

こんな光景を思い浮かべてみてください。ウェブサイトを立ち上げ、やる気満々の顧客が集まってくるのを待っていたら、実際に流れてきたトラフィックの半分が……ロボットだった。SF映画の話ではありません。検索エンジンやAIボット、解析用のクローラーといったデジタルの巡回者たちが、昼も夜も休まずサイトを歩き回り、姿の見えない来訪者の行列のように動き続けているのです。2026年のいま、これはサーバーログに紛れ込んだちょっとした珍事ではなく、ごく当たり前の日常になりました。誰が、あるいは何がサイトをクロールしているのか、どれくらいの頻度で、何のために訪れているのか——それを把握することは、オンラインで事業を営むうえでの土台になっています。
SaaS、自動化、AIの世界で長く手を動かしてきた身として言えるのは、ウェブクロールが裏方の技術的な細部から、経営の最前線に立つ課題へと様変わりしたということです。数字はなかなか衝撃的で、いまやボットがインターネットトラフィック全体のほぼ半分を占め、地域によっては人間を追い越しています。AI駆動のクローラーが大規模言語モデルの学習用にコンテンツを吸い上げる時代になり、インフラ、予算、ブランドへの影響は、これまでにない大きさになっています。それでは、最新のウェブクロール統計と業界ベンチマーク、そしてそれが2026年のビジネスにとって何を意味するのかを、順に見ていきましょう。
2026年のウェブクロール:全体像のスナップショット
AIであらゆるウェブサイトからデータを抽出 Get Started Free
ウェブクロールは、規模の面でも複雑さの面でも、まったく新しい段階に踏み込みました。毎日、数十億件もの自動リクエストが、増え続けるクローラーの群れによってインターネット上を行き交っています。かつての主役はGooglebotやBingbotのような検索エンジンのボットで、ユーザーが検索結果からページにたどり着けるようインデックスを作っていました。しかし今では、AIデータクローラー、SNSスクレイパー、解析ボットといった新しい世代がそこに加わっています。
まず、目を引く数字があります。ただし、どの指標を選ぶかで見える景色は変わります。CloudflareのYear in Review 2025によれば、2025年12月上旬の時点で、同社ネットワーク上のHTMLリクエストの**約53%をボットとAIクローラーが占め、人間によるトラフィックは47%**まで落ち込んでいました。Impervaも、自社の企業顧客ベースを対象としたBad Bot Report 2026(2026年4月29日公開)で、2025年通年の結果として同じ結論を導いています。ボット53%、人間47%で、前年の51/49からボットの比率が高まりました。観測する立ち位置が違っても、行き着く答えは同じです。自動化トラフィックは、もはやウェブの“過半数”を握っているのです。新しいのは量だけではありません。顔ぶれそのものが入れ替わっています。以前はボット欄を検索インデクサーが牛耳っていましたが、2026年にはAI学習用クローラーが増え、チャットボットや回答エンジン向けにデータを集める割合がぐんと上がりました。
その内訳は、かつてないほど多彩です。
- 良質なボット:検索インデクサー、稼働監視ボット、正規のデータスクレイパー。
- 悪質なボット:スパム、ハッキング、不正なスクレイピング。
- AIクローラー:AIの学習やリアルタイム回答のためにコンテンツを集める新顔。
AIクローラーは、検索エンジン系のボットとは振る舞いが異なる場合が少なくありません。キーワードをインデックスするだけでなく、意味を読み解くためにページ全体を取り込むこともあり、しかもその頻度が高い。数日のうちに数百万件ものリクエストを投げ込むことすらあります。こうしてウェブクロールはいまや遍在し、拡大し、細分化しているわけです。従来のインデックス作成と、AIの飽くなきデータ需要が、混然と入り混じっています。
すべてのビジネスが知っておくべきウェブクロールの主要統計
2026年のウェブをかたちづくっている数字を見ていきましょう。これらの統計は雑学の類ではありません。インフラ、コンテンツ戦略、そして収益に直結するベンチマークです。
ボット vs. 人間:トラフィック争いを制するのは?
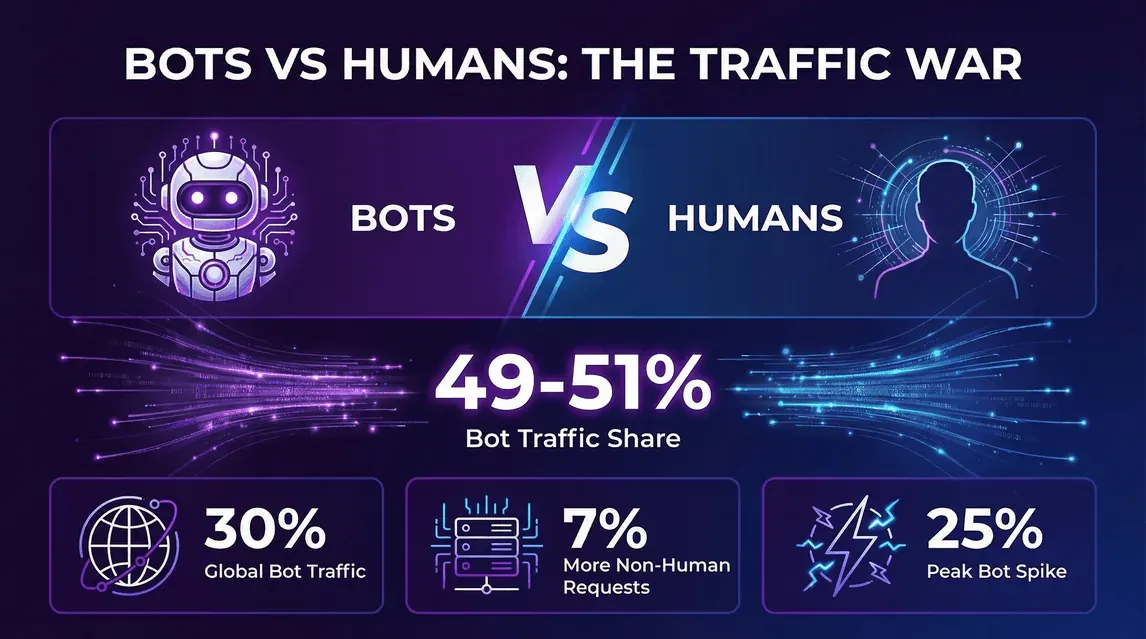
- ImpervaのBad Bot Report 2026(2026年4月):2025年の自動トラフィックはウェブ全体の**53%に達し、2024年の51%から上昇。人間のトラフィックは49%から47%**へ低下しました。
- CloudflareのYear in Review 2025:2025年12月2日時点で、Cloudflareネットワーク上のHTMLリクエストのうち**47%**が人間、**44%が非AIボット、残りの約9%**がAIボットとGooglebotの合計でした。
- この動きは、ひと四半期だけのブレではありません。Impervaのデータでは2019年以降、毎年ボット比率が上がり続けており、2024年から2025年の伸びを牽引したのは、いつものスクレイピングや認証情報の総当たりではなく、主にAI学習用クローラーでした。
- サイト運営者にとっての意味:分析でボットを除外していなければ、純粋なリクエスト数のおよそ半分は人間ではないということになります。ボットを切り分けずに生ログだけでインフラを見積もれば過大になりますし、逆にボット対応力を甘く見積もると、そのしわ寄せは実在の人間ユーザーに向かいます。
AIクローラーの急増
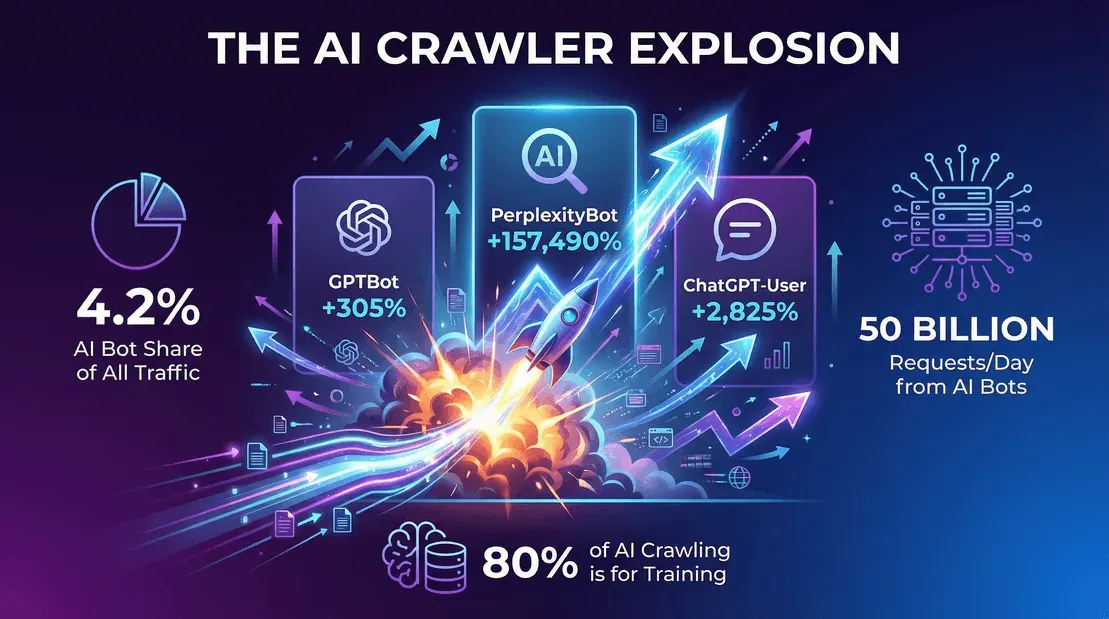
- AIボットのトラフィック比率は、いまも上昇を続けています。 CloudflareのYear in Review 2025によると、Googlebotを除くAIボットは2025年後半にHTMLリクエストの**約4.2%を占め、Googlebot単体でもさらに4.5%**ありました。3年前には存在すらしなかったカテゴリが、いまやGooglebotに肩を並べる規模に育っています。
- OpenAIのGPTBotは、2025年5月のクローラーリクエストの7.7%から、2025年後半には**ユニークページ要求の3.6%**へと変わりました(Cloudflare YIR 2025)。比率が小さく見えるのは、Cloudflareが分母をユニークページに変えたことと、市場にボットが増えたことが理由です。生の量で見れば、GPTBotはいまも公開ウェブ上のAIクローラー上位3位に入ります。
- AnthropicのClaudeBotは、Meta-ExternalAgentと並んで2025年後半には**ユニークページ要求の約2.4%**を占めました。ClaudeBotの相対シェアは前年比で下がったものの(Cloudflareの2024年5月〜2025年5月の期間では46%減少)、Anthropicが再学習を進めたことで盛り返しました。
- PerplexityBotは絶対値ではまだ小さく、2025年後半の**ユニークページ要求は約0.06%**にとどまりますが、主要AIボットの中では最も急な成長曲線を描いています。
- Googlebotは、いまも公開ウェブ最大の単独クローラーです。CloudflareのYear in Reviewでは、PerplexityBotのユニークページ量のおよそ200倍とされています。
文脈の中で見るクローラートラフィック
2025年後半のRedditスレッドに、生々しい実例があります。ある開発者が30日分のサーバーログを集計したものです。
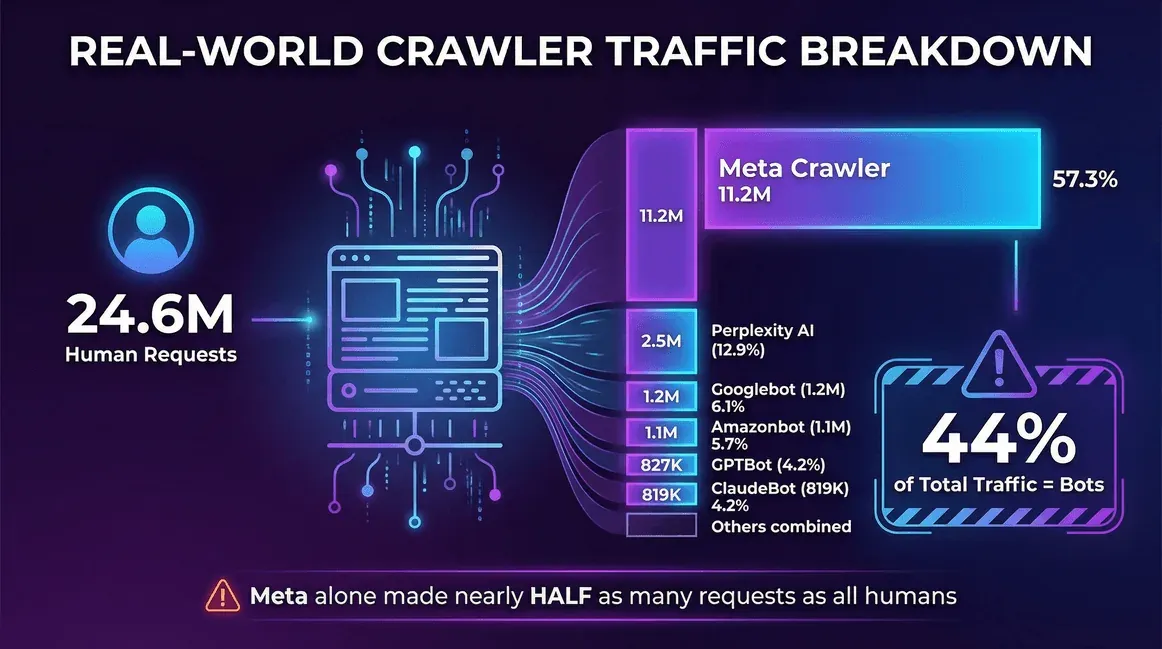
| トラフィックソース | リクエスト数(月間) | クローラーに占める割合 |
|---|---|---|
| 実ユーザー(人間) | 24,647,904 | -- |
| Meta Crawler(Facebook) | 11,175,701 | 57.3% |
| Perplexity AI | 2,512,747 | 12.9% |
| Googlebot | 1,180,737 | 6.1% |
| Amazonbot | 1,120,382 | 5.7% |
| OpenAI GPTBot | 827,204 | 4.2% |
| ClaudeBot(Anthropic) | 819,256 | 4.2% |
| Bingbot | 599,752 | 3.1% |
| ChatGPT-User(OpenAI) | 557,511 | 2.9% |
| Ahrefs Crawler | 449,161 | 2.3% |
| ByteDance Spider | 267,393 | 1.4% |
このサイトでは、ボットが**全トラフィックの44%**を占めており、Metaのクローラーだけで、実ユーザー全体のおよそ半分に匹敵するリクエストを送り込んでいました。
全体像
- クローラートラフィック(検索+AIボット)は、対象サイト群で2024年5月から2025年5月の間に18%増加しました (blog.cloudflare.com)。
- LLM学習用ボットは、主要CDNの一部で「ボット」トラフィック全体のほぼ80%を占めました (webscraft.org)。
- Cloudflareのネットワークでは、2025年後半時点でAIボットだけで1日あたり約500億件のクローラーリクエストが発生していました (webscraft.org)。
AIクローラーの台頭:AIがウェブクロールをどう変えているか
ここで、誰もが気づいていながら口に出しにくい主役、AIクローラーの話に踏み込みましょう。これらのボットは、検索用にサイトをインデックスするだけにとどまりません。大規模言語モデルの学習や、AIによる即時回答の提供のために、コンテンツをむしゃむしゃと平らげていきます。その規模たるや、どんなに野心的な検索エンジンでも顔負けするほどです。
AIクローラーブームを押し上げるものは?
- データを大量に欲しがるAIモデル:いまどきのLLMには、膨大で多様なデータセットが欠かせません。ウェブは彼らにとって食べ放題のビュッフェで、あなたのコンテンツはそのメニューの一品です。
- 学習 vs. リアルタイム回答:AIボットのクロールの約80%は学習目的であり、その場の検索に答えるためだけではありません。
- 新しいクロールパターン:AIボットは一気にまとめてアクセスしてくることがあり、とくにモデルの再学習や更新のタイミングでは、数日で数百万ページをクロールすることもあります。
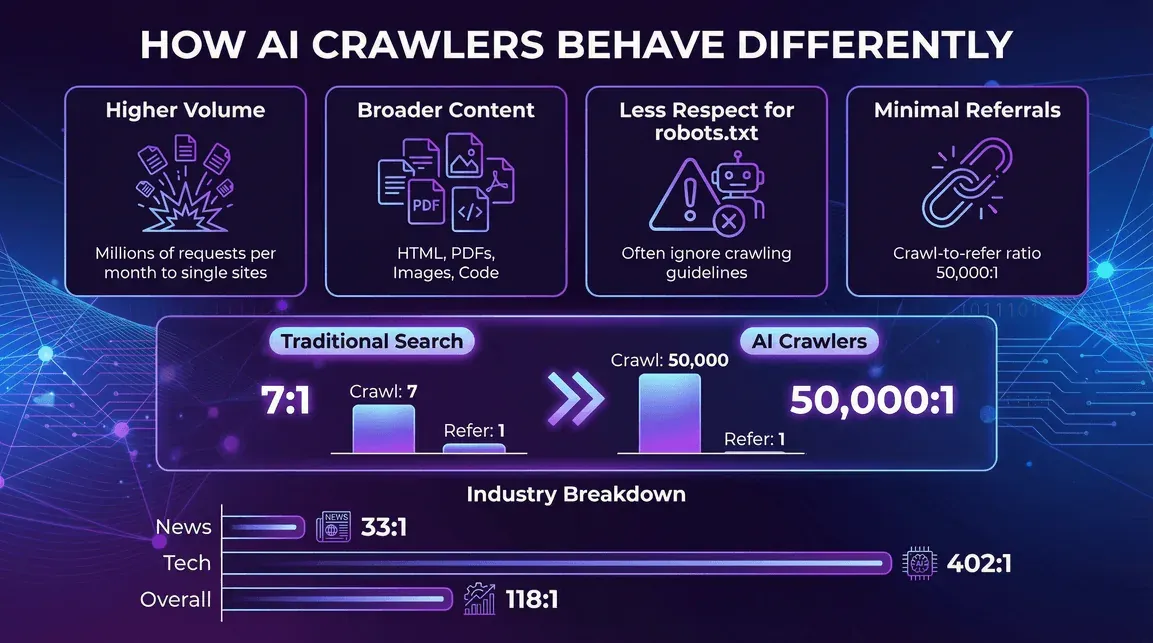
AIクローラーの挙動の違い
- 1クローラーあたりの量が多い:1体のAIボットが、1サイトに対して月間数百万件のリクエストを生み出すことがあります(Redditの事例)。
- 対象コンテンツの幅が広い:HTMLにとどまらず、PDF、画像、コードまで、手当たり次第です。
- robots.txtへの配慮が薄い。AIクローラーの一部は、クロール指示を無視したり、部分的にしか守らなかったりします (blog.cloudflare.com)。
- リファラートラフィックが極端に少ない。出版社にとって、いちばん頭の痛いのがここでしょう。Cloudflareの2025年7月のcrawl-to-click分析では、Anthropicはクロール38,000ページあたり1件の訪問、OpenAIは1,091:1、Perplexityは194:1という比率でした。対するGoogleの従来型検索クローラーは、数ページごとに1件は参照流入を返してくれます。AIクローラーは大量に持ち去る一方で、返してよこすものはごくわずかです。しかも回答がチャットボットのUI内で完結するようになるにつれ、その差はさらに開いています。
業界別のAIクローラートラフィック
どの業界も一律にクロールされるわけではありません。たとえば、
- ニュース・出版:AIクローラーの活動はきわめて活発な一方で、参照流入の比率はやや良好です(例:Perplexityのcrawl-to-refer比率はニュースサイトで33:1、全体では118:1)(blog.cloudflare.com)。
- テクノロジー・電子機器:GPTBotとAmazonbotが優勢で、crawl-to-refer比率はなお高めです(例:OpenAIの比率はテック分野で402:1)(blog.cloudflare.com)。
- 金融、学術、その他:分野ごとにボットの組み合わせや参照流入率は変わりますが、傾向ははっきりしています。AIクローラーはどこにでもいて、その多くはほとんどトラフィックを返してくれません。
2026年の主要ウェブクローラー:誰が一番ウェブをクロールしているのか?
このクロール劇の主役は誰なのか。Cloudflareの2025年中頃のデータをもとにしたランキングがこちらです。
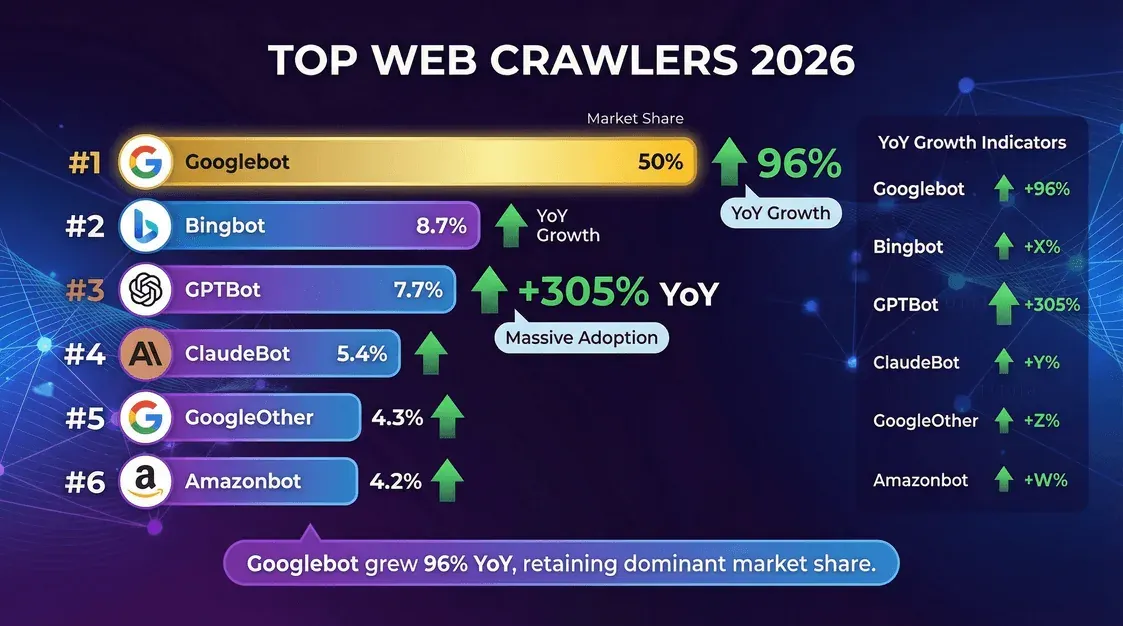
| クローラー(運営元) | ユニークページ要求の割合(2025年10〜11月) | 補足 |
|---|---|---|
| Googlebot(Google) | 11.6% | 依然として最大の単独クローラー。Cloudflare YIR 2025ではPerplexityBotの約200倍。 |
| GPTBot(OpenAI) | 3.6% | 専用AI学習クローラーとして最大。Cloudflareが分母を変更し、AIボット数が増えた後は2025年5月時点の比率より低下。 |
| Bingbot(Microsoft) | 2.6% | Bing検索とCopilotの基盤の両方を支える。 |
| Meta-ExternalAgent | 2.4% | Llama学習向けのコンテンツ取り込みクローラー。2025年にトップ5入り。 |
| ClaudeBot(Anthropic) | 2.4% | 年前半の急落のあと、2025年後半に持ち直した。 |
| Applebot(Apple) | 急速に上昇中 | Cloudflareデータの二次分析によると、2026年第1四半期に上位層へ急上昇。 |
| PerplexityBot | 0.06% | 絶対値は小さいが、主要AIボットの中で相対成長率は最速。 |
出典:CloudflareのYear in Review 2025。2025年10〜11月にクロールされたユニークページの割合で測定。注:これは、以前のレポートで使われていた2025年5月の「全クローラーリクエストに占める割合」とは分母が異なります。順位は比較可能ですが、割合をそのまま横並びにはできません。
押さえておきたい点は次のとおりです。
- Googlebotはいまも王座にあり、クロール活動全体の半分を一手に担っています。
- GPTBotとMetaのクローラーがもっとも勢いよく伸びており、GPTBotのシェアはこの1年で3倍になりました。
- PerplexityBotとChatGPT-User系エージェントは全体比率こそ小さいものの、目を見張る速さで成長しています。
ウェブクロールのベンチマーク:クロール速度、スループット、性能
 ウェブクロールは、ただ量だけの話ではありません。速さと効率の話でもあります。2026年に押さえておきたいクロール速度と性能ベンチマークを見ていきましょう。
ウェブクロールは、ただ量だけの話ではありません。速さと効率の話でもあります。2026年に押さえておきたいクロール速度と性能ベンチマークを見ていきましょう。
クロール速度:クローラーはどれくらいの速さでページを取得しているのか?
- クロール速度は通常、1秒あたりのページ数(またはリクエスト数)で測ります (IBM)。
- スレッド/並列接続数:スレッドが多いほど、理論上のクロール速度は上がります。たとえば、200スレッドでサイトごとに2秒の遅延がある場合、1秒あたり約100ページを取得できます (IBM)。
- 実世界のベンチマーク:最適化したクローラーを、そこそこのサーバークラスタで走らせるなら、1秒あたり100〜200ページ程度が目安です。
- GoogleとBing:世界中の何百万ものサイトに分散しながら、1秒あたり数千ページを取得していると見られます。
クロール速度に影響する要因
- スレッド数/並列取得数:スレッドが多いほど速くなります(別のボトルネックに突き当たるまでは)。
- アクティブなサイト数:複数ドメインを並行してクロールすればスループットは上がります。
- クロール遅延/待機時間:待ち時間が長いほどクロール速度は落ちます。
- リソース制限:帯域幅、CPU、データベースの書き込み速度は、いずれもボトルネックになりえます。
- 対象サイトの性能:遅いサイトやレート制限のあるサイトは、クロール速度を引き下げます。
たとえば、クローラーが100スレッドを持ち、サイトごとの遅延が1秒なら、1秒あたり約100ページ取得できる計算です。ただし、データベースが書き込みに追いつかなければ、足を引っ張るのはネットワークではなく保存先になります。
ウェブクロールがビジネスに与える影響:コスト、機会、リスク
ウェブクロールは、単なる技術的な好奇心の対象ではありません。実際のコストとチャンスを抱えた経営課題です。
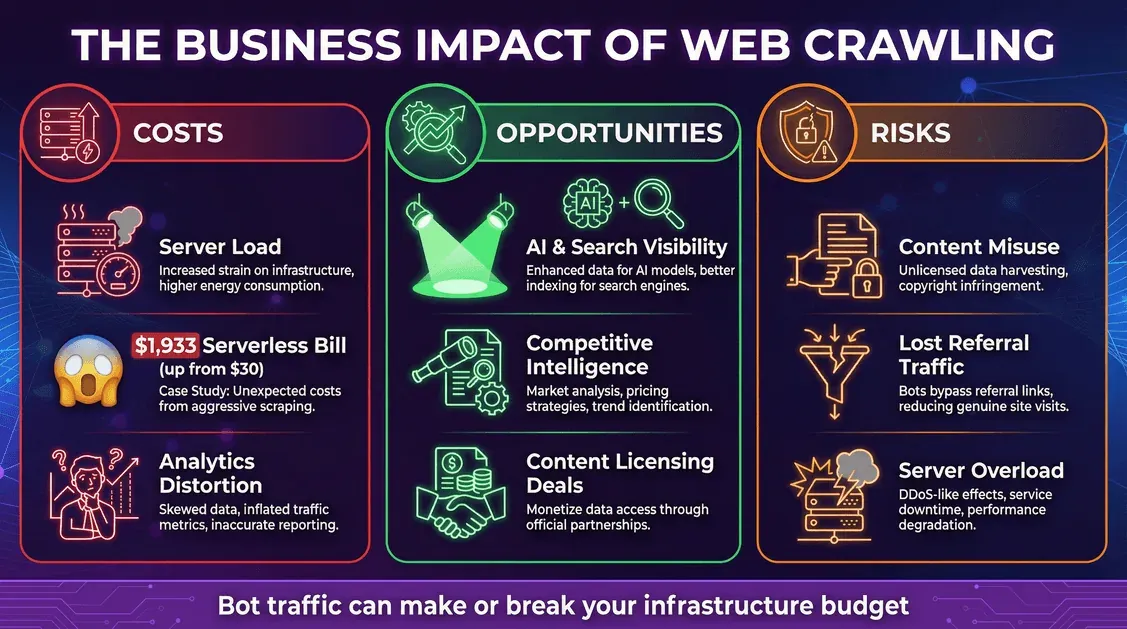
コスト:インフラと予想外の請求
- サーバー負荷:ボットのリクエスト1件ごとに、CPU、メモリ、帯域幅が削られていきます。
- クラウド料金:従量課金型(サーバーレスなど)を使っていると、ボットのせいで請求が膨らむことがあります。ある開発者は、Metaのクローラーが1か月で1100万件のリクエストを生み、サーバーレス料金が30ドルから1,933ドルに跳ね上がったと報告しています。
- 分析の歪み:ボットはウェブ解析を歪めるので、本物のユーザー行動を読み取るのが難しくなります。
機会:可視性とデータ活用
- AIと検索での可視性:AIの学習データや検索インデックスに含まれることで、ブランドのリーチが広がる可能性があります (blog.cloudflare.com)。
- 競合インテリジェンス:企業は市場調査や価格監視といった用途にクローラーを役立てています。
- 収益化:一部の出版社は、いまやAI企業へコンテンツをライセンス提供しています。
リスク:コンテンツの不正利用と流入減少
- コンテンツの不正利用:AIクローラーが、はっきりした許可も対価もないまま、あなたのコンテンツをモデルに取り込んでしまうことがあります。
- 参照流入の喪失:AIの回答だけでユーザーが満足し、サイトへ来なくなることで、いわゆる「中抜き」が起こります。
- セキュリティとダウンタイム:攻撃的なクローラーはサーバーに過剰な負荷をかけ、速度低下や障害を招くおそれがあります。
ウェブクローラートラフィックの管理:ベストプラクティス
では、ボットに予算を食い尽くされないためには、どう手を打てばよいのでしょうか。
1. robots.txtを最適化する
robots.txtを使えば、特定のボットを許可したり拒否したりできます。Googlebotのような信頼性の高いクローラーの多くはこれに従いますが、AIボットの多くは従わないこともあります (blog.cloudflare.com)。- 2025年半ば時点で、上位サイトのおよそ14%がAIボット向けの明示的なルールを追加し始めていました (blog.cloudflare.com)。
2. ボット管理ツールを使う
- Web Application Firewall(WAF)やボット管理サービスを使えば、不審なトラフィックをブロックしたり、レート制限をかけたりできます。
- Cloudflareをはじめとするベンダーは、ボット軽減機能や、コンテンツ制作者向けの「AI Audit」ツールも提供しています (blog.cloudflare.com)。
3. レート制限とキャッシュを導入する
- 1つのボットからの短時間に集中するリクエストには、レート制限をかけます。
- できる限り、ボットにはキャッシュ済みコンテンツを返しましょう。高コストなサーバーレス関数やデータベースクエリを、無駄に走らせてはいけません (Redditの事例)。
4. ボットトラフィックを監視・分析する
- サーバーログをこまめに確認しましょう。どのボットが、どれくらいの頻度で、いつ来ているのかを把握します。
- 不自然なトラフィックの急増に対して、アラートを仕掛けておきます。
5. 新しい標準に先回りする
- AI利用の可否を伝える新しいメタタグやHTTPヘッダーに目を配りましょう(例:
<meta name="ai:allow" content="no">)。 - ContentSignals.orgのような業界の取り組みや、x402のような決済プロトコルにも注意を払いましょう。
2026年以降に注目すべきウェブクロールのトレンド
2025年のデータスクレイピングとは何か、そのやり方 Get Started Free
ウェブクロールの世界は、ものすごい勢いで進化しています。私が目を凝らしているポイントは次のとおりです。
- AI駆動のクロールは増える一方:テキスト、画像、動画など、より多様なコンテンツを追うAIボットが、さらに増えていくでしょう。
- コンテンツライセンスと課金標準。「無法地帯」という言い回しは、もう時代遅れに感じられ始めています。Anthropicは2025年後半、学習データをめぐる著者との間で15億ドルの和解を発表し、これは現時点で出版社とAI企業の和解として最大級です。MetaはCNN、Fox News、People Inc.、USA Todayと複数年のコンテンツライセンス契約を結び、2025年前半のAP–GoogleやAxios–OpenAIの契約は、例外ではなく“ひな型”として見られるようになりました。新たな訴訟も続いており、2026年5月5日には5つの出版社がマンハッタンでMetaを提訴しています。つまり、法的な決着はまだついていないものの、流れははっきりしています。コンテンツは、ただスクレイプされる対象ではなく、価値を認められ、対価が支払われ、そして争われる対象になりつつあるのです。プロトコルの面では、x402とContentSignals.orgが、それぞれマシン決済層とマシン許可層の有力候補として頭角を現しています。
- 規制がやってくる:とりわけAI学習データをめぐって、ボットに何が許され何が許されないのか、法的な整理がいっそう進むでしょう (reuters.com)。
- コンテンツ利用の技術標準:新しいメタタグ、robots.txtの拡張、機械可読なボット宣言が登場するはずです。
- 出版社とAIの協業:受け身の対象に甘んじるのではなく、構造化データフィードやAPIをAI企業と交渉する出版社が増えていくでしょう。
結論:これらのウェブクロール統計があなたのビジネスに意味すること
結論をひと言でまとめれば、2026年のウェブクロールは支配的な存在であり、その勢いが衰える気配はありません。自動ボット、とりわけAIクローラーが、いまやトラフィックの大きな部分を握っており、インフラ、予算、コンテンツ戦略への影響は膨らむ一方です。
では、何をすべきか。
- 大量のボットトラフィックを前提に置く:インフラ、予算、監視体制を、それを織り込んで設計しましょう。
- 自分のクローラーを知る:ボットはみな同じではありません。相手に合わせて対応を変えましょう。
- 指標を監視する:人間の訪問者と同じように、ボットのトラフィックも追いかけましょう。
- コンテンツと財布を守る:技術的な制御、法的な契約、新しい標準を組み合わせて使いましょう。
- 良い面を生かす:AIや検索のインデックスに載れば、ブランドは伸びます。ただし、その見返りをきちんと受け取れているか確かめてください。
- 情報を追い、適応する:クロールの世界は急速に動いています。新しい標準、規制、ビジネスモデルを追い続けましょう。
自動化とAIツールを長年作ってきた者として、そしていまThunderbitに身を置く立場として、はっきり言えます。この新時代で勝ち抜く企業は、ウェブクロールを単なる技術的な厄介ごとではなく、戦略上の優先課題として扱う会社です。営業でも、ECでも、マーケティングでも、不動産でも、ウェブクロール統計と業界ベンチマークを理解することは、もはや最低限の前提条件です。
次にサーバーログを開いてボットの行列を目にしたら、ため息ひとつで済ませないでください。そのデータを使うのです。自社サイトをベンチマークにかけ、戦略を調整しましょう。そして忘れないでください。AI時代において、ボットは“これからやって来る”のではなく、すでにそこにいます。彼らに使われるのではなく、彼らを自分のために働かせましょう。
油断せず、好奇心を絶やさず、サーバーログがいつもあなたの味方でありますように。
Thunderbit AI Web Scraperを無料で試す
ウェブスクレイピング、自動化、AIを活用した生産性について、もっと知りたいですか。掘り下げた解説やハウツー、最新トレンドはThunderbitのブログでまとめています。自分のデータを自在に扱いたい方は、AI搭載のウェブスクレイピングを実現するThunderbit Chrome Extensionをぜひお試しください。コード不要、手間いらず、結果はすぐに手に入ります。
AIウェブスクレイパーを試す Get Started Free
参考文献・追加資料:
- From Googlebot to GPTBot: Who’s Crawling Your Site in 2025 (Cloudflare)
- Cloudflare Report Reveals Global Internet Traffic Grew 19% in 2025—but a Lot of It Was Just Bots (TechRadar)
- How Crawling Works in the AI Era 2025 (Webscraft)
- Meta’s Crawler Made 11 Million Requests to My Site in 30 Days (Reddit)
- Monitoring - Web Crawler Crawl Rate (IBM)
- A Timeline of the Major Deals Between Publishers and AI Tech Companies in 2025 (Digiday)
- Launching the x402 Foundation with Coinbase (Cloudflare)




