2026年にウェブスクレイピングツールを比較検討するなら、たいてい求めているのは哲学ではありません。信頼できる候補を手早く絞り込み、ビジネスユーザー向けツールとエンジニア向けの重厚なスタックを見分け、間違った製品を買わないだけの根拠を確保したいはずです。このページは、そのためにあります。
私はThunderbitの共同創業者兼CEO、Shuai Guanです。AIを活用したスクレイピングとブラウザ自動化に毎日取り組んでいるので、一般的な順位付けよりも「適合性」を重視しています。つまり、営業チームやオペレーションチームが今週すぐに前進できるツールはどれか、開発者向けワークフローに属するのはどれか、そして規模や対ボット対策のインフラが主課題になったときに初めて意味を持つのはどれか、という視点です。
ひとまずの結論
ルート選定だけ知りたいなら、まずは次の基準で考えてください。
- 最小限の設定で、ウェブサイトからスプレッドシートまで最短でたどり着きたいなら、AIウェブスクレイパーを選ぶ。
- コードを書かずに、タスク制御やスケジュール実行、クラウド実行をもっと細かく管理したいなら、ノーコードスクレイパーを選ぶ。
- チームにレンダリング、プロキシローテーション、対ボット処理、あるいは社内プロダクトへの組み込みが必要なら、APIプラットフォームを選ぶ。
- 完全な制御を求め、保守、セレクター、インフラ、障害対応まで自分たちで持てるなら、オープンソースライブラリを選ぶ。
この記事では20ツールすべてを紹介しますが、推奨ロジックは意図的にシンプルです。まずは、自分のワークフローを確実に回せる中で最も軽いツールから始め、保守負担、ブロック、スケールが本当に必要になるまで、必要以上に下位スタックへ進まないことです。
クイック比較表:2026年のベスト・ウェブスクレイピングツール
以下の価格とプラン体系は、2026年5月7日時点で公式製品ページまたは料金ページを確認しています。ベンダーが従量課金や個別見積もりを採用している場合は、架空の定価を示す代わりに、その料金モデルを説明しています。
| ツール | 種類 | 最適な用途 | 2026年のリストに入った理由 | 料金モデル(2026年5月確認) |
|---|---|---|---|---|
| Thunderbit | AIウェブスクレイパー | 営業、オペレーション、EC、不動産 | 非エンジニアにとって最短ルート。AIによる項目提案、サブページ、エクスポート、ブラウザ+クラウドのワークフロー | 無料枠、有料プラン、法人向け個別料金 |
| Browse AI | AIウェブスクレイパー | ウェブサイトを監視するビジネスユーザー | ノーコードロボット、監視機能、スプレッドシート/API形式の出力が強力 | 無料プラン、有料プラン、プレミアムのマネージド層 |
| Bardeen | AI自動化+スクレイピング | Revenue Ops、ブラウザワークフロー | スクレイピングがより大きな自動化フローの一部なら特に強い | 無料プランと有料プラン |
| Diffbot | AI抽出プラットフォーム | エンタープライズ、データチーム | AI抽出と大規模な構造化データワークフローを両立したいときに最も適する | エンタープライズ向け料金 |
| Instant Data Scraper | 軽量ブラウザスクレイパー | 一般ユーザー、すぐに表を抜きたいとき | 目に見えるリストや表をCSVへすばやく取り込む最も簡単な方法の一つ | 無料 |
| Octoparse | ノーコードスクレイパー | 分析担当、継続案件の多いオペレーションチーム | クラウド抽出、ブロック回避、テンプレートを備えた成熟したビジュアルビルダー | 無料プラン、有料は月額69ドルから、法人向け個別料金 |
| ParseHub | ローコードスクレイパー | ロジックとデスクトップ制御が必要な分析担当 | 柔軟なプロジェクトロジックとネストしたナビゲーション。AI先行ツールより学習コストは高め | 無料プランと有料プラン |
| Web Scraper | ノーコードスクレイパー | 初心者、軽量なクラウドジョブ | サイトマップベースのスクレイピングとブラウザ起点の導入がしやすい | 無料拡張機能、有料クラウドプラン |
| Data Miner | ブラウザスクレイパー | リサーチ担当、グロース担当 | ブラウザ内で素早くレシピベースの抽出をしたいときに今でも有用 | 無料プランと有料プラン |
| Apify | API+Actorプラットフォーム | 技術チーム、ハイブリッド運用 | ブラウザ拡張を超えたときに、再利用可能なActorのエコシステムとカスタム実行環境が非常に強い | 無料プラン、月額29ドルから+従量課金、より上位の有料層 |
| ScrapingBee | スクレイピングAPI | JSが重いサイトを扱う開発者 | レンダリングとプロキシ処理を、自前でブラウザ層を作らずに扱いたいときに向く | 無料トライアルと有料プラン |
| ScraperAPI | スクレイピングAPI | すばやくリクエストをスケールしたい開発者 | シンプルなAPI、試用クレジット、構造化された商品設計、インフラの肩代わりのしやすさ | 7日間トライアルで5,000クレジット、月額49ドルから |
| Bright Data | エンタープライズAPI+プロキシプラットフォーム | 大量処理、コンプライアンス重視の案件 | ブロック解除、プロキシ、マネージド取得が単純さより重要なときに最も広いデータ収集スタック | 従量課金と製品別課金 |
| Oxylabs | エンタープライズAPI+プロキシプラットフォーム | スクレイピングをインフラとして買うチーム | 大規模収集、特に価格、SEO、市場調査系のワークロードに強い | Web Scraper APIは月額49ドルから。広範なプロキシ料金は変動 |
| Zyte | API+対ボット対策スタック | 開発チーム、データチーム | APIファーストの抽出に、強力なブラウザ、ローテーション、検知回避の仕組みを求めるなら適する | 5ドル分の無料クレジット付きトライアル、従量ベースの契約 |
| Selenium | オープンソースのブラウザ自動化 | QA風の自動化、難しい操作フロー | ユーザー操作の忠実性がスループットより重要なときに今でも有用 | 無料のオープンソース |
| BeautifulSoup4 | オープンソースのパーサー | 初心者、軽量パース | フルのスクレイピング基盤ではなく、シンプルなスタックのパーサーとして最適 | 無料のオープンソース |
| Scrapy | オープンソースのクロールフレームワーク | 本番運用のカスタムクローラー | 自前でパイプラインを持ちたいなら、力と成熟度のバランスが最も良い | 無料のオープンソース |
| Puppeteer | オープンソースのブラウザ自動化 | Node中心のスクレイピングとブラウザスクリプト | チームがすでにChrome/Nodeの世界で動くことに慣れているなら最適 | 無料のオープンソース |
| Playwright | オープンソースのブラウザ自動化 | モダンなマルチブラウザ自動化 | 現代的なブラウザ自動化では、開発者体験の良さも含めて最も洗練された選択肢の一つ | 無料のオープンソース |
これらのツールをどう評価したか
私は4つの基準で見ました。
- 最初の成功スクレイプまでの速さ
非技術系の担当者がすぐに使えるデータを取れないなら、その時点で重要な問題です。 - 保守負担
立ち上げが速くても、サイトが変わるたびに壊れるなら意味がありません。 - スケール上限
週50ページには最適でも、月500万リクエストでは最悪というツールもあります。 - ワークフローへの適合性
Revenue Opsチームに最適なツールが、データプラットフォームチームにも最適とは限りません。
その結果は、普遍的な順位表ではありません。まず適切な種類のツールを選び、そのうえでそのクラスの中から製品を選ぶための意思決定ページです。
あなたに本当に必要なウェブスクレイピングツールの種類は?
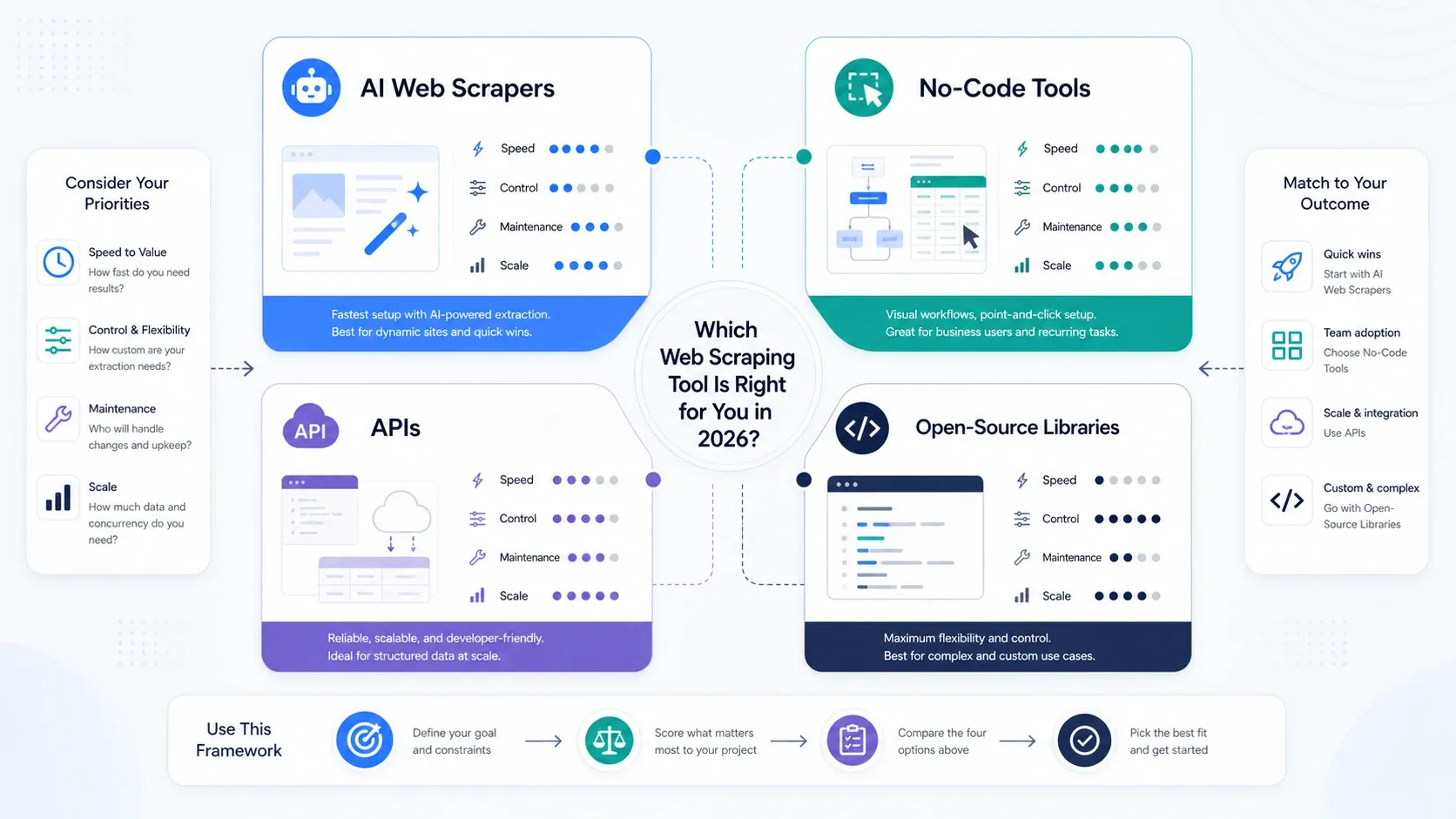
- 主な目的が運用スピードなら、AIウェブスクレイパーを選びましょう。
- ページ送り、スケジュール実行、繰り返し可能なタスク制御を重視するなら、ノーコードツールを選びましょう。
- レンダリング、ローテーション、ブロック解除性能がボトルネックなら、APIとスクレイピングプラットフォームを選びましょう。
- 操作性より制御性を重視し、スタックを社内で支えられるなら、オープンソースライブラリを選びましょう。
チーム内で、スクレイピングをオペレーション側で持つべきか、それともエンジニアリング側で持つべきかまだ迷っているなら、まずはAIツールかノーコードツールから始めてください。最初からスタックを過剰設計するより、実際のジョブを回したほうが、何が重要かを早く学べます。
ビジネスチーム向けのベストAIウェブスクレイパー
ここでは、できるだけ手間をかけずに、スプレッドシートにそのまま入れられるデータを得たいときに、私なら最初に見るツールを紹介します。
1. Thunderbit
Thunderbitは、セレクター、ブラウザスクリプト、スクレイピングインフラを学ばずに構造化データを抽出したいチームにとって、ここで最も簡単な選択肢です。ワークフローは、AIによる項目提案、サブページの補完、そしてビジネスユーザーが普段使っているツールへの直接エクスポートを中心に設計されています。
- 最適な用途: 営業、オペレーション、EC、不動産など、ブラウザ中心のチーム。
- 際立つ理由: 非エンジニアに対して、ここに挙げたどのツールよりもセットアップ時間を短縮できること。
- 注意点: 深いカスタムクローラーロジックや、極めて専門的なエンジニアリング制御が必要なら、最終的にはより下位のスタックへ進むことになります。
- 料金モデル: 無料枠、セルフサービスの有料プラン、法人向け料金。
2. Browse AI
Browse AIは、ポイント&クリックでの設定と継続監視を求めるビジネスユーザーにとって、今でも有力な候補です。スクレイピングと変化検知を同じくらい重視する場合、このロボットモデルは特に便利です。
- 最適な用途: 価格ページ、競合ページ、繰り返し使うリスト抽出の監視。
- 際立つ理由: 洗練された導入体験、事前構築済みロボット、ウェブサイトからスプレッドシートまたはAPI風の出力までの明確な導線。
- 注意点: 複雑で大量のジョブは、APIファーストのスタックより早く高コストまたは運用上の煩雑さを招くことがあります。
- 料金モデル: 無料プラン、有料プラン、プレミアム/マネージド層。
3. Bardeen
Bardeenが最も魅力的なのは、スクレイピングが広いブラウザ自動化フローの一部にすぎないときです。CRM、スプレッドシート、アウトバウンド系ワークフローへデータを流し込むなら、純粋な抽出性能よりも自動化の強さが重要になります。
- 最適な用途: Revenue Ops、リード系ワークフロー、ブラウザネイティブなタスク自動化。
- 際立つ理由: 純粋な抽出ツールよりも、ワークフロー自動化のストーリーが強いこと。
- 注意点: スクレイピングそのものが複雑で、かつミッションクリティカルな場合には最適とは言えません。
- 料金モデル: 無料プランと有料プラン。
4. Diffbot
Diffbotは、最安・最簡単な道を探す人向けではなく、エンタープライズ規模でAI抽出が必要なチーム向けです。構造化データの品質と大規模取り込みが、手元での細かな制御より重要なときに意味を持ちます。
- 最適な用途: エンタープライズのデータチーム、コンテンツインテリジェンス、大規模抽出プロジェクト。
- 際立つ理由: コンピュータビジョン型の抽出と、構造化出力への強い志向。
- 注意点: 小規模チームには過剰で、軽量な用途では扱いづらいことがあります。
- 料金モデル: エンタープライズ向けプランと個別営業。
5. Instant Data Scraper
Instant Data Scraperが今も候補に入るのは、いま見えている表、ディレクトリ、リストをその場で取り込みたいケースがまだまだ多いからです。プラットフォームではありませんが、それで十分な場面は多いです。
- 最適な用途: 単発の抽出、すぐ欲しいリードリスト、シンプルなディレクトリ、可視テーブル。
- 際立つ理由: 条件に合うページなら、ほぼ摩擦なく使えること。
- 注意点: 自動化の幅が狭く、深さも限定的で、高度なワークフローには向きません。
- 料金モデル: 無料。
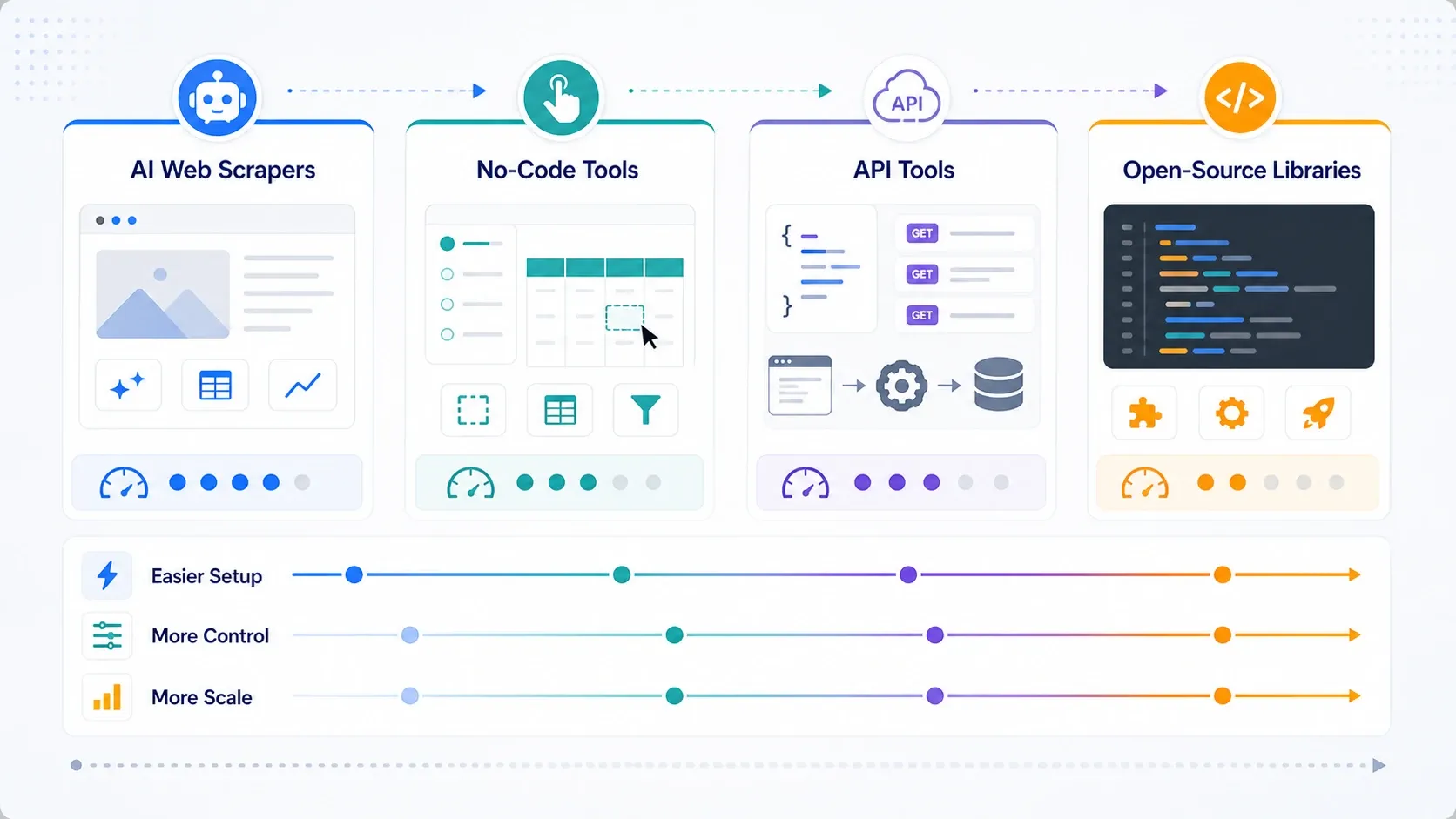
繰り返し実行する仕事向けのベストノーコード・ウェブスクレイピングツール
たまに使うだけのスクレイプを超えると、ビジュアルビルダーとクラウド実行が重要になります。
6. Octoparse
Octoparseは、クラウド実行、テンプレートの充実度、そしてブラウザ拡張では難しいタスク管理が必要な場合、今でも最有力のノーコードプラットフォームの一つです。
- 最適な用途: 分析担当、価格担当、継続的な収集ジョブを回す運用担当。
- 際立つ理由: 成熟したタスクビルダー、クラウド抽出、ブロック回避機能、豊富なテンプレート群。
- 注意点: AI先行のブラウザツールより強力な分、セットアップの手間も増えます。
- 料金モデル: 無料プラン、有料は月額69ドルから、法人向け個別料金。
7. ParseHub
ParseHubは、AIスクレイパーより細かい制御が欲しいが、コードベースを作るのは避けたい人に今でも有用です。速さではなく、粘り強さに応えてくれるツールです。
- 最適な用途: 学習コストの高さを受け入れられる分析担当、技術に明るい運用担当。
- 際立つ理由: 柔軟なナビゲーションロジックと、軽量なブラウザツールより高い制御性。
- 注意点: 特に動きの速いビジネスチームにとっては、新しい製品より重たく感じられます。
- 料金モデル: 無料プランと有料プラン。
8. Web Scraper
Web Scraperは、サイトマップモデルが好きで、まずはブラウザで始めて、あとからクラウドスケジューリングへ育てたい人にとって、今でも妥当な入口です。
- 最適な用途: 初心者、趣味プロジェクト、小規模な反復ジョブ。
- 際立つ理由: 親しみやすいサイトマップのワークフローと、ブラウザ起点で導入しやすい点。
- 注意点: より適応的な抽出ロジックが必要になると、すぐに限界が見えてきます。
- 料金モデル: 無料のブラウザ拡張機能と有料クラウドプラン。
9. Data Miner
Data Minerは、完全なスクレイピングプラットフォームというより、素早く使える抽出ユーティリティとして理解するのが適切です。レシピ駆動の作業は、多くのリサーチや見込み客開拓の仕事で今でも役立つため、このリストに入る価値があります。
- 最適な用途: リサーチ担当、グロースチーム、ブラウザ側での素早いエクスポート作業。
- 際立つ理由: レシピモデル、低摩擦、簡単なブラウザ出力。
- 注意点: 本格的なプラットフォーム規模のスクレイピングには向きません。
- 料金モデル: 無料プランと有料プラン。
規模とブロック対策が本当の課題になるときのベストAPIプラットフォーム
この層では、エンジニアリングチームが「このページをどうやってスクレイプするか?」ではなく、「どうすれば大量処理でも安定させられるか?」を考え始めます。
10. Apify
Apifyは、再利用可能なスクレイパーのマーケットプレイスと、自分のコードを実行する場所の両方が欲しいなら、このグループで最も柔軟なプラットフォームです。ノーコード探索と開発者実行の橋渡しが、競合の多くよりうまくできています。
- 最適な用途: ハイブリッドチーム、開発者主導のスクレイピング、再利用可能な自動化ワークフロー。
- 際立つ理由: Actorエコシステムとカスタム実行環境の組み合わせが、珍しい広さを生むこと。
- 注意点: 一度カスタム化すると、再びエンジニアリングの世界に戻り、シンプルさの利点は薄れます。
- 料金モデル: 無料プラン、月額29ドルから+従量課金、より大きな利用層とエンタープライズ。
11. ScrapingBee
ScrapingBeeは、実際のニーズが「レンダリング済みページを渡して、面倒なインフラは全部任せたい」であるときに良い選択肢です。JSが重い対象にもよく合います。
- 最適な用途: インフラ作業にあまり時間を割きたくない、動的サイトを扱う開発者。
- 際立つ理由: レンダリング、プロキシ、ブラウザ自動化をまとめたシンプルなAPI。
- 注意点: これはインフラサービスなので、パース、リトライ、下流の品質管理は自分で担う必要があります。
- 料金モデル: トライアルと有料プラン。
12. ScraperAPI
ScraperAPIは、短期間でスケールしたいときに、プロキシ管理とリクエスト成功率の負担を外部化する最も簡単な方法の一つです。
- 最適な用途: 試作品から大量処理へ素早く移行したい開発者。
- 際立つ理由: わかりやすいAPI、試用クレジット、構造化された商品設計、スケール用の階層。
- 注意点: 他のAPIファースト製品と同様、パースやデータ検証に関するエンジニアリング判断は不要になりません。
- 料金モデル: 7日間トライアルで5,000クレジット、月額49ドルから。
13. Bright Data
Bright Dataは、ブロック解除能力、プロキシ在庫、マネージド取得が、ツールのシンプルさより重要なときの重量級オプションです。
- 最適な用途: エンタープライズ案件、コンプライアンス重視の大規模収集、マネージドデータ取得。
- 際立つ理由: プロキシ、スクレイパー、ブラウザ、データセット製品の幅広さ。
- 注意点: 高価で、コアワークフローがまだ単純な場合は過剰購入しやすいです。
- 料金モデル: API、プロキシ、マネージドサービス全体で従量課金と製品別課金。
14. Oxylabs
Oxylabsは、ブラウザツールとしてではなく、インフラとしてスクレイピングを買いたいチームにとって、今でも強力な選択肢です。特に、信頼性と購買プロセスの成熟度が重要な場面で存在感があります。
- 最適な用途: エンタープライズ収集、価格監視、SEO監視、市場調査。
- 際立つ理由: 強固なインフラのストーリー、豊富なプロキシ、より明確なエンタープライズ向け営業体制。
- 注意点: 気軽なセルフサービス型ワークフローを望むチームにはあまり向きません。
- 料金モデル: Web Scraper APIは月額49ドルから。その他の製品は単位と利用量で変動。
15. Zyte
Zyteは、対検知、ブラウザ操作、JSレンダリング、ローテーションIPを、ひとつのAPIファーストなストーリーの中で使いたい開発・データチームに、引き続き真剣に検討する価値があります。
- 最適な用途: 反復可能な抽出システムを構築する技術チーム。
- 際立つ理由: ブラウザ操作、JSレンダリング、IPローテーション、対ボット姿勢が一つのスタックにまとまっていること。
- 注意点: 非技術者よりも、エンジニアリングの責任を持つチームに向いています。
- 料金モデル: 5ドル分の無料クレジット付きトライアルと、従量ベースの月額契約。
完全な制御を求める開発者向けのベストオープンソースライブラリ
スクレイパースタックをエンドツーエンドで自分たちのものにしたいなら、2026年に役立つ最重要の構成要素はこれです。
16. Selenium
Seleniumは、QA風の操作忠実性、レガシーなブラウザ自動化ワークフロー、あるいは非常に明示的なユーザーフロー制御が必要なときに今でも有用です。
- 最適な用途: 操作が多い自動化、QAとの重なり、クロール速度よりブラウザ挙動が重要なサイト。
- 際立つ理由: 成熟したエコシステムと幅広いブラウザ対応。
- 注意点: 多くのスクレイピング用途では、新しいブラウザツールより重く、遅くなりがちです。
- 料金モデル: 無料のオープンソース。
17. BeautifulSoup4

BeautifulSoupはフルのスクレイピングプラットフォームではありませんが、軽量なワークフローで厄介なHTMLをパースする最も簡単な方法の一つであり続けています。
- 最適な用途: 初心者、短いスクリプト、パーサー先行の作業。
- 際立つ理由: シンプルなAPIと低い認知負荷。
- 注意点: リクエスト系、ブラウザ系、クローラー系のツールと組み合わせて使ってください。単体ではパーサーにすぎません。
- 料金モデル: 無料のオープンソース。
18. Scrapy
Scrapyは、いくつかのスクリプトではなく、本物のクローラーフレームワークが必要なときの最適解であり続けています。
- 最適な用途: 本番用のカスタムクローラーと、社内で所有するデータパイプライン。
- 際立つ理由: 高性能、パイプライン、ミドルウェア、長期的な拡張性。
- 注意点: 実際のエンジニアリング負担があり、JSが重い対象では補助ツールが必要になることが多いです。
- 料金モデル: 無料のオープンソース。
19. Puppeteer
Puppeteerは、Chromiumとブラウザスクリプトを直接制御したいNode中心のチームにとって、今でも強い選択肢です。
- 最適な用途: Nodeベースのスクレイピング、スクリーンショット、ブラウザ自動化タスク。
- 際立つ理由: Chromiumの挙動を直接かつ強力に制御できること。
- 注意点: Playwrightよりブラウザ対応の幅が狭く、規模が大きくなるとリソース消費も依然として重いです。
- 料金モデル: 無料のオープンソース。
20. Playwright
Playwrightは、チームがコードを書き、Seleniumより新しい抽象化を求めるなら、モダンなブラウザ自動化のデフォルト推奨です。
- 最適な用途: 現代的なブラウザ自動化、JSが重いサイト、開発者体験を重視するチーム。
- 際立つ理由: 強力なマルチブラウザ対応、信頼性の高い待機動作、きれいなAPI。
- 注意点: ブラウザインフラ、並列実行、セレクターの変化、データ検証は、引き続き自分たちで持つ必要があります。
- 料金モデル: 無料のオープンソース。
チーム別の私の厳選候補
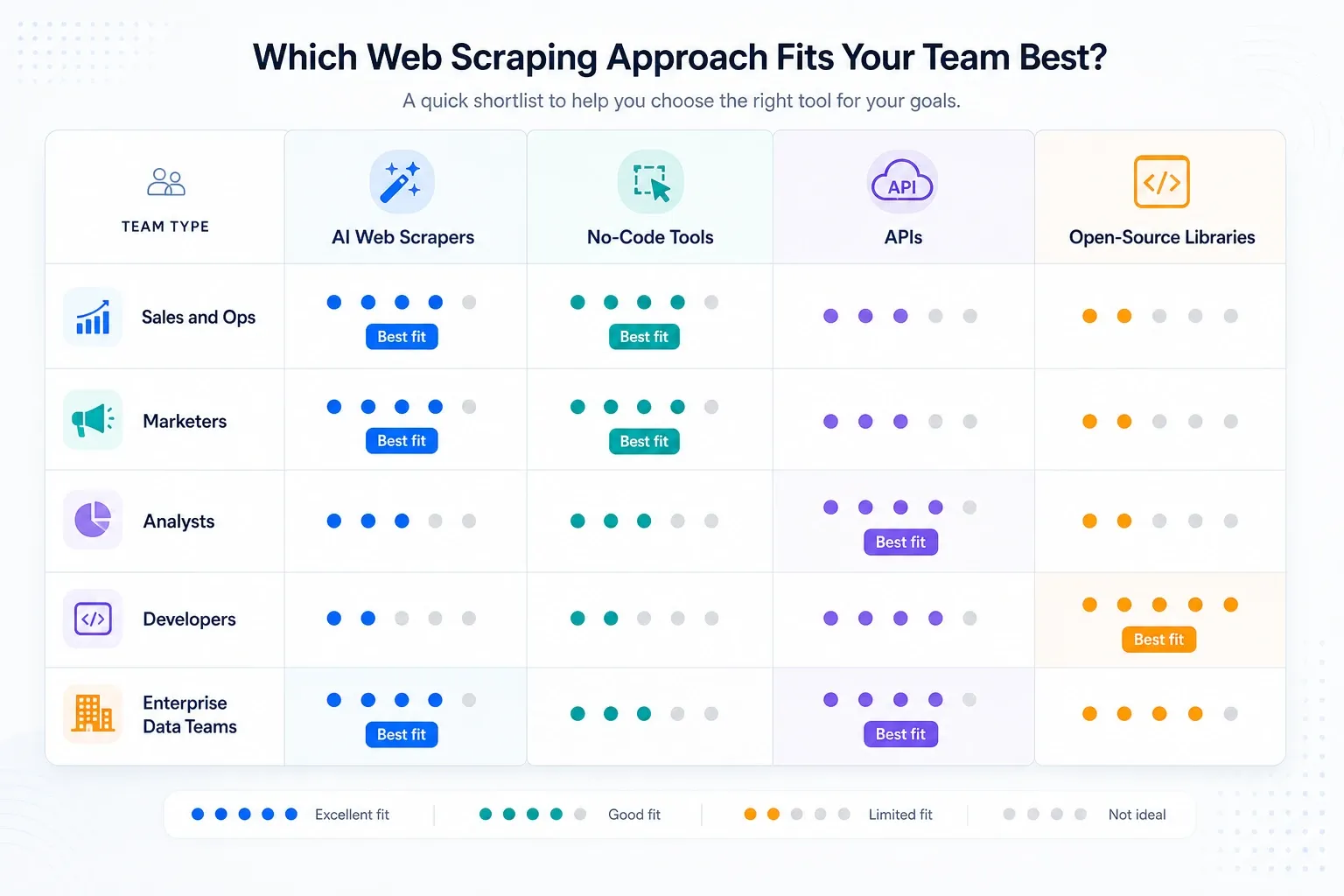
- 営業・オペレーションチーム: まずはThunderbit。監視がサブページ補完より重要ならBrowse AIも検討。
- 分析・リサーチチーム: 反復ジョブがブラウザ拡張ツールの手に負えなくなってきたら、まずOctoparse。
- 自動化重視のGTMチーム: スクレイピングが広いワークフローの一工程にすぎないならBardeen。
- 社内ツールを作る開発チーム: どれだけスタックを自分たちで持ちたいかに応じて、Apify、Zyte、ScraperAPI、Playwright。
- エンタープライズのデータプログラム: Bright Data、Oxylabs、Diffbot、Zyteが本格的なインフラの検討対象です。
下位スタックへ移るべきタイミング
次のルールで考えましょう。
- 繰り返し性や例外ケースの限界に当たるまでは、AIツールに留まる。
- スケジューリング、ページ送り、ブロック回避、クラウド実行が、ワンクリックの簡単さより重要になったら、ノーコードツールへ移る。
- ブロック解除率、JSレンダリング、並列実行が本当のボトルネックになったら、APIへ移る。
- ベンダーの抽象化コストが、スタック全体を自分で持つコストより高くなったら、オープンソースライブラリへ移る。
多くのチームは、早すぎる段階で下位スタックへ移行しがちです。これは私が最もよく見るミスの一つです。
最後に
多くの非技術チームにとって、2026年の正解は「最も強力なスクレイパー」ではありません。必要なデータを、最小の保守で次のワークフローへ運べるツールです。だからこそ、AIファーストのツールは運用担当者に引き続き強く、APIやオープンソースのスタックは、明確なスケール要件を持つ技術チームにより適しています。
ページから構造化出力までの最短ルートを求めるなら、まずThunderbitから始めてください。すでに重いインフラが必要だと分かっているなら、最初からAPI層や開発者層へ進んでかまいません。複雑さと洗練を混同しないことが大切です。
FAQ
1. 2026年に、非技術ユーザーに最適なウェブスクレイピングツールは何ですか?
多くの非技術ユーザーにとっては、ThunderbitやBrowse AIのようなAIファーストのツールが最短で実用データにたどり着けます。セレクター作業、初期設定の手間、保守負担を減らせるからです。
2. サイトがJavaScript重視だったり、リクエストを強くブロックしたりする場合は何を選ぶべきですか?
マネージドサービスを求めるか、直接エンジニアリングを持ちたいかに応じて、ScrapingBee、ScraperAPI、Zyte、Bright Data、Oxylabs、Playwright、Seleniumへ移るとよいでしょう。
3. AIウェブスクレイパーが進化した今でも、ノーコードツールは必要ですか?
はい。OctoparseやParseHubのようなノーコードツールは、タスクロジック、クラウド実行、繰り返しジョブの管理をより明示的に制御したいときに、今でも重要です。
4. エンジニアリングチームにとって最も自然なツールはどれですか?
Apify、Zyte、ScraperAPI、Scrapy、Playwright、Puppeteer、Seleniumが、開発者がワークフローを持つ場合の自然な選択肢です。
5. 調べすぎず、素早く候補を絞るにはどうすればいいですか?
まず、ベンダーではなくツールの種類を決めてください。AIの手軽さ、ノーコードの制御性、APIのインフラ、オープンソースの所有性のどれが必要かを判断し、その層の中で製品を比較します。
関連コンテンツ