Walmartは、一部商品の価格を変えます。これをプログラムで追いかけたことがあるなら、その大変さは身に覚えがあるはずです。スクリプトが20分は普通に動いても、そのあと何事もなかったように、200 OKでCAPTCHAページを返し始めることがあります。
Thunderbitでのデータ抽出業務の一環として、Walmartのボット対策にはかなり時間をかけて向き合ってきました。そこで今回、実際に使える手法、データを汚染するサイレント失敗、そして自作スクレイパーにするか、スクレイピングAPIにお金を払うか、ノーコードツールで済ませるかという現実的なトレードオフまで、学んだことをすべて共有したいと思います。このガイドでは、3つの抽出方法(HTML解析、__NEXT_DATA__ JSON、内部APIのインターセプト)、多くのチュートリアルが完全に省略しがちな本番向けエラーハンドリング、そして最適な方法を選ぶための率直な判断フレームワークを紹介します。Pythonで書く人にも、昼までに価格一覧のスプレッドシートが欲しい人にも、役立つ内容です。
なぜPythonでWalmartをスクレイピングするのか?
Walmartは売上高ベースで世界最大の小売業者で、を記録し、を維持しています。サイト上にはおよそがあり、WalmartのCFOはマーケットプレイスについてと述べています。その約で、カタログは非常に流動的です。出品者は入れ替わり、バリエーションは変わり、在庫は毎日変動します。
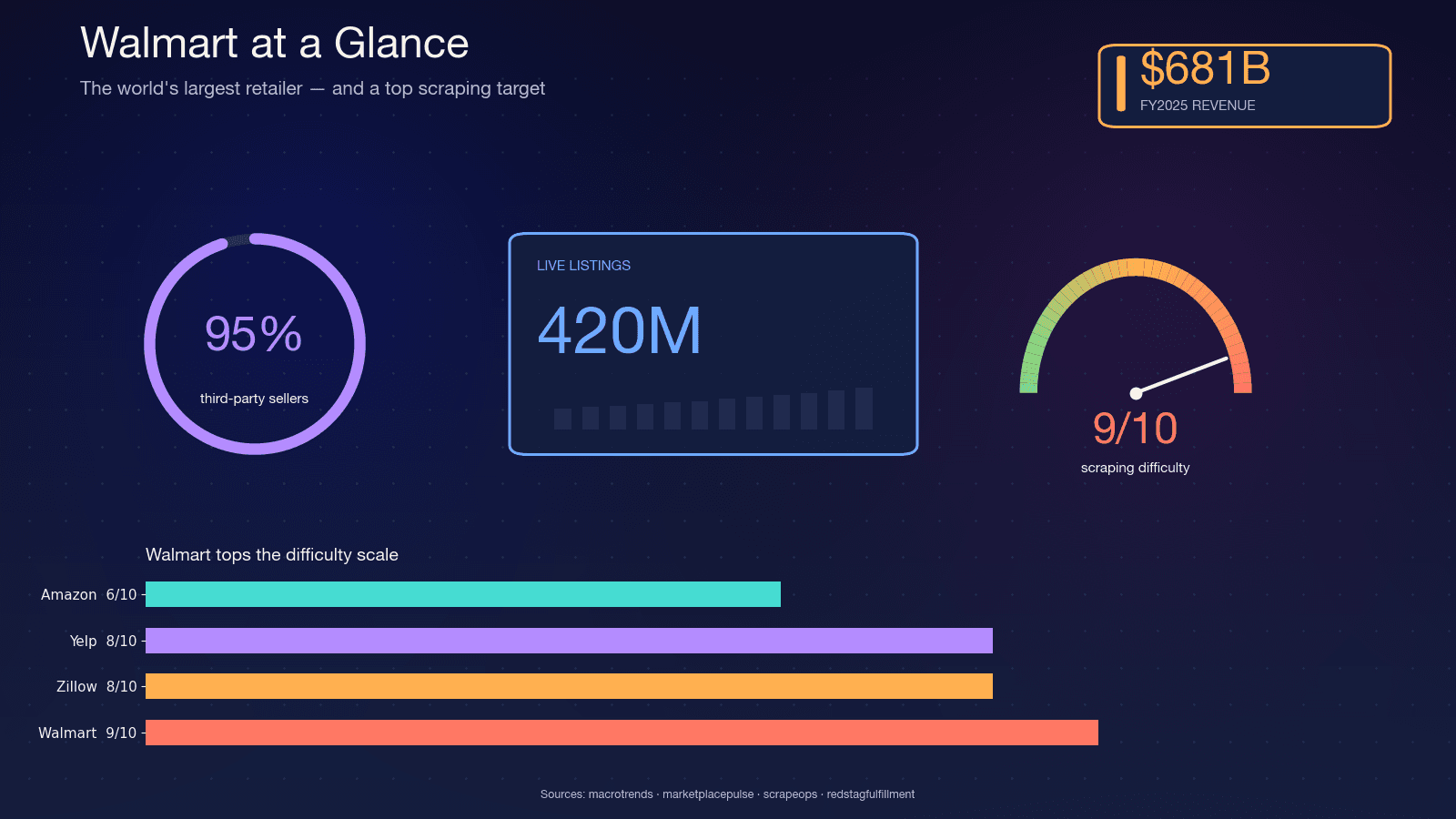
この変化の大きさこそ、スクレイピングが重要な理由です。四半期レポートでは、毎晩のスクレイピングで拾える細かな変化までは追えません。よくあるユースケースは次のとおりです。
| 用途 | 必要とする人 | 抽出対象 |
|---|---|---|
| 競合価格のモニタリング | EC運営、価格改定ツール | 価格、プロモーション、MAP順守状況 |
| 商品カタログの充実 | 営業、マーチャンダイジング担当 | 説明文、画像、仕様、バリエーション |
| 在庫有無の追跡 | サプライチェーン、ドロップシッパー | 在庫状況、販売者情報 |
| 市場調査・トレンド分析 | マーケティング、プロダクトマネージャー | 評価、レビュー、カテゴリ構成 |
| リード獲得 | 営業チーム | 販売者名、商品数、カテゴリ |
に達し、2033年には50.9億ドルに成長すると予測されています。消費者行動もこの支出を後押ししています。、83%は複数サイトで見比べています。
この分野ではPythonが標準です。Apifyの2026年インフラレポートによると、で行われており、中核ライブラリのrequestsもされています。何らかの規模でスクレイピングするなら、ほぼ確実にPythonを使っているはずです。
Walmartが最もスクレイピングしづらいサイトの一つである理由
Walmartが特に難しいのは、2つの商用ボット対策製品を連続で使っているからです。がエッジWAFとTLSフィンガープリント層を担い、が挙動ベースのJavaScriptチャレンジ層を担っています。Scrape.doはこの組み合わせを「珍しく、回避が極めて難しい」と評しています。
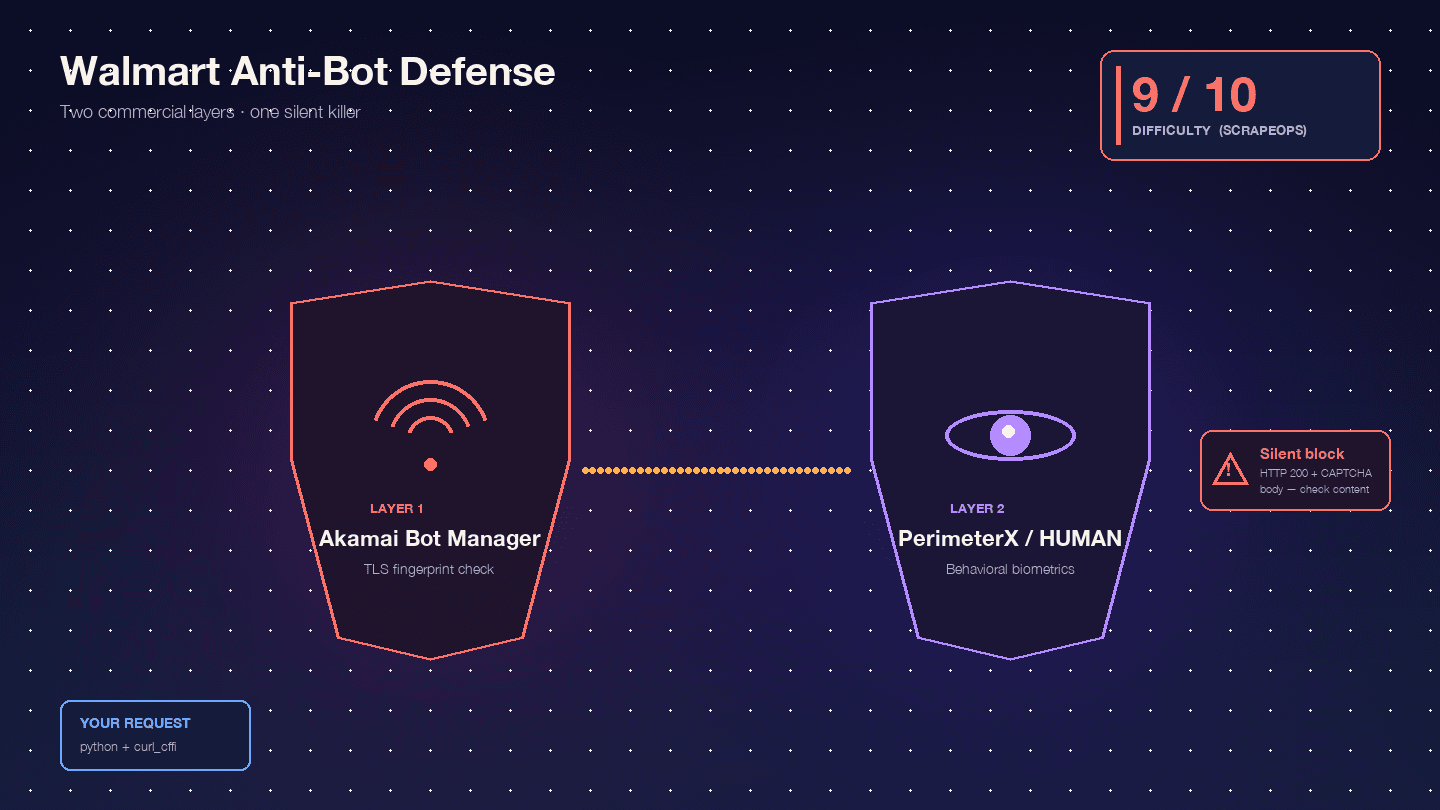
と評価しており、Akamai単体でも9/10です。実際の体感としても、おおむねその通りです。
実際に何と戦うのかを整理すると、次のとおりです。
Akamai Bot Managerは、TLSフィンガープリント(JA3/JA4ハッシュ)、HTTP/2のフレーム順序、ヘッダーの順序と大文字小文字、セッションCookie(_abck、ak_bmsc)を検査します。標準のPython requests は、実ブラウザでは生成されないTLSフィンガープリントを送るため、Walmartのサーバーに届く前にAkamaiに弾かれます。
PerimeterX/HUMANはAkamaiの後段で動き、JavaScriptによるフィンガープリント(px.js)を実行して、navigatorのプロパティ、canvas描画、WebGL、audio context、そして行動生体情報(マウス移動、スクロール速度、キー入力のリズム)を確認します。目に見える失敗例が、悪名高いです。およそ10秒間ボタンを押し続け、その間に行動シグナルが採取されます。Oxylabsは率直にこう述べています。「WalmartはPerimeterX提供のCAPTCHAである『Press & Hold』方式を使っており、コードから解くのはほぼ不可能として知られている。」
本当に厄介なのは、サイレントブロックです。Walmartは403ではなく、HTTP 200でCAPTCHA本文を返すことがあります。。「WalmartはCAPTCHAページを返すときでも200 OKを返します。リクエストが成功したかどうかをステータスコードだけで判断することはできません。」スクリプトはCAPTCHAのHTMLを「商品が見つからない」と解釈して、そのまま進んでしまいます。するとデータセットの半分がゴミになり、しかも気づけません。
さらに、店舗スコープのデータ問題があります。Walmartの価格と在庫は地域ごとに異なり、locDataV3 や assortmentStoreId のようなCookieで制御されています。適切なCookieがないと、「全国共通のデフォルト」データが返ります。一見すると完全に見えても、実際の購入者が見る内容とは一致しません。Cookie不足はブロックページを返すのではなく、見た目上は正常で、しかも間違っているデータを返すため、むしろ厄介です。
Walmartからデータを抽出する3つの方法(比較つき)
手順に入る前に、主要な3つの抽出方法を見ておきましょう。競合のチュートリアルの多くは1つか2つしか扱っていません。ここでは3つすべてを説明するので、自分の状況に合うものを選べます。
| 方法 | 信頼性 | データの完全性 | ボット対策の難易度 | 保守負担 |
|---|---|---|---|---|
| HTML + BeautifulSoup | ⚠️ 低い(デプロイのたびにセレクタが壊れる) | 中程度 | 高い | 高い |
__NEXT_DATA__ JSON | ✅ 良い | 高い | 中〜高 | 中程度 |
| 内部APIのインターセプト | ✅ 最良 | 最高(バリエーション、在庫、レビュー) | 中〜高 | 低い(構造化JSON) |
| Thunderbit(ノーコード) | ✅ 良い | 高い | 低い(AIが処理) | なし |
HTML解析はWalmartにとって最悪の選択肢です。このサイトはNext.jsのバンドルを配信しており、ハッシュ化されたCSSクラス名がデプロイのたびに変わります。__NEXT_DATA__ JSON方式は、2024〜2026年の本格的なオープンソースWalmartスクレイパーが採用している実用的な方法です。内部APIのインターセプトは最も強力ですが、多くのチュートリアルが軽く流している注意点があります。そしてThunderbitは、カスタムパイプラインが不要なら最適な選択肢です。
Python環境を整えてWalmartをスクレイピングする
必要なものは次のとおりです。
- 難易度: 中級
- 所要時間: セットアップに約30分、加えてコーディング時間
- 必要なもの: Python 3.10以上、pip、コードエディタ、そして本番運用ではプロキシサービスまたはスクレイピングAPI
プロジェクトフォルダと仮想環境を作成します。
1mkdir walmart-scraper && cd walmart-scraper
2python -m venv venv
3source venv/bin/activate # Windowsの場合: venv\Scripts\activate必要なライブラリをインストールします。
1pip install curl_cffi parsel beautifulsoup4 lxmlcurl_cffi は、2025年時点で難易度の高い対象をスクレイピングするための標準です。これは、ブラウザのTLSフィンガープリントを正確に偽装できるlibcurlバインディングです。によると、「Walmartはボット検知の一部としてTLSフィンガープリントを使用しており、User-Agentを実ブラウザ風にしても回避できない。」単なるrequestsやhttpxでは、どんなヘッダーを付けてもAkamaiを通過できません。impersonate="chrome124" を指定したcurl_cffiが決定打になります。
このあと扱う本番向けのパターンのために、json(標準)、csv(標準)、time、random、loggingも使います。
手順で学ぶ:PythonでWalmartの商品ページをスクレイピングする
ステップ1:Walmartの商品ページを取得する
最初の仕事は、即座にブロックされないHTTPリクエストを送ることです。2024〜2026年にScrapfly、Scrapingdog、Oxylabs、ScrapeOpsで共通して使われている標準的なヘッダーセットは次のとおりです。
1from curl_cffi import requests
2HEADERS = {
3 "User-Agent": (
4 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
5 "AppleWebKit/537.36 (KHTML, like Gecko) "
6 "Chrome/124.0.0.0 Safari/537.36"
7 ),
8 "Accept": (
9 "text/html,application/xhtml+xml,application/xml;q=0.9,"
10 "image/avif,image/webp,*/*;q=0.8"
11 ),
12 "Accept-Language": "en-US,en;q=0.9",
13 "Accept-Encoding": "gzip, deflate, br",
14 "Upgrade-Insecure-Requests": "1",
15 "Sec-Fetch-Dest": "document",
16 "Sec-Fetch-Mode": "navigate",
17 "Sec-Fetch-Site": "none",
18 "Sec-Fetch-User": "?1",
19 "Referer": "https://www.google.com/",
20}
21session = requests.Session(impersonate="chrome124")
22url = "https://www.walmart.com/ip/Apple-AirPods-Pro-2nd-Generation/1752657021"
23response = session.get(url, headers=HEADERS)ここで重い役割を担っているのが impersonate="chrome124" です。これにより、curl_cffi はChrome 124の正確なTLS ClientHello、HTTP/2のフレーム順序、擬似ヘッダー順を再現します。これがないと、AkamaiはPython特有のJA3ハッシュを検知し、Walmartのアプリケーション層に届く前にブロックします。
ブロックされたレスポンスの見分け方: レスポンスHTMLのタイトルに "Robot or human?" が含まれる、または walmart.com/blocked にリダイレクトされるなら、検知されています。厄介なのは、Walmartが200ステータスでCAPTCHA本文を返すことが多い点です。つまり、response.ok だけを見ても足りません。
本番運用や繰り返し利用では、住宅IPプロキシが必要です。データセンターIPはAkamaiのIPレピュテーションで即座に焼かれます。完全なエラーハンドリングとプロキシ戦略は、後半の本番向けセクションで扱います。
ステップ2:__NEXT_DATA__ JSONから商品データを解析する
Walmart.comはNext.jsアプリケーションで、サーバーレンダリングされたHTMLの中に、単一のscriptタグとして完全なハイドレーションペイロードを埋め込んでいます。<script id="__NEXT_DATA__" type="application/json"> です。ここが宝の山です。
でも、「2026年のWalmartはNext.jsを使い、__NEXT_DATA__のscriptタグ内に構造化JSONを持っているため、隠しデータの抽出は従来のCSSセレクタ解析より信頼性が高い」と確認されています。注目度の高いオープンソースWalmartスクレイパーはすべて、、、を含め、この方法を使っています。
抽出方法は次のとおりです。
1import json
2from parsel import Selector
3sel = Selector(text=response.text)
4raw = sel.xpath('//script[@id="__NEXT_DATA__"]/text()').get()
5data = json.loads(raw)
6product = data["props"]["pageProps"]["initialData"]["data"]["product"]
7idml = data["props"]["pageProps"]["initialData"]["data"].get("idml", {})多くのチュートリアルはここで終わります。以下は、実際に必要な項目についての完全なJSONパスマップです。2024〜2026年のライブWalmartページで確認済みです。
| データ項目 | JSONパス(initialData 配下) | 型 | 備考 |
|---|---|---|---|
| 商品名 | data > product > name | 文字列 | — |
| ブランド | data > product > brand | 文字列 | — |
| 現在価格(数値) | data > product > priceInfo > currentPrice > price | 浮動小数点数 | 店舗Cookieで変わる場合あり |
| 現在価格(文字列) | data > product > priceInfo > currentPrice > priceString | 文字列 | 例: "$9.99" |
| 短い説明 | data > product > shortDescription | HTML文字列 | テキスト化するならBeautifulSoupで解析 |
| 長い説明 | data > idml > longDescription | HTML文字列 | product ではなく idml にある — 古いチュートリアルがよく間違える罠 |
| すべての画像 | data > product > imageInfo > allImages | 配列 | {id, url} オブジェクトの一覧 |
| 平均評価 | data > product > averageRating | 浮動小数点数 | キーは旧式の rating ではなく averageRating |
| レビュー数 | data > product > numberOfReviews | 整数 | — |
| バリエーション | data > product > variantCriteria | 配列 | サイズ、色などの選択肢グループ |
| 在庫状況 | data > product > availabilityStatus | 文字列 | IN_STOCK、OUT_OF_STOCK、LIMITED_STOCK |
| 販売者 | data > product > sellerDisplayName | 文字列 | — |
| 製造元 | data > product > manufacturerName | 文字列 | — |
longDescription のパスは、特に引っかかりやすい部分です。2023年のScrapeHeroの投稿では product.longDescription に置かれていましたが、2024年以降のソースでは一貫して兄弟キーの idml にあります。必ず idml.longDescription を先に読み、古いページ向けのフォールバックとして product.longDescription を使ってください。
.get() をつないで安全に抽出するパターンは次のとおりです。
1def extract_product(data):
2 product = data["props"]["pageProps"]["initialData"]["data"]["product"]
3 idml = data["props"]["pageProps"]["initialData"]["data"].get("idml", {})
4 price_info = product.get("priceInfo", {})
5 current_price = price_info.get("currentPrice", {})
6 image_info = product.get("imageInfo", {})
7 return {
8 "name": product.get("name"),
9 "brand": product.get("brand"),
10 "price": current_price.get("price"),
11 "price_string": current_price.get("priceString"),
12 "short_desc": product.get("shortDescription"),
13 "long_desc": idml.get("longDescription", product.get("longDescription")),
14 "images": [img.get("url") for img in image_info.get("allImages", [])],
15 "rating": product.get("averageRating"),
16 "review_count": product.get("numberOfReviews"),
17 "variants": product.get("variantCriteria"),
18 "availability": product.get("availabilityStatus"),
19 "seller": product.get("sellerDisplayName"),
20 "manufacturer": product.get("manufacturerName"),
21 }JSONパスの扱いを一切考えたくない人には、がこれらの項目を自動で見つけて構造化してくれます。手作業でパスを整理する必要はありません。「AIで列を提案」をクリックすれば、ページを読み取り、表が生成されます。ただし、カスタムパイプラインを組むなら、上のマップが基準になります。
ステップ3:Walmartの内部APIエンドポイントを傍受して、より豊富なデータを取る
この方法をきちんと扱っている競合記事はほとんどありません。最も強力な抽出手段ですが、同時に最も複雑でもあります。
Walmartのフロントエンドは、を呼び出しています。エンドポイントは www.walmart.com/orchestra/* 配下にあります。
/orchestra/pdp/graphql/...— 商品詳細のハイドレーションとバリエーション切り替え/orchestra/snb/graphql/...— 検索・閲覧のページネーション/orchestra/reviews/graphql/...— ページネーション付きレビュー
これらは、__NEXT_DATA__ では時に省略されるデータ、たとえばバリエーション単位の価格、リアルタイム在庫数、レビューの全ページなどを含む、きれいで構造化されたJSONを返します。
多くのブログ記事が濁す点: Walmartはを使っています。リクエスト本文にはクエリ文字列ではなく、SHA-256ハッシュ(persistedQuery.sha256Hash)だけが送られます。そのハッシュがサーバーに未知なら、PersistedQueryNotFound が返ります。Walmartはデプロイのたびにこのハッシュをローテーションします。これが、注目度の高いオープンソースWalmartスクレイパーのどれも、コピペ可能な /orchestra/ コードを公開していない理由です。
実務的で正直なやり方は、DevToolsを使った調査です。
- ChromeでWalmartの商品ページを開く
- DevToolsを開き、Networkタブで「Fetch/XHR」に絞る
- 通常どおりページを操作する — バリエーションをクリックし、レビューまでスクロールし、店舗を変更する
- 商品データを返す
/orchestra/*エンドポイントへのリクエストを探す - 該当リクエストを右クリックして「Copy as cURL」
- そのcURLを
curl_cffiでPythonに変換する
再生したAPI呼び出しは、次のようになります。
1import json
2from curl_cffi import requests
3session = requests.Session(impersonate="chrome124")
4# まず商品ページを訪問してセッションを温める
5session.get("https://www.walmart.com/ip/some-product/1234567", headers=HEADERS)
6# その後、内部API呼び出しを再生する(DevToolsからコピーしたもの)
7api_url = "https://www.walmart.com/orchestra/pdp/graphql"
8api_headers = {
9 **HEADERS,
10 "accept": "application/json",
11 "content-type": "application/json",
12 "referer": "https://www.walmart.com/ip/some-product/1234567",
13 "wm_qos.correlation_id": "コピーしたcorrelation_id",
14}
15payload = {
16 # DevToolsから取得した正確なリクエスト本文を貼り付ける
17 "variables": {"productId": "1234567"},
18 "extensions": {
19 "persistedQuery": {
20 "version": 1,
21 "sha256Hash": "コピーしたハッシュ"
22 }
23 }
24}
25api_response = session.post(api_url, headers=api_headers, json=payload)
26api_data = api_response.json()セッションを温める手順は非常に重要です。WalmartのPerimeterX Cookie(_px3、_pxhd、ACID)は、最初のHTML取得でセットされていなければ、API呼び出しは成功しません。これがないと、412または403になります。
この方法を使うべき場面: __NEXT_DATA__ に含まれないデータ、たとえば深い階層のバリエーション価格、最初のバッチを超えるページネーション付きレビュー、リアルタイム在庫数が必要なときです。多くの用途では、__NEXT_DATA__ で十分であり、はるかに簡単です。
Walmartの検索結果と複数ページをスクレイピングする
検索結果も同様に __NEXT_DATA__ パターンですが、JSONパスは少し違います。
1search_url = "https://www.walmart.com/search?q=laptops&page=1"
2response = session.get(search_url, headers=HEADERS)
3sel = Selector(text=response.text)
4raw = sel.xpath('//script[@id="__NEXT_DATA__"]/text()').get()
5data = json.loads(raw)
6search_result = data["props"]["pageProps"]["initialData"]["searchResult"]
7items = search_result["itemStacks"][0]["items"]
8# スポンサード商品を除外する
9organic_items = [i for i in items if i.get("__typename") == "Product"]
10for item in organic_items:
11 print(item.get("name"), item.get("priceInfo", {}).get("currentPrice", {}).get("price"))ページネーションは page パラメータを増やしていく形です。&page=1、&page=2 という具合です。ただし、文書化されていない上限があります。Walmartは、実際の総件数に関係なく検索結果を25ページまでに制限しています。 。「Walmartは、利用可能な総ページ数に関係なく、アクセス可能な結果ページ数の上限を25に設定している。」
より深く取得するための回避策は次のとおりです。
- 並び順の切り替え: 同じ検索クエリを
&sort=price_low、次に&sort=price_highで実行し、約50ページ分をカバーする - 価格帯で分割:
&min_price=X&max_price=Yを追加してカタログを小さな範囲に分ける - カテゴリで分割: サイト全体ではなく、特定カテゴリ内で検索する
itemStacks が配列である点にも注意してください。Scrapflyのリポジトリは [0] を固定で使っていますが、カテゴリページや閲覧ページには複数のスタック(「Top picks」「More results」など)が含まれることがあります。堅牢なパターンは、すべてのスタックを回すことです。
1for stack in search_result.get("itemStacks", []):
2 for item in stack.get("items", []):
3 if item.get("__typename") == "Product":
4 # item を処理する
5 passあわせて重要なのは、Walmartのrobots.txtがことです。商品詳細ページ(/ip/...)や多くのカテゴリページ(/cp/...)は禁止されていません。コンプライアンスが気になるなら、検索よりもまず商品ページやカテゴリツリーから始めましょう。
サイレントブロックにデータを壊させない:本番向けエラーハンドリング
多くのチュートリアルはここで崩れます。1ページ取得し、1商品を解析して終わり、という内容がほとんどです。本番では何千ページも取得しますし、Walmartは積極的に止めにきます。デモ用スクレイパーと実運用で動くスクレイパーの違いは、失敗をどう扱うかです。
サイレントブロックがデータを汚染する前に検知する
Walmartスクレイパーで最も重要な関数は、ブロック検知です。、、、 の各社の知見を総合すると、独立した4つのチェックが必要です。
1BLOCK_MARKERS = (
2 "Robot or human",
3 "Press & Hold",
4 "Press & Hold",
5 "px-captcha",
6 "perimeterx",
7)
8def is_walmart_blocked(response) -> bool:
9 # 1. 専用ブロック先へのリダイレクト
10 if "/blocked" in str(response.url):
11 return True
12 # 2. 明確なステータスコード
13 if response.status_code in (403, 412, 428, 429, 503):
14 return True
15 # 3. 200 OKだがCAPTCHA本文のケース(サイレントブロック)
16 body = response.text or ""
17 if any(m.lower() in body.lower() for m in BLOCK_MARKERS):
18 return True
19 # 4. レスポンス長の健全性 — 正常なPDPは300〜900KB程度
20 if len(response.content) < 50_000 and "/ip/" in str(response.url):
21 return True
22 return False4つ目のチェックであるレスポンス長は、明らかなCAPTCHA文言はないのに、必要な商品データも入っていない、というケースを拾えます。
指数バックオフとジッターを使った再試行ロジック
リクエストが失敗したときに、すぐWalmartを連打したくはありません。定番の方法は、再試行をずらすために指数バックオフにジッターを加えることです。
1import time
2import random
3import logging
4from curl_cffi import requests as cffi_requests
5log = logging.getLogger("walmart")
6def fetch_with_retry(session, url, max_retries=5, base_delay=2, max_delay=60):
7 for attempt in range(max_retries):
8 try:
9 response = session.get(url, headers=HEADERS, timeout=15)
10 if response.status_code in (429, 503):
11 raise Exception(f"Throttled: \{response.status_code\}")
12 if is_walmart_blocked(response):
13 raise Exception("Silent block detected")
14 return response
15 except Exception as e:
16 if attempt == max_retries - 1:
17 raise
18 wait = min(max_delay, base_delay * (2 ** attempt)) + random.uniform(0, 3)
19 log.warning(f"Attempt {attempt + 1} failed: \{e\}. Retrying in {wait:.1f}s")
20 time.sleep(wait)
21 return Noneジッター(random.uniform(0, 3))は飾りではありません。複数のスクレイパーが同じ秒に再試行してAkamaiの速度検知に引っかかるのを防ぎます。
レート制限
とは、Walmartに対して1リクエストあたり3〜6秒のランダム遅延という点で一致しています。「ページ読み込みの間隔を3〜6秒空け、遅延をランダム化せよ。」ということです。
1import time
2import random
3def rate_limited_fetch(session, url):
4 response = fetch_with_retry(session, url)
5 time.sleep(random.uniform(3.0, 6.0))
6 return response大規模運用では、非同期レート制限に aiolimiter を検討してください。
1from aiolimiter import AsyncLimiter
2limiter = AsyncLimiter(max_rate=10, time_period=60) # 1分あたり10リクエストデータ検証
レスポンスがブロックされていなくても、解析結果が間違っていることがあります(店舗違い、劣化したペイロードなど)。出力に書き込む前に検証してください。
1def validate_product(product):
2 """商品データが妥当ならTrueを返す。"""
3 if not product.get("name"):
4 return False
5 price = (product.get("priceInfo") or {}).get("currentPrice", {}).get("price")
6 if not isinstance(price, (int, float)) or price <= 0:
7 return False
8 if product.get("availabilityStatus") not in ("IN_STOCK", "OUT_OF_STOCK", "LIMITED_STOCK"):
9 return False
10 return Trueセッションログ
セッションごとの成功率を追跡してください。10分間で80%を下回ったら、何かが変わったサインです。IPが焼かれたか、Cookieが切れたか、Walmartが新しいボット対策を導入した可能性があります。
1class ScrapeMetrics:
2 def __init__(self):
3 self.total = 0
4 self.success = 0
5 self.blocks = 0
6 self.errors = 0
7 def record(self, result):
8 self.total += 1
9 if result == "success":
10 self.success += 1
11 elif result == "blocked":
12 self.blocks += 1
13 else:
14 self.errors += 1
15 @property
16 def success_rate(self):
17 return (self.success / self.total * 100) if self.total > 0 else 0
18 def check_health(self):
19 if self.total > 20 and self.success_rate < 80:
20 log.critical(f"Success rate dropped to {self.success_rate:.1f}% — consider rotating proxies or pausing")派手さはありません。でも、データをきれいに保つには必要です。
自作Python vs. スクレイピングAPI vs. ノーコード:Walmartをスクレイピングする最適な方法を選ぶ
多くの開発者は、そもそもそれが正しい選択かを考えずに、いきなりカスタムスクレイパーを書き始めます。しています。フォーラムの利用者も「基本9/10」と表現し、「専用のWebスクレイピングAPIは大げさではないか」と悩んでいます。答えは、件数、予算、エンジニアリング余力によって変わります。
| 要素 | 自作Python(requests + プロキシ) | スクレイピングAPI(Oxylabs、Bright Dataなど) | ノーコードツール(Thunderbit) |
|---|---|---|---|
| 最初の1行までのセットアップ時間 | 数時間 | 15〜60分 | 約2分 |
| 本番投入までのセットアップ時間 | 40〜80時間 | 4〜16時間 | 約30分 |
| ボット対策対応 | 自分で対応(難しい) | ベンダーが対応 | 自動対応 |
| 小規模時のコスト(月1,000ページ未満) | 低い(プロキシ代は約4〜8ドル/GB) | 月額40〜49ドルの入門プラン | 無料〜月15ドル |
| 大規模時のコスト(月10万ページ以上) | リクエスト単価は低め | リクエスト単価は高め | 変動 |
| カスタマイズ性 | 完全自由 | APIパラメータ次第 | UI/列に制約あり |
| 継続保守 | 月4〜8時間 | ほぼゼロ | なし(AIが適応) |
| 最適な用途 | 独自パイプラインを作る開発者 | 中規模の本番スクレイピング | ビジネスユーザー、単発の素早い抽出 |
自作Pythonが向いているケース
自作が勝つのは、すでにプロキシ契約を持っている、ヘッダーや郵便番号ターゲティング、販売者セグメントを厳密に制御したい、月間数百万ページを索引化しておりAPIの従量課金が積み上がる、オンプレミスやコンプライアンス保証が必要、といった場合です。代償は明確な工数です。ページネーション、再試行、プロキシローテーション、TLS偽装、複数のページタイプのスキーマ対応を備えた本番レベルのScrapyスパイダーには、に加え、Walmartがフィンガープリントを更新するたびに月4〜8時間の保守が必要です。
スクレイピングAPIが時間を節約してくれるケース
スクレイピングAPIはボット対策層を代わりに処理してくれます。では、Walmartに対して 、**Scrape.doが98%**の成功率を示しています。 、、 のようなツールは、入門プランが月40〜49ドルです。2〜5人規模のエンジニアチームで、月1万〜100万ページを扱うなら、APIがほぼ常に正解です。リクエスト単価と引き換えに、保守がほぼゼロになります。
ノーコードが正しい選択になるケース
は、まったく別の利用者像に向いています。PM、アナリスト、EC運営担当で、「次のスプリント」ではなく「今日の午後」にWalmartの商品データをスプレッドシートで欲しいなら、ノーコードツールが率直な答えです。
使い方はこうです。を入れ、Walmartの商品ページまたは検索ページを開き、「AIで列を提案」をクリックします。するとThunderbitのAIがページを読み取り、列(商品名、価格、評価など)を提案します。「スクレイピング」をクリックすると、データが表に埋まります。Excel、Google Sheets、Airtable、Notionへエクスポートでき、すべて無料です。
Thunderbitはクラウド側でボット対策を処理するため、CAPTCHA、プロキシ、TLSフィンガープリントを気にする必要がありません。レイアウト変更にもAIが自動で適応するので、保守も不要です。JSONパスの扱いを一切したくない人にとっては、これが最も楽な道です。
正直な制約もあります。Thunderbitは1日10万ページ超の運用向けには作られていません。クレジット予算とクラウド上限のため、大量取り込みでは生のAPIより非経済的です。対応していない場合は、特定の郵便番号やASNを固定することもできません。継続的な大規模パイプラインなら、やはり自作かスクレイピングAPIが適しています。
ざっくりした価格感: ThunderbitでWalmartの商品行を1,000件取得するには、約2,000クレジット(Starter/Proプランでおよそ0.60〜1.10ドル)です。これはOxylabsのWalmart APIと同程度で、少量利用なら多くの趣味レベルのスクレイピングAPIより安いです。最新情報はをご確認ください。
抽出したWalmartデータを書き出す
データを取ったら、使いやすい場所に置く必要があります。多くの用途は次の3形式で足ります。
CSV — アナリストが実際に開く、最も汎用的な形式です。
1import csv
2def export_csv(products, filename="walmart_products.csv"):
3 fieldnames = ["name", "price", "availability", "rating", "review_count", "seller", "url"]
4 with open(filename, "w", newline="", encoding="utf-8-sig") as f:
5 writer = csv.DictWriter(f, fieldnames=fieldnames, quoting=csv.QUOTE_MINIMAL)
6 writer.writeheader()
7 for p in products:
8 writer.writerow({k: p.get(k) for k in fieldnames})Excel互換のために utf-8-sig を使ってください。BOMマーカーがあると、Excelが特殊文字を崩しにくくなります。
JSONL — スクレイピングパイプライン向けの本番形式です。
1import json
2import gzip
3def export_jsonl(products, filename="walmart_products.jsonl.gz"):
4 with gzip.open(filename, "at", encoding="utf-8") as f:
5 for p in products:
6 f.write(json.dumps(p, ensure_ascii=False) + "\n")(途中で止まっても失うのは最後の1行だけ)、一定メモリでストリーミングでき、バリエーションやレビューのようなネストしたデータもそのまま保持できます。
Excel — 単発の引き継ぎ向けです。
1from openpyxl import Workbook
2def export_excel(products, filename="walmart_products.xlsx"):
3 wb = Workbook(write_only=True)
4 ws = wb.create_sheet("Products")
5 ws.append(["Name", "Price", "Availability", "Rating", "Reviews", "Seller"])
6 for p in products:
7 ws.append([p.get("name"), p.get("price"), p.get("availability"),
8 p.get("rating"), p.get("review_count"), p.get("seller")])
9 wb.save(filename)Thunderbitは、Pythonを使わない人向けの書き出しもカバーしています。Google Sheets、Airtable、Notion、Excel、CSV、JSONへのワンクリックエクスポートがあり、ベースプランではすべて無料です。継続監視では、Thunderbitのスケジュール済みスクレイパー機能で定期抽出を自動実行できます。
スケジューリングに関する注意点として、。GitHub ActionsのランナーはAzureのIP帯域にあり、Walmartのボット対策に即座にブロックされます。VPS上でAPSchedulerを使うか、すべてのトラフィックを住宅プロキシ経由にしてください。
Walmartスクレイピングの法的・倫理的ガイドライン
フォーラムの利用者も、こうした懸念をはっきり口にしています。「開発者といたちごっこをするのは構わないが、法務チームと遊ぶのは避けたい。」
Walmartの利用規約は、「事前の書面による明示的な同意」なしに、いかなるロボット、スパイダー、その他の手動・自動デバイスを使って「資料を取得、索引化、『スクレイプ』、『データマイニング』、またはその他の方法で収集すること」を禁じています。
Walmartのrobots.txtは、/search、/account、/api/、そして多数の内部エンドポイントをしています。商品詳細ページ(/ip/...)とレビュー(/reviews/product/)は禁止されていません。
hiQ対LinkedIn判決(第9巡回、)は、一般公開データのスクレイピングが連邦CFAAに違反する可能性は低いとしました。ただし同じ裁判では、その後と判断され、が出ています。さらに2024年のより新しい判断(、)では、CFAAの適用はさらに狭められ、著作権による先占の抗弁も生まれましたが、これらはWalmartにそのまま当てはまるわけではない、個別の利用規約文言に依存した判断でした。
実務上の指針: サーバーに負荷をかけすぎない。レート制限を守る。個人情報やユーザーデータはスクレイプしない。データは責任を持って使う。公開されているWalmartの商品ページを個人研究の範囲で適度な速度でスクレイプするのと、Walmartの利用規約に反して商用規模で抽出するのとでは、リスクは大きく異なります。Walmartデータを使った製品を作るなら、弁護士に相談し、Walmartの公式なも確認してください。
免責事項: これは教育目的の情報であり、法的助言ではありません。
まとめと重要ポイント
WalmartをPythonでスクレイピングするのは、二重のAkamai + PerimeterXボット対策スタックのせいで、です。不可能ではありませんが、適切なツールとパターンが必要です。
重要ポイント:
__NEXT_DATA__JSON抽出が、ほとんどの用途で最も実用的な選択です。2024〜2026年の本格的なオープンソースWalmartスクレイパーはすべてこれを使っています。基本パスは、PDPではprops.pageProps.initialData.data.product、検索・閲覧ではsearchResult.itemStacksです。impersonate="chrome124"を指定したcurl_cffiは必須です。通常のrequestsやhttpxでは、ヘッダーを工夫してもAkamaiのTLSフィンガープリントを通過できません。- 本当に危険なのはサイレントブロックです。WalmartはCAPTCHA本文つきで200 OKを返します。ステータスコードだけでなく、レスポンス本文を確認してください。
- 本番スクレイパーには、うまくいくときだけのコード以上のものが必要です。指数バックオフとジッター、4つのシグナルによるブロック検知、1リクエストあたり3〜6秒のレート制限、データ検証、セッションの健全性監視はすべて必須です。
/orchestra/*経由の内部APIのインターセプトは強力ですが壊れやすいです。主な抽出方法ではなく、特定データが必要なときのDevTools調査として使ってください。- Walmartは検索結果を25ページで打ち切ります。 並び順の切り替えや価格帯分割で広くカバーしましょう。
- 正直に手法を選びましょう: 独自要件と大量処理がある開発者には自作Python。スクレイピング専任エンジニアがいない中規模チームにはスクレイピングAPI。今日の午後にGoogle Sheetsでデータが欲しいビジネスユーザーにはです。
ノーコードで試したいなら、には無料プランがあるので、Walmartのページを数件スクレイプして結果を自分で確認できます。Pythonで進めるなら、この記事のコードパターンは本番で検証済みです。どちらを選んでも、Walmartの防御と、その突破ルートが3通りあることがわかったはずです。
Webスクレイピングの手法についてさらに学ぶなら、、、のガイドもぜひご覧ください。ではチュートリアル動画も公開しています。
FAQ
Walmartの商品データをスクレイピングするのは合法ですか?
Walmartの利用規約では、書面による同意なしの自動スクレイピングを禁じています。第9巡回区の hiQ対LinkedIn 判決(2022年)は、公開ページのスクレイピングには連邦CFAAが適用されにくいことを示しましたが、同じ事件は最終的にスクレイパー側に対するで終わっています。個人研究のために公開商品ページを控えめな速度でスクレイプするのと、商用規模で抽出するのとでは、リスクの大きさがまったく違います。Walmartデータを使って事業を作るなら、弁護士に相談してください。
なぜWalmartスクレイパーはブロックされ続けるのですか?
よくある原因は、通常のrequestsやhttpxを使っていること(Akamaiが即座に検知するPython特有のTLSフィンガープリントを出す)、ヘッダーの不足または誤り、プロキシのローテーションがないこと、1ページあたり3〜6秒より速いリクエスト、セッションCookie(_px3、_abck、locDataV3)の不足です。impersonate="chrome124" を指定した curl_cffi に切り替え、住宅プロキシを使い、この記事で説明したブロック検知と再試行パターンを実装してください。
PythonでWalmartからどんなデータを取れますか?
商品名、価格(現在価格と値下げ前価格)、画像、短い説明と長い説明、評価、レビュー数、在庫状況、販売者名、製造元情報、バリエーション選択肢(サイズ、色)、カテゴリ上の位置づけです。__NEXT_DATA__方式なら、これらはすべて構造化JSONとして取得できます。内部APIのインターセプトを使えば、さらにバリエーション単位の価格、リアルタイム在庫数、ページネーション付きレビューも取得できます。
Walmartをスクレイピングするのにプロキシは必要ですか?
はい、本番や繰り返し利用では必要です。。ヘッダーを完璧にしても、住宅系でないIPはAkamaiのIPレピュテーションで弾かれます。住宅プロキシまたはモバイルプロキシが必要です。データセンターIPはほぼ即座に使えなくなります。プロバイダとプランにもよりますが、1,000ページあたりおよそ3〜17ドルを見込んでください。
コードを書かずにWalmartをスクレイピングできますか?
はい。はAI搭載のChrome拡張機能で、2クリックでWalmartをスクレイピングします。「AIで列を提案」で商品データ列を自動検出し、「スクレイピング」でデータを抽出します。ボット対策はクラウド側で処理され、Excel、Google Sheets、Airtable、Notionへ直接エクスポートできます。すべて無料です。独自パイプラインを作らず、すぐデータが必要なアナリスト、PM、ビジネスユーザーに最適です。大量・高度にカスタマイズしたスクレイピングには、やはりPythonかスクレイピングAPIが向いています。
詳しくはこちら