は、AI を使ってウェブサイトからデータを取得できる AI Web Scraper の Chrome 拡張機能です。ビジネスユーザーでも、AI の力を借りて手軽にウェブデータを集められます。ここで大事なのは、ScrapingBee の料金ページでは“安そう”に見えるプランでも、いざ実運用に入ると様子がガラッと変わり、クレジットがベース料金の 5 倍〜75 倍の速さで消えていくことです。このレビューでは、多くの記事が見落としがちな5つの視点――実運用時の本当のコスト、セレクター方式と AI 抽出の違い、非エンジニアにとっての使いやすさ、スクレイピング後のデータ活用、そして 2026 年時点の信頼性ベンチマーク――を整理していきます。ScrapingBee をチーム導入で検討しているなら、開発者でも、営業オペレーションの責任者でも、創業者でも、この整理はきっと役に立つはずです。
ScrapingBee とは?まずは概要から
ScrapingBee は、プロキシのローテーション、JavaScript のレンダリング、CAPTCHA の解決をまとめて担ってくれる Web Scraper API です。開発者は自前でスクレイピング基盤を作らなくても、サイトからデータを抜き出せます。HTTP リクエストにパラメータを付けて送ると、HTML、または一部エンドポイントでは JSON が返ってきます。スクレイピングを組み立てるための視覚的な UI やクリック操作の画面はありません。
主な機能は次のとおりです。
- ローテーション対応のプレミアムプロキシ(classic、premium、stealth、residential)
- ヘッドレスブラウザによるレンダリング(フル Chrome、デフォルトで有効)
- 自動 CAPTCHA 回避
- Google Search API(構造化 JSON:オーガニック結果、広告、地図、ナレッジグラフ、People Also Ask、画像、ニュース)
- スクリーンショット取得(標準、全ページ、CSS セレクター指定)
- 国コードによる地域指定
- CSS/XPath 抽出ルール(宣言的な JSON ベースで、構造化 JSON を返す)
- Amazon、Walmart、YouTube、ChatGPT 向けの専用 API
- AI 抽出(2024〜2025 年頃に追加):
ai_query、ai_extract_rules、ai_selectorパラメータ(1 リクエストにつき +5 クレジット) - CLI ツール(2025〜2026 年頃に提供開始):バッチ処理、クロール、サイトマップ解析、CSV の補完、スケジュール cron ジョブ、プロキシ昇格
2019 年にフランスで創業した ScrapingBee は、2026 年初頭時点で約 に達し、2,500 社以上の顧客(SAP、Zapier、Deloitte、Zillow)を抱えるまでに成長しました。しかも、従業員はわずか 4〜6 人規模という少数精鋭で、すべて自己資金で運営されてきました。2025 年 6 月には、(8 桁規模の取引)。ブランドと経営体制は独立性を保っており、サポートチームも してタイムゾーン対応が改善されています。
ひとつ大事な点があります。ScrapingBee には今でもネイティブのビジュアルビルダー、クリック操作の GUI、組み込みのダッシュボードスケジューラーがありません。スケジューリングをするには、CLI ツール、cron ジョブ、または Zapier、Make、n8n などの外部自動化ツールが必要です。彼らが公開している「ノーコード」系のガイドは、Make や Zapier との連携方法を説明しているだけで、ネイティブなノーコード画面を指しているわけではありません。
ScrapingBee は誰向けのツールなのか?
ScrapingBee は、Python や cURL の呼び出しを書き、HTML を読み、CSS/XPath セレクターを組み立てられる開発者向けに作られています。ドキュメントもコード中心で、Python と cURL の例が多めです。 のレビューでは「JavaScript の例がない」と指摘する声があり、別のレビューでは「情報量が多く、読み通すのに 1 日から 1 週間かかる」と表現されていました。
ただし、2026 年に「ScrapingBee review」と検索する人は、バックエンドエンジニアだけではありません。リードリストを作るマーケティングマネージャー、CRM データを補完したい営業オペレーションチーム、競合価格を追いたい EC オペレーション、チーム向けツールを比べたい創業者まで含まれます。以下では各項目ごとに、その機能や制約が開発者向けなのか、ビジネスユーザー向けなのか、あるいは両方に関係するのかを分けて解説します。
ScrapingBee の料金プランをざっくり確認
以下は、ScrapingBee の現行プランです(2026 年 4 月時点)。
| プラン | 月額料金 | API クレジット/月 | 同時リクエスト数 |
|---|---|---|---|
| Freelance | $49 | 250,000 | 10 |
| Startup | $99 | 1,000,000 | 50 |
| Business | $249 | 3,000,000 | 100 |
| Business+ | $599 | 8,000,000 | 200 |
| Enterprise | 営業に問い合わせ | 4,100万以上 | カスタム |
年間契約では が適用されます。無料トライアルでは 1,000 API クレジットが付与され、クレジットカードは不要です。なお、Google Search API は買収後に 1 回あたり られました。
一見すると、クレジット数はかなり太っ腹に見えます。でも、実際はそう単純ではありません。
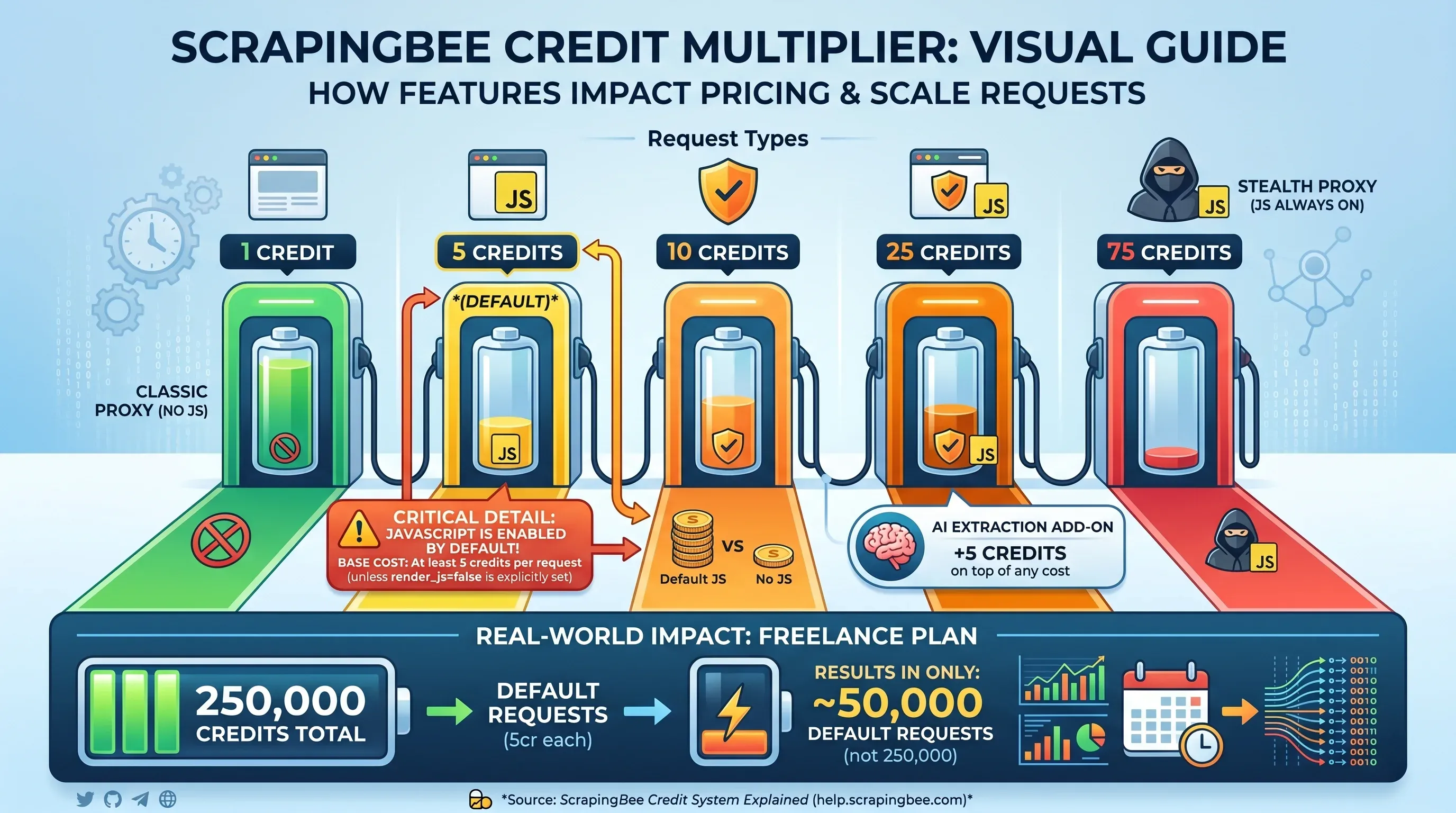
クレジット倍率の仕組み
ここからが、ScrapingBee の料金がややこしくなるポイントです。表示上のクレジット数は、そのままスクレイピングできるページ数ではありません。1 リクエストごとに有効にする機能によって変わります。
| リクエスト種別 | 1 回あたりのクレジット |
|---|---|
classic プロキシ、JS レンダリングなし(render_js=false) | 1 クレジット |
| classic プロキシ、JS レンダリングあり(デフォルト) | 5 クレジット |
| premium プロキシ、JS レンダリングなし | 10 クレジット |
| premium プロキシ、JS レンダリングあり | 25 クレジット |
| stealth プロキシ(JS は常時 ON) | 75 クレジット |
| AI 抽出アドオン | さらに +5 クレジット |
重要なポイント: JavaScript のレンダリングは です。render_js=false を明示しない限り、すべてのリクエストは最低でも 5 クレジット消費します。つまり、Freelance プランの 250,000 クレジットは、実際には 50,000 回分のデフォルトリクエスト しかカバーしません。250,000 回ではありません。
ほとんどの人が見せてくれない“本当の”クレジット計算
以下は、10,000 ページを処理する場合の実コストです。条件ごと、プランごとにどう変わるかを見てみましょう。
| シナリオ | 必要クレジット | Freelance ($49/25万) | Startup ($99/100万) | Business ($249/300万) |
|---|---|---|---|---|
| 1万ページ(静的 HTML、1cr) | 10,000 | ✅ 対応可($0.20/1K) | ✅ 対応可($0.10/1K) | ✅ 対応可($0.08/1K) |
| 1万ページ(JS レンダリング、5cr) | 50,000 | ✅ 対応可($0.98/1K) | ✅ 対応可($0.50/1K) | ✅ 対応可($0.42/1K) |
| 1万ページ(premium プロキシ + JS、25cr) | 250,000 | ⚠️ ちょうど上限($4.90/1K) | ✅ 対応可($2.48/1K) | ✅ 対応可($2.08/1K) |
| 1万ページ(stealth プロキシ、75cr) | 750,000 | ❌ 大幅に不足 | ✅ ぎりぎり対応可($7.43/1K) | ✅ 対応可($6.23/1K) |
同じ 10,000 ページでも、プロキシやレンダリング設定しだいで 1,000 ページあたり $0.20 から $7.43 まで変わります。そして、どの設定が必要かは、実際に試すまで分からないことも少なくありません。
予算シナリオ:月 10,000 ページのリード獲得
営業チームが、リード獲得のために毎月 10,000 件の企業ページをスクレイピングするケースを考えます。最近の B2B サイトの多くは React や Vue を使っているため、JS レンダリングが必要です。
- 必要クレジット: 50,000(1万 × 5 クレジット)
- Freelance プラン($49): 20 万クレジット余るので十分対応可
- ただし対象サイトで premium プロキシが必要なら: 250,000 クレジットで、Freelance 1 契約分をちょうど使い切る。余裕ゼロ
- stealth プロキシが必要なら: 750,000 クレジットが必要で、月額 $99 の Startup プランが必要
予算シナリオ:月 100,000 ページの EC 価格監視
競合サイト上の 100,000 商品ページを監視する EC チームを想定します。
| 構成 | 必要クレジット | 必要プラン | 月額費用 |
|---|---|---|---|
| 静的 HTML(1cr) | 100,000 | Freelance | $49 |
| JS レンダリング(5cr) | 500,000 | Startup | $99 |
| premium プロキシ + JS(25cr) | 2,500,000 | Business | $249 |
| stealth プロキシ(75cr) | 7,500,000 | Business+ | $599 |
同じ作業でも、月額 $49 から $599 までぶれます。これは誤差ではありません。構成次第で 12 倍 の差が出るということです。
「$49 という入口価格は、スクレイピング API 市場で最も誤解を招く数字だ。」—
「JavaScript レンダリングや高度な機能を使うと、クレジットの消費が非常に早い。小規模案件や、スクレイピング量が読めないチームには正当化しづらい。」— Nick S, Manager, Computer Software,
しかも、未使用クレジットは 。
ScrapingBee のコストは競合と比べてどうか

比較をフェアにするため、中位プランを使って見てみます。
| シナリオ(1,000 ページあたり) | ScrapingBee ($99/100万) | ScraperAPI ($149/100万) | Scrapfly ($100/100万) |
|---|---|---|---|
| 静的 HTML | $0.10 | $0.15 | $0.10 |
| JS レンダリング済みページ | $0.50 | $1.64 | $0.60 |
| premium + JS | $2.48 | $3.73 | $3.00 |
| stealth/ultra premium + JS | $7.43 | $11.18 | N/A |
静的ページや JS レンダリング済みページでは、ScrapingBee はだいたい最安か、少なくとも最安水準です。 は一貫して最も高く、JS レンダリングは ScrapingBee と Scrapfly の +5 クレジットに対して +10 クレジットかかります。ただし、 の独立テストでは、実際のサイト難易度を加味すると少し違う結果も出ています。
| サービス | 1,000 リクエストあたりの平均コスト | 成功率 | 平均応答時間 |
|---|---|---|---|
| Scrape.do | $0.80 | 98.19% | 4.7秒 |
| ScrapingBee | $3.90 | 92.69% | 11.7秒 |
| Scrapfly | $4.11 | — | — |
| ZenRows | $4.48 | 92.64% | 10.0秒 |
| ScraperAPI | $8.49 | 92.70% | 15.7秒 |
Thunderbit のクレジットモデルはまったく違う
は、もっとシンプルな料金体系を採用しています。1 クレジット = 1 出力行 で、JS レンダリング、プロキシ種別、対象ドメインによる倍率はありません。サブページのスクレイピングは 1 行あたり 2 クレジットです。
| プラン | 月額料金 | クレジット | 1 行あたりの費用 |
|---|---|---|---|
| Free | $0 | 月 6 ページ | 無料 |
| Starter | $15 | 500 | $0.030 |
| Pro 1 | $38 | 3,000 | $0.013 |
| Pro 2 | $75 | 6,000 | $0.013 |
| Pro 3 | $125 | 10,000 | $0.013 |
| Pro 4 | $249 | 20,000 | $0.012 |
JS が多い EC サイトから 10,000 件の商品情報を取る場合でも、Thunderbit なら、そのサイトが JavaScript レンダリングを求めようが、premium プロキシが必要だろうが、bot 対策回避が必要だろうが、月額 $125 で済みます。ScrapingBee では、同じ作業が構成次第で $49 から $599 に変わります。予算の見通しやすさは、かなり大事です。
CSS セレクター vs. AI 抽出:見落とされがちな保守コスト
多くの ScrapingBee レビューは、この点をまるごと飛ばしています。でも、数か月〜数年単位で継続的にスクレイピングするなら、ここはかなり重要です。
ScrapingBee は、HTML からデータを抜き出すのに CSS/XPath セレクター を使います。CSS セレクターを JSON で定義すると、対応するデータを返してくれる仕組みです。最初はうまく動きます。問題は、その後です。
セレクターが壊れる問題
対象サイトのレイアウトが変わると――クラス名、DOM 構造、フレームワークのバージョンなどが変わると――CSS セレクターは壊れます。2,500 本以上のジョブを運用する成熟したスクレイピング基盤では、研究によると があり、抽出器を維持するだけで毎週 30〜35 件の修正が必要になります。50 サイトをスクレイピングする組織では、年間の保守工数が 850〜1,300 時間に達し、エンジニア人件費込みで $64,000〜$156,000 かかる計算です。
多くのチームはこのコストを甘く見がちです。最初の見積もりでは月 10〜15 時間程度と考えがちですが、実際には に膨らみます(月 40〜90 時間)。しかも、ひとつの“静かな失敗”――セレクターが壊れているのに、空データを返し続けて誰にも気づかれない状態――だけで、失われる売上、順位回復、担当者工数を含めて $38,000〜$57,000 の損失になると見積もられています。
よくある原因は、フレームワーク更新時の CSS クラス名変更、対象要素の周りに新しいコンテナが追加されること、React/Vue/Angular のバージョン更新による DOM 再構成、A/B テストによる動的クラス名、そしてスクレイピング対策の難読化です。
AI 抽出なら保守工数を 60〜80% 削減できる
2025 年の DataRobot の調査では、AI 対応スクレイパーはサイト再設計後の保守工数が、従来のセレクター方式より ことが示されました。時間配分はほぼ逆転します。
| 指標 | 従来型(CSS セレクター) | AI ベース |
|---|---|---|
| リデザイン後の保守 | 基準値 | 70% 少ない |
| 作業時間の配分(初期構築 : 保守) | 20% : 80% | データ上は 5% : 95% |
| 全体の保守削減 | 基準値 | 60〜80% 削減 |
| JS が多いページでの速度 | 基準値 | 30〜40% 高速 |
セットアップ時間:セレクターを書くか、AI に項目を提案させるか
ScrapingBee のセットアップ: ページソースを確認 → CSS セレクターを特定 → JSON で抽出ルールを記述 → テストとデバッグ → ページ差分の例外対応 → 破損監視 → サイト更新時に壊れたセレクターを修正。
Thunderbit のセットアップ: Chrome でページを開く → 「AI Suggest Fields」をクリック → AI がページを読み取り、適切なデータ型付きで列を提案 → 「Scrape」をクリック。セレクター記述も、ソースコードの目視確認も不要です。Thunderbit の AI は、複数の基盤モデル(ChatGPT、Gemini、Claude、DeepSeek R1)を使っており、人間のようにウェブページを視覚的に読み取ります。
Thunderbit の もかなり強力です。各列に独自の AI 指示を付けられるため、抽出時にデータを変換できます。たとえば、日付の整形、翻訳、商品分類、氏名の分割、電話番号の正規化などです。ScrapingBee ユーザーが別工程として自前で組む必要のある後処理を、ここでまとめて省けます。
構造化出力:生 HTML か、そのまま使える行データか
| 観点 | ScrapingBee(セレクター方式) | Thunderbit(AI ベース) |
|---|---|---|
| デフォルト出力 | 生 HTML | 型付きの構造化行データ |
| 構造化抽出 | CSS/XPath ルールを書くか、AI アドオン(+5 クレジット)が必要 | AI が自動で項目を検出 |
| 対応データ型 | テキスト(HTML 解析が必要) | テキスト、数値、日付、URL、メール、電話、画像 |
| レイアウト変更への強さ | ⚠️ セレクターの手動更新が必要 | ✅ AI が毎回ページを再読込して適応 |
| 必要な技術スキル | Python/cURL、CSS セレクター、HTML の理解 | なし — Chrome 拡張で 2 クリック操作 |
| 継続保守 | あり(週 1〜2% の破損率) | 最小限(AI が自動適応) |
ScrapingBee には、セレクター保守の課題をある程度補う AI 抽出機能(ai_query、ai_extract_rules)も追加されています。ただし、これはベース料金に加えて 1 リクエストあたり +5 クレジットかかりますし、ツール自体は依然として API ファーストで、視覚的な操作画面はありません。
非エンジニアにとっての ScrapingBee:正直な使い勝手チェック
ScrapingBee は、非技術ユーザー向けではありません。API だからです。使うにはコードを書く必要があります。もしあなたがマーケティングマネージャーや営業オペレーション担当なら、それだけでかなり厳しいです。
非技術ユーザーが ScrapingBee を使うときの実際の体験は、こんな流れになります。
- API 呼び出しを書く(Python、cURL、または別言語)
render_js=true、premium_proxy=true、country_code=usのような HTTP パラメータを理解する- BeautifulSoup などを使って生の HTML レスポンスを解析する
- 必要な項目を抜き出す CSS セレクターを書く
- ページネーションを処理するためのクロールロジックを自作する(ScrapingBee は単ページのリクエスト処理が中心)
- 抽出データを整形・構造化・保存するデータパイプラインを作る
ドラッグ&ドロップのビルダーはありません。クリックだけで操作できる画面もありません。何をスクレイピングしているのかを視覚的に確認するプレビューもありません。
「学習コストがあります。しかもドキュメントは分厚く、読み通すのに 1 日から 1 週間かかります。」— Arvind K, Proprietor, Financial Services,
「システムがかなり独特で、コードや構造を覚えるまでに時間がかかります。」—
開発者からの評価は高いです。あるレビューでは「完全に API ベースで、とてもモダンで洗練されており、ただ動く」と評されていました。ただし、API を評価する開発者にとっての「使いやすさ」と、コードを書かずにリードリストを作りたい人にとっての「使いやすさ」は、まったく別ものです。
ノーコード代替を選んだ方がよいケース
は、まったく違う体験を提供します。
- Chrome でウェブページを開く(拡張機能を入れた状態で)
- 「AI Suggest Fields」をクリック — AI がページを読み取り、適切なデータ型付きで列(商品名、価格、評価、URL など)を提案
- 確認して調整 — 列の追加・削除・名前変更、変換用の Field AI Prompts の追加
- 「Scrape」をクリック — 構造化された行データとして抽出
- エクスポート — Google Sheets、Airtable、Notion、Excel、CSV、JSON にワンクリックで出力(すべて無料)
API 呼び出しも、セレクターも、コードも不要です。Thunderbit は 2026 年 4 月時点で に対応しています。
また、一般的なサイト向けには もあります。Amazon、Zillow、Shopify、LinkedIn、Google Maps、Instagram、eBay、Apollo などのために、あらかじめ用意・保守されているテンプレートです。AI に項目提案を待つ必要すらなく、すぐに使えます。
さらに Thunderbit には、プラン不要で使える として、メール抽出、電話番号抽出、画像抽出があります。ちょっとしたデータ収集をしたい営業・マーケティングチームにはかなり便利です。
判断基準:誰に何が向いているか
| こんな人なら… | 最適な選択 |
|---|---|
| API と HTML 解析に慣れた開発者 | ScrapingBee または ScraperAPI |
| セレクター作業なしで構造化データがほしい技術者 | Thunderbit API(Extract エンドポイント) |
| コーディング不要のビジネスユーザー(営業、マーケ、EC 運用) | Thunderbit Chrome Extension |
| DevOps なしで定期監視したいチーム | Thunderbit Scheduled Scraper(自然言語でスケジュール) |
| LLM/RAG パイプライン向けにきれいな Markdown が必要 | Thunderbit Distill API または Firecrawl |
| コストの予測しやすさを重視し、クレジット倍率を避けたい | Thunderbit(1 クレジット = 1 行) |
スクレイピングの後、データはどこへ行くのか?
スクレイピングは仕事の半分にすぎません。残り半分――データを実際に使える場所へ持っていく工程――については、多くの ScrapingBee レビューが触れていません。
ScrapingBee:生 HTML を返すので、パイプラインは自前で作る
ScrapingBee のデフォルト出力は 生 HTML です。そこから次の作業が必要になります。
- BeautifulSoup や lxml で HTML を解析する
- ナビゲーション、フッター、スクリプト、スタイルを取り除く(これらは を占める)
- 必要なフィールドを抜き出す
- 構造化フォーマットに変換する
- ページネーションやエラー状態を処理する
- データを保存・共有する
「ScrapingBee は生 HTML を返します。AI エージェントには、きれいな Markdown、セマンティック検索、Webhook が必要です。」—
ScrapingBee には return_page_markdown=true や return_page_text=true のような任意設定もあり、Google Search API は構造化 JSON を返します。ただし、標準的なワークフロー、そして汎用スクレイピング体験の中心は、やはり自分で処理する必要がある生 HTML です。
実際には、追加ツールが必要になることが多いです。解析用の BeautifulSoup/lxml、データ整形用の Pandas、スケジュール用の cron/Airflow、複数ページ対応のクロールロジック、そして 。つまり、「取れた」から「使える」までに、かなりのエンジニアリングが挟まります。
Thunderbit:構造化出力と組み込みエクスポート
Thunderbit は、定義済みデータ型(テキスト、数値、日付、URL、メール、電話、画像)を持つ構造化行データを返し、そのままエクスポートできます。すべてのプランで出力は無料です。
| 出力先 | 料金 |
|---|---|
| Excel (.xlsx) | 無料 |
| Google Sheets | 無料(直接連携) |
| Airtable | 無料(直接連携) |
| Notion | 無料(直接連携) |
| CSV | 無料 |
| JSON | 無料 |
すでに Google Sheets や Airtable を CRM や業務ハブとして使っているチームなら、ここで必要な作業レイヤーが丸ごと減ります。Notion や Airtable にエクスポートする場合は、画像も画像ライブラリにアップロードされ、行内でそのまま表示できます。実務ではかなり効く、地味だけど大事なポイントです。
ScrapingBee の連携エコシステム
ScrapingBee には、(8,000 以上のアプリ連携)、(3,000 以上のアプリ)、n8n、Microsoft Power Automate との連携があります。これらを使えば、生 HTML と最終的な活用先との間をつなげられますが、その分、コスト、複雑さ、失敗ポイントも増えます。
開発者向け:Thunderbit の Open API
プログラムでパイプラインを組みたい人向けに、Thunderbit には 2 つの主要エンドポイントがあります。
- Distill エンドポイント — ページをきれいな Markdown に変換。LLM/RAG パイプラインに最適(1 回あたり 1 クレジット)
- Extract エンドポイント — ユーザー定義スキーマに一致した構造化 JSON を返す(1 回あたり 20 クレジット)
- バッチ処理 — 1 リクエストあたり最大 100 URL
つまり Thunderbit は、ノーコードユーザー(Chrome 拡張)と開発者(Open API)の両方を、同じ AI エンジンで支えています。大事なのは「スクレイピングできるか」だけではなく、「データがどこへ行くか」です。
2026 年の信頼性チェック:ScrapingBee は本番で通用するのか?
古い Reddit スレッド(2021〜2023 年)には、ScrapingBee の信頼性に関する不満が見られます。それは 2026 年の現実にも当てはまるのでしょうか。そこで、6 つの独立ベンチマークを参照しました。結果はまちまちで、時には矛盾もあります。
Scrapeway の隔週ベンチマーク(2026 年 4 月)
総合成功率は で、9 サービス中 7 位でした。
| サイト | 成功率 |
|---|---|
| Amazon | 48% |
| 41% | |
| Indeed | 38% |
| Etsy | 21% |
| Booking | 17% |
| Realtor | 0% |
| StockX | 0% |
| Twitter/X | 0% |
| Zillow | 0% |
| Walmart | 0% |
| 0% |
Scrapingdog の直接比較テスト(2025 年)
| サイト | ScrapingBee | Scrapingdog | ScraperAPI |
|---|---|---|---|
| Amazon | 100% | 100% | 100% |
| Glassdoor | 0% | 100% | 100% |
| eBay | 100% | 100% | 100% |
| Walmart | 40% | 100% | 100% |
| 90% | 100% | 80% |
Proxyway ベンチマーク(2025 年 12 月)
- 2 リクエスト/秒で
- 10 リクエスト/秒では 72.98% に低下し、負荷時に 12 ポイント下落
- 平均応答時間 25.46 秒 で、ベンチマーク群の中では最も遅い
Scrape.do ベンチマーク(2025〜2026 年)
- 総合成功率
- 個別サイトに強い:Amazon 99.11%、Indeed 99.29%、GitHub 100%、X/Twitter 99.6%
- Capterra は弱く、成功率 59%、応答時間 36 秒
見えてくる傾向
データからは、次のようなはっきりしたパターンが見えてきます。
- ScrapingBee は、保護が中程度の一般的なサイトには強い — Amazon、eBay、GitHub、Indeed では一貫して 90〜100% の成功率
- 強固に保護されたサイトでは完全に失敗することがある — LinkedIn、Zillow、Realtor.com、StockX、Twitter では複数ベンチマークで 0%
- 負荷が上がると性能がかなり落ちる — 2 req/s で 84% でも、10 req/s で 73% に低下
- ベンチマーク結果は方法論で大きく変わる — 33.3%(Scrapeway、幅広いサイト構成)から 92.69%(Scrape.do、比較的中程度の対象)まで差が大きい
ScrapingBee の (137 件)は好材料ですが、初期セットアップの満足度が高いことと、大規模運用での長期的な信頼性は必ずしも一致しません。乗り換えたユーザーが挙げる理由は、導入時の難しさではなく、失敗率の上昇とコスト増です。
「とても良いです。ScrapingBee は安定していて、予測可能で、本番環境への統合も簡単でした。」— Verified Reviewer, CEO,
ScrapingBee は「信頼性に一貫性がない」とされ、特に「Glassdoor で成功率 0%」「」という結果が出ていました。
AI ベースのスクレイピングは信頼性の扱い方が違う
Thunderbit の AI は、レンダリング済みのページをリアルタイムで読み取り、毎回のセッションごとに bot 対策やレイアウト変更へ適応します。信頼性の課題には、2 つのスクレイピングモードがあります。
- クラウドスクレイピング — Thunderbit のクラウドサーバー上で実行され、一度に最大 50 ページを処理可能。Amazon、Zillow、Shopify などの大規模な公開スクレイピングに向いている
- ブラウザスクレイピング — ユーザー自身の Chrome ブラウザ上で実行され、ログイン済みセッションをそのまま使う。LinkedIn や非公開ダッシュボード、SaaS プラットフォームのような、ScrapingBee のような API ベースのツールでは認証の奥にあるコンテンツへ届きにくいサイトに最適
Thunderbit には、人気サイト向けの もあり、あらかじめ構築・保守されているので、サイト構造が変わっても動き続けやすいです。ScrapingBee が 0% 成功を示したサイト(LinkedIn、Zillow)では、Thunderbit のブラウザスクレイピングモード――自分のログイン済みセッションを使う方法――は、根本的に違うアプローチです。
ScrapingBee vs. 主要代替ツール:横並び比較
| 観点 | ScrapingBee | Thunderbit | ScraperAPI | Scrapfly |
|---|---|---|---|---|
| タイプ | API のみ | Chrome 拡張 + API | API のみ | API のみ |
| 開始価格 | $49/月 | 無料($0) | $49/月 | $30/月 |
| クレジットモデル | 倍率あり(1×〜75×) | 1 クレジット = 1 行(倍率なし) | 倍率あり(1×〜75×) | 倍率あり(1×〜30×) |
| AI 抽出 | あり(+5 クレジット/回) | 標準搭載(AI Suggest Fields) | ネイティブ AI なし | あり |
| ノーコード対応 | なし(API のみ) | あり(Chrome 拡張) | なし(API のみ) | なし(API のみ) |
| 構造化出力 | CSS ルールまたは AI アドオンが必要 | デフォルト(型付き列) | 特定サイト向けの構造化エンドポイントあり | サイトによる |
| 出力先 | 生 HTML/JSON(自前で構築) | Excel、Sheets、Airtable、Notion、CSV、JSON(すべて無料) | 生 HTML/JSON | 生 HTML/JSON |
| サブページスクレイピング | 手動(クロールロジックを自作) | 標準搭載(1 行あたり 2 クレジット) | 手動 | 手動 |
| スケジュール実行 | CLI のみ(ダッシュボードスケジューラーなし) | 標準搭載(自然言語) | 標準機能なし | 標準機能なし |
| 無料枠 | 1,000 クレジットの試用版 | 月 6 ページ(永続無料) | 5,000 クレジット(7 日間トライアル) | 1,000 クレジット |
| JS レンダリングのデフォルト | ON(コスト 5 倍) | 含まれる(追加費用なし) | OFF | OFF |
| 学習コスト | 高い(API + セレクター) | 低い(2 クリック) | 高い(API + セレクター) | 高い(API) |
| 向いている用途 | プロキシ制御を重視する開発者 | ビジネスユーザー + 開発者 | 開発者 + 構造化エンドポイント | 開発者で ASP 回避を重視する人 |
| Capterra 評価 | 4.9/5(137 件) | — | 4.6/5(62 件) | 4.9/5(221 件) |
ScrapingBee と Thunderbit の主な違い
最大の違いは、アーキテクチャとターゲットユーザーです。
- API のみ vs. Chrome 拡張 + API: ScrapingBee は、すべての操作にコードが必要です。Thunderbit は、ノーコード向けの と、開発者向けの Open API の両方を提供します。AI エンジンは同じで、操作画面だけが違います。
- セレクター方式 vs. AI ベースの抽出: ScrapingBee では CSS/XPath セレクターを自分で書き、保守する必要があります。Thunderbit は AI が自動で項目を提案し、サイト変更にも適応します。
- 生 HTML 出力 vs. 型付き行データの無料エクスポート: ScrapingBee は、解析が必要な HTML を返します。Thunderbit は、型とラベルが付いた行データを返し、 できます。
- サブページスクレイピング: Thunderbit は、AI が各詳細ページを巡回し、メイン表を自動で補完します。自作クロールロジックは不要です。ScrapingBee では、それを自分で実装する必要があります。
- 即時テンプレート: Thunderbit には、Amazon、Zillow、Shopify、LinkedIn、Google Maps、eBay など、人気サイト向けの事前構築テンプレートがあります。ScrapingBee には Amazon と Walmart の専用 API がありますが、利用するにはやはりコードが必要です。
そのほか注目の代替ツール
- — 独立テストで 1,000 リクエストあたり $0.80 と最安クラス、成功率 98.19%、月額 $29 から
- Apify — actor ベースのプラットフォームで G2 レビュー 415 件以上(4.7/5)だが、最も多い不満は「料金問題」
- — AI/LLM ネイティブで、Markdown を返し、生 HTML より 67% 少ないトークンで済む。オープンソースのコアを持ち、月額 $16 から
- — 7,200 万以上の IP を持つエンタープライズ級。月額 $499 から、定額制
- ZenRows — 5,500 万の residential IP、Amazon/Walmart/Zillow 向けの事前構築スクレイパー、月額 $69 から
チームに合うスクレイピングツールはどれか?
シナリオ別におすすめをまとめると、次のとおりです。
- カスタムスクレイピングパイプラインを作り、細かなプロキシ制御がほしい開発者 → ScrapingBee または ScraperAPI。HTTP パラメータの細かい制御、プロキシ種別の選択、レンダリング制御ができます。ただし、クレジット倍率は予算に入れておきましょう。
- コードを書かずにウェブサイトからリードを集めたい営業・マーケチーム → 。2 クリックで構造化データ、1 クリックで Google Sheets。API もセレクターも、解析作業も不要です。
- 人気サイトから構造化データをすぐ取りたい → Thunderbit の即時テンプレート。Amazon、Zillow、Shopify、LinkedIn などに対応し、事前構築済みで保守もされています。AI の初期設定すら不要です。
- devops なしで、価格や在庫を定期監視したい → Thunderbit Scheduled Scraper。間隔を自然な日本語で伝えるだけで(「毎週月曜の午前9時」など)、そのまま実行できます。
- LLM/RAG パイプライン用に、きれいな Markdown を大量に欲しい → Thunderbit Distill API または Firecrawl。どちらも AI 消費向けに最適化された Markdown を返します。
- コストの予測しやすさを重視し、クレジット倍率を避けたい → Thunderbit。JS レンダリングやプロキシ種別に関係なく、1 クレジット = 1 行です。
総保有コストは API 価格だけではありません。セットアップ時間 + 保守工数 + 解析の実装 + データ出力のワークフローまで含めて考える必要があります。ScrapingBee の表示価格は競争力がありますが、全体コストで見ると話は別です。
この ScrapingBee レビューの重要ポイント
覚えておきたい点は 5 つあります。
- クレジットコストは規模が大きくなるほど急激に膨らむ。 $49 の入口価格でも、JS レンダリングや premium プロキシが必要になると $599 超になり得ます。Thunderbit の 1 行 = 1 クレジットの固定モデルなら、この不確実性を避けられます。
- CSS セレクターには継続的な保守負担があり、AI 抽出はそれを回避する。 AI ベースのツールなら が期待でき、サイト更新時のセレクター破損も起こりません。
- 非開発者にとって ScrapingBee の学習コストは高い。 コーディング、HTML の確認、セレクター作成が必要な API 専用ツールです。ビジネスユーザーはノーコード代替を検討すべきです。
- データ出力には自前の実装が必要。 ScrapingBee は生 HTML を返し、パイプラインは自分で作ります。Thunderbit なら に構造化データを無料で出力できます。
- 一部のサイトでは強いが、他では不安定。 Amazon や eBay ではうまく動く一方で、LinkedIn、Zillow など強く保護された対象では 0% になることがあります。
ScrapingBee は、プロキシ管理された HTTP アクセスを細かく制御したい開発者にとっては、今でも十分使えるツールです。ただし、2026 年の Web スクレイピング市場は AI ベースのノーコードツールへと移りつつあり、 はまさにその変化に合わせて設計されています。まずは無料枠(無料 6 ページ、または無料トライアルでもっと多く)で、その違いを体感してみてください。
よくある質問
2026 年に ScrapingBee は使う価値がありますか?
答えは、技術力と処理規模次第です。静的ページを中程度の件数でスクレイピングする開発者にとっては、ScrapingBee は堅実で、ドキュメントも整っており、サポートも反応が早く、 の評価があります。一方、ビジネスユーザーや大量処理、あるいはコーディングなしで構造化データがほしいチームには、Thunderbit のような AI ベースの代替のほうが価値が高く、総保有コストもかなり低くなります。
ScrapingBee はコードなしで使えますか?
いいえ。ScrapingBee は API 専用ツールなので、Python、cURL などでコードを書く必要があり、HTTP パラメータの理解も求められます。スクレイピングを組み立てるためのビジュアル画面はありません。非技術ユーザーは、 のようなノーコード विकल्प を検討したほうがよいです。コードを 1 行も書かずにデータを抽出して、そのままエクスポートできます。
ScrapingBee の実際の 1 ページあたりのコストはどれくらいですか?
有効にする機能によって変わります。静的 HTML ページは 1 クレジットです。JS レンダリング付きページ(デフォルト)は です。premium プロキシ + JS のページは 25 クレジット、stealth プロキシのページは 75 クレジットです。AI 抽出を使うと、さらに +5 クレジットかかります。Freelance プラン($49/25 万クレジット)では、静的ページ 1,000 枚あたり $0.20、stealth プロキシのページ 1,000 枚あたり $14.70 です。詳細は上のコスト表を参照してください。
2026 年の ScrapingBee の代替として有力なのは?
有力候補には、(AI ベース、ノーコードの Chrome 拡張 + API、1 クレジット = 1 行)、(特定サイト向けの構造化エンドポイントを持つ開発者向け API)、(強力な bot 回避機能を持つ開発者向け API)、(独立テストで最安のリクエスト単価)、(AI/LLM ネイティブで、きれいな Markdown を返す)があります。それぞれ得意分野が異なり、Thunderbit はビジネスユーザーとコスト予測を重視する人向け、ScraperAPI と Scrapfly はプロキシ制御を重視する開発者向け、Firecrawl は LLM パイプライン向けです。
ScrapingBee は JavaScript が重いサイトをスクレイピングできますか?
はい、できます。ただし、回転プロキシではベース料金の 5 倍、premium プロキシでは 25 倍のコストがかかります。JavaScript レンダリングは なので、明示的にオフにしない限り、すでに 5 倍料金を払っていることになります。Thunderbit は JavaScript レンダリングを自動で処理しつつ、クレジット倍率はありません。ページの作りに関係なく、1 行あたり 1 クレジットです。
関連リンク