

ScrapyでECサイトから商品データを収集するには、Python環境の準備だけでなく、セレクター、ページネーション、デバッグまで設計する必要があります。私が初めてAmazonの価格追跡ツールを作ろうとしたときも、手元にあったのはPythonとコーヒーでしたが、数時間後にはXPathセレクターやページネーションへの対応、デバッグ作業に追われていました。
ウェブスクレイピングは、開発者による大規模なデータ収集だけでなく、営業、EC運用、マーケティングなどの業務でも利用されています。実際、ウェブスクレイピングソフトウェア市場は2024年に10.1億ドル規模へ達し、2032年には24.9億ドルに達すると予測されています。一方、PythonやScrapyのようなフレームワークは、大規模でカスタム性の高い処理に向いているものの、初めて扱う人には一定の学習が必要です。
このチュートリアルでは、Amazonを題材に、Scrapyの環境構築、スパイダーの作成、ページネーション、データ出力までを順に解説します。さらに、コードを書かずに同様の業務データを取得したい場合の選択肢としてThunderbitも紹介し、用途に応じた使い分けを整理します。
Scrapy Pythonとは?ウェブスクレイピングの仕組みと特徴
Scrapy は、ウェブクロールとスクレイピング専用に作られたオープンソースのPythonフレームワークです。サイトを巡回し、リンクをたどり、ページネーションを処理し、大量の構造化データを抽出するためのカスタムスパイダー(Scrapyでいうクローラー)を構築できます。
PythonのrequestsとBeautifulSoupは、単発の比較的シンプルなスクレイピングに使いやすいライブラリです。一方、Scrapyは大規模で複雑なプロジェクトを継続的に運用するための機能を備えています。たとえば、次のような用途です。
- 数千ページをクロールする(例:ECカタログ内の全商品)
- リンクを自動でたどり、ページネーションを処理する
- 速度のために非同期でデータを処理する
- 繰り返し使える形でデータを構造化・整形・エクスポートする
Scrapyは柔軟性と拡張性に優れていますが、利用にはPythonやHTML、セレクター、プロジェクト構成に関する知識が必要です。
ウェブスクレイピングでScrapy Pythonを使う理由
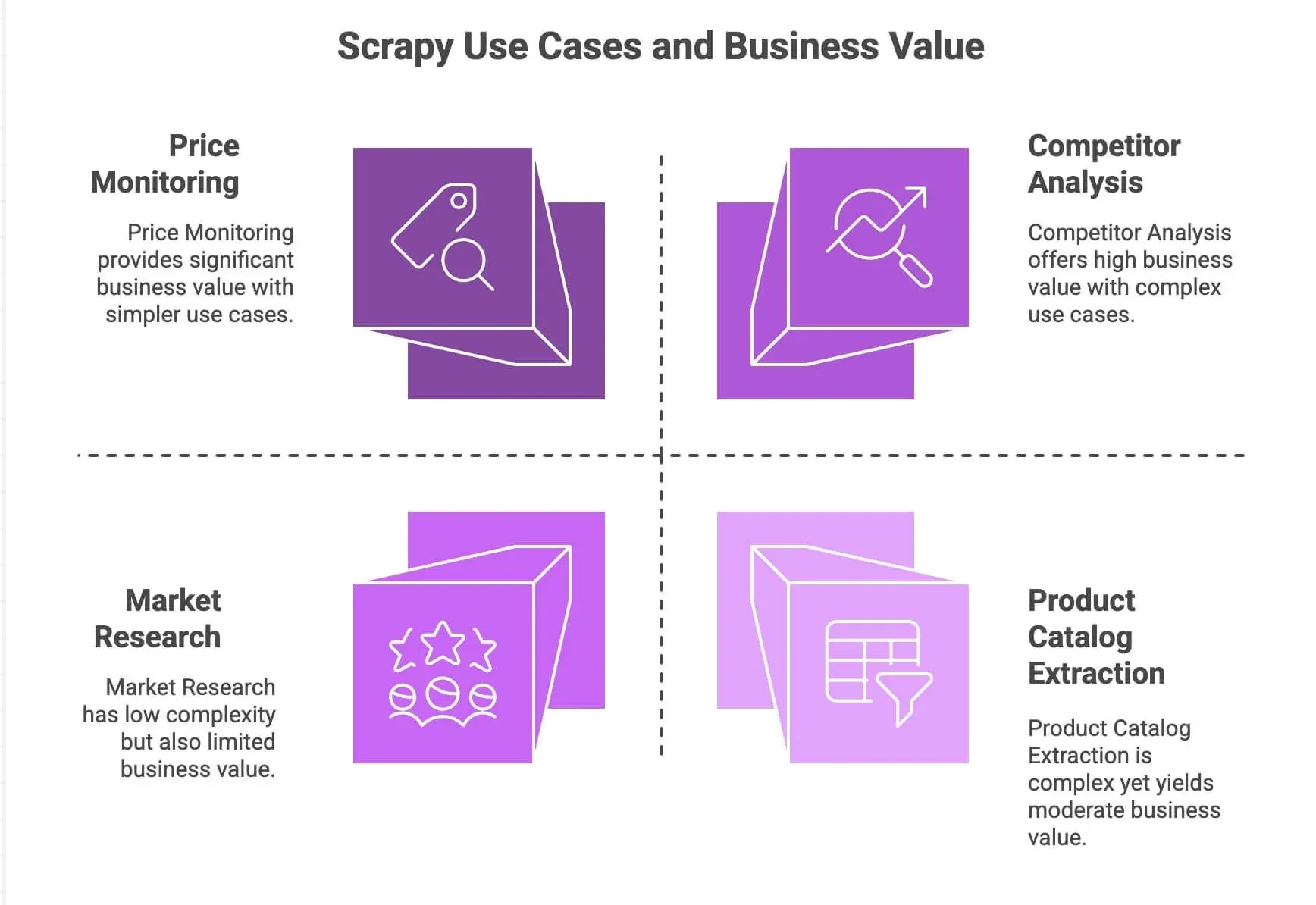
Scrapyが選ばれる理由を、主な用途と実装上の強みに分けて整理します。
| ユースケース | Scrapyの強み | ビジネス価値 |
|---|---|---|
| 価格モニタリング | ページネーション、非同期リクエスト、スケジューリングに対応 | 競合価格の変化を把握し、動的価格設定の判断材料にできる |
| 商品カタログ抽出 | リンクをたどり、構造化データを抽出 | 商品データベースの構築、分析基盤への連携 |
| 競合分析 | 拡張性が高く、サイト変更にも比較的強い | トレンド、新商品投入、在庫状況を追跡できる |
| 市場調査 | データの整形・変換に向いたモジュール型パイプライン | レビューを集約し、感情分析を実行できる |
Scrapyの非同期エンジン(Twistedベース)は、複数ページを並列で取得できるため、高速かつスケーラブルです。モジュール設計により、プロキシやユーザーエージェント、データ整形などのカスタムロジックを差し込めます。さらにパイプラインを使えば、CSV、JSON、データベースなど、好きな形式でデータを処理・検証・出力できます。
Pythonに慣れたチームにとって、Scrapyは大規模な収集処理を細かく制御しやすい選択肢です。一方、一般的なビジネスユーザーが導入する場合は、開発環境と運用担当者を用意する必要があります。
Scrapy Python環境のセットアップ
Scrapyをゼロからセットアップする手順を、実行順に説明します。
1. Scrapyをインストールする
まず、Python 3.10以降がインストールされていることを確認してください(Scrapy 2.14.0は2026年に3.9のサポートを終了しました)。そのうえで、ターミナルを開いて次を実行します。
pip install scrapy
インストール確認は次のコマンドです。
scrapy version
WindowsやAnacondaを使っている場合は、競合を避けるために仮想環境を作成するとよいでしょう。ScrapyはWindows、macOS、Linuxで動作します。
2. 新しいScrapyプロジェクトを作成する
amazonscraperという新しいプロジェクトを作成します。
scrapy startproject amazonscraper
次のようなフォルダ構成が生成されます。
amazonscraper/
├── scrapy.cfg
├── amazonscraper/
│ ├── __init__.py
│ ├── items.py
│ ├── pipelines.py
│ ├── middlewares.py
│ ├── settings.py
│ └── spiders/
各ファイルの役割は次のとおりです。
scrapy.cfg:プロジェクト設定(普段はあまり触らない)items.py:データモデルを定義する場所(たとえば、名前や価格などを持つProduct)pipelines.py:データを整形・検証・出力する場所middlewares.py:高度な処理(プロキシ、カスタムヘッダーなど)settings.py:Scrapyの挙動を調整する場所(同時実行数、遅延など)spiders/:実際のスクレイピングロジックを置く場所
最初からすべてのファイルを編集する必要はありません。まずはspiders/で取得処理を作り、必要に応じてデータモデル、パイプライン、設定を追加します。
Pythonスクレイパーを作る:ScrapyでAmazonの商品データをスクレイピングする
実例として、Amazonの検索結果から商品データを取得するスパイダーを作成します。Amazonを対象にする場合は、利用規約とアクセス条件を事前に確認し、bot対策やサーバー負荷にも配慮してください。以下は学習用の例です。
1. スパイダーを作成する
spiders/フォルダ内にamazon_spider.pyというファイルを作成します。
import scrapy
class AmazonSpider(scrapy.Spider):
name = "amazon_example"
allowed_domains = ["amazon.com"]
start_urls = ["https://www.amazon.com/s?k=smartphones"]
def parse(self, response):
products = response.xpath("//div[@data-component-type='s-search-result']")
for product in products:
yield {
'name': product.xpath(".//span[@class='a-size-medium a-color-base a-text-normal']/text()").get(),
'price': product.xpath(".//span[@class='a-price-whole']/text()").get(),
'rating': product.xpath(".//span[@aria-label]/text()").get()
}
next_page = response.xpath("//li[@class='a-last']/a/@href").get()
if next_page:
yield scrapy.Request(url=response.urljoin(next_page), callback=self.parse)
このコードでは、次の処理を行っています。
- Amazonの検索結果ページで「smartphones」の検索結果を起点にしています。
- 各商品について、XPathセレクターを使って名前、価格、評価を抽出しています。
- 「次のページ」リンクを見つけて、Scrapyにそれをたどらせ、さらに商品を取得しています。
2. スパイダーを実行する
プロジェクトのルートで次を実行します。
scrapy crawl amazon_example -o products.json
これでScrapyが検索結果を巡回し、ページネーションをたどり、データをJSONファイルに保存してくれます。
ページネーションと動的コンテンツの処理
リンクをたどったりページネーションを処理したりできるのは、Scrapyの大きな強みの1つです。ただし、JavaScriptで読み込まれるページのような動的コンテンツはどうでしょうか。標準のScrapyが見られるのは静的HTMLだけです。無限スクロールやポップアップレビューのようにJavaScriptで読み込まれるコンテンツを取得したい場合は、SeleniumやSplashのようなツールと連携させる必要があります。このような動的コンテンツへの対応は、追加ツールの設定や保守も含めて別途設計する必要があります。
Scrapy Pythonでのデータ処理とエクスポート
データを取得した後は、用途に合わせて整形し、分析や共有に使う場所へ出力します。
- パイプライン:
pipelines.py内でPythonクラスを書き、データの整形、検証、付加情報の追加ができます(たとえば、価格を数値に変換する、欠損行を除外する、翻訳APIを呼び出す、など)。 - エクスポート:Scrapyは
oフラグを使って、CSV、JSON、XMLへ直接出力できます。Google Sheetsへの書き込みのような、より高度な出力を行うには、追加コードを書くか、サードパーティライブラリを使う必要があります。
感情分析や商品説明の翻訳を行う場合は、外部APIやPythonライブラリとの連携を実装します。これらは標準機能ではありません。
見落としがちなコスト:ビジネスユーザーにとってのScrapy Pythonの課題
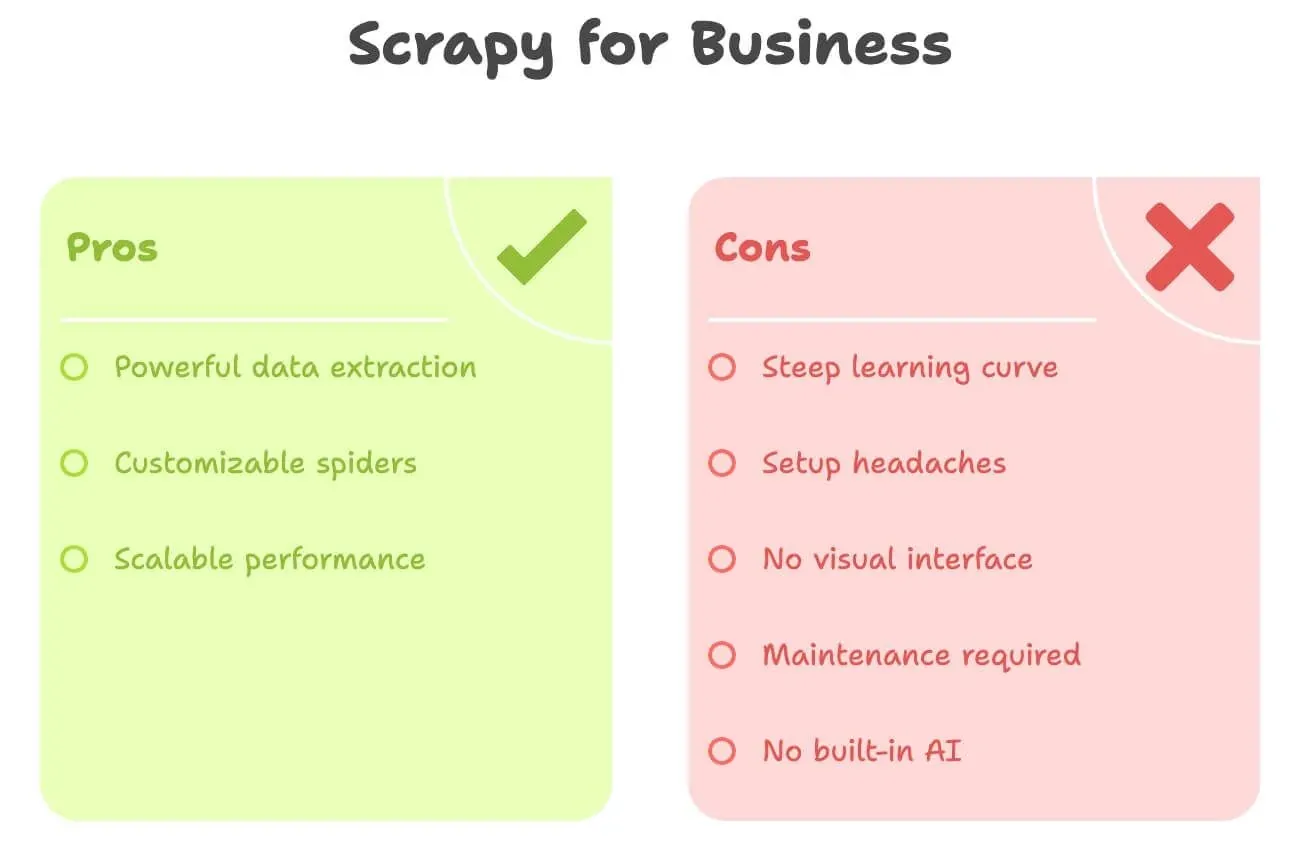
Scrapyは高い柔軟性を持つ一方、非開発者が単独で導入・運用するには、学習と保守の負担があります。主な課題は次のとおりです。
- 学習曲線が急:Python、HTML、XPath/CSSセレクター、そしてScrapyのプロジェクト構成を理解する必要があります。慣れるまでに数日、場合によっては数週間かかることもあります。
- セットアップが面倒:Pythonのインストール、依存関係の管理、エラー対応は大変です。特にWindowsでは負担が大きくなりがちです。
- ビジュアルUIがない:すべてコードで操作します。ページをクリックしてデータを選ぶようなことはできません。
- 保守が必要:サイトが変わるとスパイダーが壊れます。修正は自分で行う必要があります。
- AI機能が標準ではない:翻訳、要約、感情分析をしたい場合は、すべて追加実装が必要です。
ビジネスユーザーの要件と比較すると、次のように整理できます。
| 課題 | Scrapy(Python) | ビジネスユーザーのニーズ |
|---|---|---|
| コーディングの必要性 | あり | ノーコードが望ましい |
| セットアップ時間 | 環境や要件により数時間(または数日) | 数分で基本設定を試したい |
| 保守 | サイト変更に応じて継続的に必要 | 保守負担を最小限にしたい |
| データ出力 | CSV/JSON(Sheets/Excel連携には追加対応) | Excel/Sheets/Notionへ直接出力 |
| AI機能 | なし(自力で連携) | 翻訳・感情分析を標準搭載 |
そのため、単発の営業リスト作成や商品情報の整理が目的で、開発担当者を置けない場合は、ノーコードツールも比較対象になります。
Thunderbit:非エンジニア向けのノーコード選択肢
ここからは、Scrapyとは異なる選択肢としてThunderbitを紹介します。長年自動化ツールを作ってきた立場から言うと、多くのビジネスユーザーが必要としているのは、コードそのものではなく、業務に使えるデータを短時間で用意することです。
Thunderbitは、Chrome拡張機能として提供されるAI搭載ウェブスクレイパーです。非技術系のユーザーが次のような作業を行う場面を想定しています。
- 対応するWebページから、画面操作でデータを取得する
- 「商品名、価格、評価」のように自然言語で欲しい項目を伝える
- ページネーションやサブページを処理する
- データをExcel、Google Sheets、Airtable、Notionへ直接出力する
- 翻訳、要約、感情分析をその場で行う
Pythonやセレクターの設定を減らし、抽出項目の指定から出力までを一つの画面で進められます。
AIを使ってあらゆるウェブサイトをスクレイピングする方法 Get Started Free
Thunderbitは、商品情報の整理、営業リスト作成、価格調査など、非エンジニアが小〜中規模のデータ収集を短時間で試したい場合に向いています。複雑な独自ロジックや大規模な継続処理が必要な場合は、Scrapyとの比較が必要です。
ThunderbitとScrapy Pythonの比較
両者は、必要な技術スキル、導入時間、処理規模、保守方法が異なります。用途別の違いを次の表に整理します。
| 項目 | Scrapy(Python) | Thunderbit(AIツール) |
|---|---|---|
| 必要スキル | Python、HTML、セレクター | 基本操作ではコーディング不要。クリック操作と自然言語で指定 |
| セットアップ時間 | 環境や要件により数時間(インストール、コーディング、デバッグ) | 基本設定は数分(Chrome拡張を入れてサインイン) |
| データ構造化 | 手動(items、pipelinesを定義) | AIが列を検出し、項目を提案 |
| ページネーション/サブページ | コードが必要 | 1クリックで設定でき、AIが処理を支援 |
| 翻訳 | カスタムコードまたはAPI連携 | 標準機能の「翻訳」で設定 |
| 感情分析 | 外部ライブラリ/API | 「感情」列を追加して実行 |
| 出力オプション | CSV/JSON(Sheets/Excelへ手動取り込み) | Excel、Google Sheets、Airtable、Notionへ1クリック出力 |
| 保守 | 手動(サイト変更時にコード更新) | 軽微なサイト変更への対応をAIが支援 |
| 規模感 | 大規模で継続的なプロジェクトに向いている | すばやい作業や中規模(数百〜数千行)に向いている |
| コスト | 無料(ただし時間や開発リソースがかかる) | 無料プラン+有料プラン(月額9ドル〜。ただし時間と手間を大幅節約) |
ウェブスクレイピングでScrapy PythonとThunderbitをどう使い分けるか
選択時は、担当者の技術スキル、処理規模、カスタマイズ要件、必要な出力を基準にします。私の目安は次の通りです。
- Scrapyが候補になる場合
- あなたが開発者、またはチームに開発者がいる
- 数万ページ規模をスクレイピングしたい、または独自の継続パイプラインを作りたい
- サイトが非常に複雑で、高度なロジックが必要
- 完全な制御を求めており、保守も厭わない
- Thunderbitが候補になる場合
- コードを書かない(または書きたくない)
- 単発または定期的な業務タスクのために、すぐデータがほしい
- 翻訳、感情分析、データ拡張が標準で欲しい
- 細かなカスタマイズよりも、速さと柔軟性を重視する
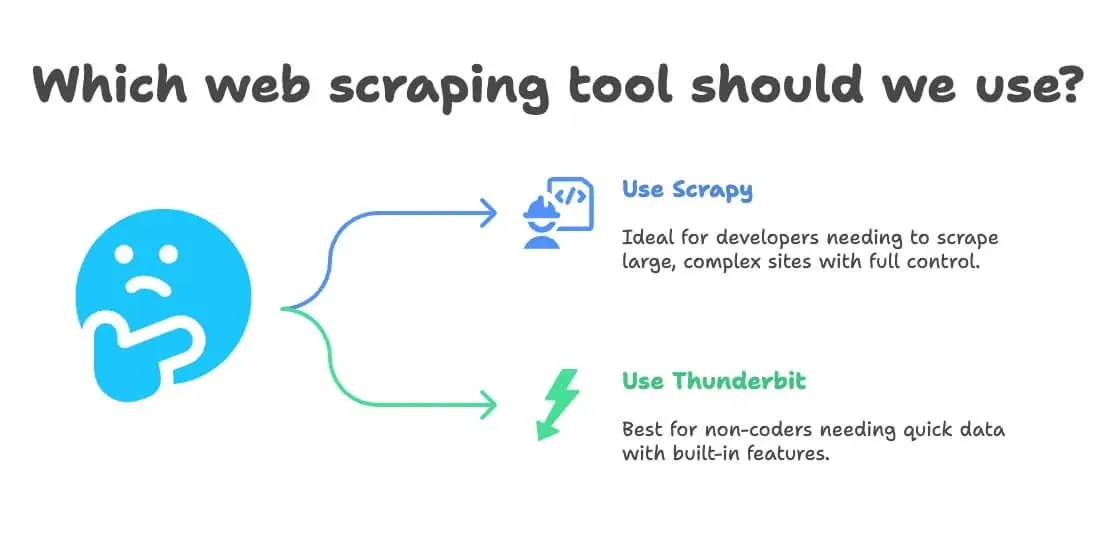
判断フローは次のように整理できます。
- Pythonでコードを書けますか?
- はい → 独自ロジックや継続基盤を重視するならScrapy、短時間で試すならThunderbitも候補
- いいえ → Thunderbitが候補
- プロジェクトは大規模で継続的ですか?
- はい → Scrapy
- いいえ → Thunderbit
- 翻訳や感情分析が必要ですか?
- はい → Thunderbit
- いいえ → どちらでも可
最終的には、対象サイトとの相性、取得精度、運用頻度、保守担当の有無を踏まえて選びます。
ステップごとに解説:ThunderbitでAmazonの商品データをスクレイピングする(ノーコード)
次に、同じAmazonの商品データ取得をThunderbitで行う手順を説明します。
1. Thunderbitをインストールする
- ThunderbitのChrome拡張をダウンロード
- アカウント登録(無料プランあり)
営業リスト作成や商品情報の収集など、Webページ上の情報を表形式にしたい場合は、まず対象ページを1つ選び、必要な項目と抽出結果が用途に合うかを確かめてから利用範囲を広げます。
2. Amazonに行って商品を検索する
- Amazon.comを開き、「laptops」(または任意の商品)を検索する
3. ページ上でThunderbitを起動する
- ブラウザのThunderbitアイコンをクリックする
- サイドパネルが開き、Amazonのページを認識する
4. AIでフィールド提案を使う
- 「AIでフィールド提案」 をクリックする
- ThunderbitのAIがページを解析し、「商品名」「価格」「評価」「レビュー数」などの列を提案する
- 必要に応じて列を追加・削除する(「商品URL」や「Prime対象かどうか」が欲しければ、そのまま入力するだけ)
5. ページネーションとサブページのスクレイピングを有効にする
- ページネーション をオンにする:Thunderbitが「次へ」を自動クリックして全ページを取得します
- サブページのスクレイピング をオンにする:Thunderbitが各商品の詳細ページを訪れ、説明文やASIN番号などの追加情報を取得します
6. スクレイピングを実行する
- スクレイピング をクリックする
- Thunderbitがページごとにリアルタイムでデータを収集していく様子を確認する
7. 翻訳と感情分析を行う(任意)
- 商品説明を翻訳する場合は、その列で「翻訳」をオンにします
- レビューの感情分析を行う場合は、「感情」列を追加すると、ThunderbitのAIが結果を入力します
8. データをエクスポートする
- エクスポート をクリックする
- Excel、Google Sheets、Airtable、Notionから選択する
- 選択した出力先で利用できる形式にデータを整える。手動インポートやCSV変換の作業を減らせる
9. 定期スクレイピングを設定する(任意)
- スケジュールを設定する(例:毎日午前8時)
- Thunderbitが自動でスクレイピングを実行し、指定先を更新する
以上で設定は完了です。コードやセレクターを使わずに運用できますが、定期実行前に取得項目、アクセス頻度、出力先を見直し、対象ページの変更に応じて設定を調整してください。
ウェブスクレイピングを業務で運用する際のポイント
ScrapyでもThunderbitでも、あるいは別のツールでも、私が実際に試行錯誤して学んだベストプラクティスをいくつか紹介します。
- データを検証する:欠損値や不自然な値($0の価格や空の名前など)を必ず確認する
- コンプライアンスを守る:サイトの利用規約を確認し、
robots.txtを尊重し、サーバーに負荷をかけすぎない - 賢く自動化する:最新データを保つためにスケジューリングを使う。ただし、必要以上の頻度でスクレイピングしない
- 無料ツールを活用する:Thunderbitには無料のメール、電話番号、画像エクストラクターが含まれており、リード獲得やコンテンツ整理に便利
- 分析しやすく整える:Sheets/Excelへ直接出力し、すぐにフィルター、ピボット、可視化ができるようにする
さらに詳しいヒントは、ThunderbitのブログやAIを使ってあらゆるウェブサイトをスクレイピングするガイドをご覧ください。
AIを使ってWebサイトのデータをExcelに取り込む方法 Get Started Free
さらに詳しいヒントは、ThunderbitのブログやAIを使ってあらゆるウェブサイトをスクレイピングするガイドをご覧ください。
まとめ:ScrapyとThunderbitを要件に応じて使い分ける
Scrapyは、Pythonに慣れた開発者が、大規模でカスタム性の高いスクレイパーを構築・保守する場合に向いています。一方、商品データの整理、価格調査、営業リスト作成などを非技術チームが短時間で試す場合は、Thunderbitが候補になります。翻訳や感情分析を含む処理が必要か、独自ロジックと完全な制御が必要かによって使い分けることが重要です。
非技術チームがThunderbitを使い、データ収集にかかる時間や作業負担を減らした事例を、私は何度も目にしてきました。AIでのフィールド提案、サブページのスクレイピング、ワンクリック出力といった機能は、「必要なデータを定義する」作業から「スプレッドシートで利用する」段階までを短縮するために使えます。
導入時は、まず対象ページを1つ選び、必要な列、取得精度、出力形式を検証してください。結果が用途に合えば、対象ページや実行頻度を段階的に広げると、運用条件を整理しやすくなります。
もっと詳しく知りたいですか? Thunderbit公式サイトを確認したり、Chrome拡張をダウンロードしたり、Thunderbitブログでウェブスクレイピングのベストプラクティスをさらに深掘りしてみてください。
関連記事
- データスクレイピングとは何か、2026年にどう実践するか
- AIを使ってWebサイトのデータをExcelに取り込む方法
- 2026年版:最高のウェブスクレイピングツール&ソフトウェア
- ウェブスクレイピングの現状レポート
免責事項:ウェブスクレイピングの実施にあたっては、必ずサイトの利用規約と現地法を遵守してください。判断が難しい場合は、法律の専門家に相談してください。
Thunderbitの共同創業者兼CEO、Shuai Guanによる執筆。SaaS、自動化、AIの分野に長年携わってきました。
AIウェブスクレイパーを試す Get Started Free




