

いまや全ウェブサイトの98.7%がJavaScriptで作られている——この一点が、昔ながらのスクレイピングのやり方を時代遅れにしました。コンテンツはページを開いた瞬間にすべて揃うのではなく、スクロールやクリックに応じて少しずつ運ばれてくる。無限スクロール、ポップアップ、数回操作してようやく中身が見えるダッシュボード。こうした作りが当たり前になった結果、静的なHTMLだけを読みに行くツールでは、価値あるデータの多くが手からこぼれ落ちます。最新のECサイトで商品価格を拾おうとしたり、操作できる地図から物件一覧を集めようとして、欲しい数字がソースのどこにも見当たらず途方に暮れた——そんな経験があるなら、この話はすぐに腑に落ちるでしょう。
その壁を越える手段が、Seleniumによるスクレイピングです。私はこれまで長く自動化ツールを手がけ、数えきれないほどのサイトを相手にしてきました。その実感として断言できるのは、動的で最新のデータを欲しがる人にとって、Seleniumを操れることが強力な切り札になるということです。この実践的な入門記事では、環境構築から自動化までの勘どころを順を追って押さえ、最後に Thunderbit と合わせて、そのまま書き出せる構造化データを仕上げる流れまで紹介します。ビジネスアナリストでも営業担当でも、Pythonをちょっとかじってみたいだけの方でも、現場で使えるスキルとちょっとした笑いを土産に持って帰れるはずです(XPathセレクターのデバッグが人を成長させる、というのはもはや一種の真理です)。
Selenium とは何か? そしてなぜウェブスクレイピングに使うのか?
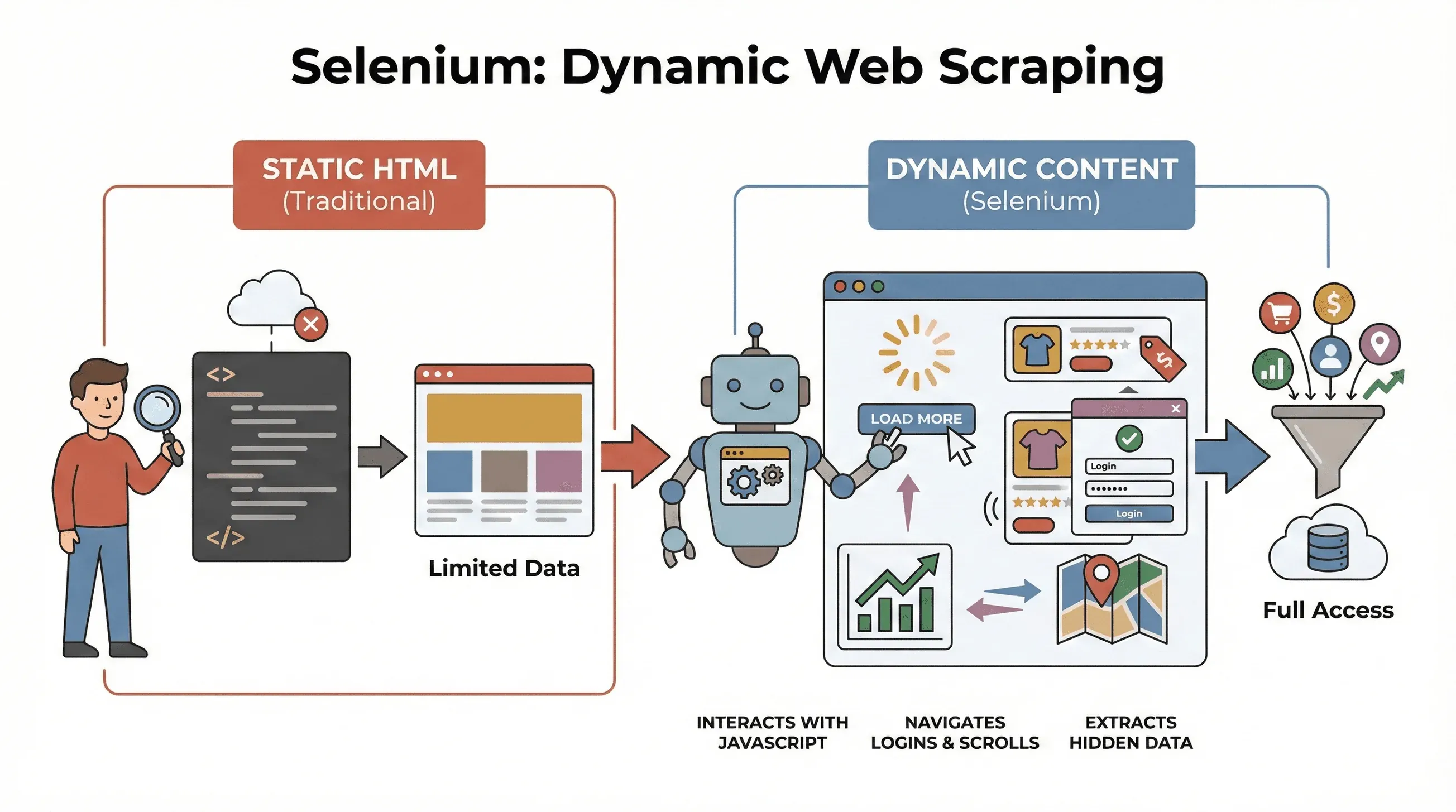 Selenium は、コードからChromeやFirefoxといった本物のブラウザを操れるオープンソースのフレームワークです。まずはここを押さえましょう。ページを開き、ボタンを押し、フォームを埋め、スクロールし、さらにはJavaScriptまで走らせる——人間が手でやるのと同じ動作を肩代わりしてくれる“ロボット”だと思ってください。なぜこれが効くのか。理由は、いまどきのサイトの大半が、最初の段階ですべてのデータを見せてくれるわけではないからです。多くの場面では、ユーザーが何か操作したあとに、コンテンツが後追いで読み込まれます。
Selenium は、コードからChromeやFirefoxといった本物のブラウザを操れるオープンソースのフレームワークです。まずはここを押さえましょう。ページを開き、ボタンを押し、フォームを埋め、スクロールし、さらにはJavaScriptまで走らせる——人間が手でやるのと同じ動作を肩代わりしてくれる“ロボット”だと思ってください。なぜこれが効くのか。理由は、いまどきのサイトの大半が、最初の段階ですべてのデータを見せてくれるわけではないからです。多くの場面では、ユーザーが何か操作したあとに、コンテンツが後追いで読み込まれます。
データスクレイピングとは何か? 2026年版のやり方 Get Started Free
ではなぜ、これがスクレイピングで決定的なのでしょうか。 BeautifulSoupやScrapyといった従来のツールは、静的HTMLの解析にはめっぽう強い反面、初回読み込みのあとにJavaScriptが書き加えた中身には手が届きません。対してSeleniumは、ページとリアルタイムにやり取りできます。だからこそ、次のような場面でこそ真価を発揮します。
- 「もっと見る」をクリックしたあとに表示される商品一覧の取得
- 動的に更新される価格やレビューの収集
- ログインフォーム、ポップアップ、無限スクロールの操作
- ダッシュボード、地図、その他のインタラクティブ要素からのデータ抽出
つまり、ページが読み込み終わったあと、あるいはユーザーが操作したあとにしか姿を現さないデータを狙うなら、まず手に取るべきはSeleniumというわけです。
Python と Selenium を使ったウェブスクレイピングの重要ステップ
Seleniumでのスクレイピングは、突き詰めれば3つの大きなステップに整理できます。
| ステップ | やること | 重要な理由 |
|---|---|---|
| 1. 環境セットアップ | Selenium、WebDriver、Python ライブラリをインストールする | ツールを使えるようにして、セットアップのつまずきを減らすため |
| 2. 要素の特定 | ID、クラス、XPath などを使って欲しいデータを見つける | JavaScript に隠れていても、必要な情報を正確に狙えるため |
| 3. データの抽出と保存 | テキスト、リンク、表を取り出して CSV/Excel に保存する | 生のウェブデータを実際に使える形にするため |
それでは、実例を交えながらステップごとに進めていきましょう。コピーして少し手直しすれば、すぐ動かせて、仲間に見せて自慢できる代物になるはずです。
ステップ 1: Python と Selenium の環境を整える
最初にやるべきは、Seleniumとブラウザドライバー(Chromeなら ChromeDriver など)の導入です。ありがたいことに、この手順は昔に比べて格段に楽になりました。
Selenium をインストールする
ターミナルを開いて、次を実行します。
pip install selenium
WebDriver を入手する
- Chrome: ChromeDriver をダウンロードします(Chrome のバージョンと一致していることを確認してください)。
- Firefox: GeckoDriver をダウンロードします。
ワンポイント: Selenium 4.6 以降では Selenium Manager を使ってドライバーを自動ダウンロードできるので、もう PATH 変数をいじる必要すらないかもしれません(ドキュメント)。
最初の Selenium スクリプト
Selenium の “Hello, world!” はこんな感じです。
from selenium import webdriver
driver = webdriver.Chrome() # または webdriver.Firefox()
driver.get("https://example.com")
print(driver.title)
driver.quit()
トラブルシューティングのヒント:
- 「driver not found」エラーが出る場合は、PATH を確認するか Selenium Manager を使ってください。
- ブラウザとドライバーのバージョンが一致していることを確認してください。
- GUI のないヘッドレスサーバーで動かす場合は、下のヘッドレスモードのヒントを参照してください。
ステップ 2: データ抽出のためにウェブ要素を特定する
ここからが本番です。「どのデータが欲しいのか」をSeleniumに教えてあげます。ウェブページは div や span、table といった要素の積み重ねでできており、Seleniumにはそれらを拾い上げる手段がいくつも用意されています。
よく使う検索方法
By.ID: 一意の ID を持つ要素を見つけるBy.CLASS_NAME: CSS クラスで要素を見つけるBy.XPATH: XPath 式を使う(非常に柔軟ですが、壊れやすいこともある)By.CSS_SELECTOR: CSS セレクターを使う(複雑な条件に便利)
使い方はこんな感じです。
from selenium.webdriver.common.by import By
# ID で探す
price = driver.find_element(By.ID, "price").text
# XPath で探す
title = driver.find_element(By.XPATH, "//h1").text
# CSS セレクターで商品画像をすべて探す
images = driver.find_elements(By.CSS_SELECTOR, ".product img")
for img in images:
print(img.get_attribute("src"))
ワンポイント: locator は、なるべく単純で崩れにくいものを選ぶのが鉄則です(ID > class > CSS > XPath の順で優先)。加えて、データの表示にひと呼吸かかるページを相手にするなら、明示的な待機を挟むのが基本になります。
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
wait = WebDriverWait(driver, 10)
price_elem = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, ".price")))
こうしておけば、データの描画が多少遅れたくらいでは、スクリプトがあっさり落ちることはなくなります。
ステップ 3: データを抽出して保存する
狙った要素を捕まえたら、いよいよデータを取り出し、使い勝手のよい場所へしまい込みます。
テキスト、リンク、表を抽出する
たとえば、商品一覧の表をスクレイピングする場合はこうです。
data = []
rows = driver.find_elements(By.XPATH, "//table/tbody/tr")
for row in rows:
cells = row.find_elements(By.TAG_NAME, "td")
data.append([cell.text for cell in cells])
Pandas で CSV に保存する
import pandas as pd
df = pd.DataFrame(data, columns=["名前", "価格", "在庫"])
df.to_csv("products.csv", index=False)
CSVだけでなくExcel形式(df.to_excel("products.xlsx"))に落とすこともできますし、APIを介してGoogle Sheetsへ送り込むことも可能です。
完全な例: 商品タイトルと価格をスクレイピングする
from selenium import webdriver
from selenium.webdriver.common.by import By
import pandas as pd
driver = webdriver.Chrome()
driver.get("https://example.com/products")
data = []
products = driver.find_elements(By.CLASS_NAME, "product-card")
for p in products:
title = p.find_element(By.CLASS_NAME, "title").text
price = p.find_element(By.CLASS_NAME, "price").text
data.append([title, price])
driver.quit()
df = pd.DataFrame(data, columns=["タイトル", "価格"])
df.to_csv("products.csv", index=False)
Selenium と BeautifulSoup / Scrapy の違いとは?
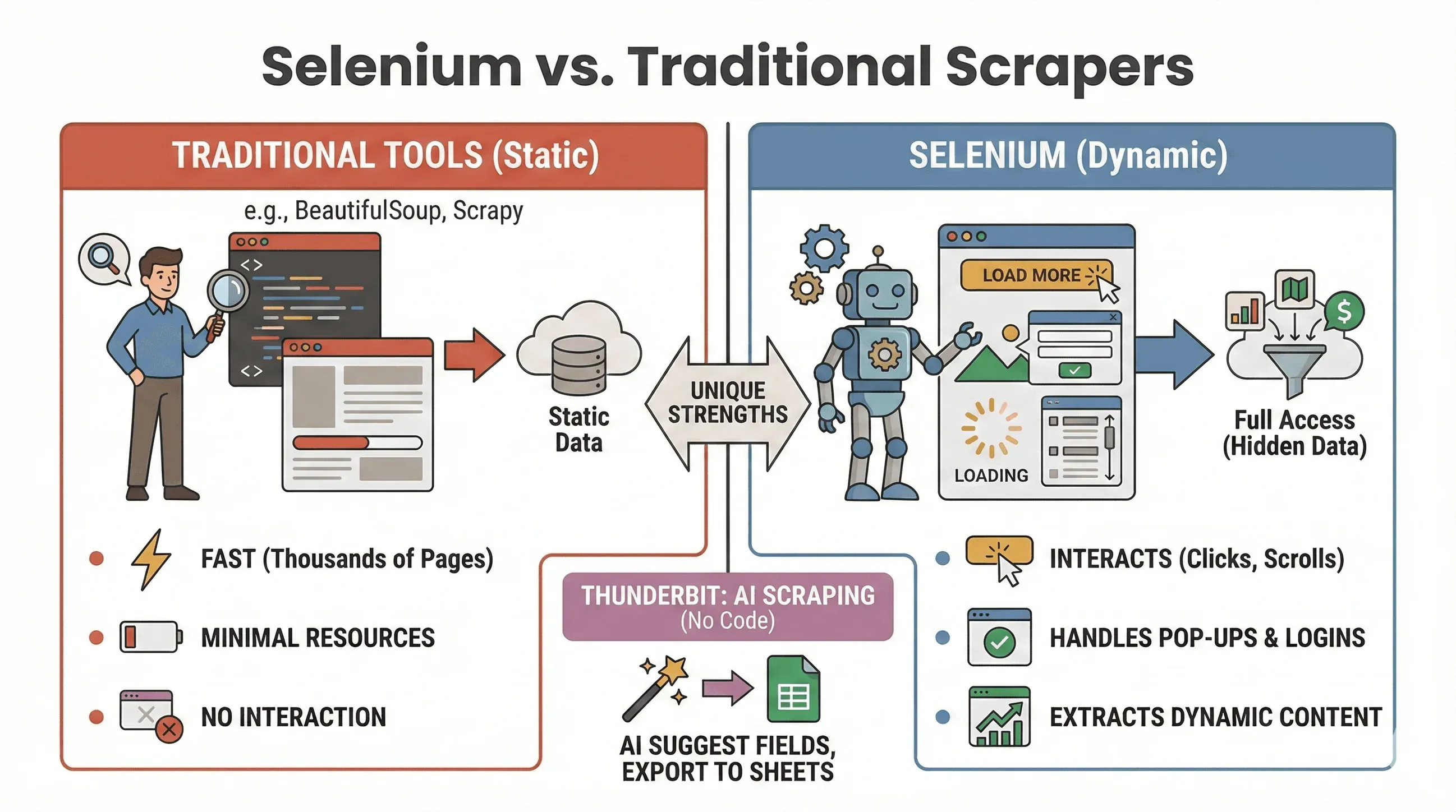 よく持ち上がる論争に、ここで一区切りつけておきましょう。どんなときにSeleniumを選び、どんなときにBeautifulSoupやScrapyに軍配が上がるのか。ざっと表で見比べてみます。
よく持ち上がる論争に、ここで一区切りつけておきましょう。どんなときにSeleniumを選び、どんなときにBeautifulSoupやScrapyに軍配が上がるのか。ざっと表で見比べてみます。
| ツール | 最適な用途 | JavaScript 対応 | 速度・リソース使用量 |
|---|---|---|---|
| Selenium | 動的・インタラクティブなサイト | はい | やや遅く、メモリを多く使う |
| BeautifulSoup | 単純な静的 HTML のスクレイピング | いいえ | 非常に高速で軽量 |
| Scrapy | 大量の静的サイトのクロール | 限定的* | 超高速、非同期、RAM 消費が少ない |
| Thunderbit | ノーコードの業務向けスクレイピング | はい(AI) | 小規模〜中規模の作業に高速 |
* Scrapy はプラグインを使えば一部の動的コンテンツに対応できますが、得意分野ではありません(ScrapingBee)。
Selenium を使うべき場面:
- データがクリック、スクロール、ログイン後にしか表示されない
- ポップアップ、無限スクロール、動的なダッシュボードを操作する必要がある
- 静的スクレイパーでは対応しきれない
BeautifulSoup / Scrapy を使うべき場面:
- データが最初の HTML に含まれている
- 数千ページを高速にスクレイピングしたい
- リソース消費をできるだけ抑えたい
なお、一行もコードを書きたくないという向きには、Thunderbit という手があります。AIの力で動的サイトを相手にでき、あとは「AI Suggest Fields」を押して、Sheets や Notion、Airtable へ書き出すだけ。詳しくはこのあと触れます。
AI でどんなウェブサイトでもスクレイピングする方法 Get Started Free
Selenium と Python でウェブスクレイピングを自動化する
スクレイピングのスクリプトを動かすために、わざわざ午前2時に布団から這い出したい人など、まずいないでしょう。安心してください。PythonのスケジューリングツールやOSのスケジューラ——Linux/Macのcron、WindowsのTask Scheduler——を活用すれば、Seleniumの処理は自動で回せます。
schedule ライブラリを使う
import schedule
import time
def job():
# ここにスクレイピングコードを書く
print("スクレイピング中...")
schedule.every().day.at("09:00").do(job)
while True:
schedule.run_pending()
time.sleep(1)
cron を使う場合(Linux/Mac)
1 時間ごとに実行したいなら、crontab に次を追加します。
0 * * * * python /path/to/your_script.py
自動化のヒント:
- GUI のポップアップを避けるため、Selenium はヘッドレスモードで実行します(下記参照)。
- エラーを記録し、何か問題が起きたら自分に通知を送るようにします。
- リソースを解放するため、最後は必ず
driver.quit()でブラウザを閉じます。
効率を上げる: より速く、より安定した Selenium スクレイピングのコツ
Seleniumは頼もしい一方で、気を抜くと処理がもたつき、リソースをむやみに食い潰すこともあります。ここからは、スピードを稼ぎつつ、ありがちな落とし穴を回避するコツをまとめます。
1. ヘッドレスモードで実行する
Chromeのウィンドウが何度も開いては閉じる様子を、いちいち眺めている必要はありません。ヘッドレスモードにすれば、ブラウザは画面の裏側で黙々と働いてくれます。
from selenium.webdriver.chrome.options import Options
opts = Options()
opts.headless = True
driver = webdriver.Chrome(options=opts)
2. 画像や不要なコンテンツをブロックする
テキストだけが目当てなら、わざわざ画像を読み込ませる理由はありません。ブロックしてしまえば、その分ページの表示が軽くなります。
prefs = {"profile.managed_default_content_settings.images": 2}
opts.add_experimental_option("prefs", prefs)
3. 効率的な locator を使う
- 複雑な XPath よりも、ID やシンプルな CSS セレクターを優先する
time.sleep()はできるだけ避け、代わりに明示的な待機(WebDriverWait)を使う
4. 待機時間をランダム化する
人間のブラウジングに近づけてブロックされにくくするため、ランダムな待ち時間を入れます。
import random, time
time.sleep(random.uniform(1, 3))
5. User-Agent と IP をローテーションする(必要なら)
大量にスクレイピングする場合は、User-Agent 文字列を切り替え、簡単な bot 対策を避けるためにプロキシの利用も検討してください。
6. セッションとエラーを管理する
try/exceptで要素がない場合も落ちずに処理する- エラーをログに残し、デバッグ用にスクリーンショットを保存する
もっと最適化の引き出しが欲しければ、BrowserStack のガイド ものぞいてみる価値があります。
応用編: Selenium と Thunderbit を組み合わせて構造化データを出力する
さて、いよいよ本領発揮の場面です。とりわけ、データの整形や書き出しの手間を減らしたい人には、ここからが効いてきます。
Seleniumで生のデータを掴んだあと、Thunderbit に渡すと、こんなことが叶います。
- フィールドを自動検出: Thunderbit の AI が、スクレイピングしたページや CSV を読み取り、列名を提案します(「AI Suggest Fields」)。
- サブページのスクレイピング: 商品ページのように URL の一覧がある場合、Thunderbit が各ページを巡回して、表に追加情報を補完できます。追加のコードは不要です。
- データの強化: その場で翻訳、分類、分析ができます。
- どこへでも出力: Google Sheets、Airtable、Notion、CSV、Excel にワンクリックでエクスポートできます。
ワークフロー例:
- Selenium で商品 URL とタイトルの一覧をスクレイピングする。
- データを CSV に出力する。
- Thunderbit を開き、CSV を取り込んで AI にフィールドを提案させる。
- Thunderbit のサブページスクレイピングで、各商品 URL から画像や仕様などの詳細を取得する。
- 最終的に構造化されたデータセットを Sheets や Notion に出力する。
この合わせ技なら、ぐちゃぐちゃなデータの後片付けに何時間も削られることなく、整形作業ではなく分析そのものに頭を使えます。このワークフローをもっと深掘りしたい方は、Thunderbit の Selenium ガイド をどうぞ。
Thunderbit AI で Selenium データを出力する
Selenium ウェブスクレイピングのベストプラクティスとトラブルシューティング
ウェブスクレイピングは、どこか釣りに通じるところがあります。狙い通りの大物が上がる日もあれば、針が藻に絡まって動かなくなる日もある。ここでは、スクリプトを安定して動かし、なおかつ後ろ指を差されない使い方をするためのポイントを挙げておきます。
ベストプラクティス
- robots.txt とサイト規約を尊重する: スクレイピングが許可されているか必ず確認する
- リクエストを制限する: サーバーに負荷をかけすぎないように、待機時間を入れ、HTTP 429 エラーに注意する
- 利用可能なら API を使う: データが API で公開されているなら、そちらを使うほうが安全で安定している
- 公開データだけを取得する: 個人情報や機微な情報は避け、プライバシー法にも注意する
- ポップアップと CAPTCHA に対応する: Selenium でポップアップを閉じることはできますが、CAPTCHA は自動化がかなり難しいので慎重に
- User-Agent と待機時間をランダム化する: 検知やブロックを避けやすくなる
よくあるエラーと対処法
| エラー | 意味 | 対処法 |
|---|---|---|
NoSuchElementException | 要素が見つからない | locator を再確認し、待機を使う |
| タイムアウトエラー | ページまたは要素の表示に時間がかかりすぎた | 待機時間を延ばす。通信速度も確認する |
| ドライバーとブラウザの不一致 | Selenium がブラウザを起動できない | ドライバーとブラウザのバージョンを更新する |
| セッションのクラッシュ | ブラウザが予期せず閉じた | ヘッドレスモードを使い、リソースを管理する |
さらに突っ込んだトラブルシューティングを知りたければ、Thunderbit の Selenium チュートリアル も合わせて参照してください。
まとめと重要ポイント
動的なウェブスクレイピングは、もはやベテラン開発者だけに許された芸当ではありません。PythonとSeleniumさえあれば、どんなブラウザも自在に操り、JavaScriptで固められた手強いサイトとも渡り合いながら、営業・リサーチ・あるいは純粋な好奇心のために必要なデータを引き出せます。心に留めておきたい要点はこちらです。
- Selenium は、動的でインタラクティブなサイトに最適なツールです。
- 重要な 3 ステップ は、セットアップ、要素の特定、抽出と保存です。
- スクリプトは自動化 して、定期的にデータを更新しましょう。
- ヘッドレスモード、適切な待機、効率的な locator を使って、速度と信頼性を高めましょう。
- Selenium と Thunderbit を組み合わせる と、データの構造化と出力が簡単になります。特に、スプレッドシート周りの面倒を避けたいならおすすめです。
さあ、自分の手で動かしてみる準備はできましたか。まずは上のコード例を足がかりにしてみてください。そして、スクレイピングをもう一段上へ引き上げたくなったら、Thunderbit を試して、AIによる即席のデータ整理と書き出しを味わってみましょう。もっと学びたい方は、Thunderbit Blog で掘り下げ記事やチュートリアル、ウェブ自動化の最新情報をチェックしてください。
それでは、楽しいスクレイピングを。あなたのセレクターが、いつでも探し物を言い当ててくれますように。
Thunderbit AIウェブスクレイパーを無料で試す Get Started Free
FAQ
1. ウェブスクレイピングに BeautifulSoup や Scrapy ではなく Selenium を使うべきなのはなぜですか?
Selenium は、ユーザー操作や JavaScript 実行のあとにコンテンツが読み込まれる動的サイトのスクレイピングに最適です。BeautifulSoup と Scrapy は静的 HTML には高速ですが、動的要素の操作やクリック、スクロールの再現はできません。
2. Selenium のスクレイパーをもっと速く動かすにはどうすればいいですか?
ヘッドレスモードを使い、画像や不要なリソースをブロックし、効率的な locator を使い、人間のブラウジングを模したランダムな待機時間を追加してください。さらに詳しいヒントは BrowserStack のガイド をご覧ください。
3. Selenium のスクレイピング処理を自動実行するようにスケジュールできますか?
はい。Python の schedule ライブラリ、または OS のスケジューラ(cron や Task Scheduler)を使って、決まった間隔でスクリプトを実行できます。スクレイピングを自動化すると、データを常に最新に保ちやすくなります。
4. Selenium で取得したデータを出力する最善の方法は何ですか?
Pandas を使って CSV か Excel に保存するのがおすすめです。さらに高度な出力(Google Sheets、Notion、Airtable など)を行いたい場合は、データを Thunderbit に取り込み、ワンクリック出力機能を使ってください。
5. Selenium でポップアップや CAPTCHA はどう扱えばいいですか?
ポップアップは、要素を見つけて閉じるボタンをクリックすれば対応できます。CAPTCHA はずっと難しいため、遭遇した場合は手動の回避策や CAPTCHA 解決サービスの利用を検討し、常にサイトの利用規約を守ってください。
スクレイピングのチュートリアル、AI 自動化のヒント、ビジネスデータツールの最新情報をもっと見たいですか? Thunderbit Blog を購読するか、YouTube チャンネル で実践デモをご覧ください。
さらに詳しく




