
正直に言うと、ビジネスデータを手に入れようとしたことがあるなら、「ウェブスクレイピング vs データマイニング」の議論にぶつかったことがあるはずです。あるチームはウェブ上のあらゆる情報をかき集めようとし、別のチームはそれを分析して深い洞察を得ようとする。ときには両者とも、スプレッドシートを前にして「で、結局何をしてるんだっけ?」と首をかしげることもあります。もし心当たりがあるなら、あなただけではありません。
SaaSや自動化ツールの開発に長年携わり、今はの共同創業者でもある私は、この混乱を営業現場から役員会議室まで、あらゆる場所で見てきました。そこで、専門用語はいったん脇に置いて、実務ベースで整理してみましょう。ウェブスクレイピングとデータマイニングの本当の違いは何か、誰がそれぞれを使っているのか、そして何より、どう組み合わせればチームの成果につなげられるのか。\n\n## ウェブスクレイピング vs データマイニング:忙しいチーム向けの簡単定義\n\nまずはシンプルに。技術辞書はいりません。\n\n- ウェブスクレイピング: サイトからデータを収集するプロセスです。ウェブ上の情報を自動でコピペしてスプレッドシートに移すようなものだと考えてください。ウェブスクレイパーはページを巡回し、商品価格や会社名、記事などの特定情報を抽出して、行と列のある構造化された形式に整理します。この段階では分析は行いません。必要な生データを手に入れることが目的です。\n- データマイニング: データがそろってから始まる、本当の価値が生まれる工程です。データマイニングとは、統計、アルゴリズム、AIを使ってデータセットを分析し、傾向やパターン、洞察を見つけ出すことを指します。巨大なスプレッドシートを手にして、その意味を読み解くようなものです。たとえば、顧客のセグメント分け、売上予測、不正検知などがこれに当たります。\n\n私がいつも使うたとえ:\n\nウェブスクレイピングは店で食材を集めること。データマイニングは、その食材を料理にすることです。夕食を単なる買い出しの山で終わらせたくないなら、両方が必要です。\n\n## 誰がウェブスクレイピングとデータマイニングを使うのか — そしてなぜか?\n\nここからが面白いところです。違いは単に「集めるか、分析するか」ではありません。誰が何をしているのか、そしてその理由にあります。\n\n### 誰がウェブスクレイピングを使うのか?\n\n典型的な利用者:\n\n- 営業チーム(リスト作成、連絡先情報の取得)\n- マーケティングチーム(市場インテリジェンス、競合監視)\n- オペレーション部門(価格追跡、サプライチェーンの把握)\n- リサーチチーム(不動産、金融など)\n\n目的:\n\n新鮮な外部データを、すばやく手に入れることです。何千件もの商品価格を取得する場合でも、LinkedInからリードをスクレイピングする場合でも、競合の新製品発表を監視する場合でも、こうした担当者は日々の意思決定に必要な最新情報を求めています(、)。\n\n### 誰がデータマイニングを使うのか?\n\n典型的な利用者:\n\n- データアナリスト、ビジネスインテリジェンス(BI)チーム\n- データサイエンティスト\n- プロダクトマネージャー、戦略チーム\n\n目的:\n\nデータに意味を見つけることです。これらの担当者は、ウェブから取得したものでも社内システムから取り出したものでも、生の情報を分析し、パターン、傾向、実行可能な洞察を探します。彼らはデータが「どう集められたか」よりも、「何を語っているか」に注目します()。\n\n### シナリオ表:誰が何をするのか?\n\n
| 役割 | ウェブスクレイピングの例 | データマイニングの例 |
|---|---|---|
| 営業 | 企業ディレクトリをスクレイピングしてリードを集める | どのリードが最も成約しやすいかを分析する |
| マーケティング | 競合の製品発表をスクレイピングする | 購買行動で顧客をセグメント化する |
| オペレーション | 仕入先価格を毎日スクレイピングする | 需要を予測し、在庫を最適化する |
| BI / データサイエンス | (通常は自分たちではスクレイピングしない) | 予測モデルを構築し、トレンドを見つける |
| プロダクト管理 | アプリストアのレビューをスクレイピングしてフィードバックを集める | 機能の不足を特定し、ロードマップの優先順位を決める |
ウェブスクレイピング:ウェブサイトをビジネス向けデータに変える
\nはっきり言って、インターネットはビジネスデータの宝庫です。ただし、その大半は、乱雑で非構造化なウェブページの中に埋もれています。ウェブスクレイピングは、そのデータを解放し、チームが実際に使える形へ変えるための鍵です。\n\n### なぜウェブスクレイピングが重要なのか(特に非技術チームにとって)\n\n- 時間を節約できる: インターンが何日もコピペする必要はもうありません。スクレイパーなら、何千ものデータポイントを数分で取得できます。\n- 拡張しやすい: 毎日50社の競合サイトを監視したい? スクレイピングなら可能です。\n- 最新情報を保てる: 価格、在庫、ニュースの最新情報を、手作業なしで入手できます。\n\n全体像としては、によると、ウェブスクレイピング市場は2026年に11.7億米ドル、2031年には22.3億米ドルに達すると見込まれています。さらに、そのレポートで引用されている2024年のBrowserCatの調査では、企業の65%がすでにAIや機械学習プロジェクトへの入力としてウェブスクレイピングを使っているとされます。つまり、IT部門の外にある営業・マーケティング・オペレーションへ導入が広がる、まさにその流れです。\n\n### 実践的なユースケース\n\n- リード獲得: 公開ディレクトリやSNSから、名前、メールアドレス、電話番号をスクレイピングする。\n- 価格モニタリング: 競合価格や商品の在庫状況をリアルタイムで追跡する。導入はすでに一般化しており、によると、米国小売業者の81%が動的な価格再設定のために自動価格スクレイピングを実施しています。2020年の34%から大きく増加しており、元データはActowiz Solutionsの調査です。\n\n- 市場調査: オンラインレビューを集約したり、SNSから感情分析をしたり、ニュースサイトを監視してトレンドを把握する。\n- データ拡充: 企業サイトやLinkedInの最新情報でCRMを強化する。\n- 不動産・金融: 物件一覧、金融ニュース、代替データをスクレイピングして投資調査に活用する()。\n\nさらに重要なのは、もうコーディングができる必要はないということです。Octoparse、Browse AI、Bardeen、Thunderbit といった新しいスクレイピングツールの多くは、ドラッグ&ドロップやクリック操作を標準機能として備えており、コーダー向けのオプションではありません。それだけで、スクレイピングはエンジニアのバックログから営業・オペレーションのデスクへ移ってきました。\n\n\n### Thunderbit がウェブスクレイピングを誰でも使いやすくする方法\n\nの開発を始めた頃、私たちの目標はシンプルでした。ウェブスクレイピングを、インターンにコピペを頼むくらい簡単にすること。ただしその「インターン」は、眠らず、文句も言わず、猫動画に気を取られることもないAIエージェントです。\n\nThunderbit は、データ収集とビジネス分析の間のギャップを次のように埋めます。\n\n- AIで項目を提案: 「AIで項目を提案」をクリックするだけで、Thunderbit のAIがページを解析し、抽出すべきデータ項目を提案し、列名まで出してくれます。HTMLやセレクタをいじる必要はありません。必要なものを選ぶだけです()。\n- サブページのスクレイピング: 商品詳細や求人説明のように、サブページからさらに情報が必要ですか? Thunderbit は自動でページをたどり、追加情報を取得してデータセットに追記できます。\n- 即時データエクスポート: Excel、Google Sheets、Airtable、Notion、またはCSV/JSONへワンクリックで出力できます。追加料金も面倒な手順もありません。データはすぐに使えます。\n- ノーコード、クリック操作: Thunderbit はブラウザ内で動きます。欲しい項目を選べば完了です。初めてのスクレイピングでも、数分で使い始められます。\n- AIによる高い耐性: サイトは常に変化しますが、Thunderbit のAIは多くのレイアウト変更に自動で適応します。保守の手間が減り、ストレスも減ります。\n- 定期スクレイピングとAIオートフィル: スケジュール実行を設定したり、フォーム入力やログインをAIに任せたりできます。Thunderbit はPDF、画像、メール、電話番号までワンクリックで扱えます。\n\n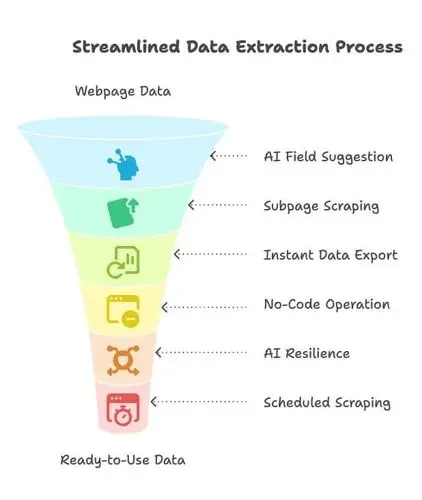 \n\n要するに、Thunderbit はスキルギャップを埋めてくれます。今では営業オペレーション、マーケティング、さらにはCEOでさえ、IT部門に頼まずにスクレイピングを設定できます。散らかったウェブデータと、実際に分析で使うツールをつなぐ「中間レイヤー」なのです。\n\n実際に見てみたいですか? をチェックするか、でさらに多くのユースケースをご覧ください。\n\n
\n## データマイニング:収集したデータから洞察を見つける\n\nさて、大量のデータをスクレイピングできました。次は何をするのでしょうか? ここでデータマイニングの出番です。\n\n### データマイニングとは何か(わかりやすく言うと)\n\nデータマイニングとは、大規模なデータセットを分析して、ビジネスの示唆につながる隠れたパターン、相関、異常値を見つけることです。生の数字を実行可能な知識に変える作業であり、たとえば「商品Aを買う顧客は商品Bも買う傾向がある」とか、「特定の行動が解約リスクの高さを示している」といった発見がそれに当たります。\n\n### よくあるビジネス目標\n\n- トレンドの発見と予測: 売上トレンド、季節性、市場の変化を見つけ、次に何が起こるかを予測する。\n- 顧客セグメンテーション: 行動や属性ごとに顧客をグループ化し、ターゲットマーケティングに活かす。\n- 異常検知: 不正、リスク、新しい機会を示す可能性のある外れ値を見つける。\n- 戦略的インサイト: 複数のデータセット(社内データ+スクレイピングデータ)を組み合わせ、新市場への参入や価格調整などの大きな意思決定を支える。\n\nここで注意したいのは、データマイニングの質は入力データの質に完全に左右されるということです。「ゴミを入れればゴミが出る」は、本当にその通りです。実際、アナリストはを、実際に分析する前のデータ整形と前処理に費やすこともあります。\n\nだからこそ、Thunderbit のような構造化されたウェブスクレイピングが価値を持つのです。分析しやすいきれいなデータセットをすぐに得られるので、アナリストは本題にすぐ取りかかれます。\n\n## ウェブスクレイピング vs データマイニング:並べて比較\n\n2つを正面から比べて、どこが違い、どこが重なるのかを見てみましょう。\n\n
\n\n要するに、Thunderbit はスキルギャップを埋めてくれます。今では営業オペレーション、マーケティング、さらにはCEOでさえ、IT部門に頼まずにスクレイピングを設定できます。散らかったウェブデータと、実際に分析で使うツールをつなぐ「中間レイヤー」なのです。\n\n実際に見てみたいですか? をチェックするか、でさらに多くのユースケースをご覧ください。\n\n
\n## データマイニング:収集したデータから洞察を見つける\n\nさて、大量のデータをスクレイピングできました。次は何をするのでしょうか? ここでデータマイニングの出番です。\n\n### データマイニングとは何か(わかりやすく言うと)\n\nデータマイニングとは、大規模なデータセットを分析して、ビジネスの示唆につながる隠れたパターン、相関、異常値を見つけることです。生の数字を実行可能な知識に変える作業であり、たとえば「商品Aを買う顧客は商品Bも買う傾向がある」とか、「特定の行動が解約リスクの高さを示している」といった発見がそれに当たります。\n\n### よくあるビジネス目標\n\n- トレンドの発見と予測: 売上トレンド、季節性、市場の変化を見つけ、次に何が起こるかを予測する。\n- 顧客セグメンテーション: 行動や属性ごとに顧客をグループ化し、ターゲットマーケティングに活かす。\n- 異常検知: 不正、リスク、新しい機会を示す可能性のある外れ値を見つける。\n- 戦略的インサイト: 複数のデータセット(社内データ+スクレイピングデータ)を組み合わせ、新市場への参入や価格調整などの大きな意思決定を支える。\n\nここで注意したいのは、データマイニングの質は入力データの質に完全に左右されるということです。「ゴミを入れればゴミが出る」は、本当にその通りです。実際、アナリストはを、実際に分析する前のデータ整形と前処理に費やすこともあります。\n\nだからこそ、Thunderbit のような構造化されたウェブスクレイピングが価値を持つのです。分析しやすいきれいなデータセットをすぐに得られるので、アナリストは本題にすぐ取りかかれます。\n\n## ウェブスクレイピング vs データマイニング:並べて比較\n\n2つを正面から比べて、どこが違い、どこが重なるのかを見てみましょう。\n\n
| 観点 | ウェブスクレイピング | データマイニング |
|---|---|---|
| 主な目的 | ウェブサイトから生データを収集する(データ抽出) | データセットを分析してパターンや洞察を見つける(データ分析) |
| 典型的な利用者 | 営業、マーケティング、オペレーション、リサーチ(非技術者やドメイン専門家が多い) | データアナリスト、BIチーム、データサイエンティスト、戦略担当(分析・技術職) |
| データソース | ウェブページ、オンラインソース、公開ディレクトリ、API | 構造化データセット:スクレイピングデータ、社内DB、CSV、データウェアハウス |
| プロセスとツール | クロール、抽出(Thunderbit のようなノーコードツール、ブラウザ拡張機能) | データ分析(BIツール、Python/R、SQL、機械学習プラットフォーム) |
| 出力 | 構造化データセット(CSV、スプレッドシート、データベース表) | 洞察、レポート、ダッシュボード、予測モデル |
| 代表的なユースケース | 競合価格の収集、SNSメンションの取得、掲載情報の抽出 | 顧客のセグメント化、解約予測、リードスコアリング |
| 主な課題 | サイト変更、スクレイピング対策、データ品質、法務・倫理面 | 汚れた/不完全なデータ、適切なモデル選定、プライバシー、結果の解釈 |
robots.txt を尊重し、サイトに過負荷をかけないようにし、必要ならプロキシの使用も検討してください()。\n\n### 3. 法務・倫理面の懸念\n\n- 問題: 公開データのスクレイピングは一般に合法ですが、プライバシー法や利用規約は重要です。\n- 解決策: いつもサイトの規約を確認し、公開データに絞り、可能な限り匿名化し、GDPR/CCPAを順守しましょう。どんなデータセットよりも、あなたの評判のほうが大切です()。\n\n### 4. データを実行可能な洞察に変える\n\n- 問題: データは集めたのに、意思決定に結びつけるのが難しい。\n- 解決策: 明確なビジネス質問から始め、可視化を使い、結果の解釈にドメイン専門家を巻き込みましょう。洞察を業務フローに組み込みます(たとえば、CRMで離脱リスクのある顧客にフラグを付ける)。\n\n### 5. ツールとスキルのギャップ\n\n- 問題: すべてのチームにコーダーやデータサイエンティストがいるわけではありません。\n- 解決策: Thunderbit のような使いやすいノーコードツールでスクレイピングし、最新のBIプラットフォームでマイニングを行いましょう。基本的なデータリテラシー研修にも投資してください。ときにはピボットテーブルだけで十分です。\n\n## 正しいアプローチの選び方:ウェブスクレイピング、データマイニング、それとも両方?\n\nでは、どうやって必要なものを見極めればよいのでしょうか。簡単な判断ガイドを示します。\n\n1. 必要なデータはもうありますか?\n - いいえ: まずはウェブスクレイピングで収集します。\n - はい: データマイニングで洞察を抽出します。\n2. 質問は外部世界についてですか、それとも内部のパターンについてですか?\n - 外部(競合、市場、リード): ウェブスクレイピング。\n - 内部(顧客行動、売上トレンド): データマイニング。\n3. 両方必要ですか?\n - 実務では多くの場合、答えは「はい」です。外部データをスクレイピングし、そこに社内データも加えてマイニングすれば、全体像が見えます。\n4. チームの能力はどうですか?\n - コーディングスキルがない? Thunderbit のようなノーコードのスクレイピングツールを使いましょう。\n - データサイエンティストがいない? 使いやすいBIツールを使うか、基本的な分析から始めましょう。\n5. 時間的な緊急性はありますか?\n - リアルタイムが必要? 継続的なスクレイピングと分析を設定します。\n - 単発プロジェクト? 一度だけスクレイピングしてマイニングしましょう。\n\nチェックリスト:\n\n- 「必要なデータは社内にすべてありますか?」 もし違うなら、スクレイピングしましょう。\n- 「持っているデータを理解できていますか?」 もし違うなら、マイニングしましょう。\n- 「この課題は、複数の手法を組み合わせる価値がありますか?」 もしそうなら、両方やりましょう。\n- 「チームに必要なスキルはありますか?」 もしなければ、ノーコードツールを使うか、助けを借りましょう。\n\nそして、すべてを一度にやる必要はないことも覚えておいてください。小さく始め、試験運用を行い、結果を見ながら広げていけば十分です。\n\n