Craigslist は今でも約700の地域サイトをまたいで、月間およそものアクセスを集めています。それでも、公開APIは今もありません。賃貸物件、中古車、求人、ギグ広告などのデータをきれいに構造化して取りたいなら、スクレイピングがほぼ唯一の手段です。
ただ、Craigslist 独自のボット対策はかなり手強いです。Cloudflare や DataDome を使っているわけではなく、10年以上かけて磨かれてきた独自の nginx ベースのレート制限が動いています。やり方を間違えると、コーヒーを2杯飲み終わる前に、あっさり403が返ってきます。私は CraigsList の防御に対していろいろな方法を長く検証してきましたが、その集大成がこのガイドです。2025年時点で使える、カテゴリを問わない Python チュートリアルとして、JSON-LD 抽出という最新手法(古い解説との最大の違い)、BAN回避の実践策、法的な注意点、そしてコードを書かずにデータだけ欲しい人向けのノーコード代替手段まで、まとめて紹介します。
PythonでCraigslistをスクレイピングするとは?
Craigslist のウェブスクレイピングとは、Python スクリプトを使って Craigslist のページにプログラムでアクセスし、タイトル、価格、説明文、画像、所在地、投稿日など必要な構造化データを抽出して、スプレッドシート、データベース、JSONファイルに保存することです。
Python がよく使われるのは、ライブラリエコシステムがとても充実しているからです。requests、BeautifulSoup、lxml、curl_cffi を組み合わせれば、100行未満で動く Craigslist スクレイパーを作れます。コミュニティもかなり大きいので、Craigslist 側の仕様が変わっても(実際に変わります)、すでに誰かが対処法を見つけていることが多いです。
ここで押さえておくべき大事なポイントは、Craigslist はということです。公式のプログラム用インターフェースは Bulk Posting Interface(BAPI)だけで、これは書き込み専用です。承認済みの有料投稿者が掲載を送信するためのもので、取得はできません。サードパーティのプラットフォームで見かける「Craigslist API」製品は、すべて非公式のスクレイパーであって、公式エンドポイントではありません。大量のデータが欲しいなら、結局スクレイピングするしかないのです。
なぜCraigslistをスクレイピングするのか?実際の活用例
Craigslist は中古ソファを探す場所、というだけではありません。数十のカテゴリにまたがる、巨大で常に更新されるデータセットです。実際にスクレイピングの恩恵を受けるのは、たとえば次のような人たちです。
| 用途 | 恩恵を受ける人 | 抽出する項目 |
|---|---|---|
| 賃貸・物件価格のモニタリング | 不動産会社、借り手、PropTech企業 | 価格、面積、寝室数、エリア、緯度経度 |
| 中古車市場の分析 | 販売店、消費者向けアプリ、研究者 | 価格、メーカー、モデル、年式、走行距離、状態 |
| 求人市場の調査 | 採用担当、労働経済学者、人材分析担当 | タイトル、報酬、雇用形態、投稿日 |
| リード獲得 | 営業チーム、サービス提供事業者 | 連絡先、会社名、対応エリア |
| 競合価格調査 | 地域サービス事業者、EC運営 | サービス料金、説明文、対応エリア |
よく引用される学術的な例としては、があります。これは約50万件の米国中古車掲載情報を26項目でまとめたもので、2024年の ResearchGate 研究を含む、多くの論文の土台になっています。ヘッジファンドが賃貸トレンド研究のために Craigslist の賃貸データを集約して購入した例もありますし、営業チームがサービスやギグのカテゴリを定期的にスクレイピングしてリード獲得に使うことも珍しくありません。
要するに、手作業で8時間コピー&ペーストするのか、それとも10分ほどでちゃんと作ったスクレイパーを使うのか、という話です。
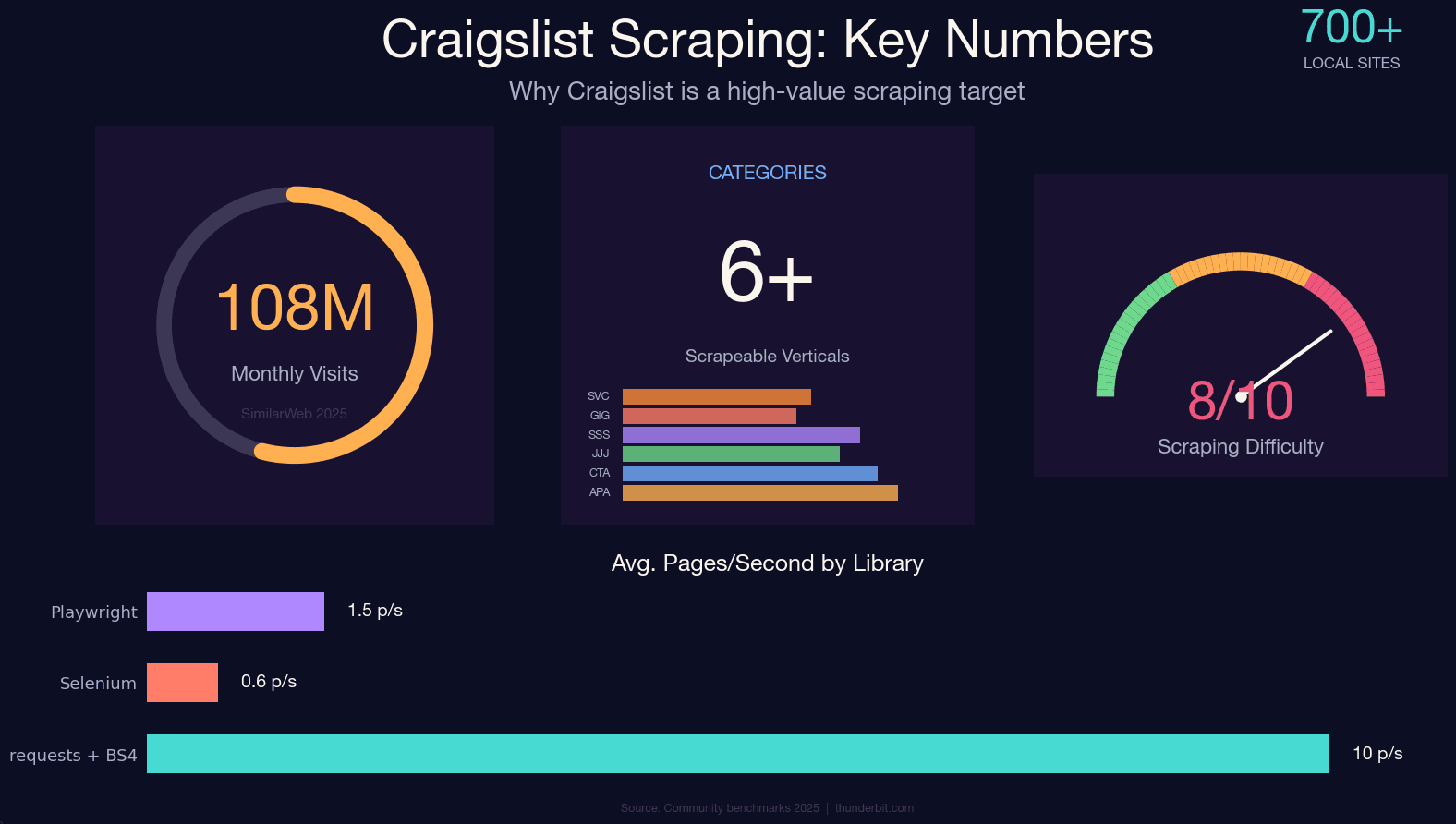
PythonでCraigslistをスクレイピングする:車だけでなく全カテゴリ対応
Craigslist の解説記事は、ほとんどが車販売だけを扱っています。これは、Google のチュートリアルで画像検索だけを説明しているようなものです。Craigslist には多くのカテゴリがあり、URLパターンもそれぞれ違います。
基本構造は常に https://{city}.craigslist.org/search/{category_slug} です。
都市のサブドメインとスラッグを差し替えるだけで、まったく別の分野を取得できます。以下は主要カテゴリの参考表です(2025年4月確認)。
| カテゴリ | URLスラッグ | よく抽出する項目 |
|---|---|---|
| Apartments / Housing | /search/apa | 価格、面積、寝室数、所在地、ペット可否 |
| Cars & Trucks | /search/cta | 価格、メーカー、モデル、年式、走行距離 |
| Jobs | /search/jjj | タイトル、会社名、給与、雇用形態 |
| Services | /search/bbb | タイトル、説明、電話番号、地域 |
| Gigs | /search/ggg | タイトル、報酬、日付、カテゴリ |
| For Sale (general) | /search/sss | タイトル、価格、状態、所在地 |
さらに、検索条件はクエリパラメータで絞り込めます。
| パラメータ | 用途 | 例 |
|---|---|---|
query | キーワード全文検索 | ?query=studio |
min_price / max_price | 価格帯 | &min_price=1500&max_price=3000 |
hasPic | 画像付き投稿のみ | &hasPic=1 |
postedToday | 直近24時間 | &postedToday=1 |
sort | 並び順 | &sort=priceasc |
s | ページネーションのオフセット(1ページ120件) | ?s=120 |
つまり、https://newyork.craigslist.org/search/apa?min_price=1500&max_price=3000&hasPic=1 のようなURLを使えば、写真付きで1,500〜3,000ドルのニューヨークの賃貸物件を取得できます。このガイドの Python スクレイパーは、スラッグを変えるだけでこれらすべてのカテゴリに対応できます。
2025年版CraigslistのHTMLセレクタ:旧方式と新方式、そしてJSONという近道
Craigslist のスクレイパーが壊れる大きな理由は、HTML構造の変更です。2022年のチュートリアルを見て .result-row や .result-info を狙えと書いてあっても、そのスクレイパーはもう動きません。
Craigslist は2023〜2024年に検索結果のマークアップを再設計しました。古いクラス名は新しいラッパーの中に残っていますが、DOM の上位でそれを狙っても空のリストが返るだけです。変更点は次のとおりです。
| 要素 | 旧セレクタ(2024年以前) | 現在のセレクタ(2025年) |
|---|---|---|
| 掲載コンテナ | .result-info | .cl-search-result |
| タイトルリンク | .result-title | .posting-title a |
| 価格 | .result-price | .priceinfo |
| メタ情報(エリア) | .result-hood | .meta |
でも、ここで本当に重要なのは、そして2025年対応のスクレイパーを古い手法と分けるのは、検索結果に対してはHTMLを解析する必要すらないという点です。
Craigslist は今、表示される掲載情報をすべて <script id="ld_searchpage_results"> タグ内に構造化JSON-LDデータとして埋め込んでいます。requests.get() を1回実行するだけで、そのページ上の全掲載情報を含む schema.org の ItemList が丸ごと返ります。タイトル、価格、通貨、所在地、画像URL、詳細ページのリンクまで取得できます。JavaScriptレンダリングは不要で、CSSセレクタの壊れやすさもありません。
JSON-LD 方式は、HTML を直接たどる方法よりも高速で安定しており、Craigslist 側がUIを少し変えた程度では壊れにくいのが大きな利点です。今も保守されている GitHub リポジトリの多くが使っている方法で、このあと紹介するチュートリアルでもこれを採用します。
注意点として、このJSON-LDブロックはことが多いです。たとえば apartments(apa)、for sale(sss)、cars(cta)、housing(hhh)などです。一方で jobs(jjj)、gigs(ggg)、community(ccc)、services(bbb)では、schema.org/Offer の価格情報がないため、存在しないか薄いことがよくあります。その場合は .cl-search-result のHTML経路に戻ります。
Pythonスタックの選び方:requests + BS4、Selenium、Playwright の比較
スクレイピングの話題で必ず出るのが、「どのライブラリを使うべき?」という質問です。Craigslist に限って言えば、答えは多くのサイトよりもはっきりしています。
| 比較項目 | requests + BeautifulSoup | Selenium | Playwright |
|---|---|---|---|
| 速度 | 5〜15ページ/秒(通信依存) | 0.3〜1ページ/秒 | 0.5〜2ページ/秒 |
| JavaScript描画の必要性 | なし | あり | あり |
| メモリ使用量 | 約30〜60 MB | 約400〜700 MB | 約300〜500 MB |
| セットアップの複雑さ | 低い | 中 | 中 |
| ボット対策への耐性 | 低い(ヘッダー/プロキシが必要) | 中(実ブラウザ) | 中〜高 |
| Craigslistでの最適用途 | 検索結果(JSON-LD) | 動的要素のある詳細ページ | 大規模な非同期スクレイピング |
| 学習コスト | 初心者向け | 中程度 | 中程度 |
Craigslist のページはサーバーサイドで描画されています。JSON-LD の塊も初回HTMLに入っています。読み取り側で JavaScript チャレンジはありません。現時点で保守されているは、ほぼすべて requests + BeautifulSoup か Scrapy を使っており、Selenium や Playwright は使っていません。これは偶然ではありません。ブラウザ自動化フレームワークは、数百MBのメモリ消費、10〜100倍の速度低下、そして利点のないまま目立つフィンガープリントを増やすだけだからです。
私のおすすめ:
- requests + BS4: まずここから始めるのが最適です。JSON-LD 抽出と相性がよく、Craigslist スクレイピングの95%をカバーできます。
- Selenium: 特定の詳細ページで動的コンテンツとのやり取りが必要な場合だけ使います(Craigslist ではまれです)。
- Playwright: 数千ページを非同期並列で処理する場合。ただし正直なところ、ボトルネックはライブラリの速度ではなく、Craigslist 側のレート制限です。
より詳しい比較としては、別記事で や をまとめています。
ノーコード代替手段:Pythonを書かずにCraigslistを取得する
コードの前に少し寄り道します。この章は、開発者ではない人向けです。不動産エージェント、営業チーム、運用担当者など、とにかくデータが欲しくて Python を書きたくないなら、もっと早い方法があります。
は Chrome 拡張機能として動く AIウェブスクレイパーです。Craigslist なら、たった2クリックほどでスクレイピングでき、コードは不要です。手順は次のとおりです。
- まず、Craigslist の検索結果ページ(賃貸、車、求人など、どのカテゴリでもOK)を開きます。
- Thunderbit のサイドバーで 「AIで項目を提案」 をクリックします。AI がページを読み取り、掲載タイトル、価格、所在地、リンクなどの列を自動で見つけます。
- 「スクレイピング」 をクリックすると、数秒でデータが抽出されます。
- サブページスクレイピング を使えば、各掲載の詳細ページに移動して、説明文、電話番号、画像、属性情報まで補完できます。
- Google Sheets、Excel、Airtable、Notion に直接、しかも完全無料でエクスポートできます。
毎日や毎週のような定期取得が必要な場合、たとえば毎日の賃貸価格モニタリングや週次の求人一覧取得なら、Thunderbit の定時スクレイパーでスケジュールを自然文で書くだけで自動実行できます。cron ジョブもサーバー設定も不要です。
Thunderbit は Cloud Scraping モードでボット対策も処理するので、プロキシのローテーションやヘッダー調整を自分で気にする必要がありません。試してみたいなら、 を入れて体験してみてください。
自分で細かく制御したいなら、このまま Python の手順を読み進めてください。
手順付き:PythonでCraigslistをスクレイピングする方法(完全版)
- 難易度: 中級
- 所要時間: 約30分(セットアップ+最初の取得)
- 必要なもの: Python 3.8以上、Chromeブラウザ(ページ確認用)、ターミナル
ステップ1:Python環境を準備する
必要なライブラリをインストールします。
1pip install requests beautifulsoup4 lxmllxml は必須ではありませんが、BeautifulSoup の解析速度をかなり上げてくれます。後で TLS のフィンガープリント問題が出た場合(詳細はBAN回避の章で説明します)、curl_cffi も入れておくとよいでしょう。
1pip install curl_cffiインポートは次のようになります。
1import requests
2from bs4 import BeautifulSoup
3import json
4import csv
5import time
6import randomこれで、必要な依存関係がそろったクリーンな Python 環境ができました。
ステップ2:どのカテゴリにも使えるCraigslistのURLを組み立てる
都市名 + カテゴリスラッグ + 任意のフィルターで、対象URLを動的に作ります。
1from urllib.parse import urlencode
2BASE = "https://{city}.craigslist.org/search/{slug}"
3def build_url(city, slug, **params):
4 return f"{BASE.format(city=city, slug=slug)}?{urlencode(params)}"
5# 例:ニューヨークの賃貸、1500〜3000ドル、写真付き
6url = build_url("newyork", "apa", min_price=1500, max_price=3000, hasPic=1)
7print(url)
8# https://newyork.craigslist.org/search/apa?min_price=1500&max_price=3000&hasPic=1"apa" を "cta"(車)、"jjj"(求人)、"bbb"(サービス)など、先ほどのカテゴリ表にあるスラッグへ置き換えてください。"newyork" も "sfbay"、"chicago"、"losangeles" などに変えられます。
ステップ3:ページを取得して埋め込みJSONを抽出する
適切なヘッダー付きでGETリクエストを送り、JSON-LDブロックを解析します。
1HEADERS = {
2 "User-Agent": (
3 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
4 "AppleWebKit/537.36 (KHTML, like Gecko) "
5 "Chrome/124.0.0.0 Safari/537.36"
6 ),
7 "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
8 "Accept-Language": "en-US,en;q=0.9",
9 "Accept-Encoding": "gzip, deflate, br",
10 "Referer": "https://www.craigslist.org/",
11 "Sec-Fetch-Dest": "document",
12 "Sec-Fetch-Mode": "navigate",
13 "Sec-Fetch-Site": "same-origin",
14 "Upgrade-Insecure-Requests": "1",
15}
16session = requests.Session()
17r = session.get(url, headers=HEADERS, timeout=20)
18r.raise_for_status()
19soup = BeautifulSoup(r.text, "html.parser")
20tag = soup.select_one("script#ld_searchpage_results")
21data = json.loads(tag.text) if tag else {"itemListElement": []}tag が None の場合、そのカテゴリではJSON-LDブロックが存在しません。そのときはHTML解析に切り替えます(上のセレクタ表を参照)。賃貸、車、売買系カテゴリでは、JSON-LDブロックはかなり安定して存在します。
ステップ4:掲載データを構造化レコードに変換する
JSONの各項目を回しながら、必要なフィールドを取り出します。
1listings = []
2for entry in data["itemListElement"]:
3 item = entry["item"]
4 offers = item.get("offers", {}) or {}
5 addr = (offers.get("availableAtOrFrom") or {}).get("address", {})
6 listings.append({
7 "name": item.get("name"),
8 "url": offers.get("url"),
9 "price": offers.get("price"),
10 "currency": offers.get("priceCurrency"),
11 "locality": addr.get("addressLocality"),
12 "region": addr.get("addressRegion"),
13 "image": item.get("image"),
14 })
15print(f"Found {len(listings)} listings")おそらく「Found 120 listings」のように表示されるはずです(Craigslist は1ページあたり120件表示します)。投稿者が価格を入れていない場合、いくつかの掲載は None になることがありますが、後続処理で適切に扱えば問題ありません。
ステップ5:詳細ページを取得して情報を増やす
検索結果だけでは概要しか取れません。詳細な説明、属性(寝室数、面積、ペット条件)、緯度経度、画像まで取得したいなら、各掲載の詳細URLを訪問する必要があります。
1def fetch_detail(url, session):
2 r = session.get(url, headers=HEADERS, timeout=20)
3 r.raise_for_status()
4 s = BeautifulSoup(r.text, "html.parser")
5 body = s.select_one("#postingbody")
6 mp = s.select_one("#map")
7 return {
8 "description": body.get_text("\n", strip=True) if body else None,
9 "attributes": [x.get_text(" ", strip=True)
10 for x in s.select("p.attrgroup span, div.attrgroup .attr")],
11 "lat": mp.get("data-latitude") if mp else None,
12 "lng": mp.get("data-longitude") if mp else None,
13 "images": [img["src"] for img in s.select("div.gallery img")],
14 }
15for item in listings:
16 item.update(fetch_detail(item["url"], session))
17 time.sleep(random.uniform(3, 6)) # 重要:BAN回避のためのジッターtime.sleep(random.uniform(3, 6)) は省略しないでください。これを飛ばすと、数十件も取得しないうちに403にぶつかります。詳細ページはサーバー描画で、#titletextonly、#postingbody、#map などのセレクタが約2017年からほぼ変わっていないため、Craigslist の中では珍しく安定しています。
ステップ6:ページネーションに対応して全件取得する
Craigslist のページ送りは ?s=120 のオフセットパラメータで行われます。1ページに120件表示され、最大オフセットは通常2999です。
1def iter_all(city, slug, max_pages=25, **filters):
2 for page in range(max_pages):
3 offset = page * 120
4 url = build_url(city, slug, s=offset, **filters)
5 r = session.get(url, headers=HEADERS, timeout=20)
6 r.raise_for_status()
7 soup = BeautifulSoup(r.text, "html.parser")
8 tag = soup.select_one("script#ld_searchpage_results")
9 if not tag:
10 break
11 data = json.loads(tag.text)
12 items = data.get("itemListElement", [])
13 if not items:
14 break
15 for entry in items:
16 item = entry["item"]
17 offers = item.get("offers", {}) or {}
18 yield {
19 "name": item.get("name"),
20 "url": offers.get("url"),
21 "price": offers.get("price"),
22 }
23 time.sleep(random.uniform(2.5, 5.0))何千ページも一気に取得しようとしないでください。Craigslist のレート制限はIP単位でかかっており、どのライブラリを使っても、単一IPで持続的に出せるのはおおむね0.3〜0.5リクエスト/秒が上限です。この上限は Python ではなく Craigslist 側が決めています。
ステップ7:CraigslistデータをCSV、JSON、またはGoogle Sheetsに出力する
結果を保存します。
1# CSV
2with open("craigslist.csv", "w", newline="", encoding="utf-8") as f:
3 w = csv.DictWriter(f, fieldnames=listings[0].keys())
4 w.writeheader()
5 w.writerows(listings)
6# JSON
7with open("craigslist.json", "w", encoding="utf-8") as f:
8 json.dump(listings, f, indent=2, ensure_ascii=False)エクスポートのコード自体を省きたいなら、Thunderbit ならブラウザから Google Sheets、Excel、Airtable、Notion へ無料で直接出力できます。とはいえ、Python のパイプラインでは CSV と JSON が標準的な出力です。さらに pandas に渡して分析したり、sqlite3 でデータベースに入れたりもできます。
PythonでCraigslistをスクレイピングしてBANされないための方法
多くの解説記事はこの部分を軽く流していますが、Craigslist のボット対策は既製品ではなく独自実装で、いくつか独特の癖があります。

現実的なリクエストヘッダーを使う
Craigslist はヘッダーの順序や不足をチェックしています。Sec-Fetch-Dest がない、あるいは古い User-Agent を使っているリクエストは、内容に届く前に弾かれることがあります。Step 3 で示した Chrome 120+ 相当のヘッダー一式が最低ラインです。User-Agent は1セッションごとに、最近の Chrome/Firefox デスクトップ用文字列を5〜10種類ほど回すとよいですが、セッション途中で変えるのは不自然なので避けてください。
Sec-Fetch-* ヘッダーが欠けていることは、初めてのスクレイパーが即ブロックされる最も多い原因です。
リクエストの合間にランダムな遅延を入れる
(ScrapingBee、Scraperly、Oxylabs、Multilogin)でも、検索結果の取得には2〜5秒のランダム遅延、詳細ページには3〜6秒のランダム遅延が推奨されています。一定間隔はボットっぽく見えます。time.sleep(2) ではなく、time.sleep(random.uniform(2, 5)) を使ってください。
大規模に取得するならプロキシをローテーションする
Craigslist は AWS、GCP、Azure の IP レンジをまとめて事前ブロックすることがあります。データセンター系プロキシは、使った瞬間に死んでいることも多いです。数百ページを超えるなら、住宅系のローテーションプロキシが必要で、20〜30リクエストごとに切り替えるのが一般的です。モバイルプロキシは検出リスクが最も低いですが、費用は1GBあたり8〜30ドルです。
| プロキシ種別 | Craigslistでの検出リスク | 費用(2025年) |
|---|---|---|
| データセンター | 非常に高い — 初回でブロックされることが多い | $0.50〜2/GB |
| 住宅系ローテーション | 低い — 推奨 | $5〜15/GB |
| モバイル | 最も低い | $8〜30/GB |
Thunderbit の Cloud Scraping モードを使えば、このプロキシ管理を自分でやらなくても大丈夫です。
CAPTCHAは無理に突破しない
Craigslist で CAPTCHA が出ることはまれで、ほとんどは投稿や返信フローで発生します。もし表示されたら、少なくとも60秒は待ち、IPを変え、Cookieを消し、速度を落としてください。繰り返し出る CAPTCHA は、解くべきパズルではなく、処理速度が速すぎるサインです。
レート制限を尊重し、バックオフを実装する
Craigslist はレート制限に達すると 429 ではなく 403 を返します。403 は、そのIPが拒否リストに入ったという意味です。やみくもに再試行しないでください。IPを変え、UAを変え、待機しましょう。
1from requests.adapters import HTTPAdapter
2from urllib3.util.retry import Retry
3retry = Retry(
4 total=5,
5 backoff_factor=1.5, # 1.5, 3, 6, 12, 24秒
6 status_forcelist=[429, 500, 502, 503, 504],
7 allowed_methods={"GET"},
8 respect_retry_after_header=True,
9)
10adapter = HTTPAdapter(max_retries=retry)
11session.mount("https://", adapter)もうひとつのコツとして、コミュニティの報告では対象都市の現地時間で午前2時〜6時が最も安全な取得時間帯で、昼間よりブロック率が約30〜40%低いとされています。
目に見えない落とし穴:TLSフィンガープリント
Craigslist のボット層は TLS ClientHello も確認しています。Python の requests ライブラリ(OpenSSL ベース)は、実ブラウザとは違う JA3 フィンガープリントを持っています。User-Agent だけ完璧でも、TLS の指紋がブラウザらしくないと不一致として検知されます。回避策は、Chrome の TLS ハンドシェイクを模倣できる を impersonate="chrome124" 付きで使うことです。
1from curl_cffi import requests as cffi_requests
2r = cffi_requests.get(url, headers=HEADERS, impersonate="chrome124")住宅系のクリーンなIPと正しいヘッダーを使っているのに説明不能な403が出るなら、原因は TLS フィンガープリントである可能性が高いです。
Craigslistのrobots.txt、利用規約、そして倫理的なスクレイピング
多くのガイドはこの話題を完全に飛ばすか、FAQ に一行だけ書いて終わっています。でも Craigslist はスクレイピングをめぐって RadPad に対しを勝ち取っており(2017年)、ここは脚注で済ませられません。
Craigslistのrobots.txtは実際に何を言っているのか
は驚くほど短く、User-agent: * のブロックが1つあるだけで、禁止パスは7つだけです。
1Disallow: /reply
2Disallow: /fb/
3Disallow: /suggest
4Disallow: /flag
5Disallow: /mf
6Disallow: /mailflag
7Disallow: /eafこの7つはいずれも、返信、フラグ、提案、友達にメール送信などの操作系エンドポイントです。掲載ページ(/search/... や個別投稿URL)は禁止されていません。 Crawl-delay の指定もありませんが、Craigslist 側は IP ブロックで実質的に制御しています。
都市ごとのサブドメインにはサイトマップも公開されています。たとえば https://newyork.craigslist.org/sitemap/index.xml で、掲載情報を公式にたどれる経路になっています。
法的な先例:重要なケース
Craigslist v. 3Taps(2013年、2015年和解): 3Taps は Craigslist の掲載情報をスクレイピングして再販していました。Craigslist が停止要求を送り、IP をブロックした後も、3Taps はローテーションプロキシで回避しました。裁判所は、明示的に権限が取り消された後に IP ブロックを回避する行為は、CFAA 上の「無権限アクセス」にあたると判断しました。3Taps はしています。
Meta v. Bright Data(2024年): より最近の判決では、Meta の利用規約は、公開されているデータのログアウト状態でのスクレイピングを禁止できないとされました。裁判所は、ログアウトしたスクレイパーは「訪問者と同じ立場」だと判断しています。これは2024〜2025年のスクレイパーにとってかなり重要な判断です。Craigslist アカウントを作らず、ログインもせず、公開表示されているページだけにアクセスするなら、利用規約を契約として強制されない可能性があります。
実務上の結論: 公開ページに対するスクレイピングは、Van Buren(2021年)や hiQ v. LinkedIn(2022年)以降、CFAA リスクがかなり下がっています。ただし、州法上の不法行為(動産侵害、misappropriation など)のリスクは残ります。3Taps の和解や RadPad への6,050万ドル判決を動かしたのも、まさにこの部分です。
これは情報提供であり、法律相談ではありません。Craigslist を商用でスクレイピングするなら、弁護士に相談してください。
実践的な倫理チェックリスト
- ✅ robots.txt の
Disallowをすべて守る — とくに7つの操作系エンドポイント - ✅ 1IPあたり24時間で1,000ページを大きく超えない(Craigslist の利用規約では、それを超えるとの損害賠償が設定されています)
- ✅ ログアウト状態を保つ — スクレイピング用に Craigslist アカウントを作らない
- ✅ 明示的にブロックされた後に、プロキシで IP 制限を回避しない(これが 3Taps の失敗原因です)
- ✅ リクエストの間隔を空ける — 最低でも2〜5秒
- ✅ スパム目的で個人の連絡先を取得しない
- ✅ 生の Craigslist データを再配布したり、自分のプラットフォームのように見せたりしない
- ✅ 正当な調査、分析、個人利用目的で使う
- ✅ 可能なら、力任せのクロールより公開サイトマップを優先する
- ✅ 保存するなら、取り込み時に PII(メールアドレス、電話番号)を削除する
さらに詳しく知りたい方は、についての詳しいガイドもあります。
Pythonとノーコード、どちらが向いている?
| 比較項目 | Python(requests + BS4) | Thunderbit(ノーコード) |
|---|---|---|
| 準備時間 | 30〜60分(インストール、コーディング) | 2分(Chrome拡張を入れるだけ) |
| 必要な技術 | 中級Python | 不要 |
| カスタマイズ性 | ロジック、項目、処理フローを完全制御 | AIが項目を自動検出、必要に応じて調整可能 |
| スケール | 無制限(プロキシ、スケジュール運用込み) | 定期実行はScheduled Scraperで対応 |
| BAN対策 | 手動対応(ヘッダー、遅延、プロキシ、TLS) | 内蔵(Cloud Scraping) |
| 出力 | CSV、JSON(自分で実装) | Google Sheets、Excel、Airtable、Notionへ無料出力 |
| 向いている人 | 開発者、データサイエンティスト、独自パイプライン構築者 | 営業、不動産、運用担当者 |
完全なカスタマイズが必要な場合、より大きなデータパイプラインに統合したい場合、あるいは仕組みを自分で正確に理解したい場合は Python が向いています。コードを書かず、保守もしたくないなら が向いています。どちらも正しい選択です。要は、あなたの用途と、ターミナルで作業したいかブラウザで完結させたいかです。
まとめ
Craigslist は、住宅、車、求人、サービス、ギグなどにまたがる、豊富で常に更新されるデータソースです。そして公開APIがない以上、構造化データを大規模に取得するにはスクレイピングが唯一の方法です。2025年時点で本当に機能するやり方は、検索結果に埋め込まれた JSON-LD を抽出すること(壊れやすい CSS セレクタではなく)、requests + BeautifulSoup を使うこと(Selenium ではなく)、Sec-Fetch-* を含む現実的なヘッダーを付けること、遅延をランダム化すること、そして数百ページを超えるなら住宅系プロキシを使うことです。
JSON-LD 方式は、古い解説と比べたときの最大の改善点です。高速で、レイアウト変更に強く、JavaScript レンダリングも不要です。上で紹介した BAN 回避策と組み合わせれば、多くのスクレイパーがつまずく403を避けやすくなります。
もしコードを書かずに済ませたいなら、 を使えば、Craigslist のどのカテゴリでも数クリックで取得でき、好きなスプレッドシートやデータベースへ直接エクスポートできます。さらに深く学びたいなら、 や のガイドも、基本から詳しく解説しています。
FAQ
Craigslistをスクレイピングするのは合法ですか?
Craigslist の利用規約では自動スクレイピングが禁止されており、1日1,000ページを超えると1ページ0.25ドルの損害賠償条項があります。ただし、Meta v. Bright Data(2024年)や hiQ v. LinkedIn(2022年)など最近の判決により、公開データのログアウト状態でのスクレイピングに対する CFAA 上の責任は狭まっています。州法上の不法行為(動産侵害など)のリスクは依然として残り、特に商用再配布では注意が必要です。robots.txt を守り、ログアウト状態を維持し、待機時間を入れ、生データを再配布しないでください。これは一般情報であり、法律相談ではありません。
Craigslistに公開APIはありますか?
いいえ。Craigslist が提供しているのは、承認済みの有料投稿者向けの書き込み専用 Bulk Posting Interface(BAPI)だけです。公開の読み取りAPI、開発者ポータル、データ取得用のレート制限付き階層はありません。サードパーティで見かける「Craigslist API」は、すべて非公式のスクレイパーです。
なぜCraigslistスクレイパーはすぐ壊れるのですか?
ほとんどの場合、HTML構造の変更が原因です。Craigslist は2023〜2024年に検索結果のマークアップを再設計しており、.result-row や .result-info のような旧セレクタを使う解説はもう通用しません。代わりに、埋め込み JSON-LD(script#ld_searchpage_results)を解析する方法に切り替えると、かなり頑丈になります。さらに、ヘッダーに Sec-Fetch-* が入っているかも確認してください。欠けていると即ブロックされます。
PythonなしでCraigslistをスクレイピングできますか?
できます。Thunderbit の AIウェブスクレイパー Chrome 拡張機能は、Craigslist のどのページでも使えます。賃貸、車、求人、サービスなど何でも対応可能です。"AIで項目を提案" をクリックして列を自動検出し、"スクレイピング" を押せばデータを取得できます。そのまま Google Sheets、Excel、Airtable、Notion へ無料でエクスポート可能です。コーディング不要、準備不要、プロキシ管理も不要です。
BANされずにCraigslistをどのくらいの頻度でスクレイピングできますか?
1つの住宅系IPであれば、ページ間に2〜5秒のランダム遅延を入れて、持続可能な速度はおおむね0.3〜0.5リクエスト/秒です。BANや Craigslist 利用規約の損害賠償ラインを避けるため、1IPあたり24時間で1,000ページ未満に抑えてください。オフピーク時間帯(対象都市の現地時間で午前2時〜6時)に取得すると、ブロック率は約30〜40%下がります。大量取得が必要なら、20〜30リクエストごとに住宅系プロキシをローテーションしてください。
さらに詳しく学ぶ