

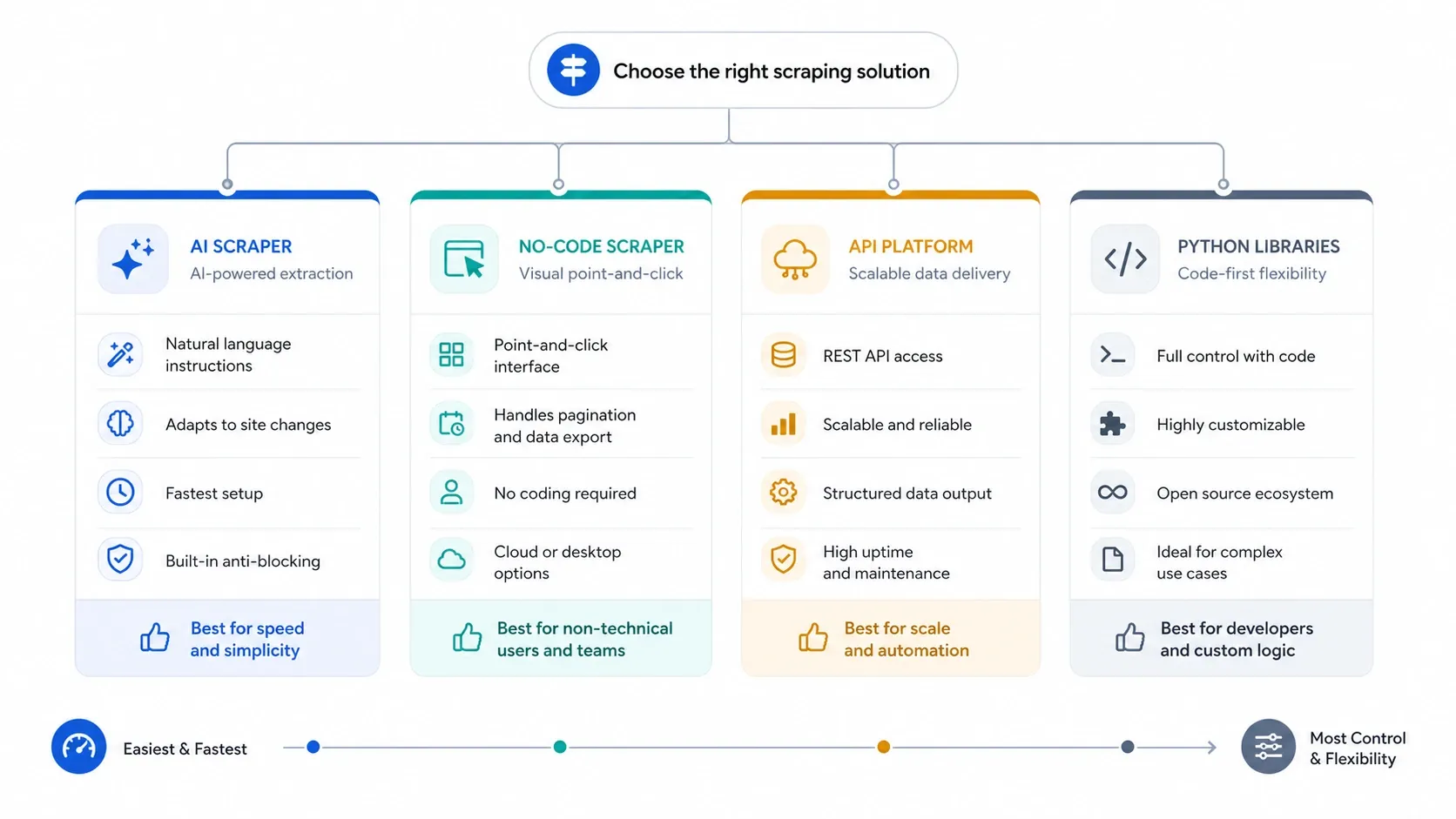
2026年にウェブデータが必要になったとき、難しいのはもう「これってスクレイピングできるんだっけ?」ではありません。「どのツール層を選べば、無駄なセットアップ、保守、インフラコストを最小限に抑えながら、使えるデータを手元に届けられるか」 — 問いの中身がここに移りました。だからこそ、このページは最初に「適合性」で整理しています。高速な AI ウェブスクレイパー、繰り返しのブラウザー作業に向くノーコードツール、拡張性と対ボット対策に強い API、そして完全な制御を求めるチーム向けの Python ライブラリ — この4層の使い分けです。
まず結論
- ページからスプレッドシートまでを最短で抜きたいなら AI ウェブスクレイパーを。
- より明確なページネーション、スケジュール実行、ログイン対応、繰り返し可能なタスク管理が必要なら ノーコードスクレイパーを。
- レンダリング、対ボット保護、同時実行、ブロック回避率が UI の分かりやすさより重要なら スクレイピング APIを。
- リクエスト、パース、ブラウザー自動化、リトライ、デプロイまで全部を自分たちで握りたいなら Python ライブラリを。
多くのビジネスチームでありがちな失敗は、早すぎる段階で下位レイヤーに降りてしまうこと。まずは安定して仕事をこなせる「いちばん軽いツール」から始めて、ワークフロー上どうしても必要になったタイミングで、AI →ノーコード→API→コード、と段階的に降りていきましょう。
完全版のビジュアル素材はこちらからダウンロードできます: website scraping tools visual pack。
ひと目で分かる比較表:ウェブスクレイピングツール一覧
以下の価格情報は、2026年5月12日時点で公式の製品ページ、料金ページ、ドキュメントを直接確認したものです。ベンダーが個別見積もりや従量課金を採用している場合は、無理に月額を横並びにせず、料金モデルそのものを説明しています。
| ツール | カテゴリ | 最適用途 | 2026年版リストに入れた理由 | 価格の目安(2026年5月確認) |
|---|---|---|---|---|
| Thunderbit | AIウェブスクレイパー | 営業、オペレーション、EC、不動産 | ウェブページから構造化テーブルまでの最短ルート | 無料プラン、有料プラン、法人向け料金 |
| Kadoa | AI抽出プラットフォーム | データチーム、継続運用の大規模案件 | 自己修復型のエージェント風抽出ワークフローに強い | 無料評価、従量課金、エンタープライズプラン |
| Octoparse | ノーコードスクレイパー | アナリスト、定常運用の仕事 | 成熟したクラウドスクレイピングと視覚的タスクビルダー | 無料プラン、Standard は月額69ドルから、上位プランあり |
| ParseHub | ローコードスクレイパー | 技術寄りの非エンジニア、研究者 | 難しいサイト向けの柔軟なナビゲーションロジック | 無料プラン、有料プランは月額189ドルから |
| Web Scraper | ブラウザー型ノーコードスクレイパー | 初心者、軽量な反復作業 | 直感的なサイトマップモデルと任意のクラウド層 | 無料拡張機能、Cloud は月額50ドルから |
| Browse AI | ノーコードのロボットスクレイパー | 監視用途、スプレッドシート中心のチーム | 繰り返し監視と変更アラートに強い | 無料プラン、有料プラン、マネージドプラン |
| Bardeen | AIブラウザー自動化 | GTM、RevOps 自動化 | スクレイピングが大きなワークフローの一部なら最適 | 無料プラン、Basic は月額10ドルから、Premium と Enterprise あり |
| ScrapeStorm | AI支援のビジュアルスクレイパー | すばやい視覚設定を求めるユーザー | 手動セレクタとAI支援のちょうど中間にある存在 | 無料トライアル、有料プラン、エンタープライズ価格 |
| ScraperAPI | スクレイピングAPI | リクエスト量を拡大する開発者 | シンプルなAPIに加え、プロキシ、CAPTCHA、レンダリングを代行 | 7日間トライアル、有料は月額49ドルから |
| Bright Data Web Scraper | エンタープライズ向けスクレイピングプラットフォーム | 調達重視、コンプライアンス重視の案件 | この中で最も広いデータ収集スタック | 製品ベースおよび従量課金 |
| Zyte | API + 対ボット対策スタック | 開発者、データチーム | ブラウザー操作、JSレンダリング、IPローテーションに強い | 5ドル分の無料トライアルクレジット、従量課金プラン |
| ZenRows | スクレイピングAPI | スタートアップ、開発チーム | 導入しやすく、対ボット対策APIとして使いやすい | 無料トライアル、Developer は月額69ドルから |
| ScrapingBee | スクレイピングAPI | JavaScriptが多いサイトを扱うチーム | レンダリングが最大の課題なら有効 | 無料トライアル、有料は月額49ドルから |
| Selenium | オープンソースのブラウザー自動化 | QA的なフロー、操作量の多いスクレイピング | 正確なユーザー操作が重要な場面では今も有効 | 無料・オープンソース |
| Beautiful Soup | Pythonパースライブラリ | 軽量なPythonスクレイピング | 雑なHTMLを扱うときに最も使いやすいパーサー | 無料・オープンソース |
| Playwright | モダンなブラウザー自動化 | 最新のWebアプリ、開発チーム | スクリプト型ブラウザー・スクレイピングの現代的な最有力候補 | 無料・オープンソース |
| urllib3 | Python HTTPライブラリ | 低レベルのリクエスト制御をしたい開発者 | 転送挙動を直接管理したいときの基盤として有用 | 無料・オープンソース |
正しいウェブスクレイピングツールの選び方
ブランドを比較する前に、次の4つの軸で見てください。
- 最初の有用な出力までの速さ
実用に足るテーブルがすぐに出てこないツールは、多くのビジネス用途ではその時点で不利です。 - 保守の負担
レイアウトが変わるたびに壊れる安いスクレイパーは、実態としてちっとも安くありません。 - スケールの上限
ブラウザー拡張は週50ページには最適でも、月500万リクエストには付き合えません。 - ワークフローとの相性
RevOps に最適なスクレイパーが、プラットフォームエンジニアにも最適とは限りません。
意思決定の枠組みは、チームが想像するほど複雑ではありません。
- リード、一覧、商品ページをセレクタ操作なしで取りたいなら、まずは AIから。
- 繰り返し実行、クラウド実行、より明確な制御が必要になったら ノーコードのビジュアルビルダーへ。
- 対ボット対策、JavaScript レンダリング、同時実行が本当の課題になったら APIへ。
- 全部を自分たちで握りたいなら Python ライブラリを選び、その保守負担も引き受ける。
速い業務フローに強いおすすめAIウェブスクレイパー
設定はできるだけ少なく、スプレッドシートにそのまま貼れるデータが欲しい — そういう用途なら、まず真っ先に試すべきカテゴリです。
1. Thunderbit
Thunderbit は、非エンジニアにとっていまも最も入りやすい選択肢です。強みは抽象的な「AI」というラベルではなく、セットアップの往復をぎゅっと圧縮できる点。ページを開いて、AI に項目を提案させ、必要ならサブページで補完して、結果をチームがすでに使っているツールへそのまま流す — この流れがほぼ摩擦なく回ります。
- 最適用途: 営業の見込み客開拓、EC 監視、不動産収集、ブラウザー内で完結するオペレーション業務。
- 際立つ点: 雑然としたページから構造化テーブルへ最短で到達できること。
- 注意点: クローラー級のロジックや、相当に特殊なエンジニアリングフローが必要なら、いずれは API かコードに移行することになります。
- 価格の目安: 無料プラン、セルフサービスの有料プラン、法人向け料金。
AI ファーストのスクレイピングが自分の業務に足りるかどうか — そこを最短で確かめたい方には、いまだにこのデモがいちばん速い答え合わせになります。
2. Kadoa
Kadoa は、このリストの中ではよりインフラ寄りの AI 選択肢。自己修復型の抽出と、ブラウザー拡張では捌ききれない規模の反復ジョブが必要なら、筋の通った選択になります。
- 最適用途: データチーム、社内インテリジェンス案件、大規模な継続抽出ワークロード。
- 際立つ点: エージェント的なオーケストレーションと、保守削減に関する強い訴求。
- 注意点: 単発の素早いスクレイピング用途には、多くのビジネスユーザーにとって少し重め。
- 価格の目安: 無料評価、従量課金、エンタープライズプラン。
繰り返し作業に強いおすすめノーコードウェブスクレイピングツール
スクレイピングが定常業務になってくると、1回あたりの速さよりも、視覚的なワークフロービルダーとクラウド実行の重要度がぐっと上がってきます。
3. Octoparse
Octoparse は、ブラウザー拡張では物足りないけれど、カスタム開発案件を組むほどでもない、という温度感の場面で、いまも最有力級のノーコードツールです。価値の源泉は、クラウド実行・テンプレート・成熟したビジュアルタスクビルダーの組み合わせ。
- 最適用途: アナリスト、価格調査チーム、実務上重要な定常収集ジョブ。
- 際立つ点: ブラウザープラグイン以上の深さがありつつ、コードに追い込まれずに済むこと。
- 注意点: その柔軟性の対価として、AI ファーストツールより学習コストはやや高め。
- 価格の目安: 無料プラン、Standard は月額69ドルから、上位有料プランあり。
AI 中心のツールに投資する前に、より伝統的なノーコード環境を試したい方には、こちらの公式紹介もまだ十分参考になります。
4. ParseHub
ParseHub がいまも使われ続けているのは、軽量な AI スクレイパーより、段階的なタスクロジックを求めるチームがまだしっかり存在しているから。見た目はこのカテゴリで最先端というわけではないものの、柔軟性は確かにあります。
- 最適用途: 研究者、ジャーナリスト、多少の準備を許容できる技術寄りの非エンジニア。
- 際立つ点: 多くの初心者向けツールより、条件分岐ロジックとナビゲーション制御に厚みがあること。
- 注意点: 学習に時間がかかり、新興製品ほど今どきの使い心地ではない。
- 価格の目安: 無料プラン、有料プランは月額189ドルから。
5. Web Scraper
Web Scraper は、「プラットフォームを買わずに基本を学ぶ」ためのすっきりした選択肢のひとつ。サイトマップモデルが性に合うなら、いまも有力な入り口です。
- 最適用途: 初心者、個人プロジェクト、小規模なブラウザー中心の作業。
- 際立つ点: 立ち上げが分かりやすく、ローカル拡張からクラウドプランへ素直につながること。
- 注意点: より適応的なロジックや、強いブロック回避が必要になった瞬間、限界が見えてきます。
- 価格の目安: 無料拡張機能、Cloud は月額50ドルから。
6. Browse AI
Browse AI は、スクレイピングと監視を同じ温度で扱いたいなら、いまも有力な1本。ロボットモデルは、「このページを見張って、何が変わったか教えて」と考えるビジネスユーザーにとって、直感的にハマります。
- 最適用途: 競合監視、価格追跡、スプレッドシート中心のチーム。
- 際立つ点: こなれた導入体験、定期監視、自動化しやすい出力。
- 注意点: 複雑で大量のジョブでは、API 中心の構成より早めにコスト高になりがち。
- 価格の目安: 無料プラン、有料プラン、マネージドプラン。
単発抽出ではなく「ページ監視」を評価しているチームにとっては、この短い公式概要を見ておくだけでも、十分な判断材料になります。
7. Bardeen
Bardeen は、純粋なスクレイピングの深さよりも「その後に何が起きるか」に重心がある製品。ウェブ抽出が、より大きなブラウザー自動化ワークフローの一工程である場面でいちばん強く効いてきます。
- 最適用途: GTM オペレーション、リードルーティング、CRM への受け渡し、ブラウザー内自動化。
- 際立つ点: スクレイピングを軸に据えた、ワークフロー自動化のストーリーの強さ。
- 注意点: 抽出精度だけが評価軸になる場面では、いちばんきれいな選択肢とは言いがたい。
- 価格の目安: 無料プラン、Basic は月額10ドルから、Premium と Enterprise あり。
8. ScrapeStorm
ScrapeStorm は、AI 支援を使いたい一方で、より伝統的な視覚型スクレイピング環境にも期待している、というユーザーにとって、いまも有用な中間地点を埋めてくれます。
- 最適用途: ディレクトリのスクレイピング、EC ページ収集、視覚設定型の定常ジョブ。
- 際立つ点: 多くの古いビジュアルツールより、立ち上げが楽なこと。
- 注意点: カテゴリ上位製品ほどの洗練はなく、難しいサイトでは対応範囲が狭く感じることも。
- 価格の目安: 無料トライアル、有料プラン、エンタープライズ価格。

規模と対ボット対策が重要なときのおすすめスクレイピングAPI
本当に効いてくる制約が「どうやってデータを取るか」ではなく「負荷がかかっても安定運用できるか」に切り替わったら、このカテゴリへ移るタイミングです。
9. ScraperAPI
ScraperAPI は、プロキシやリクエスト成功率のことをもう考えたくない、という開発者にとって、いまも最も気楽な API ファースト製品のひとつです。
- 最適用途: 試作から本番まで一気にスケールさせたい開発者。
- 際立つ点: シンプルな API に加えて、プロキシ、CAPTCHA、レンダリングを丸ごと面倒みてくれること。
- 注意点: パース、リトライ、その先のデータ品質は自分で担う必要あり。
- 価格の目安: 7日間トライアル、有料は月額49ドルから。
10. Bright Data Web Scraper
Bright Data は、ブロック回避力、プロキシ在庫、コンプライアンス姿勢、マネージドオプション — このあたりが「シンプルさ」より重要になるシーンで頼れる、重量級の選択肢です。
- 最適用途: エンタープライズ規模の収集、コンプライアンス重視の案件。
- 際立つ点: プロキシからマネージド収集製品まで、比較対象の中で最も広いスタックを持っていること。
- 注意点: まだ比較的単純なワークフローしかないのに、過剰に買ってしまうケースが意外と多い。
- 価格の目安: 製品ベースおよび従量課金。
11. Zyte
Zyte は、ブラウザー操作、JS レンダリング、IP ローテーション、対ボット対策を1つのプラットフォームとしてまとめて扱いたい開発チームにとって、いまも本格的な選択肢です。
- 最適用途: エンジニア主導のスクレイピング案件、反復可能な抽出システム。
- 際立つ点: 強力な検知回避スタックと、API ファーストのワークフロー。
- 注意点: ビジネスユーザーよりも、エンジニアリングが主体性を持つチーム向け。
- 価格の目安: 5ドル分の無料トライアルクレジット、従量課金プラン。
12. ZenRows
ZenRows は、エンタープライズ向けの購買プロセスを通らずに対ボット対策の API を使いたい、というニーズに、API カテゴリでもかなり気持ちよく応えてくれます。開発者体験は良好です。
- 最適用途: スタートアップ、開発者、軽量な社内ツールチーム。
- 際立つ点: 導入のハードルが比較的低く、対ボット対策の訴求も強いこと。
- 注意点: あくまで API 製品なので、アプリケーションロジックや QA の負担は残ります。
- 価格の目安: 無料トライアル、Developer は月額69ドルから。
13. ScrapingBee
ScrapingBee は、特に JavaScript が多いサイトで、レンダリング済みのページが本当に必要で、しかもインフラ作業を減らしたい、というシーンに向いています。
- 最適用途: 動的サイトをスクレイピングしつつ、レンダリング処理を外部化したい開発者。
- 際立つ点: ヘッドレスブラウジングとプロキシを、シンプルな API で扱える気軽さ。
- 注意点: インフラ作業は減らせますが、優れたスクレイピングロジックの必要性そのものは消えません。
- 価格の目安: 無料トライアル、有料は月額49ドルから。
カスタム構成向けのおすすめPythonウェブスクレイピングライブラリ
このグループがいまも正解になるのは、利便性より制御が重要で、チームが保守を自分たちで担う覚悟ができているとき。
14. Selenium
Selenium は最新のブラウザーツールではありませんが、ユーザー操作の忠実さが生のスループットより重要、という場面では、いまも十分に現役です。
- 最適用途: 操作量の多いフロー、QA との重なりがあるケース、ブラウザー挙動自体が本質的な課題のサイト。
- 際立つ点: 成熟したエコシステムと、広いブラウザー対応。
- 注意点: 多くのスクレイピング用途では、新しい自動化スタックより重く・遅くなりがち。
- 価格の目安: 無料・オープンソース。
15. Beautiful Soup

Beautiful Soup は、Python スクレイピングスタックの中で最も扱いやすいパーサーのひとつ。完全なスクレイピングプラットフォームではないものの、雑な HTML を「使える構造」に変える最短の手段、というポジションはいまも変わりません。
- 最適用途: 軽量な Python ジョブ、静的 HTML ページ、素早い試作。
- 際立つ点: 認知負荷の低さと、パースの柔軟性。
- 注意点:
requests、ブラウザー層、あるいはクローラーと組み合わせて使うのが前提。単体ではパースしかしません。 - 価格の目安: 無料・オープンソース。
16. Playwright
Playwright は、いまの Web で堅牢なブラウザー自動化が必要な開発チームに対する、こちらの標準的なおすすめです。
- 最適用途: JavaScript が多いサイト、最新のブラウザー自動化、コードを書くことに慣れているチーム。
- 際立つ点: 強力な待機挙動、マルチブラウザー対応、すっきりした API。
- 注意点: 同時実行、セレクタ、ブラウザーインフラ、データ検証はやはり自社管理が必要。
- 価格の目安: 無料・オープンソース。
17. urllib3
urllib3 がこの一覧に入るのは、上位の抽象化よりも転送挙動を直接握りたいチームが、いまも一定数いるから。初心者向けスクレイパーではないものの、自前のスタックを組むときには確実に役立つ基盤ライブラリです。
- 最適用途: リトライ、プロキシ、セッション、HTTP 挙動を細かく制御したい開発者。
- 際立つ点: 軽量で信頼性が高く、インフラとして広く使われていること。
- 注意点: スタックの大半を自分たちで組むことになります。
- 価格の目安: 無料・オープンソース。
まず試す価値がある無料ウェブスクレイピングツール
購入前に試したい、という方に最初のとっかかりとしておすすめなのは、Thunderbit、Octoparse、ParseHub、Web Scraper、Browse AI、Bardeen、Selenium、Beautiful Soup、Playwright、そして urllib3。無料体験を回すだけでも、自分たちに必要なスクレイパーの「種類」はかなり見えてきます。初日に完璧な機能一覧を揃えるより、そっちのほうが大事なケースは結構多いです。
チーム別の私のおすすめ候補

- 営業、オペレーション、EC チーム: まずは Thunderbit。監視のほうがサブページ補完より重要なら、次に Browse AI を比較対象に。
- アナリスト、定常的な手作業オペレーター: まずは Octoparse。よりカスタムなタスクロジックが必要なら ParseHub を検討。
- GTM 自動化チーム: スクレイピング結果を CRM、Sheets、ブラウザーワークフローに直接流したいなら Bardeen。
- 社内ツールを作る開発チーム: どこまでスタックを自前で持ちたいかに応じて、ScraperAPI、ZenRows、Zyte、Playwright。
- エンタープライズデータ案件: ここでは Bright Data と Zyte が本格的なインフラの話になり、保守負担の削減が主目的なら Kadoa が AI 主導の代替候補です。
いつ下位レイヤーへ移るべきか
次のアップグレード経路で考えてみてください。
- 繰り返し性やエッジケースの限界に当たるまでは、AI ウェブスクレイパーのまま進める。
- スケジュール実行、ページネーション、クラウド実行が「1クリックの簡単さ」より重要になったら、ノーコードビルダーへ。
- ブロック回避率、レンダリング、同時実行がボトルネックになったら、APIへ。
- ベンダーの抽象化コストが、システム全体を自分たちで持つコストを上回ったら、Python ライブラリへ。
多くのチームは、この順番を間違えます。最初に作り込みすぎて、後から「もっと軽いツールで十分だったな」と気づく — 現場でいちばんよく見るパターンです。
最後に
2026年に最適なウェブスクレイピングツールというのは、機能一覧がいちばん長いもの、ではありません。あなたのチームにとって最小限の保守負担で、正確なデータを次のワークフローへ流し込めるもの — これに尽きます。だからこそ、オペレーターには AI ファーストのツールが勝ち続けるし、繰り返しのブラウザー作業ではノーコードツールがいまも価値を持ち、スケールとブロック対策が重要なら API が強く、高い制御性が必要な領域では Python ライブラリが主役、という構図になります。
今週中に使えるデータが欲しいなら、まずはシンプルに始める。いまのワークロードが、ブロック回避率、ブラウザーレンダリング、エンジニアリング上の制御こそが本当の課題だと示しているなら、習慣ではなく意図をもって下位レイヤーへ降りる — このスタンスで十分です。
実際に仕事をこなせる、最も軽いスクレイパーから始めよう Get Started Free
よくある質問
1. 2026年に、非技術者にとって最適なウェブスクレイピングツールは何ですか?
多くの非技術チームにとっては、Thunderbit や Browse AI のような AI ファーストツールがいまも最速。セットアップ、セレクタ作業、保守負担を一気に減らせます。
2. JavaScript が多いサイトや対ボット保護されたサイトには何を選ぶべきですか?
その場合はたいてい、ScraperAPI、Bright Data、Zyte、ZenRows、ScrapingBee、Playwright、Selenium のいずれかがブラウザー拡張より適しています。
3. AI スクレイパーが進化した今でも、ノーコードのスクレイピングツールは必要ですか?
はい。Octoparse、ParseHub、Web Scraper、Browse AI は、より明確なタスク管理、定期実行、ブラウザー上で見えるデバッグが必要な場面で、いまも欠かせない存在です。
4. 開発チームにはどのツールが最も合いますか?
ScraperAPI、Zyte、ZenRows、ScrapingBee、Playwright、Selenium、Beautiful Soup、そして urllib3 は、エンジニアリングがワークフローを管理する場合にいちばん自然に馴染みます。
関連資料




