

ウェブにはデータがあふれ、それを手元に引っ張ってきたいニーズも年々強まっています。市場規模を一つの数字で言い切るのは難しく、ソフトまで含めるか、サービスやプロキシも数えるかで見積もりは大きくぶれます。要するにウェブスクレイピングは、データ基盤のなかで「派手さはないが、なくては困る」領域として根を張っているわけです。
分析職でも、マーケターでも、「ちょっと触ってみたい」初心者でも、ウェブサイトからデータを取り出す力は急速に欠かせないスキルになっています。私もそうですが、延々と続くコピペは飛ばして、価値の出る場所——使えるインサイト、整ったスプレッドシート、ほんの少しの自動化——へ一足飛びでたどり着きたい人は多いはずです。
その近道が Python です。データ仕事の万能ナイフのような言語で、初心者にも扱いやすく、1 ページの取得から数千ページのクロールまでこなせます。この実践チュートリアルでは、Python によるウェブスクレイピングの基礎から、JavaScript で動く厄介なサイトへの対処までを順に追い、最後にデータ抽出を出前感覚まで手軽にしてくれる AI 搭載・ノーコードのウェブスクレイパー Thunderbit も紹介します。コードを身につけたい人にも、近道がほしい人にも、ちょうどいい出発点になるはずです。
ウェブスクレイピングとは何か、なぜ Python でウェブサイトからデータを取るのか
AIであらゆるウェブサイトからデータを抽出 Get Started Free
ウェブスクレイピングとは、ウェブサイト上の情報を自動で抜き出し、スプレッドシートや CSV、データベースといった構造化された形に変えて、分析や業務にそのまま使えるようにする手法です(PromptCloud)。人が手でコピペする代わりに、スクレイパーが人間の操作を模倣しながら、桁違いの速度と規模でこなしてくれます。
これほど価値があるのは、いまのビジネスがデータドリブンな意思決定を当たり前にしているからです。組織が大きくなるほど、勘ではなく実データで裏づけたい判断は増えます。そしてそのデータの多くは、最初は誰かのウェブページの上に生まれています。
競合価格を毎朝チェックする、点在する不動産情報を一か所にまとめる、自分だけの見込み客リストを組み立てる——こうした作業が、ほとんど手をかけずに回るとしたら、と想像してみてください。
では、なぜ Python なのか。選ばれ続ける理由を挙げてみます。
- 読みやすく、素直: Python の文法はすっきりしていて初心者にもなじみやすく、スクレイピング用のスクリプトを書くのも読み解くのも楽です(PromptCloud)。
- エコシステムが豊富:
requests、BeautifulSoup、Scrapy、Seleniumといったライブラリが、取得・解析・ブラウザ操作の自動化を一気に簡単にしてくれます。 - コミュニティが強い: Python は世界でもっとも人気のあるプログラミング言語として常に上位にあり、チュートリアルもフォーラムもコード例も無数に見つかります。
- スケールする: ちょっとした単発スクリプトから、本格的な大規模クロールまで、同じ言語で対応できます。
つまるところ、Python はウェブデータの世界への入場券です。まったくの初心者にも、ベテランのアナリストにも、等しく開かれています。
まずは土台から: Python ウェブスクレイピングの基本の流れ
コードに飛び込む前に、Python でウェブサイトからデータを取るときの基本的な流れを押さえておきましょう。
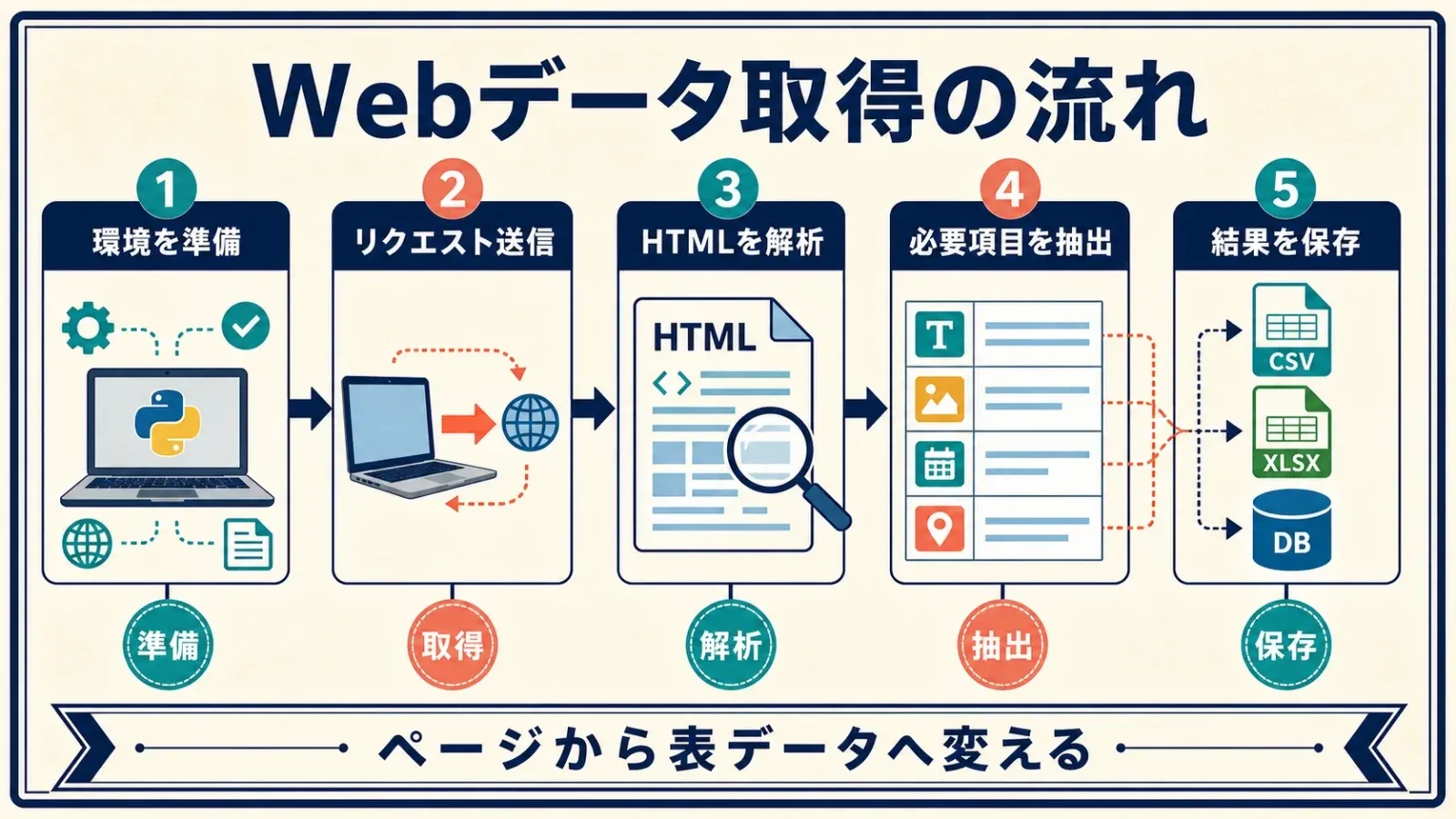
- 環境を整える: Python と必要なライブラリ(
requests、BeautifulSoupなど)を入れます。 - リクエストを投げる: Python で対象ページの HTML を取得します。
- HTML を解析する: パーサーでページ構造をたどります。
- データを抜き出す: ほしい情報を見つけて取り出します。
- 結果を保存する: CSV、Excel、データベースに残して分析に回します。
コードの達人である必要はありません。Python を入れてスクリプトを走らせられれば、もう半分は終わったようなものです。初心者なら仮想環境や Jupyter Notebook を使うとやりやすいですが、ふつうのテキストエディタでも十分です。
最低限そろえたいライブラリ:
requests— ウェブページの取得用BeautifulSoup— HTML 解析用pandas— データの保存・整形用(任意ですが、入れておくと本当に楽です)
どの Python スクレイピングライブラリを選ぶか: BeautifulSoup・Scrapy・Selenium を比べる
Python のスクレイピングツールは横並びではありません。特によく使われる 3 つをざっと見ていきます。
| ツール | 最適な用途 | 強み | 弱み |
|---|---|---|---|
| BeautifulSoup | シンプルで静的なページ、初心者向け | 使いやすい、導入が簡単、ドキュメントが充実 | 大規模クロールや動的コンテンツにはあまり向かない |
| Scrapy | 大規模・複数ページのクロール | 高速、非同期、パイプライン内蔵、クロールと保存処理に対応 | 学習コストが高め、小規模作業にはやや大げさ、JavaScriptは実行しない |
| Selenium | 動的サイト、JavaScriptが多いサイト、自動操作 | JSを描画できる、ユーザー操作を再現できる、ログインやクリックに対応 | 遅い、リソースを多く使う、設定がやや複雑 |
BeautifulSoup: シンプルな HTML 解析の王道
BeautifulSoup は初心者や小ぶりなプロジェクトにいちばん向いています。数行で HTML を解析し、要素を取り出せます。対象がほぼ静的で込み入った JavaScript 読み込みがないなら、BeautifulSoup と requests だけで事足ります。
例:
import requests
from bs4 import BeautifulSoup
url = "https://example.com"
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
titles = [h2.text for h2 in soup.find_all('h2', class_='product-title')]
print(titles)
向いている場面: 単発の取得、素朴なブログ、商品ページ、ディレクトリなど。
Scrapy: 大規模で構造化されたクロール向け
Scrapy は、サイト全体や数千ページ規模の処理までこなせる本格派のフレームワークです。非同期で高速、整形・保存パイプラインも備え、リンクも自動でたどれます。
例:
import scrapy
class ProductSpider(scrapy.Spider):
name = "products"
start_urls = ["https://example.com/products"]
def parse(self, response):
for item in response.css('div.product'):
yield {
'name': item.css('h2::text').get(),
'price': item.css('span.price::text').get()
}
向いている場面: 大きめのプロジェクト、定期的なクロール、速度と構造の両方がほしいとき。
Selenium: 動的サイトや JavaScript 中心のサイトに
Selenium は Chrome や Firefox の実ブラウザを動かすため、JavaScript でデータを読み込むサイト、ログインが要るサイト、ボタン操作が必要なサイトにも対応できます。
例:
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get("https://example.com/login")
driver.find_element(By.NAME, "username").send_keys("myuser")
driver.find_element(By.NAME, "password").send_keys("mypassword")
driver.find_element(By.XPATH, "//button[@type='submit']").click()
dashboard = driver.find_element(By.ID, "dashboard").text
print(dashboard)
driver.quit()
向いている場面: SNS、株価サイト、無限スクロールのページ、「ページのソースを表示」しても中身が空に見えるサイトなど。
手順解説: Python でウェブサイトからデータを取る(初心者向け)
ここからは requests と BeautifulSoup を使って、実際に手を動かしてみましょう。書籍一覧サイトから、タイトル、著者、価格を取り出します。
ステップ1: Python の環境を整える
まずは必要なライブラリを入れます。
pip install requests beautifulsoup4 pandas
そのうえで、スクリプトに読み込みます。
import requests
from bs4 import BeautifulSoup
import pandas as pd
ステップ2: ウェブサイトにリクエストを送る
HTML を取得します。
url = "http://books.toscrape.com/catalogue/page-1.html"
response = requests.get(url)
if response.status_code == 200:
html = response.text
else:
print(f"ページの取得に失敗しました: {response.status_code}")
ステップ3: HTML を解析する
BeautifulSoup オブジェクトを作ります。
soup = BeautifulSoup(html, 'html.parser')
書籍のコンテナをすべて拾います。
books = soup.find_all('article', class_='product_pod')
print(f"このページで {len(books)} 冊見つかりました。")
ステップ4: ほしいデータを抜き出す
各書籍をループして詳細を取得します。
data = []
for book in books:
title = book.h3.a['title']
price = book.find('p', class_='price_color').text
data.append({"タイトル": title, "価格": price})
ステップ5: 分析できる形で保存する
DataFrame に変換して書き出します。
df = pd.DataFrame(data)
df.to_csv('books.csv', index=False)
これで、そのまま分析に使えるきれいな CSV ファイルが手に入りました。
つまずいたときのヒント:
- 結果が空っぽなら、データが JavaScript で読み込まれていないか疑ってください(次のセクションで扱います)。
- ブラウザの開発者ツールで、HTML 構造は必ず先に確認しておきましょう。
- データの欠けは
get_text(strip=True)と条件分岐でさばきます。
動的コンテンツへの対処: JavaScript で描画されるサイトからデータを取る
いまどきのサイトは、とにかく JavaScript を多用します。ページが表示されてからデータを読み込むので、最初に返ってくる HTML には、ほしい情報が入っていないことも珍しくありません。スクレイパーが何も拾えないときは、この動的コンテンツが犯人かもしれません。
対処の手立て:
- Selenium: 実ブラウザを再現し、コンテンツの読み込みを待ち、ボタン操作やスクロールもこなします。
- Playwright / Puppeteer: もう一段高度ですが、発想は同じです(ヘッドレスブラウザ)。
Selenium ミニガイド:
- Selenium とブラウザドライバー(例: ChromeDriver)を入れます。
- 明示的な待機を使って、コンテンツが読み込まれるのを待ちます。
- 描画後の HTML を取得し、必要なら BeautifulSoup で解析します。
例:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Chrome()
driver.get("https://example.com/dynamic")
WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CLASS_NAME, "dynamic-content"))
)
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
# ここまでと同じようにデータを抽出
driver.quit()
Selenium が要るのはどんなときか:
requests.get()では中身のない HTML が返るのに、ブラウザでは見えている場合。- 無限スクロール、ポップアップ、ログイン必須のサイト。
AI でスクレイピングをもっと身軽に: Thunderbit でウェブサイトからデータを取る
Thunderbit AIウェブスクレイパーを試す 2クリックで、どんなウェブサイトからでもデータを取得。コードは不要です。 Get Started Free
正直に言えば、コードではなくデータだけほしい場面もあります。そんなとき頼れるのが Thunderbit です。AI 搭載の Chrome 拡張機能で、数クリックでどんなサイトからでもデータを取得できます。Python は要りません。
Thunderbit の使い方:
- Thunderbit の Chrome 拡張機能を入れます。
- 対象のサイトを開きます。
- Thunderbit のアイコンをクリックして「AIで項目を提案」を押します。 AI がページを読み解き、どのデータを抜き出すべきか提案してくれます(例: 商品名、価格、メールアドレス)。
- 必要に応じて項目を直し、「スクレイプ」をクリックします。
- データを Excel、Google Sheets、Notion、Airtable へそのまま書き出します。
Thunderbit が優れている点:
- コーディング不要。 うちの母でも使えます(いまだに Wi-Fi が不調だと私に電話してきますが)。
- サブページやページネーションに対応。 複数ページにまたがる商品詳細も、ページを順にたどってまとめてくれます。
- 自然な言葉で指示できる。 「商品名と価格を全部抜き出して」と伝えるだけで、あとは AI がさばきます。
- 人気サイト向けのテンプレートが用意済み。 Amazon、Zillow、LinkedIn などは、ワンクリックで片づきます。
- 書き出しが楽。 CSV や Excel でダウンロードするか、お気に入りのツールへ直接送れます。
Thunderbit は世界中の10万人以上のユーザーに使われています。無料プランもあり、費用をかけず試せます。利用枠は変わるため、最新の上限は料金ページで確認してください。ビジネス利用者には時短の心強い味方であり、Python 派にとっても、自前のスクレイパーを書く価値があるかを判断する前に作業量の当たりをつける道具として便利です。
取得したあと: pandas と NumPy でデータを整え、分析する
データを取るのは最初の一歩にすぎません。生のウェブデータは、重複や欠損、妙な書式が混じって散らかりがちです。そこで活きるのが Python の pandas と NumPy です。
よくある整形作業:
- 重複を消す:
df.drop_duplicates(inplace=True) - 欠損値をさばく:
df.fillna('Unknown')またはdf.dropna() - データ型を変える:
df['Price'] = df['Price'].str.replace('$','').astype(float) - 日付を解析する:
df['Date'] = pd.to_datetime(df['Date']) - 外れ値を取り除く:
df = df[df['Price'] > 0]
基本的な分析:
- 要約統計:
df.describe() - カテゴリ別の集計:
df.groupby('Category')['Price'].mean() - 手軽な可視化:
df['Price'].hist()またはdf.groupby('Category')['Price'].mean().plot(kind='bar')
もっと高度な数値計算や、高速な配列処理がしたいなら NumPy が便利です。とはいえ多くのビジネス用途では、pandas だけで必要な作業の 95% はまかなえます。
参考資料: pandas に初めて触れるなら、10 Minutes to pandas に目を通しておくとよいです。
Python でスクレイピングを成功させるためのベストプラクティス
ウェブスクレイピングは強力ですが、その分だけ責任もついて回ります。ブロックやもめごとを避け、プロらしく取得するためのチェックリストを紹介します。
- robots.txt と利用規約を尊重する。 そのサイトがスクレイピングを認めているか、必ず確かめましょう(PromptCloud)。
- サーバーに負荷をかけすぎない。 リクエストの間隔を空けて(
time.sleep(2)など)、人間らしいペースで取りましょう。 - 自然なヘッダーを使う。 User-Agent を設定し、ブラウザらしく見せます。
- エラーをていねいに扱う。 try/except でくるみ、失敗したリクエストは再試行します。
- 必要ならプロキシを使う。 大規模に取るなら、IP ブロックを避けるためプロキシプールも検討します。
- 倫理と法令を守る。 許可のない個人データや、ログインの向こう側にあるコンテンツには手を出さないでください。
- 作業を記録する。 何を、どこから、いつ取ったのかをメモに残しておきます。
- 公式 API があるなら、そちらを優先する。 HTML を直接削るより、もっと素直な方法があることもあります。
さらに踏み込んだヒントは、究極のウェブスクレイピングガイドもどうぞ。
まとめと押さえておきたいポイント
Python によるウェブスクレイピングは、ウェブの雑然とした情報を構造化された使えるデータへ変える強力な武器です。requests、BeautifulSoup、Scrapy、Selenium を書くにせよ、Thunderbit のようなノーコードツールに任せるにせよ、データを取り新しい気づきを引き出す手段はそろっています。
心に留めておきたいこと:
- まずは小さく始める——大きなプロジェクトに挑む前に、1 ページだけ取ってみましょう。
- 目的に合った道具を選ぶ(基本は BeautifulSoup、規模なら Scrapy、動的サイトは Selenium、ノーコードなら Thunderbit)。
- pandas と NumPy でデータを整え、分析する。
- いつでも責任と倫理を忘れずにスクレイピングする。
さて、ご自身でも試してみませんか。手始めに今日のニュース見出しや商品リストでも取ってみて、未加工のページがどれだけ早くきれいなスプレッドシートに変わるか確かめてください。コードを飛ばしたいなら、Thunderbit をダウンロードして、面倒なところは AI に丸投げしましょう。
チュートリアルやコツ、ウェブスクレイピングの知識をもっと知りたいなら、Thunderbit Blog をのぞいてみてください。
よくある質問
1. ウェブスクレイピングとは何ですか。なぜ Python が人気なのですか。
ウェブスクレイピングとは、ウェブサイトからデータを自動で抜き出すことです。Python が人気なのは、読みやすい文法、BeautifulSoup・Scrapy・Selenium といった強力なライブラリ、そして手厚いコミュニティの支えがあるからです(PromptCloud)。
2. ウェブスクレイピングには、どの Python ライブラリを使えばいいですか。
シンプルで静的なページには BeautifulSoup、大規模または複数ページのクロールには Scrapy、動的サイトや JavaScript の多いサイトには Selenium を使いましょう。用途に応じて、それぞれに持ち味があります(IPRoyal)。
3. JavaScript でデータを読み込むサイトは、どう扱えばいいですか。
JavaScript で描画されるコンテンツには、Selenium(または Playwright)でブラウザを再現し、データが読み込まれるのを待ってから抜き出します。ネットワーク通信をのぞくと、裏側の API エンドポイントが見つかることもあります。
4. Thunderbit とは何ですか。どうやってスクレイピングを楽にするのですか。
Thunderbit は、コードなしでどんなウェブサイトからでもデータを取れる AI 搭載の Chrome 拡張機能です。AI が抽出項目を提案し、サブページやページネーションをさばき、データを Excel、Google Sheets、Notion、Airtable へそのまま書き出します。
5. Python で取ったデータは、どう整えて分析すればいいですか。
pandas を使えば、重複削除、欠損値の処理、データ型の変換、分析までこなせます。NumPy は数値計算に向いています。可視化なら、pandas と Matplotlib を組み合わせると手軽にグラフを作れます(10 Minutes to pandas)。
それでは、よいスクレイピングを。あなたのデータが、いつもきれいで、構造化されていて、すぐ使える状態でありますように。
AIウェブスクレイパーを試す Get Started Free
さらに詳しく




