想像してみてください。2025年の朝、コーヒー片手にWalmartで狙っていた65インチテレビの値下げがあったか気になる——もしくは、ECビジネスをやっていて、Walmartの価格や在庫、レビューの動きをリアルタイムでキャッチしたい。毎日全部の商品を手作業でチェックするなんて、現実的じゃないですよね。でも、Pythonと웹 스크래퍼の知識があれば、面倒な作業を自動化して、大量のデータを効率よく集めることができます。
自分は長年、ビジネスユーザー向けの自動化・AIツールを作ってきました。walmartスクレイピングは、地味なリサーチ作業を数行のコードで一気に片付ける“秘密兵器”のひとつです。このガイドでは、walmartスクレイピングの基本から、2025年のビジネスでの価値、Pythonでの実装方法まで、実際のコード例を交えて分かりやすく紹介します。コーヒーや好きなお菓子を用意して、さっそく始めましょう。
walmartスクレイピングとは?2025年の基本
ざっくり言うと、walmartスクレイピングはWalmartのウェブサイトから商品情報・価格・レビューなどを自動で抜き出すこと。手作業でコピペする代わりに、Pythonスクリプトでページを取得して、必要なデータを抜き出して保存します。
なぜPythonなのか?Pythonは웹 스크래퍼にぴったりの言語で、読みやすくて、RequestsやBeautifulSoup、pandasなど強力なライブラリが揃っています。個人でもチームでも、開発経験が少なくても始めやすいのが魅力です。
また、個人利用(自分の買い物用に数商品を追跡)とビジネス利用(数千SKUを競合調査などで監視)では、規模や難易度が大きく違います。特にWalmartは2025年時点で公式APIを公開していないので、ちょっとした工夫が必要です()。
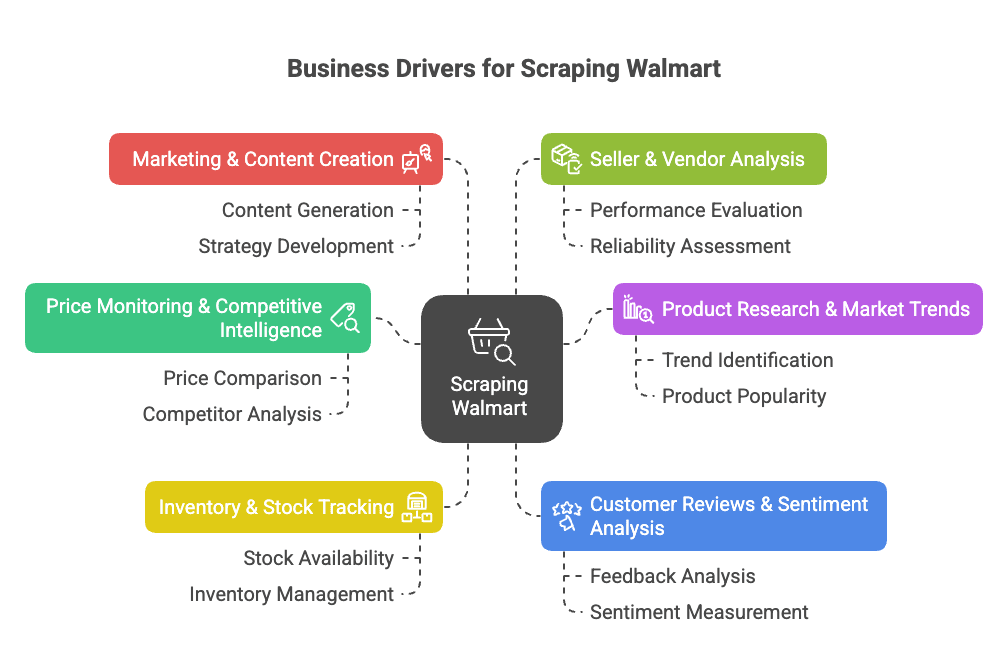
なぜwalmartをスクレイピングするのか?ビジネスでの価値
Walmartはアメリカ最大の小売チェーンで、オンライン売上もに到達し、EC比率も**全体の約18%**まで拡大しています()。膨大な商品・価格・レビュー・トレンドデータが分析対象です。
walmartスクレイピングがもたらす主なビジネスメリットはこんな感じ:
- 価格監視・競合分析:Walmartの価格やプロモーション、商品ラインナップの変化をすぐにキャッチして、自社の価格戦略に活用()。
- 商品リサーチ・市場トレンド分析:Walmartの品揃えや仕様、カテゴリの動きを分析して、新しいビジネスチャンスを発見()。
- 在庫・ストック状況の把握:在庫切れや補充状況を監視して、サプライチェーン最適化や競合の欠品をチャンスに()。
- レビュー・顧客の声分析:レビューを集めて分析し、商品改善や課題発見に活用()。
- マーケティング・コンテンツ最適化:「ベストセラー」商品や訴求ポイント、コンテンツの工夫を調査()。
- 出品者・ベンダー分析:有力なサードパーティ出品者や無許可出品を特定()。
下の表で、主な活用例・対象部門・得られる効果をまとめています:
| 活用例 | 対象部門 | 主な効果・ROI |
|---|---|---|
| 価格監視 | 価格・営業チーム | 競合価格の即時把握、動的価格設定、利益率維持 |
| 品揃え・カタログ分析 | 商品企画・MD | 品揃えの隙間発見、新商品投入、カタログ充実 |
| 在庫状況トラッキング | オペレーション・SCM | 需要予測精度向上、欠品回避、流通最適化 |
| レビュー・顧客の声 | 商品開発・CX | データに基づく商品改善、顧客満足度向上 |
| 市場トレンド分析 | 戦略・市場調査 | トレンド把握、戦略立案、新規参入判断 |
| コンテンツ・価格戦略 | マーケ・EC | 価格最適化、効果的なコンテンツ学習 |
| 出品者監視 | 営業・パートナー | パートナー発掘、ブランド保護、無許可出品監視 |
つまり、walmartスクレイピングは時短・売上アップ・データ競争力の源泉です。毎朝50ページを手作業で確認する代わりに、スクリプトなら数千件を数分で取得できます()。
walmartスクレイピングは、EC・営業・市場調査チームにとって大きな武器。適切なツールを使えば、データ収集を自動化して、分析や意思決定に集中できます。
Pythonで始めるwalmartスクレイピング:準備するもの
まずはPython環境を用意しましょう。必要なツールは:
- Python 3.9以上(2025年なら3.11や3.12推奨)
- Requests:ウェブページ取得用
- BeautifulSoup (bs4):HTML解析用
- pandas:データ整理・エクスポート用
- json:JSONデータ処理(標準搭載)
- 開発者ツール付きブラウザ:ページ構造の確認(F12キー)
- pip:パッケージ管理
インストールコマンド:
1pip install requests beautifulsoup4 pandasプロジェクトを整理したい場合は仮想環境もおすすめ:
1python3 -m venv walmart-scraper
2source walmart-scraper/bin/activate # Mac/Linux
3# または
4walmart-scraper\Scripts\activate.bat # Windows動作確認:
1import requests, bs4, pandas
2print("Libraries loaded successfully!")このメッセージが出れば準備OKです。
ステップ1:Pythonでwalmartスクレイパーのセットアップ
まずは作業環境を整えましょう:
- プロジェクト用フォルダ作成(例:
walmart_scraper/) - エディタを開く(VSCode、PyCharm、Notepad++など)
- 新しいスクリプト作成(例:
walmart_scraper.py)
テンプレート例:
1import requests
2from bs4 import BeautifulSoup
3import pandas as pd
4import jsonこれでWalmartの商品ページ取得の準備ができました。
ステップ2:PythonでWalmart商品ページを取得
WalmartのHTMLを取得するには、requests.get(url)を使いますが、Walmartはボット対策が厳しいので、そのままだとすぐにブロックされることも。
ポイントは「本物のブラウザを装う」こと。 User-AgentやAccept-LanguageなどのヘッダーをChromeやFirefoxに似せて設定しましょう。
例:
1headers = {
2 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0 Safari/537.36",
3 "Accept-Language": "en-US,en;q=0.9"
4}
5response = requests.get(url, headers=headers)
6html = response.textワンポイント: requests.Session()を使うとCookieが維持されて、より人間っぽく見えます。
1session = requests.Session()
2session.headers.update(headers)
3session.get("<https://www.walmart.com/>") # Cookie取得
4response = session.get(product_url)response.status_codeが200か必ず確認しましょう。CAPTCHAや異常なページが出たら、リクエスト間隔を空けたり、IPを変えたりして対策します。Walmartのボット対策はかなり強力です()。
Walmartのボット対策への対応
WalmartはAkamaiやPerimeterXなどのサービスで、IP・ヘッダー・Cookie・TLS指紋までしっかりチェックしています。対策としては:
- 現実的なヘッダーを必ず設定
- リクエスト間隔を3〜6秒空ける
- 遅延をランダム化
- 大量取得時はプロキシを活用
- CAPTCHAが出たら無理せず一旦ストップ
より高度な対策にはcurl_cffiなどのライブラリも使えますが、多くの場合はヘッダーと適切な遅延で十分です。
ステップ3:BeautifulSoupでWalmart商品データを抽出
いよいよデータ抽出です。WalmartのサイトはNext.jsで作られていて、商品情報は<script id="__NEXT_DATA__">タグ内の巨大なJSONに入っています。
取得例:
1from bs4 import BeautifulSoup
2import json
3soup = BeautifulSoup(html, "html.parser")
4script_tag = soup.find("script", {"id": "__NEXT_DATA__"})
5if script_tag:
6 json_text = script_tag.string
7 data = json.loads(json_text)このdataから商品情報を取得できます。一般的な商品ページでは:
1product_data = data["props"]["pageProps"]["initialData"]["data"]["product"]必要な項目を抽出:
1name = product_data.get("name")
2price_info = product_data.get("price", {})
3current_price = price_info.get("price")
4currency = price_info.get("currency")
5rating_info = product_data.get("rating", {})
6average_rating = rating_info.get("averageRating")
7review_count = rating_info.get("numberOfReviews")
8description = product_data.get("shortDescription") or product_data.get("description")なぜJSONを使うのか? HTMLタグよりも構造が安定していて、Walmart側のレイアウト変更にも強いからです。ページ上に表示されていない情報も取得できる場合があります()。
動的コンテンツやJSONデータの扱い
レビューや在庫状況など、一部の情報はJavaScriptやAPI経由で動的に読み込まれますが、多くは__NEXT_DATA__のJSONに含まれています。もし足りない場合は、ブラウザの開発者ツールでAPIエンドポイントを調べて、同じようにリクエストを送ることも可能です。
ステップ4:Walmartデータの保存・エクスポート
抽出したデータはCSVやExcel、JSONなどで保存できます。pandasを使った例:
1import pandas as pd
2product_record = {
3 "商品名": name,
4 "価格(USD)": current_price,
5 "評価": average_rating,
6 "レビュー数": review_count,
7 "説明": description
8}
9df = pd.DataFrame([product_record])
10df.to_csv("walmart_products.csv", index=False)複数商品を取得する場合は、各レコードをリストに追加して、最後にDataFrame化しましょう。
Excelならdf.to_excel("walmart_products.xlsx", index=False)(openpyxlが必要)、JSONならdf.to_json("walmart_products.json", orient="records", indent=2)。
ワンポイント: エクスポート後は必ずデータを確認しましょう。キー名の変更などで全て「None」になっていることもあるので注意。
ステップ5:walmartスクレイパーの拡張・スケールアップ
複数商品ページを一括取得するには:
1product_urls = [
2 "<https://www.walmart.com/ip/Apple-AirPods-Pro-2nd-Generation/720559357>",
3 "<https://www.walmart.com/ip/SAMSUNG-65-Class-QLED-4K-Q60C/180355997>",
4 # ...他のURL
5]
6all_records = []
7for url in product_urls:
8 resp = session.get(url)
9 # ...前述の抽出処理...
10 all_records.append(product_record)
11 time.sleep(random.uniform(3, 6)) # マナーを守って!URLリストがない場合は、検索結果ページから商品リンクを抽出して、順次スクレイピングする方法もあります()。
注意: 短時間で大量ページを取得するとIPブロックされやすいので、プロキシの利用が必須です。
プロキシや스크래퍼APIの活用
プロキシを使うとIPアドレスを切り替えられて、ブロックされにくくなります。リクエスト時に以下のように指定:
1proxies = {
2 "http": "<http://your.proxy.address>:port",
3 "https": "<https://your.proxy.address>:port"
4}
5response = session.get(url, proxies=proxies)大規模なスクレイピングには스크래퍼APIも便利。プロキシやCAPTCHA、JavaScriptレンダリングまで自動で対応してくれます。URLを送るだけでデータが返ってくるので、非開発者にもおすすめです。
比較表:
| アプローチ | メリット | デメリット | おすすめ用途 |
|---|---|---|---|
| Python+プロキシ自作 | 柔軟・小規模なら低コスト | 保守・プロキシ費用・ブロックリスク | 開発者・カスタム用途 |
| サードパーティ스크レイパーAPI | 簡単・自動で大規模対応 | 大量利用時はコスト増・柔軟性低 | ビジネス・大規模・迅速なデータ取得 |
開発不要でサクッとデータが欲しい場合は、が便利。クリックだけで取得できて、コードやプロキシの設定も不要です。
walmartスクレイピングのよくある課題と対策
walmartスクレイピングにはこんな課題がありますが、ちゃんと対策もあります:
- 強力なボット対策:IP・ヘッダー・Cookie・TLS指紋・JavaScriptチェックなど。→現実的なヘッダー、セッション、遅延、プロキシで対応()。
- CAPTCHA:頻繁に出る場合は一旦ストップ。解決サービスもあるけどコスト増()。
- サイト構造の変更:JSON構造が変わったら再調査・修正。モジュール化しておくと対応しやすい。
- ページネーション・サブページ:大量データ取得時はページ送り処理が必要。終了条件の設定も忘れずに()。
- データ量・レート制限:大規模取得時はバッチ処理や部分保存を活用。メモリに一度に全件は避ける。
- 法的・倫理的配慮:公開データのみ取得し、Walmartの利用規約やサーバー負荷に配慮。ビジネス利用時は必ず規約を確認。
管理型ツールへの切り替え時期は? CAPTCHA対策や保守に時間を取られる場合は、Thunderbitや스크래퍼APIなどの利用を検討しましょう。非開発者にはノーコードツールが最適です()。
Pythonによるwalmartスクレイピング:フルコード例
ここまでの内容をまとめた、Walmart商品ページ用のPythonスクリプト例です:
1import requests
2from bs4 import BeautifulSoup
3import json
4import pandas as pd
5import time
6import random
7# セッションとヘッダー設定
8session = requests.Session()
9session.headers.update({
10 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0 Safari/537.36",
11 "Accept-Language": "en-US,en;q=0.9"
12})
13# Cookie取得のためホームページ訪問
14session.get("<https://www.walmart.com/>")
15# 取得対象URLリスト
16product_urls = [
17 "<https://www.walmart.com/ip/Apple-AirPods-Pro-2nd-Generation/720559357>",
18 "<https://www.walmart.com/ip/SAMSUNG-65-Class-QLED-4K-Q60C/180355997>",
19 # 必要に応じて追加
20]
21all_products = []
22for url in product_urls:
23 try:
24 response = session.get(url)
25 except Exception as e:
26 print(f"リクエストエラー: \{url\}: \{e\}")
27 continue
28 if response.status_code != 200:
29 print(f"取得失敗: \{url\} (ステータス \{response.status_code\})")
30 continue
31 soup = BeautifulSoup(response.text, "html.parser")
32 script_tag = soup.find("script", {"id": "__NEXT_DATA__"})
33 if not script_tag:
34 print(f"データスクリプトが見つかりません: \{url\}")
35 continue
36 try:
37 data = json.loads(script_tag.string)
38 except json.JSONDecodeError as e:
39 print(f"JSONパースエラー: \{url\}: \{e\}")
40 continue
41 try:
42 product_info = data["props"]["pageProps"]["initialData"]["data"]["product"]
43 except KeyError:
44 print(f"JSON内に商品データが見つかりません: \{url\}")
45 continue
46 name = product_info.get("name")
47 brand = product_info.get("brand", {}).get("name") or product_info.get("brand", "")
48 price_obj = product_info.get("price", {})
49 price = price_obj.get("price")
50 currency = price_obj.get("currency")
51 orig_price = price_obj.get("priceStrikethrough") or price_obj.get("price_strikethrough")
52 rating_obj = product_info.get("rating", {})
53 avg_rating = rating_obj.get("averageRating")
54 review_count = rating_obj.get("numberOfReviews")
55 desc = product_info.get("description") or product_info.get("shortDescription") or ""
56 product_record = {
57 "URL": url,
58 "商品名": name,
59 "ブランド": brand,
60 "価格": price,
61 "通貨": currency,
62 "元値": orig_price,
63 "平均評価": avg_rating,
64 "レビュー数": review_count,
65 "説明": desc
66 }
67 all_products.append(product_record)
68 # ランダム遅延でブロック回避
69 time.sleep(random.uniform(3.0, 6.0))
70df = pd.DataFrame(all_products)
71print(df.head(5))
72df.to_csv("walmart_scrape_output.csv", index=False)カスタマイズ例:
product_urlsにURLを追加- 抽出項目をニーズに合わせて調整
- 遅延時間もリスクに応じて調整
まとめ・ポイント
ここまでの要点を振り返ります:
- walmartスクレイピングは価格・商品・レビュー情報の収集に強力。競合分析や商品開発、価格戦略に不可欠。
- Pythonが最適:Requests・BeautifulSoup・pandasで堅牢な웹 스크래퍼が作れる。
- ボット対策は本格的:ブラウザヘッダー模倣、セッション、遅延、プロキシ活用が重要。
__NEXT_DATA__のJSONからデータ抽出:HTMLより安定・高精度。- pandasでCSV/Excel/JSONにエクスポート。
- 大規模化にはプロキシや스크래퍼APIも検討。非開発者ならでWalmart含む多くのサイトを2クリックで取得可能。ExcelやGoogle Sheets、Airtable、Notionへのエクスポートも無料()。
アドバイス:
まずは1商品から始めて、データの正確性を確認。Walmartの利用規約を守り、サーバーに負荷をかけないよう注意しましょう。規模が大きくなったら管理型ツールやAPIの利用も検討を。Pythonのデバッグに疲れたら、ThunderbitならAIが面倒な部分を自動化してくれます()。
ウェブスクレイピングやデータ自動化、AI活用に興味があれば、もぜひチェックしてみてください。
スクレイピングがうまくいきますように。新鮮で正確なデータが、CAPTCHAに邪魔されませんように!
P.S. 深夜2時にWalmartをスクレイピングしながら画面にぼやいているあなたへ——その気持ち、めっちゃ分かります。デバッグはデータ人材の“修行”です。
よくある質問(FAQ)
1. PythonでWalmartのデータをスクレイピングするのは合法ですか?
公開データを個人利用や非商用分析目的で取得するのは一般的に問題ありませんが、ビジネス利用の場合は法的・倫理的な配慮が必要です。Walmartの利用規約を必ず確認し、リクエスト頻度やサーバー負荷、機密データの取得を避けましょう。
2. PythonスクレイピングでWalmartからどんなデータが取得できますか?
商品名、価格、ブランド情報、説明文、カスタマーレビュー、評価、在庫状況など、<script id="__NEXT_DATA__">タグ内の構造化JSONから多くの情報が取得可能です。
3. Walmartのスクレイピングでブロックされないコツは?
現実的なヘッダー設定、セッション維持、3〜6秒のランダム遅延、プロキシの活用、短時間での大量リクエスト回避が有効です。大規模案件では스크래퍼APIやThunderbitのようなツール利用もおすすめです。
4. 数百〜数千件のWalmart商品ページを一括取得できますか?
可能ですが、プロキシ管理やリクエスト制御、場合によっては스크래퍼APIの利用が必要です。Walmartのボット対策は強力なので、準備不足だとブロックやCAPTCHAが発生します。
5. コードが書けなくてもWalmartをスクレイピングできますか?
ThunderbitのAIウェブ스크래퍼拡張機能を使えば、コード不要でWalmartの商品ページを取得できます。アンチボット対策も自動、Excel・Notion・Sheetsへのエクスポートも簡単なので、非開発者やビジネスチームにも最適です。