ウェブにはデータがあふれていますが、問題は、それを手作業で集めるのが、ペンキが乾くのを眺めるのと同じくらい退屈で、しかも生産性が低いことです。2025年には、企業が扱うWebコンテンツはこれまで以上に増え、平均的な企業の1日あたりのウェブデータ取り込み量は、2020年の1.2TBから2025年には8TBへと跳ね上がっています()。営業、マーケティング、eコマース、オペレーションのどの領域でも、素早く、構造化され、正確なウェブデータは「あると便利」ではなく、業務に欠かせないものです。正直なところ、延々とコピペを続ける時間なんて、誰にもありません。
だからこそ、コンテンツクローリングツールの人気が急速に高まっているのです。AI搭載のChrome拡張からエンタープライズ向けプラットフォームまで、こうしたツールを使えば、面倒な作業をまとめて自動化でき、雑然としたWebページをきれいなスプレッドシート、データベース、リアルタイムダッシュボードに変えられます。私はSaaSと自動化の分野で長年経験を積んできましたが、はっきり言えます。適切なツールは時間を節約するだけでなく、チームの働き方そのものを変えます。そこで今回は、2025年の効率的なウェブスクレイピングに最適なコンテンツクローリングツール18選を、各ツールの独自性、さまざまなビジネスニーズへの適合性、そして業務フローに合った選び方に焦点を当てて紹介します。
企業が優れたコンテンツクローリングツールを必要とする理由
リードリストの作成、競合価格の監視、市場の温度感の把握を手作業でやったことがあるなら、データ収集があっという間に悪夢になることをご存じでしょう。遅く、ミスも起こりやすく、やっと終わる頃にはデータがすでに古くなっていることさえあります。だからこそ、2025年までに70%超の企業が自動ウェブ抽出を導入し、手作業の負担を約60%削減しているのです()。
コンテンツクローリングツールは、Webサイトから構造化データを自動で抽出し、次のようなことを可能にします。
- 新しいリードをCRMに直接取り込む(ディレクトリからのコピペはもう不要)
- 競合価格や在庫をリアルタイムで監視する
- レビュー、ニュース、SNSでの言及を集約してマーケティングに活用する
- 調査や分析用のカスタムデータセットを作成する
- 定期的なデータ取得をスケジュールして継続レポートに活かす
しかもROIは本物です。ウェブスクレイピングを導入した企業は、2020年から2025年の間に合計で5億ドル以上を節約し、業務効率も20〜40%向上したと報告しています()。要するに、コンテンツクローリングツールは、チームを単純作業から解放し、戦略に集中させてくれるのです。
優れたコンテンツクローリングツールの選定基準
すべてのウェブスクレイパーが同じではありません。この一覧を作るにあたり、私は営業、マーケティング、オペレーション、調査など、実際に成果を必要とするビジネスユーザーの視点でツールを見ました。特に重視したのは次の点です。
- 使いやすさ: 非技術系のユーザーでもすぐ始められるか。ポイント&クリックの操作画面やAI支援はあるか。
- 自動化と機能: ページネーション、サブページ、スケジューリング、動的コンテンツに対応しているか。クラウドで高速かつ大規模に実行できるか。
- データ出力と連携: Excel、CSV、Google Sheets、Airtable、Notionへの出力やAPI連携ができるか。
- 拡張性: 単発作業にも、大規模で継続的な案件にも向いているか。
- カスタマイズ性: 抽出ロジックの調整、カスタム項目の追加、扱いの難しいサイトへの対応ができるか。
- コンプライアンスとプライバシー: GDPR、CCPA、サイト利用規約を守るうえで役立つか。
- サポートとコミュニティ: ドキュメント、サポート、ユーザーコミュニティがあり、トラブル時に助けになるか。
- コスト: 無料プランやトライアルはあるか。価格は規模や予算に見合っているか。
もちろん、特に注目したのはThunderbitです。これは私たちのチームが開発したツールで、AI搭載のウェブスクレイピングをビジネスユーザーが最も簡単に始められる方法だと、私は本気で考えています。
効率的なウェブスクレイピングに最適なコンテンツクローリングツール18選
AIによる手軽さから開発者向けの強力なツールまで、幅広く見ていきましょう。
1. Thunderbit
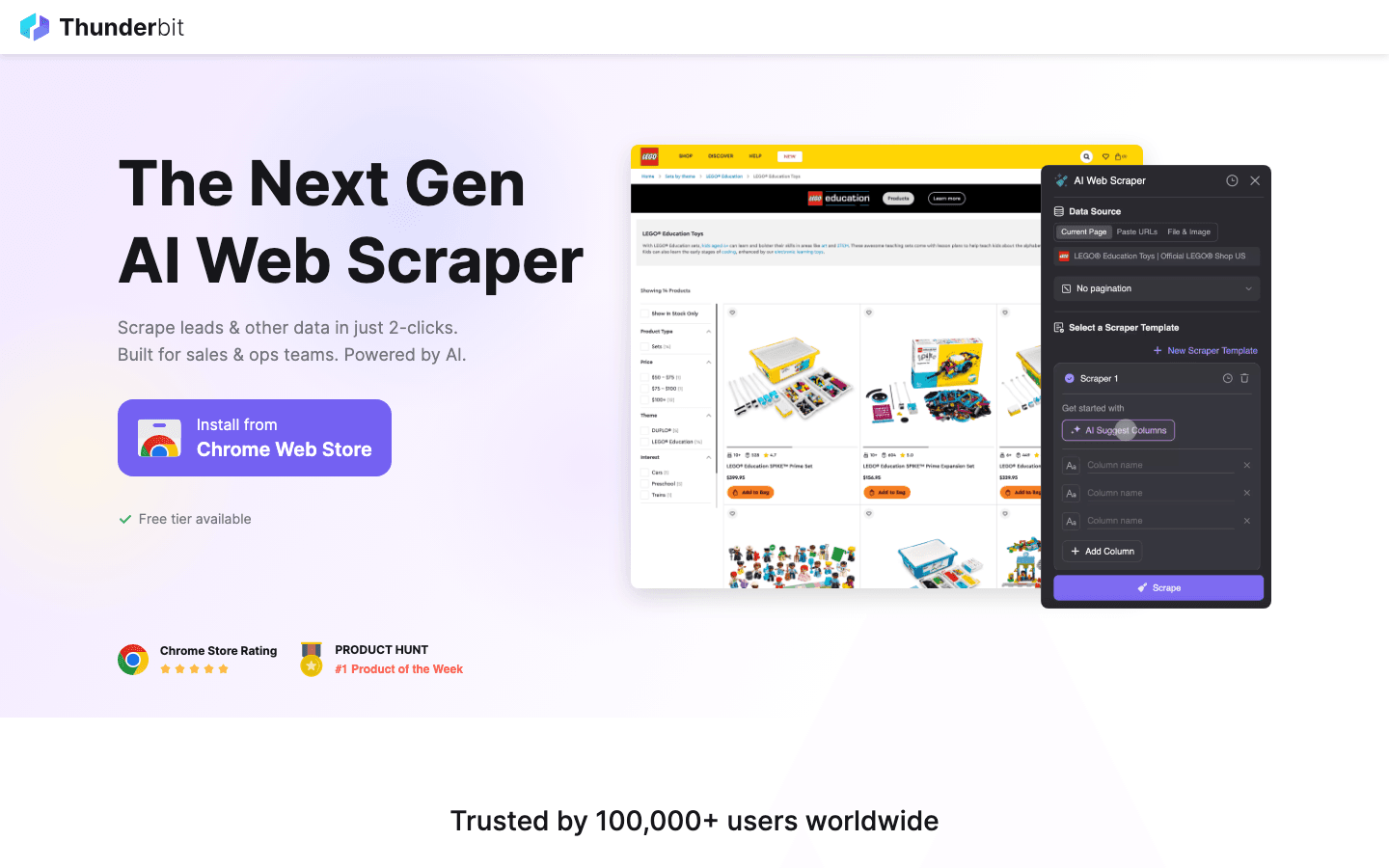 は、素早く成果を出したいビジネスユーザー向けに設計されたAIウェブスクレイパーのChrome拡張です。最大の特長はAI Suggest Fields。Webページを開いて「AI Suggest」をクリックするだけで、ThunderbitのAIがページを読み取り、抽出項目を提案し、スクレイパーを自動でセットアップしてくれます。コードもセレクター調整も不要。クリックして、抽出して、エクスポートするだけです。
は、素早く成果を出したいビジネスユーザー向けに設計されたAIウェブスクレイパーのChrome拡張です。最大の特長はAI Suggest Fields。Webページを開いて「AI Suggest」をクリックするだけで、ThunderbitのAIがページを読み取り、抽出項目を提案し、スクレイパーを自動でセットアップしてくれます。コードもセレクター調整も不要。クリックして、抽出して、エクスポートするだけです。
- サブページ抽出: 商品詳細やプロフィール詳細のような各サブページを自動で巡回し、データセットを拡張できます。リード獲得やEC調査に最適です。
- ページネーションとテンプレート: 複数ページの一覧に対応し、Amazon、Zillow、Instagramなどのサイト向けに即使えるテンプレートも用意されています。
- 無料データ出力: Excel、Google Sheets、Airtable、Notion、CSV、JSONへ無料で出力可能。課金の壁はありません。
- AI Autofill: AIでオンラインフォーム入力を自動化でき、スクレイピングを超えて業務自動化まで広げられます。
- クラウドとブラウザの両対応: 公開サイトには高速なクラウド抽出、ログインが必要なセッションにはブラウザモードを選べます。
- 料金: 6ページまで無料(トライアルなら10ページ)で、月額15ドルからの有料プランがあります。
Thunderbitは、技術的なハードルなしでデータ収集を自動化したい営業、マーケティング、オペレーションチームに最適です。何年も前にこんなツールがあればよかった、と思えるほどで、今では誰でも数分でリードリストを作成したり、競合を監視したりできます。
2. Scrapy
 は、開発者向けのオープンソースの強力ツールです。Pythonベースのフレームワークで、カスタムスパイダーを作成し、大規模にクロールとデータ抽出を行えます。高速性と柔軟性を重視して設計されており、非同期クロール、カスタムパイプライン、プロキシローテーション、データベースやAPIとの連携に対応しています。
は、開発者向けのオープンソースの強力ツールです。Pythonベースのフレームワークで、カスタムスパイダーを作成し、大規模にクロールとデータ抽出を行えます。高速性と柔軟性を重視して設計されており、非同期クロール、カスタムパイプライン、プロキシローテーション、データベースやAPIとの連携に対応しています。
- 最適な用途: 大規模で複雑、または継続的なスクレイピング案件を構築する開発者やデータエンジニア。
- 強み: 完全な制御性、高い拡張性、大きなコミュニティ、実戦で鍛えられた信頼性。
- 弱点: コードを書かない人には学習コストが高い。視覚的な操作画面はありません。
Pythonに慣れていて、堅牢で拡張性の高いクローラーを作りたいなら、Scrapyはまさに基準となる存在です。
3. Octoparse
 は、ビジュアルなドラッグ&ドロップ操作に対応した、ノーコードのクラウド型ウェブスクレイパーです。ポイント&クリックでデータを選択し、ページネーションを設定でき、AI支援のパターン検出でセットアップも素早く進められます。
は、ビジュアルなドラッグ&ドロップ操作に対応した、ノーコードのクラウド型ウェブスクレイパーです。ポイント&クリックでデータを選択し、ページネーションを設定でき、AI支援のパターン検出でセットアップも素早く進められます。
- 事前構築テンプレート: Amazon、Twitter、Google Mapsなどの人気サイトから数分でデータを抽出できます。
- クラウド抽出とスケジューリング: Octoparseのサーバー上でジョブを実行し、定期タスクを設定し、大規模案件にも対応できます。
- 出力形式: CSV、Excel、JSON、API連携。
- 料金: 制限付きの無料プランあり。有料プランは月額約75ドルから。
Octoparseは、コードを書かずに強力なスクレイピングを行いたいビジネスアナリストや非プログラマーに最適です。
4. ParseHub
 は、動的コンテンツや複雑なサイト構造の扱いに強いビジュアルウェブスクレイパーです。ポイント&クリックのインターフェースで、条件分岐、ループ、多段階ナビゲーションを使ったワークフローを構築できます。
は、動的コンテンツや複雑なサイト構造の扱いに強いビジュアルウェブスクレイパーです。ポイント&クリックのインターフェースで、条件分岐、ループ、多段階ナビゲーションを使ったワークフローを構築できます。
- 動的コンテンツ: ドロップダウン、無限スクロール、インタラクティブ要素に対応。
- クラウド実行とローカル実行: クラウドでは有料で実行でき、小規模作業ならローカルでも使えます。
- 出力: CSV、Excel、JSON、API。
- 料金: 充実した無料プランあり。有料プランは月額49ドルから。
ParseHubは、扱いの難しいWebサイトに対して柔軟さとパワーを求める非エンジニアにぴったりです。
5. Data Miner
 は、テンプレートベースで素早く抽出できるChrome/Edge拡張です。15,000以上のWebサイト向けに5万件超の公開抽出レシピがあり、ページによってはワンクリックで抽出できます。
は、テンプレートベースで素早く抽出できるChrome/Edge拡張です。15,000以上のWebサイト向けに5万件超の公開抽出レシピがあり、ページによってはワンクリックで抽出できます。
- Google Sheets連携: 抽出したデータを直接Sheetsにアップロードできます。
- カスタムレシピ: ポイント&クリックまたはXPathで独自の抽出ロジックを作成できます。
- ページネーションと自動化: 複数ページの抽出や定期実行に対応。
- 料金: 無料プランあり。有料プランは月額19ドルから。
ブラウザ上で素早く小〜中規模のデータ取得をしたいアナリストやマーケターに最適です。
6. WebHarvy
 は、ポイント&クリック操作と自動パターン検出を備えたWindowsデスクトップアプリです。要素を1つクリックするだけで、WebHarvyが同種の項目をまとめて検出し、抽出対象としてハイライトします。
は、ポイント&クリック操作と自動パターン検出を備えたWindowsデスクトップアプリです。要素を1つクリックするだけで、WebHarvyが同種の項目をまとめて検出し、抽出対象としてハイライトします。
- 画像、テキスト、ページネーションに対応: 商品写真、メールアドレス、URLなどを抽出できます。
- デスクトップでのスケジューリング: PC上で抽出を定期実行できます。
- 買い切りライセンス: 1台あたり約199ドル。
定期的な抽出に使える、シンプルでサブスク不要のツールを求める小規模ビジネスに向いています。
7. Import.io
 は、大規模データ抽出向けのエンタープライズ級クラウドプラットフォームです。AIによるデータクレンジング、リアルタイム監視、堅牢なコンプライアンス機能を備えています。
は、大規模データ抽出向けのエンタープライズ級クラウドプラットフォームです。AIによるデータクレンジング、リアルタイム監視、堅牢なコンプライアンス機能を備えています。
- API連携: データをデータベース、BIダッシュボード、アプリケーションへ直接配信できます。
- コンプライアンス: GDPRとCCPAを考慮して設計されています。
- 料金: エンタープライズ契約で高価格帯です。
信頼性が高く、コンプライアンスに配慮され、拡張性のあるウェブデータ基盤を必要とする大企業に最適です。
8. Apify
 は、ウェブスクレイピング用の「アクター」(ボット)を扱えるクラウド自動化プラットフォーム兼マーケットプレイスです。よく使うサイト向けの事前構築アクターを使うことも、JavaScriptやPythonで自作することもできます。
は、ウェブスクレイピング用の「アクター」(ボット)を扱えるクラウド自動化プラットフォーム兼マーケットプレイスです。よく使うサイト向けの事前構築アクターを使うことも、JavaScriptやPythonで自作することもできます。
- マーケットプレイス: LinkedIn、Amazonなど向けの、すぐ使えるスクレイパーが数百件そろっています。
- スケジューリングとAPI: API経由でアクターを実行、予約、連携できます。
- 料金: 無料プランあり。有料利用は月額49ドルから。
自動化、柔軟性、コミュニティ主導のソリューションを求める開発者や技術に強いチームに理想的です。
9. Visual Web Ripper
 は、高度な一括データ抽出向けのデスクトップツールです。ワークフロービルダーを使って多段階のクロールを設計し、大規模案件を自動化できます。
は、高度な一括データ抽出向けのデスクトップツールです。ワークフロービルダーを使って多段階のクロールを設計し、大規模案件を自動化できます。
- スケジューリングと自動化: 設定した間隔でプロジェクトを実行できます。
- データベース連携: SQL、Excel、CSV、XML、JSONへ直接出力可能。
- 買い切りライセンス: 約349ドル。
社内で大量データを抽出したいITチームやパワーユーザーに最適です。
10. Dexi.io
 は、共同作業のウェブデータ案件向けクラウドプラットフォームです。ワークフロー自動化、スケジューリング、チーム管理機能を備えています。
は、共同作業のウェブデータ案件向けクラウドプラットフォームです。ワークフロー自動化、スケジューリング、チーム管理機能を備えています。
- ワークフロー自動化: チーム間でデータパイプラインを構築し、共有できます。
- APIと出力: データベース、クラウドストレージ、BIツールと連携できます。
- 料金: カスタム見積もり。チームや企業向けです。
継続的で共同作業を伴うデータ案件を管理する組織に向いています。
11. Content Grabber
 は、代理店や企業向けのプロフェッショナルグレードのスクレイピングツールです。高度な自動化、エラー処理、ホワイトラベル対応まで備えています。
は、代理店や企業向けのプロフェッショナルグレードのスクレイピングツールです。高度な自動化、エラー処理、ホワイトラベル対応まで備えています。
- スクリプトとカスタマイズ: C#またはVB.NETで細かく制御できます。
- エラー復旧とログ記録: 大規模ジョブでも安定稼働できるよう設計されています。
- エンタープライズ向け料金: 高価格帯ですが、無料トライアルがあります。
クライアント向けに、再現性の高いカスタムスクレイピングソリューションを構築したい代理店や企業に最適です。
12. Helium Scraper
 は、ビジュアル抽出とスクリプトの柔軟性を両立したデスクトップツールです。多くの作業はポイント&クリックで行えますが、必要に応じてカスタムJavaScriptで高度なロジックも組めます。
は、ビジュアル抽出とスクリプトの柔軟性を両立したデスクトップツールです。多くの作業はポイント&クリックで行えますが、必要に応じてカスタムJavaScriptで高度なロジックも組めます。
- 動的コンテンツ対応: AJAXが多いサイトも抽出できます。
- データクレンジングと変換: カスタムワークフロー用の組み込みスクリプトを備えています。
- 買い切りライセンス: 約99ドル。
サブスクリプションなしで柔軟性を求めるパワーユーザーにぴったりです。
13. Web Scraper
 は、ウェブスクレイピングの入門として多くの人が使う無料のChrome拡張です。サイトマップを定義し、要素をクリックして選択し、CSVやJSONに出力できます。
は、ウェブスクレイピングの入門として多くの人が使う無料のChrome拡張です。サイトマップを定義し、要素をクリックして選択し、CSVやJSONに出力できます。
- 多段階クロール: リンクをたどり、ページネーションを処理し、ネストしたデータも抽出できます。
- ローカル利用は無料: スケジューリングや大規模運用向けの有料クラウド版もあります。
初心者、学生、あるいは小規模作業に手早く使える無料ソリューションを求める人に最適です。
14. Mozenda
 は、コンプライアンス、拡張性、マネージドサービスを重視したエンタープライズ向けクラウドプラットフォームです。ポイント&クリックのインターフェースで、データ抽出用の「エージェント」を作成できます。
は、コンプライアンス、拡張性、マネージドサービスを重視したエンタープライズ向けクラウドプラットフォームです。ポイント&クリックのインターフェースで、データ抽出用の「エージェント」を作成できます。
- マネージドサービス: Mozendaのチームがスクレイパーの構築と保守を代行できます。
- コンプライアンスとサポート: GDPR、CCPA、エンタープライズ要件への対応に強みがあります。
- 料金: 月額約500ドルから。
強力なサポート付きで、すぐに使える拡張可能なウェブデータソリューションを求める大企業に最適です。
15. SimpleIndex
 は、OCRとインデックス作成に重点を置いた、文書およびウェブデータ抽出向けの自動化ツールです。
は、OCRとインデックス作成に重点を置いた、文書およびウェブデータ抽出向けの自動化ツールです。
- 画面OCR: スキャン文書、PDF、さらには画面上のWebフォームからもデータを抽出できます。
- 連携: データベースや文書管理システムへ出力できます。
- 買い切りライセンス: 1ワークステーションあたり数百ドル。
文書とウェブデータのワークフローを組み合わせる組織に向いています。
16. Spinn3r
 は、ブログ、ニュース、SNS向けのリアルタイムコンテンツクローリングプラットフォームです。Firehose APIにより、数百万のソースから新しいコンテンツが継続的に配信されます。
は、ブログ、ニュース、SNS向けのリアルタイムコンテンツクローリングプラットフォームです。Firehose APIにより、数百万のソースから新しいコンテンツが継続的に配信されます。
- スパムフィルタリングと自然言語処理: きれいに構造化されたデータフィードを提供します。
- APIアクセス: 自社システムへ直接組み込めます。
- サブスクリプション料金: 利用量ベースです。
メディア監視、ニュース集約、リアルタイムのコンテンツストリームを必要とする調査チームに最適です。
17. FMiner
 は、複雑なWebクロール向けのビジュアルワークフロービルダーです。ドラッグ&ドロップのインターフェースで、多段階かつ条件分岐のある抽出ルーチンを設計できます。
は、複雑なWebクロール向けのビジュアルワークフロービルダーです。ドラッグ&ドロップのインターフェースで、多段階かつ条件分岐のある抽出ルーチンを設計できます。
- Pythonスクリプティング: 高度なロジック用にカスタムコードを挿入できます。
- クロスプラットフォーム: WindowsとMacで利用可能です。
- 買い切りライセンス: 約168ドルから。
複雑なワークフローを視覚的に組み立てたいアナリストやデータサイエンティストにぴったりです。
18. G2 Webscraper
 (G2で高評価のツールを指す)は、そのシンプルさと効果の高さで評価されています。無料で簡単、しかも大幅に時間を節約できるツール――たとえばWeb ScraperのChrome拡張やData Miner――を好むユーザーが多いのです。
(G2で高評価のツールを指す)は、そのシンプルさと効果の高さで評価されています。無料で簡単、しかも大幅に時間を節約できるツール――たとえばWeb ScraperのChrome拡張やData Miner――を好むユーザーが多いのです。
- 高いユーザーレビュー: 使いやすさと信頼性の評価が高いです。
- すぐに使える: 基本〜中級レベルの作業なら、学習コストがほとんどありません。
「とにかくちゃんと動く」シンプルなスクレイピングツールが欲しいなら、G2で人気のツールは安全な選択です。
比較表:主要コンテンツクローリングツールを一目で比較
| ツール | 使いやすさ | 自動化と機能 | 出力形式 | コンプライアンスとプライバシー | 料金 | 最適な用途 |
|---|---|---|---|---|---|---|
| Thunderbit | ⭐⭐⭐⭐⭐ | AI項目、サブページ、クラウド | Excel、CSV、Sheets、Notion、Airtable、JSON | ユーザー主導 | 無料、月額15ドル〜 | 非エンジニア、営業、オペレーション |
| Scrapy | ⭐ | フルコード、非同期、プラグイン | CSV、JSON、DB | ユーザー管理 | 無料、オープンソース | 開発者、大規模案件 |
| Octoparse | ⭐⭐⭐⭐ | ビジュアル、テンプレート、クラウド | CSV、Excel、JSON、API | ユーザー主導 | 無料、月額75ドル〜 | アナリスト、EC、ノーコードユーザー |
| ParseHub | ⭐⭐⭐⭐ | ビジュアル、動的処理、クラウド | CSV、Excel、JSON、API | ユーザー主導 | 無料、月額49ドル〜 | 非エンジニア、複雑なサイト |
| Data Miner | ⭐⭐⭐⭐⭐ | テンプレート、ブラウザ、Sheets | CSV、Excel、Sheets | ユーザー主導 | 無料、月額19ドル〜 | ブラウザでの素早い作業 |
| WebHarvy | ⭐⭐⭐⭐⭐ | ビジュアル、パターン検出 | Excel、CSV、XML、JSON | ユーザー主導 | 199ドル買い切り | Windowsユーザー、小規模ビジネス |
| Import.io | ⭐⭐⭐⭐ | AI、クラウド、監視 | CSV、API、DB | GDPR、CCPA | エンタープライズ | 大企業、コンプライアンス |
| Apify | ⭐⭐⭐ | クラウド、マーケットプレイス、API | JSON、API、Sheets | ユーザー管理 | 無料、月額49ドル〜 | 開発者、自動化、連携 |
| Visual Web Ripper | ⭐⭐⭐ | ワークフロー、スケジューリング | CSV、Excel、DB | ユーザー主導 | 349ドル買い切り | ITチーム、大量データ |
| Dexi.io | ⭐⭐⭐ | クラウド、チーム、ワークフロー | CSV、API、DB、ストレージ | ユーザー主導 | カスタム | チーム、継続案件 |
| Content Grabber | ⭐⭐⭐ | スクリプト、自動化 | CSV、XML、DB | ユーザー主導 | エンタープライズ | 代理店、カスタムソリューション |
| Helium Scraper | ⭐⭐⭐ | ビジュアル+スクリプト | CSV、DB | ユーザー主導 | 99ドル買い切り | パワーユーザー、独自ロジック |
| Web Scraper | ⭐⭐⭐⭐⭐ | サイトマップ、ブラウザ | CSV、JSON | ユーザー主導 | 無料(ローカル) | 初心者、小規模作業 |
| Mozenda | ⭐⭐⭐ | クラウド、マネージド、コンプライアンス | CSV、API、DB | GDPR、CCPA | 月額500ドル〜 | 大企業、マネージドサービス |
| SimpleIndex | ⭐⭐⭐ | OCR、ウェブ、文書 | DB、DMS | ユーザー主導 | 500ドル買い切り | 文書+ウェブデータ |
| Spinn3r | ⭐⭐ | リアルタイム、API | JSON、API | ユーザー主導 | サブスクリプション | メディア、ニュース、調査 |
| FMiner | ⭐⭐⭐ | ビジュアルワークフロー、Python | CSV、DB | ユーザー主導 | 168ドル買い切り | 複雑で視覚的なワークフロー |
| G2 Webscraper | ⭐⭐⭐⭐⭐ | シンプル、ブラウザ | CSV、JSON | ユーザー主導 | 無料/変動 | シンプルさ、素早い成果 |
ビジネスに最適なコンテンツクローリングツールの選び方
適切なツール選びは、自分たちのニーズをツールの強みに合わせることです。簡単なチェックリストをご紹介します。
- 用途を明確にする: 単発ですか、それとも継続的ですか。小規模ですか、それとも大規模ですか。公開データですか、ログイン後のデータですか。
- スキルレベルに合わせる: ノーコードならThunderbit、Octoparse、ParseHub、WebHarvyから始めるのがよいでしょう。開発者ならScrapyやApifyに進めます。
- 出力要件を確認する: Excel、Sheets、API連携が必要ですか。使いたいツールが対応しているか確認しましょう。
- コンプライアンスを考慮する: 規制産業にいる場合や個人データを抽出する場合は、コンプライアンス機能のあるツール(Import.io、Mozenda)を優先しましょう。
- 小さく始める: 無料プランやトライアルを使って、実データで試してから本格導入しましょう。
- 将来を見据える: 需要は増えそうですか。スケールできるツールを選びましょう。
そして忘れてはいけないのは、時には最もシンプルなツールが最適だということです。ちょっとしたスプレッドシートが欲しいだけなら、物事を複雑にしすぎないでください。
データプライバシーとコンプライアンス:注意すべき点
ウェブスクレイピングは大きな可能性を開きますが、同時に責任も伴います。法令と適切な実務を守るためのポイントは次のとおりです。
- robots.txtとサイトポリシーを尊重する: そのサイトがスクレイピングを許可しているかを必ず確認し、ガイドラインに従いましょう。
- 正当な理由と同意がない限り、個人データの抽出は避ける: GDPRやCCPAは軽く考えてはいけません。
- サーバーに負荷をかけすぎない: 内蔵のスロットリング、遅延、スケジューリングを使い、ブロックされないようにしましょう(インターネットの良き市民でいるためにも大切です)。
- 規制の厳しい業界では、コンプライアンス機能のあるツールを使う: Import.ioとMozendaはGDPR/CCPAを考慮して作られています。
- 作業を記録する: 何を、なぜスクレイピングしたのかを残しておきましょう。特に業務用途や規制対象の案件では重要です。
倫理的なスクレイピングは、持続可能なスクレイピングです。そして、それがビジネスをトラブルから守ります。
まとめ:適切なコンテンツクローリングツールでチームを強化しよう
Webは、あなたのビジネスにとって最大で、最も雑然としたデータベースです。そして適切なコンテンツクローリングツールがあれば、そのデータをようやく実務に活かせます。リードリストの作成、競合の追跡、リアルタイムダッシュボードへの供給など、これら18のツールはあらゆるシナリオ、スキルレベル、予算をカバーしています。
最短で成果を出したいなら、がビジネスユーザー向けの私の最有力候補です。AI搭載、ノーコード、そしてどんなWebサイトでも数分で構造化データに変えられます。とはいえ、どんなニーズであれ、まずは無料トライアルで試し、自分のワークフローに最も合うものを見つけてください。
コピペ作業から卒業する準備はできましたか? をダウンロードして、ウェブデータがどれだけ簡単に扱えるかを体験してください。さらにウェブスクレイピングを深く学びたいなら、でガイド、ヒント、チュートリアルをぜひご覧ください。
よくある質問
1. コンテンツクローリングツールとは何ですか?通常のウェブスクレイパーとどう違いますか?
コンテンツクローリングツールは、Webサイトから構造化データを自動抽出するために設計されたウェブスクレイパーの一種です。すべてのウェブスクレイパーがデータを収集する一方で、コンテンツクローリングツールはスケジューリング、サブページ移動、AIによる項目検出、業務フロー連携といった機能を備えていることが多く、ビジネスチームにとってより強力で使いやすいのが特徴です。
2. 非技術系ユーザーに最適なコンテンツクローリングツールはどれですか?
Thunderbit、Octoparse、ParseHub、Data Miner、WebHarvyはいずれもノーコードユーザーに優れています。なかでもThunderbitは、AIによる簡単さと、Excel、Sheets、Airtable、Notionへの即時出力が際立っています。
3. ウェブスクレイピングを合法かつコンプライアンスに沿って行うにはどうすればよいですか?
サイトの利用規約、robots.txt、GDPRやCCPAのようなプライバシー法を必ず尊重してください。正当な理由と同意がない限り、個人データの抽出は避けましょう。規制の厳しい業界では、コンプライアンス機能を内蔵したツール(例:Import.io、Mozenda)を選ぶのがよいです。
4. これらのツールは、JavaScriptや無限スクロールを使う動的サイトに対応できますか?
はい。Thunderbit、Octoparse、ParseHub、Apify、FMinerのようなツールは、動的コンテンツ、無限スクロール、多段階ナビゲーションに対応できます。複雑なサイトでは、追加設定やクラウド実行が必要になる場合があります。
5. ビジネス向けにコンテンツクローリングツールを選ぶ際、何を考慮すべきですか?
チームの技術力、必要なデータ量、出力・連携要件、コンプライアンス上の懸念、予算を考慮してください。まずは無料プランやトライアルで始め、実際の用途で試してから導入を決めるのが賢明です。
楽しくスクレイピングしましょう。そして、あなたのデータが常に新鮮で、構造化され、すぐ行動に移せる状態でありますように。
さらに詳しく