eBayのスクレイピング解説は、だいたい3か月もすれば使いものにならなくなります。Thunderbitのチームは、壊れたコードのかけら、古びたCSSセレクタ、そして2回前のeBayリニューアルの時点でひっそり動かなくなっている「動作確認済み」GitHubリポジトリを、開発者たちが次から次へと渡り歩く場面を何度も見てきたので、これは本当によく分かっています。
eBayには があり、オープンウェブ上では Amazon に次ぐ規模のロングテール価格データセットを抱えています。このデータは、リセラー向けの価格設定から競合インテリジェンスまで、いろいろな用途を支えています。ただし、プログラムで取ろうとすると話は別で、状況は常に変わります。eBay の React ベースのフロントエンドでは CSS クラス名がしょっちゅう変わり、A/B テストでユーザーごとに異なる DOM が出てきて、Akamai Bot Manager が HTML にたどり着く前に立ちはだかります。この記事では、今日そのまま使える Python コードを紹介しながら、スクレイパーがなぜ壊れるのか、壊れにくくするにはどう設計すべきか、eBay API とスクレイピングのどちらを選ぶべきかを率直に整理します。さらに、Python の準備コストに見合わないときのノーコードの逃げ道も紹介します。
PythonでeBayをスクレイピングするとは?
PythonでeBayをスクレイピングするとは、Pythonスクリプトを使って eBay のWebページを自動で取得し、HTML(あるいはページ内に隠されたJSON)を解析して、タイトル、価格、出品者情報、販売日、バリエーション情報などを、CSVやスプレッドシート、データベースなど実用的な形式にまとめることです。
eBayでは、次のようなページを取得できます。
- 検索結果ページ(例:「AirPods Pro」の出品一覧)
- 個別の商品詳細ページ(仕様、画像、出品者情報など)
- 売却済み/終了済みリスト(実際の取引価格と日付)
- 出品者プロフィールとレビュー
この用途では Python が定番です。Requests、BeautifulSoup、lxml、pandas などのエコシステムがそろっていて、ページ取得、HTML解析、データ加工がスムーズにできます。ただし、サイトのHTMLを直接スクレイピングする方法と、eBay公式APIを使う方法は別物です。次の章でその違いを説明します。
なぜeBayをスクレイピングするのか?ビジネスチームでの実践例
この記事を読んでいる時点で、もう目的はあるはずです。それでも、話を具体的なビジネス価値に落としておきましょう。というのも、eBayデータのROIは本当に大きいからです。Bain によると、 とされています。McKinsey も、小売のダイナミックプライシングが と指摘しています。
よくある活用例は次のとおりです。
| 用途 | 必要なデータ | 得られる成果 |
|---|---|---|
| 価格モニタリング/再価格設定 | 出品中価格、送料、コンディション | 競争力のある価格設定、利益率の保護 |
| 競合分析 | 商品ラインアップ、販促、送料条件 | 戦略的なポジショニング、品揃えのギャップ把握 |
| 市場調査/トレンド把握 | 出品数の推移、カテゴリトレンド、需要パターン | 新商品発掘、需要予測 |
| リセラー向け価格査定 | 売却価格、販売日、コンディション | 適正価格の把握、仕入れ判断 |
| 感情分析 | レビュー、評価、返品ポリシー | 商品品質の洞察、顧客満足度の把握 |
| リード獲得 | 出品者プロフィール、ストア情報、連絡先 | 高GMV出品者へのB2Bアプローチ |
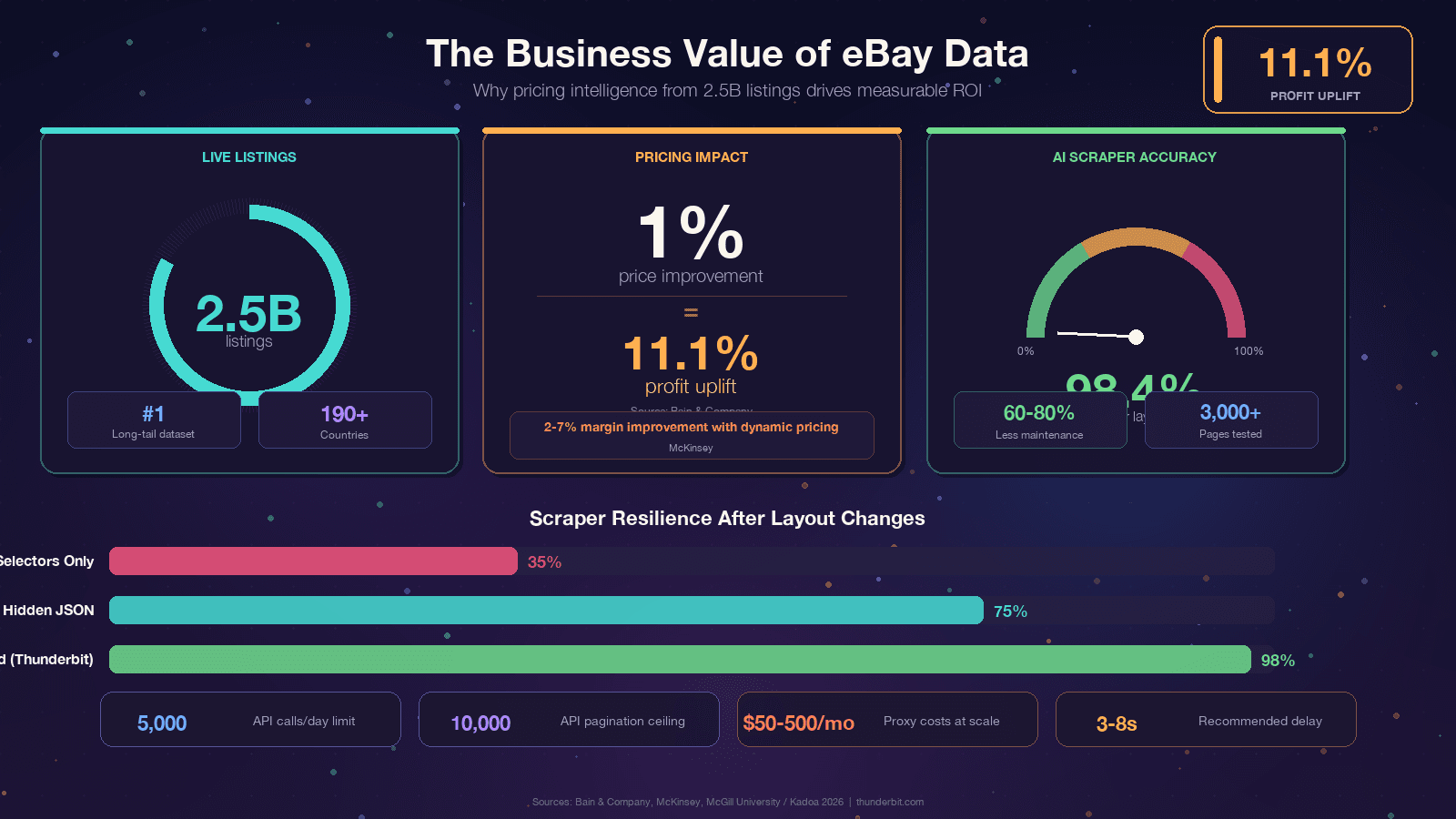
共通しているのは、eBayにはデータがあるのに、それがWebページの中に閉じ込められていることです。
スクレイピングは、それを競争優位に変える手段です。
eBay公式API vs Pythonスクレイピング:どちらを選ぶべき?
これは、もっと多くのチュートリアルで正直に扱ってほしかったテーマです。eBay は公式API、主に を提供しています。では、APIを使うべきか、それとも直接スクレイピングすべきか。答えは、必要なデータ次第です。
| 比較項目 | eBay Browse/Finding API | Pythonスクレイピング |
|---|---|---|
| 売却済み/終了済みリスト | 限定的 — Marketplace Insights API はあるが、アクセスが通らないことが多い | URLパラメータ LH_Sold=1&LH_Complete=1 で完全取得可能 |
| レート制限 | ベーシックプランで 1日5,000回 | 自前管理(プロキシ依存) |
| データ項目 | 事前定義済み(タイトル、価格、カテゴリ、基本的な出品者情報) | ページ上で見えるものは何でも取得可能(レビュー、詳細仕様、バリエーション表など) |
| 導入難易度 | OAuth 2.0、アプリ登録、APIキー | pip install とコード記述のみ |
| 安定性 | エンドポイントは安定 | HTML変更で壊れる |
| コスト | 無料枠あり、大量利用は有料 | コード自体は無料だが、大量取得ではプロキシ費用が発生 |
| バリエーション/MSKUデータ | 部分的 — 多くの場合は親SKUのみ | 完全取得可能(隠しJSONを解析) |
| ページネーション上限 | 1万件のハード上限 | 理論上は無制限 |
ひとつ補足すると、旧 Finding API(findCompletedItems を含む)は しています。ebaysdk-python や Finding モジュールを叩くライブラリを使っているなら、今は本番では動きません。
私のおすすめ: 出品中商品の、安定していて中規模の構造化検索には Browse API を使いましょう。売却済み価格、レビュー、バリエーション情報、APIが公開していない項目が必要なら Python スクレイピングを使うべきです。実務では両方を併用するチームも多いです。
PythonでeBayをスクレイピングするのに必要なツールとライブラリ
コードを書く前に、まずは道具をそろえましょう。eBayの多くのページではヘッドレスブラウザは不要です。データはサーバーレンダリングされたHTMLの中に埋め込まれています。
| ライブラリ | 用途 |
|---|---|
requests または httpx | eBayページを取得するHTTPクライアント |
curl_cffi | 実ブラウザ相当のTLSフィンガープリントを持つHTTPクライアント(Akamai回避に重要) |
beautifulsoup4 | CSSセレクタで抽出するためのHTMLパーサー |
lxml | BeautifulSoup向けの高速パーサー |
jmespath | 入れ子JSONを扱うためのクエリ言語 |
pandas | データ加工とCSV/Excel出力 |
gspread | Google Sheets 連携 |
まとめてインストールするならこちらです。
1pip install requests httpx curl_cffi beautifulsoup4 lxml jmespath pandas gspreadPython 3.11以上 を使いましょう。pandas 3.0 は 3.10 以上が必要で、3.11 ならI/O中心の処理で10〜60%ほど高速化が見込めます。
特に注目したいライブラリがひとつあります。curl_cffi は、2026年時点の eBay スクレイパーにとって最も効果の大きいアップグレードです。eBay は を使っており、Akamai の主な検知ポイントは TLS フィンガープリントです。通常の requests は Python 特有の JA3 フィンガープリントを出してしまい、すぐに弾かれがちです。curl_cffi は本物の Chrome ブラウザの TLS ハンドシェイクを偽装するため、ヘッドレスブラウザなしで約90%の Akamai 対策サイトに対応できます。
手順付き:PythonでeBay検索結果をスクレイピングする方法
ここが本題です。商品検索結果ページを対象にeBayをスクレイピングしていきます。
- 難易度: 初級〜中級
- 所要時間: 最初に動くところまで約30分
- 必要なもの: Python 3.11以上、上記ライブラリ、ターミナル、対象となるeBay検索URL
ステップ1:Pythonプロジェクトを準備する
プロジェクト用ディレクトリを作成し、依存関係を入れます。
1mkdir ebay-scraper && cd ebay-scraper
2python -m venv venv
3source venv/bin/activate # Windows: venv\Scripts\activate
4pip install requests curl_cffi beautifulsoup4 lxml pandasscrape_ebay.py というファイルを作成しましょう。これが作業用スクリプトになります。
ステップ2:eBay検索URLを組み立てる
eBayの検索URL構造はシンプルです。重要なのは _nkw(キーワード)です。
1import urllib.parse
2keyword = "airpods pro"
3base_url = "https://www.ebay.com/sch/i.html"
4params = {
5 "_nkw": keyword,
6 "_ipg": "120", # 1ページあたりの件数: 60, 120, 240(240はbot判定の原因になりやすい)
7 "_pgn": "1", # ページ番号
8}
9url = f"{base_url}?{urllib.parse.urlencode(params)}"
10print(url)
11# https://www.ebay.com/sch/i.html?_nkw=airpods+pro&_ipg=120&_pgn=1そのほか便利なパラメータは以下です。
LH_BIN=1— 即決のみ_sacat=175673— 特定カテゴリ_sop=12— ベストマッチ順(10 = 価格+送料の安い順、13 = 新着順)LH_Complete=1&LH_Sold=1— 売却済み/終了済みリスト(後半で詳しく説明します)
ステップ3:リクエストを送信し、レスポンスを扱う
ここで curl_cffi の真価が出ます。通常の requests.get() は、Akamai から 403 を返されることがよくあります。curl_cffi を使えば、実際の Chrome ブラウザとしてアクセスしているように見せられます。
1from curl_cffi import requests as cffi_requests
2import random, time
3USER_AGENTS = [
4 "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/143.0.0.0 Safari/537.36",
5 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/143.0.0.0 Safari/537.36",
6 "Mozilla/5.0 (X11; Linux x86_64; rv:124.0) Gecko/20100101 Firefox/124.0",
7]
8HEADERS = {
9 "User-Agent": random.choice(USER_AGENTS),
10 "Accept-Language": "en-US,en;q=0.9",
11 "Accept-Encoding": "gzip, deflate, br",
12}
13def fetch_page(url, max_retries=5):
14 delay = 2
15 for attempt in range(max_retries):
16 try:
17 r = cffi_requests.get(url, impersonate="chrome124", headers=HEADERS, timeout=30)
18 if r.status_code == 200:
19 return r.text
20 if r.status_code in (403, 429, 503):
21 retry_after = r.headers.get("Retry-After")
22 sleep_for = float(retry_after) if retry_after else delay + random.uniform(0, 1)
23 print(f" Status {r.status_code}, retrying in {sleep_for:.1f}s...")
24 time.sleep(sleep_for)
25 delay *= 2
26 continue
27 r.raise_for_status()
28 except Exception as e:
29 print(f" Request error: {e}, retrying...")
30 time.sleep(delay)
31 delay *= 2
32 raise RuntimeError(f"Failed after {max_retries} retries: {url}")指数バックオフにジッターを入れるのは重要です。固定の待機時間も、bot判定の材料になってしまうからです。
ステップ4:検索結果ページから商品情報を解析する
eBayは現在、2つの検索結果レイアウトの移行途中にあります。堅牢なスクレイパーは両方に対応できなければなりません。
| 項目 | 旧レイアウト | 新レイアウト |
|---|---|---|
| カードのコンテナ | li.s-item | li.s-card または div.su-card-container |
| タイトル | .s-item__title | .s-card__title |
| URL | a.s-item__link[href] | a.su-link[href] |
| 価格 | span.s-item__price | .s-card__price |
両方に対応する解析コードはこちらです。
1from bs4 import BeautifulSoup
2def parse_search_results(html):
3 soup = BeautifulSoup(html, "lxml")
4 cards = soup.select("li.s-item, li.s-card, div.su-card-container")
5 results = []
6 for card in cards:
7 # タイトル — 両方のレイアウトを確認
8 title_el = card.select_one(".s-item__title, .s-card__title")
9 title = title_el.get_text(strip=True) if title_el else None
10 # 先頭に出るダミーの「Shop on eBay」カードを除外
11 if not title or "Shop on eBay" in title:
12 continue
13 # 価格
14 price_el = card.select_one("span.s-item__price, .s-card__price")
15 price = price_el.get_text(strip=True) if price_el else None
16 # URL
17 link_el = card.select_one("a.s-item__link[href], a.su-link[href]")
18 url = link_el["href"].split("?")[0] if link_el else None
19 # 画像
20 img_el = card.select_one("img.s-item__image-img, .s-card__image img")
21 image = None
22 if img_el:
23 image = img_el.get("src") or img_el.get("data-src")
24 # 送料
25 ship_el = card.select_one("span.s-item__shipping, span.s-item__logisticsCost, .s-card__attribute-row")
26 shipping = ship_el.get_text(strip=True) if ship_el else None
27 results.append({
28 "title": title,
29 "price": price,
30 "url": url,
31 "image": image,
32 "shipping": shipping,
33 })
34 return results最初に出てくるダミーカードの罠は定番です。多くのeBay検索ページでは、最初の li.s-item が実データのないプレースホルダーで、タイトルは「Shop on eBay」になっています。必ず除外しましょう。
ステップ5:ページネーション対応で複数ページを取得する
eBay のページ送りは _pgn パラメータで制御されます。次ページリンクは a.pagination__next です。
1import urllib.parse
2def scrape_ebay_search(keyword, max_pages=5):
3 all_results = []
4 for page_num in range(1, max_pages + 1):
5 params = {"_nkw": keyword, "_ipg": "120", "_pgn": str(page_num)}
6 url = f"https://www.ebay.com/sch/i.html?{urllib.parse.urlencode(params)}"
7 print(f"Scraping page {page_num}: {url}")
8 html = fetch_page(url)
9 results = parse_search_results(html)
10 if not results:
11 print(f" No results on page {page_num}, stopping.")
12 break
13 all_results.extend(results)
14 print(f" Found {len(results)} listings (total: {len(all_results)})")
15 # 丁寧な間隔 — 3〜8秒のランダム待機
16 time.sleep(random.uniform(3, 8))
17 return all_results3〜8秒のランダムジッターは任意ではありません。
eBay の Akamai レイヤーは、単一IPからの1秒あたり1件超の継続アクセスを検知します。
ステップ6:スクレイピングしたデータをCSVまたはJSONに出力する
1import pandas as pd
2results = scrape_ebay_search("airpods pro", max_pages=3)
3df = pd.DataFrame(results)
4df.to_csv("ebay_airpods.csv", index=False)
5df.to_json("ebay_airpods.json", orient="records", indent=2)
6print(f"{len(df)}件の出品情報をCSVとJSONに出力しました。")これで、見やすいeBay出品一覧のスプレッドシートが手に入ります。私の環境では、3ページ(360件)を取得するのに、待機時間込みで約45秒かかりました。
PythonでeBayの商品詳細ページをスクレイピングする方法
検索結果ページは要約情報です。商品詳細ページには、本当に欲しい情報があります。たとえば、詳細な説明、出品者の評価、商品スペック、画像カルーセル、バリエーション情報などです。
単一の商品ページを解析する
eBayの商品ページは /itm/<ITEM_ID> にあります。最も安定している取得経路は JSON-LD です。eBay は Product スキーマのブロックを埋め込んでおり、CSSの変更があってもほぼ壊れません。
1import json
2def parse_item_page(html):
3 soup = BeautifulSoup(html, "lxml")
4 item = {}
5 # 1. JSON-LD — 最も安定した取得経路
6 for tag in soup.find_all("script", type="application/ld+json"):
7 try:
8 data = json.loads(tag.string or "")
9 except (json.JSONDecodeError, TypeError):
10 continue
11 if isinstance(data, dict) and data.get("@type") == "Product":
12 item["title"] = data.get("name")
13 item["brand"] = (data.get("brand") or {}).get("name")
14 item["images"] = data.get("image")
15 offers = data.get("offers") or {}
16 item["price"] = offers.get("price")
17 item["currency"] = offers.get("priceCurrency")
18 break
19 # 2. JSON-LDにない項目のCSSフォールバック
20 def first_text(selectors):
21 for sel in selectors:
22 el = soup.select_one(sel)
23 if el and el.get_text(strip=True):
24 return el.get_text(strip=True)
25 return None
26 item.setdefault("title", first_text([
27 "h1.x-item-title__mainTitle",
28 "h1.x-item-title__mainTitle .ux-textspans--BOLD",
29 ]))
30 item["condition"] = first_text([
31 ".x-item-condition-text .ux-textspans",
32 ])
33 item["seller"] = first_text([
34 ".x-sellercard-atf__info__about-seller a .ux-textspans",
35 ])
36 item["shipping"] = first_text([
37 "div.ux-labels-values--shipping .ux-textspans--BOLD",
38 ])
39 # 3. 商品の詳細項目
40 specifics = {}
41 for dl in soup.select(".ux-layout-section-evo__item--table-view dl.ux-labels-values"):
42 k = dl.select_one(".ux-labels-values__labels-content .ux-textspans")
43 v = dl.select_one(".ux-labels-values__values-content .ux-textspans")
44 if k and v:
45 specifics[k.get_text(strip=True).rstrip(":")] = v.get_text(strip=True)
46 item["specifics"] = specifics
47 return itemここでのパターン、つまり JSON-LDを先に見て、CSSフォールバックを後から使う という考え方が、四半期ごとの変更で壊れにくいスクレイパーを作るカギです。これについては後ほどさらに説明します。
eBayの商品バリエーション(MSKUデータ)を取得する
eBayの一部商品には、色、サイズ、容量などの複数バリエーションがあります。画面上では、ユーザーが選択肢をクリックするまでは「$899〜$1,099」のような価格帯しか見えません。実際のバリエーションごとの価格は、MSKU と呼ばれる隠しJavaScriptオブジェクトの中にあります。
ここは、eBay API だと親SKUまでしか取れないことが多く、スクレイピングのほうが有利な領域です。
1import re, json
2def extract_variants(html):
3 # 非貪欲マッチが重要 — 貪欲な .+ はページ全体を飲み込んでしまう
4 m = re.search(r'"MSKU"\s*:\s*(\{.+?\})\s*,\s*"QUANTITY"', html, re.DOTALL)
5 if not m:
6 return []
7 try:
8 msku = json.loads(m.group(1))
9 except json.JSONDecodeError:
10 return []
11 item_labels = {str(k): v["displayLabel"] for k, v in msku.get("menuItemMap", {}).items()}
12 skus = []
13 for combo_key, variation_id in msku.get("variationCombinations", {}).items():
14 option_ids = combo_key.split("_")
15 options = [item_labels.get(oid, oid) for oid in option_ids]
16 var = msku.get("variationsMap", {}).get(str(variation_id), {})
17 bin_model = var.get("binModel", {})
18 price_spans = bin_model.get("price", {}).get("textSpans", [{}])
19 price = price_spans[0].get("text") if price_spans else None
20 qty = var.get("quantity")
21 skus.append({
22 "options": options,
23 "price": price,
24 "quantity_available": qty,
25 "variation_id": variation_id,
26 })
27 return skusこの正規表現の非貪欲な (.+?) が、eBayスクレイパーがいちばんつまずきやすいポイントです。貪欲な .+ を使うと、ページ内の最後の "QUANTITY" まで全部飲み込んでしまい、JSONが壊れます。私は、こうしたバグを「動く」と書かれたチュートリアルで少なくとも3回見ました。
PythonでeBayの売却済み・終了済みリストをスクレイピングする方法
これこそ、APIよりスクレイピングを選ぶ理由がいちばんはっきりする用途です。売却済みデータ、つまり何が、いくらで、いつ売れたのかは、市場調査、リセラー価格設定、査定の基本中の基本です。eBay Browse API は、これを明示的には提供していません。 は一応対応していますが、アクセスは「限定提供」で、 のが実情です。
必要なURLパラメータは LH_Complete=1(終了済み)と LH_Sold=1(実際に売れたものだけに限定)です。両方必要です。 LH_Sold=1 だけだと、カテゴリによっては静かに通常の出品一覧に戻ってしまうことがあり、これがコミュニティでいちばん多い落とし穴です。
1def scrape_sold_listings(keyword, max_pages=3):
2 all_sold = []
3 for page_num in range(1, max_pages + 1):
4 params = {
5 "_nkw": keyword,
6 "_ipg": "120",
7 "_pgn": str(page_num),
8 "LH_Complete": "1",
9 "LH_Sold": "1",
10 }
11 url = f"https://www.ebay.com/sch/i.html?{urllib.parse.urlencode(params)}"
12 print(f"Scraping sold page {page_num}...")
13 html = fetch_page(url)
14 soup = BeautifulSoup(html, "lxml")
15 cards = soup.select("li.s-item")
16 for card in cards:
17 title_el = card.select_one(".s-item__title")
18 title = title_el.get_text(strip=True) if title_el else None
19 if not title or "Shop on eBay" in title:
20 continue
21 # 実際に売れたものだけを対象にする(緑色のPOSITIVE表示)
22 sold_tag = card.select_one(
23 ".s-item__title--tag .POSITIVE, .s-item__caption--signal.POSITIVE"
24 )
25 if sold_tag is None:
26 continue # 売れていない終了済み出品は除外
27 price_el = card.select_one("span.s-item__price")
28 price = price_el.get_text(strip=True) if price_el else None
29 # 売却日を解析
30 sold_date = None
31 import re, datetime as dt
32 card_text = card.get_text()
33 m = re.search(r"Sold\s+([A-Z][a-z]{2}\s+\d{1,2},\s*\d{4})", card_text)
34 if m:
35 sold_date = dt.datetime.strptime(m.group(1), "%b %d, %Y").strftime("%Y-%m-%d")
36 link_el = card.select_one("a.s-item__link[href]")
37 url = link_el["href"].split("?")[0] if link_el else None
38 all_sold.append({
39 "title": title,
40 "sold_price": price,
41 "sold_date": sold_date,
42 "url": url,
43 })
44 if not cards:
45 break
46 time.sleep(random.uniform(3, 8))
47 return all_soldHTML上の大事な違いは、売却済みアイテムの価格は緑色で .POSITIVE ラッパーに入るのに対して、売れていない終了済みリストは赤い取り消し線表示になることです。必ず .POSITIVE クラスで判定しましょう。
なぜeBayスクレイパーは壊れるのか(そして、どうすれば壊れにくくできるのか)
eBayのスクレイパーが突然動かなくなっても、あなただけではありません。これは私が読んできたeBayスクレイピング系フォーラムで、いちばん多い悩みです。問題は「壊れるかどうか」ではなく、「いつ壊れるか」です。
なぜ壊れるのか:
- eBay は React ベースの描画と動的生成されたクラス名を使っており、デプロイのたびに変わる
- A/B テストで、ユーザーごとに異なる DOM が返る(今まさに
s-itemとs-cardの2系統が共存しているのがその例) - 定期的なUI刷新で、データ自体は同じでもHTMLのネスト構造が変わる
#itemTitleや#prcIsumのような古いセレクタは何年も前に廃止されているのに、いまだにチュートリアルで見かける
でも、「eBayのWebスクレイピングで本当に難しいのはCSSセレクタの変更対応だ。eBayはフロントエンドを定期的に更新するため、特定のクラス名に依存したスクレイパーは壊れやすい」と指摘しています。
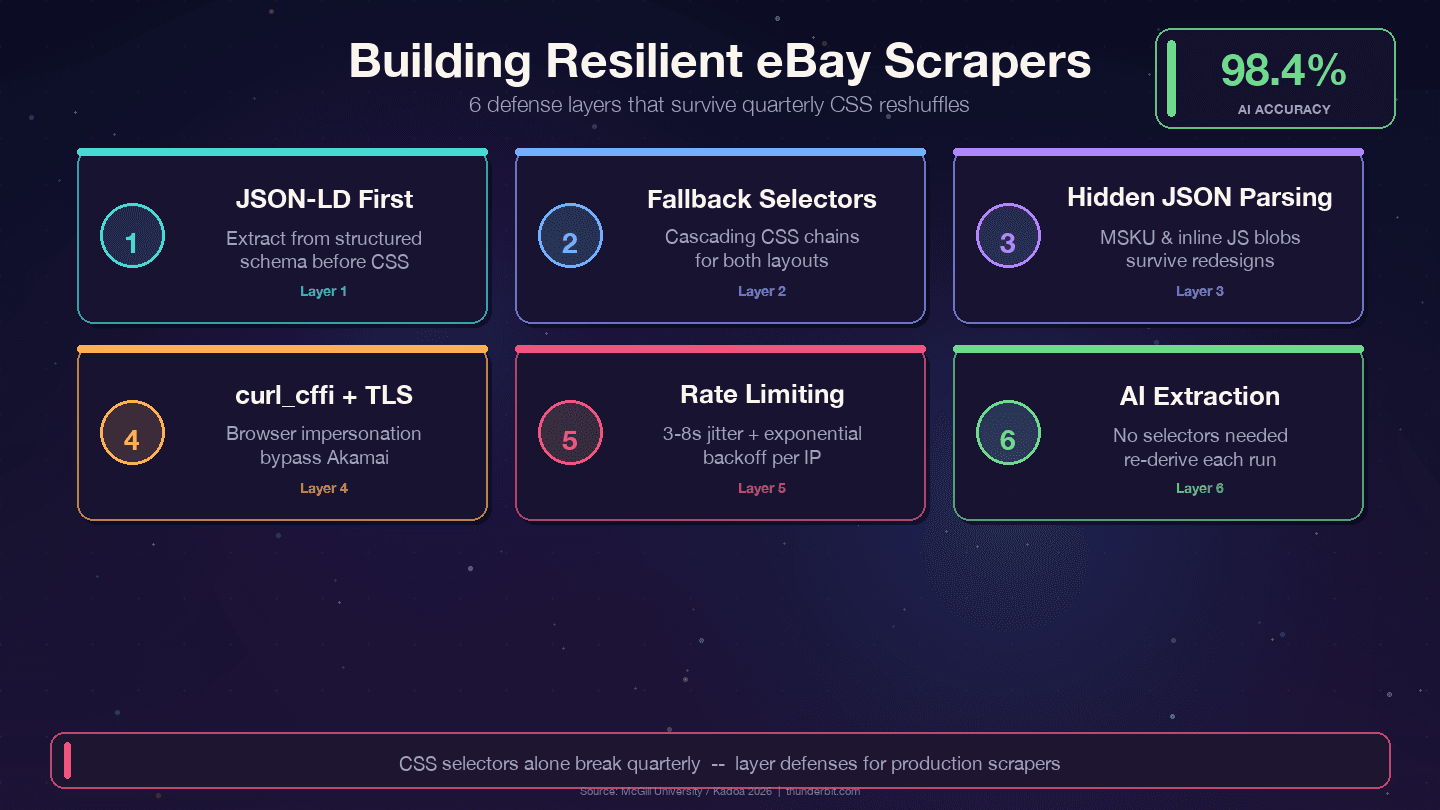
長く使えるeBayスクレイパーの防御策
eBayの四半期ごとの変更を乗り切るための4つの戦略です。
1. CSSセレクタよりJSON-LDを優先する。 eBayは商品ページごとに構造化された Product スキーマを埋め込んでいます。CSSなどの見た目レイヤーは変わりやすい一方で、price、name、seller といったデータ層は内部APIに紐づいており、名前が変わることはまれです。
2. セレクタは必ず複数の候補を持たせる。 ひとつのCSSセレクタに頼ってはいけません。常に代替候補を用意します。
1def first_text(soup, selectors):
2 for sel in selectors:
3 el = soup.select_one(sel)
4 if el and el.get_text(strip=True):
5 return el.get_text(strip=True)
6 return None
7title = first_text(soup, [
8 "h1.x-item-title__mainTitle",
9 "h1.x-item-title__mainTitle .ux-textspans--BOLD",
10 "[data-testid='x-item-title'] h1",
11])3. 隠しJSONを解析する。 MSKU のバリエーションオブジェクトや、インラインJavaScriptのデータは、サーバー側で生成されるため CSS 変更の影響を受けにくいです。<script> タグから正規表現で抜き出すのは手間ですが、保守コストをかなり下げられます。
4. セレクタ失敗をログに残す。 データが空になってから気づくのではなく、いつ壊れたか分かるように監視を入れましょう。
1if title is None:
2 print(f"WARNING: title selector failed for {url}")5. ブラウザ偽装つきの curl_cffi を使う。 これで Akamai の TLS フィンガープリント対策を、ヘッドレスブラウザなしで回避しやすくなります。
AIを使う代替手段:セレクタ保守が不要
数か月ごとにセレクタを直すのに疲れたなら、まったく別のやり方があります。 のようなツールは、ページをそのたびにAIが読み取り、その場で抽出ロジックを組み立てます。McGill大学の研究では、AI方式とセレクタ方式を3,000ページで比較し、 し、業界ベンチマークでは とされています。
| 手法 | eBayのHTML変更で壊れる? | 保守負荷 |
|---|---|---|
| ハードコードされたCSSセレクタ | はい、四半期ごとに壊れやすい | 高い — 継続的な修正が必要 |
| 隠しJSON / JSON-LD抽出 | ほとんど壊れない | 低い |
| AIベースのスクレイピング(Thunderbit) | いいえ — 毎回AIがセレクタを再推定 | なし |
Thunderbit のワークフローは後ほど詳しく紹介します。ここでのポイントは、長期運用するスクレイパーなら、JSON優先の抽出とフォールバックセレクタに投資すべきだということです。そもそもセレクタ保守をしたくないなら、AIアプローチを検討する価値があります。
eBayの定期スクレイピングを自動化して価格監視する
一度だけのスクレイピングでも十分役立ちます。でも、価格監視、在庫追跡、競合分析には、継続的なデータ収集が必要です。競合記事では価格監視がよくユースケースとして挙がりますが、実際にどう自動化するかまで示しているものはほとんどありません。
方法1:Cronジョブ(Linux/macOS)またはタスクスケジューラ(Windows)
最もシンプルな方法です。Pythonスクリプトを cron に登録します。cron は最小限の環境で動くので、venv の Python は必ず絶対パスで指定しましょう。
1crontab -e
2# 毎日08:15に実行
315 8 * * * /Users/me/ebay/venv/bin/python /Users/me/ebay/scrape_ebay.py >> /Users/me/ebay/scrape.log 2>&1Windows では PowerShell を使います。
1$A = New-ScheduledTaskAction -Execute "C:\Users\me\ebay\venv\Scripts\python.exe" -Argument "C:\Users\me\ebay\scrape_ebay.py"
2$T = New-ScheduledTaskTrigger -Daily -At 8:15am
3Register-ScheduledTask -TaskName "eBayScraper" -Action $A -Trigger $Tこの方法では常時稼働のマシンが必要で、プロキシやbot対策も自分で管理します。
方法2:クラウド関数(サーバーレス)
AWS Lambda や Google Cloud Functions を使えば、専用サーバーなしでスクレイパーを動かせます。依存関係のパッケージ化、タイムアウト対策(Lambdaは最大15分)、プロキシ管理は必要なので、セットアップは少し重めです。ただしサーバー保守は不要になります。
方法3:Thunderbitによるノーコードのスケジュール実行
の Scheduled Scraper なら、「毎日8時」みたいに自然言語で間隔を指定して、eBayのURLを入れてスケジュールするだけです。クラウド上で動き、bot対策も内蔵されています。
| 手法 | 導入の手間 | サーバーは必要? | bot対策対応? |
|---|---|---|---|
| Cron + Pythonスクリプト | 中 | はい(常時稼働マシンが必要) | プロキシは自分で管理 |
| クラウド関数(Lambda) | 高 | いいえ(サーバーレス) | プロキシは自分で管理 |
| Thunderbit Scheduled Scraper | 低(言葉で指定するだけ) | いいえ(クラウドベース) | 標準搭載 |
定期的なスクレイプ結果を保存するなら、価格履歴にはローカルSQLiteデータベースが最適です。INSERT OR REPLACE ではなく、ON CONFLICT ... DO UPDATE を使いましょう。INSERT OR REPLACE は ことがあります。
1CREATE TABLE IF NOT EXISTS listings (
2 item_id TEXT PRIMARY KEY,
3 title TEXT NOT NULL,
4 price REAL,
5 last_price REAL,
6 first_seen_at TEXT DEFAULT (datetime('now')),
7 last_seen_at TEXT DEFAULT (datetime('now'))
8);
9CREATE TABLE IF NOT EXISTS price_history (
10 item_id TEXT NOT NULL,
11 observed_at TEXT NOT NULL DEFAULT (datetime('now')),
12 price REAL NOT NULL,
13 PRIMARY KEY (item_id, observed_at)
14);コーディングしたくない?Thunderbitで2分でeBayをスクレイピングする方法
ここまでで Python のコードをかなり紹介しましたが、実は不要なケースもある、ということはちゃんとお伝えしたいです。
単発の市場調査をしたいビジネス担当者、比較価格を確認したいリセラー、今すぐデータが必要なのに開発スプリントを待てないECチームにとっては、Pythonはオーバースペックです。セットアップ、セレクタ保守、プロキシ管理……「200件の出品をスプレッドシートに入れたいだけ」なのに、負担が大きすぎます。
ThunderbitでeBayをスクレイピングする流れ
- をインストール — クレジットカードは不要です。
- ChromeでeBayの検索結果ページまたは商品ページを開く。
- Thunderbitサイドバーの「AIで項目を提案」をクリック。AIがページを読み取り、Title、Price、Condition、Shipping、Seller、Rating などの列を提案します。
- 「スクレイプ」をクリック。 拡張機能がページネーションを処理しながら、データ表を埋めていきます。eBay向けには、Thunderbit には もあります。
- Google Sheets、Airtable、Notion、CSV、JSON、Excel に無料でエクスポート。
全体で2分もかかりません。
私も実測しました。
サブページ強化:追加コードなしで詳細ページのデータを取得
検索結果ページをスクレイピングしたあと、Thunderbit は各出品の詳細ページに移動して、より詳しい項目を追加できます。たとえば、詳細仕様、出品者情報、説明文、全画像などです。これは、先ほど書いた20行以上のサブページ取得用Pythonコードを、ワンクリックで置き換えるものです。
それでもPythonを使うべき場面
Python が強いのは、次のようなケースです。
- 大規模スクレイピング(1回あたり数万ページ)
- 高度にカスタマイズした解析ロジックやデータ変換
- 既存のデータパイプラインとの統合(Airflow、dbt、Kafka など)
- 高度なbot対策のための細かなTLS/セッション制御
- 単位経済性 — 数百万行規模なら、保守済みの自前スタックのほうがSaaS課金より有利
多くの単発〜中規模プロジェクトでは Thunderbit のほうが速くて簡単です。大規模な本番パイプラインなら、Python で自由度を確保できます。
PythonでeBayをスクレイピングしてブロックされないためのコツ
eBay の Akamai 対策はかなり本気です。実際に効く対策は次のとおりです。
impersonate="chrome124"を指定したcurl_cffiを使う — 通常のrequestsよりいちばん効果が大きい改善点です- 現行ブラウザ版の User-Agent を複数ローテーションする(Chrome 143、Firefox 124、Safari 26 など)
- リクエスト間に を入れる — 固定間隔は識別材料になります
- 数十ページを超えるなら住宅回線プロキシまたはローテーションプロキシを使う。データセンターIP(AWS、GCP、DigitalOcean)は Akamai にすぐ弾かれがちです。
robots.txtを尊重する — ほとんどの絞り込み済み browse URL は明示的に Disallow されています。商品詳細ページ(/itm/<id>)は対象外です- CAPTCHA は丁寧に扱う — 検知して別IPで再試行するか、CAPTCHA解決サービスを使いましょう
- サーバーを叩きすぎないこと。 の前例では、実際にサーバー性能を損なうスクレイピングに対して trespass to chattels が適用されました。1IPあたり1req/s程度に抑えていれば、その閾値からはかなり離れられます。
大量利用の商用用途なら、出品中商品の取得には Browse API を使い、売却済み比較やAPI非公開データだけを狙ってスクレイピングする、というハイブリッド構成がおすすめです。技術面でも法務面でも、そのほうがすっきりします。
PythonでeBayをスクレイピングするのは合法?
私は弁護士ではありませんし、この記事は法的助言ではありません。ここは簡潔にまとめます。
公開されているデータのスクレイピングをめぐる法的環境は、近年かなりスクレイピング寄りに動いています。重要な判例は次のとおりです。
- (第9巡回区、2022年):公開データのスクレイピングは CFAA に違反しない
- Van Buren v. United States(米連邦最高裁、2021年):CFAA の「許可されたアクセスを超える」条項を狭く解釈
- (カリフォルニア北部地区、2024年):ログアウト状態でのスクレイピングは、スクレイパーが「ユーザー」ではないためプラットフォームの利用規約違反にならない
とはいえ、eBay の では、「buy-for-me エージェント、LLM駆動ボット、または人間の確認なしに注文完了を目指すエンドツーエンドのフロー」が明確に禁止されています。線引きははっきりしています。公開ページの読み取り専用スクレイピングは比較的安全ですが、チェックアウトの自動化は別問題です。
ベストプラクティスは、公開表示されているデータだけを取ることです。偽アカウントを作らない、ログイン壁を回避しない、著作権のある画像を無断で大量再利用しない、商用規模なら法務に相談する、という点は守りましょう。
まとめと重要ポイント
Python は eBay をスクレイピングする最も柔軟な方法ですが、サイトのHTMLが変わるたびに保守が必要です。選び方の目安は次のとおりです。
- eBay Browse API は、出品中商品の安定した中規模の構造化検索に使う
- Pythonスクレイピング は、売却済み一覧、レビュー、バリエーション情報、APIにない項目に使う
- は、コードを書いたり保守したりせずに eBay データを取りたい場合に最適
このガイドのコードは、堅牢性を最優先にしています。つまり、最初に JSON-LD を見て、次に CSS のフォールバックを使い、バリエーションは隠しJSONから取る構成です。この多層的な設計なら、eBayのフロントエンドチームが次にUIを刷新しても、スクレイパーがすぐ壊れることはありません。
ノーコードを試したいなら、 で今すぐ eBay ページを試せます。 の動きを見たい場合も、ワンクリックです。
Webスクレイピングツールについてさらに知りたい方は、、、 もご覧ください。 ではチュートリアル動画も公開しています。
FAQ
1. PythonでeBayを無料でスクレイピングできますか?
はい。Requests、BeautifulSoup、curl_cffi、pandas などのライブラリはすべて無料のオープンソースです。コストがかかるのは大量取得時で、住宅回線プロキシは帯域に応じて通常 月50〜500ドルほどです。数百ページ程度の小規模案件なら、慎重にレート制限すれば自宅回線からでも取得できます。
2. PythonでeBayの売却済み・終了済みリストを取得するには?
検索URLのパラメータに LH_Complete=1&LH_Sold=1 を追加します。両方必要です。LH_Sold=1 だけだと、カテゴリによっては静かに通常の出品一覧に戻ることがあります。結果は、価格要素に .POSITIVE のCSSクラスが付いているかを確認して、実際に売れたものだけを残しましょう。これは売れていない終了済み出品と区別するためです。
3. eBayはWebスクレイピングをブロックしますか?
eBay は Akamai Bot Manager を使っており、主に TLS フィンガープリントと行動分析でスクレイパーを検知します。通常の requests は 403 になりやすいです。curl_cffi によるブラウザ偽装、User-Agent のローテーション、リクエスト間の3〜8秒のランダム遅延で、多くのブロックは回避できます。大量取得では住宅回線プロキシが役立ちます。
4. eBay APIとWebスクレイピング、どちらを使うべき?
出品中商品の安定した中規模クエリには Browse API を使いましょう(1日5,000回まで)。売却価格の履歴、完全なバリエーション/MSKUデータ、レビュー、APIが公開していない項目が必要ならスクレイピングです。Marketplace Insights API は理論上売却データを提供しますが、アクセス制限があり、 のが現実です。
5. コードなしでいちばん簡単にeBayをスクレイピングする方法は?
はAIで eBay ページを読み取り、データ列を提案し、ワンクリックで出品情報を抽出します。ページネーション、詳細ページの追加取得、Google Sheets、Excel、Airtable、Notion への出力にも対応しています。事前構築済みの を使えば、よくある用途ならさらに速くなります。
さらに学ぶ