ScraperAPIに登録して、Hobbyプランの「100,000クレジット」を見て、よし、スクレイピングを始めようと思ったとします。ところが3日後、ダッシュボードを見るとその80%が消えていて、取得できたページはせいぜい6,000件ほど。いったい何が起きたのでしょうか?
答えはクレジットの倍率システムです。しかもこれこそが、ScraperAPIについてほとんどのレビューがきちんと説明していない、いちばん大事なポイントです。私は数週間かけてScraperAPIのドキュメントを読み込み、競合5社の実際の料金を調べ、Redditの投稿やCapterraのレビューを片っ端から確認しました。このScraperAPIレビューは、私たちのチームが最初にスクレイピングAPIを検討し始めた頃にあればよかったと思う内容です。この記事では、クレジットの本当の計算方法、ScraperAPIが強い場面と完全に苦戦する場面、G2・Capterra・Redditで実際のユーザーが何を言っているのかをまとめ、最後に、そもそもあなたにスクレイピングAPIが必要なのかまで整理します。
ScraperAPIとは? どんな人向けに作られているのか?
ScraperAPIは、大規模スクレイピングを支える面倒な裏側の仕組みを肩代わりしてくれるWeb Scraper APIです。たとえば、を使ったプロキシローテーション、CAPTCHAの自動解決、JavaScriptレンダリング、自動リトライなどを処理します。シンプルなAPIリクエストでURLを送るだけで、HTMLを返してくれます(構造化データ用のエンドポイントを使えば、JSON形式の解析済みデータも取得可能です)。同社は2018年にDaniel Niによって設立され、本社はラスベガスにあり、現在はDeloitte、Sony、Alibabaを含むに利用されています。月間を処理しています。
主な利用者は、独自のスクレイピングパイプラインを構築する開発チームや技術系オペレーション担当です。コードを書かない人向けではありません(この点は後ほど詳しく触れます)。
主な機能は、プロキシローテーション、JavaScriptレンダリング、ジオターゲティング、人気サイト向けの構造化データエンドポイント、失敗リクエストの自動再試行です。
ただし、多くのレビューが見落としている重要な点があります。ScraperAPIの料金ページにある「○○クレジット」という数字は、倍率の仕組みを理解していないとかなり誤解しやすいです。まずはそこから見ていきましょう。
ScraperAPIのクレジット体系はどう動くのか(多くのレビューが飛ばす部分)
ScraperAPIはクレジット制で課金されます。基本ルールは「1回のAPIリクエスト = 1クレジット」です。……ただし、実際はほぼそうなりません。必要クレジットは、スクレイピング対象のドメインと、有効化する機能フラグの2つで決まります。そしてこのコストは、直感に反する形で積み上がります。
登録前に全ユーザーが見るべきクレジット倍率表

まず、パラメータを1つも切り替えなくても、スクレイピングするサイトの種類によって基本クレジットが変わります。
| ドメインカテゴリ | 1リクエストあたりの基本クレジット | 例 |
|---|---|---|
| 通常サイト | 1 | ブログ、ニュースサイト、シンプルなHTMLページ |
| ECサイト | 5 | Amazon、eBay、Walmart |
| SERP(検索エンジン結果) | 25 | Google、Bing |
| SNS | 30 |
さらに、機能フラグで追加クレジットが発生します。
| パラメータ | 追加クレジット | 補足 |
|---|---|---|
render=true(JSレンダリング) | +10 | 全プラン対象 |
screenshot=true | +10 | 全プラン対象 |
premium=true(プレミアムプロキシ) | +10 | 全プラン対象 |
ultra_premium=true | +30 | 有料プランのみ |
| アンチボット回避(Cloudflare、DataDome、PerimeterX) | 各+10 | 自動判定で付与され、選択不可 |
premium=true + render=true の併用 | +25 | +20ではない |
ultra_premium=true + render=true の併用 | +75 | +40ではない |
最後の行がかなり重要です。機能を組み合わせると、単純な合算以上にクレジットを消費します。プレミアムプロキシ(+10)とJavaScriptレンダリング(+10)なら、普通は合計+20のはずですが、ScraperAPIではです。ultra-premium(+30)とJavaScriptレンダリング(+10)なら+40のはずですが、実際はで、ほぼ2倍です。この非線形な積み上がりは目立つ形では説明されておらず、「思ったより早くクレジットが消える」というユーザーの声の主因になっています。
追加クレジットが0のパラメータは、wait_for_selector、country_code、session_number、device_type、output_format、keep_headers=true、autoparse=true です。
各プランで実際に何が使えるのか:FreeからEnterpriseまで
ScraperAPIのはこちらです。
| プラン | 月額料金 | 年額(月換算) | APIクレジット | 同時実行スレッド | ジオターゲティング |
|---|---|---|---|---|---|
| Free | $0 | — | 1,000 | 5 | なし |
| Hobby | $49 | $44 | 100,000 | 20 | 米国・EUのみ |
| Startup | $149 | $134 | 1,000,000 | 50 | 米国・EUのみ |
| Business | $299 | $269 | 3,000,000 | 100 | 国レベル(50か国以上) |
| Scaling | $475 | $427 | 5,000,000 | 200 | 国レベル |
| Enterprise | カスタム | カスタム | 5,000,000以上 | 200以上 | 国レベル |
次に、倍率を加味した1,000リクエストあたりの実効コストを見てみましょう。
| プラン | 通常(1×) | JSレンダリング(10×) | ECサイト(5×) | SERP(25×) | ultra-premium + JS(75×) |
|---|---|---|---|---|---|
| Hobby ($49) | $0.49 | $4.90 | $2.45 | $12.25 | $36.75 |
| Startup ($149) | $0.15 | $1.49 | $0.75 | $3.73 | $11.18 |
| Business ($299) | $0.10 | $1.00 | $0.50 | $2.49 | $7.48 |
| Scaling ($475) | $0.10 | $0.95 | $0.48 | $2.38 | $7.13 |
月額49ドルで「100,000クレジット」と宣伝されていても、保護の強いサイトを ultra-premium + JavaScriptレンダリングで取得すると、実際には1,333リクエストしか処理できません。これはに相当し、フルマネージド型のスクレイピングサービスより高い場合もあります。
なぜクレジットが予想より早く減るのか
ユーザーが驚くポイントは3つあります。
1つ目は、ドメイン別料金が自動適用されることです。Amazonの5倍課金やGoogleの25倍課金を、ユーザーが自分で選ぶわけではありません。ScraperAPIがそのドメインを検知した瞬間に自動で適用されます。Cloudflare、DataDome、PerimeterXなどへのアンチボット回避用クレジット(各+10)も同様に、自動検知で加算されます。
2つ目は、クレジットは繰り越されないことです。未使用分はします。積み立てはできません。
そして3つ目が厄介ですが、Pay-As-You-GoはScalingプラン(月475ドル)以上でしか使えません。Hobby、Startup、Businessで月途中にクレジットを使い切ると、次の請求期間まで停止されます。実質的には、上位プランへアップグレードするしかありません。
Redditでは、Amazonリクエスト1回あたり1クレジットの見積もりで6,000万クレジットを3,600ドルと案内されたのに、支払い後に事前説明なしで5倍の倍率が適用されたという報告がありました。その結果、60Mプランの実質利用可能回数は1,200万件に減り、想定よりしていたそうです。
DataPipelineのクレジット罠
ScraperAPIのノーコード機能であるDataPipeline(スケジュール実行とWebhook配信)は、標準APIとは別の、かなり高いクレジット体系を使います。通常の基本リクエストは標準APIなら1クレジットですが、DataPipelineではかかります。
| リクエスト種別 | 標準API | DataPipeline | 倍率 |
|---|---|---|---|
| 通常の基本リクエスト | 1 | 6 | 6倍 |
| ECサイトの基本取得 | 5 | 10 | 2倍 |
| SERPの基本取得 | 25 | 30 | 1.2倍 |
| ultra-premium + JS(通常) | 75 | 80 | 1.07倍 |
ノーコードのパイプラインを作りながら、標準APIと同じ感覚で使えると思っていると、基本リクエストで6倍のクレジットを消費していることに気づきます。これは文書化されていますが、かなり探さないと見つかりません。
実際の1リクエストあたりコスト:ScraperAPIと競合比較
倍率を考慮しない表面上の価格は、ほとんど意味がありません。そこで5社の最新料金を取得し、月額300ドル前後のプランで、よくある3つのシナリオを横並びで比較しました。
基本HTMLスクレイピング(JSなし、プレミアムプロキシなし)
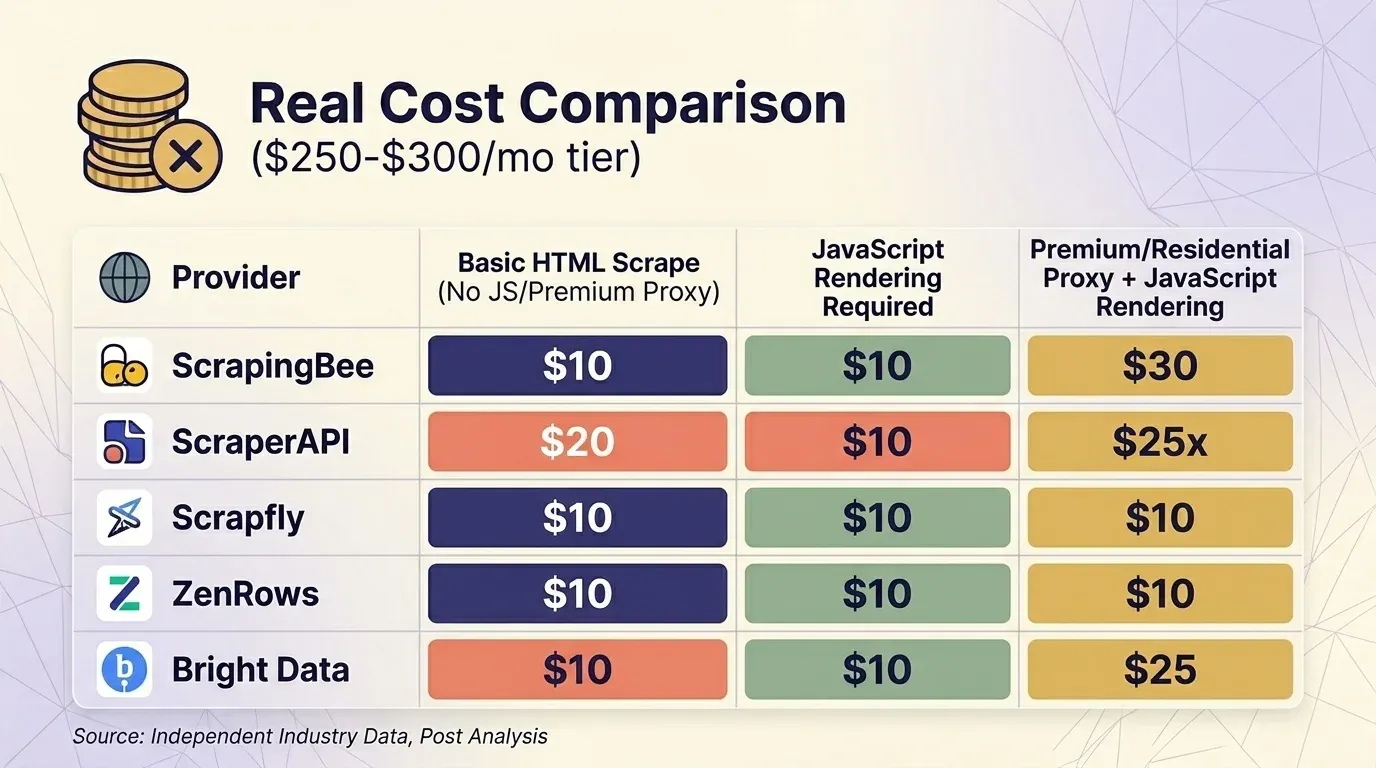
| 提供元 | プラン | 1リクエストあたりのクレジット | 実質リクエスト数 | 1,000件あたりコスト |
|---|---|---|---|---|
| ScrapingBee | Business $249 | 1 | 3,000,000 | $0.08 |
| ScraperAPI | Business $299 | 1 | 3,000,000 | $0.10 |
| Scrapfly | Startup $250 | 1 | 2,500,000 | $0.10 |
| ZenRows | Business $300 | $0.28/1K | 約1,071,000 | $0.28 |
| Bright Data | PAYG | $1.50/1K | 約200,000 | $1.50 |
JavaScriptレンダリングが必要な場合
| 提供元 | プラン | 1リクエストあたりのクレジット | 実質リクエスト数 | 1,000件あたりコスト |
|---|---|---|---|---|
| ScrapingBee | Business $249 | 5(デフォルトでON) | 600,000 | $0.42 |
| Scrapfly | Startup $250 | 6 | 416,667 | $0.60 |
| ScraperAPI | Business $299 | 10 | 300,000 | $1.00 |
| ZenRows | Business $300 | 5倍 | 約214,000 | $1.40 |
| Bright Data | PAYG | 一律 | 約200,000 | $1.50 |
プレミアム/住宅IPプロキシ + JavaScriptレンダリング(保護サイト向け)
| 提供元 | プラン | 1リクエストあたりのクレジット | 実質リクエスト数 | 1,000件あたりコスト |
|---|---|---|---|---|
| Bright Data | PAYG | 一律 | 約200,000 | $1.50 |
| ScrapingBee | Business $249 | 25 | 120,000 | $2.08 |
| ScraperAPI | Business $299 | 25 | 120,000 | $2.49 |
| Scrapfly | Startup $250 | 31 | 80,645 | $3.10 |
| ZenRows | Business $300 | 25倍 | 約42,857 | $7.00 |
Bright DataのWeb Unlockerは、唯一のプロバイダーで、すべてのリクエストが同じ定額です。月300ドル前後の帯では、保護サイトのスクレイピングにおいてScrapingBeeとScraperAPIは競争力がありますが、ZenRowsは最も高額です。
1点、行動面で注意したいことがあります。ScrapingBeeはにしており、その場合は5倍課金です。ScrapingBeeとScraperAPIを比較するなら、同じレンダリング設定で比べてください。
Scrape.doの独立分析によると、ScraperAPIの平均コストはで、「テストした全プロバイダーの中で最も高い」とされています。平均応答時間もで、「利用可能な中でもかなり遅い部類」と評価されています。契約前に知っておく価値は十分あります。
サイト別の成功率:ScraperAPIが強い場面、苦手な場面
どのスクレイピングAPIも、すべてのサイトで同じように動くわけではありません。Scrapewayの独立ベンチマーク(2026年4月)を見ると、その差はかなり極端です。
サイトカテゴリ別の性能
| 対象サイト | 成功率 | 平均速度 | 1,000件あたりコスト(Businessプラン) |
|---|---|---|---|
| Zillow | 100% | 10.5秒 | $0.49 |
| Etsy | 99% | 4.8秒 | $4.90 |
| Amazon | 98% | 6.5秒 | $2.45 |
| 95% | 17.8秒 | $14.70 | |
| Walmart | 93% | 11.4秒 | $2.45 |
| Indeed | 90% | 15.8秒 | $4.90 |
| StockX | 84% | 3.9秒 | $4.90 |
| Realtor.com | 12% | 11.8秒 | $0.49 |
| 0% | — | — | |
| Booking.com | 0% | — | — |
| Twitter/X | 0% | — | — |
全体の平均成功率はで、業界平均の58.2~59.5%をわずかに上回っています。平均応答時間は5.2~7.3秒で、業界平均の9.8秒より速めです。
ScraperAPIが得意な分野
ScraperAPIは、ECサイト(Amazon、Walmart、Etsy)と不動産(Zillow)で本当に強いです。これらのサイト向け構造化データエンドポイントは、解析済みJSONを高い信頼性で返してくれます。主な用途がAmazonの商品ページやGoogle SERPの取得なら、十分現実的な選択肢です。
ScraperAPIが苦手な分野
SNSは完全な苦戦領域です。 Instagram、Twitter/X、Booking.com は独立テストでいずれも成功率0%でした。LinkedInは95%で動きますが、1リクエスト30クレジットはかなり重いです。
ログイン必須サイトは明確に対象外です。 ScraperAPIはsession_numberパラメータによるセッション維持をサポートしていますが、されています。フォーム入力、2要素認証、複雑な認証フローには対応できません。
保護対象ではデータが古くなることがあります。 ScraperAPIは難易度の高い対象に対してを適用するため、価格や在庫など時系列が重要なデータでは、最大10分前の結果が返る可能性があります。
Proxywayの2025年ベンチマークでは、ScraperAPIはGoogleに対してで、81.72%でした。
サイトカテゴリ別の要約
| サイトカテゴリ | ScraperAPIの性能 | 既知の課題 | 代替候補 |
|---|---|---|---|
| Amazon / EC | ✅ 強い(SDPエンドポイント) | 大規模になるとクレジット消費が重い | Thunderbitテンプレート(1クリック、テンプレート自体は行ごとのクレジット不要) |
| Google SERP | ✅ 強い | ジオターゲティングに追加コストがかかる/あるベンチマークではGoogleの成功率が最低 | — |
| 不動産(Zillow) | ✅ 優秀(100%) | — | — |
| Instagram / SNS | ❌ 成功率0% | 完全失敗 | Playwright + プロキシ(自作) |
| JSの多いSPA | ⚠️ 中程度 | ヘッドレスレンダリングで10倍クレジットが必要 | Scrapfly、ZenRows |
| ログイン必須サイト | ❌ ToS上不可 | セッション/認証サポートなし | Thunderbitのブラウザスクレイピング(ログイン済みセッションを利用) |
| Booking.com / 旅行系 | ❌ 成功率0% | 完全失敗 | Bright Data |
実際のユーザーは何と言っているのか:G2、Capterra、Redditの評判まとめ
3つのプラットフォームからフィードバックを集めました。現在の評価は以下の通りです。
| プラットフォーム | 評価 | レビュー数 |
|---|---|---|
| G2 | 4.4/5 | 16 |
| Capterra | 4.6/5 | 62 |
| Trustpilot | 4.5/5 | 43 |
Capterraの内訳評価は、使いやすさ 4.9/5、カスタマーサービス 4.6/5、機能 4.5/5、費用対効果 4.5/5 です。
テーマ別の印象まとめ
| テーマ | ポジティブな声 | ネガティブな声 |
|---|---|---|
| 導入のしやすさ/ドキュメント | 「セットアップが本当に簡単。数分でスクレイピングを始められる」— Latenodeコミュニティ; Capterraの使いやすさ評価4.9/5 | — |
| 料金の分かりやすさ | 「手頃なエントリープラン」(Capterraの複数レビュー) | 「クレジットコストの内訳が分かりにくい」— John S., Founder, Capterra(2025年2月); 「価格が1000%上がり、品質が落ちた」— CTO, Online Media, Capterra(2022年9月) |
| 信頼性 | 「Amazon/Googleではかなり良い」(G2, Capterra) | 「重い処理になるとScraperAPIは不安定になる」— emcarter, Latenode; 「一部ターゲットで失敗率80%」(Reddit) |
| カスタマーサポート | 「対応が早いチーム」(Capterra) | Redditでは、1つの料金を案内されたのに実際は5倍請求されたという報告あり(事前説明なし) |
| 長期的な価値 | 成功したリクエスト(200/404)のみ課金 | 「大規模運用では費用がすぐ膨らむ」うえ、自前インフラのほうが「長期的にはコスト効率が高い」— mikezhang, Latenode |
要するに、ScraperAPIは初期設定のしやすさで高評価を得ており、人気のある定番ターゲットでは安定して動きます。一方で、不満は主に料金のサプライズ(倍率や予想外の値上げ)と、難しいターゲットでの安定性に集中しています。
ScraperAPIの構造化データエンドポイントは、追加クレジットを払う価値があるのか?
ScraperAPIは5つのプラットフォームにまたがるを提供しており、HTMLの生データではなく、解析済みJSONを返します。
- Amazon(3エンドポイント):ASINからの商品詳細、検索結果、競合オファー。価格、評価、説明、レビュー、BSR、画像、販売者情報など18項目以上を返します。をサポート。
- Google(5エンドポイント):(自然検索結果、ナレッジグラフ、動画、関連質問、ページネーション)、ショッピング、マップ、ニュース、求人。
- Walmart(4エンドポイント):商品、検索、カテゴリ、レビュー。
- eBay(2エンドポイント):商品、検索。
- Redfin(4エンドポイント):検索、エージェント詳細、賃貸物件、販売物件。
SDEはFreeを含む全プランで利用できます。ScraperAPIは、対応SDEドメインでをうたっていますが、独立ベンチマークではサイトによってもっと複雑な結果が出ています。
データの充実度
AmazonのSDPは、ScraperAPIの中でも最も強力な機能の1つです。価格、レビュー、BSR、バリエーション、画像、販売者情報など、かなり包括的な項目が返ってきます。Google SERPのSDPも、自然検索結果、広告、強調スニペット、People Also Ask を取得できます。この2つのプラットフォームでは、データの充実度は本当に高いです。
クレジット効率:SDP vs 自前パース
Businessプラン(月299ドル、300万クレジット)でAmazon商品1万件をSDE経由で取得すると、必要クレジットは50,000(1件5クレジット)で、プラン料金の約5ドル分です。標準リクエスト(1件1クレジット)で自前のパーサーを作れば、必要クレジットは1万ですが、その代わり開発・保守にエンジニアの工数がかかります。
開発者がいない小規模チームなら、SDEはかなり時間を節約できます。
一方、エンジニアリソースがあり、しかも大量取得するチームにとっては、5倍のクレジットプレミアムは正当化しにくいです。
SDPはノーコードのスクレイパーテンプレートと比べてどうか
この比較は、多くのレビューが十分に触れていない重要ポイントです。 には、Amazon、Shopify、Zillow、向けの即使えるスクレイパーテンプレートがあり、コード不要、しかもテンプレート自体には行ごとのクレジット課金がありません。
| 比較項目 | ScraperAPI SDP(Amazon) | Thunderbit Amazonテンプレート |
|---|---|---|
| セットアップ時間 | 30〜60分(コード + API連携) | 約2分(拡張機能を入れてAmazonを開き、テンプレートをクリック) |
| 1,000商品あたりコスト(Businessプラン) | 約$5(50,000クレジット、$0.10/クレジット換算) | 約$16.50(Proで1行あたり1クレジット、$0.0165/クレジット換算) |
| 取得項目 | 18項目以上(包括的) | 商品名、価格、評価、レビュー、画像、URLなど |
| エクスポート方法 | JSON(パース用コードが必要) | Excel、CSV、Google Sheets、Airtable、Notionへ1クリック |
| 保守 | ScraperAPIがSDEを保守 | Thunderbitチームがテンプレートを保守 |
| 技術スキル | Python/Node.js 必須 | 不要 |
高ボリュームでAmazonを取得する開発チームにとっては、ScraperAPIのSDEはスケール時の単価効率が高いです。一方、コードを書かずにAmazonデータをスプレッドシートで使いたいビジネスユーザーには、Thunderbitのほうが圧倒的に速く導入できます。
そもそもスクレイピングAPIは必要? 多くのレビューが見逃すノーコードの選択肢
「Scraper API review」と検索する人の中には、まだAPIベースのワークフローを採用するか決めていない人が少なくありません。そもそも必要かどうかを判断している段階です。
意外かもしれませんが、必要ない人もかなりいます。Web scraping API市場はで、年率14〜18%で成長していますが、その成長を牽引しているのは主にエンタープライズのエンジニアチームです。Webサイトから500件のリードが欲しい営業オペレーション担当者ではありません。
スクレイピングAPI vs ノーコードツール:判断フレームワーク
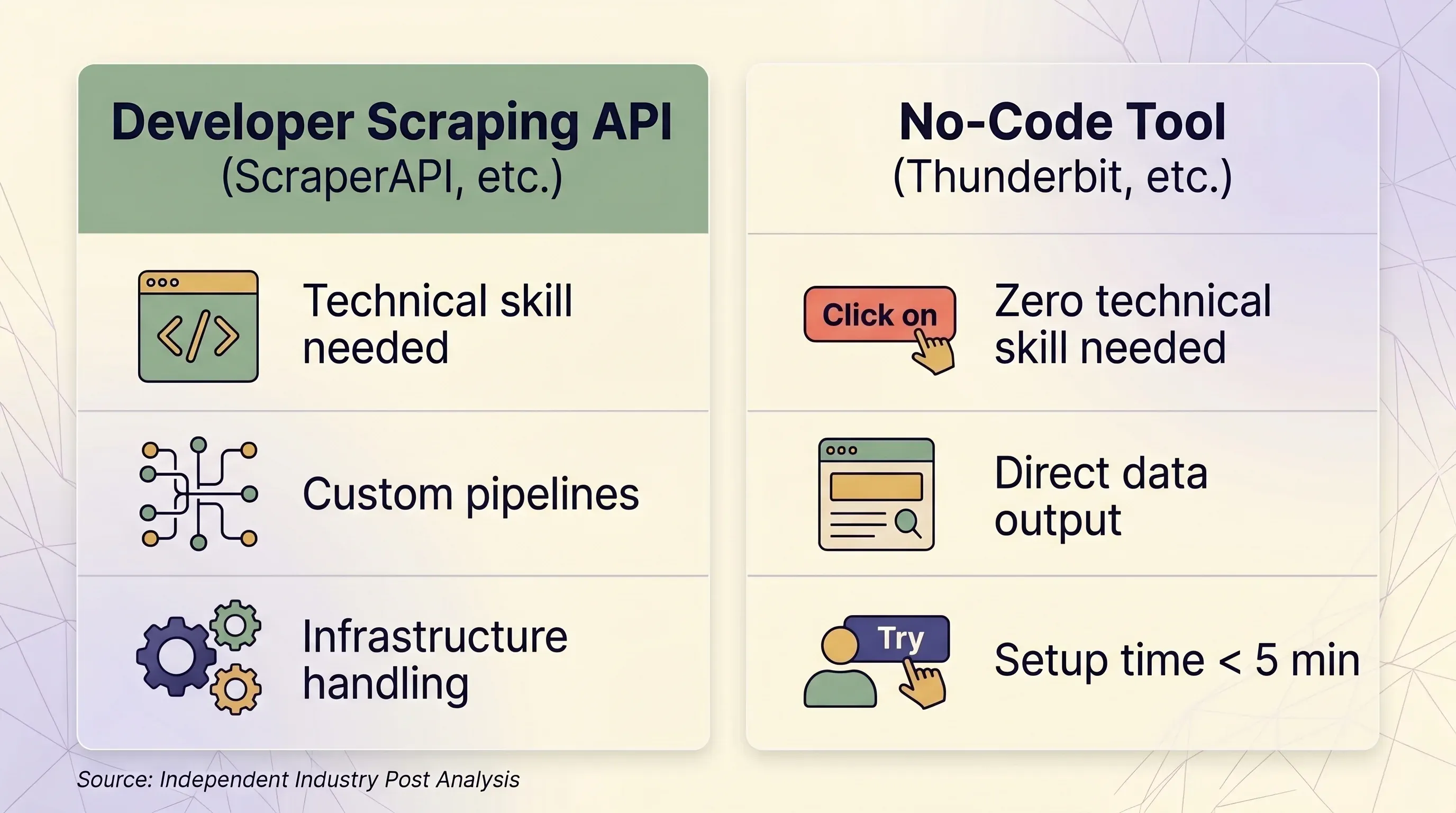
| 比較項目 | スクレイピングAPI(ScraperAPIなど) | ノーコードツール(Thunderbitなど) |
|---|---|---|
| 最適な用途 | 大規模なデータパイプラインを作る開発者 | ビジネスユーザー、マーケター、営業、リサーチャー |
| 必要な技術スキル | Python/Node.js、HTTPの基礎、JSONパース | 不要。ブラウザ上でクリック操作だけ |
| セットアップ時間 | 最低1〜2時間(コード作成・テスト・デバッグ) | 5分以内 |
| アンチボット対策 | プレミアムプロキシ(1回10〜75クレジット) | 実ブラウザセッションで自然に回避 |
| ログイン必須サイト | ❌ ScraperAPIのToSで禁止 | ✅ Browser Scraping が既存セッションを利用 |
| 規模感(1日あたりページ数) | 月10万〜300万件以上のリクエスト | 単発利用中心、通常は1日1,000ページ未満 |
| 出力形式 | 生HTMLまたはJSON(解析コードが必要) | 構造化済みの行・列でそのまま使える |
| エクスポート | JSON、CSV(コード経由) | Excel、CSV、Google Sheets、Airtable、Notion、Word、JSON |
| 保守 | セレクタ、リトライロジック、インフラの更新が必要 | 不要。AIが毎回ページ構造を読み直す |
| 料金単位 | リクエスト課金(1〜75クレジット/回で変動) | 行課金(1クレジット=1行、サブページは2クレジット) |
| 初期価格 | 100Kクレジットで月額$49 | 年払いなら月額$9で5,000クレジット |
| 無料枠 | 月1,000クレジット、同時5件 | 月6ページ、1ページ30クレジット |
| 料金の予測しやすさ | 低い。倍率で想定外の請求が起きやすい | 高い。1行は常に1クレジット |
スクレイピングAPIが向いているケース
- 開発者またはエンジニアチームがいる
- 1日10万ページ以上をプログラムで取得したい
- リクエストヘッダー、セッション、リトライロジックを細かく制御したい
- 対象サイトがよくサポートされている(Amazon、Google、Walmart、Zillow)
Thunderbitのようなノーコードツールが向いているケース
- あなたの仕事が営業、EC運用、マーケティング、不動産で、エンジニアリングではない
- サイトごとに独自パーサーを作らず、いろいろなサイトからデータが欲しい
- Excel、Google Sheets、Airtable、Notionへ直接出力したい
- ログインが必要なサイトを取得したい(Thunderbitのはあなたのセッションを使います)
- ページ変更のたびにコードを直さず、AIに毎回最新の構造を読み取ってほしい
- サブページも取り込みたい:Thunderbitなら各詳細ページを巡回して行データを自動で拡張できます
の流れは驚くほどシンプルです。拡張機能を入れて、任意のページを開き、「AIで項目を提案」をクリックし、「スクレイプ」を押してエクスポートするだけ。AIがページ上のデータを判断して列を提案してくれるので、セレクタもコードも不要です。仕組みの詳細は、も参考にしてください。
が2024年にクラウドコストの超過を経験しており、使用量ベース課金を適切に管理できていない企業では、請求ショックの影響でとされています。変動するAPIコストで痛い目を見たことがあるなら、1行単位のクレジットモデルの予測しやすさはかなり重要です。
ScraperAPIのメリット・デメリットをひと目で
| メリット | デメリット |
|---|---|
| 強力なプロキシ基盤(4,000万以上のIP、50か国以上) | 分かりにくいクレジット倍率システム。機能を組み合わせると単純合計以上に高い |
| ドキュメントが充実し、初期セットアップが簡単(Capterraの使いやすさ4.9/5) | クレジットは月をまたいで繰り越されない |
| Amazon、Google、Zillow、Etsyで安定 | Instagram、Twitter/X、Booking.comでは成功率0% |
| 成功したリクエスト(200/404)のみ課金 | 404レスポンスでもクレジットを消費する |
| 18の構造化データエンドポイントでJSON出力 | ログイン必須サイトは明確に禁止 |
| Freeを含む全プランで利用可能 | Pay-As-You-GoはScaling(月475ドル)以上のみ |
| 7日間の理由不要返金保証 | 難しい対象には10分の強制キャッシュがあり、古いデータのリスクあり |
| 売上が前年比30〜35%増とされ、継続開発がうかがえる | DataPipelineは標準APIの最大6倍のクレジットを消費 |
| — | 米国・EU以外のジオターゲティングにはBusinessプラン(月299ドル)が必要 |
| — | 事前の使用量アラートがなく、ダッシュボードを自分で確認する必要がある |
ScraperAPIを最大限活用するための実践ヒント(使うと決めた場合)
クレジット消費は毎日確認する
ScraperAPIのでは、平均レイテンシ、取得ドメイン、同時実行数などの使用状況を確認できます。ただし、使用量の事前アラートはありません。クレジット残量が少なくなってもメールやSMSは飛んできません。自分で確認する必要があります。分析履歴も、Hobby/Startupプランでは2週間、Business以上で6か月に制限されます。
最初の1か月は、毎日ダッシュボードを確認するようカレンダーにリマインダーを入れておきましょう。対象サイトごとに、クレジットがどのくらい速く減るか感覚をつかむ必要があります。
まずは無料枠で対象サイトを試す
有料プランに入る前に、1,000クレジットの無料枠(加えて5,000クレジットの7日間トライアル)で、自分の対象サイトに対する成功率を確認しましょう。どのサイトでJavaScriptレンダリングやプレミアムプロキシが必要かを記録しておくと、倍率を反映した現実的な月額コストを見積もれます。
必要な場合を除き、プレミアム機能は使わない
ScraperAPIは、プレミアムプロキシやJavaScriptレンダリングを自動でONにはしません。render=true、premium=true、ultra_premium=true を明示的に設定する必要があります。ただし、ドメイン別料金は自動です。Amazonは常に5クレジット、Googleは常に25、LinkedInは常に30です。Cloudflare、DataDome、PerimeterX向けのアンチボット回避クレジット(各+10)も、検知時に自動で加算されます。バッチ実行前に必ず理解しておきましょう。
対応サイトでは構造化データエンドポイントを使う
AmazonやGoogleを取得するなら、SDEはクレジットが少し高くても開発時間を節約できます。未対応サイトの場合は、独自パーサーを作るよりのほうが早くて安いかを検討しましょう。
不安定な対象にはバックアップを用意する
特定サイトでの成功率が90%を下回るなら、そのリクエストを別プロバイダーに流すか、ブラウザベースのツールを使うことを検討してください。ログインが必要なサイトではScraperAPIはそもそも使えません。のようにブラウザセッション内で動くツールが必要です。
落とし穴を知っておく
- 404レスポンスでもクレジットを消費する — ScraperAPIは200と404の両方を課金対象にします
- キャンセルしたリクエストも課金対象 — 70秒の処理ウィンドウが終わる前にキャンセルしても請求されます
- 難しい対象には10分の強制キャッシュ — 古いデータが返る可能性あり
- Pay-As-You-GoはScaling(月475ドル)以上のみ — 下位プランでクレジットを使い切ると停止
- 米国・EU以外のジオターゲティングにはBusinessプラン(月299ドル)が必要
まとめ:ScraperAPIはあなたに合うツールか?
調査をすべて終えた時点での結論はこうです。
- ScraperAPIは、開発チームにとって堅実な選択肢です。Amazon、Google、Walmart、Zillowのような、処理量が多くサポートの厚い対象には特に向いています。構造化データエンドポイントは本当に便利で、プロキシ基盤も大きく、ドキュメントの質も平均以上です。
- 最大のリスクはクレジット倍率システムです。倍率の積み上がり方を理解していないと、確実に予算を超えます。広告上のクレジット数と実際に処理できるリクエスト数の差は、5〜75倍にもなり得ます。有料プランに入る前に、自分の用途で必ず計算してください。
- 信頼性はサイト次第です。ScraperAPIはECと不動産では優秀ですが、求人サイトやSNSではそこそこ、Instagram、Twitter/X、Booking.com では実質使えません。どこでも同じ性能だとは思わないでください。
- 非技術チームには向きません。営業、マーケティング、オペレーションで、コードなしで構造化データが欲しいなら、のようなノーコードツールのほうが適しています。AIによる項目検出、スプレッドシートへの直接出力、サブページの自動補完、保守不要で、2クリックで使えます。を試すか、のチュートリアルを見てみてください。
- 予算重視の開発者なら、まずScraperAPIの無料枠で自分の対象を試し、その後にScrapingBee、Scrapfly、Bright Dataとの実効コストを比べてから決めるのが賢明です。最安の選択肢は、用途と必要機能によって完全に変わります。
あなたのスクレイピング要件に対して、実際どこまで費用がかかるのか見てみたいですか? まずはScraperAPIの無料枠で対象サイトを試すか、して、2クリックでどこまでできるか確かめてみてください。さらにについては、プラン一覧もご覧ください。
FAQ
ScraperAPIは無料ですか?
はい。ScraperAPIにはと、5,000クレジットの7日間トライアルがあります。ただし、JavaScriptレンダリング、プレミアムプロキシ、高コストドメイン(Amazon = 5倍、Google = 25倍、LinkedIn = 30倍)の倍率があるため、実際に使える件数は1,000件よりかなり少なくなることがあります。無料枠ではultra-premiumプロキシは使えません。
ScraperAPIの1リクエストあたりの料金はいくらですか?
機能フラグと対象ドメインに大きく左右されます。シンプルなHTMLサイトへの通常リクエストは1クレジット、Amazonは5クレジット、Google SERPは25クレジットです。JavaScriptレンダリングを使うと10クレジット追加されます。ultra-premiumプロキシとJavaScriptレンダリングを組み合わせると、1リクエスト75クレジットです。Hobbyプラン(月49ドル、10万クレジット)では、1件あたり約$0.00049(通常)から約$0.0368(ultra-premium + JS)まで幅があります。詳細は上の料金表をご覧ください。
ScraperAPIはAmazonスクレイピングに向いていますか?
ScraperAPIのAmazon向け構造化データエンドポイントは最も強い機能の1つで、独立ベンチマークではがあり、18項目以上の充実したJSONを返します。ただし、Amazonのリクエストは最低でも5クレジットかかるため、大量取得ではコストが積み上がります。少人数チームで、コードなしでAmazonデータをスプレッドシートに入れたいなら、が1クリックで直接出力できる代替手段です。
ScraperAPIの代替でおすすめは?
開発者向けには、(基本HTMLが最安)、(JavaScriptレンダリングが得意)、(保護サイト向けに最適。レンダリング有無で料金が変わらない)、があります。非技術ユーザー向けには、Excel、Google Sheets、Airtable、Notionへ直接出力できる、ノーコードのAI搭載Chrome拡張機能がおすすめです。詳しくはをご覧ください。
ログインが必要なサイトもScraperAPIで取得できますか?
ScraperAPIはsession_numberパラメータによるセッション維持(複数リクエストで同じIPを使うこと)に対応していますが、しています。フォーム入力、2要素認証、複雑な認証フローには対応できません。ログイン必須サイトには、今見えているブラウザセッションをそのまま使って取得できるのようなブラウザベースのツールのほうが信頼性があります。
さらに学ぶ