Zillow にはが集約されており、そのデータを大規模に取り出す作業は、不動産データ業務の中でも最も要望が多く、同時に最も厄介なタスクの一つです。Zillow のスクレイピングを試して、物件情報の代わりに CAPTCHA ページを前に途方に暮れた経験があるなら、それはあなただけではありません。
私はこれまで、Python を使う方法と、Thunderbit で私たちが開発したノーコードツールを使う方法の両方で、Zillow スクレイピングのさまざまなアプローチを徹底的に調べ、検証してきました。このガイドでは、その両方を紹介します。Python を使った本格的な手順とボット対策を知りたい方も、昼までに 200 件の物件情報をスプレッドシートに入れたい方も、きっと役立つ内容があります。Zillow のデータが重要な理由、サイト内部の構造、Python によるステップバイステップの解説、スクレイパーが壊れる具体的な原因、そして価格モニタリングのために定期スクレイピングを自動化する方法までカバーします。
そもそも、なぜ Zillow のデータをスクレイピングするのか?
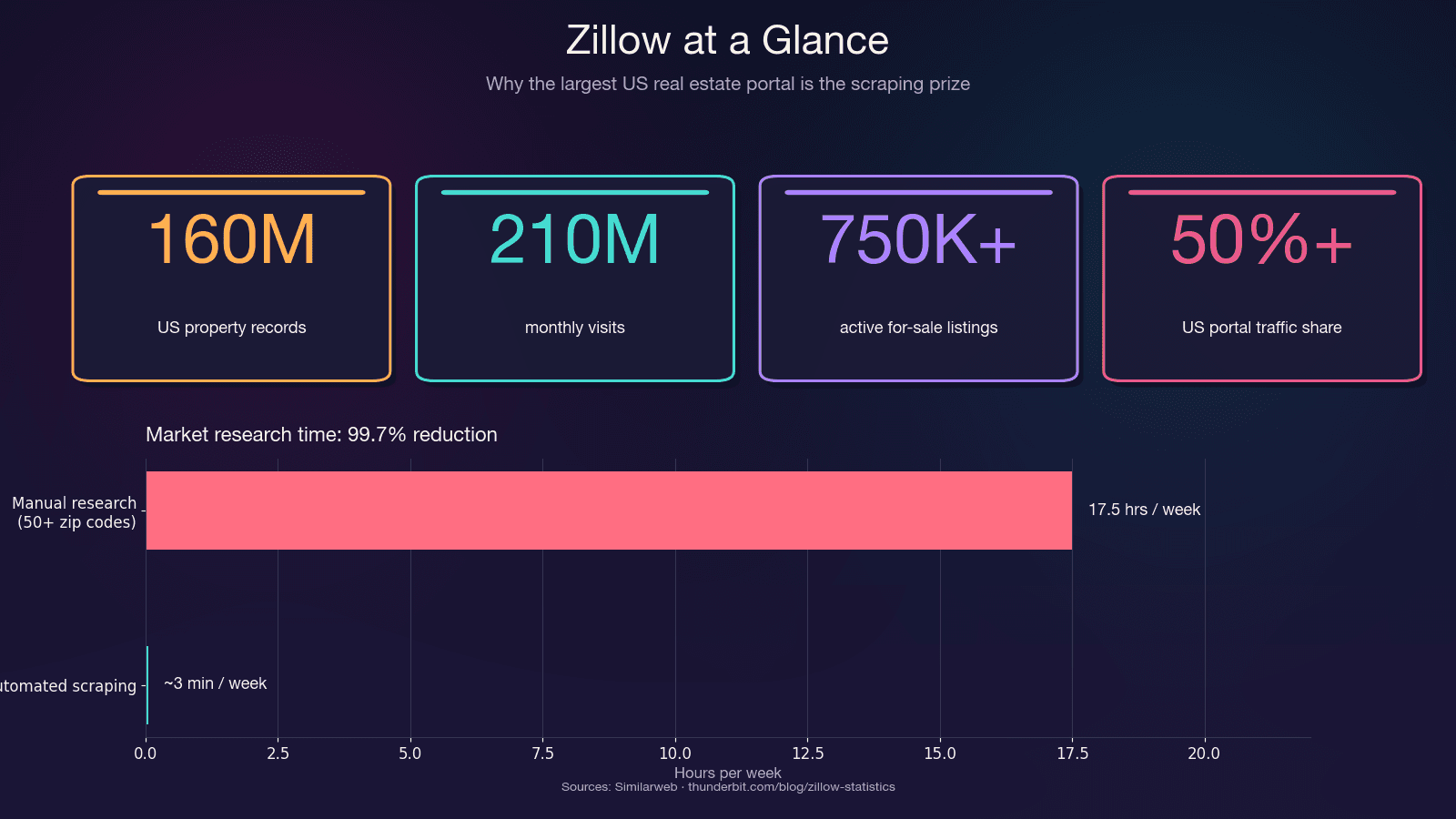
Zillow は、米国の住宅不動産データを集約する最大級のデータソースです。月間を集め、約 75 万件以上の売り出し中物件と、190 万件の賃貸物件を掲載しています。米国の不動産ポータル流入の 50% 超を占め、次点の競合の 2 倍以上です。
Python コードに入る前に知っておきたいのは、Zillow を Python でスクレイピングする方法だけが正解ではないということです。方法選びを間違えると、何時間も無駄になります。たとえば、httpx と BeautifulSoup を使う Python 方式は中級者向けで、ヘッダーやプロキシの手動管理が必要、速度は中程度(1〜3 秒/ページ)、保守の手間は高いものの無料です。Selenium や Playwright は JavaScript を描画するためボット対策には強くなりますが、遅く(5〜15 秒/ページ)、やはり保守負担は大きいです。ScraperAPI や ScrapFly のようなスクレイピング API は、ボット対策が組み込みで速度も速く保守は中程度ですが、月額 30〜599 ドルかかります。Bridge Interactive 経由の Zillow 公式 API は高速で保守負担も少ない一方、利用制限があり、料金はおよそ月 500 ドルです。そして Thunderbit のようなノーコードツールは、初心者でも使いやすく高速で、AI がページに適応するため保守不要、さらに一般的にはフリーミアムで利用できます。
時間短縮効果も非常に大きいです。50 件以上の郵便番号エリアを手作業で調べると、週 15〜20 時間はあっという間に消えます。自動スクレイピングなら同じ作業が数分で済み、時間コストを 99.7% 削減できます。
Zillow をスクレイピングする方法:Python・API・ノーコードを比較
Python のコードに入る前に、「Python で Zillow をスクレイピングする」だけが選択肢ではないことを押さえておきましょう。方法を間違えると、何時間も無駄になります。まずは比較表を見て、自分に合う手段を選んでください。
| 方法 | スキルレベル | ボット対策 | 速度 | 保守 | コスト |
|---|---|---|---|---|---|
| Python + httpx/BeautifulSoup | 中級者向け | 手動(ヘッダー、プロキシ) | 中程度(1〜3秒/ページ) | 高い(セレクタが壊れやすい) | 無料 |
| Python + Selenium/Playwright | 中級者向け | より強い(JS を描画) | 遅い(5〜15秒/ページ) | 高い | 無料 |
| スクレイピング API(ScraperAPI、ScrapFly) | 中級者向け | 組み込み | 速い | 中程度 | 月額 $30〜599 |
| Zillow 公式 API(Bridge Interactive) | 初級〜中級者 | 該当なし | 速い | 低い | 約 $500/月、利用制限あり |
| ノーコードツール(Thunderbit) | 初級者 | 組み込み(AI が適応) | 速い | ほぼ不要(AI がページを再認識) | フリーミアム |
今すぐコードなしでデータが必要なら、Thunderbit から始めてください。仕組みを理解したい、あるいは細かくカスタマイズしたいなら、このあとに続く Python の解説を読み進めてください。
2分でできる方法:Thunderbit で Zillow をスクレイピングする(コード不要)
Python の詳しい解説に入る前に、今すぐ Zillow データが欲しい人向けの方法を紹介します。Python のセットアップも、プロキシ設定も、セレクタの保守も不要です。Thunderbit では、不動産データを構造化して取得できるよう、このワークフローを特に設計しました。
難易度: 初級 所要時間: 約 2 分 必要なもの: Chrome ブラウザ、(無料プランで可)
ステップ 1:Thunderbit をインストールして Zillow を開く
Chrome Web Store から Thunderbit 拡張機能をインストールします。Zillow の検索結果ページを開き、たとえばテキサス州ヒューストンの物件を検索してください。
ステップ 2:「AI Suggest Fields」をクリック
Thunderbit のサイドバーを開き、「AI Suggest Fields」をクリックします。AI がページを読み取り、価格、住所、ベッド数、バス数、面積、Zestimate、物件 URL などの列を自動で提案します。私の検証では、手動設定なしで 20 項目以上を検出できました。
ステップ 3:「Scrape」をクリック
Scrape ボタンを押すと、データが拡張機能内の構造化テーブルに表示されます。Thunderbit は Zillow のページネーションにも自動対応します。クリック式のページ送りも、無限スクロールも問題ありません。
ステップ 4:サブページも取得して情報を拡張
税履歴、学校評価、価格推移のような詳細ページ情報が欲しい場合は、「Scrape Subpages」を使ってテーブルを充実させます。Thunderbit が各物件 URL をたどり、追加項目を取得します。コードは一切不要です。
ステップ 5:エクスポート
Google Sheets、Excel、Airtable、Notion に出力できます。エクスポートは無料です。
Thunderbit が Zillow に強い理由
本当の強みは、壊れにくさです。Thunderbit の AI は、スクレイプするたびにページ構造を毎回新しく読み込みます。Zillow がレイアウトを変更しても(これは頻繁に起こります)、修正が必要な脆い CSS セレクタはありません。AI が自動で適応するため、コード型スクレイパー特有の「すぐ壊れる」問題をしっかり解消できます。
Zillow から取得できるデータは?(20項目以上)
多くのガイドは価格と住所を取って終わりますが、Zillow の物件ページには、実はもっと多くの抽出可能なデータがあります。以下はその参考表です。
| 項目 | 取得元 | 抽出難易度 |
|---|---|---|
| 表示価格 | 検索結果 + 詳細ページ | 簡単 |
| 住所 / 郵便番号 | 検索結果 + 詳細ページ | 簡単 |
| Zestimate | 検索結果 + 詳細ページ | 簡単 |
| 価格履歴(各イベント) | 詳細ページ | 難しい(ネストされた JSON) |
| 税履歴 | 詳細ページ | 難しい(ネストされた JSON) |
| ベッド数 / バス数 / 面積 | 検索結果 + 詳細ページ | 簡単 |
| 築年数 | 詳細ページ | 簡単 |
| HOA 料金 | 詳細ページ | 中程度 |
| Walk Score / Transit Score | 詳細ページ(iframe) | 難しい(JS 描画が必要) |
| 学校評価 | 詳細ページ | 中程度 |
| 敷地面積 | 詳細ページ | 簡単 |
| Zillow 上の掲載日数 | 検索結果 | 簡単 |
| 担当エージェント / 仲介会社 | 検索結果 + 詳細ページ | 中程度 |
| MLS 番号 | 詳細ページ | 簡単 |
| 物件タイプ | 検索結果 + 詳細ページ | 簡単 |
| 緯度 / 経度 | __NEXT_DATA__ JSON | 中程度 |
| 説明文 | 詳細ページ | 簡単 |
| 画像 URL | 検索結果 + 詳細ページ | 中程度 |
| Rent Zestimate | 詳細ページ | 中程度 |
| 近隣の類似売買事例 | 詳細ページ | 難しい |
「難しい」項目である価格履歴、税履歴、比較対象の売買事例は、詳細ページ内のネストされた JSON にあります。以下の Python セクションで、その取り出し方を具体的に示します。コードを書かずに済ませたい場合でも、Thunderbit の AI Suggest Fields がこれらの列の大半を自動検出し、さらに Subpage Scraping が詳細ページの項目も自動取得します。
Zillow をスクレイピングするための Python 環境を準備する
難易度: 中級 所要時間: セットアップ約 5 分、チュートリアル全体で約 30 分 必要なもの: Python 3.8 以上、Chrome ブラウザ(ページ確認用)、テキストエディタまたは IDE
必要なライブラリをインストールします。
1pip install httpx beautifulsoup4 pandas lxmlそれぞれの役割は以下のとおりです。
- httpx —
requestsより高性能で、非同期処理にも対応する HTTP クライアント - beautifulsoup4 + lxml — HTML パース用
- pandas — CSV / Excel への出力用
- 必要に応じて selenium または playwright — JavaScript が多いページを描画したい場合
スクレイピング前に Zillow のページ構造を理解する
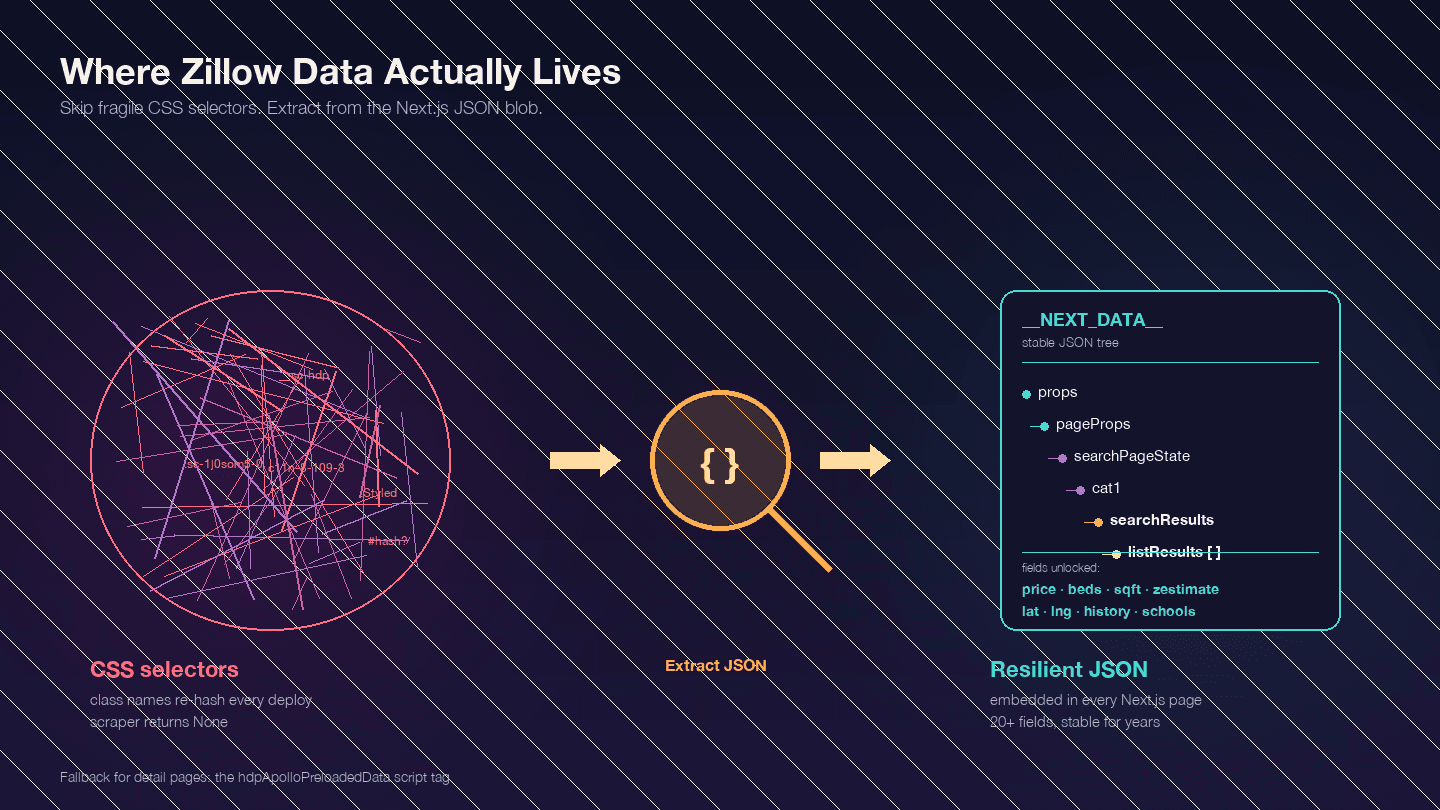
コードを書く前に、ここを理解しておくのが最重要です。Zillow は Next.js アプリケーション です。これはでも確認されています。つまり、欲しいデータの多くは目に見える HTML 要素の中にはなく、<script id="__NEXT_DATA__"> の JSON 塊に埋め込まれています。
Zillow の物件ページを開いて F12 を押し、Elements を開いて __NEXT_DATA__ を検索してみてください。価格、座標、物件詳細、価格履歴、税情報、学校評価など、物件データ一式を含む巨大な JSON オブジェクトが見つかります。
なぜこれが重要なのでしょうか。Zillow の CSS クラス名はハッシュ化されており(styled-components によって生成されます)、公開のたびに変わります。たとえば StyledPropertyCardHomeDetailsList-c11n-8-109-3__sc-1j0som5-0 のようなクラス名は、来週にはまったく別のハッシュになります。CSS セレクタに依存したスクレイパーは、定期的に壊れることになります。
一方で __NEXT_DATA__ の JSON を使う方法は、HTML 構造に依存しないため、はるかに安定しています。
検索結果でよく使う JSON パスは次のとおりです。
| パス | 内容 |
|---|---|
props.pageProps.searchPageState.cat1.searchResults.listResults | 検索結果の配列 |
props.pageProps.searchPageState.cat1.searchResults.mapResults | 地図表示の結果 |
props.pageProps.searchPageState.cat1.searchList.totalPages | 利用可能な総ページ数 |
詳細ページでは、__NEXT_DATA__ を使う場合もあれば、hdpApolloPreloadedData という別の script タグを使う場合もあります。以下のコードはその両方に対応しています。
Python で Zillow をスクレイピングする手順
ステップ 1:即ブロックを避けるために HTTP ヘッダーを設定する
素の httpx.get() を Zillow に送ると、物件データではなく CAPTCHA ページが返ってきます。Zillow は Cloudflare に加えて PerimeterX(HUMAN Security) を使っており、スクレイピング基準では難易度 と評価されています。この仕組みは TLS フィンガープリント、HTTP ヘッダー、IP の信頼性をチェックします。
2025 年時点で機能する最低限のヘッダーは以下です。
1import httpx
2headers = {
3 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 "
4 "(KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36",
5 "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,"
6 "image/avif,image/webp,*/*;q=0.8",
7 "Accept-Language": "en-US,en;q=0.9",
8 "Accept-Encoding": "gzip, deflate, br",
9 "Sec-Ch-Ua": '"Chromium";v="124", "Google Chrome";v="124", "Not-A.Brand";v="99"',
10 "Sec-Ch-Ua-Platform": '"Windows"',
11 "Sec-Fetch-Dest": "document",
12 "Sec-Fetch-Mode": "navigate",
13 "Sec-Fetch-Site": "none",
14 "Sec-Fetch-User": "?1",
15 "Upgrade-Insecure-Requests": "1",
16}Sec-Ch-Ua ヘッダーは非常に重要です。多くのチュートリアルでは省略されていますが、だからこそそれらのコードは PerimeterX 相手に動きません。
ステップ 2:Zillow の検索結果をスクレイピングする
Zillow の検索 URL は予測しやすいパターンです。テキサス州ヒューストンの場合:
- 1 ページ目:
https://www.zillow.com/houston-tx/ - 2 ページ目:
https://www.zillow.com/houston-tx/2_p/ - 3 ページ目:
https://www.zillow.com/houston-tx/3_p/
各ページには約 41 件の物件が表示されます。Zillow は結果を 20 ページ(約 820 件)で打ち切ります。より大きなデータセットが必要な場合は、地域を分割する必要があります(後述)。
以下は、__NEXT_DATA__ の JSON からデータを取り出して検索結果をスクレイピングするコードです。
1from bs4 import BeautifulSoup
2import json
3import time
4import random
5def scrape_zillow_search(url):
6 """Zillow の検索結果ページから物件データを取得する。"""
7 response = httpx.get(url, headers=headers, timeout=15)
8 if response.status_code != 200:
9 print(f"Got status {response.status_code} for {url}")
10 return []
11 soup = BeautifulSoup(response.text, "lxml")
12 script_tag = soup.find("script", {"id": "__NEXT_DATA__"})
13 if not script_tag:
14 print("No __NEXT_DATA__ found — likely blocked by CAPTCHA")
15 return []
16 next_data = json.loads(script_tag.string)
17 try:
18 results = (
19 next_data["props"]["pageProps"]["searchPageState"]
20 ["cat1"]["searchResults"]["listResults"]
21 )
22 except KeyError:
23 print("Unexpected JSON structure — Zillow may have changed its format")
24 return []
25 listings = []
26 for item in results:
27 listing = {
28 "zpid": item.get("zpid"),
29 "address": item.get("addressStreet"),
30 "city": item.get("addressCity"),
31 "state": item.get("addressState"),
32 "zipcode": item.get("addressZipcode"),
33 "price": item.get("unformattedPrice") or item.get("price"),
34 "beds": item.get("beds"),
35 "baths": item.get("baths"),
36 "sqft": item.get("area"),
37 "zestimate": item.get("zestimate"),
38 "days_on_zillow": item.get("daysOnZillow"),
39 "listing_url": item.get("detailUrl"),
40 "img_src": item.get("imgSrc"),
41 "property_type": item.get("hdpData", {}).get("homeInfo", {}).get("homeType"),
42 "latitude": item.get("latLong", {}).get("latitude"),
43 "longitude": item.get("latLong", {}).get("longitude"),
44 }
45 listings.append(listing)
46 return listings複数ページを取得するには、間隔を空けながらループします。
1all_listings = []
2base_url = "https://www.zillow.com/houston-tx/"
3for page in range(1, 6): # 最初の5ページ
4 url = base_url if page == 1 else f"{base_url}{page}_p/"
5 print(f"Scraping page {page}...")
6 page_listings = scrape_zillow_search(url)
7 all_listings.extend(page_listings)
8 # 3〜7秒のランダム待機
9 delay = random.uniform(3, 7)
10 time.sleep(delay)
11print(f"Total listings scraped: {len(all_listings)}")これで all_listings に構造化された物件データが蓄積されていくはずです。空の結果しか出ない場合は、下の「スクレイパーが壊れる理由」を確認してください。
ステップ 3:Zillow の物件詳細ページをスクレイピングする
検索結果では基本情報しか取れません。詳細ページには、価格履歴、税履歴、学校評価、担当エージェント情報、物件説明など、より深いデータが入っています。ステップ 2 で取得した各物件 URL は、詳細ページを指しています。
Zillow の詳細ページには 2 種類のデータ形式があります。以下のコードはその両方を処理します。
1def scrape_zillow_detail(url):
2 """Zillow の物件ページから詳細データを取得する。"""
3 response = httpx.get(url, headers=headers, timeout=15)
4 if response.status_code != 200:
5 return None
6 soup = BeautifulSoup(response.text, "lxml")
7 # まず __NEXT_DATA__ を試す(最も一般的)
8 script_tag = soup.find("script", {"id": "__NEXT_DATA__"})
9 if script_tag:
10 next_data = json.loads(script_tag.string)
11 try:
12 cache_str = next_data["props"]["pageProps"]["componentProps"]["gdpClientCache"]
13 cache = json.loads(cache_str)
14 first_key = next(iter(cache))
15 prop = cache[first_key]["property"]
16 return extract_property_fields(prop)
17 except (KeyError, StopIteration):
18 pass
19 # フォールバック: hdpApolloPreloadedData
20 apollo_tag = soup.find("script", {"id": "hdpApolloPreloadedData"})
21 if apollo_tag:
22 raw = json.loads(apollo_tag.string)
23 api_cache = json.loads(raw["apiCache"])
24 for key, value in api_cache.items():
25 if "ForSale" in key or "property" in str(value)[:100]:
26 prop = value.get("property", value)
27 return extract_property_fields(prop)
28 return None
29def extract_property_fields(prop):
30 """Zillow の物件 JSON から構造化データを取り出す。"""
31 return {
32 "zpid": prop.get("zpid"),
33 "zestimate": prop.get("zestimate"),
34 "rent_zestimate": prop.get("rentZestimate"),
35 "description": prop.get("description"),
36 "year_built": prop.get("yearBuilt"),
37 "lot_size": prop.get("lotSize"),
38 "hoa_fee": prop.get("monthlyHoaFee"),
39 "mls_id": prop.get("mlsid"),
40 "broker_name": prop.get("brokerName") or prop.get("attributionInfo", {}).get("brokerName"),
41 "price_history": [
42 {
43 "date": event.get("date"),
44 "event": event.get("event"),
45 "price": event.get("price"),
46 }
47 for event in prop.get("priceHistory", [])
48 ],
49 "tax_history": [
50 {
51 "year": record.get("time"),
52 "tax_paid": record.get("taxPaid"),
53 "value": record.get("value"),
54 }
55 for record in prop.get("taxHistory", [])
56 ],
57 "schools": [
58 {
59 "name": school.get("name"),
60 "rating": school.get("rating"),
61 "distance": school.get("distance"),
62 }
63 for school in prop.get("schools", [])
64 ],
65 }物件 URL をループし、間隔を空けて取得します。
1detail_data = []
2for listing in all_listings[:10]: # まずは10件でテスト
3 detail_url = listing.get("listing_url")
4 if not detail_url:
5 continue
6 if not detail_url.startswith("http"):
7 detail_url = f"https://www.zillow.com{detail_url}"
8 print(f"Scraping detail: {detail_url}")
9 detail = scrape_zillow_detail(detail_url)
10 if detail:
11 detail_data.append({**listing, **detail})
12 time.sleep(random.uniform(3, 8))この手順が終わると、検索レベルと詳細レベルの両方のデータを含む辞書のリストができあがります。
ステップ 4:ページネーションを処理して複数ページをスクレイピングする
820 件を超えるエリア(20 ページの上限)では、地理的に分割する必要があります。Zillow の内部 API は mapBounds パラメータを受け取ります。戦略としては、地図を四分割し、それぞれを個別にスクレイピングします。
1def split_bounds(bounds):
2 """地図の範囲を 4 つの四分割に分ける。"""
3 mid_lat = (bounds["north"] + bounds["south"]) / 2
4 mid_lng = (bounds["east"] + bounds["west"]) / 2
5 return [
6 {"north": bounds["north"], "south": mid_lat, "east": bounds["east"], "west": mid_lng},
7 {"north": bounds["north"], "south": mid_lat, "east": mid_lng, "west": bounds["west"]},
8 {"north": mid_lat, "south": bounds["south"], "east": bounds["east"], "west": mid_lng},
9 {"north": mid_lat, "south": bounds["south"], "east": mid_lng, "west": bounds["west"]},
10 ]多くの用途、たとえば特定エリアの 50〜200 件を監視するようなケースでは、通常の URL ページネーションで十分です。四分割の方法は、市全体や州全体を対象にする場合向けです。
ステップ 5:Zillow のスクレイピングデータをエクスポートする
pandas を使って CSV に保存します。
1import pandas as pd
2df = pd.DataFrame(detail_data)
3df.to_csv("zillow_houston_listings.csv", index=False)
4print(f"Exported {len(df)} listings to zillow_houston_listings.csv")JSON で保存したい場合は次のとおりです。
1with open("zillow_houston_listings.json", "w") as f:
2 json.dump(detail_data, f, indent=2)エクスポート自体を飛ばしたいなら、Thunderbit は Google Sheets、Airtable、Notion に無料で出力できます。すぐに共同編集できる形式でデータを使いたいときに便利です。
Zillow スクレイパーが壊れる理由と、壊れにくく作る方法
ここは“サバイバルガイド”です。
私の経験では、Zillow でスクレイパーが壊れる理由は主に 3 つあり、それぞれに明確な対策があります。
PerimeterX と CAPTCHA:なぜ空のデータが返ってくるのか
Zillow の PerimeterX は、TLS フィンガープリント、HTTP ヘッダー、IP の信頼性、リクエストのパターンを同時にチェックします。自動化だと判断されると、物件データの代わりに「Press & Hold」CAPTCHA ページが返されます。
典型的な失敗パターン: デフォルトの Python ヘッダーでリクエストを送ると、レスポンス HTML には物件データではなく PerimeterX のチャレンジスクリプトが含まれます。その結果、BeautifulSoup で解析しても __NEXT_DATA__ タグが見つかりません。
対策: ステップ 1 で示した、ブラウザを模した完全なヘッダーを使ってください。さらに、数十件を超えるリクエストを送るなら、プロキシローテーションも必要です(後述)。大量スクレイピングでは、impersonate="chrome" を指定できる curl_cffi のようなライブラリも検討してください。これは実際の Chrome に近い TLS フィンガープリントを再現できる、Python HTTP クライアントの中でも特に有効な選択肢です。
動的 CSS セレクタ:なぜ BeautifulSoup が None を返すのか
.list-card-price のような CSS セレクタや、ハッシュ付きのクラス名を使っている場合、Zillow が新しいコードをデプロイするたびにスクレイパーは壊れます。
Zillow は styled-components を使っており、StyledPropertyCardHomeDetailsList-c11n-8-109-3__sc-1j0som5-0 のようなクラス名を生成します。このハッシュ部分はビルドごとに変わります。
対策: 上のコードで示したように、CSS セレクタは使わず、__NEXT_DATA__ の JSON ブロックから取得してください。この方法は、HTML マークアップよりも JSON 構造の変化が少ないため、何年も安定しています。
どうしても HTML をパースする必要があるなら、data-test 属性(例: data-test="property-card")を探すか、[class*="PropertyCard"] のような部分一致を使ってください。ただし、JSON 抽出のほうが圧倒的に信頼できます。
プロキシローテーションと指数バックオフ:IP ブロックに耐えるコード
Zillow はデータセンター系 IP をします。安定してアクセスするには住宅用プロキシが必要です。安全な速度は、1 IP あたり 3〜8 秒に 1 リクエスト、かつ 1 時間あたり約 500 リクエスト以下です。
以下は、指数バックオフとジッターを使った再試行デコレータです。
1import random
2import time
3def backoff_with_jitter(attempt, base_delay=2, max_delay=60):
4 """AWS 方式のフルジッター付き指数バックオフ。"""
5 delay = min(max_delay, base_delay * (2 ** attempt))
6 return random.uniform(0, delay)
7def fetch_with_retry(url, max_retries=5):
8 for attempt in range(max_retries):
9 try:
10 response = httpx.get(url, headers=headers, timeout=15)
11 if response.status_code == 200:
12 return response
13 if response.status_code in (403, 429):
14 delay = backoff_with_jitter(attempt, base_delay=5)
15 print(f"Blocked ({response.status_code}). Retrying in {delay:.1f}s...")
16 time.sleep(delay)
17 continue
18 except Exception as e:
19 if attempt == max_retries - 1:
20 raise
21 time.sleep(backoff_with_jitter(attempt))
22 return None簡易的なプロキシローテーションプールも用意できます。
1class ProxyPool:
2 def __init__(self, proxies):
3 self.proxies = proxies
4 self.index = 0
5 self.failures = {}
6 def get_next(self):
7 proxy = self.proxies[self.index % len(self.proxies)]
8 self.index += 1
9 return {"http://": proxy, "https://": proxy}
10 def report_failure(self, proxy):
11 self.failures[proxy] = self.failures.get(proxy, 0) + 1
12 if self.failures[proxy] > 3:
13 self.proxies.remove(proxy)
14# 使用例:
15pool = ProxyPool(proxies=[
16 "http://user:pass@residential1.example.com:8080",
17 "http://user:pass@residential2.example.com:8080",
18])プロキシ提供元としては、 が住宅用プロキシを約 $1/GB で提供しており、最安クラスです。IPRoyal や Smartproxy も、$4〜7/GB の中堅として使いやすい選択肢です。
保守ゼロの代替案
Zillow を定期的にスクレイピングしていて、壊れたセレクタの修正やプロキシプールの管理に疲れているなら、Thunderbit の AI はスクレイプごとにページ構造を新しく読み込みます。セレクタの保守も、プロキシ設定も不要です。コード型スクレイパーを悩ませる脆さの問題を、実際に解消してくれます。
Zillow スクレイピングを自動化する:スケジューリングと価格モニタリング
私が話した不動産投資家は皆これを求めていましたが、他の Zillow スクレイピングガイドではここまで扱っていません。価格追跡のための定期自動スクレイピングです。
Python ユーザー向け:cron と価格変動検出
スクレイパーを毎週実行する cron ジョブを設定し、価格変動を検知します。
1import pandas as pd
2from datetime import datetime
3def detect_price_changes(new_data, historical_file, threshold=0.05):
4 """新しいスクレイプ結果と履歴データを比較し、しきい値超過の変化を検出する。"""
5 try:
6 old = pd.read_csv(historical_file)
7 except FileNotFoundError:
8 new_data.to_csv(historical_file, index=False)
9 print("First run — saved baseline data.")
10 return pd.DataFrame()
11 merged = new_data.merge(old, on="zpid", suffixes=("_new", "_old"))
12 merged["price_change_pct"] = (
13 (merged["price_new"] - merged["price_old"]) / merged["price_old"]
14 )
15 alerts = merged[merged["price_change_pct"].abs() > threshold]
16 # タイムスタンプ付きで新データを追記
17 new_data["scraped_at"] = datetime.now().isoformat()
18 new_data.to_csv(historical_file, mode="a", header=False, index=False)
19 return alertsこれを毎週月曜の午前 6 時に実行するよう、crontab に追加します。
10 6 * * 1 cd /path/to/scraper && python zillow_monitor.py実用例として、テキサス州オースティンの 50 件の物件を毎週監視するケースを考えてください。毎週月曜にスクリプトが現在価格を取得し、前週と比較して、5% を超える値下げを CSV に出力します。
非エンジニア向け:Thunderbit の Scheduled Scraper
Thunderbit の Scheduled Scraper なら、間隔を自然文で指定し(「毎週月曜の 9 時」など)、Zillow の検索 URL を入力して Schedule を押すだけです。実行ごとに Google Sheets へ自動エクスポートされます。Python も cron もサーバー運用も不要です。エンジニアの支援なしで安定した価格監視が必要な不動産エージェントや運用チームには特に便利です。
Zillow を責任ある形でスクレイピングするための注意点
境界線を越えないためのポイントをいくつか挙げます。
- 公開されているデータのみを取得する。 ログインが必要なページや認証の裏側には入らない。
- 無理のないリクエスト頻度にする。 1 リクエストごとに 3〜8 秒空ける。サーバーに負荷をかけすぎない。
- 個人・非公開データを取得しない。 掲載されているエージェント名や仲介会社情報は公開情報ですが、ユーザーアカウント情報は対象外です。
- データは倫理的に扱う。 市場調査、投資分析、リード獲得は正当な用途ですが、スパム目的は不適切です。
- 法的な文脈: は、公開アクセス可能なデータのスクレイピングは CFAA に違反しないことを示しました。Meta v. Bright Data(2024 年)の判決も同様の原則を支持しています。ただし、Zillow の利用規約は自動アクセスを制限しており、法的措置ではなく IP ブロックや CAPTCHA で対処しています。最新のガイダンスを確認し、 を尊重してください。
Python で Zillow をスクレイピングするなら、最適な方法を選ぼう
最適解は状況によって変わります。
今すぐデータが欲しい、コードは書きたくない? なら、Zillow の検索ページから構造化されたスプレッドシートまで約 2 分で到達できます。AI がレイアウト変更に対応し、ページネーションも処理し、エクスポートも無料です。 を入れて、Zillow の検索ページで試してみてください。
完全な制御が欲しい? このガイドの Python コードを使ってください。安定性のため、CSS セレクタではなく __NEXT_DATA__ JSON から取得しましょう。ブラウザを模した適切なヘッダーを設定し、住宅用プロキシと指数バックオフで信頼性を高めます。
大規模化したい? (Zillow で 99% の成功率)や ScraperAPI のようなスクレイピング API なら、プロキシと CAPTCHA の仕組みを代行してくれます。料金は量に応じて月額 $30〜599 です。
時間を追って価格を追跡したい? 価格変動検出スクリプトを使って cron ジョブを設定するか、保守不要の方法として Thunderbit の Scheduled Scraper を使ってください。
データはすでにそこにあります。あとは、それを取り出すためにどれだけエンジニアリング時間を使いたいかだけです。Web データをスプレッドシートに取り込む方法をもっと知りたい方は、 や、最新のプラットフォーム情報をまとめた もご覧ください。 でもチュートリアルを公開しています。
FAQ
Python で Zillow を無料でスクレイピングできますか?
はい。httpx、BeautifulSoup、pandas はすべて無料のオープンソースです。ただし、そのぶん時間はかかります。ヘッダー設定、プロキシローテーション、セレクタの保守を自分で管理する必要があります。初期セットアップには 4〜8 時間、Zillow がサイトを変更した際の月次保守には 4〜10 時間ほど見込んでください。コード作業を完全に避けたいなら、Thunderbit にも無料プランがあります。
Zillow に公式 API はありますか?
Zillow は 2021 年 9 月に無料の公開 API を終了しました。現在は Bridge Interactive 経由でのアクセスになり、承認が必要で、料金はおよそ月 500 ドル、対象はライセンスを持つ不動産業者向けです。投資家、研究者、市場分析を行うエージェントなど、多くのユーザーにとってはスクレイピングが現実的な代替手段です。なお Zillow は、 で Zillow Home Value Index や Zillow Observed Rent Index を含む研究用 CSV を無料公開しています。
Zillow をスクレイピングしてブロックされないようにするには?
ポイントは 3 つです。(1) Sec-Ch-Ua を含む本物らしいブラウザヘッダーを使うこと。これは多くのチュートリアルが省略しており、PerimeterX が最初に見る項目です。(2) 住宅用プロキシをローテーションすること。データセンター IP はすぐブロックされます。(3) HTML セレクタではなく __NEXT_DATA__ JSON から抽出すること。これでレイアウト変更による破損を避けられます。1 IP あたり 3〜8 秒に 1 リクエストのペースを守ってください。あるいは、Thunderbit のようなボット対策を自動処理するツールを使うのも有効です。
コードなしで Zillow をスクレイピングする最善の方法は?
Thunderbit の AI Web Scraper が最速です。 をインストールし、Zillow の検索ページを開き、「AI Suggest Fields」で列を自動検出してから「Scrape」をクリックしてください。Google Sheets、Excel、Airtable、Notion へ、コードなしでエクスポートできます。AI が毎回ページを新しく読み取るため、Zillow がレイアウトを更新しても壊れにくいです。
Zillow のサイト構造はどのくらいの頻度で変わり、スクレイパーにどう影響しますか?
Zillow は頻繁に、時には毎週のように更新を入れます。styled-components を使っているため、CSS クラス名はデプロイごとに変わり、CSS セレクタに依存したスクレイパーは定期的に壊れます。Python で最も安定する方法は、変化頻度の低い __NEXT_DATA__ JSON ブロックから取得することです。保守ゼロで運用したいなら、Thunderbit の AI が毎回ページ構造を再読込し、レイアウト変更に自動適応します。
さらに詳しく知る