

403。Indeedから構造化データをプログラムで取りに行ったことがある人なら、この数字を見ただけで何が起きたか察しがつくでしょう。これはコードのバグではありません。Indeedが意図して仕込んだ防御の一部なのです。求人タイトルをスプレッドシートに50回近く手で写したあたりで、自分のキャリア選択そのものを疑い始めた——そんな経験があるなら、なおさら身に覚えがあるはずです。
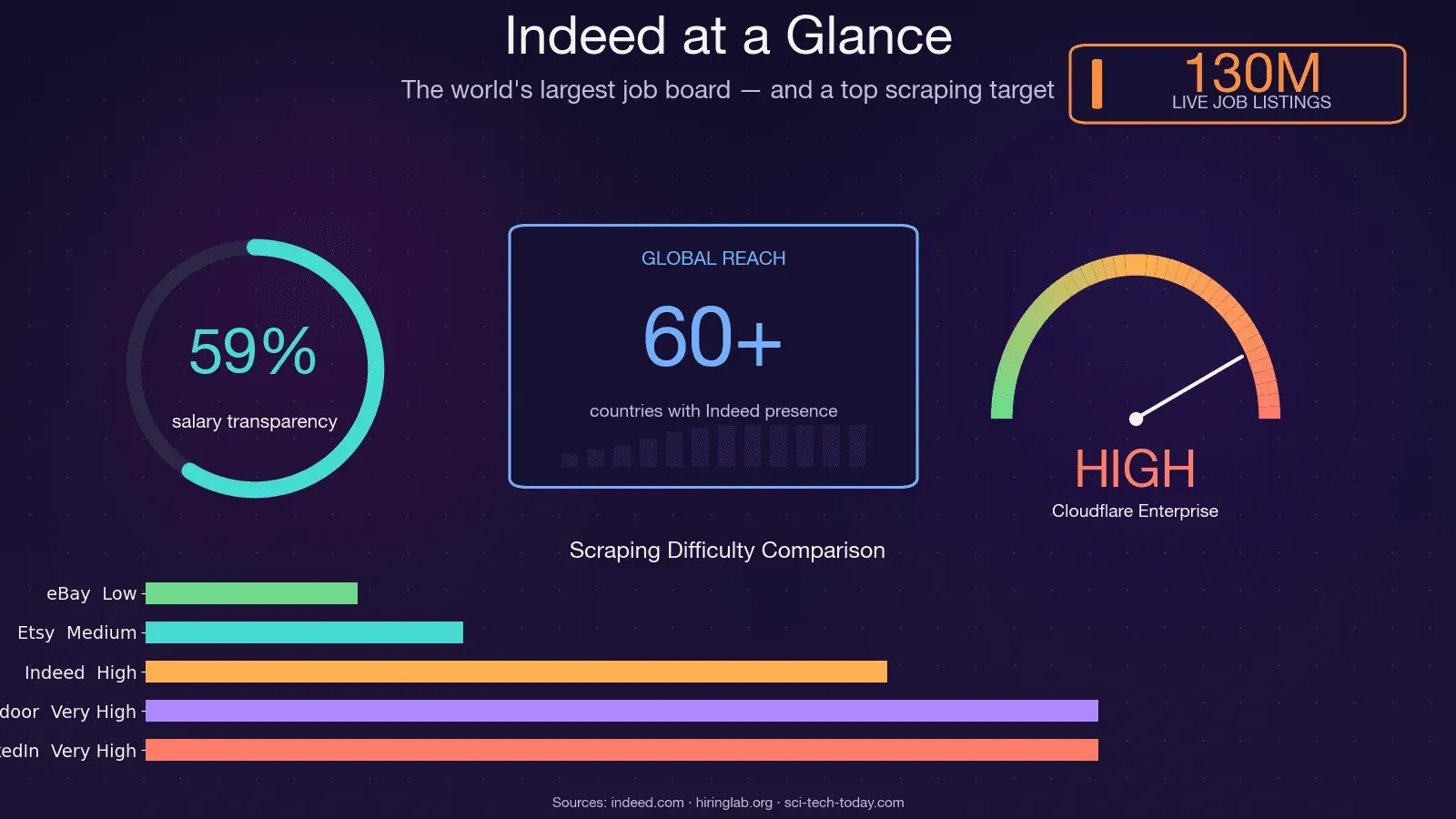
そもそもIndeedは桁違いの規模を持っています。展開している国と地域は60以上、常時抱える求人は1億3,000万件、そして月間ユニーク訪問者数は約3億5,000万人。世界有数の求人市場データが眠っている一方で、突破の難しさも世界トップクラス、という二面性を持つサイトなんです。それを象徴するのがオープンソースのJobFunnelでした。GitHubスター数千を集めたこのスクレイパーは、アンチボットとの長い消耗戦の末に力尽き、2025年12月にメンテナー自身の手でアーカイブされています。メンテナー本人いわく、「すべてのユーザーが一部の求人は取得できますが、すぐにCAPTCHAに阻まれ、スクレイピングは失敗して求人は取得できません。」 ある貢献者にいたっては、最初のリクエストでもうCAPTCHAが出たと報告しているほどです。つまり生半可な相手ではない。本ガイドではPythonでIndeedを攻略する実践手法を一通りそろえ、あの403の壁をどう越えるかを掘り下げます。デバッグ自体を省きたい方には、Thunderbitを使ったノーコードの逃げ道も用意しました。
PythonでIndeedをスクレイピングするとはどういう意味か?
ウェブスクレイピングという言葉は、突き詰めればWebページから構造化データを自動で抜き出す作業を指します。これをIndeedとPythonに当てはめると、検索結果ページや求人詳細ページにアクセスするスクリプトを書き、内部のHTML(あるいは埋め込まれたデータ)を読み取り、求人タイトル・企業名・勤務地・給与・説明文といった項目を、CSVやデータベース、Google スプレッドシートのような扱いやすい形に落とし込む——そういう一連の流れになります。
道具立てとしてよく登場するのは、HTTP通信のRequests、HTML解析のBeautifulSoup、ブラウザ自動化のSeleniumやPlaywrightです。ただ、ここで油断できないのがIndeedの正体。単純な静的サイトではありません。サーバーサイドでレンダリングされたHTMLの中にJSONの状態データが仕込まれ、その手前にはCloudflare Bot Managementが構えています。結果として、JavaScriptで描かれるコンテンツ、コロコロ変わるCSSクラス名、手強いアンチボット——この三つすべてにスクレイパーが対応せざるを得ない。求人タイトルを一件解析する前に、まずこの関門を抜ける必要があるわけです。
公式APIに望みをつなぐのも難しいのが実情です。2026年現在、無料で使える読み取り専用のIndeed APIは存在しません。かつてのPublisher Jobs APIは2020年ごろに姿を消し、いま残っているのは雇用主向けのJob SyncやSponsored Jobsだけ。現実的な選択肢は二つに絞られます。自分でスクレイピングするか、第三者のデータプロバイダーに対価を払うか、です。
なぜIndeedの求人データをスクレイピングするのか?
ビジネス上の動機は、突き詰めればシンプルです。何千件もの求人を一件ずつ目で追うのは現実的でない一方、その一件一件に詰まったデータには確かな価値がある——ここに尽きます。
| ユースケース | 恩恵を受ける人 | 例 |
|---|---|---|
| リード獲得 | 営業・採用チーム | 採用中の企業リストと連絡先を作成する |
| 求人市場調査 | アナリスト、人事チーム | 注目スキルや地域別の給与相場を把握する |
| 競合分析 | 企業、採用代行会社 | 競合の採用動向や提示給与を追跡する |
| 個人の転職活動の自動化 | 求職者 | 条件に合う求人を地域横断で集約する |
| 機械学習モデルの学習データ | データサイエンティスト | 過去の求人データから給与予測モデルを作る |
具体的にどう効いてくるのか。たとえばヘッジファンドは、求人掲載数の増減を代替データのシグナルとして読み取ります。人事チームはスクレイピングで集めた給与レンジを使い、自社の報酬水準をベンチマークする。採用担当者なら、積極採用中の企業から見込み先リストを起こせます。こうした使い方を裏づけるように、Indeed Hiring Lab自身の調査でも、求人掲載データがBLS JOLTSをよく追随し、米国の労働市場をほぼリアルタイムで映す指標になり得ると確認されています。
ただし、給与データには落とし穴が一つあります。年々改善されてはいるものの、まだ穴だらけなんです。2025年半ばの段階で、給与情報が載っていた米国の求人掲載は約59%。しかも正確な金額まで示されていたのは22%ほどで、残りはレンジ表記にとどまります。Indeedのデータで給与分析をするなら、この欠損が最初から存在する前提で設計しておくべきでしょう。
PythonでIndeedをスクレイピングする方法の選び方
「これさえやれば正解」という単一の手法は、残念ながらありません。最適解は人によって変わります——自分のスキル、必要なデータ量、保守の手間をどこまで許容できるか、によってです。主要な4つの方法を実際に試したので、比較表にまとめました。
| 比較項目 | BS4 + Requests | Selenium | 非公開JSON(window.mosaic) | ノーコード(Thunderbit) |
|---|---|---|---|---|
| 難易度 | 初級 | 中級 | 中級〜上級 | なし(2クリック) |
| 速度 | 高速 | 低速(ブラウザ描画) | 高速 | 高速(クラウドスクレイピング) |
| JS描画コンテンツ | いいえ | はい | はい(埋め込みデータ) | はい |
| アンチボット耐性 | 低い | 中程度(検知されやすい) | 中〜高 | 高い(自動処理) |
| HTML変更時の保守負荷 | 高い(セレクタが壊れやすい) | 高い | 中程度(JSON構造の方が安定) | なし(AIが適応) |
| 向いている用途 | すばやい試作 | 動的ページ、ログイン必須ページ | 大量の構造化データ | 非エンジニア、素早く結果が欲しい場合 |
以降では、これらの方法を一つずつ順番に解説していきます。Python開発者の方は、BS4・非公開JSON・Seleniumの各セクションに目を通すとよいでしょう。逆に、コードは書きたくない、あるいは403のデバッグにもう疲れた——そういう方は、迷わずThunderbitのセクションまで飛んでください。
始める前に
- 難易度: 初級〜中級(Pythonの各章);なし(Thunderbitの章)
- 所要時間: Pythonのセットアップと最初のスクレイピングに約20〜60分;Thunderbitなら約2分
- 必要なもの: Python 3.9以上、コードエディタ、Chromeブラウザ、そしてノーコードで進める場合はThunderbit Chrome拡張機能
Indeedスクレイピング用のPython環境をセットアップする
コードに手をつける前に、足場となる環境を先に整えておきましょう。
必要なライブラリをインストールする
まず仮想環境を切り、そこへ必要なパッケージを入れていきます。
python -m venv indeed_env
source indeed_env/bin/activate # Windowsの場合: indeed_env\Scripts\activate
# HTTP + 解析の方法
pip install requests beautifulsoup4 lxml httpx
# 非公開JSONの方法(推奨)
pip install curl_cffi parsel tenacity
# ブラウザ自動化の方法
pip install selenium
各パッケージについて、補足しておきます。
curl_cffiは、Cloudflare保護サイトに挑む際の2026年時点での定番です。本物のブラウザに近いTLSフィンガープリントを装える点が肝で、素のrequestsやhttpxでは届かない領域に手が届きます。なぜそれが効くのかは、後段のアンチボットの章でじっくり扱います。- Selenium 4.6以降 ではSelenium Managerが標準で同梱されました。おかげでChromeDriverを手動で落とす手間は不要で、ブラウザバイナリの管理は自動で済みます。
- BeautifulSoupに渡すパーサーは**
lxml**を指定しましょう。標準のhtml.parserに比べて約1.5倍速いからです。
プロジェクト構成を作る
凝った構成は要りません。これで十分です。
indeed_scraper/
├── scraper.py
├── requirements.txt
└── output/
これ以降のコード例は、すべてscraper.pyを前提に進めます。
BeautifulSoupを使ってPythonでIndeedをスクレイピングする方法
初心者がまず触れる入り口がこれです。requestsでページを取ってきて、BeautifulSoupに解析させる。セットアップの手軽さは随一ですが、こと相手がIndeedとなると、最も脆い手法でもあります。
ステップ1: Indeedの検索URLを作成する
Indeedの検索URLは、こういう決まった型に収まっています。
https://www.indeed.com/jobs?q=<query>&l=<location>&start=<offset>
たとえば「Austin, TX」の「data analyst」を1ページ目から検索したいなら、こうなります。
from urllib.parse import urlencode
params = {
"q": "data analyst",
"l": "Austin, TX",
"start": 0,
}
url = f"https://www.indeed.com/jobs?{urlencode(params)}"
print(url)
# https://www.indeed.com/jobs?q=data+analyst&l=Austin%2C+TX&start=0
ページ送りは10件刻みで、上限は1,000件(start <= 990)です。990を超えるオフセットを渡しても、エラーにはならず同じページがそのまま返ってくるだけです。
ステップ2: 適切なヘッダー付きでHTTPリクエストを送る
PythonがデフォルトでつけるUser-Agent文字列のままでは、Indeedは一瞬でブロックしてきます。もっと現実的なヘッダーを用意してやる必要があります。
import requests
headers = {
"User-Agent": (
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 "
"(KHTML, like Gecko) Chrome/145.0.0.0 Safari/537.36"
),
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Language": "en-US,en;q=0.9",
"Accept-Encoding": "gzip, deflate, br",
"Referer": "https://www.indeed.com/",
}
response = requests.get(url, headers=headers, timeout=30)
print(response.status_code)
200が返ってくれば、とりあえず一関門は突破。403が返ってきたら、Cloudflareに足止めされています。(その抜け方は、このあと詳しく説明します。)
ステップ3: HTMLから求人一覧を解析する
BeautifulSoupで求人カードの要素を拾います。狙うべきはランダム化されたCSSクラス名ではなく、data-testid属性のほう。こちらのほうが格段に安定しています。
from bs4 import BeautifulSoup
soup = BeautifulSoup(response.text, "lxml")
cards = soup.find_all("div", attrs={"data-testid": "slider_item"})
jobs = []
for card in cards:
title_el = card.find("h2", class_="jobTitle")
title = title_el.get_text(strip=True) if title_el else None
company = card.find(attrs={"data-testid": "company-name"})
location = card.find(attrs={"data-testid": "text-location"})
link = title_el.find("a")["href"] if title_el and title_el.find("a") else None
jobs.append({
"title": title,
"company": company.get_text(strip=True) if company else None,
"location": location.get_text(strip=True) if location else None,
"url": f"https://www.indeed.com{link}" if link else None,
})
print(f"{len(jobs)}件の求人を見つけました")
ステップ4: ページネーションを処理する
startパラメータを少しずつ増やしながら、ページを順に巡ります。
import time, random
all_jobs = []
for page in range(0, 50, 10): # 最初の5ページ
params["start"] = page
url = f"https://www.indeed.com/jobs?{urlencode(params)}"
response = requests.get(url, headers=headers, timeout=30)
# ... 上と同様に解析 ...
all_jobs.extend(jobs)
time.sleep(random.uniform(3, 6))
この方法の限界
ここははっきり言っておきます。2026年のIndeed相手では、BS4 + Requestsは最も心もとない手法です。通常のrequestsはPython標準ライブラリのTLSをそのまま使うため、Cloudflareに「これはブラウザじゃない」と一発で見抜かれるJA3フィンガープリントを発信してしまうんです。おまけにIndeedが提供するHTTP/2にも非対応。となれば、数ページ取った時点でブロックされる公算が高い。CSSセレクタの脆さも追い打ちをかけます。Indeedはcss-1m4cuufやjobsearch-JobComponent-embeddedBody-1n0gh5sのようなクラス名をしょっちゅう差し替えるので、それを当てにしたセレクタは時限爆弾も同然です。
この手法の出番は、1ページだけの試作までと割り切りましょう。本格的に量を捌くなら、次の非公開JSONの方法に移るべきです。
非公開JSONデータを使ってPythonでIndeedをスクレイピングする方法
Python開発者には、たいていこの手法を推します。脆いHTML要素を相手にする代わりに、Indeedのページソースに埋め込まれたJavaScript変数window.mosaic.providerData["mosaic-provider-jobcards"]から、構造化データをそのまま抜き取るやり方です。
このJSONブロックには、欲しい情報がひととおり揃っています——求人タイトル、企業名、勤務地、給与、job key、掲載日時、リモート判定まで。しかもJavaScriptを実行する必要は一切ありません。スキーマも少なくとも2023年以降は安定していて、DOMセレクタとは比べものにならないほど堅牢なんです。
ステップ1: ページのHTMLを取得する
ここではrequestsではなくcurl_cffiを使います。Cloudflare突破の鍵となる、本物のブラウザさながらのTLSフィンガープリントを装えるからです。
from curl_cffi import requests as cffi_requests
response = cffi_requests.get(
"https://www.indeed.com/jobs?q=python+developer&l=Remote&start=0",
impersonate="chrome124",
headers={
"Accept-Language": "en-US,en;q=0.9",
"Referer": "https://www.indeed.com/",
},
timeout=30,
)
print(response.status_code, len(response.text))
なぜcurl_cffiを選ぶのか。これはcurl-impersonateのPythonバインディングで、実際のブラウザと同一のTLS ClientHello、HTTP/2 SETTINGSフレーム、ヘッダー順までそっくり再現してくれます。JA3/JA4とAkamai H2フィンガープリントの両方を、たった1回の呼び出しでまとめてかわせる——しかも現在も活発に保守が続くPython HTTPクライアントなんです。impersonationの選択肢もchrome120、chrome124、chrome131、Safari、Edge系と幅広く揃っています。
ステップ2: 正規表現でJSONを抜き出す
目当てのJSONブロックは<script>タグの中に埋もれています。正規表現で引っ張り出しましょう。
import re, json
MOSAIC_RE = re.compile(
r'window\.mosaic\.providerData\["mosaic-provider-jobcards"\]=(\{.+?\});',
re.DOTALL,
)
match = MOSAIC_RE.search(response.text)
if match:
data = json.loads(match.group(1))
results = data["metaData"]["mosaicProviderJobCardsModel"]["results"]
print(f"非公開JSON内で{len(results)}件の求人を見つけました")
else:
print("非公開JSONが見つかりません。ブロックかページ変更の可能性があります")
ステップ3: JSONから求人項目を解析する
resultsの各要素には、画面上に表示されている以上の情報が詰まっています。
jobs = []
for job in results:
jobs.append({
"jobkey": job["jobkey"],
"title": job["title"],
"company": job.get("company"),
"location": job.get("formattedLocation"),
"remote": job.get("remoteLocation"),
"salary": (job.get("salarySnippet") or {}).get("text"),
"posted": job.get("formattedRelativeTime"),
"job_type": job.get("jobTypes"),
"easy_apply": job.get("indeedApplyEnabled"),
"url": f"https://www.indeed.com/viewjob?jk={job['jobkey']}",
})
このJSONには、給与推定、分類属性(スキルタグ)、企業評価など、レンダリング済みのHTMLには必ずしも顔を出さない情報まで含まれていることがよくあります。
ステップ4: 複数ページをスクレイピングする
JSON内のtierSummariesから総件数を読み取り、それを頼りにループを回します。
import time, random
all_jobs = []
for start in range(0, 50, 10): # 最初の5ページ
url = f"https://www.indeed.com/jobs?q=python+developer&l=Remote&start={start}&sort=date"
response = cffi_requests.get(
url,
impersonate="chrome124",
headers={"Accept-Language": "en-US,en;q=0.9", "Referer": "https://www.indeed.com/"},
timeout=30,
)
match = MOSAIC_RE.search(response.text)
if match:
data = json.loads(match.group(1))
results = data["metaData"]["mosaicProviderJobCardsModel"]["results"]
all_jobs.extend([{
"jobkey": j["jobkey"],
"title": j["title"],
"company": j.get("company"),
"location": j.get("formattedLocation"),
"salary": (j.get("salarySnippet") or {}).get("text"),
"url": f"https://www.indeed.com/viewjob?jk={j['jobkey']}",
} for j in results])
time.sleep(random.uniform(3, 7))
print(f"合計: {len(all_jobs)}件の求人を取得しました")
非公開JSONの方が堅牢な理由
理由は単純で、window.mosaic.providerDataの構造はCSSクラス名ほど頻繁には変わらないからです。厄介なHTMLと格闘せずとも、最初からきれいな構造化データが手に入る。とはいえ、ヘッダーや待機時間、プロキシといったアンチボット対策まで省けるわけではありません。その話は次のセクションに譲ります。
Seleniumを使ってPythonでIndeedをスクレイピングする方法
Seleniumはブラウザそのものを動かす手法です。求人詳細パネルをクリックで開かせる、ログインが要るコンテンツを扱う、初期HTMLには載っていない動的ロードの説明文を引き出す——こういう場面でこそ真価を発揮します。
HTTPクライアントではなくSeleniumを使うべき場面
- Indeedが一部コンテンツを動的に読み込む場合(右側パネルの完全な求人説明など)
- セッション状態やログインが必要なページを取得したい場合
- 速度がそれほど重要でない小規模スクレイピングの場合
簡単な流れ
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
import time
options = Options()
options.add_argument("--disable-blink-features=AutomationControlled")
# options.add_argument("--headless=new") # ヘッドレスは検出されやすいので注意
driver = webdriver.Chrome(options=options)
driver.get("https://www.indeed.com/jobs?q=data+engineer&l=New+York")
time.sleep(3)
cards = driver.find_elements(By.CSS_SELECTOR, "[data-testid='slider_item']")
for card in cards:
try:
title = card.find_element(By.CSS_SELECTOR, "h2.jobTitle").text
company = card.find_element(By.CSS_SELECTOR, "[data-testid='company-name']").text
location = card.find_element(By.CSS_SELECTOR, "[data-testid='text-location']").text
print(f"{title} | {company} | {location}")
except Exception:
continue
driver.quit()
限界
Seleniumの最大の弱点は遅さです。ページごとにブラウザを丸ごと描画する必要があるため、どうしても時間を食います。さらにヘッドレスChromeは、Indeedのアンチボットに見つかりやすい。Cloudflareがnavigator.webdriver、WebGLのベンダー文字列、プラグイン数あたりを逐一チェックしているからです。undetected-chromedriverを噛ませても、検出を遅らせられるだけで、永久に防げるわけではありません。そしてBS4と同じく、IndeedがUIを刷新すればセレクタはあえなく壊れます。
ほとんどの用途では、非公開JSONの方法のほうが軍配が上がります。同じデータをより速く、しかも保守の手間を抑えて取れるからです。Seleniumは、本当にブラウザでなければ無理という例外的なケースに限って投入しましょう。
PythonでIndeedをスクレイピングする際に403エラーを避ける方法
ここからが本丸です。イライラの募るGoogle検索の果てにこのページへたどり着いたのなら、まさに来るべきところに来ています。
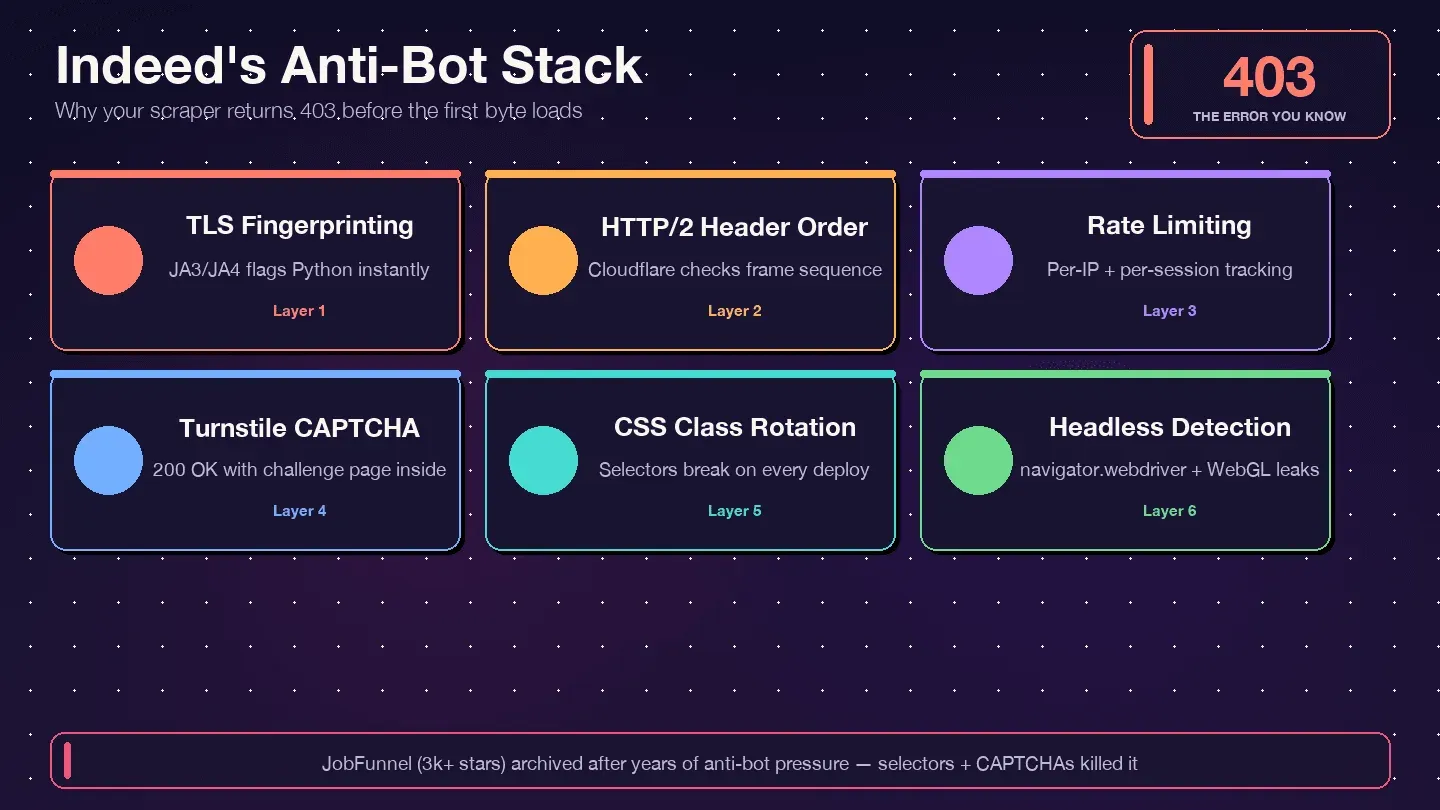
なぜIndeedはスクレイパーをブロックするのか
Indeedが採用しているのはCloudflare Bot ManagementとCloudflare Turnstileです。DataDomeでもPerimeterXでもありません。証拠はレスポンスヘッダーに出ています——server: cloudflare、cf-ray、それにボット管理用Cookieの__cf_bm。Cloudflareは、TLSフィンガープリント(JA3/JA4)、HTTP/2のヘッダー順、リクエストパターン、ブラウザ挙動のシグナルを総合的に見ています。そのうちどれか一つでも人間らしさを欠いていれば、返ってくるのは403、429、503——あるいは最も陰険なパターンとして、実データの代わりにTurnstileのチャレンジページを乗せた200 OKです。
User-Agentとリクエストヘッダーをローテーションする
一つのUser-Agentを固定で使い回す。これが最速でブロックを招く悪手です。現行で自然に見える文字列を何種類か用意し、そこから回していきましょう。ここで一つ注意。Chromeのマイナーバージョン表記は、User-Agent削減以降ずっと0.0.0に固定されています。実在しないマイナーバージョンをでっち上げると、アンチボットに即座に疑われます。
import random
USER_AGENTS = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 "
"(KHTML, like Gecko) Chrome/145.0.0.0 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 "
"(KHTML, like Gecko) Chrome/145.0.0.0 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 "
"(KHTML, like Gecko) Chrome/145.0.0.0 Safari/537.36 Edg/145.0.3800.97",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:128.0) Gecko/20100101 Firefox/128.0",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 "
"(KHTML, like Gecko) Version/17.4 Safari/605.1.15",
]
headers = {
"User-Agent": random.choice(USER_AGENTS),
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Language": "en-US,en;q=0.9",
"Accept-Encoding": "gzip, deflate, br, zstd",
"Referer": "https://www.indeed.com/",
"Sec-Fetch-Dest": "document",
"Sec-Fetch-Mode": "navigate",
"Sec-Fetch-Site": "same-origin",
}
sec-ch-uaのClient Hintsも、UAのバージョンと食い違わないように揃えてください。User-AgentではChrome 145を名乗っているのにsec-ch-ua: "Chrome";v="131"になっている——こんな矛盾は、即アウトの赤信号です。
リクエスト間にランダムな遅延を入れる
きっちり等間隔のリクエストは、パターン検出にあっさり引っかかります。ランダムなジッターを混ぜましょう。
import time, random
# 各リクエストの間
time.sleep(random.uniform(3, 6))
# ブロック後の再試行時
def backoff_sleep(attempt):
base = 4
sleep_time = base * (2 ** attempt) + random.uniform(0, 2)
time.sleep(min(sleep_time, 60))
ScrapeOpsやWebScraping.AIが示す目安では、1 IPあたりの間隔は3〜6秒、そしてセッション中の1 IPあたりのリクエスト上限はおよそ100件、とされています。
プロキシローテーションを使う
成功率を最も大きく左右するのが、実はこの要素です。AWS/GCP系のデータセンタープロキシは、Cloudflare Enterprise相手だと成功率がせいぜい5〜15%程度で、Indeedにはほぼ歯が立ちません。ところがレジデンシャルプロキシを正しいTLSフィンガープリントと組み合わせると、成功率は一気に80〜95%まで跳ね上がります。
PROXIES = [
"http://user:pass@us.residential.example:7777",
"http://user:pass@us.residential.example:7778",
"http://user:pass@us.residential.example:7779",
]
proxy = random.choice(PROXIES)
response = cffi_requests.get(
url,
impersonate="chrome124",
headers=headers,
proxies={"https": proxy},
timeout=30,
)
2026年時点のレジデンシャルプロキシの相場は、プロバイダーや契約条件しだいで、おおむね1GBあたり4〜8.50ドルに収まります。Indeed用途なら、まずは小さなプールから入り、足りなくなったら広げていく——その進め方が無難でしょう。
403、429、503を適切に処理する
闇雲に再試行を繰り返すのではなく、ステータスコードごとに意味を切り分けて対処します。
def fetch_with_retry(url, proxy_pool, max_retries=5):
for attempt in range(max_retries):
proxy = random.choice(proxy_pool)
headers["User-Agent"] = random.choice(USER_AGENTS)
try:
r = cffi_requests.get(
url,
impersonate=random.choice(["chrome124", "chrome120", "edge101"]),
headers=headers,
proxies={"https": proxy},
timeout=30,
)
# ひっかけの「200だがチャレンジページ」のケースを確認
if r.status_code == 200 and "cf-turnstile" not in r.text and "Just a moment" not in r.text:
return r
if r.status_code == 403:
print(f"403 — ブロックされました。プロキシを切り替えて再試行します。試行 {attempt + 1}")
elif r.status_code == 429:
print(f"429 — レート制限です。速度を落とします。")
elif r.status_code == 503:
print(f"503 — サーバー過負荷、またはJSチャレンジです。")
backoff_sleep(attempt)
except Exception as e:
print(f"リクエストエラー: {e}")
backoff_sleep(attempt)
raise RuntimeError(f"{max_retries}回の再試行後も失敗しました: {url}")
最もたちが悪いのが「200だがチャレンジページ」のケースです。200を成功と早合点する前に、レスポンス本文にcf-turnstileやJust a momentが紛れていないか、必ず確かめてください。
もっと簡単な代替案: Thunderbitにアンチボット処理を任せる
プロキシプールの構築も保守も、ヘッダーのローテーションも、TLSフィンガープリントの偽装も——どれも自前でやりたくない。そう思うなら、Thunderbitのクラウドスクレイピングに丸ごと任せる手があります。CAPTCHA、プロキシローテーション、アンチボット対策のすべてを自動で捌いてくれるんです。プロキシ設定も、curl_cffiの構成も、CAPTCHA解決ライブラリも一切不要。とにかくデータだけ早く欲しいときの、最短ルートと言えます。
Pythonを書いたのにIndeedスクレイパーが壊れ続ける理由と、その直し方
403の壁が急性の痛みだとすれば、保守は慢性の痛みです。今日きちんと動いていたスクレイパーが来週には壊れ、しかも気づかぬうちに空データや古い結果を吐き続ける——これがやっかいなんです。
Indeedがセレクタを壊す仕組み
IndeedはCSSクラス名を惜しみなく入れ替えてきます。Bright Dataのガイドも、css-1m4cuufやcss-1rqpxryといったクラスについて「ランダム生成されているように見え、おそらくビルド時に作られている」とはっきり指摘しています。加えてA/Bテストの影響で、セッションごとに異なるレイアウトが出てくることもある。DOM構造そのものも、何の予告もなく変わります。
その典型がJobFunnelの事例でした。ある貢献者は、*「CaptchaBusterはCAPTCHAをうまく回避できたが、ページのスクレイピングが成功しない理由は、古いBeautiful Soupセレクタにある」*と報告しています。つまり、ブロックされていたのではなく、まったく別の要素を読みにいっていたわけです。
方針: DOM解析より非公開JSONを優先する
window.mosaic.providerDataのブロックは、スキーマが少なくとも2023年以降ずっと安定しています。metaData.mosaicProviderJobCardsModel.results[]というパスは、2026年の今も正規の取得ルートとして生きています。DOMセレクタが月単位で崩れていくのに対し、JSON抽出が崩れるのはせいぜい年単位。この差は大きい。
方針: クラス名よりデータ属性を使う
どうしてもDOMに手を出さざるを得ないときは、機能を表す属性を狙い撃ちにします。
| セレクタ | 用途 |
|---|---|
[data-testid="slider_item"] | 各求人カードのコンテナ |
[data-testid="job-title"] または h2.jobTitle > a | 求人タイトルのリンク |
[data-testid="company-name"] | 企業名 |
[data-testid="text-location"] | 勤務地テキスト |
各カードの data-jk="<jobkey>" | 最も安定したフック。2019年以降変更なし |
セレクタの陳腐化を検知するためにアサーションを入れる
最も避けたいのは、スクレイパーが0件のまま黙々と動き続ける状態です。取得のたびに、こうしたチェックを挟みましょう。
results = parse_hidden_json(html)
assert len(results) > 0, (
f"Indeedが start={start} で空の結果を返しました — "
"ブロック、CAPTCHA、またはセレクタのずれの可能性があります。 "
f"レスポンス先頭500文字: {html[:500]}"
)
失敗したときは、元レスポンスの先頭500〜2000文字をログに残しておいてください。そうしておけば、Turnstileのチャレンジなのか、サインイン壁なのか、それともスキーマ変更なのか——原因の切り分けが一目でつきます。さらに、固定クエリ(たとえばq=python&l=remote)に対してゼロ件でないことを毎日確認する、CIレベルのスモークテストを回しておくと安心です。
AIによる代替案: 壊れないスクレイパー
ThunderbitのAIは、アクセスのたびにページ構造を一から読み直します。ハードコードしたセレクタや正規表現に頼っていないので、IndeedのHTMLが変わってもThunderbit側が勝手に追従してくれる。フォーラムで決まって最大の不満として挙がるのが保守負荷ですが、このアプローチはまさにそこへ直接効きます。「また空の行を返してるぞ」というSlack通知で叩き起こされた経験があるなら、保守がいらないありがたさは身に染みているはずです。
Pythonを書かずにIndeedをスクレイピングする方法: ノーコードの代替案
世に出回る競合記事の多くは、Pythonコードを書く前提で話を進めます。けれどフォーラムをのぞくと、聞こえてくる声はだいぶ違う。*「バグとエラーが絶えず、本当に難しすぎる」*という嘆きや、いっそデータを取るためだけにFiverrで人を雇えばいい、という意見まで飛び交っています。もしそれが他人事に思えないなら、この先がまさに抜け道です。
ThunderbitでIndeedをスクレイピングする方法(手順付き)
ステップ1: ChromeウェブストアからThunderbit Chrome拡張機能をインストールします。無料で始められます。
ステップ2: ブラウザでIndeedの検索結果ページに移動します。例えば、https://www.indeed.com/jobs?q=data+analyst&l=Austin%2C+TX です。
ステップ3: ブラウザのツールバーにあるThunderbitアイコンをクリックし、次に**「AIで項目を提案」**をクリックします。ThunderbitのAIがページを解析し、求人タイトル、企業名、勤務地、給与、求人URL、投稿日などの列を自動検出します。提案された項目は確認・調整でき、不要な列を外したり、欲しい内容を自然な英語で説明して独自の列を追加したりできます。
ステップ4: **「スクレイプ」**をクリックします。Thunderbitがページからデータを抽出し、構造化された表で表示します。設定した項目を持つ求人一覧の行が見えるはずです。
サブページスクレイピングで情報を拡張する
一覧ページを取り終えたら、**「サブページをスクレイプ」**をクリックします。すると、各求人詳細ページをThunderbitが自動で巡回し、求人全文、応募条件、福利厚生、応募リンクまで拾ってきてくれます。追加設定はいりません。これは、各/viewjob?jk=<jobkey> URLを訪ねる2本目のPythonスクレイパーを書くのと同じ作業を、クリック1回に置き換えたようなものです。
ページネーションも自動処理
Indeedのクリック式ページネーションも、Thunderbitが自動でこなします。オフセットURLを手で組み立てたり、ページ送りのループを書いたりする必要はありません。ページを順々にたどり、結果をまとめて返してくれます。
お好みのツールへエクスポート
抜き出したデータは、CSV、Excel、Google スプレッドシート、Airtable、Notionへそのまま書き出せます。しかも完全無料。csv.writer()やpandas.to_csv()を自分で書く必要はありません。
PythonとThunderbitの使い分け
| シナリオ | 最適なツール |
|---|---|
| cron/Airflowによる定期自動化を含む独自データパイプライン | Python |
| 大きなコードベースへの組み込み | Python |
| 高度にカスタマイズされた解析ロジック | Python |
| 単発のリサーチや市場分析 | Thunderbit |
| 非技術系メンバーがデータを必要としている | Thunderbit |
| 403のデバッグなしですぐデータが欲しい | Thunderbit |
| 追加設定ゼロでサブページを拡張取得したい | Thunderbit |
時間の観点で並べてみると差は歴然です。Pythonのセットアップにアンチボットのデバッグを足すと、初回はとくに数時間から数日かかります。一方、同じデータがThunderbitなら2分以内。誤解しないでほしいのは、Pythonが間違っていると言いたいわけではないこと。要は、何が必要かで選べばいい、という話です。
Indeedをスクレイピングするのは合法か?知っておくべきこと
上位に並ぶIndeedスクレイピングのガイドは、なぜか合法性にほとんど触れません。けれどフォーラムでは*「Indeedのスクレイピングは合法なのか?」*という問いが繰り返し挙がる——つまり、皆が気にしている論点なんです。法的助言ではありませんが、現状を整理しておきます。
Indeedの利用規約
Indeedの利用規約(indeed.com/legal)には、何もかもを覆う「スクレイピング全面禁止」のような条項はありません。自動化を明示的に禁じているのはA.3.5節で、対象は*「Indeed Applyプロセスを自動化するために、あらゆる自動化、スクリプト、またはボットを使用すること」*。あくまでApplyフローに絞られた禁止であり、公開求人情報を受け身で読む行為まで縛るものではありません。そしてIndeedの主たる執行手段は法廷ではなく、Cloudflareチャレンジ、IPブロック、デバイスフィンガープリントといった技術的なものに置かれています。
関連する法的判例
米国でまず引かれるのがhiQ Labs対LinkedInです。第9巡回区控訴裁判所は2022年4月、公開アクセス可能なデータのスクレイピングは「CFAA(Computer Fraud and Abuse Act)に違反しない可能性が高い」と判断しました。ただし話には続きがあります。hiQはその後、従業員が偽のLinkedInプロフィールを作って利用規約に同意していた点を突かれ、契約違反の責任を負うと認定されています。
より近い時期では、Meta対Bright Data(カリフォルニア北部地区、2024年1月)がさらに踏み込んだ判断を示しました。Chen判事は、FacebookとInstagramの利用規約はログアウト状態での公開データスクレイピングを禁じていないと判示しています。その後Metaは、残る請求を自ら取り下げました。
Indeedのrobots.txt
Indeedのrobots.txtは、既定のUser-agent: *に対して/jobs/と/job/を幅広く禁止しています。ただしGooglebotとBingbotには例外があり、/viewjob?(個別求人詳細ページ)へのアクセスが明示的に許可されています。AI学習用クローラー(GPTBot、CCBot、anthropic-ai)のほうは大きく制限されています。robots.txt自体は米国で法的拘束力を持つわけではありませんが、これに従うのはベストプラクティスであり、誠実に運用している証拠にもなります。
責任あるスクレイピングの実践ガイド
- 公開されているデータだけを取得する。ログインしない、偽アカウントを作らない
- レート制限を守る。IPあたり3〜6秒に1リクエスト、同時実行は少数に抑える
- スクレイピングしたデータを自分の求人サイトとして再公開しない
- 個人利用や社内調査にとどめ、許可なく商用再販しない
- 必要のない個人情報は削除またはハッシュ化する。個人に近いデータの保持期間は最小限にする
- 大規模運用やEU/英国での運用では弁護士に相談する。個人情報保護法の透明性義務はスクレイピングした個人データにも適用されます
リスクの濃淡で言えば、個人の転職活動を自動化する程度なら低リスク。逆に、Indeedのデータを大規模に商用再販するとなれば高リスクです。
まとめと重要なポイント
PythonでIndeedをスクレイピングすること自体は可能です。ただし、週末にさっと組んで放置できるような気軽な案件ではありません。Cloudflare保護に、揺れ動くセレクタ、強力なアンチボット対策まで揃ったこの相手には、適切な道具と現実的な期待値をもって臨む必要があります。
ここまでの要点を、改めて並べておきます。
- Indeedはウェブ上で最も豊富な求人市場データのひとつです。月間3.5億人、1.3億件の求人がありますが、スクレイパーには強硬に対抗してきます。
- 非公開JSON抽出(
window.mosaic.providerData)が、Pythonでは最も堅牢な方法です。 スキーマは何年も安定している一方、CSSセレクタは毎月のように壊れます。 - 2026年のCloudflare保護サイトでは、ブラウザ偽装付きの
curl_cffiが標準的なHTTPクライアントです。 素のrequestsやhttpxはTLSフィンガープリントの時点で止められます。 - 403エラーを避けるには、ローテーションするヘッダー、ランダム遅延、レジデンシャルプロキシを必ず使いましょう。 データセンタープロキシはCloudflare Enterpriseにはほぼ通用しません。
- セレクタが壊れたとき、またはデータの代わりにチャレンジページが返ったときにすぐ気づけるよう、アサーションチェックを入れてください。
- 非技術系ユーザーや、単純に早く結果が欲しい人には、Thunderbitのようなノーコード・AI駆動の手段が、サイト変更にも自動対応できる現実的な選択肢です。プロキシ設定も、デバッグも、保守も不要です。
ノーコードを試したいなら、Thunderbitには無料プランがあるので、実際にIndeedで気軽に試せます。Pythonで進める場合でも、上のコード例は十分良い出発点です。ただし、アンチボット耐性は後回しではなく最優先事項として扱ってください。
ウェブスクレイピングの手法やツールについてもっと知りたい方は、Pythonでウェブスクレイピングする方法、おすすめの自動ウェブスクレイピングツール、ブロックされずにウェブスクレイピングする方法のガイドもご覧ください。Thunderbit YouTubeチャンネルでもチュートリアルを公開しています。
Indeedデータをより速くスクレイピングするためにThunderbitを試す Get Started Free
よくある質問
Indeedのスクレイピングに最適なPythonライブラリは何ですか?
HTTPリクエストなら、2026年時点ではcurl_cffiが頭一つ抜けています。本物のブラウザのTLSフィンガープリントを偽装でき、これがCloudflare回避に欠かせないからです。保護が緩い相手であれば、HTTP/2対応版のhttpxを代わりに使う手もあります。HTML解析では、lxmlを組み合わせたBeautifulSoup4が依然として定番。ブラウザ自動化ではplaywright-stealth付きのPlaywrightやundetected-chromedriverが候補に挙がりますが、いずれも年々検出されやすくなっています。なお、非公開JSONを正規表現で抜く方法(window.mosaic.providerData)を選べば、そもそも重い解析自体が不要になります。
Indeedをスクレイピングすると403エラーが出続けるのはなぜですか?
原因はCloudflare Bot Managementです。IndeedはこれでTLSフィンガープリント(JA3/JA4)、HTTP/2のヘッダー順、リクエストパターン、ブラウザ挙動を検査しています。素のrequestsのままだと、TLSフィンガープリントだけでPythonスクリプトと見抜かれ、ヘッダーを読まれる前に403で弾かれてしまうわけです。対処は四つ。ブラウザ偽装付きのcurl_cffiへ切り替える、自然なUser-Agentをローテーションする、ランダム遅延(3〜6秒)を入れる、そしてレジデンシャルプロキシを使う。さらに、cf-turnstileを含む「200だがチャレンジページ」のケースも忘れず確認してください。
コーディングなしでIndeedをスクレイピングできますか?
できます。Thunderbitのようなツールを使えば、数クリックでIndeedの求人一覧が手に入ります。手順はこうです——Chrome拡張機能を入れ、Indeedの検索ページを開き、**「AIで項目を提案」を押してから「スクレイプ」**をクリックするだけ。ThunderbitのAIが求人タイトル、企業名、勤務地、給与などを自動で見つけ出します。ページネーション、サブページ拡張取得(求人全文)、アンチボット対策まで、すべて自動。CSV、Google スプレッドシート、Airtable、Notionへのエクスポートも無料です。
IndeedのHTML構造はどれくらいの頻度で変わりますか?
IndeedはCSSクラス名(たとえばcss-1m4cuufのようなランダムなハッシュ文字列)を定期的に差し替え、DOM要素の構造も予告なしに組み替えます。A/Bテストの都合で、ユーザーごとに別々のレイアウトが同時並行で表示されることすらあります。その点、非公開JSON方式(window.mosaic.providerData)ははるかに安定していて、スキーマは少なくとも2023年以降ほぼ一貫しています。どうしてもDOMセレクタを使うなら、CSSクラスではなくdata-testid属性やdata-jk(job key)を頼りにしてください。
Indeedをスクレイピングするのは合法ですか?
ログアウト状態で公開されているIndeedの求人URLをスクレイピングする限り、米国では第9巡回区のhiQ対LinkedIn判決(2022年)やMeta対Bright Data判決(2024年)に照らして、CFAA違反にはなりにくいと考えられます。Indeedの利用規約が特に禁じているのも、公開求人を受け身で読む行為ではなく、Applyプロセスの自動化のほうです。とはいえ、必ず責任ある方法で。ログインしない、偽アカウントを作らない、レート制限を守る、データを自分の求人サイトとして再公開しない、そして個人データ(採用担当者名、メールアドレスなど)はGDPR/CCPAに配慮して丁寧に扱う——これが前提です。商用規模で動かすなら、弁護士に相談してください。
さらに詳しく知る




