
2025年、ウェブ上のデータは「あると便利」なものから、ビジネス戦略のど真ん中に位置づけられるようになりました。大手EC企業がライバルの価格をリアルタイムで追いかけたり、営業チームが新しいリードを自動で集めたりと、企業は公開ウェブデータを“デジタルオイル”のようにフル活用しています。実際、し、しています。Pythonが話題になりがちですが、です。特に信頼性やシステム連携が求められるエンタープライズ領域では、Javaは外せません。
 SaaSや自動化の現場で長年やってきた自分も、Javaによるウェブスクレイピングが業務効率を劇的に変える瞬間を何度も見てきました。でも、低レベルなコードに苦戦したり、動的なウェブサイトやボット対策で悩むチームも多いのが現実。そこで今回は、2025年の最新事情を踏まえたJavaウェブスクレイピングの実践ガイドをお届けします。コードとAI搭載の最新ツールの活用法も交えて、開発者はもちろん、ノンエンジニアの人にも役立つ内容です。
SaaSや自動化の現場で長年やってきた自分も、Javaによるウェブスクレイピングが業務効率を劇的に変える瞬間を何度も見てきました。でも、低レベルなコードに苦戦したり、動的なウェブサイトやボット対策で悩むチームも多いのが現実。そこで今回は、2025年の最新事情を踏まえたJavaウェブスクレイピングの実践ガイドをお届けします。コードとAI搭載の最新ツールの活用法も交えて、開発者はもちろん、ノンエンジニアの人にも役立つ内容です。
Javaウェブスクレイピングとは?ノンエンジニアにもわかりやすく
難しい話は抜きにして、JavaウェブスクレイピングはJavaのプログラムを使ってウェブサイトから自動で情報を集める技術です。イメージは、超高速のバーチャルアシスタントが何千ページも一気に読み込んで、必要なデータだけをきれいにスプレッドシートにまとめてくれる感じ。このアシスタントは疲れ知らず、ミスもなく、ネットのスピードで働きます。
仕組みはとてもシンプル:
- ウェブサイトにリクエストを送る(ブラウザでページを開くのと同じ)
- HTMLデータを取得(ページの元になるコード)
- HTMLを解析して、プログラムが扱いやすい形に変換
- 必要な情報を抽出(例:商品名、価格、メールアドレスなど)
- データを保存(CSV、Excel、データベース、Googleスプレッドシートなど)
プログラミングのプロじゃなくても、適切なツールとちょっとしたコツがあれば、誰でもウェブデータの自動収集ができます。ごちゃごちゃしたウェブページも、すぐに使えるデータに変身!
2025年、なぜJavaウェブスクレイピングがビジネスに欠かせないのか
ウェブスクレイピングは、もはや技術者だけの趣味じゃありません。今やビジネスの競争力を左右する必須スキル。Javaウェブスクレイピングが企業にもたらす価値と、そのROI(投資対効果)を見てみましょう。
| ウェブスクレイピング活用例 | ビジネス効果(ROI) | 主な業界 |
|---|---|---|
| 競合価格モニタリング | 市場変動に即応し、20%以上の売上増加を実現 | EC、小売 |
| リード獲得・営業リサーチ | 見込み客リストを自動生成、70%の工数削減 | B2B営業、マーケティング、人材採用 |
| 市場調査・トレンド分析 | トレンドの早期発見、5〜15%の売上増・10〜20%のマーケROI向上 | 消費財、広告代理店 |
| 金融・投資データ | 取引用オルタナティブデータ、ウェブ抽出データ市場は50億ドル超 | 金融、ヘッジファンド、フィンテック |
| 業務自動化・モニタリング | 定型データ収集を自動化、73%のコスト削減・85%の導入スピード向上 | 不動産、サプライチェーン、行政 |
()
Javaが選ばれる理由は、スケーラビリティ・信頼性・システム連携力が抜群だから。多くの企業システムがJavaで作られているので、ウェブスクレイパーの組み込みもスムーズ。さらに、Javaのマルチスレッドやエラー処理は、大量ページの高速処理や安定運用にピッタリです。
Javaウェブスクレイピングの仕組みと強み
Javaウェブスクレイパーの基本構成を分解してみましょう:
- HTTPリクエスト:JSoupやApache HttpClientなどのライブラリでページを取得。ヘッダー設定やプロキシ利用、ブラウザのふりもOK。
- HTML解析:JSoupなどでHTMLを「DOM」構造に変換し、CSSセレクタで欲しいデータを抽出。
- データ抽出:たとえば「
<span class='price'>要素を全部取得」など、ルールを決めて情報を抜き出す。 - データ保存:CSV、Excel、JSON、データベースなどに出力。
Javaがウェブスクレイピングで強い理由
- マルチスレッド:複数ページを同時並行で処理でき、大規模クロールも高速化。PythonのGILみたいな制約もなし。
- 高パフォーマンス:コンパイル型言語なので、大量データやメモリ負荷の高い処理も得意。
- エンタープライズ連携:CRMやERP、DBなど既存システムとの統合が簡単。
- 堅牢なエラー処理:型安全性や例外処理で、長期運用にも耐える安定性。
ミッションクリティカルなデータ基盤には、Javaの安定性と拡張性が大きな武器になります。
Javaウェブスクレイピングの主要ライブラリ・フレームワーク
Javaでウェブスクレイピングをやるなら、特におすすめなのがJSoup、HtmlUnit、Seleniumの3つ。それぞれの特徴を比較します:
| ライブラリ | JavaScript対応 | 使いやすさ | パフォーマンス | 得意な用途 |
|---|---|---|---|---|
| JSoup | ❌(非対応) | 非常に簡単 | 高速 | 静的ページ、軽量なタスク、素早い処理 |
| HtmlUnit | ⚠️ 一部対応 | 普通 | 中程度 | 簡単なJS、フォーム送信、ヘッドレススクレイピング |
| Selenium | ✅(完全対応) | 普通〜やや難しい | 低速(1ページごと) | JS主体のサイト、動的・インタラクティブなページ |
()
JSoup:静的HTML解析の定番
は、ほとんどのスクレイピング案件で最初に検討したい軽量ライブラリ。静的ページのデータ抽出に最適で、使い方も直感的です。
例:
1Document doc = Jsoup.connect("https://www.scrapingcourse.com/ecommerce/").get();
2String bannerTitle = doc.select("div.site-title").text();
3System.out.println("Banner: " + bannerTitle);ブログ記事や商品リスト、ディレクトリなど、JavaScriptを使わないページならJSoupがベスト。
HtmlUnit:ブラウザ動作を再現したいときに
はJava製のヘッドレスブラウザ。ある程度のJavaScript実行やフォーム送信、ボタン操作も可能。
こんな時におすすめ: ログインが必要なサイトや、簡単な動的コンテンツの取得に。Seleniumほど重くないのでサクッと使えます。
例:
1WebClient webClient = new WebClient();
2HtmlPage page = webClient.getPage("https://example.com/login");
3// ... フォーム入力・送信 ...Selenium:JS主体・動的ページの最強ツール
は実際のブラウザ(ChromeやFirefox)を操作できるので、人間が見れるあらゆるサイトに対応。
こんな時におすすめ: モダンなWebアプリ、無限スクロール、クリックや待機などユーザー操作が必要な場合。
例:
1WebDriver driver = new ChromeDriver();
2driver.get("https://www.scrapingcourse.com/ecommerce/");
3List<WebElement> products = driver.findElements(By.cssSelector("li.product"));
4// ... データ抽出 ...
5driver.quit();ThunderbitでJavaウェブスクレイピングを加速:ビジュアル自動化×コードの融合
ここからが本番。特に「コードばかり書きたくない」「ノンエンジニアでも使いたい」人におすすめなのが、AI搭載・ノーコード型のウェブスクレイパーです。ブラウザ上で直感的に抽出項目を指定し、ExcelやGoogleスプレッドシート、Airtable、Notionへワンクリックでデータ出力できます。
JavaとThunderbitを組み合わせるメリット
- AIによる項目自動抽出:Thunderbitの「AIサジェスト」で、HTMLやセレクタを意識せずに必要なデータを自動判別。
- サブページ自動巡回:商品詳細ページなど、リンク先も自動でクロールしデータを拡充。
- 即使えるテンプレート:Amazon、Zillow、LinkedInなど人気サイトはテンプレート一発設定。
- 簡単エクスポート:抽出後は数秒でデータ出力。Javaコードでの後処理や分析もスムーズ。
Thunderbitは、プロトタイピングや複雑なサイト対応、ノンエンジニアの現場活用に最適。開発者にとっても、面倒な部分をThunderbitに任せて、ビジネスロジックに集中できます。
Thunderbit×Javaのハイブリッド活用例
自分がよくやるワークフローはこんな感じ:
- Thunderbitでプロトタイプ作成:Chrome拡張でビジュアルにスクレイピング設定。AIで項目抽出、ページネーションも自動化、GoogleスプレッドシートやCSVに出力。
- Javaでデータ処理:SheetsやCSV、AirtableからJavaでデータを読み込み、分析やシステム連携を実施。
- 自動化・定期実行:Thunderbitのスケジューラーでデータを常に最新化し、Javaパイプラインで自動取得。
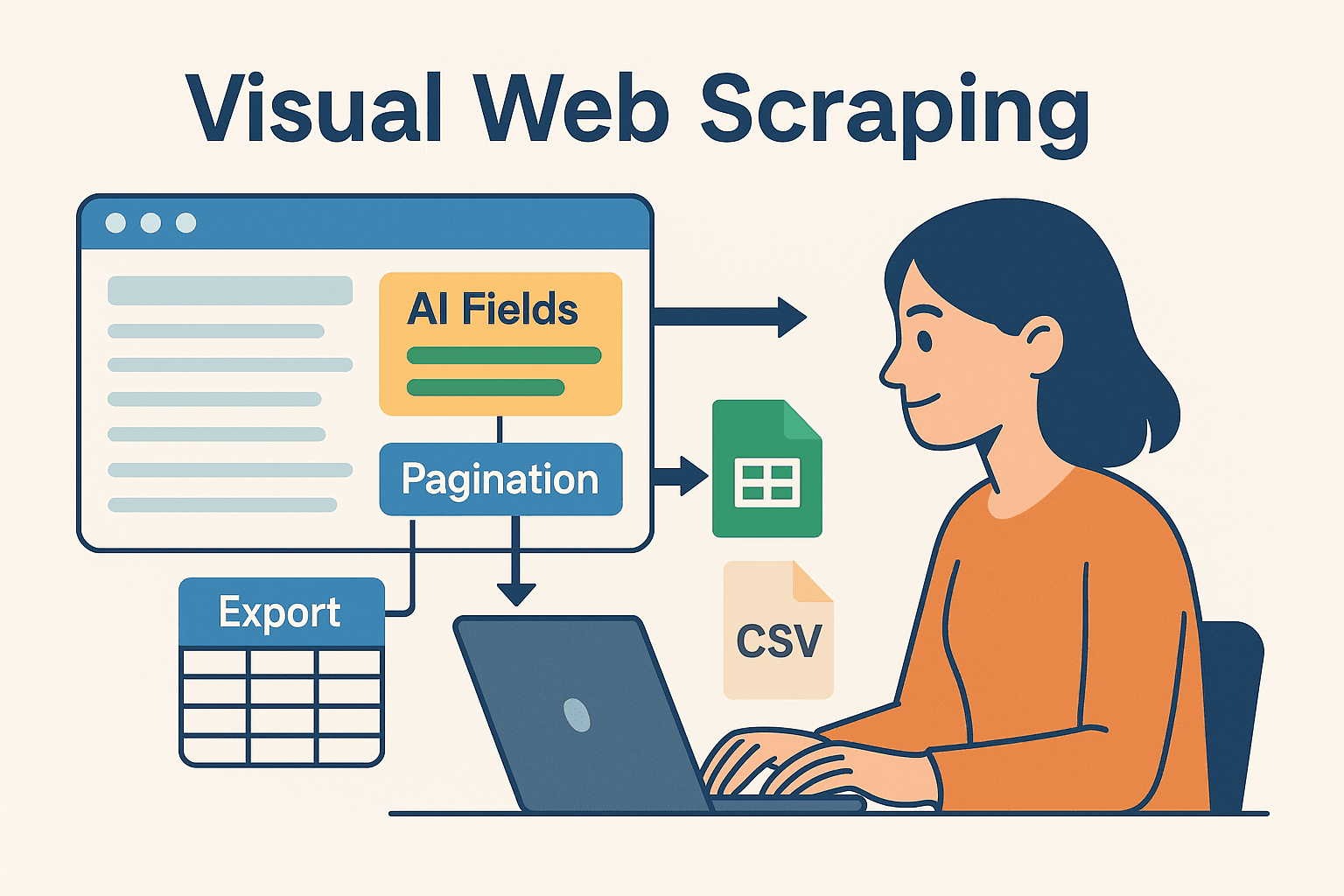 このハイブリッド手法なら、AIノーコードの柔軟性とJavaの強力な処理能力を両立できます。
このハイブリッド手法なら、AIノーコードの柔軟性とJavaの強力な処理能力を両立できます。
実践編:Javaウェブスクレイパーをゼロから作る手順
実際に手を動かしてみましょう。ここでは、Javaでシンプルなウェブスクレイパーを作る流れを紹介します。
Java環境のセットアップ
- Java(JDK)をインストール:Java 17または21推奨。
- Mavenを導入:依存ライブラリ管理に便利。
- IDEを選択:IntelliJ IDEA、Eclipse、VSCodeなど。
- pom.xmlにJSoupを追加:
1<dependency> 2 <groupId>org.jsoup</groupId> 3 <artifactId>jsoup</artifactId> 4 <version>1.16.1</version> 5</dependency>
スクレイパーの作成と実行
デモ用ECサイトから商品名と価格を抽出してみます。
1import org.jsoup.Jsoup;
2import org.jsoup.nodes.Document;
3import org.jsoup.select.Elements;
4import org.jsoup.nodes.Element;
5public class ProductScraper {
6 public static void main(String[] args) {
7 String url = "https://www.scrapingcourse.com/ecommerce/";
8 try {
9 Document doc = Jsoup.connect(url)
10 .userAgent("Mozilla/5.0")
11 .get();
12 Elements productElements = doc.select("li.product");
13 for (Element productEl : productElements) {
14 String name = productEl.selectFirst("h2").text();
15 String price = productEl.selectFirst("span.price").text();
16 System.out.println(name + " -> " + price);
17 }
18 } catch (Exception e) {
19 e.printStackTrace();
20 }
21 }
22}ポイント:User-Agentは必ず設定しよう。デフォルトのJava User-Agentはブロックされることが多いです。
データのエクスポートと活用
- CSV出力:FileWriterやOpenCSVライブラリでCSVファイルに保存。
- Excel出力:Apache POIで.xls/.xlsx形式に対応。
- DB連携:JDBCでデータベースへ直接挿入。
- Googleスプレッドシート:Thunderbitでエクスポートし、JavaのGoogle Sheets APIで読み込み。
Javaウェブスクレイピングでよくある課題と対策
スクレイピングにはトラブルもつきもの。代表的な課題とその解決策をまとめます:
- IPブロック・リミット:リクエスト間隔を調整(Thread.sleep)、プロキシをローテーション、遅延をランダム化。大量処理はプロキシサービス活用。
- CAPTCHA・ボット検知:Seleniumで人間の操作を再現、またはアンチボットAPIを利用。Thunderbitのクラウドスクレイピングも有効な場合あり。
- 動的コンテンツ:JSoupでデータが取れない場合は、JavaScriptで生成されている可能性。SeleniumやHtmlUnit、またはAPIを直接利用。
- サイト構造の変化:柔軟なセレクタ設計と、スクレイパーの監視・メンテナンスが重要。ThunderbitのAIサジェストならレイアウト変更にも即対応。
- セッション管理:ログインが必要な場合はCookieやセッション管理に注意。SeleniumやThunderbit(Chromeログイン時)は認証ページも対応可能。
Javaウェブスクレイピング効率化の上級テクニック
さらに効率を高めたい人向けに、プロの技を紹介します:
- マルチスレッド:JavaのExecutorServiceで複数ページを並列処理。ただし過剰なリクエストはブロックの原因になるので注意。
- スケジューリング:JavaのQuartz Schedulerや、Thunderbitのクラウドスケジューラー(自然言語で「毎週月曜9時」など)を活用。
- クラウド分散:大規模案件はクラウド上でヘッドレスブラウザを動かしたり、複数マシンで分散処理。
- ハイブリッド運用:Thunderbitで難易度の高いサイトを担当し、Javaコードで他の部分を処理。データウェアハウスで統合。
- 監視・ログ:Javaのロギングフレームワークでスクレイパーの稼働状況を監視し、異常時はアラート通知。
まとめ・重要ポイント
ウェブデータは現代ビジネスの“金脈”。Javaは今も信頼性・拡張性・連携力でトップクラスの選択肢です。基本の流れは「取得→解析→抽出→出力」。JSoup、HtmlUnit、Seleniumを使い分ければ、静的ページから複雑なJavaScriptサイトまで幅広く対応できます。
全部手作業でやる必要はありません。のようなAI・ビジュアル自動化ツールを組み合わせれば、プロトタイピングや保守も圧倒的に効率化。コードとノーコードの“いいとこ取り”が、これからの主流です。まずはThunderbitでサクッとセットアップし、Javaで本格運用するのがおすすめ。
Thunderbitの実力を体感したい人は、して、数分でスクレイピングを始めてみてください。さらに詳しいノウハウや最新情報はで随時公開中です。
データがいつも新鮮で、構造化されて、すぐに使える状態でありますように!
よくある質問(FAQ)
1. 2025年でもJavaはウェブスクレイピングで有効?
もちろん。Pythonは手軽なスクリプト向きだけど、Javaは大規模・長期運用・システム連携・マルチスレッド処理で今も主力です。
2. JSoup、HtmlUnit、Seleniumはどう使い分ける?
静的ページはJSoup、簡単な動的コンテンツやフォーム送信はHtmlUnit、JavaScript主体やインタラクティブなサイトはSeleniumが最適。サイトの特性に合わせて選ぼう。
3. スクレイピングでブロックされないコツは?
リクエスト間隔を調整、プロキシを活用、User-Agentを現実的に設定、人間らしい挙動を再現。難易度が高い場合はThunderbitのクラウドスクレイピングやアンチボットAPIも検討を。
4. ThunderbitとJavaは連携できる?
できる。Thunderbitでビジュアルに抽出・スケジューリングし、データをエクスポート。Javaで後処理やシステム連携も自在。ビジネスユーザーと開発者、両方におすすめの組み合わせ。
5. Javaウェブスクレイピングを最速で始めるには?
JavaとMavenをセットアップし、JSoupを追加してシンプルなサイトで練習しよう。より複雑な案件やプロトタイピングにはを使い、AIに抽出を任せてJavaで活用するのが効率的。
さらにノウハウやサンプルコード、自動化テクニックを知りたい人は、やもぜひチェックしてみてください。 関連リンク