

Google Shopping では、毎月 12億件以上の製品検索 が行われています。複数の小売店から集まる価格、商品トレンド、販売者の情報を確認できるため、EC 運営や競合調査の情報源として活用できます。
一方、検索結果を比較・分析できる形でスプレッドシートへ整理するには、取得方法の選定や設定が必要です。私は、ノーコードのブラウザー拡張から本格的な Python スクリプトまで、さまざまな方法を試してきました。短時間で設定できた方法がある一方、CAPTCHA 対応のデバッグに3日かかったこともあり、必要な技術と保守負担には大きな差があります。
Google Shopping のデータを必要とするのは、開発者だけではありません。EC 運営者、価格分析担当、マーケターなど、コードを書かずに必要な数字を取得したい担当者もいます。そこで本記事では、Google Shopping データを取得する3つの方法を難易度の低い順に比較します。目的、技術レベル、運用頻度に合う方法を選ぶ際の参考にしてください。
Google Shopping データとは?
Google Shopping は商品検索エンジンです。たとえば「ワイヤレス ノイズキャンセリング ヘッドホン」と検索すると、Google が複数のオンラインストアから商品をまとめて表示します。商品名、価格、販売店、評価、画像、リンクまで、ネット上で売られているものをリアルタイムで集めたカタログのようなものです。
なぜ Google Shopping データをスクレイピングするのか?
商品ページを1件確認するだけでは、市場全体の傾向を判断するのは困難です。数百件の商品情報を同じ項目で整理すれば、価格差、レビューの増減、販売者の変化などを比較しやすくなります。
私がよく見かける主な用途は次のとおりです。
| ユースケース | 恩恵を受ける人 | 探したい情報 |
|---|---|---|
| 競合価格分析 | EC チーム、価格分析担当 | 競合価格、値下げ傾向、価格変動の推移 |
| 商品トレンドの発見 | マーケティングチーム、プロダクトマネージャー | 新商品、伸びているカテゴリ、レビュー増加率 |
| 広告インテリジェンス | PPC 担当、成長チーム | スポンサード掲載、入札している販売者、広告の表示頻度 |
| 販売者・リード調査 | 営業チーム、B2B | 稼働中の販売者、カテゴリに新規参入した店舗 |
| MAP 監視 | ブランドマネージャー | 最低広告価格ポリシーに違反している小売店 |
| 在庫・品揃えの追跡 | カテゴリマネージャー | 在庫状況、商品ラインナップの抜け |
米国小売業者の78% は、すでに AI 対応の価格設定ツールを使っているという調査があります。競争価格のインテリジェンスに投資した企業では、最大29倍のリターンが報告されています。また、Amazon はおよそ10分ごとに価格を更新しているとされています。調査対象や算出条件によって数値は異なりますが、価格を手作業だけで継続的に追うことが難しくなっている点は共通しています。
AIで Google Shopping データをスクレイピング Get Started Free
Thunderbit は、AI を使ってウェブサイトからデータを取得できる AI Web Scraper の Chrome 拡張機能です。特に、コードを書かずに構造化された Google Shopping データを欲しい EC 運営者、価格分析担当、マーケターに向いています。
Google Shopping から実際にどんなデータを取得できるのか?
ツールを選んだり、コードを書き始めたりする前に、どの項目が取得できて、どの項目に追加作業が必要なのかを把握しておくと役立ちます。
Google Shopping の検索結果から取得できる項目
Google Shopping で検索すると、結果ページの各商品カードには次のような情報があります。
| 項目 | 型 | 例 | 備考 |
|---|---|---|---|
| 商品名 | テキスト | "Sony WH-1000XM5 Wireless Headphones" | ほぼ常に表示される |
| 価格 | 数値 | $278.00 | セール価格と通常価格の両方が出ることがある |
| 販売者 / 店舗 | テキスト | "Best Buy" | 1商品に複数の販売者が表示される場合あり |
| 評価 | 数値 | 4.7 | 5点満点。常に表示されるとは限らない |
| レビュー件数 | 数値 | 12,453 | 新商品では表示されないことがある |
| 商品画像URL | URL | https://... | 初回読み込み時は base64 のプレースホルダーになる場合あり |
| 商品リンク | URL | https://... | Google の商品ページ、または販売店の直接ページへ遷移 |
| 配送情報 | テキスト | "Free shipping" | 常にあるわけではない |
| スポンサータグ | 真偽値 | Yes/No | 広告枠かどうかの判定に役立つ |
商品詳細ページから取得できる項目(サブページデータ)
Google Shopping の各商品詳細ページを開くと、さらに詳しい情報が取得できます。
| 項目 | 型 | 備考 |
|---|---|---|
| 詳細説明 | テキスト | 商品ページへのアクセスが必要 |
| すべての販売者価格 | 数値(複数) | 複数店舗の価格比較ができる |
| 仕様情報 | テキスト | 商品カテゴリごとに内容が異なる(寸法、重量など) |
| 個別レビュー本文 | テキスト | 購入者のレビュー全文 |
| 長所 / 短所の要約 | テキスト | Google が自動生成することがある |
これらの項目を取るには、検索結果を取得したあとで各商品のサブページにアクセスする必要があります。サブページスクレイピング に対応したツールなら、この作業を自動で処理できます。下でその流れを紹介します。
Google Shopping データを取得する3つの方法(あなたに合うものを選ぶ)

ここでは、3つの方法を必要な技術レベルが低い順に整理します。単発の調査か定期運用か、コードによる制御が必要か、保守を担当できるかを基準に選んでください。
| 方法 | 難易度 | 準備時間 | ボット対策への対応 | 向いている用途 |
|---|---|---|---|---|
| ノーコード(Thunderbit Chrome 拡張) | 初心者 | 約2分 | ツール側で処理(対象ページや実行環境による) | EC 運営、マーケター、単発調査 |
| Python + SERP API | 中級 | 約30分 | API 提供元が処理 | プログラムから繰り返し使いたい開発者 |
| Python + Playwright(ブラウザー自動化) | 上級 | 約1時間以上 | 自分で設計・管理 | 独自パイプライン、例外対応が必要なケース |
方法1: コードなしで Google Shopping データを取得する(Thunderbit を使用)
- 難易度: 初心者
- 所要時間: 約2〜5分
- 必要なもの: Chrome ブラウザー、Thunderbit Chrome 拡張(無料枠で可)、Google Shopping の検索条件
コードや API キー、プロキシ設定を用意せず、Google Shopping の検索結果をスプレッドシートに整理したい場合に向く方法です。私はこの流れを非技術系のメンバーに何十回も案内してきましたが、これまで案内した範囲では、途中で進めなくなった人はいませんでした。対象ページの構成によって結果は異なるため、まずは少量の商品で取得項目を確認すると進めやすくなります。
ステップ1: Thunderbit を入れて Google Shopping を開く
Chrome ウェブストアから Thunderbit AI Web Scraper をインストールし、無料アカウントを作成します。
次に Google Shopping へ移動します。shopping.google.com に直接行ってもいいですし、通常の Google 検索結果にある Shopping タブを開いても構いません。気になる商品やカテゴリを検索しましょう。たとえば「wireless noise-cancelling headphones」のようなキーワードです。
価格、販売店、評価が並んだ商品一覧が表示されるはずです。
ステップ2: 「AI Suggest Fields」を押して列を自動検出する
Thunderbit の拡張機能アイコンをクリックしてサイドバーを開き、「AI Suggest Fields」 を押します。AI が Google Shopping ページを解析し、商品名、価格、販売者、評価、レビュー件数、画像URL、商品リンクなどの列を提案します。
提案された項目を確認してください。列名の変更、不要な列の削除、カスタム項目の追加ができます。たとえば「通貨記号を含めず、数値だけ価格を取りたい」といった場合は、その列に Field AI Prompt を追加できます。
Thunderbit のパネルには、列構成のプレビューが表示されるはずです。
ステップ3: 「Scrape」を押して結果を確認する
青い 「Scrape」 ボタンを押します。Thunderbit が、画面上に表示されている商品一覧を構造化テーブルに取り込みます。
複数ページや追加読み込みがある場合は、ページのレイアウトに応じてページ送りまたはスクロールを処理します。ただし、対象ページの構造や表示条件によって取得範囲は異なるため、実行後に件数と主要な項目を確認してください。結果が多い場合は、Cloud Scraping(高速、最大50ページまで一度に処理、Thunderbit の分散インフラ上で実行)と Browser Scraping(自分の Chrome セッションを使用。Google が地域別結果を出す場合やログインが必要な場合に便利)のどちらかを選べます。
私の検証では、50件の商品一覧のスクレイピングは約30秒で終わりました。同じ作業を手作業で行うと、商品名、価格、販売者、評価を1件ずつ開いてコピーする必要があり、20分以上かかりました。処理時間はページ構成や通信環境によって変わるため、実際の対象ページで確認してください。
ステップ4: サブページスクレイピングでデータを充実させる
最初のスクレイピングが終わったら、Thunderbit パネルで 「Scrape Subpages」 をクリックします。AI が各商品の詳細ページを巡回し、詳細説明、すべての販売者価格、仕様、レビューなどの追加項目を元のテーブルに追記します。
ページごとの個別設定を減らせる設計ですが、詳細ページの構造や表示条件によって取得結果は異なります。私はこの方法で、40商品分の競合価格マトリクス(商品名 + 全販売者価格 + 仕様)を5分未満で作成できました。定期運用へ広げる前に、まず数商品で項目の抜け、価格表記、出力形式を確認してください。
Google Shopping のスクレイピングに Thunderbit を試す
ステップ5: Google Sheets、Excel、Airtable、Notion にエクスポートする
「Export」 をクリックし、保存先を選びます。 Google Sheets、Excel、Airtable、Notion に対応しています。すべて無料です。CSV と JSON のダウンロードも可能です。
スクレイピングは2クリック、エクスポートは1クリックです。一方、Python で同等の処理を構築する場合は、構成によって60行前後のコードに加え、プロキシ設定、CAPTCHA 対応、継続的な保守が必要になることがあります。コードによる細かな制御が必要か、設定と保守の負担を減らしたいかで選ぶとよいでしょう。
方法2: Python + SERP API で Google Shopping データを取得する
- 難易度: 中級
- 所要時間: 約30分
- 必要なもの: Python 3.10 以上、
requestsとpandasライブラリ、SERP API キー(ScraperAPI、SerpApi など)
プログラムから繰り返し Google Shopping データへアクセスしたい場合、SERP API は有力な選択肢です。多くのサービスでは、ボット対策、JavaScript レンダリング、プロキシローテーションを API 側で処理し、HTTP リクエストに対して構造化された JSON を返します。対応範囲、料金、返却項目は提供元ごとに異なるため、実装前に仕様を確認してください。
ステップ1: Python 環境を準備する
Python 3.12 をインストールし(2025〜2026年の本番環境で無難な選択)、必要なパッケージを入れます。
pip install requests pandas
SERP API 提供元に登録します。SerpApi は月250回の無料検索があり、ScraperAPI は5,000の無料クレジットがあります。ダッシュボードから API キーを取得してください。
ステップ2: API リクエストを設定する
以下は ScraperAPI の Google Shopping エンドポイントを使った最小例です。
import requests
import pandas as pd
API_KEY = "YOUR_API_KEY"
query = "wireless noise cancelling headphones"
resp = requests.get(
"https://api.scraperapi.com/structured/google/shopping",
params={"api_key": API_KEY, "query": query, "country_code": "us"}
)
data = resp.json()
API からは title、price、link、thumbnail、source(販売者)、rating といった項目を含む構造化 JSON が返ります。
ステップ3: JSON 応答を解析して項目を取り出す
products = data.get("shopping_results", [])
rows = []
for p in products:
rows.append({
"title": p.get("title"),
"price": p.get("price"),
"seller": p.get("source"),
"rating": p.get("rating"),
"reviews": p.get("reviews"),
"link": p.get("link"),
"thumbnail": p.get("thumbnail"),
})
df = pd.DataFrame(rows)
ステップ4: CSV または JSON に出力する
df.to_csv("google_shopping_results.csv", index=False)
バッチ処理にも向いています。50個のキーワードをループして、1回のスクリプト実行で大きなデータセットを作れます。ただし、その分コストはかかります。SERP API はクエリごとに課金されるため、1日に数千件になると料金が増えていきます。料金については後ほど説明します。
方法3: Python + Playwright で Google Shopping データを取得する(ブラウザー自動化)
- 難易度: 上級
- 所要時間: 約1時間以上(加えて継続メンテナンス)
- 必要なもの: Python 3.10 以上、Playwright、住宅用プロキシ、継続的な保守体制
この方法では、実ブラウザーを起動して Google Shopping にアクセスし、レンダリング後のページからデータを取得します。処理を細かく制御できる一方、ボット対策への対応やページ構造の変更に合わせた保守が必要です。
私は、CAPTCHA や IP ブロックへの対応に何週間も費やしていたユーザーを何人も見てきました。実装自体は可能ですが、導入時の開発だけでなく、稼働後の監視と修正に必要な工数も見込んでください。
ステップ1: Playwright とプロキシを設定する
pip install playwright
playwright install chromium
この構成では住宅用プロキシを使用します。データセンター IP はブロックされやすく、あるフォーラムでは「AWS の IP はすべてブロックされるか、1〜2件取得したら CAPTCHA に遭遇する」という報告もありました。Bright Data、Oxylabs、Decodo などのサービスでは、住宅用プロキシプールをおよそ $1〜5/GB から利用できます。
ブラウザーに近い user-agent とプロキシを設定します。
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch(
headless=True,
proxy={"server": "http://your-proxy:port", "username": "user", "password": "pass"}
)
context = browser.new_context(
user_agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 ..."
)
page = context.new_page()
ステップ2: Google Shopping に移動し、ボット対策に対応する
Google Shopping の URL を作って移動します。
query = "wireless noise cancelling headphones"
url = f"https://www.google.com/search?udm=28&q={query}&gl=us&hl=en"
page.goto(url, wait_until="networkidle")
EU の Cookie 同意ポップアップが出る場合は処理します。
try:
page.click("button#L2AGLb", timeout=3000)
except:
pass
操作の間には人間らしい遅延を入れます。ページ読み込みの間隔を2〜5秒ほどランダムに空けてください。Google の検出システムは、速くて一定のリクエストパターンを不審に見ます。
ステップ3: スクロール・ページ送り・商品データ取得
Google Shopping は結果を動的に読み込みます。スクロールして遅延読み込みを発動させ、そのあと商品カードを取得します。
import time, random
# スクロールして全件読み込む
for _ in range(3):
page.evaluate("window.scrollBy(0, 1000)")
time.sleep(random.uniform(1.5, 3.0))
# 商品カードを取得
cards = page.query_selector_all("[jsname='ZvZkAe']")
results = []
for card in cards:
title = card.query_selector("h3")
price = card.query_selector("span.a8Pemb")
# ... 他の項目を取得
results.append({
"title": title.inner_text() if title else None,
"price": price.inner_text() if price else None,
})
重要な注意点です。上の CSS セレクタはあくまで目安で、変更される可能性があります。Google はクラス名を頻繁に変えます。2024〜2026年だけでも、3種類の異なるセレクタ構成が確認されています。クラス名よりも、jsname、data-cid、<h3> タグ、img[alt] のような比較的安定した属性を基準にしましょう。
ステップ4: CSV または JSON に保存する
import json
from datetime import datetime
filename = f"shopping_{datetime.now().strftime('%Y%m%d_%H%M')}.json"
with open(filename, "w") as f:
json.dump(results, f, indent=2)
このスクリプトは定期的な保守が必要になると考えてください。Google がページ構造を変えるたびに、つまり年に何回もセレクタが壊れ、そのたびにデバッグし直すことになります。
最大の悩みどころ: CAPTCHA とボット対策ブロック
関連フォーラムでは、数週間試したものの、Google のボット対策への継続対応が難しく、運用を断念したという投稿が見られます。CAPTCHA と IP ブロックは、自作の Google Shopping スクレイパーを継続運用する際の主要な課題です。
Google はどうやってスクレイパーをブロックするのか?
| ボット対策 | Google が行うこと | 回避策 |
|---|---|---|
| IP フィンガープリント | 数回のリクエスト後にデータセンター IP をブロック | 住宅用プロキシ、またはブラウザー型スクレイピング |
| CAPTCHA | 高速・自動化されたリクエストパターンで発生 | レート制限(リクエスト間を10〜20秒空ける)、人間らしい遅延、CAPTCHA 解決サービス |
| JavaScript レンダリング | Shopping の結果は JS で動的に読み込まれる | ヘッドレスブラウザー(Playwright)または JS をレンダリングする API |
| user-agent 判定 | よくあるボット UA をブロック | 現実的で最新の user-agent 文字列をローテーション |
| TLS フィンガープリント | ブラウザーではない TLS 特徴を検出 | curl_cffi を使ったブラウザー偽装、または実ブラウザーの利用 |
| AWS / クラウド IP ブロック | 既知のクラウド事業者 IP をブロック | データセンター IP は使わない |
2025年1月、Google は SERP と Shopping の結果で JavaScript 実行を必須にし、多くの静的 HTML スクレイパーを壊しました。SemRush や SimilarWeb が使っていたパイプラインも影響を受けたとされています。さらに2025年9月には、Google が旧来の商品詳細ページ URL を廃止し、新しい「Immersive Product」画面へリダイレクトするようになり、非同期 AJAX で読み込む構成へ変わったとされています。そのため、2025年後半より前のチュートリアルは、現行画面ではそのまま動かない可能性があります。
各方法はこれらの問題にどう対応するか
SERP API は、プロキシ、レンダリング、CAPTCHA 対応を API 側で処理するサービスです。対応範囲や成功率は提供元、対象地域、利用プランによって異なります。
Thunderbit の Cloud Scraping は、米国、EU、アジアにまたがる分散クラウド基盤を使い、JS レンダリングとボット対策を処理します。Browser Scraping モードは、自分の認証済み Chrome セッションを使うため、地域別表示やログイン後のページを扱う場合の候補になります。ただし、どちらの方式でも対象サイトの規約と取得結果を確認する必要があります。
自作の Playwright では、プロキシ管理、遅延調整、CAPTCHA 対応、セレクタ保守、動作不良の監視を自分で設計・運用します。細かな制御が必要な場合に向く一方、その分の保守工数を見込む必要があります。
Google Shopping データ取得にかかる本当のコスト: 正直な比較
約2万リクエストで50ドルという料金を、個人プロジェクトには高いと感じる利用者もいます。ただし、方法を比較する際は API やプロキシの料金だけでなく、初期実装、障害対応、継続的な保守にかかる時間も含めて考える必要があります。
コスト比較表
| 方法 | 初期費用 | 1クエリあたりの費用(概算) | 保守負担 | 見えにくいコスト |
|---|---|---|---|---|
| DIY Python(プロキシなし) | 無料 | $0 | 高い(壊れやすさ、CAPTCHA) | デバッグに費やす自分の時間 |
| DIY Python + 住宅用プロキシ | コードは無料 | 約$1〜5/GB | 中〜高 | プロキシ事業者の料金 |
| SERP API(SerpApi、ScraperAPI) | 無料枠は限定的 | 約$0.50〜5.00 / 1K クエリ | 低い | 大量利用で一気に高くなる |
| Thunderbit Chrome 拡張 | 無料枠(6ページ) | クレジット制、約1クレジット/行 | 非常に低い | 大量処理には有料プランが必要 |
| Thunderbit Open API(Extract) | クレジット制 | 約20クレジット/ページ | 低い | 取得ごとの従量課金 |
みんなが見落としがちな隠れコスト: あなたの時間
DIY の方法はツール料金が $0 でも、デバッグに40時間かかれば実質的なコストが発生します。時給50ドルで計算すると、人件費は2,000ドルです。さらに、Google の DOM が変われば、翌月に修正が必要になる可能性もあります。

McKinsey の Technology Outlook によると、自作と購入の損益分岐点は、1日あたり360万リクエストを超えたあたり にあります。それ以下では、社内構築の開発・保守費用が投資効果に見合わない場合があります。週に数百〜数千件程度の検索を行う EC チームでは、ノーコードツール、SERP API、自社開発の費用を、処理量と必要な制御範囲に合わせて比較するとよいでしょう。
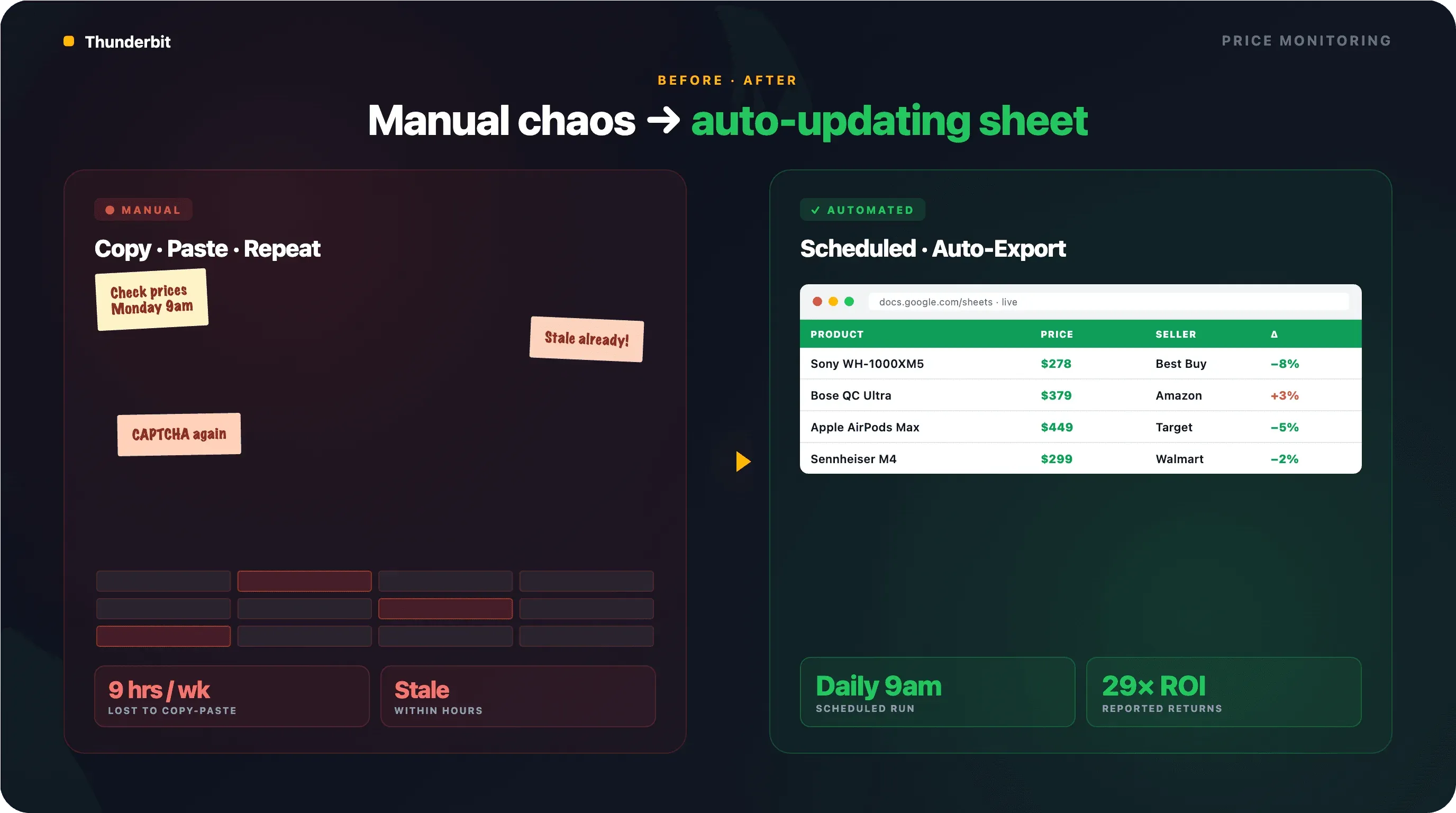
Google Shopping の価格監視を自動化する方法
Google Shopping のスクレイピングを価格監視に使う場合、1回だけ取得するのではなく、同じ条件で定期的にデータを蓄積する必要があります。日次または週次で価格を記録すると、値下げ、値上げ、販売者の入れ替わりなどの変化を比較できます。
Thunderbit で定期スクレイピングを設定する
Thunderbit の Scheduled Scraper では、「毎日午前9時」や「毎週月曜と木曜の正午」といったように、自然な文章で間隔を指定できます。AI がその指定を繰り返し実行するスケジュールに変換します。Google Shopping の URL を入力し、「Schedule」 をクリックして設定します。
実行のたびに、Google Sheets、Airtable、Notion へ自動でエクスポートできます。競合価格を継続的に蓄積し、ピボットテーブルやアラートに使う場合に便利です。運用前には、対象 URL で必要な商品が取得できるか、同一商品の照合方法、実行頻度、出力先の更新方法を確認してください。
この方法は、cron ジョブ、サーバー、Lambda 関数を自分で管理せずに定期実行したい場合に向いています。私は、AWS Lambda で Selenium を動かすために何日も対応していた開発者の投稿を見たことがあります。独自の実行基盤や細かな障害処理が必要な場合は、開発者向けの方法も比較してください。
価格監視ワークフロー の作り方については、別の記事で詳しく解説しています。
Python でスケジュールする場合(開発者向け)
SERP API を使うなら、cron ジョブ(Linux/Mac)、Windows Task Scheduler、AWS Lambda や Google Cloud Functions のようなクラウドスケジューラーで実行できます。APScheduler のような Python ライブラリも使えます。
この構成では、スクリプトの稼働監視、失敗時の再実行、プロキシのローテーション、Google のページ変更に合わせたセレクタ更新を運用側で設計します。実行規模や必要なカスタマイズによっては自社運用が適していますが、保守担当者の工数を含めて専用ツールの費用と比較する必要があります。
Google Shopping データをスクレイピングする際のヒントとベストプラクティス
方法が何であれ、少し気をつけるだけで手間がかなり減ります。
レート制限を守る
Google に対して短時間に大量のリクエストを送ると、アクセス制限や CAPTCHA が発生する可能性があります。DIY の場合は、リクエスト間を10〜20秒空け、一定間隔にならないよう調整する方法があります。ツールや API を使う場合も、提供元の仕様だけでなく、対象サイトの利用規約と適切なアクセス頻度を確認してください。
データ量に合う方法を選ぶ
簡単な目安は次のとおりです。
- 週10件未満 → Thunderbit の無料枠、または SerpApi の無料枠
- 週10〜1,000件 → SERP API の有料プラン、または Thunderbit の有料プラン
- 週1,000件超 → SERP API のエンタープライズプラン、または Thunderbit Open API
データを整形・検証する
価格には通貨記号、地域ごとの表記差(1.299,00 € と $1,299.00 のような違い)、ときどき不要な文字が含まれます。Thunderbit の Field AI Prompts で取得時に正規化するか、あとで pandas で整えましょう。
df["price_num"] = df["price"].str.replace(r"[^\d.]", "", regex=True).astype(float)
自然検索とスポンサード掲載の間で重複があるか確認してください。かなりの頻度で重なります。(title, price, seller) の組で重複排除するとよいです。
法的な位置づけを理解する
公開されている商品データであっても、スクレイピングが一律に合法とは限りません。対象となるデータ、取得方法、利用目的、契約条件、地域によって判断が異なります。最近の重要な動きとして、Google が 2025年12月に SerpApi を提訴しました 。DMCA §1201 に基づき、Google の「SearchGuard」対スクレイピングシステムを回避したとして争っています。これは、hiQ v. LinkedIn や Van Buren v. United States のような過去の判例とは異なる論点を含む可能性があります。
実務上の目安:
- 公開されているデータを対象にし、制限されたコンテンツへアクセスするためのログインや技術的制限の回避は行わない
- 個人情報(レビュー投稿者名、アカウント詳細)を必要なく抽出しない
- Google の利用規約では自動アクセスが禁止されている点を確認する — SERP API やブラウザー拡張を使っても、利用者側の法的・契約上のリスクがなくなるわけではない
- EU で運用する場合は GDPR の適用可能性も確認する。商品一覧が中心でも、レビュー投稿者などの情報が含まれる場合は個人データになり得る
- 取得したデータを使って商用製品を作るなら、対象地域の法律に詳しい専門家への相談を検討する
Web スクレイピングの法的論点 については、別記事で詳しく扱っています。
Google Shopping データのスクレイピングにはどの方法を使うべきか?
同じ商品カテゴリに対して3つの方法を試した結果、用途別の選び方は次のとおりです。
非技術系で、すぐにデータが必要な人 — Thunderbit が候補になります。Google Shopping を開き、2回クリックしてスプレッドシートを作成できます。無料枠 で少量の商品を試し、取得項目、精度、出力形式を確認してください。サブページスクレイピングは、複数の販売者価格や仕様まで確認したい場合に向いています。
繰り返し使えるプログラムからのアクセスが必要な開発者 — SERP API が候補になります。クエリごとの料金は発生しますが、ボット対策やプロキシ管理を API 提供元に任せられます。ドキュメントの分かりやすさでは SerpApi、無料枠では ScraperAPI が有利と考えられますが、導入前に現在の料金と仕様を比較してください。
最大限の制御が必要で、独自パイプラインを作っている人 — Playwright を検討できます。ただし、プロキシ管理、セレクタ保守、CAPTCHA 対応の運用工数が必要です。2025〜2026年時点では、curl_cffi による Chrome 偽装、住宅用プロキシ、10〜20秒の間隔を組み合わせる構成が最低限必要とされています。単純な requests スクリプトに user-agent ローテーションを加えるだけでは、安定運用が難しい場合があります。
選定時は、取得精度だけでなく、週あたりの処理量、必要な制御範囲、保守担当者の有無を比較してください。コードを書かずに始めたい場合は、まず少量の商品で Thunderbit の結果を確認し、要件を満たさない場合に SERP API や自作パイプラインを検討すると進めやすくなります。
大量処理が必要なら Thunderbit の料金ページ を確認してください。実際の流れを見たい方は、Thunderbit YouTube チャンネル のチュートリアルもおすすめです。
Google Shopping のスクレイピングに Thunderbit を試す Get Started Free
FAQ
Google Shopping データをスクレイピングするのは合法ですか?
公開されている商品データであっても、スクレイピングが一律に合法とは断定できません。hiQ v. LinkedIn や Van Buren v. United States などの判例は参考になりますが、対象データ、アクセス方法、利用目的、契約条件によって判断は異なります。Google の利用規約では自動アクセスが禁止されており、Google が 2025年12月に SerpApi を提訴したことで、DMCA §1201 に基づく回避禁止の論点も注目されています。ツールや API を使っても利用者の法的・契約上の責任がなくなるわけではありません。商用利用では専門家に相談してください。
ブロックされずに Google Shopping をスクレイピングできますか?
どの方法でも、ブロックされないことを保証することはできません。SERP API はボット対策を API 側で処理します。Thunderbit の Cloud Scraping は分散インフラを利用し、Browser Scraping モードは自分の Chrome セッションを使うため、地域別表示やログイン後ページを扱う場合の候補になります。DIY の Python スクリプトでは、住宅用プロキシ、リクエスト間隔、TLS フィンガープリントなどを自分で管理する必要があり、それでもアクセス制限を受ける可能性があります。いずれの方法でも、対象サイトの利用規約と適切なアクセス頻度を確認してください。
Google Shopping データを取得する最も簡単な方法は?
コードを使わずに始めたい場合は、Thunderbit の Chrome 拡張が候補になります。Google Shopping に移動し、「AI Suggest Fields」を押して、「Scrape」を押し、Google Sheets か Excel にエクスポートします。コーディング、API キー、プロキシ設定は不要です。全体で約2分という目安がありますが、まず少量の商品で取得項目と出力結果を確認してください。
価格監視のために Google Shopping をどのくらいの頻度でスクレイピングできますか?
Thunderbit の Scheduled Scraper なら、自然な文章で日次・週次・任意間隔の監視を設定できます。SERP API の場合は、プランのクレジット上限によります。多くの提供元は、数百SKU程度の毎日監視には十分な枠があります。DIY スクリプトはインフラが許す限り高頻度で回せますが、頻度を上げるほどボット対策の面倒も増えます。
Google Shopping データを Google Sheets や Excel に出力できますか?
はい。Thunderbit は Google Sheets、Excel、Airtable、Notion に直接無料で出力できます。Python スクリプトは CSV や JSON に書き出し、その後、表計算ツールへ取り込めます。継続的な価格監視では、Thunderbit から Google Sheets へ定期エクスポートする方法が候補になります。ただし、運用前に現在のプラン条件、更新方法、重複処理を確認し、出力された価格と商品数を定期的に検証してください。
- さらに詳しく




