2026年、営業やオペレーション、どんなビジネス部門で働いていても、ウェブが情報の宝庫である一方で、膨大な時間を奪う存在だと痛感している人は多いはずです。リード情報や価格、レビュー、競合の動きなど、役立つデータは山ほどあるのに、それをスプレッドシートやダッシュボードにまとめる作業は本当に骨が折れます。手作業でコピペを繰り返しても、結局データはバラバラで古くなりがち。スプレッドシート疲れでチームのやる気が下がることも珍しくありません。

でも、もう安心してください。他のウェブサイトからのコンテンツ抽出は、開発者やデータサイエンティストだけの特権じゃありません。AI搭載のノーコードツール、たとえばのようなサービスが登場したことで、ITに自信がない人でも、必要なデータをサクッと・正確に・ストレスフリーで手に入れられる時代になりました。この記事では、ウェブスクレイピングの基本から、なぜ今ビジネスに欠かせないのか、そして2026年に効率的(しかも合法的)にウェブサイトからコンテンツを抽出する方法まで、分かりやすく紹介します。初心者も、もっと効率を上げたい人も、ぜひチェックしてみてください。
「他のウェブサイトからのコンテンツ抽出」って何?
ざっくり言うと、他のウェブサイトからのコンテンツ抽出は、専用ソフトを使ってウェブページ上の情報を自動で集めて、表やスプレッドシート、データベースなどに整理することです。商品情報や連絡先、レビューなどを手作業でコピペする代わりに、웹 스크래퍼が一気に処理してくれます()。
イメージとしては、図書館で本の内容を一冊ずつ手書きでメモする代わりに、ロボットアシスタントがページをスキャンして要点をきれいにまとめてくれる感じ。それがウェブスクレイピングの役割です。
なぜウェブサイトからコンテンツを抽出するのか?
- リード獲得: 企業ディレクトリやビジネスリストから名前・メール・電話番号を集める
- 競合調査: ECサイトで価格や新商品、レビューをモニタリング
- 市場調査: ニュースやブログ、フォーラムの投稿を集めてトレンドを把握
- コンテンツ集約: ニュースレターや社内ナレッジ用に記事やリソースをまとめる
手作業のコピペと自動スクレイピングでは、スピードも正確さもまるで違います。数千ページ分のデータも、数分でゲットできるんです()。
ビジネスユーザーにとって「他のウェブサイトからのコンテンツ抽出」が大事な理由
もし今も手作業で情報を集めているなら、現代のチームが手にしているスピードやデータ活用のメリットを逃しているかもしれません。データドリブンな会社はさせていて、2026年にはが完全にデータドリブンになると予想されています。
ウェブサイトからのコンテンツ抽出がビジネスにもたらす価値はこんな感じです:
| 活用例 | 抽出対象 | メリット |
|---|---|---|
| リード獲得 | 企業ディレクトリ、LinkedIn、イエローページ | 見込み顧客リストを効率的に作成、営業パイプラインを強化 |
| 価格モニタリング | 競合商品リスト、ECサイト | リアルタイムで価格戦略を調整 |
| 顧客インサイト | レビュー、SNS投稿、フォーラム | フィードバック分析、トレンド把握、商品改善 |
| コンテンツ集約 | ニュースサイト、ブログ、業界フォーラム | 業界ニュースのキュレーション、コンテンツマーケティングに活用 |
こうした作業を自動化すれば、単なる時短だけじゃなく、もっと早く・的確に意思決定できて、チームは本当に大事な仕事に集中できます()。
最適なウェブスクレイピングツールの選び方:初心者向けガイド
ウェブサイトからコンテンツを抽出するのが初めてなら、まずは自分に合ったツール選びが大切です。僕もいろいろ失敗してきましたが、技術レベルや対象サイトの複雑さ、どれだけ早く結果を出したいかで選ぶべきツールは変わります。
主なウェブスクレイピングツールの種類:
- コード型ツール(例:Python+BeautifulSoupやScrapy): 柔軟性は抜群だけど、プログラミングが必要。エンジニアやITサポートがあるチーム向け。
- ノーコード型ツール(例:ParseHub、Octoparse): ビジュアル操作やテンプレート、クリック操作で使える。非エンジニア向けだけど、複雑なサイトだとちょっと難しいことも。
- ブラウザ拡張機能(例:Thunderbit、Web Scraper): Chrome上で動いて、インストールも簡単。サクッとピンポイントでデータを抜きたい時にぴったり。
特にビジネスユーザーや初心者には、使いやすさが一番大事。だからこそ、みたいなブラウザ拡張機能から始めるのがおすすめです。ノーコードでAIがサポートしてくれるから、誰でもすぐに使いこなせます。
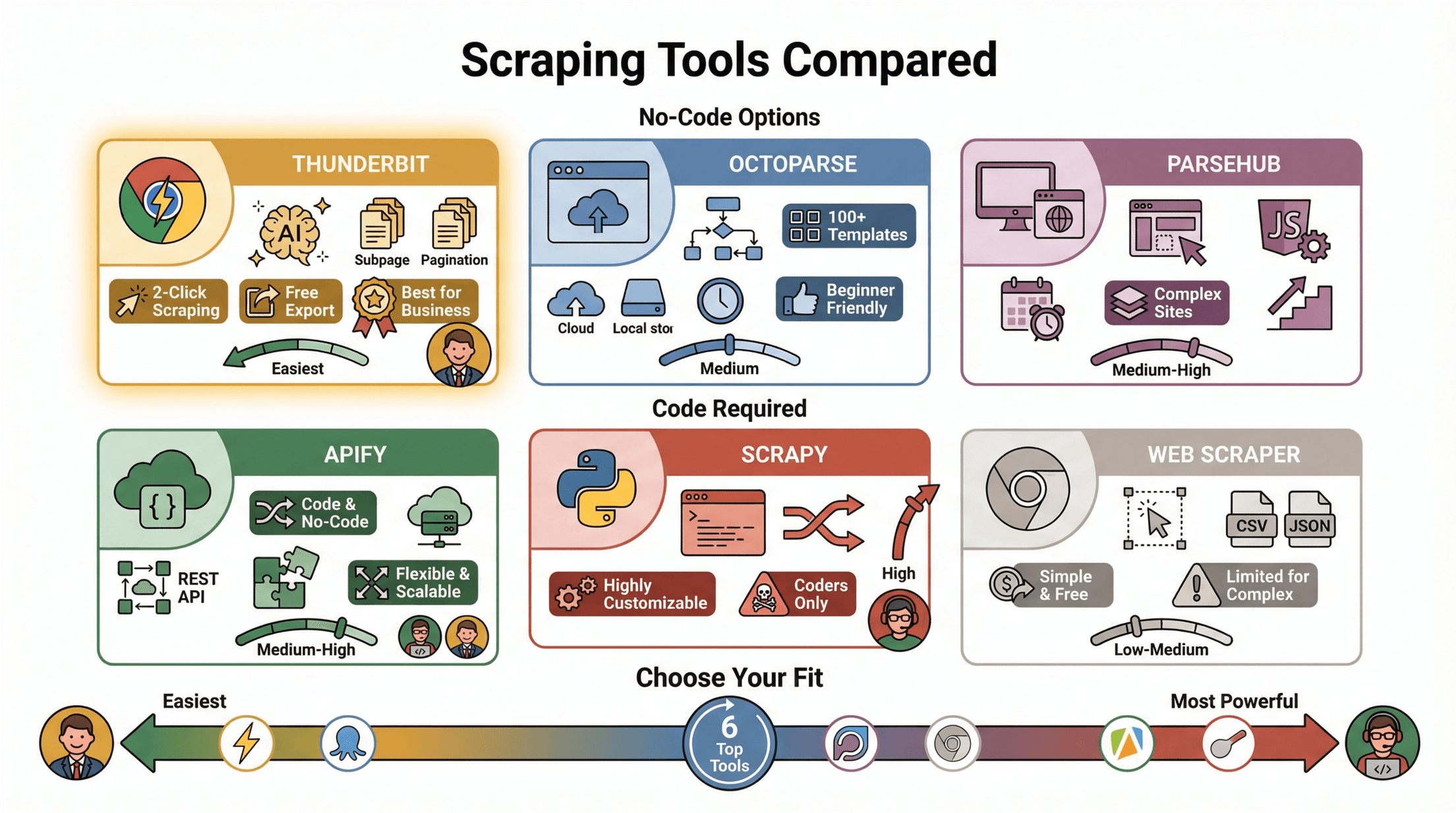
人気ウェブスクレイピングツールの比較
主要なツールをざっくり比較してみましょう:
| ツール名 | タイプ | 主な特徴 | メリット / デメリット |
|---|---|---|---|
| Thunderbit | Chrome拡張機能・AI | 2クリック抽出、AIフィールド提案、サブページ・ページ分割対応、無料エクスポート | 超簡単、ノーコード、ビジネスユーザーに最適 |
| Octoparse | デスクトップアプリ・ノーコード | ビジュアル操作、100以上のテンプレート、クラウド/ローカル、スケジューリング | 初心者向けだが無料枠は制限あり |
| ParseHub | デスクトップ/ウェブ・ノーコード | ビジュアルビルダー、動的/JSページ対応、スケジューリング | 複雑なサイトも対応、やや学習コスト高 |
| Apify | クラウド/コード/ノーコード | コード・ノーコード両対応、サーバーレス、REST API、連携 | 柔軟・拡張性高いが技術知識が必要 |
| Scrapy | Pythonライブラリ・コード | 非同期クロール、高度なカスタマイズ | 強力だがプログラマー向け |
| Web Scraper | Chrome拡張機能・ノーコード | ビジュアル選択、CSV/JSONエクスポート | シンプル・無料、複雑なサイトにはやや不向き |
多くのビジネスユーザーには、ThunderbitやOctoparseが一番手軽に始められる選択肢です()。
Thunderbitがウェブサイトからのコンテンツ抽出で選ばれる理由
ここでThunderbitの魅力をちょっと紹介します。Thunderbitの一番の強みは、初心者やビジネスユーザーでも直感的に使えること。
Thunderbitのポイント:
- 自然言語インターフェース: 「このページの全レビューと評価を取得したい」みたいに入力するだけで、AIが最適な抽出方法を自動で判断。
- AIフィールド提案&最適化: ページを解析して、名前・価格・メールなど最適なカラムを自動で提案。セレクタやコードの知識は一切不要。
- 2クリック操作: 「AIフィールド提案」→「スクレイピング」だけで完了。パソコンが苦手な人でも迷いません。
- サブページ・ページ分割対応: 商品詳細やレビューなど、リンク先の詳細ページや複数ページも自動で巡回・抽出。
- 即時エクスポート: 抽出データはExcel、Google Sheets、Airtable、Notionへワンクリックで転送。追加費用もかかりません。
例: ECサイトのレビューを抽出したい時は、レビュー一覧ページを開いてThunderbitアイコンをクリック、「AIフィールド提案」を選ぶと「レビュアー名」「評価」「レビュー内容」などが自動で提案されます。「スクレイピング」を押せば完了。さらに詳細が必要なら「サブページ抽出」で個別ページの情報も取得できます。
実際のユーザーからも「長いページでもスムーズに抽出できた」「動的なサイトも簡単だった」と高評価をもらっています()。
複雑なウェブサイトの抽出:ページ分割・サブページ対応
正直、すべてのウェブサイトがデータ抽出しやすいわけじゃありません。ECやディレクトリ、レビューサイトはページ分割(複数ページに分かれたリスト)やサブページ(詳細情報が個別ページにある)をよく使います。
課題: 従来のスクレイパーだと「次へ」ボタンやサブページのデータを見落としがち。手作業だとクリック地獄です。
Thunderbitの解決策: AIがページ分割や無限スクロールを自動で検出し、全データを漏れなく取得。サブページも各リンクをたどって追加情報を抽出し、メインデータにまとめてくれます。
実践:複数ページ・サブページのスクレイピング手順
Thunderbitで複雑なサイトを攻略する流れはこんな感じ:
- メインリストページを開く(例:ECカテゴリやディレクトリ)
- Thunderbitアイコンをクリックして「AIフィールド提案」。商品名・価格・リンクなどが自動で提案されます。
- 「スクレイピング」をクリック。今のページの全アイテムを抽出し、ページ分割も自動で巡回。
- さらに詳細が必要なら「サブページ抽出」。各アイテムの詳細ページを訪問し、レビューや仕様、連絡先など追加情報を取得。
- データを確認してエクスポート。
ポイント: 「詳細」「レビュー」「連絡先」などのリンクがある場合はサブページ抽出が便利。EC、イエローページ、不動産リストなどにぴったりです。
抽出データの整理・分析:タグ付け・カテゴリ分け・エクスポート
データを抽出しただけじゃ終わりじゃありません。価値を最大化するには、整理・分析・共有が大事です。
Thunderbitなら簡単にできること:
- タグ・カテゴリ付与: 「商品タイプ」「地域」「リードステータス」など、後から絞り込みや分析しやすいようにフィールドごとにタグやカテゴリを追加。
- フィールドAIプロンプト: SKUの分類やレビューの翻訳など、カスタム指示を追加すればAIが自動で処理。
- エクスポート: Excel、Google Sheets、Airtable、Notionへ即時転送。CSVやJSONでのダウンロードもOK。
データ整理のコツ:
- カラム名は分かりやすく統一
- タグやカテゴリで絞り込みやすく
- 生データと整形済みデータを両方保存
- 定期エクスポートやスケジュール抽出も活用
営業チームならリードのソースやステータスで分類、オペレーションなら仕入先や地域ごとに商品を整理するなど、使い道は無限大です。
法令遵守:ウェブサイトからのコンテンツ抽出時の注意点
ウェブスクレイピングを始める前に、法令遵守もちゃんと押さえておきましょう。公開データの抽出は基本的に合法ですが、いくつか守るべきルールがあります(, )。
主な注意点:
- 公開情報のみ抽出。 ログインや有料壁、セキュリティを回避しない。
- robots.txtや利用規約を尊重。 法的拘束力がなくても、サイト運営者の意向は確認しよう。
- 著作権や個人情報は避ける。 名前・価格・仕様など事実情報に限定し、著作権のある文章や画像の大量取得・再配布はNG。
- 出典明記。 レポートや公開時は必ず出典を記載。
- リクエスト頻度を抑える。 サイトに負荷をかけないように配慮。
リスク回避のチェックリスト:
- ✅ 公開ページのみ(ログイン不要)
- ✅ robots.txt・利用規約を確認
- ✅ 著作権・個人情報は抽出しない
- ✅ 出典を明記
- ✅ 過度なリクエストは避ける
Thunderbitは、必要なデータだけを効率よく抽出し、社内利用にとどめることで、責任あるスクレイピングを推奨しています。
実践ガイド:Thunderbitでウェブサイトからコンテンツを抽出する手順
実際にやってみましょう!を使ったウェブサイトからのコンテンツ抽出手順:
- Thunderbit Chrome拡張機能をインストール: して、無料アカウントを作成。
- 対象ウェブサイトを開く: 抽出したいページ(商品リスト、企業ディレクトリ、レビューなど)にアクセス。
- Thunderbitアイコンをクリック: ChromeツールバーからThunderbitを起動。
- 「AIフィールド提案」を利用: ページを解析し、「名前」「価格」「メール」など抽出カラムを自動提案。
- カラムを調整: 必要に応じてカラム名の変更・追加・削除やAIプロンプトの設定もOK。
- 「スクレイピング」をクリック: 今のページのデータを抽出し、ページ分割も自動対応。
- サブページ抽出(任意): 詳細情報が必要な場合は「サブページ抽出」でリンク先も取得。
- データを確認・エクスポート: プレビュー後、Excel、Google Sheets、Airtable、Notionへエクスポート、またはCSV/JSONでダウンロード。
よくあるトラブルと対策:
- ログインが必要なページ: ログイン状態でThunderbitのブラウザスクレイピングモードを使う。
- ブロックや遅延: 混雑時間を避ける、抽出範囲を分割するなど工夫しよう。
- 動的コンテンツが表示されない: ページを最後までスクロールしてから抽出、またはブラウザモードを活用。
- レイアウト変更: 「AIフィールド提案」を再実行して、AIに新しい構造を認識させる。
困ったときはThunderbitのやサポートチームが助けてくれます。
まとめ・ポイント
ウェブサイトからのコンテンツ抽出は、昔は開発者だけの裏技でしたが、今やビジネスの必須スキルです。2025年以降、ウェブデータの爆発的増加とノーコード・AIツールの進化で、誰でも簡単・正確・スピーディーに情報をゲットできるようになりました。
覚えておきたいポイント:
- 他のウェブサイトからのコンテンツ抽出は、リード獲得・市場調査・競争力維持に不可欠
- のような最新ツールなら、自然言語プロンプトやAIフィールド提案、即時エクスポートで誰でも使える
- ページ分割・サブページ・データ整理もThunderbitなら簡単対応
- 法令遵守を徹底:公開データのみ、サイトルールを守り、著作権・個人情報は避ける
- Chrome拡張機能をインストールし、数クリックで始められる
もうコピペ作業に悩まされる必要はありません。、次のウェブデータプロジェクトでどれだけ時間と労力が節約できるか、ぜひ体感してみてください。さらに詳しいノウハウやチュートリアルはでチェックできます。
よくある質問
1. 他のウェブサイトからコンテンツを抽出するのは合法ですか?
基本的には、公開データだけを対象にして、robots.txtや利用規約を守り、著作権や個人情報を避ければ問題ありません。各サイトのルールは必ず確認して、責任を持ってデータを活用しましょう()。
2. ウェブサイトからコンテンツを抽出するのにプログラミングは必要ですか?
必要ありません!のようなツールなら、自然言語プロンプトやAIフィールド提案で、数クリックでデータを取得できます。
3. Thunderbitでどんなサイトを抽出できますか?
ThunderbitはEC、ディレクトリ、レビュー、不動産リストなど幅広いサイトに対応。ページ分割やサブページ、動的コンテンツも多くの場合抽出可能です。
4. 抽出したデータの整理・分析方法は?
Thunderbitなら抽出時にタグやカテゴリ付与ができ、Excel、Google Sheets、Airtable、Notionへ直接エクスポートして分析・共有も簡単です。
5. サイトにブロックされたりレイアウトが変わった場合は?
抽出速度を落とす、Thunderbitのブラウザスクレイピングモードを使う、「AIフィールド提案」を再実行するなどで対応可能。困ったときはThunderbitのやサポートに相談してみてください。
快適なスクレイピングライフを!スプレッドシートがいつも整理されて、すぐに活用できる状態でありますように。
さらに詳しく知りたい方へ