Redfinは、新しくMLSに掲載された米国の物件のしています。不動産データのパイプラインを作る人にとって、これくらい鮮度の高いデータはかなり魅力的です。だからこそ、多くのスクレイパーがRedfinを狙って、あっという間にブロックされてしまうんです。
私はで長年データ抽出ツールの開発に携わってきましたが、「Redfinをスクレイピングする」と「ブロックされずにRedfinをスクレイピングする」の間にはかなり大きな壁があります。そして、ほとんどの解説記事はそこでつまずきます。BeautifulSoupのコードは載っていても、Cloudflareにリクエストを弾かれる場面は飛ばされ、403ページを前に何が起きたのか分からないまま終わってしまうんです。このガイドは違います。HTMLパース、Redfinの隠しAPI、そしてThunderbitを使ったノーコードの方法という3つの実践的なアプローチを紹介し、特に大事なボット対策をしっかり掘り下げます。読み終えるころには、自分のスキル、規模、そしてメンテナンス負荷への許容度に応じて、どの方法が最適かがはっきり分かるはずです。
Redfinとは何か? なぜそのデータが重要なのか?
Redfinは、給与制のエージェントがMLSのフィードから直接物件情報を取り込む、テクノロジー主導の不動産仲介サービスです。し、月間約5,000万人の訪問者に利用されています。単なる集約型ポータルとは違って、Redfinのデータはエージェントによって検証されており、独自のRedfin Estimate AVMはをカバーし、市場掲載中物件の中央値誤差はわずか1.96%です。
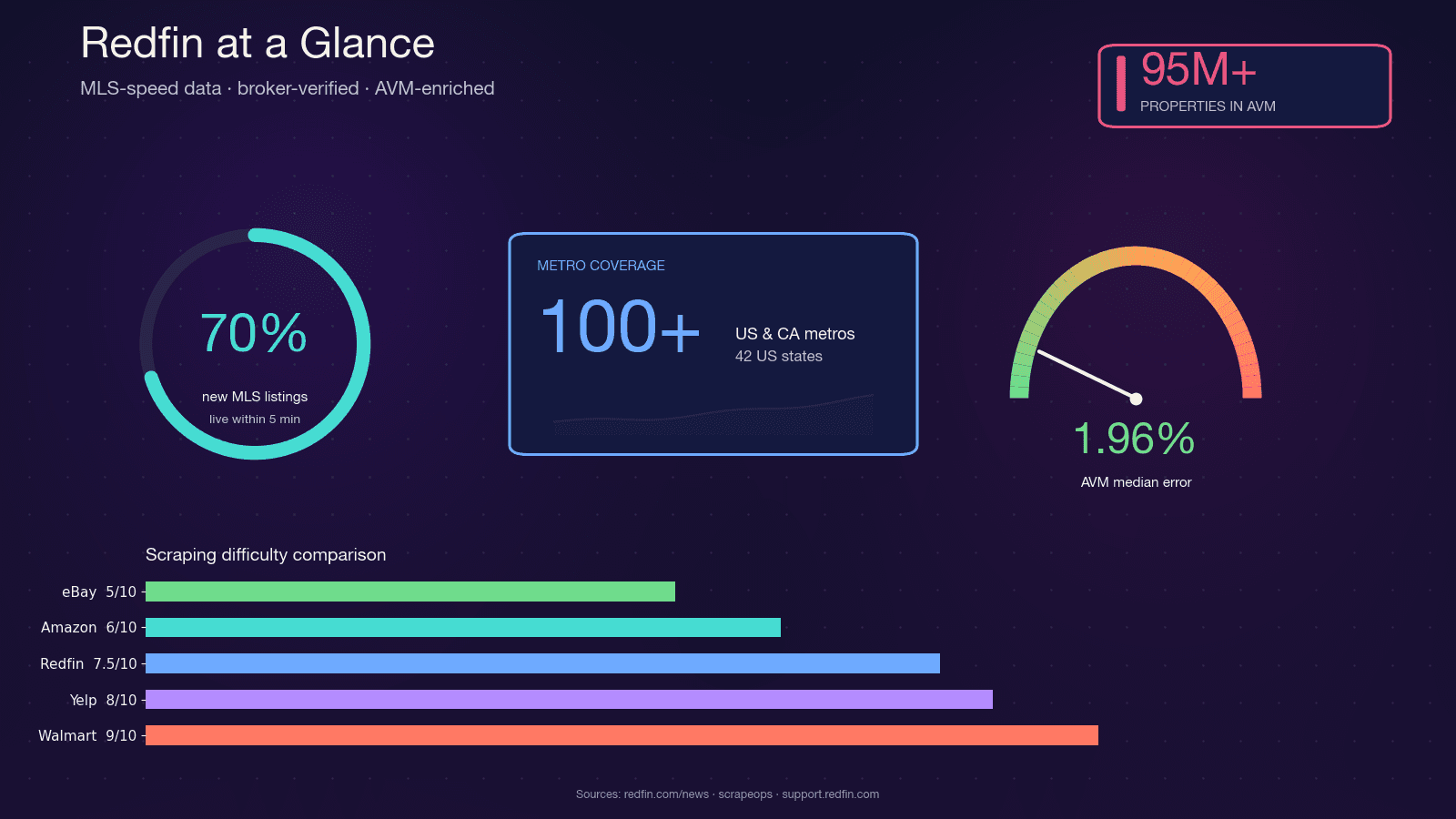
この「MLS並みの鮮度」「仲介会社による検証品質」「精度の高いAVM」という組み合わせがあるからこそ、不動産投資家、エージェント、PropTechスタートアップ、データアナリストがみんなRedfinデータへのプログラム的アクセスを求めるわけです。この用途でPythonがよく選ばれるのも自然な流れです。requests、BeautifulSoup、Selenium、Playwrightといったスクレイピング周辺のエコシステムが成熟していて、コミュニティの支援も豊富だし、pandasやJupyterとつなげて分析しやすいからです。
なぜPythonでRedfinをスクレイピングするのか?
使い道は、データを必要とする人の数だけあります。Redfinのスクレイピングデータは、典型的には次のように活用されます。
| 対象 | 主な目的 | 利用例 |
|---|---|---|
| 不動産エージェント | リード獲得、市場動向の把握 | 担当地域の新着物件・販売期限切れ物件、競合分析のためのエージェントディレクトリ |
| 不動産投資家 | 案件発掘、キャップレート分析 | 賃貸利回りのスクリーニング、割安物件の検出、毎日の新着アラート |
| PropTechスタートアップ | プロダクト向けデータ基盤 | AVM学習データ、市場ダッシュボード、iBuyer向け取得エンジン |
| データアナリスト | 市場調査、BI | ZIPコード別の中央値価格推移、掲載日数の時系列、売値/掲載価格比率 |
| 卸売業者 / リノベ業者 | 困難物件の追跡 | 値下げ検知、差押え物件、オフマーケット比較物件 |
より大きな流れもこれを裏づけています。今ではが、機会の発見とリスク管理のために予測分析を活用しています。PropTech市場は規模に達し、年平均成長率は16.4%と予測されています。構造化された不動産データは、もはや「あると便利」ではなく、最低限必要な前提条件です。
Redfinから取得できる全データ項目一覧(完全版)
コードを書く前に、実際に何が取れるのかを把握しておく必要があります。私はRedfinの検索結果ページ、物件詳細ページ、エージェントプロフィールを調べ、さらにやといったオープンソースのStingray APIラッパーとも突き合わせました。その結果、ページ種別をまたいで合計117個の異なるフィールドがあることが分かりました。
この表はぜひブックマークしておいてください。実装前にデータスキーマを把握しておくだけで、セレクターを探し回る試行錯誤の時間を何時間も節約できます。
検索結果ページのフィールド
これは掲載カード上で見られる軽量な項目です。完全なJavaScriptレンダリングなしでも取れることが多いです。
| 項目 | データ型 | 備考 |
|---|---|---|
| 物件ID | 数値 | Redfin内部の整数。href内の/home/{id}から抽出 |
| 掲載価格 | 数値 | |
| 住所全文 | テキスト | |
| ベッド数 / バス数 / 面積 | 数値 | 3つの値が順番に並ぶ |
| 物件タイプ | 単一選択 | SFH、Condo、Townhouse、Multi など |
| ステータス | テキスト | Active、Pending、Contingent など |
| 掲載日数 | 数値 | |
| 値下げ表示 | 数値 | 当初価格との差分 |
| メイン写真 | 画像URL | 1カードにつき1枚 |
| Hot Homeバッジ | 真偽値 | |
| オープンハウス日時 | テキスト | |
| 仲介会社情報 | テキスト |
物件詳細ページのフィールド
本当に情報量が多いのは詳細ページです。多くの項目はJavaScriptレンダリング、またはStingray APIが必要になります。
| 項目 | データ型 | 備考 |
|---|---|---|
| Redfin Estimate(市場掲載中) | 数値 | /stingray/api/home/details/avm 経由 |
| Redfin Estimate(非掲載) | 数値 | /stingray/api/home/details/owner-estimate 経由。中央値誤差7.52% |
| 築年数 / リノベーション年 | 数値 | |
| 敷地面積 | 数値 | |
| HOA費 | 数値 | 月額、該当する場合 |
| 固定資産税(年額) | 数値 | |
| 課税評価額 | 数値 | |
| 売買履歴テーブル | テーブル | 価格、日付、イベント種別 |
| 物件説明文 | テキスト | マーケティング用の説明文 |
| 写真URL(カルーセル) | 画像URL群 | 1件あたり20枚以上 |
| 担当エージェント名、電話、メール | テキスト / 電話 / メール | 電話はマスクされていることが多い |
| 学校評価(小・中・高) | 数値 | 学区名も含む |
| Walk / Transit / Bikeスコア | 数値 | |
| 気候リスクスコア | 数値 | 洪水、火災、暑熱、風 |
| 類似の販売中 / 成約済み / 周辺物件 | URL群 | カルーセルデータ |
| 駐車場、ガレージ、暖房、冷房 | テキスト | 設備グループ |
エージェントプロフィールのフィールド
| 項目 | データ型 | 備考 |
|---|---|---|
| エージェント名、写真、仲介会社、プロフィール | テキスト / 画像 | |
| 電話、問い合わせフォーム | 電話 / テキスト | クリックで表示 |
| 現在の掲載件数 | 数値 | |
| 過去12か月の販売件数 / 総取引額 | 数値 | |
| 平均掲載価格/成約価格比率 | 数値 | |
| 星評価 / レビュー数 | 数値 | |
| 経験年数 / ライセンス番号 | テキスト / 数値 |
ThunderbitのRedfinページでAI Suggest Fields機能を使うと、これらの列の大半を自動検出し、正しいデータ型まで自動で割り当ててくれます。手動でCSSセレクターを対応づける必要はありません。詳しくは後ほど説明します。
Redfinのボット対策を解剖する(「プロキシを使う」だけではない)
ここはかなり大事なポイントです。多くの解説記事はブロック問題をあいまいに済ませて、「プロキシを買いましょう」で話を終わらせます。でも、それだけでは足りません。Redfinが何を見てスクレイパーを検出しているのかを理解しないままでは、プロキシ代だけが消えて、結局ブロックされたままです。と評価し、と分類しています。つまり、「ZillowのようなエンタープライズWAFほど攻撃的ではないが、独自のレート制限とJavaScriptチャレンジに依存している」ということです。
Redfinは多層構造の防御を採用しています。エッジでCloudflare(JSチャレンジ、Turnstile、TLS/JA3フィンガープリント)を使い、さらにRedfin独自のアプリケーション層レートリミッターが動いています。robots.txtにはCrawl-delayはありません。実際の制御はWAF層で行われているからです。
なぜ単純なrequests + BeautifulSoupではRedfinで失敗するのか
デフォルトのヘッダーでRedfinの物件ページにrequests.get()を投げると、典型的には次のどれかになります。
- HTTP 403 — CloudflareのJSチャレンジが解けず、掲載情報の代わりにチャレンジページが返る
- インタースティシャルのチャレンジページ — HTML本文に物件データではなくCloudflareのTurnstileウィジェットが含まれる
- HTTP 200だがHTMLが不完全 —
root.__reactServerState.InitialContext配下に大きなJSON blobはあるものの、事前描画済みの検索カードや価格履歴、学校評価はない
Redfinはを独自に使っており(Next.jsではありません)、ハイドレーションキーもRedfin固有です。root.__reactServerState.InitialContextの中にReactServerAgent.cache.dataCacheとして掲載データが入っています。これは__NEXT_DATA__でもwindow.__INITIAL_STATE__でもありません。
静かに403が返る最もよくある原因は何か? Sec-Fetch-*ヘッダーの不足です。Redfin/CloudflareはSec-Fetch-Site、Sec-Fetch-Mode、Sec-Fetch-Dest、Sec-Fetch-Userを明示的に検証しています。これらがないと、すぐにフラグが立ちます。
回避の実践ガイド:遅延、ヘッダー、プロキシ、セッション
以下に、防御ごとの対処法を整理しました。
| Redfin側の防御 | 仕組み | 検知のサイン | 回避策 |
|---|---|---|---|
| Cloudflare JSチャレンジ | cf_clearanceクッキーを発行するインタースティシャル | 403 + CloudflareのHTML本文 | impersonate="chrome120"のcurl_cffi、ホームページ経由でのセッションウォームアップ、米国の住宅回線プロキシ |
| Cloudflare Turnstile | リスクの高いセッションに表示される対話型CAPTCHA | 403 + Turnstileウィジェット | ステルス対応のヘッドレスブラウザ + 住宅回線プロキシ |
| Cloudflare Error 1020(ASN拒否) | フラグ付きIP/ASNをWAFで遮断 | 403本文に「Error 1020 Access Denied」 | 住宅回線またはモバイルプロキシへ切り替え。データセンターASNは使わない |
| TLS/JA3フィンガープリント | ブラウザ以外のTLSスタックを検出 | ヘッダーが完璧でも静かに403 | curl_cffiの偽装、または実ブラウザ |
| HTTP/2フィンガープリント | HTTP/2のSETTINGSやHPACK順序を確認 | 静かなブロック | curl_cffiでChrome同様にHTTP/2を利用 |
| ヘッダー検証(UA、Sec-Fetch-*) | ブラウザらしいヘッダー一式をチェック | 初回リクエストで403 | Sec-Fetch-Site/Mode/Dest/Userを含むChrome相当の完全なヘッダー、現実的なReferer |
| Cookie/セッション継続 | cf_clearance、RF_BROWSER_IDを追跡 | 深いURLへ直接アクセスするとチャレンジ | 永続セッション。まずホームページで慣らす |
| アプリ層のレート制限 | IP単位のリクエスト制御 | 429 | 2〜5秒の遅延 + ジッター、指数バックオフ |
| データセンターIPの評判 | 既知のDC ASNを遮断 | 即座の1020/403 | 米国の住宅回線またはモバイルプロキシのみ |
| 同時実行検出 | 1つのIPからの並列リクエストを検知 | 急にTurnstileが強化される | IPあたり同時2本以下 |
コミュニティ検証で得られた実践的な目安:
- 安全な間隔:IPあたり2〜3秒に1リクエスト
- 単一のデータセンターIPで20〜30 req/minを超えて続けると、数分以内にチャレンジが発生しやすい
- ソフトなレート制限は、通信を止めると5〜15分で解除されることが多い
- データセンターIP(AWS、GCP、Azure、OVH)のBANは数時間〜数日続く場合がある
標準のPython requests(urllib3 + OpenSSL)は、を生成するため、ヘッダーが完璧でも静かにブロックされます。業界での定番対策は、**impersonate="chrome120"付きのcurl_cffi**を使って、Chromeに近いTLS + HTTP/2を話させることです。
PythonでRedfinをスクレイピングする3つの方法(どれを選ぶべきか)
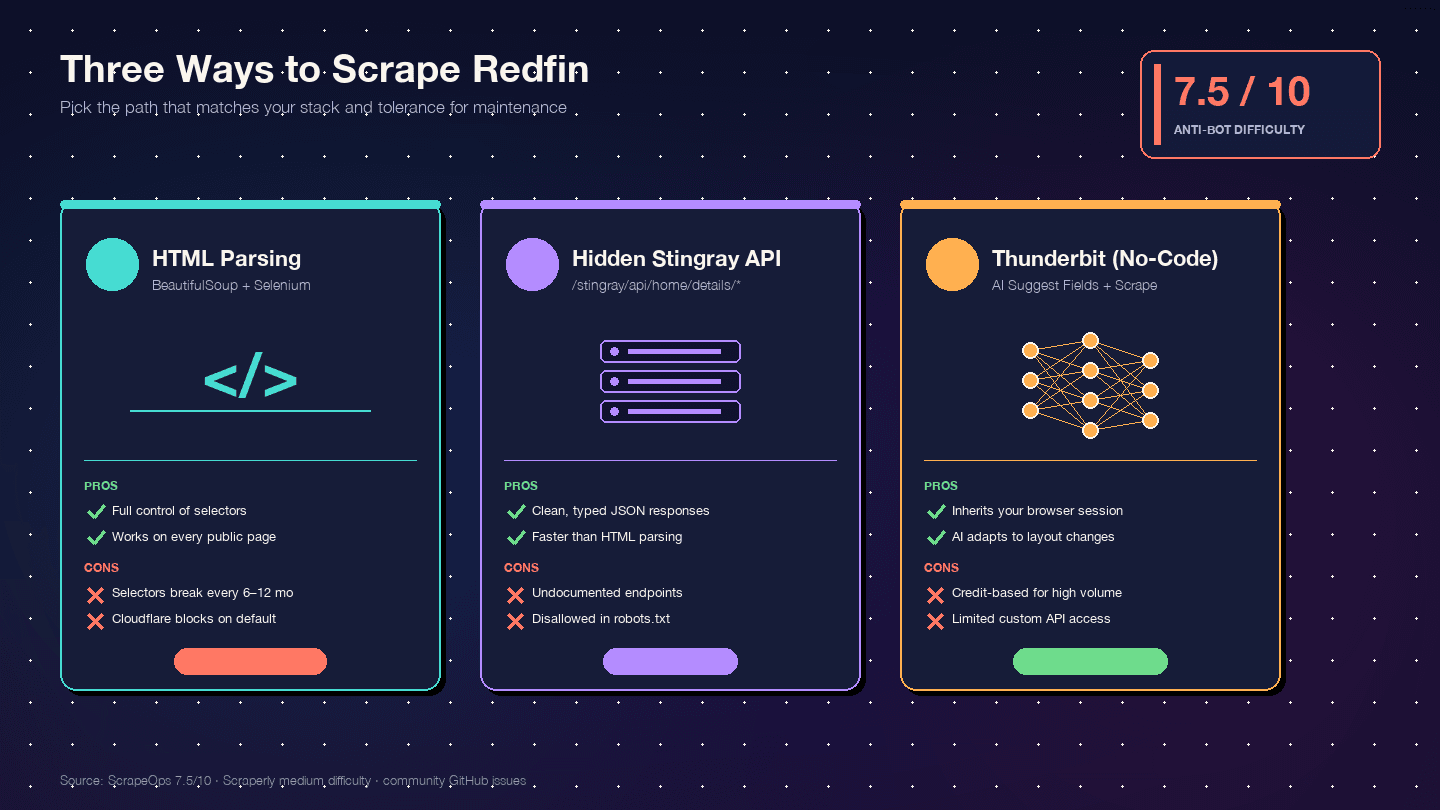
3つの方法を横並びで比べている競合記事は、私はまだ見つけていません。判断用の比較表を見てください。
| 比較項目 | HTMLパース(BS4 + Selenium) | Stingray隠しAPI | Thunderbit(ノーコード) |
|---|---|---|---|
| 初期設定の難易度 | 中(Python環境 + ブラウザドライバー) | 高(エンドポイントのリバースエンジニアリング) | 低(Chrome拡張を入れるだけ) |
| ボット対策リスク | 高(DOMへのアクセスは最も目立つ) | 中(API風リクエストは比較的自然) | 最低(実際のブラウザセッションを使う) |
| データ構造の品質 | 中(HTMLが非構造化 → 手動解析) | 非常に高い(事前構造化されたJSON) | 高い(AIがフィールドと型を自動判定) |
| メンテナンス負荷 | 高い — レイアウト変更でセレクターが壊れる | 中 — 予告なくエンドポイントが変わる可能性 | 最低 — AIがレイアウト変更に追随 |
| スケール | 小〜中規模(プロキシ使用で数百件) | 中〜大規模(数千件、よりクリーンなリクエスト) | 中規模(クラウドスクレイピングで50ページ単位) |
| 向いている人 | 完全な制御を求める開発者 | クリーンなJSONが必要な開発者 | 非エンジニア、短期案件、開発リソースなしで継続的に使いたい人 |
メンテナンスの観点は特に重要です。RedfinはカードDOMを2世代出してきました。旧版は(homecardV2Price)、現行は(span.bp-Homecard__Price--value)です。GitHubのコミュニティIssue履歴を見ると、CSSセレクターの破損はだいたい6〜12か月ごとに起きています。そうなると、BeautifulSoupのスクレイパーは一晩で壊れます。AIベースのフィールド検出なら、それに追随できます。
始める前に
- 難易度: 中級(方法1・2)、初級(方法3)
- 所要時間: 方法1・2で約30分、方法3で約5分
- 必要なもの:
- Python 3.8以上とpip(方法1・2)
- Chromeブラウザ(全方法)
- (方法3)
- 大規模スクレイピング用の米国住宅回線プロキシ(方法1・2)
方法1: HTMLパース(BeautifulSoup + Selenium)でPythonからRedfinをスクレイピングする
これは「自由度重視」の方法です。セレクターは自分で書き、ブラウザも管理し、エラー処理も自分でやります。
学びは多いですが、いちばん壊れやすい方法でもあります。
ステップ1: Python環境をセットアップする
仮想環境を作成し、必要なライブラリをインストールします。
1python -m venv redfin-scraper
2source redfin-scraper/bin/activate # Windowsでは: redfin-scraper\Scripts\activate
3pip install requests beautifulsoup4 selenium webdriver-manager pandas curl_cffiここではcurl_cffiが重要です。Cloudflareにすぐブロックされる標準のPython requestsフィンガープリントではなく、本物のChromeに近いTLSフィンガープリントとしてHTTPリクエストを偽装できるからです。
ステップ2: ブラウザのヘッダーとセッションを設定する
ここで初心者がつまずきやすいです。Redfin/Cloudflareが明示的に検証するSec-Fetch-*を含む、Chrome相当の完全なヘッダーが必要です。
1from curl_cffi import requests as curl_requests
2HEADERS = {
3 "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) "
4 "AppleWebKit/537.36 (KHTML, like Gecko) "
5 "Chrome/120.0.0.0 Safari/537.36",
6 "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
7 "Accept-Language": "en-US,en;q=0.9",
8 "Accept-Encoding": "gzip, deflate, br",
9 "Sec-Fetch-Site": "none",
10 "Sec-Fetch-Mode": "navigate",
11 "Sec-Fetch-Dest": "document",
12 "Sec-Fetch-User": "?1",
13}
14session = curl_requests.Session(impersonate="chrome120")
15session.headers.update(HEADERS)
16# セッションをウォームアップして、cf_clearance と RF_BROWSER_ID のクッキーを取得する
17session.get("https://www.redfin.com/")セッションのウォームアップはかなり重要です。深い物件URLにいきなりアクセスすると(事前のクッキーもRefererもないため)、Cloudflareの評価が下がります。
必ずホームページから始めてください。
ステップ3: Redfinの検索結果をスクレイピングする
セッションが温まったら、都市の検索結果ページを取得し、掲載カードを解析できます。現行のセレクター(2024〜2026年)は次のとおりです。
1import time
2import random
3from bs4 import BeautifulSoup
4base_url = "https://www.redfin.com/city/17151/CA/San-Francisco"
5listings = []
6for page_num in range(1, 6): # 1〜5ページ
7 url = f"{base_url}/page-{page_num}" if page_num > 1 else base_url
8 resp = session.get(url)
9 if resp.status_code != 200:
10 print(f"ページ {page_num} でブロックされました: HTTP {resp.status_code}")
11 break
12 soup = BeautifulSoup(resp.text, "html.parser")
13 cards = soup.select("[data-rf-test-id='property-card'], a.bp-Homecard")
14 for card in cards:
15 price_el = card.select_one("span.bp-Homecard__Price--value")
16 addr_el = card.select_one("a.bp-Homecard__Address")
17 stats = card.select("span.bp-Homecard__LockedStat--value")
18 listing = {
19 "price": price_el.text.strip() if price_el else None,
20 "address": addr_el.text.strip() if addr_el else None,
21 "beds": stats[0].text.strip() if len(stats) > 0 else None,
22 "baths": stats[1].text.strip() if len(stats) > 1 else None,
23 "sqft": stats[2].text.strip() if len(stats) > 2 else None,
24 "url": "https://www.redfin.com" + addr_el["href"] if addr_el else None,
25 }
26 listings.append(listing)
27 # 2〜5秒のランダム遅延
28 time.sleep(random.uniform(2, 5))
29print(f"{len(listings)}件の掲載情報を取得しました")San Franciscoの掲載物件について、価格、住所、ベッド数/バス数/面積、詳細URLを含む辞書が増えていくはずです。カードが0件ならHTTPステータスコードを確認してください。403ならCloudflareに検知されていて、住宅回線プロキシが必要な可能性があります。
ステップ4: 各物件の詳細ページをスクレイピングする
検索結果で取れるのは基本情報だけです。詳細ページではRedfin Estimate、築年、HOA、売買履歴、エージェント情報、写真が取れます。これらのページはJavaScriptレンダリングが必要なので、Seleniumに切り替えます。
1from selenium import webdriver
2from selenium.webdriver.chrome.service import Service
3from webdriver_manager.chrome import ChromeDriverManager
4from selenium.webdriver.common.by import By
5import time
6options = webdriver.ChromeOptions()
7options.add_argument("--headless=new")
8options.add_argument("--disable-blink-features=AutomationControlled")
9options.add_argument("user-agent=Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) "
10 "AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36")
11driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=options)
12for listing in listings[:10]: # 最初の10件を補完
13 driver.get(listing["url"])
14 time.sleep(random.uniform(3, 6)) # JSレンダリング待ち
15 try:
16 estimate_el = driver.find_element(By.CSS_SELECTOR, "[data-rf-test-name='avmLdpPrice']")
17 listing["redfin_estimate"] = estimate_el.text.strip()
18 except:
19 listing["redfin_estimate"] = None
20 try:
21 year_built = driver.find_element(By.XPATH, "//span[contains(text(),'Year Built')]/following-sibling::span")
22 listing["year_built"] = year_built.text.strip()
23 except:
24 listing["year_built"] = None
25driver.quit()このステップのあと、最初の10件の掲載情報にRedfin Estimateと築年データが追加されているはずです。こういう設備系の入れ子項目ではXPathのほうがCSSより頑丈ですが、それでも壊れやすいことに変わりはありません。DOMが少しでも組み替われば壊れます。
ステップ5: ブロックとエラーに対処する
指数バックオフ付きの再試行ロジックを入れましょう。
1import time
2def fetch_with_retry(session, url, max_retries=3):
3 for attempt in range(max_retries):
4 resp = session.get(url)
5 if resp.status_code == 200:
6 return resp
7 elif resp.status_code in (403, 429, 503):
8 wait = (2 ** attempt) + random.uniform(1, 3)
9 print(f"ブロックされました({resp.status_code})。{wait:.1f}秒後に再試行します...")
10 time.sleep(wait)
11 else:
12 print(f"予期しないステータスです: {resp.status_code}")
13 break
14 return Noneブロックされた兆候は、本文にCloudflareのHTMLが入ったHTTP 403、明示的なレート制限であるHTTP 429、空のレスポンス本文、またはページ内容内の「Error 1020 Access Denied」です。これらが続くなら、住宅回線プロキシを追加するか、API方式へ切り替えるタイミングです。
方法2: 隠しStingray APIを使ってPythonからRedfinをスクレイピングする
これがいちばんおすすめの方法です。Redfinのフロントエンドは内部JSON APIの/stingray/api/home/details/*と通信していて、レスポンスはきれいで型付きのJSONとして返ってきます。HTMLのパースは不要です。
Redfinの隠しAPIエンドポイントを見つける方法
Chrome DevToolsを開き、NetworkタブでFetch/XHRに絞り込み、任意のRedfin物件ページへ移動します。すると、次のようなエンドポイントへのリクエストが見つかります。
api/home/details/initialInfo— URLからpropertyId、listingIdを解決api/home/details/aboveTheFold— 価格、ベッド数、バス数、面積、写真、ステータス、エージェント、MLS番号api/home/details/belowTheFold— 設備、HOA、税金、駐車場、築年、敷地、履歴api/home/details/avm— 市場掲載中のRedfin Estimateapi/home/details/owner-estimate— 非掲載時のRedfin Estimateapi/home/details/descriptiveParagraph— 物件説明文
賃貸ページでは、rentalId(36文字のUUID)が<meta property="og:image">タグのURLから抽出されます。
Stingray APIで物件データを取得する
大事な注意点があります。StingrayのJSONレスポンスは、CSRF対策として文字列{}&&で始まります。パース前にこの接頭辞を外す必要があります。
1import json
2from curl_cffi import requests as curl_requests
3session = curl_requests.Session(impersonate="chrome120")
4session.headers.update(HEADERS)
5# セッションをウォームアップ
6session.get("https://www.redfin.com/")
7# クッキーとproperty IDを得るために物件ページを取得
8property_url = "https://www.redfin.com/CA/San-Francisco/123-Main-St-94102/home/12345678"
9page_resp = session.get(property_url)
10# Stingray APIを呼び出す
11api_url = "https://www.redfin.com/stingray/api/home/details/aboveTheFold?propertyId=12345678"
12api_resp = session.get(api_url, headers={"Referer": property_url})
13# CSRF対策の接頭辞を削除
14payload = json.loads(api_resp.text.replace("{}&&", "", 1))
15# 構造化データを抽出
16listing_data = payload.get("payload", {})
17print(json.dumps(listing_data, indent=2))このレスポンスには、価格は整数、ベッド数/バス数は数値、写真URLは配列、エージェント情報は入れ子オブジェクトという形で、型付きのフィールドが含まれています。BeautifulSoupもCSSセレクターも不要で、推測も要りません。
隠しAPI方式の長所と制約
長所:
- 事前構造化されたJSONで、HTMLパースより圧倒的に扱いやすい
- 1リクエストあたりが速い(ペイロードが小さく、レンダリング負荷がない)
- ブロックリスクが比較的低い(適切なヘッダーを付けたAPI風リクエストは自然に見える)
制約:
- エンドポイントが予告なく変わる可能性がある。公式ドキュメントはない
robots.txtではワイルドカードユーザーエージェントに対して/stingray/が明示的に禁止されている- 新しいエンドポイントを見つけるにはリバースエンジニアリングが必要
- Cloudflareを避けるため、やはりセッションのウォームアップと適切なヘッダーは必要
ノーコードの代替案: ThunderbitでRedfinをスクレイピングする
Redfinのデータが必要だけどPythonスクリプトの保守はしたくない、あるいは5分で結果が欲しい。そんなときはここから始めてください。私たちはまさにそのためにを作りました。あらゆるWebサイトから、コード不要で構造化データを抽出できます。
ステップ1: ThunderbitをインストールしてRedfinを開く
Chromeウェブストアからをインストールします。Redfinを開き、検索結果ページ、たとえばSan Franciscoの売り物件一覧に移動してください。
ステップ2: 「AI Suggest Fields」をクリックする
ブラウザのツールバーにあるThunderbitアイコンをクリックし、**「AI Suggest Fields」**を選択します。AIがRedfinページを読み取り、「Address」「Price」「Beds」「Baths」「SqFt」「Property Type」「Listing Photo」などの列を自動で提案し、データ型も適切に設定します。
不要な列は消せますし、**「+ Add Column」**をクリックして、欲しい項目を自然文で指定することもできます(例: 「listing agent name」「days on market」など)。
設定済みの列が表形式でプレビューされ、すぐにデータ投入できる状態になります。
ステップ3: 「Scrape」をクリックしてデータ取得を始める
**「Scrape」**をクリックすると、Thunderbitが表示中の掲載情報を処理して表に埋め込みます。ページネーションがある場合も自動で対応するので、ループ処理は不要です。
私の検証では、50行のテーブルが約45秒で埋まりました。構造化データがそのままエクスポート可能な状態で手に入ります。
ThunderbitがRedfinのボット対策をどう扱うか
Thunderbitはあなた自身のブラウザ内で動くので、既存のRedfinクッキー、セッション、ブラウザフィンガープリントをそのまま引き継ぎます。Cloudflareから見ると、普通のユーザーがRedfinを見ているのと同じです。技術的にもその通りです。ヘッドレスブラウザでもなければ、データセンターIPでもなく、TLSフィンガープリントの不一致もありません。公開ページなら、Thunderbitのクラウドスクレイピングモードで一度に50ページ処理できます。
これは、サーバー上のPythonスクリプトからrequestsを投げるのとは根本的に違います。
ブラウザセッションは、もう信頼されているんです。
ThunderbitでRedfinのサブページをスクレイピングする
検索結果を取ったら、**「Scrape Subpages」**をクリックして、各物件詳細URLをAIに巡回させ、Redfin Estimate、築年、HOA費、エージェント情報、物件写真、売買履歴などの追加項目で表を拡張できます。
これは方法1で40行ほど必要だったSeleniumループと同じことを、1クリック・メンテナンスゼロで実現するイメージです。
RedfinのDOMがhomecardV2Priceからspan.bp-Homecard__Price--valueに変わっても、AIなら対応できます。Pythonのセレクターはそうはいきません。
CSVを超えて: RedfinデータをGoogle Sheets、Airtable、Notionへ出力する
多くの解説記事はdf.to_csv()で終わります。単発の分析ならそれで十分です。でも不動産チームで使うなら、必要なのは誰かのPCに眠る静的ファイルじゃなくて、共同編集できる生きたデータです。
Pythonでの出力(gspread + Airtable API)
gspreadでGoogle Sheetsへ:
1import gspread
2import pandas as pd
3from gspread_dataframe import set_with_dataframe
4df = pd.DataFrame(listings)
5gc = gspread.service_account(filename="service_account.json")
6sh = gc.open("Redfin Listings")
7ws = sh.worksheet("Sheet1")
8ws.clear()
9set_with_dataframe(ws, df, include_index=False, resize=True)
10# IMAGE()関数で物件写真をセル内表示する
11image_col = df.columns.get_loc("image_url") + 1
12for row_idx, url in enumerate(df["image_url"], start=2):
13 ws.update_cell(row_idx, image_col, f'=IMAGE("{url}")')注意: Sheetsには1スプレッドシートあたり1,000万セルという上限があり、APIにも制限があります。数十行を超える場合は、1セルずつループするのではなくws.batch_update()を使ってください。
pyairtableでAirtableへ:
2024年の重要な変更点として、Airtableはしました。今はPersonal Access Token(PAT)を使う必要があります。api_key=...と書かれた古いチュートリアルは動きません。
1from pyairtable import Api
2api = Api("patXXXXXXXXXXXXXX.yyyyyyyyyyyyyyyyyyyy")
3table = api.table("appBaseId123", "Redfin Listings")
4records = [
5 {
6 "Address": row["address"],
7 "Price": row["price"],
8 "Beds": row["beds"],
9 "Photo": [{"url": row["image_url"]}], # Airtableが取得して再ホストする
10 }
11 for row in listings
12]
13created = table.batch_create(records, typecast=True)Airtableのレート制限はで、違反すると30秒間ロックされます。添付フィールドには[{"url": ...}]形式を渡せます。Airtable側のサーバーがURLを取得して、自社CDNで再ホストし、サムネイルを自動生成します。
Thunderbitでの出力(Google Sheets / Airtable / Notionへ1クリック)
ThunderbitにはGoogle Sheets、Airtable、Notionへのネイティブな1クリック出力機能があります。特に私が本当に気に入っているのは、物件写真がNotionやAirtableにインライン画像としてアップロード・表示されることです。=IMAGE()の裏技も、壊れやすいCDNリンクも不要です。「Export to Airtable」をクリックすれば、チームはスマホからでも見られるサムネイル付きの、視認性の高い物件データベースを手にできます。
物件の見極めを視覚的に行う不動産チームにとって、これは「便利なツール」と「ただのCSVの山」の違いです。
Redfinのスクレイピングは合法なのか? 利用規約、robots.txt、判例から見る
私は弁護士ではないので、これは法的助言ではありません。ただ、データ抽出の世界に長くいる立場から言えるのは、「合法なのか?」という問いこそが誰もが気にするのに、多くの解説が避けて通る論点だということです。
Redfinのrobots.txt
Redfinのはかなり細かいです。要点は次のとおりです。
- 完全にブロックされているボット:
peer39_crawler/1.0、AmazonAdBot、FireCrawlAgent— RedfinはLLM時代に広く使われるスクレイピングサービスを名指ししています - ワイルドカードの
User-agent: *に対するDisallowの主な対象:/stingray/(内部API名前空間全体)、/myredfin/、/api/v1/rentals/、/api/v1/properties/、/owner-estimate/ - どのユーザーエージェントにも**
Crawl-delay:指定なし** - 50以上のサイトマップを宣言 — サイトマップはURL列挙のなかで、WAFへの負荷がいちばん低い方法です
Redfinの利用規約
には次のようにあります。「事前に明示的な書面許可を得ていない限り、いかなる目的・手段によっても、サービスを自動的にクロールまたは問い合わせてはなりません。」
これはbrowsewrap型の同意です。つまり、クリック同意ではなく、継続利用による同意とみなす形式です。米国の裁判所は歴史的に、実際の通知を受けていないユーザーに対するbrowsewrapの強制には慎重でした(Nguyen v. Barnes & Noble, 9th Cir. 2014 参照)。
関連判例(要点のみ)
- Van Buren v. United States(最高裁、2021年): CFAAの「exceeds authorized access」は「ゲートが開いているか閉じているか」のテストで判断される。開いているドアを好ましくない目的で使うことは、連邦法上のハッキングではない。
- hiQ Labs v. LinkedIn(第9巡回、2022年): 公開データのスクレイピングはCFAA違反ではない。ただしhiQは、LinkedInにアカウント登録して「I agree」を押していたため、契約違反を理由に最終的に50万ドルを支払って和解した。
- Meta Platforms v. Bright Data(N.D. Cal., 2024年1月): 裁判所はBright Dataに略式判決を認めた。ログアウト状態で公開データをスクレイピングする行為は、Bright DataをMetaの規約に拘束される「ユーザー」とはしなかった。
- X Corp. v. Bright Data(N.D. Cal., 2024年5月): Alsup判事はXの請求を棄却し、公開コンテンツの複製を制御しようとする州法上の請求は著作権法により排除されると判断した。
実務上の指針
- 取得するのは公開アクセス可能なデータだけにする — アカウント登録後にスクレイピングするのは避ける(クリックラップ契約のリスクが生じる)
- レート制限を尊重する — 過度な取得量は、動産侵害(trespass to chattels)の主張を支えかねない
- 生データや写真を大規模に再配布しない — 訴訟(2025年7月提訴、損害額は10億ドル超の可能性)は、写真の著作権がかなり重要だという警告です
- Thunderbitのブラウザベースの方法は、自分の認証済みセッション内で動くため、ヘッドレスのデータセンターボットよりも「人間の操作を機械速度で再現する」形に近く、ライセンス付きAPIを除けば最も防御しやすい立場です
コツとよくある落とし穴
抽出ツールを作り、何千人ものユーザーが不動産サイトをスクレイピングする様子を見てきた中で得た、実践的な教訓をいくつか紹介します。
- 必ずセッションをウォームアップする。 深いURLの前に必ず
redfin.com/を開いてください。いきなり深いURLへ行くのは、Cloudflareチャレンジを引き起こす大きな原因です。 - User-Agentは現実的にローテーションする。 1種類だけを使わず、現在のChrome/Firefox UAを5〜10個ほど回してください。ただし、回しすぎも逆効果です(毎回UAが違うと不自然です)。
- 物件IDで重複排除する。 Redfinのページネーションは重複が出ることがあります。各掲載URLから
/home/{id}を取り出して、拡張前に重複排除してください。 - 可能ならピーク時間帯は避ける。 私の経験では、米国時間の深夜〜早朝はWAFの監視が比較的ゆるいことが多いです。
- 429が出たら指数的に引く。 すぐ再試行すると、ソフトな制限がハードなIP BANにエスカレートしやすくなります。
- 大規模案件(1,000ページ以上)なら、住宅回線プロキシの予算を確保する。 データセンターIP(AWS、GCP、Azure、OVH)はCloudflareのASN評判システムでブラックリスト化されています。Error 1020にほぼ即座に遭遇します。
Redfinスクレイピングの最適な方法を選ぶ
では、どの方法を選べばよいのでしょうか。答えは、あなたが誰で、何を求めるか次第です。
HTMLパース(BeautifulSoup + Selenium): 完全な制御を求め、CSSセレクターの保守に抵抗がなく、RedfinのDOM変更ごとに作り直すのも苦にならない開発者向けです。6〜12か月ごとにコードを見直す前提で考えてください。
隠しStingray API: クリーンで構造化されたJSONが必要で、未公開エンドポイントのリバースエンジニアリングができる開発者向けです。HTMLパースより保守は楽ですが、予告なく変わる可能性があります。しかも/stingray/はrobots.txtで明示的に禁止されています。
Thunderbit(ノーコード): 非エンジニア、短期案件、そして開発リソースなしで継続的にRedfinデータを使いたいチーム向けです。AIがレイアウト変更に適応し、サブページスクレイピングはワンクリックでデータを拡張でき、、Airtable、Notionへの出力も標準搭載です。単発のCSVダンプではなく、実運用できる物件データベースが必要な不動産チームなら、いちばん手間の少ない選択肢です。
どの方法を選ぶにせよ、始める前にRedfinのボット対策を理解し、必要な項目を把握し、チームのワークフローに合う出力形式を選び、の範囲内で進めてください。
ノーコードで試したいですか? なら、Redfinスクレイピングを試して、数分で結果を確認できます。Pythonで進める場合も、上のコード例はそのまま使える出発点になります。あとはプロキシと少しの忍耐を足すだけです。
FAQ
Redfinに公開APIはありますか?
いいえ。Redfinは公式の公開APIを提供していません。隠しStingray API(/stingray/api/home/details/*)は構造化されたJSONを返し、Redfin自身のフロントエンドでも使われていますが、非公式で未文書、予告なく変更される可能性があり、Redfinのrobots.txtでも明示的に禁止されています。PyPI上ののようなオープンソースラッパーでPythonからアクセスできますが、リスクを理解したうえで使ってください。
PythonなしでRedfinをスクレイピングできますか?
はい。はAI搭載のChrome拡張で、ブラウザセッションを引き継ぐためボット対策に強いのが特長です。インストールしてRedfinを開き、「AI Suggest Fields」をクリックするだけで、Excel、Google Sheets、Airtable、Notionに出力できます。代替手段として、他のノーコードスクレイピングツールや、あらかじめ用意されたデータセット提供サービスも市場にはあります。
Redfinのサイト構成はどのくらいの頻度で変わりますか?
GitHubのコミュニティIssue履歴を見ると、CSSセレクターの破損はだいたい6〜12か月ごとに起きています。RedfinはカードDOMを2世代出していて、旧版は(homecardV2Price、homeAddressV2)、現行は(bp-Homecard__Price--value、bp-Homecard__Address)です。成熟したスクレイパーは両方を順番に試します。
ThunderbitのようなAIベースのツールは、CSSセレクターではなく内容でフィールドを検出するので、します。
Redfinをスクレイピングするのに最適なプロキシは何ですか?
大規模スクレイピングなら、米国の住宅回線プロキシが最適です。コミュニティのベンチマークでは成功率は約80%です。データセンタープロキシはCloudflareのError 1020にほぼ即座に引っかかります。AWS、GCP、Azure、OVHのIP帯はブラックリスト化されています。モバイルプロキシは成功率がいちばん高いですが、コストは5〜10倍かかります。
小規模な個人利用のスクレイピング(100ページ未満)なら、適切なヘッダー + curl_cffiの偽装 + 2〜5秒の遅延で、プロキシなしでも動くことがあります。
Redfinから成約済みや非掲載の物件データをスクレイピングできますか?
はい。成約済み物件データや、非掲載のRedfin Estimate(中央値誤差)は、同じスクレイピング手法で詳細ページから取得できます。対象によって項目は少し異なり、非掲載ページでは売却価格、売却日、物件履歴、owner-estimateエンドポイントが使えますが、現在の掲載価格、掲載日数、オープンハウス情報はありません。非掲載時のStingray APIエンドポイントはapi/home/details/owner-estimateで、api/home/details/avmではありません。
さらに学ぶ