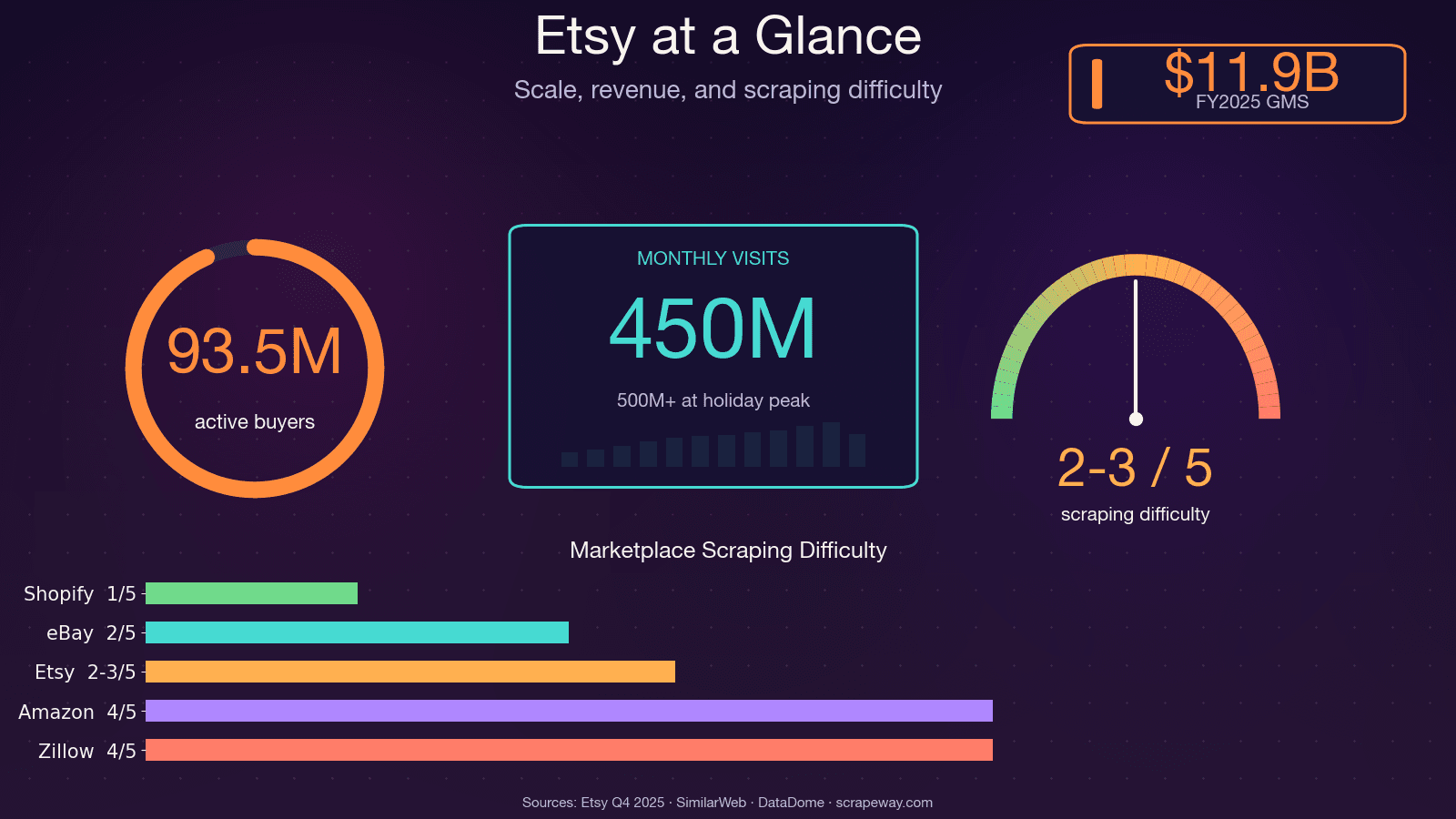
Etsyには1億件以上のアクティブな出品、560万人のセラー、そして月間およそ4億5,000万回の訪問があります。価格、トレンド、レビュー、競合に関する公開データがこれだけある以上、手作業で集めようとしたら大変なのは言うまでもありません。
以前、ある市場調査プロジェクトで競合商品の一覧を手作業でまとめようとしたことがあります。30商品を超えたあたりで、そのスプレッドシートに至るまでの自分の人生選択を疑い始めました。とはいえ、Etsyのデータは価格分析、商品開発、ニッチ発掘、セラー比較において非常に価値があります。問題は、それを本当に大規模に取得できるかどうかです。このガイドでは、Pythonを使ってEtsyをスクレイピングする方法を、主要な4種類のページタイプ(検索結果、商品ページ、ショップページ、レビュー)ごとにまとめて解説します。さらに、Etsyのボット対策への正直な向き合い方と、面倒なスクリプトを使わずに済ませたい人向けのノーコード代替手段も紹介します。
PythonでEtsyをスクレイピングするとはどういうことか?
ウェブスクレイピングとは、ひと言でいえば、ウェブページにアクセスして、欲しいデータ――商品名、価格、説明、画像、評価、レビュー、ショップ情報など――を自動で抽出し、スプレッドシートやデータベースのような構造化形式に整理するコードを書くことです。
こうした作業にはPythonが定番です。初心者にも扱いやすく、コミュニティも大きく、スクレイピング向けのライブラリエコシステムが充実しています。たとえば、Requests(ページ取得用)、BeautifulSoup(HTML解析用)、SeleniumとPlaywright(ブラウザ自動化用)、そしてpandas(データ整理・出力用)などです。PythonはStack Overflowの年次開発者調査でも常に人気上位3位に入り、スクレイピング関連ライブラリの多くはPyPIでもダウンロード数上位に入っています。
Etsyをスクレイピングするときは、ブラウザに表示されるHTML、場合によっては隠しJSONからデータを取得します。抽出できるデータの例は次のとおりです。
- 商品名、価格、説明、画像、バリエーション
- セラー/ショップ情報(名前、販売数、所在地、評価)
- 評価とレビュー全文
- 検索結果一覧、カテゴリ、トレンドの兆候
なぜEtsyをスクレイピングするのか?ROIを生む実用ユースケース
Etsyのスクレイピングは、単なる技術演習ではありません。競争優位につながります。セラーであれ、プロダクトマネージャーであれ、データアナリストであれ、整ったEtsyデータをすぐ使える形で持っていることは、最終的な収益に直接影響します。
| ユースケース | スクレイピング対象 | 恩恵を受ける人 | ビジネスへの影響 |
|---|---|---|---|
| 競合価格分析 | 検索結果 + 商品価格 | EC運用、セラー | 動的価格設定により平均で収益が5〜22%向上する可能性 |
| ニッチ・トレンド発掘 | 検索結果、トレンド商品一覧 | 創業者、アナリスト | トレンドのニッチをいち早く発見(例:「preppy pajamas」は検索数が+1,112%増加) |
| 商品開発・改善 | レビュー、商品詳細 | プロダクトチーム | あるキッチン用品ブランドはレビュー感情データを活用し、60日で「ベストセラー1位」を奪還 |
| SEO・キーワード調査 | 検索結果、商品タイトル/タグ | マーケティングチーム | 需要が高く、競争の少ないキーワードを特定 |
| セラー比較 | ショップページ、販売数 | 営業チーム、アナリスト | 購入リストではなく、1件あたり$0.01〜0.10で有望なリードリストを構築 |
| 在庫・在庫切れ監視 | 商品の在庫状況 | EC運用 | 競合の在庫変化に素早く対応 |
これらのユースケースには、それぞれ異なるEtsyページタイプのデータが必要です。だからこそ、このチュートリアルでは4種類すべてを扱います。
時間短縮効果:手作業と自動化の比較
- 手作業でのEtsy調査: 1商品あたり30〜45分(100商品なら50〜75時間)
- 自動スクレイピング: 100件を2〜5分で取得
- AIによるスクレイピングはで、精度は最大99.5%
Etsy APIとウェブスクレイピング:どちらを選ぶべきか?
コードを書く前に、まず考えるべきことがあります。Etsyの公式APIを使うべきか、それともサイトを直接スクレイピングすべきか、という点です。これはフォーラムでもよく見かける質問ですが、答えは必要なデータ次第です。
Etsy APIでできること、できないこと
EtsyはOAuth 2.0認証付きのAPI v3を提供しています。自分のショップのデータ――出品、注文、領収書――にアクセスする用途には使えます。しかし、実際には制約も多くあります。
- 競合データ: APIは基本的に自分のショップに限定されます。ほかのセラーの価格、販売数、出品情報は取得できません。
- レビュー: 大量のレビュー本文を取得するための堅牢なエンドポイントはありません。
- レート制限: デフォルトで1秒あたり10リクエスト、1日10,000リクエスト。オフセット上限は12,000件です。
- AI/ML利用: アプリ審査で明確に却下されます。
- ドキュメント: コミュニティからの不満も多く、例が不十分、廃止済みエンドポイント、サポートの遅さなどが指摘されています。
ウェブスクレイピングのほうが適している場面
競合インテリジェンス、レビューの感情分析、ショップ横断の分析、あるいはAPIでは公開されないデータが必要なら、スクレイピングが有力です。もちろん代償として、Etsyのボット対策に向き合う必要があります(その話は後ほど詳しく触れます)。また、初期設定にも手間がかかります。
比較表:API vs. スクレイピング vs. ノーコード
| 比較項目 | Etsy公式API | Pythonによるウェブスクレイピング | Thunderbit(ノーコード) |
|---|---|---|---|
| 商品価格へのアクセス | ✅(一部フィールドのみ) | ✅ HTML/JSON-LDを完全取得 | ✅ AIが可視フィールドを抽出 |
| レビューデータ | ❌ 一括取得不可 | ✅ レビュー用エンドポイント/HTML経由 | ✅ サブページスクレイピング |
| 競合ショップデータ | ❌ 自分のショップのみ | ✅ 公開ショップなら可 | ✅ 公開ショップなら可 |
| 認証の必要性 | ✅ OAuth 2.0 | ⚠️ ログイン済みデータはCookieが必要 | ⚠️ ログイン時はブラウザスクレイピング |
| ボット対策リスク | なし | 高い(DataDome) | 対応済み(ブラウザネイティブ) |
| 初期設定時間 | 中程度(APIキー、OAuth) | 長い(コード + プロキシ) | 約2分 |
競合データ、レビュー、ショップ横断分析が必要なら、APIだけでは足りません。それが現実です。
コードを書く前に、Pythonでのスクレイピング手法を選ぶ
RedditやStack Overflowでよく見る質問があります。「Requests + BeautifulSoup、Selenium、プロキシAPI、それとも別の方法を使うべき?」というものです。正解は、スキルレベル、予算、用途によって変わります。
| 手法 | 向いている用途 | 学習コスト | JS対応 | ボット対策 | コスト |
|---|---|---|---|---|---|
| Requests + BeautifulSoup | すべてを細かく制御したい開発者 | 中 | ❌ | 手動対応(ヘッダー、プロキシ) | 無料 + プロキシ費用 |
| Selenium / Playwright | JS中心のページ、ログインフロー | 高 | ✅ | 一部対応(ブラウザ指紋) | 無料 + プロキシ費用 |
| プロキシAPIサービス | 大規模運用 + ボット対策回避 | 中 | ✅(API経由) | ✅ 標準搭載 | 月額$49〜 |
| Thunderbit(ノーコード) | 非エンジニア、手早い抽出 | 非常に低い | ✅(ブラウザネイティブ) | ✅(ブラウザセッション) | 無料プランあり |
Pythonで細かく制御したい、あるいは扱いに慣れているなら、Requests + BeautifulSoupが向いています。JS描画やログインフローが必要ならSeleniumを使いましょう。大規模にボット対策を回避したいならプロキシサービスを検討してください。そして、コードを書いたり保守したりせずにEtsyデータを取りたいなら、Thunderbitは有力候補です。これについては後ほど詳しく紹介します。
Etsyはどうやって対抗してくるのか:DataDomeのボット対策を理解する
多くのスクレイピングガイドは「とりあえずプロキシを使えばいい」と言って終わります。Etsyではそれだけでは不十分です。Etsyはウェブ上でも特に強力なボット対策システムのひとつ、DataDomeを使っています。ではEtsyが成功事例として取り上げられており、かつてスクレイパーがEtsyの計算コストの約1%を占めていたとしています。
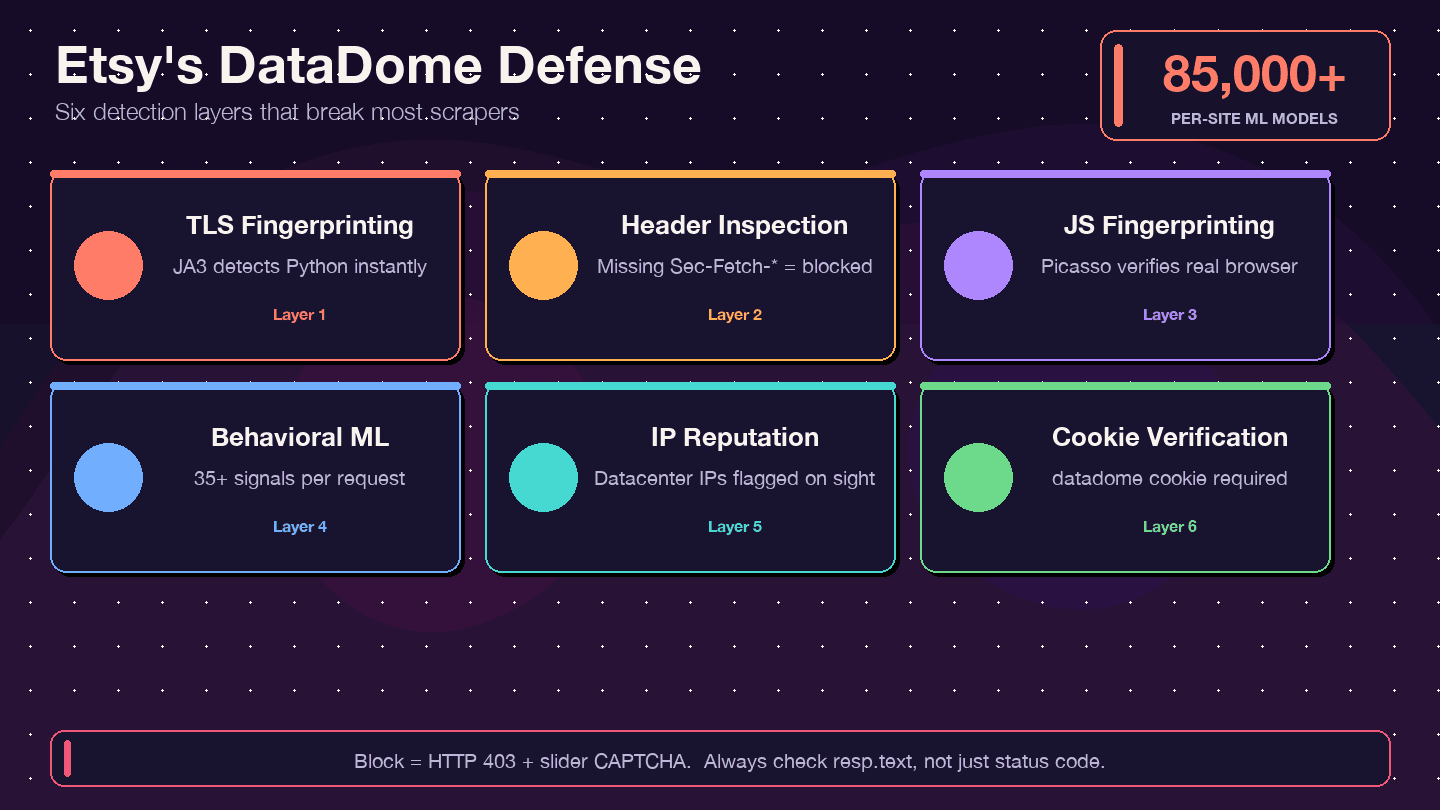
DataDomeとは何か、どう動くのか?
DataDomeはIPアドレスだけを見ているわけではありません。多層的な検知スタックを動かしています。
- TLSフィンガープリント(JA3): Pythonの
requestsライブラリには特徴的なTLSシグネチャがあり、DataDomeはすぐに見抜けます。 - HTTPヘッダー/プロトコル検査: 完全で一貫したブラウザヘッダーを確認します。足りないヘッダーや順序がおかしいヘッダーは警告サインです。
- JavaScriptフィンガープリント(Picasso protocol): ブラウザ上でJSチャレンジを実行し、本物のユーザーかどうかを確認します。
- 行動ベースの機械学習: リクエストごとに35以上のシグナルを分析し、サイトごとのモデルは85,000以上あります。
- IPレピュテーションスコアリング: データセンターIPは即座にフラグが立ちます。
- Cookie検証:
datadomeCookieが存在し、有効でなければなりません。
ブロックされたサイン(確認方法も含む)
よくある落とし穴のひとつが、200 OKレスポンスが返ってきたのに、実際の中身は欲しかったデータではなくCAPTCHAページだった、というケースです。ほかにも次のような兆候があります。
- 403 Forbidden エラー
- リダイレクトループ
- レスポンス本文に
ddJavaScriptオブジェクトやスライダー型CAPTCHAのHTMLが含まれる
ステータスコードだけでなく、必ずレスポンス本文も確認してください。簡単なチェック例は次のとおりです。
1if "captcha" in resp.text.lower() or "datadome" in resp.text.lower():
2 print("ブロックされました。データの代わりにCAPTCHAページが返っています。")検知を減らすためのヘッダーとCookie
ブロックを完全に防ぐ保証はありませんが、現実的なヘッダー設定とCookie管理はかなり有効です。
1session = requests.Session()
2session.headers.update({
3 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 Chrome/133.0.0.0 Safari/537.36",
4 "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8",
5 "Accept-Language": "en-US,en;q=0.9",
6 "Accept-Encoding": "gzip, deflate, br",
7 "Sec-Ch-Ua": '"Chromium";v="133", "Not-A.Brand";v="99", "Google Chrome";v="133"',
8 "Sec-Ch-Ua-Mobile": "?0",
9 "Sec-Ch-Ua-Platform": '"Windows"',
10 "Sec-Fetch-Dest": "document",
11 "Sec-Fetch-Mode": "navigate",
12 "Sec-Fetch-Site": "none",
13 "Upgrade-Insecure-Requests": "1",
14})あわせて重要なのは次の点です。
requests.Session()を使って、リクエスト間でCookieを保持する。- リクエストの間にランダムな待機時間(2〜7秒)を入れる。
- 参照元の流れを再現する。まずホームページ、次に検索、最後に商品ページへアクセスする。
- 大規模運用では住宅回線プロキシのローテーションが必須です。データセンターIPはほぼ即座にフラグが立ちます。
これらの対策で検知リスクは下げられますが、完全にはなくなりません。大量スクレイピングを行うなら、プロキシサービスかブラウザベースの手法が必要になる可能性が高いです。
EtsyをスクレイピングするためのPython環境を整える
始める前に:
- 難易度: 中級
- 所要時間: 約30〜60分(セットアップ + 初回スクレイピング)
- 必要なもの: Python 3.8以上、pip、コードエディタ、Chromeブラウザ(DevTools確認用)
依存関係をインストールする
プロジェクトフォルダを作成し、仮想環境をセットアップして、必要なライブラリをインストールします。
1mkdir etsy-scraper && cd etsy-scraper
2python -m venv venv
3source venv/bin/activate # Windowsの場合: venv\Scripts\activate
4pip install requests beautifulsoup4 lxml pandas- requests — ウェブページを取得
- beautifulsoup4 — HTMLを解析
- lxml — 高速なHTMLパーサー(任意だが推奨)
- pandas — データをCSV/Excel向けに整形・出力
あとでブラウザ自動化が必要になった場合(ログインやJS中心ページ向け)は、これも追加で入れます。
1pip install seleniumコードを書く前にEtsyのページ構造を理解する
かなりの時間短縮になるコツがあります。Etsyは多くのページで、<script type="application/ld+json"> タグ内に構造化された商品データを埋め込んでいます。このJSON-LDデータはすでに整理されていて、商品名、価格、評価、画像などが入っているため、フィールドごとに壊れやすいCSSセレクターと格闘する必要がありません。
Etsyの商品ページを開き、右クリックして「ページのソースを表示」を選び、application/ld+json を検索してください。必要なデータの多くが入った @type: Product のブロックが見つかるはずです。検索結果ページには @type: ItemList があります。
CSSセレクターは、JSON-LDに入っていないデータ(配送情報やレビュー本文など)を補う用途ではまだ有用ですが、まず最初に見るべきなのはJSON-LDです。
ステップ1:PythonでEtsyの検索結果をスクレイピングする
検索結果は、Etsyスクレイピングの出発点です。ニッチの監視、競合価格の追跡、商品データベースの構築など、用途はさまざまです。
検索URLを作る
Etsyの検索URLは次の形式です。
1https://www.etsy.com/search?q=\{keyword\}&ref=pagination&page=\{page_number\}複数語のクエリでは、スペースをURLエンコードしてください(例: handmade+jewelry や handmade%20jewelry)。ref=pagination パラメータを付けると、実際のブラウザ遷移により近いリクエストになります。
ほかに使える便利なパラメータは、order(most_relevant, price_asc, price_desc, date_desc)、min_price、max_price、ship_to、free_shipping=true です。1ページあたり48件返ります。
リクエストを送ってHTMLを解析する
1import requests
2from bs4 import BeautifulSoup
3import json
4import time
5import random
6headers = {
7 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 Chrome/124.0.0.0 Safari/537.36",
8 "Accept-Language": "en-US,en;q=0.9",
9 "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
10}
11def scrape_etsy_search(query, max_pages=3):
12 all_products = []
13 for page in range(1, max_pages + 1):
14 url = f"https://www.etsy.com/search?q=\{query\}&ref=pagination&page=\{page\}"
15 resp = requests.get(url, headers=headers, timeout=30)
16 if "captcha" in resp.text.lower():
17 print(f"\{page\}ページ目でブロックされました。待機時間やプロキシの追加を試してください。")
18 break
19 soup = BeautifulSoup(resp.text, "lxml")
20 for script in soup.find_all("script", type="application/ld+json"):
21 data = json.loads(script.string)
22 if data.get("@type") == "ItemList":
23 for item in data.get("itemListElement", []):
24 all_products.append({
25 "name": item.get("name"),
26 "url": item.get("url"),
27 "image": item.get("image"),
28 "price": item.get("offers", {}).get("price"),
29 "currency": item.get("offers", {}).get("priceCurrency"),
30 "position": item.get("position"),
31 })
32 time.sleep(random.uniform(2, 5))
33 return all_productsJSON-LDから出品データを抽出する
itemListElement 配列には、各出品の名前、URL、画像、価格、通貨が入っています。星評価や件数(JSON-LDに入っていない場合もあります)が必要なら、CSSセレクターにフォールバックしてください。
- 出品カード:
.v2-listing-card - タイトル:
h3.v2-listing-card__title - 価格:
span.currency-value - リンク:
a.listing-link(href)
ページネーションを処理する
ページをループし、各リクエストの間にランダムな待機時間を入れてください。Etsyは通常、クエリに応じて最大20〜250ページを返します。
1results = scrape_etsy_search("handmade+jewelry", max_pages=5)
2print(f"{len(results)}件をスクレイピングしました。")5ページ分のスクレイピングは、私のテストでは約20秒でした。手作業のコピペ30分以上と比べると大きな差です。
ステップ2:PythonでEtsyの商品ページをスクレイピングする
検索結果から商品URLの一覧を取得したら、次は各商品ページから詳細データを取得します。
商品ページを取得する
1def scrape_etsy_product(url):
2 resp = requests.get(url, headers=headers, timeout=30)
3 soup = BeautifulSoup(resp.text, "lxml")
4 for script in soup.find_all("script", type="application/ld+json"):
5 data = json.loads(script.string)
6 if data.get("@type") == "Product":
7 offers = data.get("offers", {})
8 price = offers.get("price") or offers.get("lowPrice")
9 rating_data = data.get("aggregateRating", {})
10 return {
11 "name": data.get("name"),
12 "description": data.get("description", "")[:500],
13 "brand": data.get("brand", {}).get("name") if isinstance(data.get("brand"), dict) else data.get("brand"),
14 "category": data.get("category"),
15 "price": price,
16 "currency": offers.get("priceCurrency"),
17 "availability": offers.get("availability"),
18 "rating": rating_data.get("ratingValue"),
19 "review_count": rating_data.get("reviewCount"),
20 "images": data.get("image", []),
21 "sku": data.get("sku"),
22 "material": data.get("material"),
23 }
24 return None価格のバリエーションを扱う
商品によっては offers.price が1つだけある場合もあります。サイズや色などのバリエーションがある商品では、offers.lowPrice と offers.highPrice が使われます。上のコードでは、price がなければ lowPrice にフォールバックすることで両方に対応しています。
CSSセレクターで追加フィールドを取得する
JSON-LDにないデータ――配送情報、バリエーション、セラーの詳細など――にはCSSセレクターが必要です。
- タイトル:
h1[data-buy-box-listing-title] - バリエーション:
select[data-selector-id]またはdiv[data-option-set] - 配送情報: 配送セクション付近の
div.wt-text-caption
トレードオフとして、JSON-LDはよりクリーンで、レイアウト変更にも強いです。CSSセレクターは壊れやすいですが、より多くのフィールドを拾えます。
ステップ3:PythonでEtsyのショップページをスクレイピングする
これは多くの競合ガイドが完全に省いてしまう部分ですが、営業チームや競合分析担当にとっては、実は最も価値があります。
ショップURLを作ってページを取得する
1def scrape_etsy_shop(shop_name):
2 url = f"https://www.etsy.com/shop/\{shop_name\}"
3 resp = requests.get(url, headers=headers, timeout=30)
4 soup = BeautifulSoup(resp.text, "lxml")
5 # HTMLからショップメタデータを取得(JSON-LDにはない)
6 sales_el = soup.select_one("div.shop-sales-reviews a")
7 rating_el = soup.find("input", {"name": "initial-rating"})
8 location_el = soup.select_one("div.shop-location")
9 shop_data = {
10 "name": shop_name,
11 "sales": sales_el.text.strip() if sales_el else None,
12 "rating": rating_el["value"] if rating_el else None,
13 "location": location_el.text.strip() if location_el else None,
14 }
15 # JSON-LDから出品一覧を取得
16 listings = []
17 for script in soup.find_all("script", type="application/ld+json"):
18 data = json.loads(script.string)
19 if data.get("@type") == "ItemList":
20 for item in data.get("itemListElement", []):
21 listings.append({
22 "name": item.get("name"),
23 "url": item.get("url"),
24 "price": item.get("offers", {}).get("price"),
25 })
26 shop_data["listings"] = listings
27 return shop_dataショップページから取得できるもの
ショップページのJSON-LDは @type: ItemList で、商品一覧はカバーしていますが、販売数、所在地、評価のようなショップ全体のメタデータは含まれていません。それらを取るにはCSSセレクターが必要です。
| データ項目 | セレクター | 補足 |
|---|---|---|
| ショップ名 | h1 またはメタタイトル | 通常はページタイトル内 |
| 総販売数 | div.shop-sales-reviews a | 「12,345 sales」のようなテキスト |
| 星評価 | input[name="initial-rating"] の value | 1〜5の数値 |
| 所在地 | div.shop-location | 都市、国 |
| 開店時期 | div.shop-info | 日付テキスト |
ショップデータは、リードリストの作成、競合比較、特定ニッチのトップセラー発見に非常に役立ちます。
ステップ4:PythonでEtsyのレビューをスクレイピングする
レビューは、Etsyでもっとも価値が高い一方で、もっとも扱いが難しいデータのひとつです。レビュー全文、評価、日付は最初のHTMLには入っておらず、内部API経由で読み込まれます。
方法1:Etsy内部のレビューAPIエンドポイントを見つける
Chromeで商品ページを開き、DevTools(F12)を起動し、Networkタブでレビューセクションまでスクロールしてください。次のようなPOSTリクエストが見つかります。
1https://www.etsy.com/api/v3/ajax/bespoke/member/neu/specs/deep_dive_reviewsこのエンドポイントは、レビューカードを含むHTMLフラグメントを返します。使うには次が必要です。
- listing_id — 商品URLから取れる数値ID
- shop_id — 商品ページHTMLから正規表現で抽出
- csrf_nonce — ページ内の
<meta>タグから抽出
IDとCSRFトークンを抽出する
1import re
2def get_review_params(product_url):
3 resp = requests.get(product_url, headers=headers)
4 html = resp.text
5 listing_id = product_url.split("/")[-1].split("?")[0]
6 shop_id_match = re.search(r'"shopId"\s*:\s*(\d+)', html)
7 shop_id = shop_id_match.group(1) if shop_id_match else None
8 soup = BeautifulSoup(html, "lxml")
9 csrf_meta = soup.find("meta", {"name": "csrf_nonce"})
10 csrf = csrf_meta["content"] if csrf_meta else None
11 return listing_id, shop_id, csrfページネーション付きでレビューをスクレイピングする
1def scrape_reviews(listing_id, shop_id, csrf, max_pages=5):
2 session = requests.Session()
3 session.headers.update(headers)
4 all_reviews = []
5 for page in range(1, max_pages + 1):
6 payload = {
7 "specs": {
8 "deep_dive_reviews": {
9 "module_path": "neu/specs/deep_dive_reviews",
10 "listing_id": listing_id,
11 "shop_id": shop_id,
12 "page": page,
13 }
14 }
15 }
16 resp = session.post(
17 "https://www.etsy.com/api/v3/ajax/bespoke/member/neu/specs/deep_dive_reviews",
18 json=payload,
19 headers={"x-csrf-token": csrf, "Content-Type": "application/json"},
20 )
21 data = resp.json()
22 html_fragment = data.get("output", {}).get("deep_dive_reviews", "")
23 review_soup = BeautifulSoup(html_fragment, "lxml")
24 for card in review_soup.select("div.review-card"):
25 rating_el = card.find("input", {"name": "rating"})
26 text_el = card.select_one("div.wt-text-body")
27 user_el = card.select_one("a[data-review-username]")
28 date_el = card.select_one("p.wt-text-body-small")
29 all_reviews.append({
30 "rating": rating_el["value"] if rating_el else None,
31 "text": text_el.text.strip() if text_el else None,
32 "reviewer": user_el.text.strip() if user_el else None,
33 "date": date_el.text.strip() if date_el else None,
34 })
35 time.sleep(random.uniform(2, 5))
36 return all_reviews方法2:HTMLからレビューを解析する(フォールバック)
API方式が失敗した場合(たとえばCSRFトークンの問題など)、商品ページHTMLから最初のレビューだけを直接解析できます。ただし、静的HTMLに入っているのは初回分だけです。それ以上必要なら、APIかSeleniumのようなブラウザ自動化ツールが必要です。
ログイン必須データを扱う:自分のEtsyショップをスクレイピングする
これは他のチュートリアルではあまり触れられない、でも実際には重要なポイントです。特に、注文、売上、統計を自分で抽出したいEtsyセラーにとっては必要性が高いです。
問題は、requests だけではEtsyダッシュボードにアクセスできないことです。ログインセッションのCookieを持っていないからです。
方法1:Seleniumで手動ログインし、Cookieを取得する
Seleniumでブラウザを開き、手動でログインするかログインを自動化したあと、認証済みのままスクレイピングを続けます。
1from selenium import webdriver
2driver = webdriver.Chrome()
3driver.get("https://www.etsy.com/signin")
4# ブラウザで手動ログインしたら、次を実行:
5input("ログイン後にEnterを押してください...")
6cookies = driver.get_cookies()
7# 以後は driver.get() でダッシュボードページに移動してスクレイピングSeleniumセッションからCookieを保存し、最初のログイン後は requests.Session() と組み合わせて、より速く軽いスクレイピングに再利用することもできます。
方法2:ブラウザCookieをエクスポートしてRequestsで使う
ブラウザ拡張(たとえば「EditThisCookie」)を使って、現在のEtsyセッションCookieをエクスポートし、それをRequestsセッションに読み込みます。
1import requests
2session = requests.Session()
3# ブラウザからエクスポートしたCookieを追加
4session.cookies.set("uaid", "YOUR_UAID_VALUE", domain=".etsy.com")
5session.cookies.set("user_prefs", "YOUR_USER_PREFS_VALUE", domain=".etsy.com")
6# ...必要に応じて他のセッションCookieも追加
7resp = session.get("https://www.etsy.com/your/orders", headers=headers)もっと簡単な方法:Thunderbitのブラウザスクレイピングモード
はChromeブラウザ内で動作するため、アクティブなEtsyセッションをそのまま引き継げます。認証コードもCookieのエクスポートも不要で、Etsyダッシュボードに移動してそのままスクレイピングできます。注文、売上、統計、その他のセラー限定データを、スクリプトなしで抽出したいなら本当に便利です。
スクレイピングしたEtsyデータの保存と活用
CSVまたはJSONに保存する
1import pandas as pd
2df = pd.DataFrame(results)
3df.to_csv("etsy_products.csv", index=False, encoding="utf-8")
4df.to_json("etsy_products.json", orient="records", indent=2)ベストプラクティスとして、ファイル名にはタイムスタンプを入れる、UTF-8エンコーディングを使う、商品名に含まれる特殊文字を適切に扱うことが大切です(Etsyのセラーは絵文字やアクセント付き文字が大好きです)。
Google Sheets、Airtable、Notionへ出力する
Pythonユーザーなら、gspread(Google Sheets用)やAirtable APIのようなライブラリで、プログラムからデータを送れます。ただし、 を使うなら、Google Sheets、Excel、Airtable、Notionへの出力はすべて無料でワンクリックです。APIキーもOAuth設定も不要です。
コードなしで進める:ThunderbitでEtsyをスクレイピングする方法(ノーコード代替)
Pythonスクリプトを書いたり、プロキシ設定を管理したり、深夜2時にCSSセレクターをデバッグしたりしたい人ばかりではありません。もしあなたがそうでないなら、 でEtsyデータを取得する方法を紹介します。
ThunderbitのChrome拡張機能をインストールする
にアクセスしてThunderbitをインストールしてください。無料アカウントを作成すると、無料枠でまで使え、エクスポートもすべて無料です。
どのEtsyページでもAIで項目を提案させる
Etsyの検索ページ、商品ページ、またはショップページに移動します。Thunderbitのサイドバーで 「AIで項目を提案」 をクリックしてください。AIがページを解析し、商品名、価格、評価、画像、ショップ名、タグ、配送情報などの列を提案します。必要に応じて列を調整したり追加したりできます。
スクレイピングしてエクスポートする
「スクレイプ」 をクリックすると、現在のページからデータを抽出できます。複数ページの結果には、Thunderbitのページネーションスクレイピングを使ってください。商品URLの一覧に対して、各商品ページの詳細(説明、レビュー、配送情報)を補完したい場合は、サブページスクレイピング を使います。Thunderbitが各リンク先を巡回し、追加データを自動で取得します。
Excel、Google Sheets、Airtable、Notionへ、すべて無料でエクスポートできます。
EtsyスクレイピングでThunderbitがPythonより優れている場面
- プロキシ設定やボット対策コードが不要。 Thunderbitは実際のChromeブラウザ内で動くため、セッションを引き継ぎ、DataDomeからは普通のユーザーのように見えます。
- AIがレイアウト変更に自動対応。 Etsyがフロントエンドを更新しても、壊れたセレクターを直す必要がありません。
- 単発の調査、競合分析、非技術系メンバーに最適。 すぐに使えるデータが欲しいだけなら、Python環境は不要です。
- サブページスクレイピング で、ネストしたループを書かずに商品URL一覧を詳細データで拡張できます。
使い方は、 で確認できます。
Python vs. Thunderbit:6か月のコスト比較
| 要素 | Pythonで自作 | Thunderbit |
|---|---|---|
| セットアップ時間 | 8〜20時間 | 5分以内 |
| 6か月コスト(労務費・プロキシ込み) | $2,720〜9,450 | $90〜228 |
| 月次保守 | 4〜10時間以上(セレクター更新が80%以上の工数) | 0〜1時間 |
| ボット対策対応 | 住宅回線プロキシを通常の85倍のクレジットコストで利用 | ブラウザベースでDataDomeをネイティブに回避 |
| データ品質 | 高い(労力次第) | 高い(AI駆動) |
Pythonが間違いだと言っているわけではありません。完全な制御、独自ロジック、あるいは大きなパイプラインへの統合が必要なら、コードが最強です。ただし、Etsyデータが欲しいだけの多くのビジネスユーザーにとっては、ROIの観点からノーコードツールのほうが有利です。
Etsyスクレイピングの法的・倫理的な注意点
スクレイピングに関する記事では毎回合法性を聞かれるので、短くまとめます。
- Etsyの利用規約は、自動アクセスを明確に禁止しています。 ただし、Etsyは訴訟ではなく技術的な防御(DataDome)に依存しており、スクレイパーを直接狙ったEtsy固有の訴訟は知られていません。
- 公開データだけをスクレイピングすること。 認証を回避したり、自分が所有していない非公開のセラーダッシュボードにアクセスしたりしないでください。
- 適切なリクエスト頻度を守ること。 リクエスト間は2〜7秒空け、Etsyのサーバーに負荷をかけすぎないでください。
robots.txtを尊重すること。 Etsyは検索ページを許可していますが、一部のパスは制限しています。- GDPRのようなプライバシー法のもとで個人データを責任を持って扱うこと。
- 商用規模のスクレイピングでは法務に相談すること。
背景知識としては、 の記事も参考になります。Meta v. Bright Data(2024)では公開データのスクレイピングが認められています。
まとめ:重要ポイントのおさらい
ここまでかなり幅広く見てきました。最後に持ち帰ってほしいポイントをまとめます。
- EtsyのJSON-LD構造化データ は、多くの項目で生HTMLを解析するよりもクリーンに抽出できます。
- DataDomeは本物の障害 です。Pythonで大規模スクレイピングするなら、適切なヘッダー、待機時間、Cookie管理、住宅回線プロキシが必要です。
- Etsy APIには制限があります。 レビュー、競合ショップ、ショップ横断分析が必要なら、スクレイピングが現実的な手段です。
- Thunderbitはノーコード代替手段 として、ボット対策や認証をネイティブに処理します。スクリプト保守なしでEtsyデータが欲しいなら試す価値があります。
- 常に責任あるスクレイピングを心がけ、Etsyの利用規約を尊重してください。
コードを書かずに始めたいなら、。あるいは、このチュートリアルのPythonコードを使って、自分専用のスクレイパーを作るのもありです。どうか金曜の午後にセレクターが壊れませんように。
さらに詳しいスクレイピングガイドは、 と もご覧ください。
よくある質問
1. PythonでEtsyをスクレイピングするのは合法ですか?
公開されているデータのスクレイピングは、近年の判例(例: Meta v. Bright Data、hiQ v. LinkedIn)では一般に認められています。ただし、Etsyの利用規約は自動アクセスを禁じているため、スクレイピング前に必ず利用規約と robots.txt を確認してください。大規模利用や商用利用では、法務に相談することをおすすめします。
2. ブロックされずにEtsyをスクレイピングできますか?
Etsyは、かなり強力なボット対策システムであるDataDomeを使っています。現実的なヘッダー設定、リクエスト間の待機、Cookieの維持、住宅回線プロキシのローテーションは、ブロックを減らすのに役立ちます。Thunderbitは実際のChromeセッション内で動作するため、ほとんどの検知を回避できます。
3. スクレイピングの代わりに使えるEtsyのAPIはありますか?
はい。EtsyはAPI v3を提供していますが、基本的には自分のショップのデータに限られ、堅牢なレビュー取得機能はありません。競合分析やショップ横断分析の多くは、スクレイピングが必要です。
4. Etsyをスクレイピングするのに必要なPythonライブラリは何ですか?
最低限必要なのは、requests、beautifulsoup4、pandas(出力用)、そしてjson(標準搭載)です。JS中心のページやログインが必要なページには selenium を追加してください。HTML解析を速くしたいなら lxml を使います。
5. Etsyのレビューだけを具体的にスクレイピングするにはどうすればいいですか?
Etsyのレビューは内部APIエンドポイント(/api/v3/ajax/bespoke/member/neu/specs/deep_dive_reviews)経由で読み込まれます。商品ページからlisting ID、shop ID、CSRFトークンを抽出し、ページネーション付きでそのエンドポイントにPOSTする必要があります。フォールバックとして、商品ページHTMLから最初のレビュー群を解析することもできます。このチュートリアルでは両方を手順付きで解説しています。
さらに詳しく