Yelp には と があり、そのデータを実用的な形に落とし込むのは、これまで以上に難しくなっています。2024〜2025年にかけて強化された Yelp の対ボット対策によって、既存の Python スクレイピング解説の多くは、静かに使えなくなりました。
最近 Yelp スクレイパーを試して、403 エラーや空の HTML、あるいは半年前には出なかった CAPTCHA にぶつかったなら、それは気のせいではありません。Yelp は現在、TLS/JA3 フィンガープリント、ローテーションする難読化済み CSS クラス名、そして強力な IP レピュテーション判定を組み合わせています。つまり、今でも多くのチュートリアルで推奨されている requests + BeautifulSoup のやり方は、最初のリクエストで止まってしまうのです。私は数週間にわたって Yelp の現行スタックに対し、さまざまな手法を検証してきました。このガイドでは、2025 年に実際に通用する方法だけをまとめています。公式の Fusion API(なぜそれだけでは足りないのか)、多層のブロック回避戦略を組み込んだ Python スクレイピングの実践ワークフロー、そしてデバッグ地獄を避けたい人向けの、 を使った 2 クリックのノーコード代替案まで紹介します。
なぜ Python で Yelp をスクレイピングするのか、誰に向いているのか
コードを書く前に、まず Yelp データを使って何を達成したいのかを整理しましょう。Yelp は単なる飲食店レビューサイトではありません。店舗の連絡先、評価、カテゴリ、営業時間、そして数億件規模の顧客レビューを持つ、実質的なローカルビジネスのライブデータベースです。
特に恩恵が大きいのは次のような用途です。
| 用途 | 主な取得項目 | 重要な理由 |
|---|---|---|
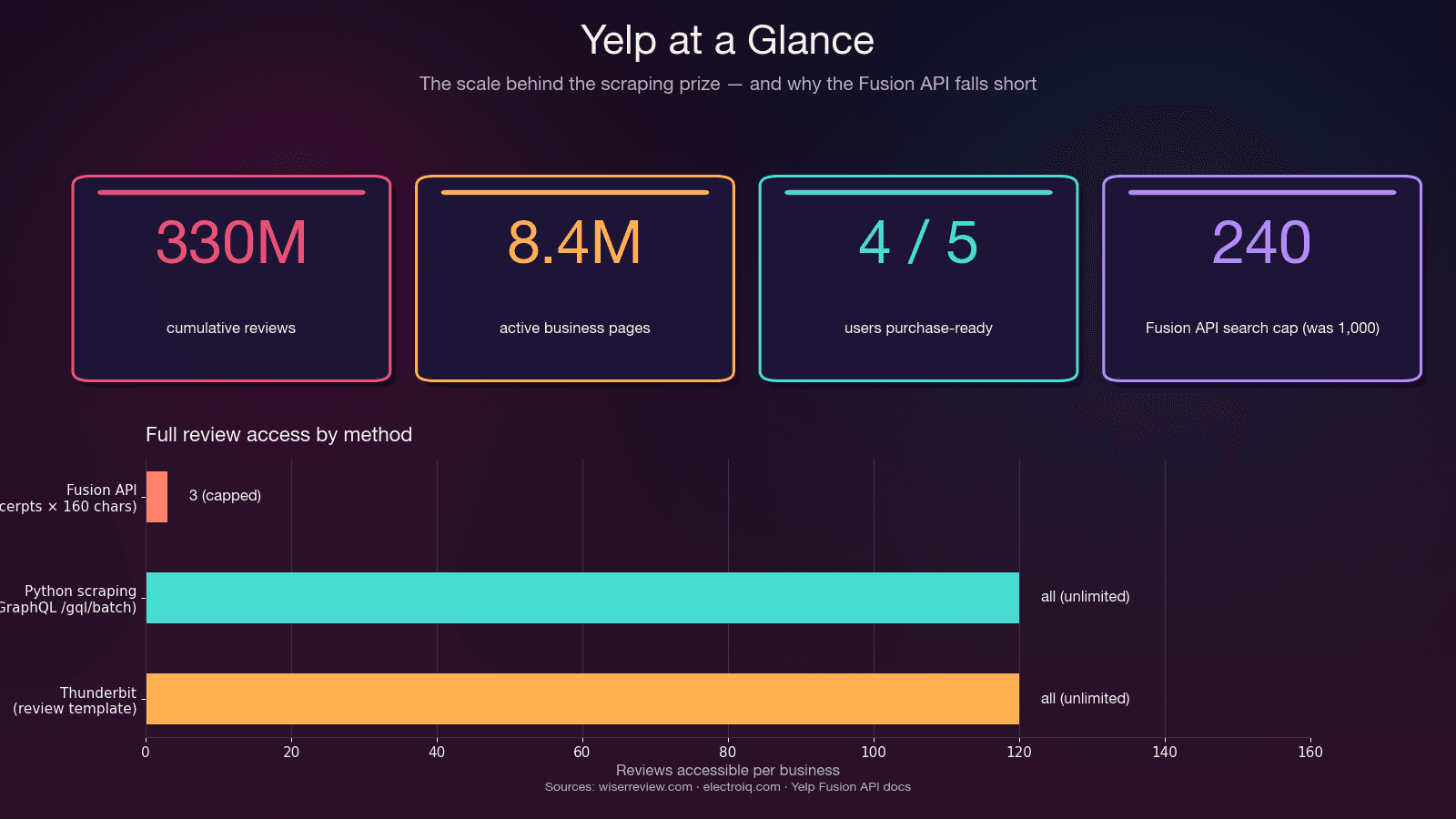
| 営業・リード獲得 | 店名、電話番号、Web サイト、住所、カテゴリ、評価 | 地域の中小企業を狙った見込み客リストを作成できる — Yelp ユーザーの 5 人中 4 人は来店準備ができている |
| 競合分析 | レビュー、星評価、レビュー件数、感情傾向 | 競合の評判を追跡し、サービスの穴やトレンドを把握できる |
| 市場調査・NLP | レビュー本文、日付、レビュアー情報 | 感情分析やトピックモデリングに活用できる — Yelp レビューは学術研究で 最もよく使われる NLP コーパスのひとつ |
| 不動産・出店戦略 | 業種密度、カテゴリの偏り、地域ごとのレビュー品質 | フランチャイズや小売店の出店判断に有効 — Yelp 自身もこの用途向けに Location Intelligence を提供している |
| EC・運営改善 | 価格の傾向、顧客の不満、営業時間 | 競合の評価傾向や運営上のパターンを把握できる |
共通するのは、最終的な目的は「構造化データ」であり、Python はその手段のひとつにすぎないという点です。プログラムで細かく制御したい人もいれば、オースティンの配管業者の連絡先をまとめたスプレッドシートが欲しいだけの人もいます。ここではその両方を扱います。
Yelp Fusion API と Python スクレイピング、どちらを使うべきか?
多くのガイドは、この判断を飛ばしていきなりコードに入ってしまいます。しかし、公式の (現在は「Yelp Places API」として再ブランド化)で十分だったのではないか、という検討は非常に重要です。私の経験では、ここを先に見極めるだけで、何時間もの無駄を防げます。API は一部の用途には優秀ですが、他の用途にはまったく不十分だからです。
Fusion API で実際に取れるもの
Fusion API では、構造化されたビジネス検索、詳細情報、オートコンプリート、レビュー用エンドポイントが提供されています。公式に認められており、ドキュメントも整っていて、対ボット対策の工夫も基本的に不要です。
ただし、問題はレビュー用エンドポイントです。Yelp のスタッフが GitHub で明言しています。
「Yelp API はレビュー本文の全文を返しません。デフォルトでは 160 文字のレビュー抜粋が 3 件提供されます。」 —
これは不具合ではなく、仕様です。API では物理的に 3 件のレビュー抜粋(Premium でも 7 件)までで、各抜粋は約 160 文字に切り詰められます。レビューのメタデータ(役に立った・面白い・クール)、レビュアー履歴、オーナー返信も取得できません。しかも 、以前の 5,000 回から大幅に減っています。料金は からです。
判断の目安
| 要素 | Yelp Fusion API | Python スクレイピング | Thunderbit(ノーコード) |
|---|---|---|---|
| 全レビュー | ❌ 3 件の抜粋のみ(各約 160 文字) | ✅ GraphQL 経由で全件取得 | ✅ 表示されているレビューをすべて取得 |
| レート制限 | 300〜500/日(新規); 5,000(旧) | 自己管理(プロキシ予算次第) | クレジット制 |
| 初期設定の手間 | 約15分(API キー + SDK) | 数時間〜数日 | 約2分 |
| 取得できるビジネス項目 | 約20項目の構造化データ | 制限なし(HTML/JSON を解析) | AI が項目を提案 |
| 対ボット対応 | 不要(公認) | 自作が必要 | 自動対応 |
| 法的リスク | ✅ 公認 | ⚠️ 利用規約上グレー | ⚠️ スクレイピング同様 |
| コスト | 最低 $29/月 | 無料 + プロキシ費用 $0.75〜$4/GB | 無料プランあり |
| 保守 | 低い(API が安定) | 高い(セレクタが壊れ、対策が強化され続ける) | 低い(AI が再適応) |
Fusion API が向いているケース: 基本的な店舗情報、小規模検索、公認された連携が必要で、1 店舗あたりレビュー抜粋 3 件で十分な場合。
Python スクレイピングが向いているケース: レビュー全文、1 店舗の全レビュー、レビューのメタデータ、1 回の検索で 240 件以上、または予算が月 $29 未満の場合。
Thunderbit が向いているケース: コードを書かず、保守もせず、とにかく速くデータを取りたい場合。詳細は下のノーコード章で説明します。
ノーコードの近道: Thunderbit で Yelp をスクレイピングする(Python 不要)
Python の深掘りに入る前に、目的が「コーディング」ではなく「データ取得」そのものである読者向けに、最短ルートを紹介します。競合の多くは Python が書ける前提で話しますが、Thunderbit で多くのユーザーを見てきた経験から言うと、「Yelp をスクレイピングしたい」と検索する人の大半は、営業担当、オペレーション担当、中小企業のオーナーです。TLS フィンガープリントの講座を受けたいわけではなく、地域の事業者一覧をスプレッドシートで欲しいだけなのです。
には、あらかじめ Yelp 用テンプレートが用意されています。
- — 店名、評価、連絡先、住所、営業時間、カテゴリを抽出
- — レビュアー名、レビュー本文、評価、日付、レビュアー所在地を抽出
実際の使い方
- Chrome で Yelp の検索結果ページまたは店舗ページを開く
- の AI Suggest Fields をクリックする — AI がページを読み取り、列を提案する(店名、評価、レビュー件数、価格帯、カテゴリ、住所、電話番号、URL など)
- Scrape をクリックする — これで完了
あらかじめ用意された Yelp テンプレートなら、さらに簡単です。テンプレートを開いて Scrape を押すだけです。
サブページスクレイピング を使えば、詳細情報の補完も自動で行われます。Yelp の検索結果ページを起点にサブページスクレイピングを有効にすると、Thunderbit が各店舗ページを巡回し、営業時間、レビュー全文、Web サイト、写真、設備情報などを取得します。追加設定は不要です。
ページネーションも自動対応 です。クリック型・スクロール型の両方に最初から対応しています。(仕組みの詳細は、 を参照してください。)
エクスポートは全プランで無料 — Excel、Google Sheets、Airtable、Notion、CSV、JSON に出力できます。pandas も CSV 書き出しコードも必要ありません。
時間比較
| 所要時間 | Python スクレイパー | Thunderbit |
|---|---|---|
| 初回実行 | 数時間〜数日(セレクタ作成、ページネーション、プロキシ、リトライ処理) | あらかじめ用意された Yelp テンプレートで約30秒 |
| Yelp が DOM を変更したとき | セレクタを手動で書き直す | AI Suggest Fields をもう一度押すだけで自動再適応 |
| IP がブロックされたとき | デバッグ、プロキシプールの切り替え、再テスト | Cloud モードが IP ローテーションを処理 |
| Google Sheets へ出力 | OAuth と pandas の連携コードを書く | ワンクリック、無料 |
まず Thunderbit を試して要件を満たすなら、この記事の残りは読まなくても大丈夫です。フルにプログラム制御したい、独自項目が必要、月に数千件を超える規模で扱いたい場合は、このまま読み進めてください。
Yelp スクレイピングに使う Python ライブラリはどれを選ぶべきか
「Scrapy、BS4+requests、それとも Selenium を使うべき?」は、Yelp に関する r/webscraping のスレッドでもよく出る質問です。しかし多くのチュートリアルは、自分のお気に入りライブラリを選んで終わりで、なぜそれが適切なのかを説明しません。ここでは率直に整理します。
2025 年の現実: requests + BeautifulSoup は Yelp では使えない
定番の Yelp チュートリアルで必ず出てくる pip install requests beautifulsoup4 の組み合わせは、2025 年の Yelp では 最初のリクエストでブロックされます。50 回目ではありません。最初です。
理由は、Python の requests ライブラリが、実際のブラウザに一致しない TLS/JA3 フィンガープリントを送るからです。Yelp の対ボット層は、User-Agent ヘッダーを読む前、TLS ハンドシェイクの段階でそれを検知します。私はこれを何度もテストしました。新規 IP、もっともらしいヘッダー、ランダムな遅延を入れても、素の requests ではすぐに 403 Forbidden になりました。
ライブラリの比較
| ライブラリ | 向いている用途 | JS 対応 | 対ボット対策 | 学習コスト | 速度 |
|---|---|---|---|---|---|
requests + BeautifulSoup | ❌ | ❌ | とても低い | 速い(ブロックされるまで) | |
httpx async + parsel | 大規模な非同期スクレイピング | ❌ | ❌ | 低い | 非常に速い |
curl_cffi + parsel | Yelp 特化: TLS なりすまし | ❌ | ✅ TLS/JA3/HTTP2 | 低い | 非常に速い |
Scrapy 2.14 | ページネーションを含むフルクロール | 一部対応(scrapy-playwright 経由) | AutoThrottle、retry ミドルウェア | 中〜高 | 速い |
Selenium 4.43 / Playwright 1.58 | JS が多いページ、CAPTCHA 回避 | ✅ | 部分的 | 中 | 遅い(約10〜30ページ/分) |
| Thunderbit | 非エンジニア、素早い抽出 | ✅(ブラウザ) | 内蔵(Cloud モード) | とても低い | 速い |
curl_cffi が変えたこと
私の Yelp スクレイピングを大きく変えたのは です。これは curl-impersonate の Python バインディングで、実際の Chrome とまったく同じ TLS/JA3 + HTTP/2 フィンガープリント を送ります。API も requests の置き換えとしてそのまま使えます。
1from curl_cffi import requests
2r = requests.get(
3 "https://www.yelp.com/biz/some-restaurant",
4 impersonate="chrome131",
5)
6print(r.status_code, len(r.text))この 1 行の変更、つまり from curl_cffi import requests と impersonate="chrome131" を付けるだけで、ブラウザを立ち上げずに Yelp の を回避できます。私の検証では、即時 403 と正常な 200 レスポンスの違いがここにありました。
2025 年に Yelp 向けで推奨する構成: curl_cffi + parsel + jmespath + レジデンシャルプロキシ。スケジューリングを含むフルクロールパイプラインが必要なら、curl_cffi ベースの downloader middleware を組み込んだ Scrapy 2.14 で包むとよいです。
Yelp をスクレイピングするための Python 環境構築
- 難易度: 中級
- 所要時間: セットアップ 15 分程度、動くスクレイパー完成まで 1〜2 時間
- 必要なもの: Python 3.10 以上(推奨は 3.12)、ターミナル、必要に応じてレジデンシャルプロキシ業者
手順 1: 仮想環境を作成してパッケージをインストールする
1python3.12 -m venv .venv
2source .venv/bin/activate # Windows の場合: .venv\Scripts\activate
3pip install "curl_cffi>=0.11" "parsel>=1.9" "jmespath>=1.0" pandas各パッケージの役割:
curl_cffi— Chrome の TLS フィンガープリントで HTTP リクエストを送る(対ボット回避の要)parsel— HTML を解析するための CSS/XPath セレクタ(Scrapy と同じエンジンで軽量)jmespath— 宣言的な JSON クエリ(Yelp の埋め込み JSON を扱うときにネストした辞書アクセスより読みやすい)pandas— CSV/Excel へのデータ出力
あると便利なもの:
1pip install fake-useragent # 注: リポジトリは 2026 年 4 月にアーカイブされたが、今でもインストール可能手順を追って解説: Python で Yelp をスクレイピングする方法
ここが本編です。すべてをより堅牢にする重要な発想は、CSS セレクタを追うのではなく、隠れた JSON を直接取ることです。Yelp はビルド時に CSS クラス名をランダム化します(今週は y-css-14xwok2、来週は y-css-hcq7b9 という具合)。そのため、そこに固定したスクレイパーは数週間で壊れます。一方、埋め込み JSON ペイロードである application/ld+json スキーマや react-root-props は安定しています。
手順 2: Yelp の検索結果を取得する
Yelp の検索 URL は https://www.yelp.com/search?find_desc={term}&find_loc={location} という分かりやすい形式です。検索結果データは、CSS クラスだらけの HTML ではなく、<script data-id="react-root-props"> タグ内に JSON として埋め込まれています。
1import re, json, jmespath
2from curl_cffi import requests
3from parsel import Selector
4> This paragraph contains content that cannot be parsed and has been skipped.
5> This paragraph contains content that cannot be parsed and has been skipped.
6これで、店名、URL、評価、レビュー件数を持つ dict のリストが返ってくるはずです。レスポンスから `react-root-props` が消えている場合は、ブロック用の空シェルが返されているので、IP を切り替えて再試行してください。
7`Cookie: intl_splash=false` は、Yelp の国別スプラッシュリダイレクトを回避する定番の対策です。これがないと、米国外 IP ではソフトブロックのように見えるスプラッシュページに飛ばされます。
8### 手順 3: Yelp の店舗ページを取得する
9検索結果から得た各ビジネス URL 先には、より豊富な情報を含む詳細ページがあります。最も安定した抽出対象は `<script type="application/ld+json">` ブロックです。ここには schema.org の構造化データが入っており、Yelp は SEO のためにこれを維持していて、難読化していません。
10```python
11def scrape_business(biz_url: str) -> dict:
12 url = f"https://www.yelp.com{biz_url}" if biz_url.startswith("/") else biz_url
13 r = requests.get(url, headers=HEADERS, impersonate="chrome131")
14 if r.status_code != 200:
15 return {"url": url, "error": r.status_code}
16 sel = Selector(text=r.text)
17 biz_id = sel.css('meta[name="yelp-biz-id"]::attr(content)').get()
18 for raw in sel.css('script[type="application/ld+json"]::text').getall():
19 try:
20 data = json.loads(raw)
21 except json.JSONDecodeError:
22 continue
23 for node in (data if isinstance(data, list) else [data]):
24 if node.get("@type") in (
25 "Restaurant", "LocalBusiness", "FoodEstablishment",
26 "HealthAndBeautyBusiness", "HomeAndConstructionBusiness",
27 ):
28 return {
29 "biz_id": biz_id,
30 "name": node.get("name"),
31 "rating": (node.get("aggregateRating") or {}).get("ratingValue"),
32 "review_count": (node.get("aggregateRating") or {}).get("reviewCount"),
33 "address": node.get("address"),
34 "telephone": node.get("telephone"),
35 "price_range": node.get("priceRange"),
36 "hours": node.get("openingHours"),
37 "url": url,
38 }
39 return {"biz_id": biz_id, "url": url}meta[name="yelp-biz-id"] の値は、レビュー用エンドポイントで必要になるエンコード済みのビジネス ID です。次の手順で使うので、ここで取得しておきましょう。
手順 4: ページネーション付きで Yelp のレビューを取得する
ここで Fusion API の限界が見えてきて、スクレイピングが強みを発揮します。Yelp の内部 GraphQL バッチエンドポイントは、レビュー全文、レビュアー情報、日付、評価、投票数を返します。API が返してくれない情報がすべて手に入ります。
エンドポイントは https://www.yelp.com/gql/batch で、GetBusinessReviewFeed オペレーション向けに固定の documentId を使います。ページネーションは base64 エンコードされた cursor で行います。
1import base64
2GQL_URL = "https://www.yelp.com/gql/batch"
3DOC_ID = "ef51f33d1b0eccc958dddbf6cde15739c48b34637a00ebe316441031d4bf7681"
4> This paragraph contains content that cannot be parsed and has been skipped.
51 ページあたり 10 件のレビューが返ります。`after` cursor 内の `offset` を増やしてページネーションします。`sortBy` パラメータには `DATE_DESC`(新しい順)、`RATING_ASC`、`RATING_DESC` などが使えます。
6### 手順 5: 取得した Yelp データをエクスポートする
7```python
8import pandas as pd
9# businesses と reviews を収集済みだと仮定
10_df_businesses = pd.DataFrame(businesses)
11_df_businesses.to_csv("yelp_businesses.csv", index=False)
12df_reviews = pd.DataFrame(all_reviews)
13df_reviews.to_csv("yelp_reviews.csv", index=False)
14> This paragraph contains content that cannot be parsed and has been skipped.
15ノーコード派の読者なら、Thunderbit は同じデータを Excel、Google Sheets、Airtable、Notion にそのまま出力できます。pandas もファイル書き込みコードも不要です。
16## ブロック回避の実践集: Yelp にブロックされずにスクレイピングする方法
17このセクションこそ、この記事が存在する理由です。Yelp の対ボット対策は 2024 年後半以降かなり厳しくなっており、[TLS フィンガープリント、IP レピュテーション判定、CAPTCHA、行動分析](https://blog.apify.com/how-to-scrape-yelp/) がすべて使われています。既存のガイドが古いのは、この大規模な締め付けの前に書かれたものだからです。
18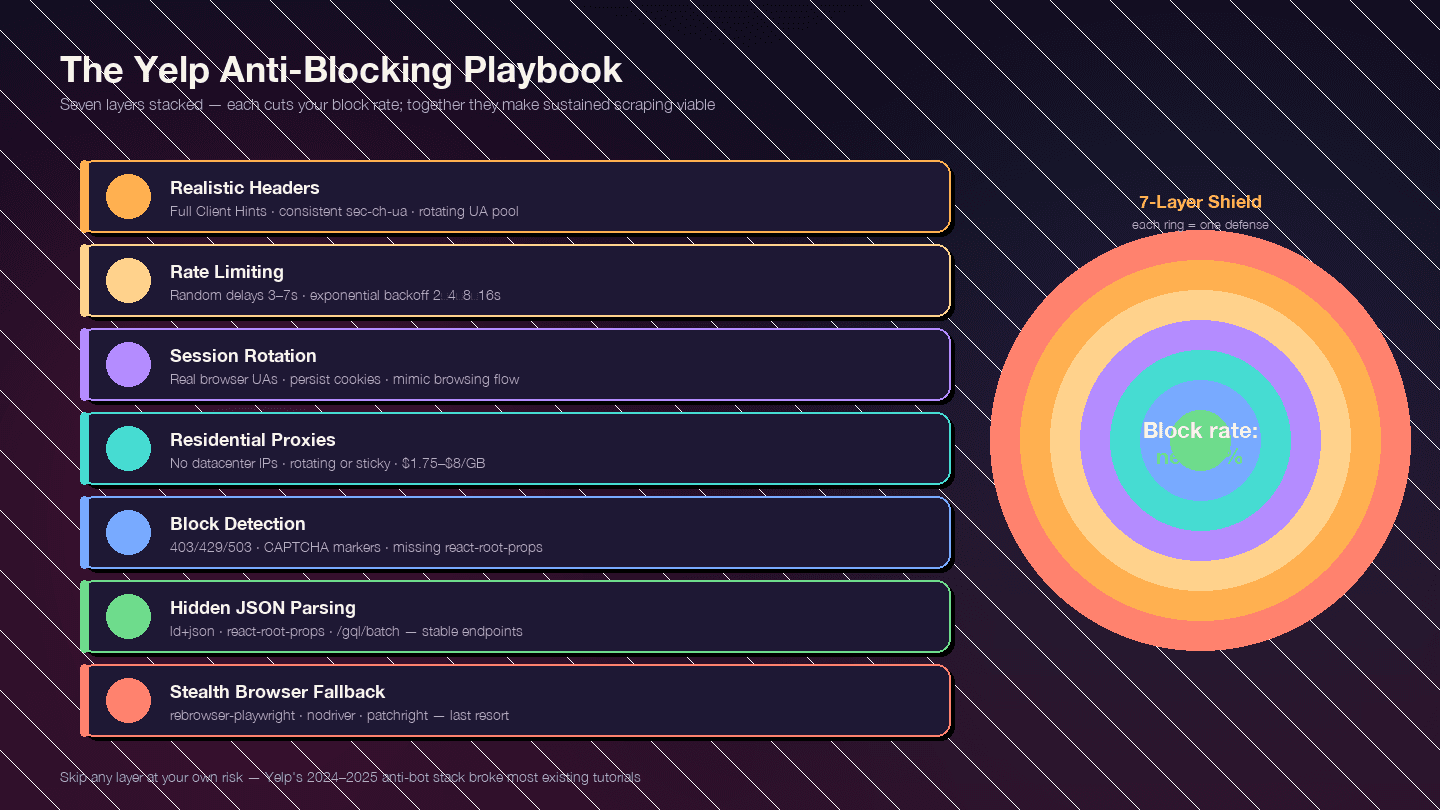
19対策は多層構造にするのが基本です。各層がブロック率を下げ、組み合わせることで継続的なスクレイピングが可能になります。
20### レイヤー 1: 現実的なリクエストヘッダー
21Python `requests` のデフォルトヘッダーは `User-Agent: python-requests/2.x` になります。これは即ブロックです。とはいえ、もっともらしい User-Agent を入れるだけでは足りません。Yelp は [Client Hints](https://scraperapi.com/web-scraping/yelp/) の一式も整合性チェックしています。
22```python
23FULL_HEADERS = {
24 "authority": "www.yelp.com",
25 "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
26 "AppleWebKit/537.36 (KHTML, like Gecko) "
27 "Chrome/124.0.0.0 Safari/537.36",
28 "accept": "text/html,application/xhtml+xml,application/xml;q=0.9,"
29 "image/avif,image/webp,image/apng,*/*;q=0.8",
30 "accept-language": "en-US,en;q=0.9",
31 "accept-encoding": "gzip, deflate, br",
32 "sec-ch-ua": '"Chromium";v="124", "Google Chrome";v="124", "Not-A.Brand";v="99"',
33 "sec-ch-ua-mobile": "?0",
34 "sec-ch-ua-platform": '"Windows"',
35 "sec-fetch-dest": "document",
36 "sec-fetch-mode": "navigate",
37 "sec-fetch-site": "same-origin",
38 "sec-fetch-user": "?1",
39 "upgrade-insecure-requests": "1",
40 "referer": "https://www.yelp.com/",
41 "cookie": "intl_splash=false",
42}ブロックされやすいミスは次の 3 つです。
- UA は Chrome を名乗っているのに
sec-ch-uaがない、または UA のバージョンと矛盾している sec-ch-ua-platformは「Windows」なのに、UA 文字列は macOS を示している- 1 つの IP から何千回も同じ UA を使い回している — 最近の Chrome/Firefox/Safari の文字列を 10〜20 個ほどローテーションする
レイヤー 2: レート制御とランダム遅延
予測可能なタイミングは危険信号です。ランダムな sleep 間隔を入れ、エラー時には指数バックオフを実装しましょう。
1import random, time
2> This paragraph contains content that cannot be parsed and has been skipped.
3<Table content={`| **パラメータ** | **推奨値** |
4|---|---|
5| リクエスト間のランダム待機 | \`random.uniform(3, 7)\` 秒 |
6| 429/403/503 時のバックオフ | 2 → 4 → 8 → 16 秒、最大 5 回 |
7| 1 IP あたりの並列ワーカー数 | 1(IP ごとに直列処理し、並列化はプロキシで) |
8| レジデンシャル IP の持続的な最大レート | 約 1 リクエスト / 5 秒(約 12 rpm) |`} />
9### レイヤー 3: User-Agent とセッションのローテーション
10実在するブラウザの User-Agent を複数用意して切り替えます。セッションと Cookie は保持し、実際のブラウジングに近い振る舞いを再現します。Yelp は Cookie ベースの検出を行うため、リクエストごとに新しいセッションを作るのは逆に不自然です。
11```python
12UA_POOL = [
13 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 Chrome/124.0.0.0 Safari/537.36",
14 "Mozilla/5.0 (Macintosh; Intel Mac OS X 14_4_1) AppleWebKit/537.36 Chrome/124.0.0.0 Safari/537.36",
15 "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:125.0) Gecko/20100101 Firefox/125.0",
16 "Mozilla/5.0 (Macintosh; Intel Mac OS X 14_4_1; rv:125.0) Gecko/20100101 Firefox/125.0",
17 "Mozilla/5.0 (Macintosh; Intel Mac OS X 14_4_1) AppleWebKit/605.1.15 Safari/17.4.1",
18 # ここに最近の文字列を 5〜10 個追加
19]レイヤー 4: プロキシのローテーション
実運用のボリュームでは、レジデンシャルプロキシが必要です。データセンター系や無料プロキシは Yelp では機能しません。Yelp の IP レピュテーション層は、AWS、GCP、DigitalOcean の IP 帯を先回りで 403 にします。
| 提供元 | 開始価格/GB | 補足 |
|---|---|---|
| IPRoyal | $1.75/GB | 最安クラス。最も引用される Yelp 解説で使われている |
| Decodo(旧 Smartproxy) | $3.20〜$3.50 | 大量利用時の GB/$ 比が優秀 |
| Bright Data | $4.00(従量課金) | 1.5 億超の IP プール、Yelp 専用ページあり |
| Oxylabs | $6.00〜$8.00 | プレミアム。 1,000 万超の IP |
| Aluvia(モバイル SIM) | $3.00 | 実在する米国キャリアのモバイル IP。 Yelp 向けとして位置付け |
ローテーション型レジデンシャル(リクエストごとに新 IP)は、大量の検索クロールに最適です。スティッキーセッション(10 分ほど同じ IP を維持)は、店舗ページ → レビュー → ページネーションの流れで Cookie を引き継ぎたいときに向いています。
レイヤー 5: ブロックの検知と対処
ブロックの見え方は一様ではありません。Yelp は CAPTCHA ではなく、一般的な「page not available」シェルを返すことがよくあります。そのため、単純なスクレイパーはデータが取れていると勘違いし、実際には空レスポンスを処理してしまいます。
1BLOCK_MARKERS = (
2 "captcha", "px-captcha", "page not available",
3 "access denied", "unusual traffic",
4)
5def is_blocked(resp):
6 if resp.status_code in (401, 403, 429, 503):
7 return True
8 body = resp.text.lower()
9 if any(m in body for m in BLOCK_MARKERS):
10 return True
11 # これは検索/店舗ページなのに react-root-props がないなら、
12 # Yelp は中身を抜いたブロック応答を返している
13 if "react-root-props" not in body and "/biz/" in str(resp.url):
14 return True
15 return False| 兆候 | 意味 |
|---|---|
| HTTP 403 | ハードブロック — IP/ヘッダー/TLS が焼かれている |
| HTTP 429 | レート制限 — バックオフで回復可能なことが多い |
| HTTP 503 | 一般的なブロック、または負荷切り捨て |
/error へリダイレクト、または本文に "page not available" | ソフトブロック |
| が空で | JS 待ちのチャレンジページ |
本文に captcha / g-recaptcha / px-captcha がある | エスカレート済み — CAPTCHA 必要 |
一覧ページで react-root-props が欠けている | 中身を抜いたブロック応答 |
レイヤー 6: もっとも堅牢な解析のコツ — CSS セレクタではなく隠れた JSON を読む
繰り返しになりますが、Yelp はビルド時に CSS クラス名をランダム化します。h3.y-css-14xwok2 に固定したスクレイパーは、Yelp が h3.y-css-hcq7b9 へ再デプロイした瞬間に壊れます。
一方で、動かないものは次です。
<script type="application/ld+json">— schema.org の構造化データ(店名、住所、電話番号、評価、営業時間)<script data-id="react-root-props">— 検索結果全体を JSON として保持https://www.yelp.com/gql/batch— 安定したdocumentIdを使う GraphQL レビューエンドポイント
CSS クラスを解析している限り、砂の上に家を建てているのと同じです。代わりに JSON を読んでください。
レイヤー 7: ステルスブラウザへのフォールバック
curl_cffi + レジデンシャルプロキシで突破できないときだけ、ヘッドレスブラウザに切り替えます。典型的には、Yelp が JavaScript チャレンジページや CAPTCHA を返してくる場合です。
ビジネスページ、検索結果、レビュー取得の 95% は、curl_cffi + 隠れ JSON + レジデンシャルプロキシの組み合わせの方が、ブラウザより速く、安く、安定しています。それでもブラウザが必要なら、次のツールが候補です。
This paragraph contains content that cannot be parsed and has been skipped.
Yelp に vanilla Selenium は使わないでください。フィンガープリントされやすすぎます。
Yelp Fusion API vs. Python スクレイピング vs. Thunderbit: 徹底比較
| 観点 | Yelp Fusion API | Python スクレイピング | Thunderbit |
|---|---|---|---|
| レビュー全文 | ❌ 約160文字の抜粋 3 件 | ✅ 無制限(GraphQL) | ✅ レビュー用テンプレート内蔵 |
| レビューのメタデータ(投票、オーナー返信) | ❌ | ✅ | ✅ AI で項目提案 |
| 写真 | ❌(Base では 0) | ✅ 無制限 | ✅ |
| 検索あたりの最大件数 | 240(2024 年以前は 1,000) | 無制限(ページネーションあり) | 無制限 |
| 1 日のレート制限 | 300〜500(新規)/ 5,000(旧) | プロキシ予算のみ | クレジット制(Pro では月 3,000) |
| 初期設定の手間 | 約15分 | 数時間〜数日 | 約2分 |
| 対ボット対応 | 不要 | 自分で対応 | 対応済み(Cloud モード) |
| 法的リスク | 低い(公認) | 中程度(利用規約上グレー) | 中程度(スクレイピング同様) |
| コスト(導入) | $29/月 | 約 $0.75〜$4/GB のプロキシ + 開発工数 | 無料プラン |
| コスト(大量利用) | 月 $643 以上 | 月 $50〜$500 のプロキシ + 開発工数 | 月 $38〜$49 |
| データ出力 | JSON | CSV/JSON(自分で実装) | Excel / Sheets / Airtable / Notion — 無料 |
| 保守 | 低い | 高い(セレクタが壊れ、対策が強化される) | 低い(AI が再適応) |
Yelp スクレイピングの法務と倫理について
私は弁護士ではなく、これは法的助言ではありません。ただし、この 2 年で法的な状況はかなり変わっているので、Yelp スクレイピングに時間を投資する前に基本は押さえておくべきです。
Yelp の利用規約では何が禁止されているか: では、「ロボット、スパイダー、その他の自動化された手段」を使って「サービスの一部へアクセス、取得、コピー、スクレイプ、インデックス化すること」が明確に禁止されています。さらに、「AI Technologies およびその他の自動ツール」に関する文言も追加されました。
繰り返し次のように案内しています: 「Yelp はサイトのいかなるスクレイピングも許可していません。」
robots.txt の内容: Yelp の にはワイルドカードの User-agent: * / Disallow: / があり、GPTBot、ClaudeBot、PerplexityBot、CCBot、Meta-ExternalAgent も明示的にブロックしています。許可されているのは Googlebot、Bingbot、いくつかのソーシャルメディアクローラーのみです。
重要な判例: (カリフォルニア北部地区、2024年1月)では、公開されログアウト状態のデータをスクレイピングすることは Meta の利用規約違反ではないと判断されました。ここで大事なのは、ログアウト状態の公開データと、ログインが必要なデータの違いです。 では、公開データのスクレイピングは CFAA に違反しない可能性が高いとされましたが、hiQ は州法上の不法行為(動産侵害、不正流用)では敗訴し、50 万ドルの判決を受けました。
実務上の指針:
- 公開されているログアウト状態のページだけを対象にする
- リクエスト頻度を抑える(このガイドの遅延処理は、倫理的なレート制限としても機能します)
- 実名ユーザーに紐づくレビュー本文をそのまま再販しない — 投稿者のプライバシーを尊重する
- 地域のデータ保護法(CCPA、GDPR)を遵守する
- ログインしてのスクレイピングはしない — それは許可の境界を越えます
- 店舗情報(店名、住所、電話番号、評価)は公開された事実データとして扱い、レビュー本文はより慎重に扱う
個別の状況については、法律の専門家に相談してください。
まとめ
目的はひとつ、やり方は三つです。
Yelp Fusion API は、公認されていて保守負担も低い選択肢ですが、レビュー抜粋は 3 件までで、料金は月 $29 からです。Python スクレイピングなら Yelp 上のあらゆるデータを細かく制御できますが、その代わり、TLS なりすましのための curl_cffi、レジデンシャルプロキシ、ランダム遅延、隠れ JSON の解析、そして Yelp の防御が進化し続ける中での継続保守が必要です。Thunderbit なら、コードもプロキシ設定もなしに、約 30 秒で「Yelp データが欲しい」から「スプレッドシートができた」まで到達できます。
2025 年に本当に効くブロック回避策は、フルの Client Hints を含む現実的なヘッダー、TLS フィンガープリントを偽装する curl_cffi、指数バックオフ付きのランダム遅延、レジデンシャルプロキシのローテーション、そして何より、壊れやすい CSS セレクタではなく隠れた JSON(application/ld+json と react-root-props)を読むことです。
どの方法が合うか迷うなら、まず を試してください。要件を満たすなら、何時間も節約できます。より高度な制御が必要なら — 完全なプログラムパイプライン、独自項目、CRM との密接な連携など — 上の Python ガイドが役立ちます。さらにスクレイピングツール全体を比較したい場合は、 のまとめや、 のガイドもご覧ください。
FAQ
Python で Yelp を無料でスクレイピングできますか?
はい。curl_cffi、parsel、jmespath のような無料ライブラリを使えば可能です。ただし、実運用の規模(数十ページを超える場合)になると、 の有料レジデンシャルプロキシが必要になります。Thunderbit も、手早くノーコードで抽出したい人向けに、月 6 ページまで使える無料プランを提供しています。
Yelp はスクレイパーをブロックしますか?
はい、かなり強くブロックします。Yelp は を使っています。素の requests は最初のアクセスで止められます。このガイドで紹介した、curl_cffi による TLS なりすまし、現実的なヘッダー、ランダム遅延、レジデンシャルプロキシを組み合わせた多層対策が、2025 年に機能する方法です。
Yelp Fusion API はスクレイピングより優れていますか?
用途次第です。API は公認でリスクが低いものの、返すのは に限られ、検索結果も 240 件まで、料金は月 $29 からです。レビュー全文、レビューのメタデータ、1 日に数百件を超える記録が必要なら、スクレイピングが唯一の選択肢になります。
Python で Yelp レビューをスクレイピングするには?
curl_cffi を impersonate="chrome131" 付きで使って店舗ページを取得し、<meta name="yelp-biz-id"> からエンコード済みビジネス ID を取り出します。その後、https://www.yelp.com/gql/batch に GetBusinessReviewFeed オペレーションで POST し、base64 エンコードされた after cursor でページネーションします。手順付きコードは上のチュートリアル部分にあります。参考実装としては も有用です。
コーディングなしで Yelp をスクレイピングできますか?
はい。 には、 と のテンプレートが最初から入っています。Yelp のページを開いて、AI Suggest Fields をクリックし、Scrape を押すだけです。Google Sheets、Excel、Airtable、Notion への出力は、無料プランを含む全プランで無料です。
さらに詳しく