

ウェブスクレイピングの世界に初めて足を踏み入れたとき、「HTMLを取ってくるだけでしょ?なんだか簡単そう」と思っていた自分がいました。でも今では、営業やEC、マーケティングリサーチの現場でウェブスクレイピングが当たり前のスキルになっているのを実感しています。ネット上には10億以上のサイトが存在し、企業はそこから得られる情報を求めてやみません。ただし、ほとんどのデータは動的なページやJavaScript、インタラクティブな仕掛けの裏に隠れていて、単純なツールではなかなか手が届きません。
そんなときに頼りになるのが、SeleniumのようなPython スクレイパーです。Selenium Pythonを使えば、実際のブラウザを自動で操作できるので、動的なウェブサイトからでもしっかりデータを引っ張ってこれます。ただ、使いこなすにはちょっとしたコツが必要。このガイドでは、初心者向けにSeleniumの使い方をallbirds.comの商品データを例にしながら分かりやすく解説します。さらに、最近登場したAI搭載のThunderbitのようなツールなら、もっと手軽に同じ作業ができることもご紹介します。
なぜウェブスクレイピングが重要?動的サイトが厄介な理由
今やウェブスクレイピングはエンジニアだけのものではありません。営業やマーケ、EC、オペレーション部門でも日常的に使われています。競合の価格調査やリード獲得、レビュー分析など、いろんな業務で大活躍。実際、開発者の3分の1以上が価格データの取得を重視していて、オンラインデータの**80〜90%**は非構造化データ。つまり、コピペだけではどうにもならない世界です。
でも、今どきのウェブサイトはほとんどが動的。JavaScriptで後からコンテンツが読み込まれたり、ボタンの裏にデータが隠れていたり、無限スクロールがあったりします。requestsやBeautifulSoupのようなシンプルなスクレイパーだと、静的なHTMLしか見えません。もし必要な情報がクリックやスクロール、ログイン後に出てくる場合は、実際のユーザーのように操作できるツールが必要です。
Selenium Pythonとは?ウェブスクレイピングで使う理由
Selenium Pythonって何?ざっくり言うと、ブラウザを自動で動かすツールです。Pythonのスクリプトで、実際のブラウザを開いてボタンをクリックしたり、フォームに入力したり、ページをスクロールしたり、動的に表示されるデータもちゃんと取得できます。
Selenium Pythonとシンプルなスクレイパーの違い
- Selenium Python:Chromeなど本物のブラウザを自動で操作。JavaScriptの実行や動的要素の操作、コンテンツの読み込み待ちもOK。まるで人間が操作しているみたいに振る舞えます。
- Requests/BeautifulSoup:静的なHTMLだけ取得。動作は速くて軽いけど、JavaScriptやユーザー操作が必要なデータには対応できません。
Seleniumは「ロボットのインターン」みたいな存在。ブラウザでできることは何でもできるけど、細かい指示とちょっとした根気が必要です。
Seleniumを使うべきシーン
- 無限スクロールのフィード(SNSや商品一覧など)
- インタラクティブなフィルターやドロップダウン(例:allbirds.comのサイズ選択)
- ログインやポップアップの裏にあるコンテンツ
- シングルページアプリケーション(ReactやVueなど)
静的なテキストだけならBeautifulSoupで十分ですが、動的なサイトにはSeleniumがぴったりです。
Selenium Pythonの環境構築
実際に手を動かす前に、必要なツールを準備しましょう。初心者でも迷わず進めるように説明します。
1. PythonとSeleniumのインストール
まずはPython 3が入っているか確認。公式サイトからダウンロードできます。確認コマンドはこちら:
python --version
次に、pipでSeleniumをインストール:
pip install selenium
これでPython用のSeleniumが使えるようになります。
2. ChromeDriverのダウンロードと設定
SeleniumでChromeを動かすには「ドライバー」が必要。Chromeの場合はChromeDriverを使います。
- Chromeのバージョン確認:Chromeを開いて、メニュー→ヘルプ→Google Chromeについて で確認。
- 対応するChromeDriverをダウンロード:自分のChromeバージョンに合ったものを選びましょう。
- ドライバーの配置:
chromedriver.exe(またはMac/Linux用)をシステムPATHかプロジェクトフォルダに置きます。
※ webdriver_managerのような自動ダウンロード用パッケージもありますが、最初は手動でOKです。
3. 動作確認
test_selenium.pyというPythonファイルを作って、以下を実行:
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("https://www.example.com")
print(driver.title)
driver.quit()
Chromeが自動で立ち上がってexample.comにアクセスし、タイトルが表示されてブラウザが閉じれば成功。「Chromeは自動テストソフトウェアによって制御されています」と出れば準備OK!
Selenium Pythonでallbirds.comの商品データを取得してみよう
実際にSeleniumを使ってみましょう。今回はallbirds.com/collections/mensから商品名と価格を取得します。
ステップ1:ブラウザを起動してページにアクセス
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get("https://www.allbirds.com/collections/mens")
ステップ2:動的コンテンツの読み込みを待つ
動的なサイトは表示に時間がかかることも。Seleniumの待機機能を使いましょう:
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CSS_SELECTOR, "div.product-card"))
)
(実際のCSSセレクタはサイトを調べて確認しましょう。ここではdiv.product-cardを例にしています)
ステップ3:要素を取得してデータを抽出
products = driver.find_elements(By.CSS_SELECTOR, "div.product-card")
print(f"Found {len(products)} products")
data = []
for prod in products:
name = prod.find_element(By.CSS_SELECTOR, ".product-name").text
price = prod.find_element(By.CSS_SELECTOR, ".price").text
data.append((name, price))
print(name, "-", price)
出力例:
Found 24 products
Wool Runner - $110
Tree Dasher 2 - $135
...
ステップ4:CSVファイルに保存
取得したデータをCSVに書き出します:
import csv
with open("allbirds_products.csv", "w", newline="") as f:
writer = csv.writer(f)
writer.writerow(["Product Name", "Price"])
writer.writerows(data)
最後にブラウザを閉じましょう:
driver.quit()
CSVを開けば、商品名と価格が一覧で確認できます。
Selenium Pythonでよくある課題とその対処法
実際にスクレイピングしてみると、思ったより手間がかかることも。よくあるトラブルとその解決法を紹介します。
要素の読み込み待ち
動的サイトは表示が遅いことも。明示的な待機を使いましょう:
WebDriverWait(driver, 10).until(
EC.visibility_of_element_located((By.CSS_SELECTOR, ".product-card"))
)
これで要素が表示されるまでしっかり待てます。
ページネーション対応
複数ページを取得したい場合はループで対応:
while True:
try:
next_btn = driver.find_element(By.LINK_TEXT, "Next")
next_btn.click()
WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.CSS_SELECTOR, ".product-card")))
except Exception:
break # 次のページがなければ終了
無限スクロールの場合:
import time
last_height = driver.execute_script("return document.body.scrollHeight")
while True:
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(2)
new_height = driver.execute_script("return document.body.scrollHeight")
if new_height == last_height:
break
last_height = new_height
ポップアップやログインの処理
ポップアップが邪魔な場合は閉じる:
driver.find_element(By.CSS_SELECTOR, ".modal-close").click()
ログインが必要な場合は入力して送信:
driver.find_element(By.ID, "email").send_keys("user@example.com")
driver.find_element(By.NAME, "login").click()
※CAPTCHAや2段階認証は自動化が難しいので注意。
Selenium Pythonでのスクレイピングのデメリット
Seleniumは強力ですが、課題もいろいろあります:
- 動作が遅い:毎回フルブラウザを起動し、画像やスクリプトも全部読み込むので、大量ページの取得は時間がかかります。
- リソース消費が大きい:CPUやメモリをかなり使うので、並列処理には高性能なPCが必要です。
- セットアップが複雑:ChromeDriverのバージョン管理や、サイトごとのコード修正など、保守が大変です。
- 壊れやすい:サイトのレイアウトが変わると、スクリプトがすぐ動かなくなります。
- データ加工が手動:翻訳や感情分析などは別途ライブラリやAPIが必要です。
技術に詳しくないビジネスユーザーや、すぐに構造化データが欲しい人には、Seleniumはちょっと大げさに感じるかもしれません。

Thunderbit:Selenium Pythonに代わるAI搭載ウェブスクレイパー
ここで、ビジネスユーザーのために開発された新しいツールThunderbitを紹介します。ThunderbitはAIウェブスクレイパーのChrome拡張で、どんなウェブサイトからでも数クリックでデータを抽出できます。コードもセットアップも一切不要です。
AIでどんなウェブサイトからもデータ抽出 Get Started Free
Thunderbitの特長
- AIによるフィールド自動検出:「AIフィールド提案」をクリックするだけで、商品名や価格、画像などを自動で抽出対象に設定。
- サブページの自動取得:商品詳細ページなども自動で巡回し、追加情報もまとめて取得。
- データの自動加工:説明文の翻訳や要約、感情分析もスクレイピングと同時に実行。
- ワンクリックでエクスポート:Excel、Google Sheets、Notion、Airtableなどに即出力。
- ノーコード操作:プログラミング不要。ブラウザ操作ができれば誰でも使えます。
私自身Thunderbitの開発に関わっていますが、営業やEC、リサーチなどビジネス現場で「すぐに使える構造化データ」を手に入れる最速の方法だと自信を持っています。
ThunderbitとSelenium Pythonの比較
違いを表でまとめました:
| 比較項目 | Selenium Python | Thunderbit(AI・ノーコード) |
|---|---|---|
| セットアップ時間 | 中〜複雑:Python・Selenium・ChromeDriverのインストールやコード作成が必要 | 非常に簡単:Chrome拡張を入れるだけ、数分で開始 |
| 必要スキル | 高:コーディングやHTMLの知識が必要 | 低:クリック操作のみ、AIが自動判別 |
| 動的コンテンツ対応 | 優秀:JSやクリック、スクロールも可能 | 優秀:ブラウザ上で動作、AJAXや無限スクロール、サブページも対応 |
| 速度 | 遅い:ブラウザ起動のオーバーヘッドあり | 小〜中規模なら高速:AI自動検出、直接DOMアクセス |
| スケーラビリティ | 拡張しにくい:リソース消費大 | 数百〜数千件なら得意、大量一括は非推奨 |
| データ加工 | 手動:データ整形や翻訳、感情分析は別途実装 | 自動:AIが翻訳・要約・分類・付加情報も同時処理 |
| エクスポート | CSVやSheets等はカスタム実装 | Excel、Google Sheets、Notion、Airtableにワンクリック出力 |
| 保守性 | 高:サイト変更に弱い | 低:AIが多くのレイアウト変化に自動対応、保守負担小 |
| 独自機能 | フルブラウザ自動化、カスタムワークフロー | AIインサイト、テンプレート、データ加工、無料抽出機能 |
ビジネスユーザーにとっては、Thunderbitならコードやドライバーのトラブルから解放されます。
実践例:Thunderbitでallbirds.comの商品データを取得
Thunderbitなら同じ作業も数クリックで完了します:
- Thunderbit Chrome拡張をインストール
- allbirds.com/collections/mensにアクセス
- Thunderbitアイコンをクリックし「AIフィールド提案」を選択
- AIが「商品名」「価格」「商品URL」などのカラムを自動検出
- (任意)「説明文(日本語)」や「感情分析」などのカラムを追加
- AIが翻訳や分析も同時に実行
- 「スクレイピング開始」をクリック
- すべての商品データがテーブルにまとめて取得されます
- Google Sheets、Notion、Excelなどにワンクリックでエクスポート
コードもブラウザの待ち時間も、CSVの整形も不要。すぐに使えるデータが手に入ります。
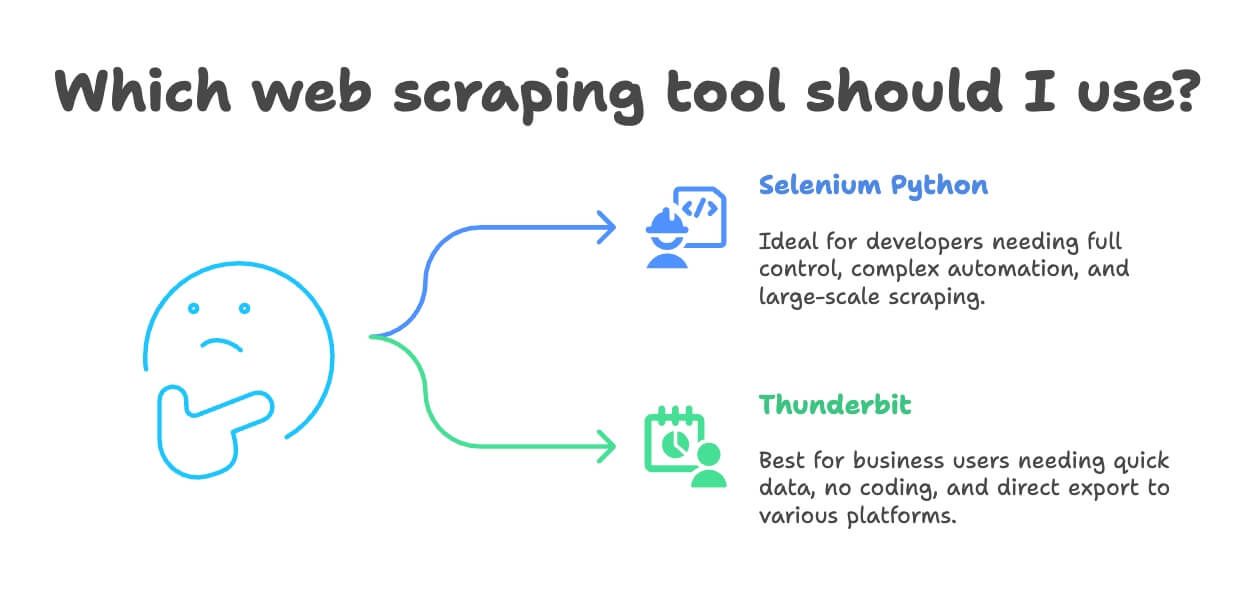
Selenium PythonとThunderbit、どちらを使うべき?
どちらが自分に合っているか、まとめてみました:
- Selenium Pythonが向いている人
- 開発者で、ブラウザ自動化を細かく制御したい
- 複雑なワークフローや大規模なシステムの一部として使いたい
- ログインやダウンロード、複数ステップの自動化が必要
- 大量データを本格的なインフラで処理したい
- Thunderbitが向いている人
- ビジネスユーザーやアナリスト、マーケターで、すぐにデータが欲しい
- コーディングやセットアップの手間を省きたい
- 翻訳や感情分析、データ加工も同時に行いたい
- 小〜中規模(数百〜数千件)の案件が中心
- ExcelやGoogle Sheets、Notion、Airtableに直接出力したい
正直なところ、Thunderbitなら数日かかるSeleniumの作業も10分で終わることが多いです。高度なカスタマイズや大規模処理が不要なら、Thunderbitが圧倒的に手軽でおすすめです。
おまけ:ウェブスクレイピングのマナーと注意点
データ収集を始める前に、守っておきたいポイントをまとめました:
- robots.txtや利用規約を確認:スクレイピング禁止のサイトでは無理に取得しない
- リクエストの間隔を空ける:サーバーに負荷をかけないよう、適度に待機を入れる
- ユーザーエージェントやIPのローテーション:簡単なブロック回避に有効ですが、規約違反はNG
- 個人情報や機密データは取得しない:公開情報のみ、GDPRなどの法令も守る
- APIがあればAPIを使う:公式APIがある場合はそちらを利用
- ログインや有料ページの無断取得は避ける:法的・倫理的に問題あり
- 取得ログやエラー処理をしっかり:ブロックされたら無理せず対応を見直す
スクレイピングの法的・倫理的な注意点はこちらのガイドも参考にしてください。
まとめ:自分に合ったウェブスクレイピングツールを選ぼう
ウェブスクレイピングは、手作業のスクリプトからAI搭載のノーコードツールまで大きく進化しています。Selenium Pythonは開発者向けに強力な選択肢ですが、学習コストや保守の手間もあります。多くのビジネスユーザーには、Thunderbitの方が翻訳や感情分析、ワンクリック出力など、より手軽に構造化データを取得できるでしょう。
私のおすすめは、両方試してみること。開発者ならSeleniumでallbirds.comのスクリプトを書いてみてください。すぐに結果が欲しい、手間を省きたいならThunderbitを使ってみましょう。無料プランもあるので、気になるサイトでぜひ体験してみてください。
そして、スクレイピングはマナーを守って、データは賢く活用しましょう。IPがブロックされないことを祈っています!
さらに学びたい方はこちらもどうぞ:
- Beautiful SoupとSeleniumの徹底比較(2025年版)
- 2025年版おすすめウェブスクレイピングツールまとめ
- AIでウェブサイトのデータをExcelに取り込む方法
- Thunderbit Chrome拡張ダウンロードページ
Thunderbit AIウェブスクレイパーを無料で試す Get Started Free




