Google は 2018 年に Flights API を終了しましたが、航空券の価格は今もずっと動き続けています。たとえば、国内線の1ルートだけでも48時間で最大17回も変わることがあります。https://mightytravels.com/ そのデータをプログラムで取りたいなら、今のところスクレイピングがほぼ唯一の手段です。
私はこれまで、Google から航空券データを取るいろいろな方法を長く試してきましたが、特に Google が 2025 年 1 月に SearchGuard を入れてから、状況はかなり変わりました。このガイドでは、Playwright を使って Google Flights を実際に動く Python スクレイパーとして作る方法、ほとんどの人がつまずく bot 対策の回避方法、さらにそれを自動の価格追跡ツールとアラート機能に育てる手順まで解説します。コードを書かずに進めたい人向けには、 を使って、約 2 分で同じ結果にたどり着くノーコードの方法も紹介します。
なぜ Python で Google Flights をスクレイピングするのか?
Google Flights は航空券検索のど真ん中にいる存在です。米国のモバイル表示シェアは し、主要 OTA をすべて上回っています。その背後にある旅行メタサーチ市場は 規模で、年平均 30.2% で伸びています。それでも、QPX Express API は していて、このデータを公式にプログラム取得する方法はありません。
一方で、航空券価格は同じ旅程でも 変わり、最安値と最高値の差は平均で約 20 ドルあります。Delta のような航空会社は、ダイナミックプライシングのために 77 の運賃バケットを使っています。2026 年初頭の米国往復航空券の平均価格は 408 ドルで、運賃は前年同期比で 状態です。
圧倒的なプラットフォーム、API の不在、そして価格の変動性。この3つが重なるからこそ、Python で Google Flights をスクレイピングする方法は、GitHub や旅行系フォーラムでかなり人気のあるテーマになっています。
対象ユーザーとメリットは次の通りです。
| ユーザータイプ | 活用例 | 主なメリット |
|---|---|---|
| 個人旅行者 | 特定ルートの価格を継続的に追跡 | 1便あたり平均 $50 節約 |
| 旅行代理店 | 競合価格のインテリジェンス収集 | リアルタイムの運賃パリティ監視 |
| 企業出張チーム | ルート別のコスト最適化 | 出張費を 10〜30% 削減 |
| 開発者 | 運賃比較アプリの構築 | 価格データへのプログラム的アクセス |
| 研究者 | 航空運賃の変動分析 | 学術研究・市場調査 |
フォーラムでは、スクレイピングに踏み切った理由として、かなり率直な声が多く見られます。「Google Flights API が終わったので、代わりに Web スクレイピングを使うべきだ」 という趣旨の投稿は何度も出てきます。そして投資対効果も実際に大きいです。 。一方、Expedia の 2026 年データでは、国内線は 8〜15 日前に予約すると約 とされています。
Google Flights からどんなデータが取得できるのか?
Google Flights の検索結果ページには、思っている以上に豊富なデータ項目があります。一般的には次の情報が取得可能です。
- 航空会社名(ロゴ含む)
- 出発時刻 と空港コード
- 到着時刻 と空港コード
- 総所要時間
- 乗継回数 と乗継詳細(空港、所要時間、深夜帯かどうか)
- 航空券価格(通貨別)
- CO2 排出量(kg CO2e、標準的な便との比較差分付き)
- 座席クラス、便名、機材モデル
- 足元スペース の仕様
- 設備(Wi-Fi、電源、機内ストリーミング)
- 価格帯指標(低・標準・高)
- 遅延警告(「30 分以上遅延しやすい」など)
取れる項目は、ルート、日付、チケット種別(片道か往復か)によって変わります。単一のスクレイピング結果を JSON にすると、だいたい次のような形になります。
1{
2 "search_date": "2026-04-16",
3 "route": "SFO-JFK",
4 "departure_date": "2026-05-15",
5 "flights": [
6 {
7 "airline": "United Airlines",
8 "flight_number": "UA123",
9 "departure_time": "08:00",
10 "departure_airport": "SFO",
11 "arrival_time": "16:35",
12 "arrival_airport": "JFK",
13 "duration_minutes": 335,
14 "stops": 0,
15 "price_usd": 287,
16 "price_level": "low",
17 "co2_kg": 156,
18 "co2_vs_typical": "-12%",
19 "travel_class": "Economy"
20 }
21 ]
22}Python 環境の準備
スクレイピングコードを書く前に、いくつか準備が必要です。
前提条件:
- 難易度: 中級
- 所要時間: チュートリアル全体で約 1〜2 時間
- 必要なもの: Python 3.7 以上、Python の基礎知識、Chromium 系ブラウザ
必要なライブラリをインストールする
ブラウザ自動化には Playwright を使います(Google Flights は 100% JavaScript で描画されるため、通常の HTTP リクエストでは使える情報が返りません)。加えて、いくつか補助ツールを入れます。
1pip install playwright playwright-stealth pandas
2playwright install chromium- Playwright — ヘッドレスブラウザ自動化、JavaScript 描画対応、待機処理が標準搭載
- playwright-stealth — 一般的な bot 検知シグナルを補正
- pandas — 後でデータ分析と CSV 出力に使う
Selenium や requests ではなく Playwright を選ぶ理由
Google Flights は requests + BeautifulSoup だけでは動きません。ページ内容がすべて JavaScript で描画されるからです。つまり、実ブラウザが必要になります。
| 機能 | Playwright | Selenium | requests + BS4 |
|---|---|---|---|
| JS 描画 | 完全対応 | 完全対応 | なし |
| 速度 | 全体で 42% 高速 | 基準 | この用途では非対応 |
| 非同期対応 | 標準対応 | 逐次のみ | 非対応 |
| メモリ使用量 | 30% 少ない | 多め | 最小 |
| bot 検知回避 | 良好(stealth 利用時) | 検知されやすい | 非対応 |
Playwright は速く、よりモダンで、非同期処理にも強いです。Google Flights の用途では、かなりはっきりした最有力候補です。
ステップごとの手順:Python で Google Flights をスクレイピングする方法
ここがチュートリアルの本編です。スクレイパーを段階的に組み立てていきます。
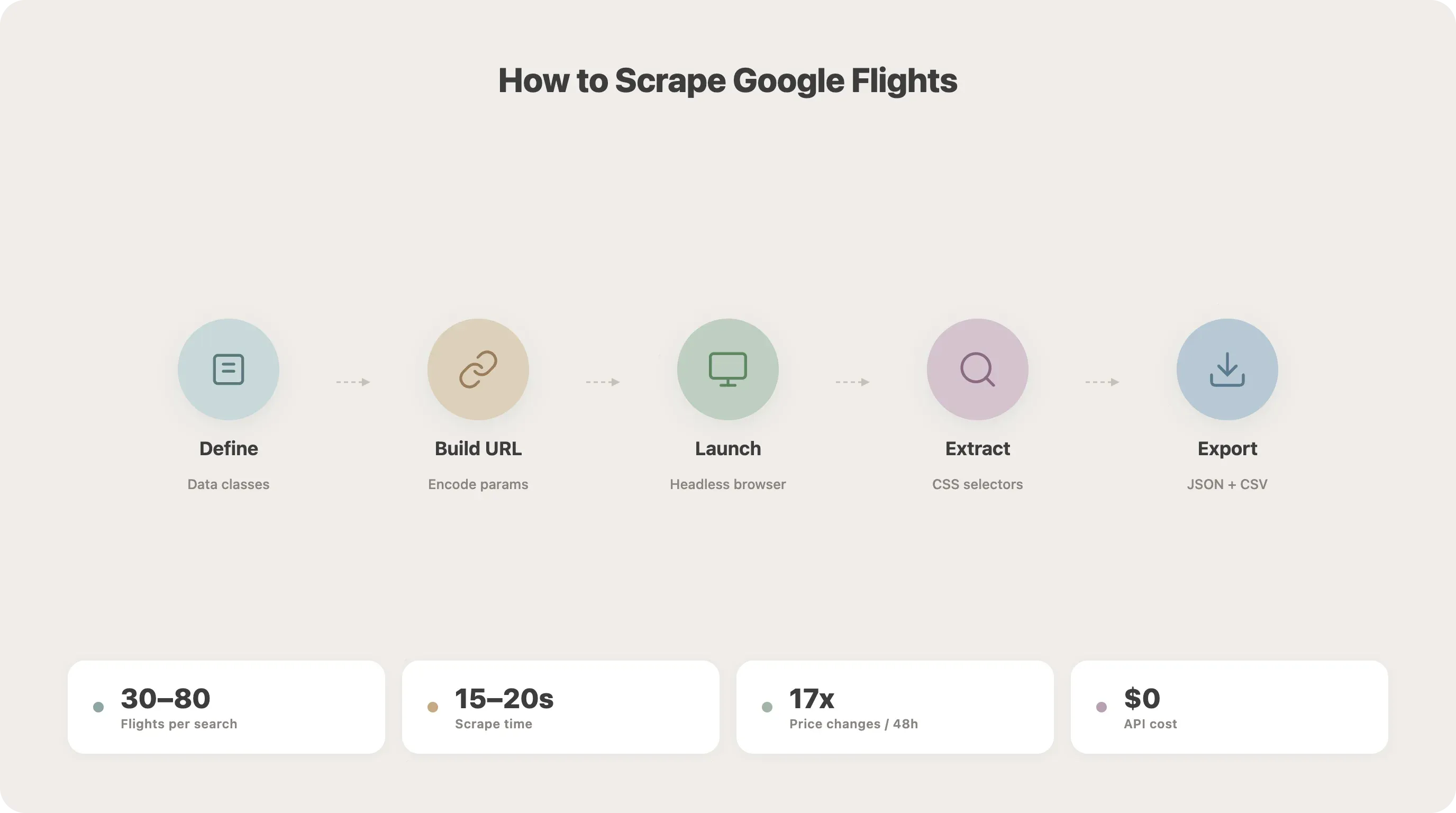
ステップ 1:データクラスを定義する
まずは、検索条件と航空券データを Python の dataclass で整理します。コードが見やすくなり、あとから拡張もしやすくなります。
1from dataclasses import dataclass, field
2from typing import Optional, List
3@dataclass
4class SearchParams:
5 origin: str # 例: "SFO"
6 destination: str # 例: "JFK"
7 departure_date: str # 例: "2026-05-15"
8 return_date: Optional[str] = None
9 trip_type: str = "one-way" # "one-way" または "round-trip"
10 travel_class: str = "economy"
11@dataclass
12class FlightData:
13 airline: str = ""
14 departure_time: str = ""
15 arrival_time: str = ""
16 duration: str = ""
17 stops: str = ""
18 price: str = ""
19 co2_emissions: str = ""各フィールドは、ページから抜く情報にそのまま対応しています。最初にこの形を決めておけば、あとで雑な辞書を行ったり来たりさせる必要がありません。
ステップ 2:Google Flights の URL 構造を理解する
Google Flights は、検索条件を tfs URL パラメータの Base64 エンコード済み Protobuf で表しています。これを逆解析する方法もありますが、もっと手軽なのは自然文の検索 URL を組み立てるやり方です。
いちばんシンプルな形は次の通りです。
1https://www.google.com/travel/flights?q=flights+from+SFO+to+JFK+on+2026-05-15&curr=USDより細かく制御したい場合は、プログラムで URL を組み立てられます。
1def build_flights_url(origin: str, destination: str, date: str) -> str:
2 base = "https://www.google.com/travel/flights"
3 query = f"flights from {origin} to {destination} on {date}"
4 return f"{base}?q={query.replace(' ', '+')}&curr=USD"もう一つの方法である Protobuf 逆解析は、より精密に制御できますが、Google が内部形式を変えると壊れます。GitHub の のようなライブラリは Protobuf をデコードして HTML パースを避けますが、こちらはより上級のやり方です。
ステップ 3:ブラウザを起動して Google Flights に移動する
以下が Playwright のセットアップです。最初から検知リスクを下げるために playwright-stealth を使います。
1import asyncio
2from playwright.async_api import async_playwright
3from playwright_stealth import Stealth
4async def scrape_flights(params: SearchParams) -> List[FlightData]:
5 async with Stealth().use_async(async_playwright()) as pw:
6 browser = await pw.chromium.launch(
7 headless=True,
8 args=[
9 "--disable-blink-features=AutomationControlled",
10 "--disable-dev-shm-usage",
11 "--no-first-run",
12 ]
13 )
14 context = await browser.new_context(
15 viewport={"width": 1920, "height": 1080},
16 user_agent=(
17 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
18 "AppleWebKit/537.36 (KHTML, like Gecko) "
19 "Chrome/125.0.0.0 Safari/537.36"
20 ),
21 locale="en-US",
22 timezone_id="America/New_York",
23 )
24 # 同意ポップアップを避けるため Cookie を先に設定
25 await context.add_cookies([{
26 "name": "SOCS",
27 "value": "CAESHwgBEhJnd3NfMjAyNTAyMjctMF9SQzIaBXpoLUNOIAEaBgiAy6O-Bg",
28 "domain": ".google.com",
29 "path": "/"
30 }])
31 page = await context.new_page()本番では headless で動かします(デバッグ時は headless=False に切り替え)。また、現実的な viewport と user agent を設定し、SOCS Cookie を先に入れて同意ポップアップを避けています。bot 対策の細かい部分は後半で説明します。
ステップ 4:検索結果に移動する
作成した URL を開き、航空券の結果が表示されるのを待ちます。
1 url = build_flights_url(
2 params.origin, params.destination, params.departure_date
3 )
4 await page.goto(url, wait_until="networkidle")
5 # 航空券結果が読み込まれるまで待つ
6 await page.wait_for_selector(
7 "li.pIav2d", timeout=15000
8 )ここでタイムアウトする場合は、同意ポップアップがページを塞いでいるか(ステップ 3 の Cookie 対策を参照)、Google が CAPTCHA を出していることが多いです。どちらも後半の bot 対策で扱います。
ステップ 5:すべての航空券結果を読み込む
Google Flights は「さらに多くの便を表示」ボタンの奥に追加結果を隠しています。全部出るまで何回かクリックする必要があります。
1 # "さらに多くの便を表示" ボタンをクリックして全件読み込む
2 while True:
3 try:
4 more_button = page.locator(
5 'button:has-text("Show more flights")'
6 )
7 if await more_button.is_visible(timeout=3000):
8 await more_button.click()
9 await page.wait_for_timeout(2000)
10 else:
11 break
12 except Exception:
13 breakこのループはボタンを押し、新しい結果が描画されるまで 2 秒待ち、ボタンが見えなくなったら終わります。私の検証では、ほとんどのルートで 1〜3 ページ分の結果があります。
ステップ 6:CSS セレクタで航空券データを抽出する
ここで、読み込んだページから実際の航空券データを抜き出します。以下のセレクタは 2026 年 4 月時点で確認済みです(なぜこの日付が大事かは保守の章で説明します)。
1 flights = []
2 cards = await page.query_selector_all("li.pIav2d")
3 for card in cards:
4 flight = FlightData()
5 # 航空会社名
6 airline_el = await card.query_selector(
7 "div.sSHqwe span:not([class])"
8 )
9 if airline_el:
10 flight.airline = (await airline_el.inner_text()).strip()
11 # 出発時刻
12 dep_el = await card.query_selector(
13 'span[aria-label*="Departure time"]'
14 )
15 if dep_el:
16 flight.departure_time = (await dep_el.inner_text()).strip()
17 # 到着時刻
18 arr_el = await card.query_selector(
19 'span[aria-label*="Arrival time"]'
20 )
21 if arr_el:
22 flight.arrival_time = (await arr_el.inner_text()).strip()
23 # 所要時間
24 dur_el = await card.query_selector("div.gvkrdb")
25 if dur_el:
26 flight.duration = (await dur_el.inner_text()).strip()
27 # 乗継回数
28 stops_el = await card.query_selector("div.EfT7Ae span")
29 if stops_el:
30 flight.stops = (await stops_el.inner_text()).strip()
31 # 価格
32 price_el = await card.query_selector(
33 "div.FpEdX span"
34 )
35 if price_el:
36 flight.price = (await price_el.inner_text()).strip()
37 # CO2 排出量
38 co2_el = await card.query_selector("div.O7CXue")
39 if co2_el:
40 flight.co2_emissions = (
41 await co2_el.get_attribute("aria-label") or ""
42 ).strip()
43 flights.append(flight)
44 await browser.close()
45 return flights注意点として、pIav2d、sSHqwe、FpEdX のような class 名は Google の Closure Compiler によって生成されていて、ビルドごとに変わる可能性があります。aria-label を使うセレクタのほうが安定しています。保守戦略は後ほどまとめます。
ステップ 7:結果を JSON または CSV に保存する
最後に、スクレイピングしたデータをタイムスタンプ付きで保存します。これは後で価格追跡をするうえでかなり重要です。
1import json
2from datetime import datetime
3from dataclasses import asdict
4async def main():
5 params = SearchParams(
6 origin="SFO",
7 destination="JFK",
8 departure_date="2026-05-15"
9 )
10 flights = await scrape_flights(params)
11 output = {
12 "search_date": datetime.now().isoformat(),
13 "params": asdict(params),
14 "flights": [asdict(f) for f in flights],
15 }
16 with open("flights.json", "w") as f:
17 json.dump(output, f, indent=2)
18 # CSV としても保存
19 import pandas as pd
20 df = pd.DataFrame([asdict(f) for f in flights])
21 df["search_date"] = datetime.now().isoformat()
22 df["route"] = f"{params.origin}-{params.destination}"
23 df.to_csv("flights.csv", index=False)
24 print(f"Scraped {len(flights)} flights")
25asyncio.run(main())これを実行すると、flights.json と flights.csv に結果が保存されます。私のテストでは、SFO-JFK 検索でたいてい 30〜80 件の候補が返り、完了まで約 15〜20 秒かかります。
Google Flights スクレイピングのための bot 対策サバイバルガイド
多くのチュートリアルはここで終わります。でも、多くのスクレイパーはここで止まります。Google は し、ほぼすべての SERP スクレイパーを一夜で壊しました。Google はこれを「何万時間もの人件費と数百万ドル規模の投資の成果」と説明しています。Google Flights のスクレイピング難易度は とされています。
競合記事の多くはここを深掘りしていませんが、実際にはスクレイパーが止まる最大の理由です。何が起きているのか、どう対処するかを見ていきましょう。

リクエスト間にランダムな遅延を入れる
レート制限対策としていちばん基本です。コード 2 行でできて、効果は中程度です。
1import time
2import random
3time.sleep(random.uniform(3, 7))ページ移動の間に入れてください。毎回ぴったり 5 秒のような固定間隔は不自然なので、必ずランダム化します。
User-Agent のローテーション
毎回同じ user-agent を送るのは、かなりわかりやすい痕跡です。候補をいくつか用意して切り替えます。
1import random
2USER_AGENTS = [
3 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 Chrome/125.0.0.0 Safari/537.36",
4 "Mozilla/5.0 (Macintosh; Intel Mac OS X 14_5) AppleWebKit/605.1.15 Safari/605.1.15",
5 "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 Chrome/124.0.0.0 Safari/537.36",
6 "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:126.0) Gecko/20100101 Firefox/126.0",
7]
8user_agent = random.choice(USER_AGENTS)ヘッドレス検知の回避
Google は navigator.webdriver フラグや、そのほかの自動化シグナルをチェックします。playwright-stealth はその多くに対応しますが、ステップ 3 で示した起動引数も必ず設定してください。重要なフラグは次の通りです。
1args=[
2 "--disable-blink-features=AutomationControlled",
3 "--disable-dev-shm-usage",
4 "--no-first-run",
5]これで基本的な検知は回避できます。SearchGuard はさらに深く、マウスの速さ、キーボード入力のタイミング、スクロールの癖まで見ていますが、中程度の件数なら stealth モードと自然な遅延だけで足りることが多いです。
プロキシのローテーション:データセンター型 vs. 住宅型
数件の検索を超えるなら、プロキシはほぼ必須です。違いはかなり大きいです。
住宅プロキシは、保護されたサイトをスクレイピングするとき、成功リクエストあたりのコストが とされています。2026 年の提供価格は、Smartproxy が $7/GB から、Bright Data が $8.40/GB、Oxylabs が $8/GB です。
Playwright にプロキシを追加するには、次のようにします。
1browser = await pw.chromium.launch(
2 proxy={"server": "http://proxy-host:port",
3 "username": "user", "password": "pass"}
4)Cookie 同意ポップアップの処理
多くのユーザーが「利用規約への同意」ポップアップを障害として挙げています。「最初に Google が '利用規約に同意しますか' のポップアップを出してくる」 という声もよくあります。いちばんきれいな対処法は、ステップ 3 で示した SOCS Cookie を先に入れておくことです。それでもだめなら、クリックで通過します。
1try:
2 accept_btn = page.locator('button:has-text("Accept all")')
3 if await accept_btn.is_visible(timeout=3000):
4 await accept_btn.click()
5 await page.wait_for_timeout(1000)
6except Exception:
7 pass # ポップアップがない場合注意:ボタンの文言はロケールによって変わります。ドイツ語なら "Alle akzeptieren"、フランス語なら "Tout accepter" です。
bot 対策のクイックリファレンス
| 手法 | 難易度 | 効果 | コードは必要? |
|---|---|---|---|
| ランダム遅延(2〜7 秒) | 低 | 中 | 2 行 |
| User-Agent ローテーション | 低 | 中 | 5 行 |
| ヘッドレス検知回避 | 中 | 高 | Playwright の起動引数 |
| playwright-stealth プラグイン | 中 | 基本サイトで 60〜80% | pip install |
| プロキシローテーション(データセンター) | 中 | 中 | 設定 |
| プロキシローテーション(住宅) | 中 | 成功率 85〜95% | 設定 |
| Cookie 同意の事前設定(SOCS) | 低 | 必須 | 1 行 |
推奨される安全なリクエスト速度としては、IP ローテーションをしながら 1 リクエストあたり 10〜20 秒の遅延を入れるのが目安です。Google の閾値は、1 IP あたりおよそ 100 リクエスト/分で 429 エラーが出始め、1 日 1,000 リクエストを超える継続利用では一時的なブロックにつながる可能性があります。
なぜ Google Flights のセレクタは壊れ続けるのか、そしてどう直すのか
かなり多い悩みです。フォーラムには 「返ってくるのは空のリストばかり」 という投稿があふれています。どのチュートリアルもセレクタは教えてくれますが、壊れる理由まではあまり説明していません。
Google Flights のセレクタが変わる理由
理由は主に 3 つです。
-
Closure Compiler による難読化。 Google は を使って
goog.setCssNameMapping()経由でBVAVmfやYMlIzのような class 名を生成します。これらはビルドごとに変わり、週単位で変化することもあります。 -
A/B テスト。 同じタイミングでも、ユーザーごとに違う HTML 構造が表示されます。あなたの環境では動いても、別地域のユーザーでは失敗することがあります。
-
ロケール差。 EU ユーザーには、米国ユーザーとは異なる文言、レイアウト、データ項目が表示されることがあります。
壊れにくいセレクタを書く
見た目ではなく意味に結びついたセレクタを優先しましょう。
1# 壊れやすい — ビルドごとに壊れる
2price_el = await card.query_selector("div.BVAVmf > div.YMlIz")
3# より安定 — アクセシビリティラベルに紐づく
4dep_el = await card.query_selector('span[aria-label*="Departure time"]')
5# こちらも安定 — テキストベースの一致
6more_btn = page.locator('button:has-text("Show more flights")')セレクタの安定性の序列(安定度が高い順):
aria-label属性 — アクセシビリティ用で、変わりにくいdata-*属性 — 機能のために明示的に付与されるrole属性 — ARIA role は意味情報- テキストベースのセレクタ — 表示文言に一致
- 部分一致の class 名 — 例:
[class*="price"] - 完全な難読化 class 名 — できるだけ避ける
バリデーション関数を追加する
壊れたセレクタが空データを静かに返すのを防ぎましょう。早めに気づくのが大事です。
1import logging
2logger = logging.getLogger(__name__)
3def validate_flight(data: FlightData) -> bool:
4 required = ["airline", "price", "departure_time",
5 "arrival_time", "duration"]
6 valid = True
7 for field_name in required:
8 if not getattr(data, field_name, ""):
9 logger.warning(
10 f"Missing '{field_name}' — selectors may need updating"
11 )
12 valid = False
13 return validスクレイピングした各便に対してこのチェックをかけてください。警告が出始めたら、ページ構造を見直してセレクタを更新するタイミングです。
セレクタ保守の方針
- セレクタは毎月確認するか、出力品質が落ちたらすぐ見直す
- セレクタを別の設定辞書にまとめ、更新しやすくする
- この記事のセレクタ最終確認日は 2026 年 4 月
- 代替手段として を検討する。これは CSS セレクタではなく Protobuf 解析を使うため、この問題を避けられる(ただし Google が内部データ形式を変えると、別の壊れやすさはある)
1 回きりのスクレイピングから、自動 Google Flights 価格トラッカーへ
多くのチュートリアルは「JSON に保存して終わり」です。でもこの記事のタイトルは「価格アラート」です。ここで本題に入ります。
![]()
スクレイパーを自動実行するようにスケジュールする
方法 1: Python の schedule ライブラリ(いちばん簡単で、OS を選ばない):
1import schedule
2import time
3def run_scraper():
4 asyncio.run(main())
5schedule.every().day.at("06:00").do(run_scraper)
6schedule.every().day.at("18:00").do(run_scraper)
7while True:
8 schedule.run_pending()
9 time.sleep(60)方法 2: cron ジョブ(Linux/Mac):
1# 毎日 6:00 と 18:00 に実行
20 6,18 * * * cd /path/to/scraper && python scraper.py方法 3: Windows タスク スケジューラ — python scraper.py を好きなスケジュールで動かす基本タスクを作ります。
注意として、これらはすべて常時稼働のマシンが必要です。スリープするノートPCで回すと、スクレイピングを取り逃がします。
過去の価格データを保存する
JSON ファイルを上書きする方式ではなく、SQLite データベースに追記する形に切り替えます。
1import sqlite3
2from datetime import datetime
3def init_db():
4 conn = sqlite3.connect("flights.db")
5 conn.execute("""
6 CREATE TABLE IF NOT EXISTS flights (
7 id INTEGER PRIMARY KEY AUTOINCREMENT,
8 scrape_date TEXT NOT NULL,
9 route TEXT NOT NULL,
10 airline TEXT,
11 departure_time TEXT,
12 arrival_time TEXT,
13 duration TEXT,
14 stops TEXT,
15 price_usd REAL,
16 co2_emissions TEXT
17 )
18 """)
19 conn.execute(
20 "CREATE INDEX IF NOT EXISTS idx_route_date "
21 "ON flights(route, scrape_date)"
22 )
23 conn.commit()
24 return conn
25def save_flight(conn, route: str, flight: FlightData):
26 price_num = float(
27 flight.price.replace("$", "").replace(",", "")
28 ) if flight.price else None
29 conn.execute(
30 "INSERT INTO flights "
31 "(scrape_date, route, airline, departure_time, "
32 "arrival_time, duration, stops, price_usd, co2_emissions) "
33 "VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?)",
34 (datetime.now().isoformat(), route, flight.airline,
35 flight.departure_time, flight.arrival_time,
36 flight.duration, flight.stops, price_num,
37 flight.co2_emissions)
38 )
39 conn.commit()1 日 2 回のスクレイピングを 1 週間続ければ、価格の流れを見つけるのに十分なデータがたまります。
価格トレンドを分析し、アラートを設定する
過去データから最安値を見つけます。
1import pandas as pd
2import sqlite3
3conn = sqlite3.connect("flights.db")
4df = pd.read_sql_query(
5 "SELECT * FROM flights WHERE route = 'SFO-JFK'", conn
6)
7summary = df.groupby("scrape_date")["price_usd"].agg(
8 ["min", "max", "mean"]
9)
10cheapest = df.loc[df["price_usd"].idxmin()]
11print(
12 f"Cheapest: ${cheapest['price_usd']:.0f} on "
13 f"{cheapest['scrape_date']} ({cheapest['airline']})"
14)価格が設定した閾値を下回ったら、メールアラートを送ります。
1import smtplib
2from email.mime.text import MIMEText
3def send_price_alert(route, price, threshold, recipient):
4 msg = MIMEText(
5 f"Price drop alert! {route}: ${price:.0f} "
6 f"(below your ${threshold:.0f} threshold)"
7 )
8 msg["Subject"] = f"Flight Deal: {route} at ${price:.0f}"
9 msg["From"] = "alerts@example.com"
10 msg["To"] = recipient
11 with smtplib.SMTP_SSL("smtp.gmail.com", 465) as server:
12 server.login("alerts@example.com", "your_app_password")
13 server.send_message(msg)
14# 各スクレイプ後にお得な価格を確認
15min_price = df["price_usd"].min()
16threshold = 250
17if min_price < threshold:
18 send_price_alert("SFO-JFK", min_price, threshold,
19 "you@email.com")おすすめのスクレイピング頻度は、個人の価格ウォッチなら 1 日 2 回で十分です(時間をランダムにすると検知リスクも下がります)。業務用途なら 4〜6 時間ごと。1 時間ごとの取得は、短期セール期間に限って一時的に使う程度にしてください。
もっと簡単な方法:Thunderbit のスケジュールスクレイパー
cron、常時稼働サーバー、プロキシ設定などを管理するのがしんどいなら、 の Scheduled Scraper を使えば、同じ用途をもっと手軽に実現できます。スクレイピング間隔を自然な言葉で指定して、Google Flights の URL を入れるだけで、Thunderbit のクラウド基盤上で自動実行されます。bot 対策も組み込みで、結果は に直接エクスポートできます。フル Python 実装の完全な代替ではありませんが、目的が「価格追跡用のスプレッドシートを作りたい」なら、これがいちばん早いルートです。 でも試せます。
Python までは不要? Google Flights をノーコードでスクレイピングする方法
ここまで作ってきて正直に言うと、かなり部品が多いです。誰もがここまでの制御を必要としているわけではありません。セレクタは壊れるし、プロキシのローテーションもいるし、cron の監視も必要です。目的が「航空券価格を定期的にスプレッドシートへ入れること」なら、もっと早い方法があります。
比較:自作 Python vs API サービス vs Thunderbit
| 方法 | 準備時間 | コーディング必要 | bot 対策対応 | スケジュール機能 | 料金 |
|---|---|---|---|---|---|
| 自作 Playwright(このチュートリアル) | 1〜2 時間 | Python(中級) | 手動設定 | 手動(cron) | 無料 + プロキシ代 |
| SerpApi の Google Flights エンドポイント | 15 分 | API 呼び出しのみ | 対応済み | API 経由 | 月額約 $50〜 |
| Thunderbit Chrome 拡張機能 | 2 分 | 不要 | クラウドで対応 | 内蔵スケジューラ | 無料プランあり |
SerpApi について一言。Google は し、2 年間でリクエスト数が 25,000% 増えたと主張しました。API 事業者を選ぶなら、この法的不確実性はちゃんと見ておく価値があります。
Thunderbit で Google Flights をスクレイピングする方法
Chrome で Google Flights の検索結果を開き、Thunderbit の「AI Suggest Fields」ボタンをクリックします。AI がページを読み取り、航空会社、価格、出発時刻、乗継などの列を提案します。提案された項目を確認してから「Scrape」をクリックすれば完了です。結果はテーブルとして表示され、Excel、Google Sheets、Airtable、Notion にエクスポートできます。これらはすべて で使えます。
特に価格追跡用途では、Thunderbit の Scheduled Scraper と (同時に 50 ページを処理可能)があれば、cron + プロキシ + サーバーの構成はまるごと不要になります。
Python は自由度と拡張性が強みです。Thunderbit は速さとメンテ不要が魅力です。自分の目的に合わせて選んでください。ノーコードのスクレイピング手法をもっと知りたいなら、 のガイドも参考になります。

Google Flights のスクレイピングは合法? 知っておくべきこと
フォーラムではよく 「Google Flights を直接スクレイピングするのは Google の利用規約違反だ」 という指摘があります。もっともな心配です。特に API が終わって、正式な代替がない今はなおさらです。
利用規約違反と法的責任は別物
Google の利用規約(2024 年 5 月 22 日更新)では、ユーザーは "robots, spiders, scrapers などの自動手段を用いてサービスやコンテンツにアクセスまたは利用してはならない" とされています。利用規約違反は契約違反(民事)であって、ただちに違法行為と同じではありません。
重要な先例は hiQ v. LinkedIn(第 9 巡回区、2022 年)です。ここでは、公開データのスクレイピングは Computer Fraud and Abuse Act(CFAA)に違反しないとされました。ただし、この件は最終的に和解で終わっており、Google の 2025 年 12 月の SerpApi に対する訴訟は別の法理、つまり DMCA 第 1201 条(技術的保護手段の回避)に基づいています。こちらのほうが、より重い問題になり得ます。
責任あるスクレイピングのベストプラクティス
- リクエストをレート制限する — IP ローテーションを使い、10〜20 秒の遅延を入れる
- 個人情報はスクレイピングしない — 航空券価格は公開されている集計データです
- CAPTCHA をプログラムで回避しない — ここは DMCA リスク領域です
- データは個人研究用途にとどめる。適切なライセンスなしに競合の商用製品を作らない
- 使えるなら公式 API を検討する
代替データソース
用途によっては、スクレイピングより合法的な API のほうが向いていることもあります。
| 提供元 | 料金 | 無料枠 | 備考 |
|---|---|---|---|
| SerpApi | 月額 $75〜$3,750+ | 月 250 検索 | Google Flights の JSON を直接取得(法的注目あり) |
| Kiwi Tequila | 無料(アフィリエイトモデル) | 無制限 | スタートアップや検証に最適 |
| Amadeus | 従量課金 | 月 2,000 リクエスト | 400+ 航空会社、予約機能あり |
| Skyscanner | 個別見積もり | 承認が必要 | 52 市場、30 言語対応 |
より詳しい内容は、 の解説記事でも紹介しています。
まとめと重要ポイント
かなり盛りだくさんでした。要点は次の通りです。
- Python + Playwright は Google Flights をスクレイピングするうえでいちばん柔軟な方法ですが、継続的な保守が必要です
- bot 対策(遅延、User-Agent ローテーション、住宅プロキシ)は必須です。特に SearchGuard 以降は、信頼性を保つために欠かせません
- セレクタは頻繁に壊れる ので、できるだけ
aria-labelとテキストベースのセレクタを使い、出力検証を行い、保守スケジュールを決めておきましょう scheduleや cron で自動化 すれば、単発のスクレイピングを、履歴データとメールアラート付きの本格的な価格トラッカーにできます- は、ノーコードで、スケジュール機能・クラウドスクレイピング・bot 対策を備えた代替手段です。コードを書くより、価格追跡用のスプレッドシートが欲しい人に向いています
- 法的な境界はちゃんと尊重する こと。レート制限を守り、公開データだけを対象にし、商用利用では API 代替も検討してください
このチュートリアルのコードを使うのもありですし、手早く進めたいなら を入れるのもありです。どちらにしても、Google Flights を手動で更新する代わりに、航空券価格を自動で追えるようになります。
Python でのスクレイピング技術をさらに学びたいなら、 と も見てみてください。
FAQ
1. Python なしで Google Flights をスクレイピングできますか?
はい。SerpApi や Kiwi Tequila のような API サービスを使えば、構造化された航空券データを API 呼び出しで取得できます(ブラウザ自動化は不要です)。完全ノーコードで進めたいなら、 を使えば、AI が提案する項目をもとにブラウザ上の Google Flights 結果を直接スクレイピングし、ワンクリックでエクスポートできます。
2. Google は航空券スクレイピングをブロックしますか?
Google は bot 検知(SearchGuard)、CAPTCHA、レート制限を使っています。ランダムな遅延、User-Agent ローテーション、住宅プロキシ、stealth ブラウザ設定などをうまく組み合わせれば、中くらいの件数なら安定してスクレイピングできます。具体的な手法と閾値は上の bot 対策セクションを見てください。
3. 価格追跡のために Google Flights をどのくらいの頻度でスクレイピングすべきですか?
個人用途なら、ランダムな時間帯に 1 日 2 回で十分です。これなら検知リスクも低めに抑えられます。業務監視なら 4〜6 時間ごとに、プロキシをローテーションして実行してください。短期セールを除き、1 時間ごとのスクレイピングは避けたほうがよく、ブロックされる可能性がかなり上がります。
4. 無料の Google Flights API はありますか?
公式の Google QPX Express API は しました。無料の公式代替はありません。いちばん近い無料 विकल्पは (アフィリエイトモデル、検索無制限)です。SerpApi には月 250 回の無料検索があります。多くの人にとっては、スクレイピングか Thunderbit のようなノーコードツールが現実的な選択肢です。
5. Google Flights の CSS セレクタが空データばかり返すのはなぜですか?
Google は Closure Compiler を使って、ビルドごとに変わる難読化された class 名を生成しています。A/B テストやロケール差によっても HTML 構造がユーザーごとに変わります。対策は、class 名ではなく aria-label 属性やテキストベースのセレクタを使うこと、壊れを早めに見つけるバリデーション関数を追加すること、そしてセレクタを毎月見直すことです。詳しくはセレクタ保守の章をご覧ください。
さらに読む