excel や Google Sheets のようなツールへ直接エクスポートしたいビジネスユーザーのために設計された、AI 搭載の Chrome 拡張機能です。コードはいりません。
4. cURLでWebサイトをスクレイピングするのは合法ですか?
公開データのスクレイピングは、近年の判例に照らすと、米国では一般に合法とされています。ただし、サイトの利用規約、robots.txt、関連法規は必ず確認してください。個人データや保護対象のデータを許可なく取らないこと、そしてレート制限と倫理的なガイドラインを守ることも忘れずに(calawyers.org、polsinelli.com)。
5. cURLからThunderbitのような高度なツールに切り替えるべきタイミングはいつですか?
動的/JavaScript 主体のページをスクレイピングしたいとき、スプレッドシート用の構造化データが欲しいとき、あるいはノーコードのワークフローを好むときは、Thunderbit のほうが向いています。cURL は手早い技術作業に、Thunderbit はビジネス向けで再利用しやすいデータ抽出に、と使い分けるとよいでしょう。
ウェブスクレイピングのコツやチュートリアルをもっと知りたい方は、ThunderbitブログやYouTubeチャンネルをのぞいてみてください。
Thunderbit AIウェブスクレイパーを試す Get Started Free




