2022年は問題なく動いていたGlassdoorスクレイパーが、今では403ばかり返してくる——そんな状況に心当たりがあっても、あなただけではありません。いろんなフォーラムを見ても、同じような質問がずらっと並んでいます。「このスクレイパー、なんで動かなくなったの?」
結論から言えば、Glassdoorが大きく変わったからです。Recruit Holdingsは2025年7月にGlassdoorをIndeedへ統合し、を実施しました。さらにボット対策も強化され、素のSeleniumやrequestsベースのスクレイパーでは、HTMLの先頭バイトが読み込まれる前に弾かれるレベルになっています。2026年2月時点では、Glassdoorのログイン処理はすべてIndeed Login経由になっているため、Glassdoor専用のログインフォームを前提にした古いチュートリアルは、構造的に最初から破綻しています。その一方で、プラットフォーム上には今なおをまたぐが蓄積されています。HRのベンチマーク、競合調査、営業リードの発掘には、これ以上ないくらい価値のあるデータです——ちゃんと取れれば、の話ですが。本ガイドは、こうした変更をすべて踏まえたうえで「今も動く」版です。求人、レビュー、給与の3種類を1本にまとめ、2025年時点で動くPythonコード、何がブロックの原因になるのか、その回避方法、そして実装を丸ごと省きたい人向けのノーコード手段まで紹介します。
2025年にPythonでGlassdoorをスクレイピングする理由
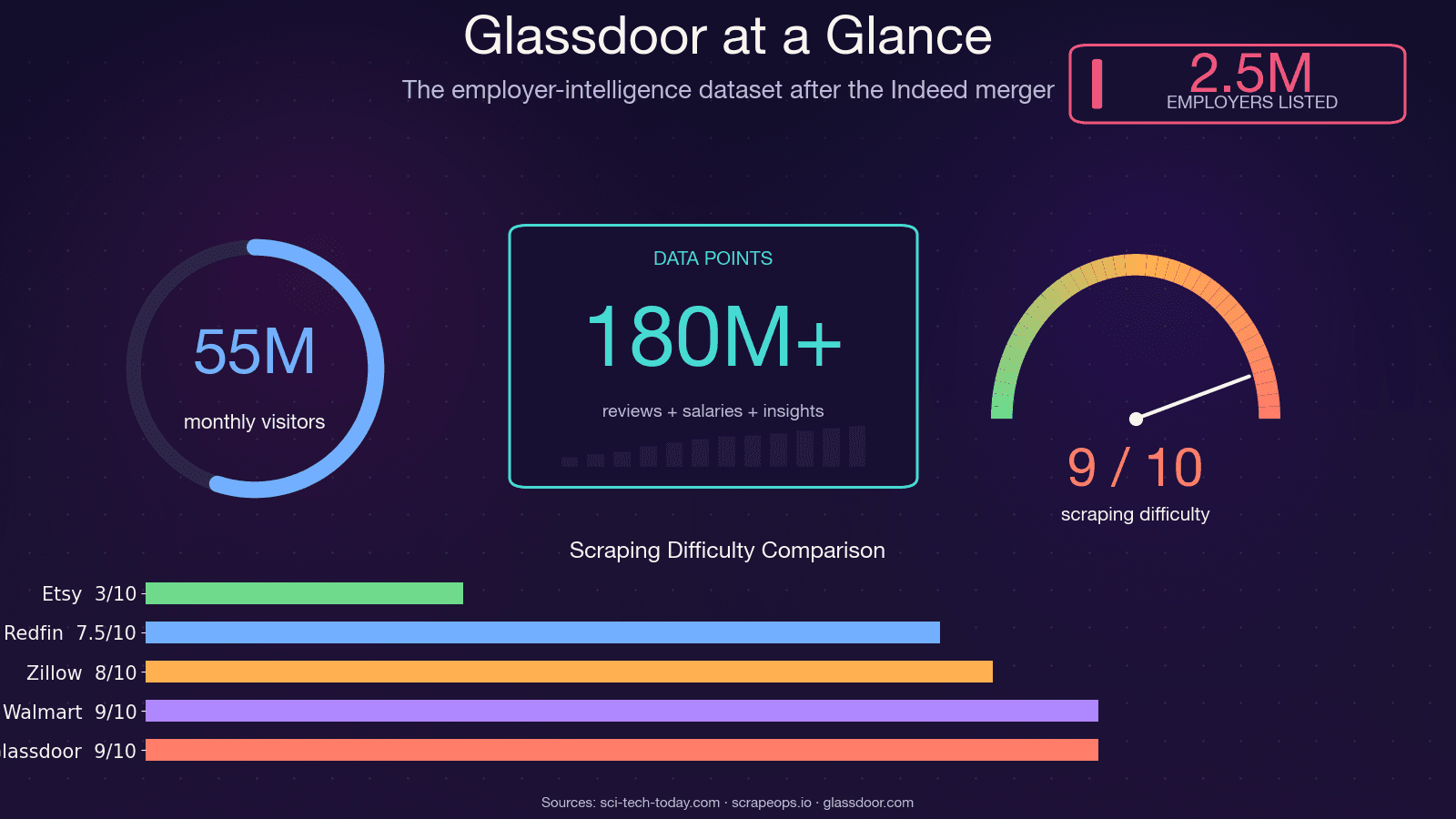
Glassdoorはただの求人サイトではありません。Web上でも屈指の企業インテリジェンス・データセットであり、が使っていて、月間約5,500万人のユニーク訪問者を集めています。ページの裏側にあるデータは、いろんな部門の実務判断を支えています。
Glassdoorデータの代表的な活用例は以下の通りです。
| ユースケース | 必要なデータ | 主な利用部門 |
|---|---|---|
| 給与ベンチマーク | 給与分布、サンプル数 | HR、報酬制度、オペレーション |
| 競合の採用動向把握 | 求人一覧、掲載頻度 | 営業、戦略、VC/Corp Dev |
| 企業ブランドのモニタリング | レビュー本文、評価トレンド、CEO承認率 | HR、マーケティング、広報 |
| リード獲得(成長企業の発見) | 求人一覧 + 企業情報 | 営業チーム、SDR |
| 市場調査・学術研究 | 3種類すべて | アナリスト、コンサルタント、研究者 |
2025年10月の米国政府閉鎖でBLSが雇用統計を公表できなかったとき、Glassdoorの経済調査チームは、自社データを使ったを公開しました。今では、このデータがどれだけ本気で扱われているかが分かります。
Pythonが定番であり続けるのは、Playwrightによるブラウザ自動化、parsel/lxmlによる解析、curl_cffiによるTLSフィンガープリント回避など、使えるエコシステムが圧倒的に広いからです。問題はPythonではありません。Glassdoorのスクレイピング難易度が、かなり上がったことにあります。
もしGlassdoorデータの取得にノーコードの代替手段を探しているなら、Thunderbitなら独自のPythonスタックを組んだり保守したりせずに、求人・レビュー・給与ページをスクレイピングできます。
そもそもGlassdoorでは何がスクレイピングできるのか?
多くのチュートリアルは求人一覧しか扱いません。でも、フォーラム投稿、GitHubのIssue、Redditの質問を追ってみると、実際に需要が高いのは、誰もちゃんと教えてくれない レビュー と 給与 です。3つのカテゴリそれぞれで取得できる項目を、以下に整理しました。
求人一覧
いちばん取り組みやすいデータです。取得できるのは、職種名、会社名、勤務地、給与目安、企業評価、掲載日、Easy Applyバッジ、求人リンクなど。求人一覧はログインなしでも一部見られますが、数ページ進むとGlassdoorがログインポップアップを出すことがあります。
企業レビュー
企業ブランド分析の本丸です。取得可能な項目には、総合評価、各種サブ評価(ワークライフバランス、文化・価値観、多様性と包摂、キャリア機会、報酬・福利厚生、経営陣)、長所、短所、投稿者の職種、レビュー日、在籍状況などがあります。レビュー全文はログイン必須で、冒頭の抜粋は見えても、全文を取るには認証が必要です。
給与データ
いちばん要望が多く、しかもいちばん厄介なデータです。取得できるのは、職種名、基本給レンジ、総報酬レンジ、給与レポート数、勤務地など。ただし給与ページは完全にログイン必須で、場合によっては「貢献して解除」の流れが重なり、自分の給与を提出しないと他人の給与が見られないこともあります。これに対応できる実用コードを載せている競合記事はほとんどありませんが、本記事で解決します。
ログイン必須かどうかの違い
以下の表を見れば、どのページが空データになりやすいかで迷わずに済みます。
| データ種類 | ログインなしで取得可能? | 補足 |
|---|---|---|
| 求人タイトル・基本情報 | ほぼ可 | 数ページ後にポップアップが出る場合あり |
| 完全な求人詳細 | 一部のみ | 2〜3回閲覧後に制限されることが多い |
| 企業レビュー(全文) | いいえ、ログイン必須 | 抜粋は表示、全文は制限 |
| 給与データ | いいえ、ログイン必須 | "contribute to unlock" が求められる場合あり |
なぜ昔のGlassdoorスクレイパーは壊れている可能性が高いのか
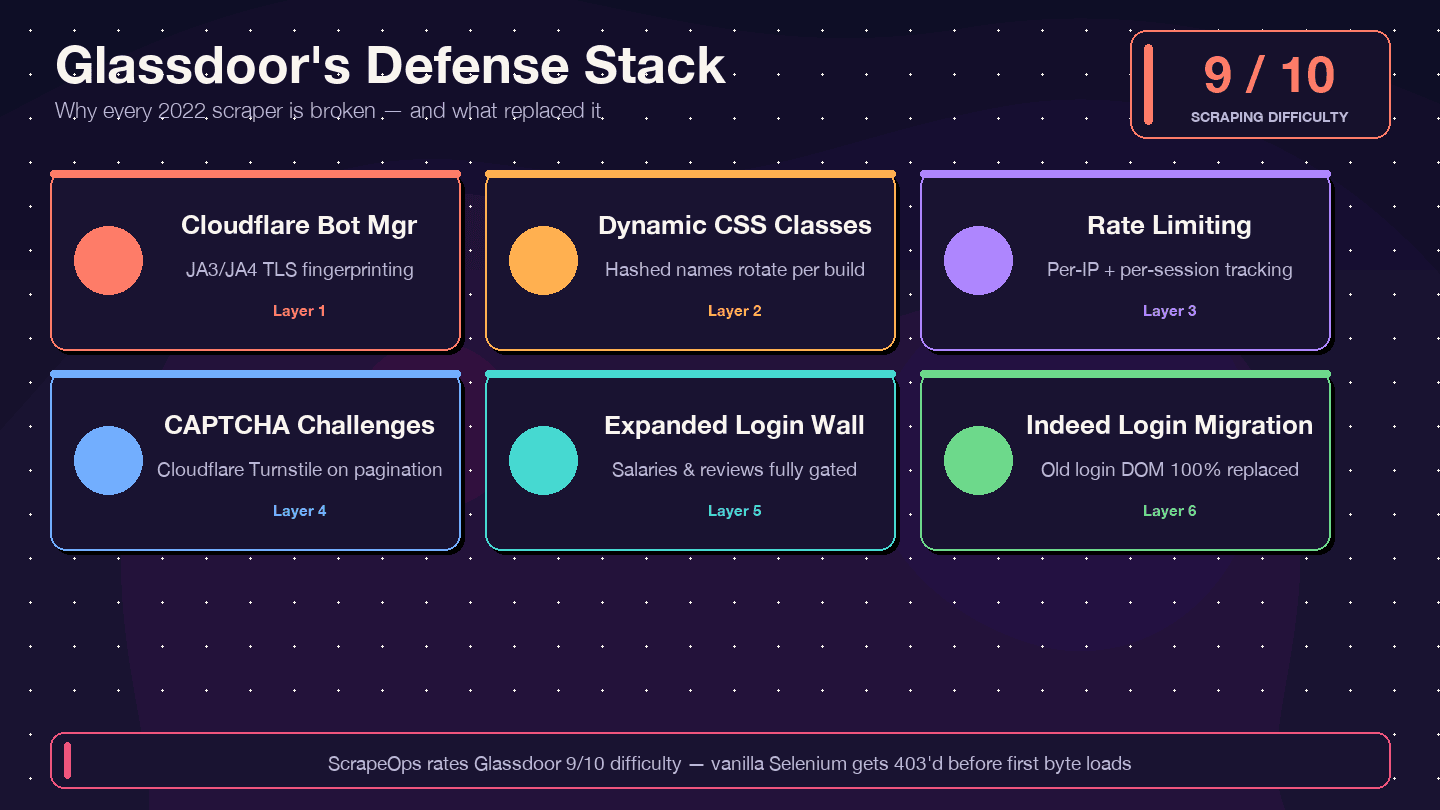
はっきり言います。2021〜2023年頃のチュートリアルをそのままコピペしても、今は動きません。GitHubで最もスター数の多い旧来のGlassdoor Seleniumスクレイパー(、約1.4kスター)には、未解決Issueが12件以上あり、内容も「Glassdoorの新UI」「Cloudflareのボット対策」「NoSuchElementException」などです。実質的には放置状態です。です。 、回避難易度を8/10と評価しています。
何が変わったのか、そしてなぜ古いコードが壊れるのかを整理すると、こうなります。
| 防御レイヤー | 変更点 | 旧スクレイパーへの影響 |
|---|---|---|
| Cloudflare Bot Management | 2024年以降、JA3/JA4フィンガープリント検知が厳格化 | 単純なrequests/Seleniumは即403 |
| 動的なCSSクラス名 | ビルドごとにクラス名をランダム化 | 古いCSSセレクタが静かに無効化 |
| レート制限 + セッション追跡 | IP単位・セッション単位の制限が強化 | 少ないページ数でブロックされる |
| CAPTCHAチャレンジ(Cloudflare Turnstileの可能性) | ページ送り時に出やすくなった | ヘッドレスブラウザが引っかかりやすい |
| ログイン壁の拡大 | 認証が必要なページが増加 | 給与・レビューが空になる |
| Indeed Loginへの移行(2026年2月) | Glassdoorのログインフォーム自体が置き換え | 旧DOMを対象にしたコードは完全に無効 |
には、次の注意書きがあります。「Glassdoorはブロック率が高いことで知られているため、Pythonコードを実行中に None が返ってきたら、ブロックされている可能性が高い。」また、 も率直にこう述べています。「requests や httpx による単純なHTTPリクエストは即座にブロックされる。」
これから紹介する対策、つまり Patchright(Playwrightのステルス派生版)、data-test属性のセレクタ、ローテーション式の住宅系プロキシ、認証済みの永続セッションは、こうした各レイヤーに対処するために作られています。
Glassdoor APIとPythonスクレイピング、最初にどちらを選ぶべきか
フォーラムでは「Glassdoor APIを使えばいいのでは?」という質問がよくあります。答えは——使えません。
。開発者ポータル自体は残っていますが、。公開レビュー用のエンドポイントはそもそも存在しておらず、MatthewChathamのスクレイパーも「Glassdoorにはレビュー用APIがないから」作られたものです。IndeedのPublisher APIにも、レビューや給与を引き継ぐ仕組みはありません。
正直な比較は以下の通りです。
| 項目 | Glassdoor Partner API v1 | Pythonスクレイピング | Thunderbit(ノーコード) |
|---|---|---|---|
| アクセス | 新規申請不可 | 可(自分で実装) | Chrome拡張 |
| 求人一覧 | 限定的 / 終了傾向 | 工夫すれば可 | 可 |
| 企業レビュー | 公開APIは存在しない | 可(ログイン必要) | 可(Browser Mode) |
| 給与データ | 公開APIは存在しない | 可(ログイン必要) | 可 |
| レート制限 | 非公開 | 自分で制御 | クレジット制 |
| 初期設定の手間 | 新規登録不可 | 数時間〜数日 | 約2分 |
| 保守負担 | 対象外 | 大きい(HTML変更で壊れる) | 小さい(AIがフィールドを再提案) |
レビューや給与データが必要なら、そしてこの記事を読んでいる人の多くがそうだと思いますが、現実的な選択肢はPythonスクレイピングかノーコードツールのどちらかです。
始める前に
- 難易度: 中級者向け(Pythonとターミナル操作に慣れていること)
- 所要時間: 初回セットアップで約30〜60分、その後はデータ種別ごとに約10分
- 必要なもの:
- Python 3.10以上(3.11または3.12推奨)
- Chromeブラウザのインストール
- Glassdoorアカウント(無料。給与・レビュー取得に必要)
- ローテーション式の住宅系プロキシ(数ページ以上スクレイピングする場合)
- 任意: ノーコードで進めたいなら
2025年にPythonでGlassdoorをスクレイピングするためのツールとライブラリ
ツール周りは大きく変わりました。今のGlassdoorの防御を相手に、実際に使える構成を紹介します。
GlassdoorにPatchrightが最適な理由
はPlaywrightのステルス派生版で、Cloudflare保護サイトで素のPlaywrightが失敗する原因である Runtime.Enable のCDPリークを修正しています。PlaywrightとAPIは同じなので、Playwrightを知っていればPatchrightも扱えます。最新は1.58.2(2026年3月)で、継続的にメンテナンスされています。
他の選択肢と比べると、
- 素のPlaywright: Runtime.Enableのリークにより、Glassdoorのログインページで検知されやすい
- Selenium + undetected-chromedriver: undetected-chromedriverの最終リリースは2024年2月で、もはや旧世代。では「テストしたすべてのドメインで失敗」とされています
- requests + BeautifulSoup: JavaScriptを描画できず、CloudflareのTLSフィンガープリントで即ブロック
- : 初期HTMLに
__NEXT_DATA__が含まれるページなら、高速経路としてかなり優秀(ブラウザより10〜20倍速い)ですが、ログインや中間チャレンジには対応できません
補助ライブラリ
- parsel(1.11.0)または lxml(6.0.4): 高速なHTML/XPath解析
- csv または pandas: データ書き出し
- asyncio: より速いページ送りのための非同期処理
プロキシは住宅系一択
GlassdoorのCloudflare層は、データセンター系ASNにかなり厳しくチャレンジを出します。という報告もあります。初期価格は、のプロモーションで1.75ドル/GB程度、またはで3.00ドル/GB程度です。本番運用では、量に応じて3〜8ドル/GBを予算に見積もるのが無難です。
また、プロキシ品質に関係なく、リクエスト間にランダムな遅延(最低3〜8秒、長時間実行では5〜15秒)は必須です。
Step 1: Python環境をセットアップする
プロジェクトフォルダを作成し、推奨スタックをインストールします。
1mkdir glassdoor-scraper && cd glassdoor-scraper
2python3.11 -m venv .venv
3source .venv/bin/activate
4pip install --upgrade pip
5# Core stack
6pip install patchright==1.58.2 parsel==1.11.0
7# Install browser binaries
8patchright install chromium
9# Optional: fast path for __NEXT_DATA__ extraction
10pip install "curl_cffi==0.15.0"PatchrightがChromiumバイナリをダウンロードするはずです。patchright install chromium が失敗する場合は、十分な空き容量(約300MB)とPython 3.10以上であることを確認してください。
Step 2: Patchrightを起動してGlassdoorに移動する
Cloudflare層に対して動く、基本の起動パターンはこちらです。
1from patchright.sync_api import sync_playwright
2import random, time
3with sync_playwright() as p:
4 browser = p.chromium.launch(
5 headless=False, # headless is still more detectable
6 channel="chrome", # use real Chrome, not bundled Chromium
7 )
8 context = browser.new_context(
9 viewport={"width": 1440, "height": 900},
10 locale="en-US",
11 timezone_id="America/New_York",
12 user_agent=(
13 "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) "
14 "AppleWebKit/537.36 (KHTML, like Gecko) "
15 "Chrome/134.0.0.0 Safari/537.36"
16 ),
17 )
18 page = context.new_page()
19 page.goto(
20 "https://www.glassdoor.com/Job/new-york-data-engineer-jobs-"
21 "SRCH_IL.0,8_IC1132348_KO9,22.htm"
22 )
23 # Dismiss the login overlay — content is still in the DOM
24 page.add_style_tag(content="""
25 #HardsellOverlay, .LoginModal { display: none !important; }
26 body { overflow: auto !important; position: initial !important; }
27 """)
28 page.wait_for_selector("[data-test='jobListing']")
29 print("Page loaded — job listings visible.")ここで大事なのは、channel="chrome" を指定して、バンドル版のChromiumではなく、インストール済みのChrome本体を使うことです。これでブラウザの指紋がより自然になります。add_style_tag のトリックは、Glassdoorのログインモーダル(#HardsellOverlay)をクリックせずに非表示化するものです。 「データ自体はDOM内に残っていて、ただオーバーレイに覆われているだけ」と確認しています。つまり、モーダルが表示されていてもHTMLの中にはデータが存在します。
Chromeウィンドウが開き、Glassdoorの求人検索ページに移動し、ログインポップアップに邪魔されず求人カードが表示されれば成功です。
Step 3: Glassdoorの求人一覧をスクレイピングする
安定したセレクタを見つける
GlassdoorはビルドごとにCSSクラス名をランダム化するため、2023年のチュートリアルにある .jobCard_xyz123 のようなセレクタは、今では黙って何も返さないことがあります。代わりに使うべきなのが data-test 属性です。これはGlassdoor内部のQA用命名規則で、デプロイ間でも比較的安定しています。
求人一覧の各項目に対応するセレクタは以下の通りです。
| 項目 | セレクタ |
|---|---|
| 求人カードのコンテナ | [data-test="jobListing"] |
| 職種名 | [data-test="job-title"] |
| 求人リンク | a[data-test="job-link"] |
| 会社名 | [data-test="employer-name"] |
| 勤務地 | [data-test="emp-location"] |
| 給与レンジ | [data-test="detailSalary"] |
| 企業評価 | [data-test="rating"] |
| 掲載日 | [data-test="job-age"] |
| 次ページボタン | [data-test="pagination-next"] |
求人データを抽出する
1from parsel import Selector
2import csv, random, time
3def scrape_jobs(page, max_pages=5):
4 all_jobs = []
5 for page_num in range(1, max_pages + 1):
6 html = page.content()
7 sel = Selector(text=html)
8 cards = sel.css('[data-test="jobListing"]')
9 if not cards:
10 print(f"Page {page_num}: No cards found — possible block or selector change.")
11 break
12 for card in cards:
13 job = {
14 "title": card.css('[data-test="job-title"]::text').get("").strip(),
15 "company": card.css('[data-test="employer-name"]::text').get("").strip(),
16 "location": card.css('[data-test="emp-location"]::text').get("").strip(),
17 "salary": card.css('[data-test="detailSalary"]::text').get("").strip(),
18 "rating": card.css('[data-test="rating"]::text').get("").strip(),
19 "link": card.css('a[data-test="job-link"]::attr(href)').get(""),
20 "posted": card.css('[data-test="job-age"]::text').get("").strip(),
21 }
22 if job["link"] and not job["link"].startswith("http"):
23 job["link"] = "https://www.glassdoor.com" + job["link"]
24 all_jobs.append(job)
25 print(f"Page {page_num}: scraped {len(cards)} jobs")
26 # Pagination
27 next_btn = page.query_selector('[data-test="pagination-next"]')
28 if next_btn and page_num < max_pages:
29 next_btn.click()
30 time.sleep(random.uniform(3, 8))
31 page.wait_for_selector("[data-test='jobListing']")
32 else:
33 break
34 return all_jobsCSVに保存する
1def save_to_csv(jobs, filename="glassdoor_jobs.csv"):
2 if not jobs:
3 print("No jobs to save.")
4 return
5 keys = jobs[0].keys()
6 with open(filename, "w", newline="", encoding="utf-8") as f:
7 writer = csv.DictWriter(f, fieldnames=keys)
8 writer.writeheader()
9 writer.writerows(jobs)
10 print(f"Saved {len(jobs)} jobs to {filename}")ページネーションの上限についても注意が必要です。Glassdoorの検索結果は、総件数にかかわらずおおむね30ページで打ち止めになります。もっと広く取りたいなら、無理に先へ進めるより、勤務地・職種・給与レンジで検索条件を絞る方が現実的です。
私のテストでは、求人一覧5ページ(約75件)のスクレイピングに、ランダムな待機を含めて約45秒かかりました。手作業で同じことをやれば、少なくとも20分はコピー&ペーストにかかります。
Step 4: Glassdoorの企業レビューをスクレイピングする
ここは、他のどのチュートリアルも実用コードをあまり載せていない部分です。レビューは、企業インテリジェンスの中心です。感情分析、企業文化の兆候、マネジメント上の赤信号がここに詰まっています。
レビューページへ移動する
レビューURLは /Reviews/{Company}-Reviews-E{id}.htm という形式です。Glassdoorで会社を検索し、URLを見れば employer ID を確認できます。
1def navigate_to_reviews(page, company_reviews_url):
2 page.goto(company_reviews_url)
3 page.add_style_tag(content="""
4 #HardsellOverlay, .LoginModal { display: none !important; }
5 body { overflow: auto !important; position: initial !important; }
6 """)
7 page.wait_for_selector('[data-test="review"]', timeout=15000)隠しBFFエンドポイント(最短ルート)
私の調査でいちばん重要だった発見は、Glassdoorのレビューには 内部JSON API があり、HTML解析をまるごと避けられることです。 でもこのエンドポイントが文書化されており、DOMスクレイピングよりずっと安定しています。
1import json, re, requests
2def get_review_ids(page):
3 """レビュー詳細ページのHTMLから employerId と dynamicProfileId を取得する。"""
4 html = page.content()
5 sel = Selector(text=html)
6 script_text = sel.xpath(
7 "//script[contains(text(), 'profileId')]/text()"
8 ).get("")
9 employer_match = re.search(r'"employer"\s*:\s*(\{[^}]+\})', script_text)
10 if employer_match:
11 meta = json.loads(employer_match.group(1))
12 return meta.get("id"), meta.get("profileId")
13 return None, None
14def fetch_reviews_bff(page, employer_id, profile_id, max_pages=5):
15 """Glassdoorの内部BFFエンドポイントから構造化レビューを取得する。"""
16 all_reviews = []
17 cookies = {c["name"]: c["value"] for c in page.context.cookies()}
18 for pg in range(1, max_pages + 1):
19 payload = {
20 "applyDefaultCriteria": True,
21 "employerId": employer_id,
22 "dynamicProfileId": profile_id,
23 "employmentStatuses": ["REGULAR", "PART_TIME"],
24 "language": "eng",
25 "onlyCurrentEmployees": False,
26 "page": pg,
27 "pageSize": 10,
28 "sort": "DATE",
29 "textSearch": "",
30 }
31 resp = requests.post(
32 "https://www.glassdoor.com/bff/employer-profile-mono/employer-reviews",
33 json=payload,
34 cookies=cookies,
35 headers={"Content-Type": "application/json"},
36 )
37 if resp.status_code != 200:
38 print(f"BFF returned {resp.status_code} on page {pg}")
39 break
40 data = resp.json()
41 reviews = data.get("data", {}).get("employerReviews", {}).get("reviews", [])
42 total_pages = data.get("data", {}).get("employerReviews", {}).get("numberOfPages", 1)
43 for r in reviews:
44 all_reviews.append({
45 "title": r.get("summary", ""),
46 "rating": r.get("ratingOverall"),
47 "pros": r.get("pros", ""),
48 "cons": r.get("cons", ""),
49 "author_role": r.get("jobTitle", {}).get("text", ""),
50 "date": r.get("reviewDateTime", ""),
51 "recommend": r.get("isRecommend"),
52 })
53 print(f"Reviews page {pg}/{total_pages}: got {len(reviews)} reviews")
54 if pg >= total_pages:
55 break
56 time.sleep(random.uniform(3, 6))
57 return all_reviewsBFFエンドポイントを使うと、レビュー項目が整理されたJSONで取れます。HTML解析もCSSセレクタの破損も必要ありません。必要なのは、Step 6で扱う認証済みPlaywrightコンテキストから取得したセッションCookieと、レビューHTMLから employerId と dynamicProfileId を先に抜き出すことだけです。
レビュー用HTMLフォールバックセレクタ
BFFの仕様が変わったり、DOMパースの方が好みなら、安定している data-test セレクタは以下です。
| 項目 | セレクタ |
|---|---|
| レビューコンテナ | [data-test="review"] |
| 見出し | [data-test="review-title"] |
| 総合評価 | [data-test="overall-rating"] |
| 長所 | [data-test="pros"] |
| 短所 | [data-test="cons"] |
| 日付 | [data-test="review-date"] |
| 投稿者の職種 | [data-test="author-jobTitle"] |
Step 5: Glassdoorの給与データをスクレイピングする
給与ページは完全にログイン必須です。このコードで実データを返すには、先に認証済みセッション(Step 6)が必要です。
給与ページへ移動する
給与URLは /Salary/{Company}-Salaries-E{id}.htm で、ページ送りは _P{n}.htm 形式です。
1def scrape_salaries(page, salary_url, max_pages=3):
2 all_salaries = []
3 for pg in range(1, max_pages + 1):
4 url = salary_url if pg == 1 else salary_url.replace(".htm", f"_P{pg}.htm")
5 page.goto(url)
6 page.add_style_tag(content="""
7 #HardsellOverlay { display: none !important; }
8 body { overflow: auto !important; position: initial !important; }
9 """)
10 time.sleep(random.uniform(3, 7))
11 html = page.content()
12 sel = Selector(text=html)
13 items = sel.css('[data-test="salary-item"]')
14 if not items:
15 print(f"Salary page {pg}: No items — possible login gate or block.")
16 break
17 for item in items:
18 salary = {
19 "job_title": item.css('[class*="SalaryItem_jobTitle__"]::text').get("").strip(),
20 "salary_range": item.css('[class*="SalaryItem_salaryRange__"]::text').get("").strip(),
21 "count": item.css('[class*="SalaryItem_salaryCount__"]::text').get("").strip(),
22 }
23 all_salaries.append(salary)
24 print(f"Salary page {pg}: scraped {len(items)} entries")
25 return all_salariesここで注目したいのは、[class*="SalaryItem_jobTitle__"] という前方一致パターンです。Glassdoorの給与ページでは、SalaryItem_jobTitle__XWGpT のようなCSSモジュール由来のハッシュ付きクラス名が使われていますが、後ろのハッシュはデプロイのたびに変わります。前半部分は安定していても、完全一致で固定名を書いてはいけません。
Step 6: Glassdoorのログイン壁を突破する
給与データと完全なレビュー本文を取るための、最重要パートです。方法はシンプルで、まず可視ブラウザで一度だけ手動ログインし、認証済みセッションを保存して、その後のスクレイピングで再利用します。
認証済みセッションを保存する
次のスクリプトを1回実行します。Chromeウィンドウが開き、Glassdoorのログインページ(現在はIndeed Loginへリダイレクト)に移動します。あとはブラウザ上で手動ログインしてください。
1import asyncio
2from pathlib import Path
3from patchright.async_api import async_playwright
4STATE_FILE = Path("glassdoor_state.json")
5async def login_and_save():
6 async with async_playwright() as p:
7 browser = await p.chromium.launch(headless=False, channel="chrome")
8 context = await browser.new_context(
9 viewport={"width": 1366, "height": 800},
10 locale="en-US",
11 )
12 page = await context.new_page()
13 await page.goto("https://www.glassdoor.com/profile/login_input.htm")
14 print("ブラウザでログインし、完了したらここでEnterを押してください...")
15 input()
16 await context.storage_state(path=str(STATE_FILE))
17 print(f"Session saved to {STATE_FILE}")
18 await browser.close()
19asyncio.run(login_and_save())ログインしてEnterを押すと、PatchrightはCookieとlocal storageをすべて glassdoor_state.json に保存します。このファイルには、gdId、GSESSIONID、cf_clearance、認証トークンが含まれます。
スクレイピング時にセッションを再利用する
以降の実行では、この保存済み状態を読み込むだけです。毎回手動ログインする必要はありません。
1async def scrape_with_auth(target_url):
2 async with async_playwright() as p:
3 browser = await p.chromium.launch(headless=True, channel="chrome")
4 context = await browser.new_context(
5 storage_state="glassdoor_state.json"
6 )
7 page = await context.new_page()
8 await page.goto(target_url)
9 await page.add_style_tag(
10 content="#HardsellOverlay{display:none!important}"
11 )
12 await page.wait_for_load_state("networkidle")
13 html = await page.content()
14 await browser.close()
15 return html保存したセッションは、普通は20〜30分ほどのアクティブ利用で有効ですが、その後は再チャレンジされることがあります。長時間のスクレイピングでは、データがあるはずのページで結果がゼロだったら、ログインスクリプトを再実行してstateファイルを更新する仕組みを入れておくと安心です。
ログインポップアップの検出と消し方
部分的に制限されるページ(データ自体は表示されるが、モーダルが重なるタイプ)では、先ほどのCSS注入が有効です。
1page.add_style_tag(content="""
2 #HardsellOverlay, .LoginModal { display: none !important; }
3 body { overflow: auto !important; position: initial !important; }
4""")これは、HTMLの中にすでにデータがある場合にだけ機能します。給与や深いレビューのような完全サーバー制限ページでは、Step 6の認証済みセッションが唯一の方法です。
Glassdoorスクレイパーを壊れにくく保つコツ
Glassdoorはフロントエンドを頻繁に更新します。スクレイパーに耐久性を持たせるには、次の点が重要です。
クラス名より data-test 属性を優先する
GlassdoorはCSSクラス名をランダム化する一方で、data-test 属性は比較的安定しています。常に .jobCard_abc123 より [data-test="jobListing"] を優先してください。data-test がない場合(給与のフィールドなど)は、[class*="SalaryItem_jobTitle__"] のような部分一致を使います。
プロキシをローテーションし、待機時間をランダム化する
ローテーション式の住宅系プロキシを使ってください。データセンターIPはほぼ即座にチャレンジされます。ページ読み込みの合間には3〜8秒、長時間ジョブでは5〜15秒のランダム待機を入れましょう。可能なら、Cloudflareの挙動検知が最も厳しくなりやすい米国の営業時間帯を避けるのも有効です。
壊れたかどうかを監視する
スクレイパーに簡単なチェックを入れてください。データがあるはずのページで抽出件数がゼロなら、「空の結果」ではなく「セレクタが壊れた」とみなしてアラートを出すべきです。Glassdoorは予告なくフロントエンドを更新するので、週1回の小規模テストスクレイプを回しておくと早期検知できます。
可能なら __NEXT_DATA__ の高速経路を使う
GlassdoorはNext.js + Apollo GraphQLのアプリです。多くのページでは、<script id="__NEXT_DATA__"> タグの中にGraphQLキャッシュ全体がJSONで入っています。これを解析する方法はDOMスクレイピングよりずっと堅牢で、できます。
1import json
2def extract_next_data(html):
3 sel = Selector(text=html)
4 raw = sel.css("script#__NEXT_DATA__::text").get()
5 if raw:
6 return json.loads(raw)["props"]["pageProps"].get("apolloCache", {})
7 return Noneこれで、求人・レビュー・給与の各項目を含む構造化されたApolloキャッシュを取得できます。CSSセレクタは不要です。GlassdoorのReactフロントエンドを支えているのと同じデータを読むため、現時点でかなり壊れにくい取得方法です。
コードを書かずにGlassdoorをスクレイピングする:Thunderbitを使う方法
この記事を読む人すべてが開発者とは限りません。HRチーム、採用担当、営業企画アナリスト、市場調査担当にもGlassdoorデータは必要ですし、そのためにPlaywrightのコンテキスト管理やプロキシローテーションを覚える必要はありません。
は、コードを書かずに同じ求人・レビュー・給与データを抽出できるAI Web ScraperのChrome拡張です。私はThunderbitチームで働いているので、その点は正直にお伝えします。ただ、ここで紹介するのは、Glassdoorスクレイピングでいちばん難しい2つの課題を本当に解決できるからです。
Glassdoor上でThunderbitが動く仕組み
使い方は2クリックです。
- Chromeで任意のGlassdoorページを開く(求人検索、企業レビュー、給与ページなど)
- Thunderbitのサイドバーで AI Suggest Fields をクリックすると、AIがページDOMを読み取り、列候補(職種名、会社名、評価、給与レンジ、長所、短所など)を提案します
- Scrape をクリックすると、CSSセレクタやブラウザ自動化コードなしでテーブルに抽出されます
Thunderbitにはがあり、1回の実行で企業ごとに23項目以上を取得できます。求人一覧、レビュー、給与ページについても、汎用のAI Suggest Fieldsワークフローで任意のGlassdoor URLに対応できます。
コードなしでログイン壁を越える
GlassdoorにおけるThunderbitの大きな強みがここです。Browser Mode はあなた自身のChromeセッション内で動きます。すでにChromeでGlassdoorにログインしていれば、ThunderbitはそのCookieを自動で引き継ぎます。サーバー側スクレイパーを止める給与・レビューのログイン壁が、そのまま問題になりません。Cookie管理も、永続コンテキストも、セッションコードも不要です。
サブページスクレイピングで情報を深掘りする
まず一覧ページ(例: 検索で出た30社)を起点にし、Thunderbitに行を列挙させてから、 を有効にすると、各社のレビューまたは給与ページを巡回して、詳細説明やレビュー本文、給与情報までテーブルに追加できます。
業務ツールへエクスポートする
CSVやJSONを書き出すPythonスクリプトと違い、ThunderbitはGoogle Sheets、Airtable、Notion、Excelへ直接エクスポートできます。しかも全プランで無料です。チームで共有・分析したいときにかなり便利です。
PythonとThunderbit、どちらを使うべきか
| シナリオ | おすすめの方法 |
|---|---|
| 定期実行するデータパイプラインを作る | Python + Patchright |
| 単発の調査や小規模チーム案件 | Thunderbit |
| すべての項目を細かくプログラム制御したい | Python |
| 今日すぐGlassdoorデータが必要な非開発者 | Thunderbit |
| 1回で1,000ページ以上をスクレイピングしたい | Python + プロキシ |
| 30社分を補完情報つきで取得したい | どちらでも可 — 設定はThunderbitの方が速い |
Thunderbitの料金は無料プランから始まり、 で3,000クレジットです。1出力行あたり1クレジット(サブページスクレイピングでは2クレジット)なので、補完付き30社の実行を月に約33回まかなえます。
Glassdoorをスクレイピングするのは合法?
ここは簡潔に事実だけ述べます。Glassdoorのでは、自動スクレイピングを明確に禁止しています。「当社の明示的な書面許可なしに、いかなる目的であってもロボット、スパイダー、スクレイパー等を使ってサービスにアクセスしてはならない」とされています。
ただし、法的な状況は1つの規約だけで決まるほど単純ではありません。
- (米カリフォルニア北部地区、2024年1月): ログインしていなければ規約に同意していないため、公開ページのログアウト状態でのスクレイピングは規約違反ではないと判断
- hiQ Labs v. LinkedIn(第9巡回): CFAAは、一般公開されているデータの自動収集には適用されないとされた。ただし、偽アカウントやログイン後のスクレイピングは別問題
- Van Buren v. United States(最高裁、2021年): CFAAの「許可されたアクセスを超える」の解釈が狭められた
実務上のポイントはこうです。ログインせずに公開求人だけをスクレイピングするなら、比較的安全な法的領域にあります。一方、ログイン済みセッションでのスクレイピングは、登録時に利用規約へ同意していることになり、しかも規約上は明確に禁止されています。これはPythonスクリプトにもThunderbitのBrowser Modeにも同じく当てはまります。
守るべき倫理指針としては、以下が挙げられます。
- 人間の閲覧速度を大きく下回るレート制御をする
- レビュアーの個人識別情報をスクレイピングまたは再販しない
- robots.txt の指示を尊重する
- 本当に必要な項目だけを取得する
まとめ:どの方法があなたに合うか?
本ガイドでは、Indeed Loginへの移行、Cloudflare Bot Management、そして過去のチュートリアルを壊したCSSモジュールのクラス名ローテーションに対応しながら、求人・レビュー・給与の3種類すべてを、2025年時点で動くコード付きで解説しました。
判断の目安は以下の通りです。
| あなたの状況 | 最適な方法 |
|---|---|
| データパイプラインを作る開発者 | Python + Patchright(上記の手順どおり) |
| 単発の調査、または繰り返しの小規模取得 | Thunderbit(ノーコード、ブラウザベース) |
| 小規模な求人一覧だけ欲しい | まずGlassdoor APIがまだ使えるか確認(たぶん不可) |
| 特に給与やレビューが必要 | PythonスクレイピングかThunderbitが必須 — APIは対象外 |
| データ共有が必要な非開発チーム | Thunderbit → Google Sheetsへエクスポート |
Glassdoorの防御は今後も進化し続けます。セレクタは壊れますし、新しいチャレンジも出てきます。このガイドはブックマークしておいてください。Webスクレイピングのツールや手法をさらに深く知りたい方は、、、 もあわせてどうぞ。 では、操作手順の動画も見られます。
よくある質問
1. Glassdoorはログインなしでスクレイピングできますか?
はい、求人一覧の多くと、概要レベルの企業評価は可能です。いいえ、完全な給与内訳や、最初の数ページを超えるレビュー全文は取得できません。#HardsellOverlay はCSSだけのモーダルなので、基礎HTMLには1ページ目のデータが残っていますが、深い内容はGlassdoorの「見せる代わりに条件を満たしてね」という壁の向こうでサーバー側に制限されています。
2. 2025年にGlassdoorスクレイピングでいちばん相性の良いPythonライブラリは?
Patchright(Playwrightのステルス派生版)が第一候補です。素のPlaywrightにある Runtime.Enable のCDPリークを修正しており、Cloudflareがチェックしているポイントにも対応しています。初期HTMLに __NEXT_DATA__ を含む一覧ページなら、impersonate="chrome124" を付けた curl_cffi が10〜20倍高速ですが、ログイン必須ページには対応できません。
3. Glassdoorでブロックされないためにはどうすればいいですか?
Patchright か rebrowser-playwright を使ってください(素のPlaywrightやSeleniumは避ける)。住宅系プロキシをローテーションし、データセンターIPは使わないこと。ページ間には3〜8秒のランダム遅延を入れ、Cookie(gdId、cf_clearance、GSESSIONID)はリクエスト間で維持してください。再チャレンジまでのセッション有効時間は20〜30分程度と見込んでください。
4. スクレイピングの代わりに使えるGlassdoor APIはありますか?
実質的にはありません。旧Partner APIはで、公開レビュー用エンドポイントも存在せず、IndeedのPublisher APIにも移行手段がありません。レビューと給与データを扱うなら、スクレイピングかThunderbitのようなノーコードツールが現実的な選択です。
5. Glassdoorスクレイパーはどのくらいの頻度で壊れますか?
かなり頻繁です。Glassdoorは予告なくフロントエンドを更新し、CSSモジュールのクラス名ハッシュはビルドごとに変わります。いちばん安定している取得方法は、(1) data-test属性セレクタ、(2) __NEXT_DATA__ のJSON、(3) 内部BFFレビューエンドポイントです。ゼロ件チェックを入れ、毎週小さくテストスクレイプして早期に壊れを検知してください。
さらに詳しく知る