ターゲットを絞った営業リストを作りたい、新しい市場を開拓したい、競合をベンチマークしたい——そんなとき、Googleマップがどれだけ貴重な情報源かは、もうご存じかもしれません。しかも、毎月15億件以上の「近くの」検索があり、ローカル検索をした人の76%が24時間以内に店舗を訪れる()ことを考えると、最新の位置情報ベースのビジネスデータへの需要はかつてないほど高まっています。
営業、マーケティング、オペレーションのどの立場でも、Googleマップから構造化データを抽出できれば、ただのコールドコールを確度の高い温かいリードに変えられるかもしれません。
私はSaaSと自動化の分野で長く仕事をしてきましたが、チームがPython(そして今では、のようなAI搭載ツール)を使ってGoogleマップを戦略資産に変えている場面を何度も見てきました。
このガイドでは、2026年にPythonでGoogleマップのデータをスクレイピングする方法を、コード、コンプライアンスの注意点、ノーコードソリューションとの比較まで含めて、ステップごとにわかりやすく解説します。Pythonに慣れている方も、とにかく最短で実用データを手に入れたい方も、ぜひ読み進めてください。
PythonでGoogleマップをスクレイピングするとはどういうことか?
まず基本から見ていきましょう。PythonでGoogleマップをスクレイピングするとは、名前、住所、評価、レビュー、電話番号、座標などのビジネス情報をプログラムで抽出し、分析・絞り込み・書き出しして業務に活用できるようにすることです。

主な方法は2つあります。
- Googleマップ Places API:公式でライセンスされた方法です。APIキーを使ってGoogleのサーバーに問い合わせ、構造化されたJSONデータを取得します。安定していて予測しやすく、基本的には規約に沿っていますが、利用枠と費用が発生します。
- HTMLをWebスクレイピングする方法:PlaywrightやSeleniumのようなツールでブラウザを自動操作し、Googleマップを開いて検索し、表示されたページを解析します。柔軟性は高いものの、Googleは頻繁にサイト構造を変更するため壊れやすく、HTMLのスクレイピングはGoogleの利用規約に抵触する可能性があります。
よく抽出されるデータ項目:
- 店舗名
- カテゴリ/業種
- 住所全体(市、州、郵便番号、国を含む)
- 緯度・経度
- 電話番号
- WebサイトURL
- 評価とレビュー数
- 価格帯
- 営業状態(営業中/閉業)
- 営業時間
- Place ID(Google独自の識別子)
- GoogleマップURL
なぜ重要なのか? これらの項目は、リード獲得や営業エリアの設計から、競合比較、市場調査まであらゆる用途を支えます。大切なのは、ビジネス目標に合ったデータを狙うことです。やみくもにスクレイピングするのは避けましょう。
営業・マーケティングチームがPythonでGoogleマップのデータを抽出する理由
少し実務寄りに見てみましょう。なぜ2026年の営業・マーケティングチームは、ここまでGoogleマップのデータに注目しているのでしょうか?
- リード獲得:連絡先や評価付きの、地域密着型の企業リストを作成し、アウトリーチ施策に活用できます。
- エリア設計:実際の事業密度や業種に基づいて、営業区域、配送エリア、サービス範囲を可視化できます。
- 競合モニタリング:競合の所在地、評価、レビューを時系列で追い、傾向や機会を見つけられます。
- 市場調査:業種、営業時間、レビューの感情傾向を分析し、Go-to-Market戦略に反映できます。
- 出店候補地の選定:不動産や小売では、周辺施設、通行量、競合状況をもとに候補地を評価できます。
実際のインパクト: によると、営業組織の92%がAI/データ投資の拡大を計画しており、地域特化データを使うチームは、一般的なコールドリストに頼る場合と比べて成約率が最大8倍高いとされています()。あるフランチャイズのリード獲得調査では、Googleマップベースのリードリストに1ドル投じるごとに15ドルの新規売上が生まれたという結果もありました。
ビジネス目標とGoogleマップの項目の対応表:
| ビジネス目標 | 必要なGoogleマップ項目 |
|---|---|
| 地域リードリスト | name, address, phone, website, category |
| エリア設計 | name, lat/lng, business_status, opening_hours |
| 競合ベンチマーク | name, rating, userRatingCount, priceLevel, reviews |
| 出店候補地の選定 | category, lat/lng, review density, openingDate |
| 感情分析/メニュー情報 | reviews, editorialSummary, photos, types |
| メール/電話アウトリーチ | nationalPhoneNumber, websiteUri(必要に応じて追加で補完) |
PythonのGoogleマップスクレイパーを準備する:ツールと要件
スクレイピングを始める前に、Python環境を整え、必要なツールをそろえておく必要があります。2026年時点で必要なものは次のとおりです。
1. Pythonと必要なライブラリをインストールする
推奨Pythonバージョン: 3.10以上。
主要ライブラリをインストール:
1pip install \
2 requests==2.33.1 httpx==0.28.1 \
3 beautifulsoup4==4.14.3 lxml==6.0.3 \
4 pandas==2.3.3 \
5 selenium==4.43.0 playwright==1.58.0 \
6 googlemaps==4.10.0 google-maps-places==0.8.0 \
7 schedule==1.2.2 APScheduler==3.11.2 \
8 python-dotenv==1.2.2 tenacity==9.1.4
9playwright install chromium各ライブラリの役割:
requests,httpx:HTTPリクエスト(API呼び出し)beautifulsoup4,lxml:HTML解析(Webスクレイピング用)pandas:データの整形、分析、出力selenium,playwright:ブラウザ自動化(HTMLスクレイピング用)googlemaps,google-maps-places:GoogleマップAPIクライアントschedule,APScheduler:タスクのスケジューリングpython-dotenv:.envファイルからAPIキーを安全に読み込むtenacity:エラー処理のためのリトライロジック
2. GoogleマップのAPIキーを取得する(APIベースのスクレイピング用)
- にアクセスします。
- プロジェクトを作成または選択します。
- 課金を有効にします(無料枠でも必要です)。
- APIs & Services > Library で「Places API (New)」を有効にします。
- Credentials > Create Credentials > API Key に進みます。
- セキュリティのため、特定のAPIとIPにキーを制限します。
- APIキーは
.envファイルに保存します(コードに直接コミットしないでください)。
1GOOGLE_MAPS_API_KEY=your_actual_api_key_here注: 2025年3月時点で、Googleは月額200ドルの一律無料クレジットを提供していません。代わりに、API階層ごとに月間の無料しきい値が設定されています(を参照)。
PythonでGoogleマップからデータを抽出する方法:ステップごとのガイド
ここでは、2つの主要なアプローチ——APIベースとHTMLスクレイピング——を順番に見ていきます。用途に合う方法を選びましょう。
アプローチ1:Googleマップ Places API を使う(推奨)
STEP 1: 必要なライブラリをインストールして読み込む
1import os
2import httpx
3import pandas as pd
4from dotenv import load_dotenvSTEP 2: APIキーを安全に読み込む
1load_dotenv()
2API_KEY = os.environ["GOOGLE_MAPS_API_KEY"]STEP 3: 検索クエリを作成する
Text Search エンドポイントを使って、条件に合う店舗を探します。
1URL = "https://places.googleapis.com/v1/places:searchText"
2FIELD_MASK = ",".join([
3 "places.id", "places.displayName", "places.formattedAddress",
4 "places.location", "places.rating", "places.userRatingCount",
5 "places.priceLevel", "places.types",
6 "places.nationalPhoneNumber", "places.websiteUri",
7 "nextPageToken",
8])STEP 4: APIリクエストを送信する
1def text_search(query, lat, lng, radius=3000, min_rating=4.0):
2 body = {
3 "textQuery": query,
4 "minRating": min_rating, # サーバー側フィルター
5 "includedType": "restaurant",
6 "openNow": False,
7 "pageSize": 20,
8 "locationBias": {
9 "circle": {
10 "center": {"latitude": lat, "longitude": lng},
11 "radius": radius,
12 }
13 },
14 }
15 headers = {
16 "Content-Type": "application/json",
17 "X-Goog-Api-Key": API_KEY,
18 "X-Goog-FieldMask": FIELD_MASK, # 必ず設定してください
19 }
20 r = httpx.post(URL, json=body, headers=headers, timeout=30)
21 r.raise_for_status()
22 return r.json()STEP 5: ページネーションを処理して結果を集める
1def collect_all_results(query, lat, lng, radius=3000, min_rating=4.0):
2 results = []
3 next_page_token = None
4 while True:
5 data = text_search(query, lat, lng, radius, min_rating)
6 places = data.get('places', [])
7 results.extend(places)
8 next_page_token = data.get('nextPageToken')
9 if not next_page_token:
10 break
11 return resultsSTEP 6: Pandasでデータを書き出す
1df = pd.DataFrame(collect_all_results("ブルックリンのコーヒーショップ", 40.6782, -73.9442))
2df.to_csv("brooklyn_coffee_shops.csv", index=False)実践ポイント:
- コスト管理のために、必ず
X-Goog-FieldMaskヘッダーを設定してください。レビューや写真を要求すると、1,000リクエストあたりの料金が5ドルから25ドルに上がることがあります()。 minRating、includedType、locationBiasのようなサーバー側フィルターを使うと、不要な結果にクレジットを使わずに済みます。- 重複排除や将来の更新のために、
place_idをキャッシュしておきましょう。
アプローチ2:GoogleマップのHTMLをWebスクレイピングする(学習用途/単発用途向け)
警告: Googleマップはシングルページアプリです。PlaywrightやSeleniumのようなブラウザ自動化が必須であり、HTMLのスクレイピングはGoogleの利用規約に違反する可能性があります。これは研究用途にとどめ、本番運用では使わないでください。
STEP 1: Playwrightをインストールしてブラウザを起動する
1from playwright.sync_api import sync_playwright
2import time, re
3def scrape_maps(query, max_results=100):
4 with sync_playwright() as pw:
5 browser = pw.chromium.launch(headless=True)
6 ctx = browser.new_context(
7 user_agent="Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36",
8 locale="en-US",
9 )
10 page = ctx.new_page()
11 page.goto("https://www.google.com/maps", timeout=60_000)
12 page.fill("#searchboxinput", query)
13 page.click('button[aria-label="Search"]')
14 page.wait_for_selector('div[role="feed"]')
15 feed = page.locator('div[role="feed"]')
16 prev = 0
17 while True:
18 feed.evaluate("el => el.scrollBy(0, el.scrollHeight)")
19 time.sleep(2)
20 count = page.locator('div[role="feed"] > div > div[jsaction]').count()
21 if count == prev or count >= max_results:
22 break
23 prev = count
24 if page.locator("text=You've reached the end of the list").count():
25 break
26 rows = []
27 cards = page.locator('div[role="feed"] > div > div[jsaction]')
28 for i in range(cards.count()):
29 c = cards.nth(i)
30 name = c.locator("div.fontHeadlineSmall").inner_text() if c.locator("div.fontHeadlineSmall").count() else ""
31 rating_el = c.locator('span[role="img"]').first
32 raw = rating_el.get_attribute("aria-label") if rating_el.count() else ""
33 m = re.search(r"([\d.]+)\s+stars?\s+([\d,]+)\s+Reviews", raw or "")
34 rating = float(m.group(1)) if m else None
35 reviews = int(m.group(2).replace(",", "")) if m else None
36 rows.append({"name": name, "rating": rating, "reviews": reviews})
37 browser.close()
38 return rowsヒント:
- Googleは数週間ごとにCSSクラスをランダム化するため、このコードは定期的な更新が必要になる場合があります。
- 人間らしい間隔を空け、速すぎるスクレイピングは避けることで、ブロックされるリスクを下げられます。
- CAPTCHAやGoogleのSearchGuardシステムを回避しようとしないでください。法的リスクを招くおそれがあります。
やみくもなスクレイピングを避ける:必要なデータを的確に絞り込む方法
何でもかんでも取得するのは、時間の無駄と肥大化したデータセットを生むだけです。大事なのは、本当に必要なデータだけを狙うことです。
- ターゲットを絞ったURLリストを作る:Googleマップ自体の検索フィルター(カテゴリ、場所、評価、営業中など)を使って、スクレイピング前に結果を絞り込みます。
- フレーズ一致を使う:正確な業種名やキーワードで検索します(例:「オースティンのヴィーガンベーカリー」)。
- 位置情報フィルター:市区町村、エリア名、さらには座標と半径まで指定して、ピンポイントで抽出します。
- サーバー側フィルタリング(API):APIリクエストの本文で
minRating、includedType、locationBiasを使います。 - クライアント側フィルタリング(Python):スクレイピング後に pandas で、評価が4.0以上、レビューが50件超、特定カテゴリなどの条件で絞り込みます。
例:マンハッタンのレストランのうち、評価4.0以上だけに絞る
1df = pd.DataFrame(results)
2filtered = df[(df['rating'] >= 4.0) & (df['types'].apply(lambda x: 'restaurant' in x))]
3filtered.to_csv("manhattan_top_restaurants.csv", index=False)PythonライブラリでGoogleマップのデータを整理・書き出しする
データを取得したら、チームで使えるように整形・分析・出力していきましょう。
Pandasでデータをクレンジングして構造化する
1import pandas as pd
2df = pd.read_json("brooklyn_restaurants.json")
3df = (
4 df.dropna(subset=["name", "address"])
5 .drop_duplicates(subset=["place_id"])
6 .assign(
7 name=lambda d: d["name"].str.strip(),
8 phone=lambda d: d["phone"].astype(str)
9 .str.replace(r"\D", "", regex=True)
10 .str.replace(r"^1?(\d\{10\})$", r"+1\1", regex=True),
11 rating=lambda d: pd.to_numeric(d["rating"], errors="coerce"),
12 user_ratings_total=lambda d: pd.to_numeric(
13 d["user_ratings_total"], errors="coerce"
14 ).fillna(0).astype("int32"),
15 )
16)データを分析・要約する
例:地域ごとの平均評価
1by_neighborhood = (
2 df.groupby("neighborhood", as_index=False)
3 .agg(avg_rating=("rating", "mean"),
4 n_places=("place_id", "nunique"),
5 median_reviews=("user_ratings_total", "median"))
6 .sort_values("avg_rating", ascending=False)
7)ExcelまたはCSVに書き出す
1df.to_csv("brooklyn_top.csv", index=False)
2df.to_excel("brooklyn_top.xlsx", index=False, sheet_name="Top Rated")大量データなら? 速度とサイズ効率のためにParquet形式を使いましょう。
1df.to_parquet("brooklyn_top.parquet", compression="zstd")Thunderbit:PythonのGoogleマップスクレイパーに代わるAI搭載ソリューション
ここまで読んで、「単純なリードリストを作るだけなのに、準備が大変すぎる」と感じた方もいるかもしれません。まさにそのために私たちはを作りました。Thunderbitは、AI搭載のノーコードWebスクレイパーで、Googleマップのデータをはじめとするさまざまな情報を、数クリックで簡単に抽出できます。
Thunderbitが選ばれる理由
- コーディングもAPIキーも不要: を開いてGoogleマップに移動し、「AIで項目を提案」をクリックするだけです。
- AIによる項目検出:ThunderbitのAIがページを読み取り、名前、住所、評価、電話番号、Webサイトなど、適切な列を提案します。
- サブページのスクレイピング:各店舗のWebサイトの情報も加えて表を充実させたいですか? Thunderbitなら各サブページを巡回して、追加情報を自動で取得できます。
- Excel、Googleスプレッドシート、Airtable、Notionへ出力:もう pandas と格闘する必要はありません。「エクスポート」をクリックするだけで、チームですぐ使える状態になります。
- スケジュールスクレイピング:競合のモニタリングやリードリストの更新を自動化する定期ジョブを設定できます。
- メンテナンスほぼ不要:ThunderbitのAIはサイト変更に合わせて適応するため、壊れたスクリプトを何度も直す必要がありません。
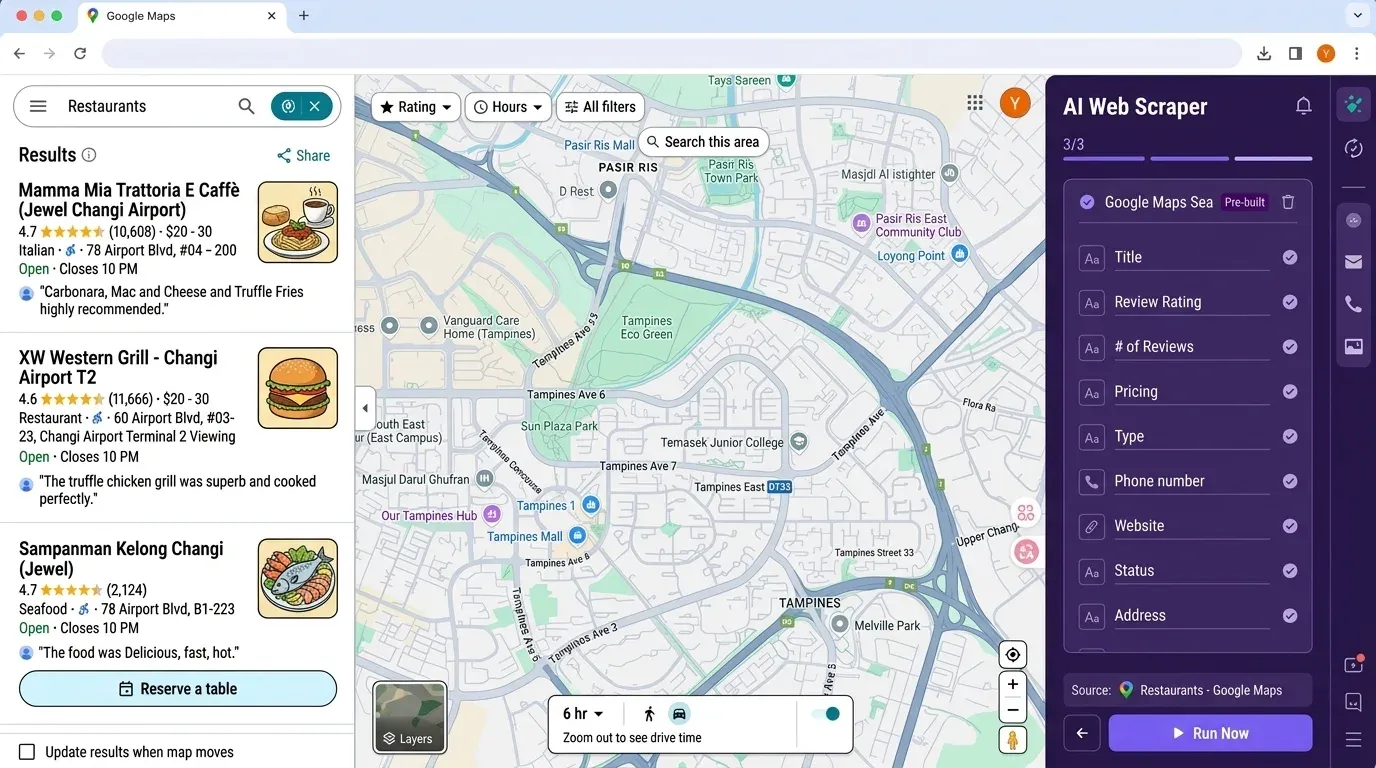
ThunderbitとPythonのワークフロー比較:
| 手順 | Pythonスクレイパー | Thunderbit |
|---|---|---|
| ツールの導入 | 30〜60分(Python、pip、ライブラリ) | 2分(Chrome拡張機能) |
| APIキー設定 | 10〜30分(Cloud Console) | 不要 |
| 項目選択 | 手動コード、フィールドマスク | AIで項目を提案(1クリック) |
| データ抽出 | スクリプト作成・実行、エラー対応 | 「スクレイプ」をクリック |
| 出力 | pandasでCSV/Excelへ | Excel/Sheets/Notionへエクスポート |
| 保守 | サイト変更時に手動更新 | AIが自動で適応 |
おまけ: Thunderbitは世界でに利用されており、無料プランでも最大6ページ(トライアル特典があれば10ページ)まで無料でスクレイピングできます。
コンプライアンスを守る:Googleマップの利用規約とスクレイピング倫理
ここは多くのPythonチュートリアルが、少し古くなってしまいやすい部分です。2026年に知っておくべきことは次のとおりです。
- Google Maps Platform 利用規約 §3.2.3 では、公式API以外でのスクレイピング、キャッシュ、データの外部出力が厳しく禁止されています()。例外は、緯度・経度は最大30日までキャッシュ可能で、Place IDは無期限で保存できることです。
- APIユーザーは契約上の拘束を受ける:APIキーを使うということは、たとえ公開データを扱っているだけでも、Googleの規約に同意したことになります。
- 技術的な制限(CAPTCHA、SearchGuard)の回避は、現在ではDMCA §1201違反にあたる可能性があり、刑事罰の対象となる場合があります()。
- GDPRとプライバシー法:Googleマップから個人データ(メール、電話番号、レビュー投稿者名など)を収集する場合は、法的根拠が必要で、削除要求にも応じなければなりません。フランスのCNILは2024年、LinkedInの連絡先をスクレイピングしたとしてKASPRに20万ユーロの罰金を科しました()。
- ベストプラクティス:
- 可能な限りPlaces APIを使う。
- リクエストをレート制限する(APIは≤10 QPS、HTMLスクレイピングは1〜2 req/s)。
- CAPTCHAや技術的ブロックを回避しない。
- スクレイピングした個人データを再配布しない。
- オプトアウトや削除の要求に応じる。
- GDPR、CCPAなど、地域の法律を必ず確認する。
結論: コンプライアンスが気になるなら、APIを使い、収集するデータは最小限に抑えるのが安全です。多くのビジネスユーザーにとっては、Thunderbitのようなノーコードツールを使うことでリスクを大きく減らせます(APIキー不要、再配布なし)。
PythonでGoogleマップのスクレイピングをスケジュールし、自動化する
週次の競合モニタリングや月次のリードリスト更新のように、データを常に最新に保ちたいなら、自動化が味方になります。
schedule を使った簡単なスケジューリング
1import schedule, time
2from my_scraper import run_job
3schedule.every().day.at("03:00").do(run_job, query="ブルックリンのレストラン")
4schedule.every(6).hours.do(run_job, query="マンハッタンのコーヒーショップ")
5while True:
6 schedule.run_pending()
7 time.sleep(30)APScheduler を使った本番向けスケジューリング
1from apscheduler.schedulers.background import BackgroundScheduler
2from apscheduler.triggers.cron import CronTrigger
3sched = BackgroundScheduler(timezone="America/New_York")
4sched.add_job(
5 run_job,
6 CronTrigger(hour=3, minute=15, jitter=600), # 午前3:15 ± 10分
7 kwargs={"query": "ブルックリンのレストラン"},
8 id="brooklyn_daily",
9 max_instances=1,
10 coalesce=True,
11 misfire_grace_time=3600,
12)
13sched.start()安全に自動化するためのヒント
- 予測しやすいパターンを避けるため、スケジュールにランダムな揺らぎを入れましょう。
- HTMLスクレイピングでは、1秒あたり1〜2リクエストを超えないようにします。
- API利用では、利用枠を監視し、課金アラートを設定しましょう。
- エラーは必ず記録し、失敗したリクエスト用の「デッドレター」ファイルを残しておきましょう。
Thunderbitの便利機能: Thunderbitなら、UI上で定期スクレイピングを直接スケジュールできます。コードもcronジョブもサーバー設定も不要です。
重要なポイント:効率的で、狙いを絞り、コンプライアンスを守ったGoogleマップデータ抽出
要点を振り返りましょう。
- Googleマップは、ビジネスの位置情報データの第一の情報源であり、リード獲得から市場調査まで幅広く支えています。
- Pythonによるスクレイピングは柔軟で制御しやすい一方、セットアップ、保守、コンプライアンスの負担が伴います。特にGoogleの対ボット対策や法的執行が強化される中ではなおさらです。
- APIベースの抽出は、ほとんどのチームにとって最も安全でスケーラブルな方法です。コスト管理には必ずフィールドマスクとサーバー側フィルターを使いましょう。
- HTMLスクレイピングは壊れやすくリスクも高いため、単発の調査用途に限定し、技術的な制限は絶対に回避しないでください。
- データは絞って取る:フレーズ一致、位置フィルター、pandas のワークフローを使い、必要なものだけ抽出しましょう。
- Thunderbitは、非エンジニアにとって最短ルートです。AI搭載、セットアップ不要、即エクスポート、スケジュール機能も内蔵しています。
- コンプライアンスは重要です:Googleの規約、プライバシー法、レート制限を守り、法的トラブルを避けましょう。
さらに詳しいチュートリアルやヒントは、 と をご覧ください。
FAQ
1. 2026年にPythonでGoogleマップのデータをスクレイピングするのは合法ですか?
公式APIを通じたGoogleマップのスクレイピングは、Googleの規約に沿い、利用枠を守り、制限付きデータを再配布しない限り許可されています。GoogleマップのHTMLスクレイピングはGoogleの利用規約で明確に禁止されており、特に技術的な制限を回避したり、同意なしに個人データを収集したりすると法的リスクがあります。常に現地の法律(GDPR、CCPAなど)を確認し、コンプライアンスのベストプラクティスを守ってください。
2. GoogleマップAPIを使うのと、HTMLをWebスクレイピングするのは何が違いますか?
APIは安定していてライセンスがあり、データ抽出向けに設計されていますが、APIキーが必要で、利用枠と費用がかかります。HTMLスクレイピングはブラウザ自動化で表示済みページからデータを取りますが、壊れやすく(サイト変更が頻繁)、規約違反になる可能性があり、法的リスクも高めです。多くの業務用途では、APIが推奨されます。
3. 2026年にPythonでGoogleマップのデータを抽出するには、どれくらい費用がかかりますか?
GoogleのPlaces APIは1,000リクエストごとの従量課金で、取得する項目に応じてEssentialsの5ドルからEnterprise+Atmosphereの25ドルまで幅があります。月間の無料しきい値もあります(Essentialsは10,000、Proは5,000、Enterpriseは1,000)が、大規模スクレイピングではすぐに費用が膨らみます。コスト管理には、常にフィールドマスクとサーバー側フィルターを使いましょう。
4. ThunderbitはPythonベースのGoogleマップスクレイパーと比べてどうですか?
ThunderbitはノーコードのAI搭載Webスクレイパーで、プログラミング、APIキー、保守なしでGoogleマップのデータを抽出できます。Excel、Googleスプレッドシート、Airtable、Notionへの高速で安定した出力が必要な営業・マーケティングチームに最適です。独自ロジックが必要な技術者にはPythonのほうが柔軟ですが、その分、準備やコンプライアンス管理の負担は増えます。
5. 定期的なGoogleマップデータ抽出はどう自動化できますか?
Pythonでは、schedule や APScheduler のようなスケジューリングライブラリを使って、スクレイパーを毎日・毎週などの間隔で実行できます。検知されにくくするためにランダムな揺らぎを加え、APIの利用枠を監視してください。Thunderbitなら、UI上で定期スクレイピングを直接スケジュールできます。コードもサーバー設定も不要です。
Googleマップを営業・マーケティングの強力な武器に変える準備はできましたか? Pythonが好きな方も、最速のノーコード手段を探している方も、2026年には使えるツールがそろっています。今すぐを試して、AI搭載の即時スクレイピングを体験するもよし、あるいは自分の手でAPIを使いこなすもよし。どちらを選んでも、リードリストは常に新鮮に、出力はきれいに、キャンペーンは高成約率の地域見込み客でいっぱいになるはずです。楽しいスクレイピングを!
詳しく知る