エグゼクティブサマリー
では、ポリシー面の問いを立てました。世界で最も訪問数の多いウェブサイトのうち、どれだけが AI クローラーに対して、何をしてよくて何をしてはいけないかを示しているのか、という問いです。
今回の続編では、その裏側にある運用上の問いを扱います。いまやそのポリシーを載せる土台として求められている robots.txt は、どれほど頼りになるのでしょうか。
答えは、あまり気持ちのいいものではありません。robots.txt が今も機能しているのは、公開されていて、安価で、機械可読で、しかもクローラーにすでに理解されているからです。同時に、本来想定されていた以上の役割も背負わされています。2026年には、同じプレーンテキストファイルの中に、SEO のクロール制御、サイトマップのインデックス、レガシーな検索エンジン向け拡張、AI 学習の拒否、Cloudflare が注入するポリシー語彙、著作権の留保、さらに将来の紛争を見据えた法的文言まで入っていることがあります。
それが構成負債です。
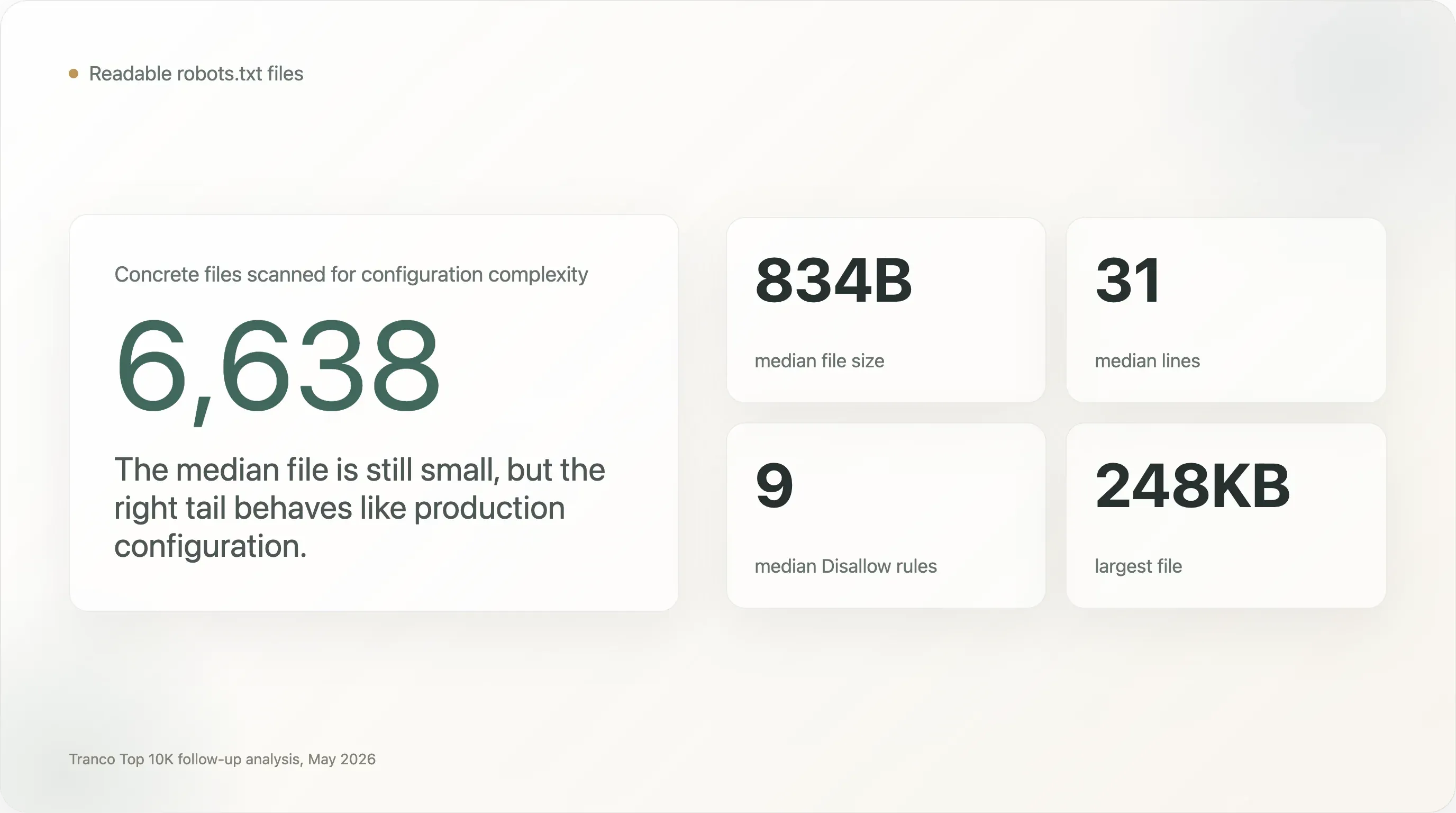
このレポートの基盤データは、元の AI クローラー調査で使った Tranco Top 10,000 のクロール結果と同じです。10,000 ドメインのうち 6,638 ドメインが読み取り可能な robots.txt を返し、さらに 610 ドメインは 404 を返しました。プロトコル上、404 は暗黙の許可として扱われます。これにより、ボットのアクセス可否の分析対象は 7,248 サイト、構成複雑度の分析対象は 6,638 の実ファイルになります。
際立つ発見は 6 つあります。
-
ほとんどの
robots.txtは小さい一方で、右側の裾は非常に複雑です。 中央値はわずか 834 バイト、31 行です。しかし 1,005 ファイルは 5 KB 以上、273 ファイルは 20 KB 以上、28 ファイルは 100 KB 以上あります。サンプル中の最大ファイルは 248 KB です。 -
上位サイトの何百件もが、ポリシーノートというより本番設定に近いファイルを運用しています。 中央値のファイルには
Disallowディレクティブが 9 個あります。しかし 707 サイトは少なくとも 100 個のDisallowルールを持ち、13 サイトは少なくとも 1,000 個を持ち、240 サイトは少なくとも 50 個のユーザーエージェント名を持ち、110 サイトは少なくとも 100 個のユーザーエージェント名を持っています。 -
プロトコルの逸脱は理屈の上だけの話ではありません。 読み取り可能な 6,638 ファイルのうち、685 件に
Crawl-delay、303 件にHost、200 件にClean-param、9 件にRequest-rate、5 件にVisit-time、271 件に Cloudflare 風のContent-Signalが含まれます。これらはすべて、同じ整った標準の一部ではありません。積み重なったクローラーの慣習です。 -
Googlebot は特別扱いされています。 分析対象 562 ドメインは、少なくとも 1 つの従来型検索クローラーをブロックしています。そのうち 404 件では、Googlebot は許可されている一方で、少なくとも 1 つの他の検索クローラーがブロックされています。AI クローラーの差別は中立的な生態系の中で突然現れたわけではなく、
robots.txtにはすでに検索エンジンの階層が組み込まれていました。 -
AI ポリシーによって、その負債はより見えやすくなります。 読み取り可能なファイル 1,377 件に AI ポリシー関連の文言があり、719 件に著作権、利用規約、ライセンス、許可に関する文言があり、501 件にはその両方があります。ファイルは機械とのインターフェースであると同時に法的アーティファクトにもなりました。それは便利ですが、脆いです。
-
最もリスクが高いファイルが、必ずしも最も反 AI 的なファイルとは限りません。 EC、旅行、ソーシャル、金融、学術、ニュースはいずれも、異なる理由で複雑なファイルを生みます。クロール予算の制御、レガシーなパス、ユーザー生成コンテンツ、権利の留保、ボット別の例外です。AI ルールは、すでに混乱した土台の上に積み重ねられています。
主な結論は次のとおりです。robots.txt は依然として公開ウェブで最も重要なクローラーポリシーの表面ですが、クローラーの識別、AI 利用の語彙、ポリシーの監査可能性がエコシステム全体で標準化されない限り、高リスクな AI ガバナンスの土台としては弱いままです。
方法論
このレポートは、Tranco Top 10,000 ドメインにおける AI クローラーポリシーを分析した元の Thunderbit 調査のデータセットを再利用しています。
入力資料は次のとおりです。
tranco_top10k.csv— 元の Tranco Top 10K ドメイン一覧。out/fetch_meta.csv— フェッチ状態、バイト数、スキーム、リダイレクト結果、エラーメタデータ。out/sites.csv— ドメイン、順位、カテゴリ、言語、robots.txtの状態。out/site_meta.csv— サイトごとの分析行。テンプレート分類、AI ブロックフラグ、ファイルサイズ、ボットポリシー要約フィールドを含みます。out/bot_status.csv— ドメインとクローラーごとの 1 行。各ボットがブロックされているか、特定ルールが存在するかを含みます。raw_robots/— ステータス200を返した 6,638 サイトのrobots.txt本文をキャッシュしたもの。
今回の続編では、読み取り可能な各 robots.txt ファイルについて次をスキャンしました。
- ファイルサイズと行数
- アクティブな非コメント行
User-agent、Disallow、Allow、Sitemapのディレクティブ数Crawl-delay、Host、Clean-param、Request-rate、Visit-timeなどのレガシーまたは非コアのディレクティブContent-Signal、llms.txt、AI、LLM、機械学習、TDM、2019/790を含む AI 時代の語彙- 著作権、利用規約、ライセンス、許可、権利留保の文言といった法的語彙
- Googlebot、Bingbot、DuckDuckBot、Slurp、Baiduspider、YandexBot に対する検索クローラーの扱い
また、このレポートではトリアージ用の簡易な構成負債スコアも定義しています。これは、ファイルサイズ、ユーザーエージェント数、Disallow 数、Allow 数、非標準ディレクティブ数、そして AI ポリシー文言と法的文言の混在を組み合わせたものです。このスコアは、正しさを測る普遍的な指標を意図したものではありません。保守、レビュー、解釈が難しくなりそうなファイルを見つけるためのものです。
派生テーブルとチャートはすべて納品フォルダに含まれています。
発見 1: 中央値のファイルは単純だが、裾はそうではない
上位ウェブにある典型的な robots.txt ファイルは、今でも小さいままです。
読み取り可能な 6,638 ファイル全体では、次のようになります。
| 指標 | 中央値 | P90 | P95 | P99 | 最大値 |
|---|---|---|---|---|---|
| ファイルサイズ | 834 バイト | 6.7 KB | 15.8 KB | 76.0 KB | 248.3 KB |
| 行数 | 31 | 238 | 332 | 1,008 | 4,998 |
| アクティブ行数 | 23 | 198 | 282 | 837 | 4,998 |
User-agent ディレクティブ | 1 | 21 | 39 | 137 | 823 |
Disallow ディレクティブ | 9 | 103 | 176 | 422 | 4,997 |
Allow ディレクティブ | 1 | 17 | 33 | 69 | 890 |
この分布が重要なのは、robots.txt がしばしば、次のような小さな宣言だと見なされるからです。
1User-agent: *
2Disallow: /private/しかし、その認識は、トラフィックの多いウェブのかなりの部分では誤りです。
このデータセットでは、
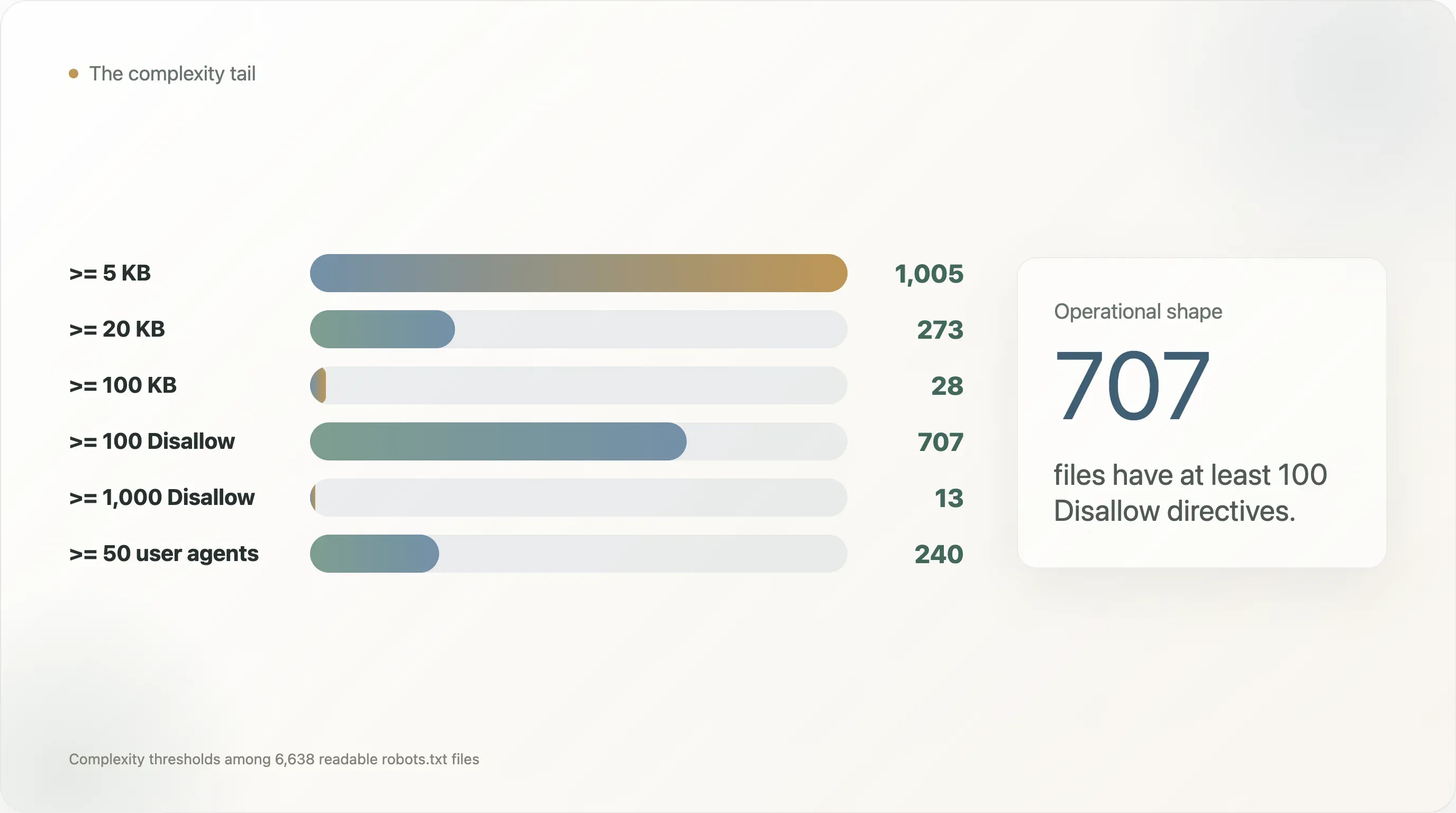
| 複雑度のしきい値 | サイト数 |
|---|---|
robots.txt が 5 KB 以上 | 1,005 |
| 20 KB 以上 | 273 |
| 100 KB 以上 | 28 |
User-agent ディレクティブが 50 個以上 | 240 |
User-agent ディレクティブが 100 個以上 | 110 |
Disallow ディレクティブが 100 個以上 | 707 |
Disallow ディレクティブが 1,000 個以上 | 13 |
Allow ディレクティブが 100 個以上 | 40 |
最大かつ最も複雑なファイルは、学術的な珍品ではありません。実際にトラフィックの多い資産に属しています。
| ドメイン | 順位 | カテゴリ | バイト数 | User-agent | Disallow | Allow |
|---|---|---|---|---|---|---|
linkedin.com | 17 | social | 114,341 | 76 | 4,184 | 281 |
runescape.com | 5,226 | unknown | 113,393 | 1 | 4,997 | 0 |
academia.edu | 832 | academia | 57,384 | 63 | 2,044 | 227 |
etsy.com | 286 | ecommerce | 51,320 | 3 | 1,621 | 120 |
thepaper.cn | 9,395 | news | 56,867 | 1 | 1,496 | 0 |
opentable.com | 4,137 | unknown | 70,494 | 32 | 1,683 | 176 |
alfabank.ru | 2,625 | finance | 73,158 | 2 | 1,566 | 133 |
これらのファイルは、ポリシースローガンというより本番のルーティング表に近いものです。何年にもわたる製品公開、レガシーなパス、ブロックされたパラメータパターン、クローラー例外、SEO 実験、CDN の判断、そして今では AI クローラーのルールまでをエンコードしています。
裾の大きさは AI だけの話ではありません。20 KB 以上の 273 ファイルのうち、131 件には AI ポリシー文言があり、142 件にはありません。少なくとも 100 個の Disallow ディレクティブを持つ 707 ファイルのうち、AI ポリシー文言があるのは 207 件だけです。つまり、AI が大きなファイル問題を作り出したのではありません。何年も前から普通のウェブ運用が、パスルール、サイトマップ参照、クローラー例外でファイルを埋めていたのです。
重要なのは、保守性は意図だけでなく形状に依存するということです。直接的な AI ブロックだけを持つ小さなファイルは、監査しやすいかもしれません。70 KB の EC や旅行のファイルは、AI について何も書いていなくても監査が難しいことがあります。リスクは、巨大ファイルがすべて間違っていることではありません。実効ポリシーが、担当者にとって確認しきれないほど複雑になってしまうことです。
運用上のリスクは明快です。robots.txt が大きくなるほど、公開者、プラットフォームエンジニア、法務、SEO リードが、次の基本的な問いに答えにくくなります。このファイルは実際に何を許可しているのか。
その問いは、もはや自明ではありません。RFC 風のパースでは、クローラーは User-agent: * よりも具体的なユーザーエージェントグループを優先してマッチすることがあります。より長いパスの一致は短い一致を上書きしうるため、Allow と Disallow は優先順位で相互作用します。汎用的な全面禁止ルールは、そのファイルが書かれた時点では存在していなかった新しいクローラーを、意図せず巻き込むこともあります。
30 行のファイルなら、人間でも考えられます。4,000 行で、何十もの名前付きボットが並ぶファイルなら、誰もそうすべきではありません。
発見 2: robots.txt はクロール規則以上のものを背負っている
AI クローラーをめぐる議論によって robots.txt は政治的に目立つようになりましたが、基盤にあるファイルはすでに無関係な責務を積み上げていました。
現代の主要サイトの robots.txt には、次のようなものが入りえます。
- クローラーパスの制御
- サイトマップの発見
- 検索エンジン固有の拡張
- クロール速度のヒント
- ホスト正規化のヒント
- URL パラメータ整理のヒント
- CDN が注入したポリシー語彙
- 著作権留保の文言
- AI 学習の拒否
- 人間向けの法的コメント
データセットは、このレイヤーの積み重なりをはっきり示しています。
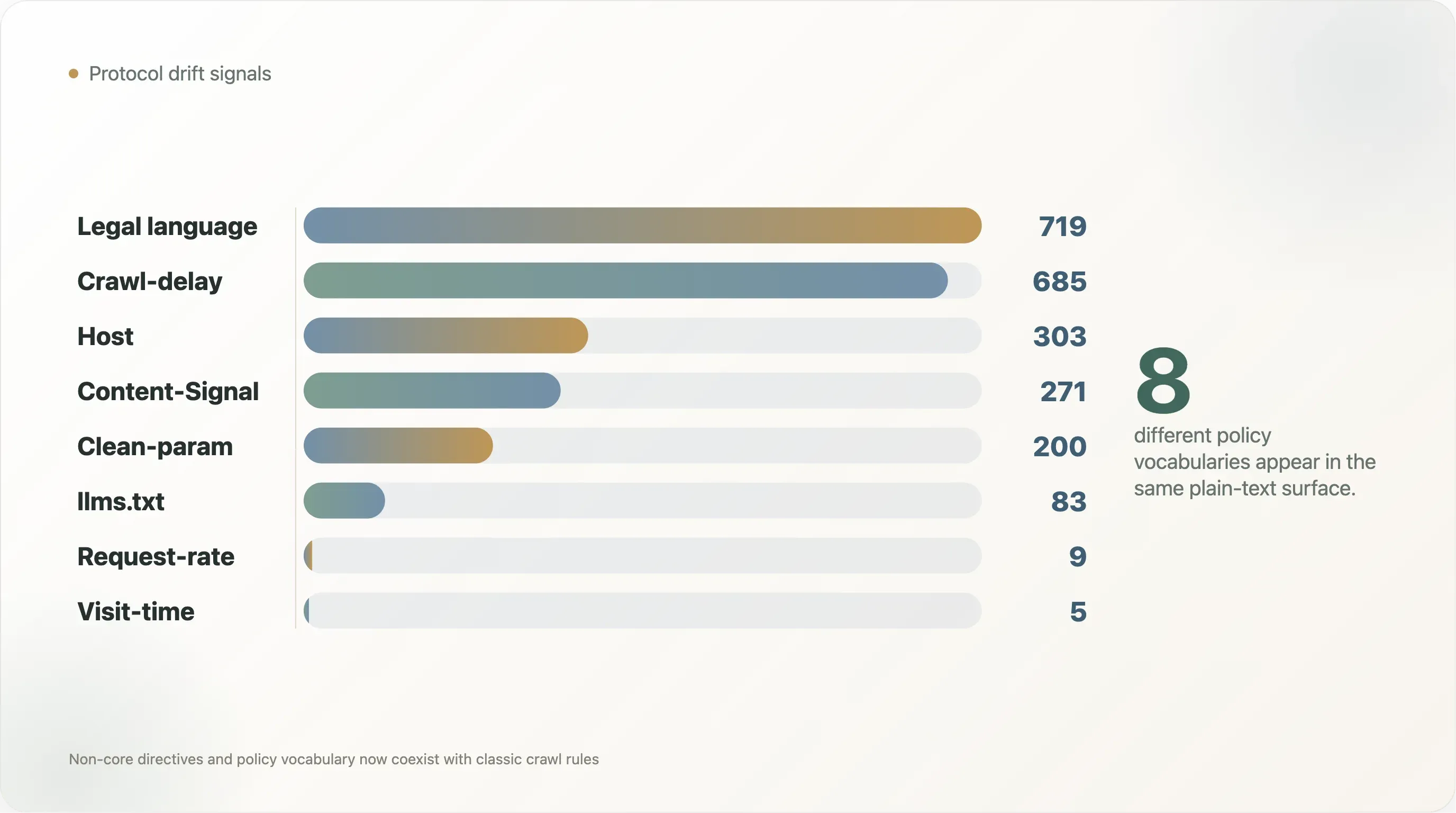
| シグナル | ファイル数 | 読み取り可能ファイルに占める割合 |
|---|---|---|
Crawl-delay | 685 | 10.3% |
Host | 303 | 4.6% |
Clean-param | 200 | 3.0% |
Content-Signal | 271 | 4.1% |
Request-rate | 9 | 0.1% |
Visit-time | 5 | 0.1% |
llms.txt への言及 | 83 | 1.3% |
| 著作権、利用規約、ライセンス、許可に関する文言 | 719 | 10.8% |
| AI ポリシー文言 | 1,377 | 20.7% |
これらのディレクティブのいくつかは、特定のクローラーには広く認識されています。いくつかはレガシーな慣習です。いくつかはベンダー固有です。いくつかは、実際にはクローラーディレクティブではなく、コメントに埋め込まれた法務文言や製品文言です。
これがプロトコルの逸脱です。
Crawl-delay は分かりやすい例です。多くのサイト運営者にはなじみがありますが、大手クローラー間での対応は不均一です。Host と Clean-param は、歴史的に Yandex の挙動と結びついてきました。Content-Signal は Cloudflare の AI 時代のポリシー語彙の一部です。llms.txt は隣接する探索フォーマットとして提案されたもので、普遍的に尊重される標準ではありません。それでもこれらは、クラシックな User-agent と Disallow ルールの隣に、しばしば同じファイル内に現れます。
数字は、古い慣習と新しい慣習がいま共存していることも示しています。Crawl-delay は 685 ファイルにあり、Content-Signal の 271 ファイルの 2 倍以上です。Host は 303 ファイル、Clean-param は 200 ファイルにあり、主に検索時代の慣習を反映しています。AI 検索界隈で盛んに議論されているにもかかわらず、llms.txt が言及されている読み取り可能ファイルは 83 件にすぎません。生きたウェブは 1 つの語彙へ収束していません。語彙を積み重ねているのです。
問題は、どれか 1 つの拡張が間違っていることではありません。問題は、そのファイルが、複数の重なるガバナンス体系のための、版管理されていない容器になっていることです。
それによって 3 種類の負債が生まれます。
- 意味論的負債。 クローラーによって同じファイルの解釈が異なることがあります。
- 所有権の負債。 SEO、法務、インフラ、セキュリティ、プロダクトの各チームに編集理由はあっても、ポリシー全体を所有するチームが存在しないかもしれません。
- 監査の負債。 サイトは意図的に見えるポリシーを公開していても、実際の挙動を決めるのはパーサーだけです。
AI がこれをより重要にするのは、賭け金が変わったからです。レガシーなクロール速度のヒントが無視されると、結果は余分なトラフィックかもしれません。AI 学習の拒否が曖昧だと、著作権やライセンスの紛争における証拠になりうるのです。
発見 3: このファイルは機械とのインターフェースであると同時に法的アーティファクトになった
元の AI クローラーレポートでは、分析可能なサイトの 17.0% が AI 専用の明示的ルールを書いていることが示されました。今回の続編では、それらのポリシーが追加するテキスト上の負担を見ます。
読み取り可能な robots.txt ファイル 6,638 件のうち、
- 1,377 件に AI ポリシー文言があり
- 719 件に著作権、利用規約、ライセンス、権利、許可に関する文言があり
- 271 件に
Content-Signalがあり - 83 件に
llms.txtへの言及があります
重なりを見ると、さらに面白くなります。
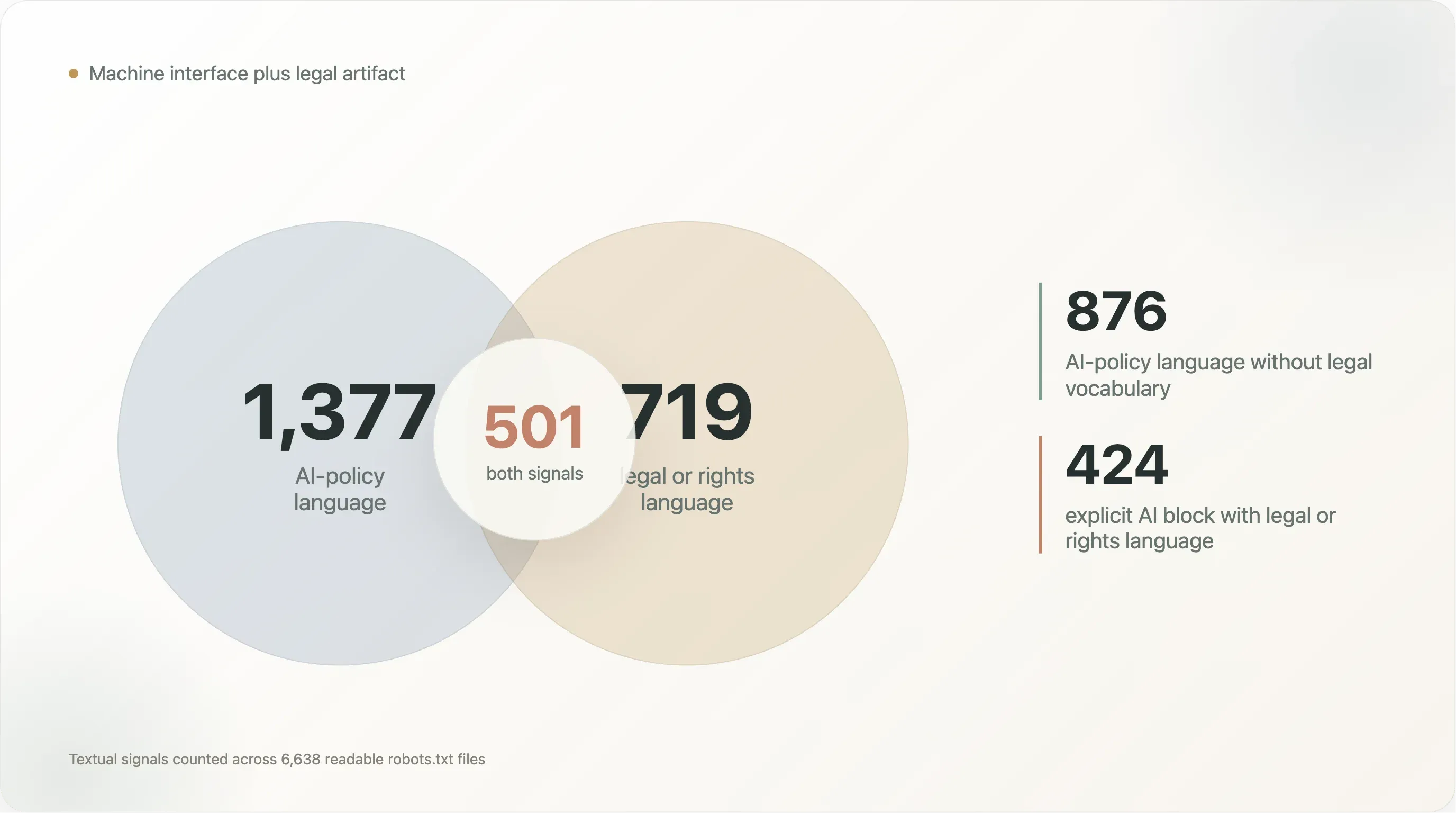
| テキストパターン | ファイル数 |
|---|---|
| AI ポリシー文言と法的/権利文言の両方 | 501 |
| 法的/権利文言はあるが AI ポリシー文言はない | 218 |
| AI ポリシー文言はあるが法的/権利文言はない | 876 |
法的/権利文言を伴う Content-Signal | 242 |
| 明示的な AI ブロックと法的/権利文言 | 424 |
これは新しい種類のファイルです。
従来の robots.txt はクローラー宛てです。法的な前文を含む robots.txt は、少なくとも 4 つの対象に同時に向けられています。
- 機械可読なディレクティブを必要とするクローラー運営者
- ポリシーのシグナルを必要とする検索・AI ベンダー
- 権利留保を明示したい法務担当者
- 意図の証拠としてコメントを読むかもしれない将来の監査人、裁判所、記者
この多重オーディエンス設計が、一部のファイルをいまやポリシー文書のように読ませる理由です。しかし同時に、クローラーが解析できるものと、人間の法務担当者が宣言したいものとのきれいな分離を弱めます。
AI ポリシー文言はあるが法的語彙はない 876 ファイルの多くは、機械向けポリシーファイルです。ボット名、Disallow ブロック、テンプレート文言が中心です。AI と法的文言の両方がある 501 ファイルは別物です。クローラー指示と権利留保を同時に行おうとしています。法的文言はあるが AI 語彙はない 218 ファイルは、このパターンが LLM で始まったものではないことを示しています。robots.txt はすでに、利用条件、許可の境界、権利主張を述べる場所として使われていたのです。
たとえば、コメントには機械学習を禁止すると書かれているのに、実際のディレクティブブロックは既知のユーザーエージェントの一部しか禁止していない、ということがあります。あるサイトは全体として権利を主張しつつ、いくつかのクローラー名しか挙げないかもしれません。CDN のテンプレートが、運用者が手で書いていない法的文言に AI 関連語彙を注入することもあります。サイトは広い User-agent: * ルールを書き、新しいクローラーを意図せずブロックしてしまうこともあります。
ガバナンスの観点から見ると、robots.txt は公開されていて機械可読であるがゆえに魅力的になりました。しかし、そこに載るポリシーが増えるほど、その限界が問題になります。
- ある特定のポリシーが、権利者によって確認されたものなのか、それともインフラから継承されたものなのかを示す認証層がありません。
- ネイティブな版管理がありません。
- 学習、取得、検索インデックス、要約、キャッシュ、モデル評価といった意図された用途を示す構造化フィールドがありません。
- AI クローラーの識別子に関する普遍的なレジストリがありません。
- 強制力がありません。
だからといって、このファイルが無意味になるわけではありません。脆弱になるのです。
より適切な解釈は、robots.txt が通知レイヤーになりつつあるということです。つまり、好みと意図を公開し、検査可能に示す層です。それ自体では完全な権利管理システムではありません。
発見 4: AI が来る前から、検索はすでに平等ではなかった
元のレポートの最も強い発見の 1 つは、多くの公開者が AI 学習クローラーと検索クローラーを区別していることでした。CCBot、GPTBot、Google-Extended をブロックしつつ、Google 検索の可視性は保つのです。
今回の続編は、別の点を加えます。従来の検索クローラー同士も、平等に扱われていないということです。
確認した検索クローラーは 6 つです。
- Googlebot
- Bingbot
- DuckDuckBot
- Slurp
- Baiduspider
- YandexBot
分析可能な 7,248 サイト全体では、
| 検索クローラーの扱い | サイト数 |
|---|---|
| 少なくとも 1 つの検索クローラーをブロック | 562 |
| Googlebot は許可しつつ、少なくとも 1 つの他の検索クローラーをブロック | 404 |
| 確認した 6 つすべての検索クローラーをブロック | 152 |
ブロックされたボット数は均等に分布していません。
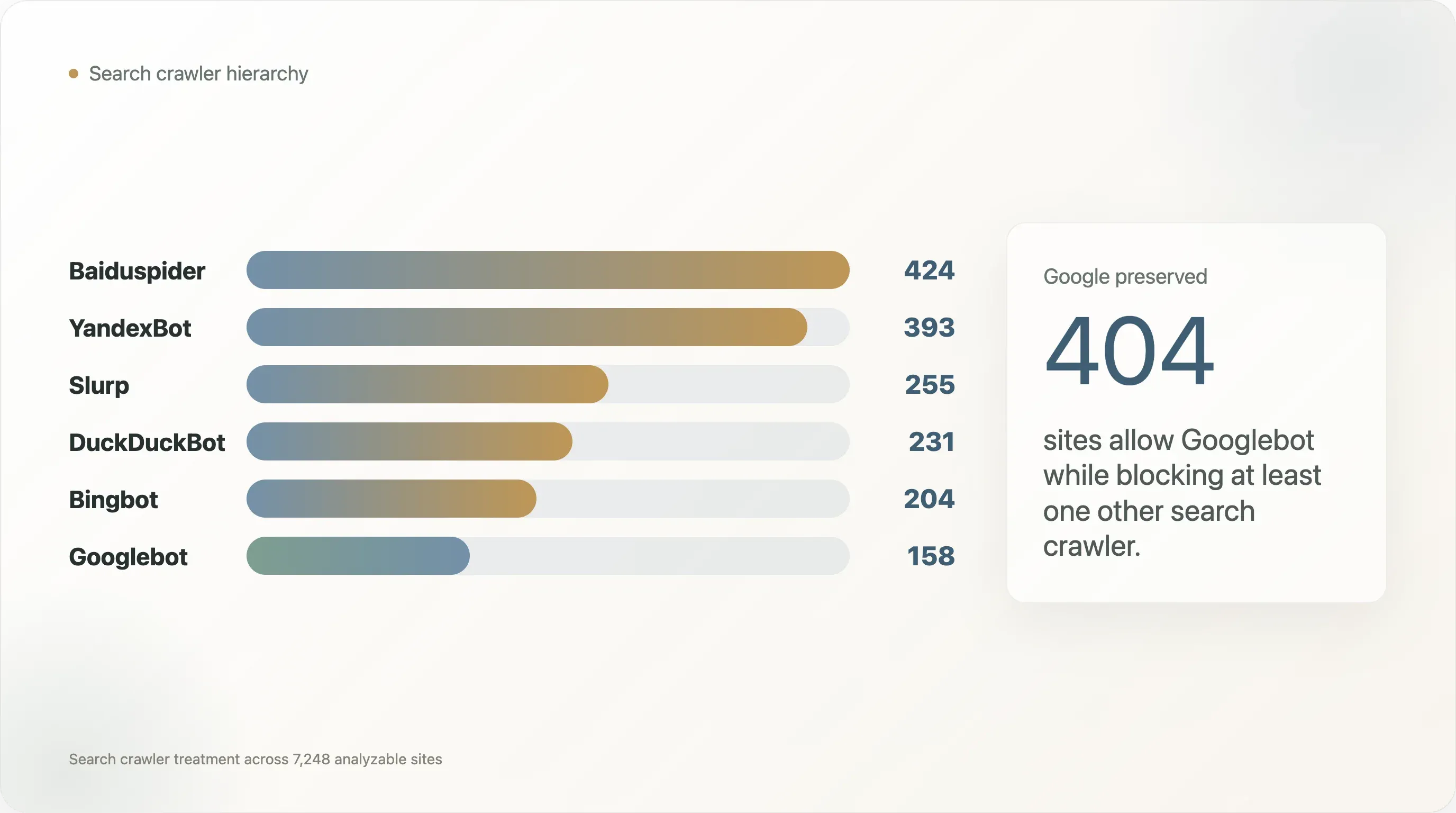
| 検索クローラー | ブロックしているサイト数 |
|---|---|
| Baiduspider | 424 |
| YandexBot | 393 |
| Slurp | 255 |
| DuckDuckBot | 231 |
| Bingbot | 204 |
| Googlebot | 158 |
このセットでは、Googlebot が最もブロックされにくいクローラーです。Baiduspider と YandexBot ははるかに頻繁にブロックされ、その多くで Googlebot は許可されたままです。Googlebot を許可しつつ別の検索クローラーをブロックしている 404 サイトのうち、269 件は Baiduspider を、240 件は YandexBot をブロックしています。
高い知名度の例もあります。
| ドメイン | Googlebot は許可しつつブロックされている検索クローラー |
|---|---|
facebook.com | Baiduspider, YandexBot |
apple.com | Baiduspider |
twitter.com | DuckDuckBot, Slurp, Baiduspider, YandexBot |
netflix.com | DuckDuckBot, Slurp |
x.com | DuckDuckBot, Slurp, Baiduspider, YandexBot |
tiktok.com | Baiduspider |
baidu.com | Bingbot, DuckDuckBot, Slurp, YandexBot |
washingtonpost.com | YandexBot |
wsj.com | YandexBot |
bilibili.com | DuckDuckBot, Slurp, YandexBot |
temu.com | Slurp |
t-mobile.com | Baiduspider, YandexBot |
これは AI 論争にとって重要です。LLM クローラーが来る前から、robots.txt は中立的なユニバーサルアクセスのプロトコルではなかったことを示しているからです。公開ウェブにはすでに階層がありました。
- Googlebot は、多くの場合、Google 検索トラフィックを失うリスクが大きすぎるため保護されます。
- 地域別や競合のクローラーは、より簡単にブロックされます。
- 一部のサイトでは、検索クローラーへのアクセスを市場別またはベンダー別の判断として扱っています。
AI クローラーは、差別化されたアクセスがすでに当たり前だったエコシステムに入ってきたのです。
そのため、このポリシー転換は理解しやすくなります。公開者が「Google-Extended はブロック、Googlebot は許可」と書くのは、新しい差別の形を発明しているわけではありません。配信は維持し、抽出は制限するという、古いパターンを新しいクローラー種別に当てはめているだけです。
未解決なのは、この古いパターンがどこまで拡張できるかです。検索では、経済的に重要なクローラーは数えるほどしかありませんでした。AI では、クローラーの識別はモデルベンダー、検索取得ボット、データブローカー、学術クローラー、合成ブラウザエージェント、インフラ層のフェッチャーにまで断片化しています。目的ベースのシグナルよりも名前付きユーザーエージェントに依存し続ける限り、その数は増え続けるでしょう。
それが構成負債の複利です。
発見 5: 複雑さはセクターによって異なるが、AI ブロック率の違いとは一致しない
元のレポートでは、AI ブロックに大きなセクター差があることが示されました。ニュースは高い割合でブロックし、通信、政府、SaaS は低い割合でした。
構成の複雑さは、別の切り口でウェブを分けます。
十分な読み取り可能な robots.txt があり、比較に耐える主要カテゴリでは、次のようになります。
| カテゴリ | n | 中央値バイト数 | P90 バイト数 | 中央値 Disallow | P90 Disallow | 中央値 User-agent | P90 User-agent |
|---|---|---|---|---|---|---|---|
| ecommerce | 215 | 1,738 | 10,388 | 37 | 164 | 3 | 49 |
| travel | 63 | 2,074 | 27,368 | 41 | 779 | 5 | 34 |
| news | 647 | 1,534 | 7,039 | 19 | 114 | 6 | 68 |
| finance | 121 | 1,002 | 8,337 | 17 | 132 | 2 | 23 |
| academia | 253 | 839 | 3,959 | 14 | 75 | 1 | 11 |
| government | 151 | 1,227 | 3,263 | 13 | 46 | 1 | 4 |
| SaaS | 368 | 485 | 12,606 | 4 | 56 | 1 | 10 |
| dev tools | 119 | 273 | 9,255 | 3 | 58 | 1 | 10 |
カテゴリ別 P90 Disallow のチャートをここに挿入<<<<<<<<<<<<<<<<<<<<<<<<<
ニュースは、明示的な AI ルールと法的文言を書くため、政治的には複雑です。しかし ecommerce と travel は、大量の商品/施設カタログ、ファセットナビゲーション、検索結果ページ、フィルター、アカウント用パス、パラメータ付き URL を抱えているため、運用上複雑です。
この違いは重要です。
旅行はその最も分かりやすい例です。このカテゴリの切り出しでは読み取り可能ファイルが 63 件しかありませんが、P90 の robots.txt は 27.4 KB、P90 の Disallow 数は 779 で、ニュースを大きく上回ります。これは、旅行サイトの AI ポリシーがより成熟しているという意味ではありません。日付検索、空室/空席ページ、レビューのページ分割、予約フロー、フィルター組み合わせ、地域別在庫パスなど、クローラー運営者が誤ってクロール予算を浪費しやすい面が多いということです。
SaaS は逆の驚きです。中央値のファイルはわずか 485 バイトですが、P90 のファイルは 12.6 KB に跳ね上がります。大半の SaaS サイトは開放的で軽量ですが、一部は長いパス制御ファイルを持っています。ドキュメント、ログイン面、アプリのルート、マーケティングページが同じドメイン下にあるためです。
ニュースは運用上は中間に位置しますが、政治的には上位です。この表では P90 の User-agent 数が 68 と、ecommerce、travel、finance、academia、government、SaaS、dev tools より高い値です。これは、単なるパス整備ではなく、ボット固有ポリシーの存在を示しています。
公開者の robots.txt は、権利ポリシーのために複雑になっていることがあります。マーケットプレイスのファイルは、クロール予算管理のために複雑になります。大学のファイルは、何千ものレガシーなパスが 1 つのドメイン下に積み上がった結果として複雑になります。ソーシャルプラットフォームのファイルは、膨大な規模で一部の面を公開し、他を抑制しなければならないため複雑になります。
AI ポリシーはそのすべての上に載ります。既存の複雑さの理由を置き換えるものではありません。
これにより、AI 時代の robots.txt ガバナンスが、万能のブロックリストでは解けない理由も説明できます。基盤となるファイルの役割が違うのです。
- ecommerce サイトは重複パスと在庫面を管理します。
- travel サイトは一覧、カレンダー、レビュー、動的検索ページを管理します。
- news サイトは著作権、アーカイブ、ライセンスの姿勢を管理します。
- SaaS と開発ツールのサイトは、しばしば AI による可視性を望みます。
- 政府機関は公開アクセスが必要な一方で、排除すべき機微システムがある場合もあります。
- ソーシャルプラットフォームは、ユーザー生成コンテンツ、プロフィール面、悪用対策を管理します。
同じ AI クローラールールでも、環境ごとに意味は異なります。
発見 6: 構成負債インデックスは、道徳的失敗ではなくレビューリスクを示す
この分析では、レビューが難しそうな robots.txt ファイルを識別するために、簡単な構成負債スコアを作成しました。
このスコアが重み付けするのは次の要素です。
- ファイルサイズ
User-agentディレクティブ数Disallowディレクティブ数Allowディレクティブ数- 非コアディレクティブ数
- AI ポリシー文言の有無
- 明示的な AI ブロックと法的または著作権文言の混在
これは正しさのスコアではありません。複雑なファイルが完全に意図どおりであることもあります。単純なファイルが間違っていることもあります。目的はトリアージです。ファイルが大きく、ポリシー色が強く、ボット固有で、例外だらけなら、より厳密なレビューが必要だということです。
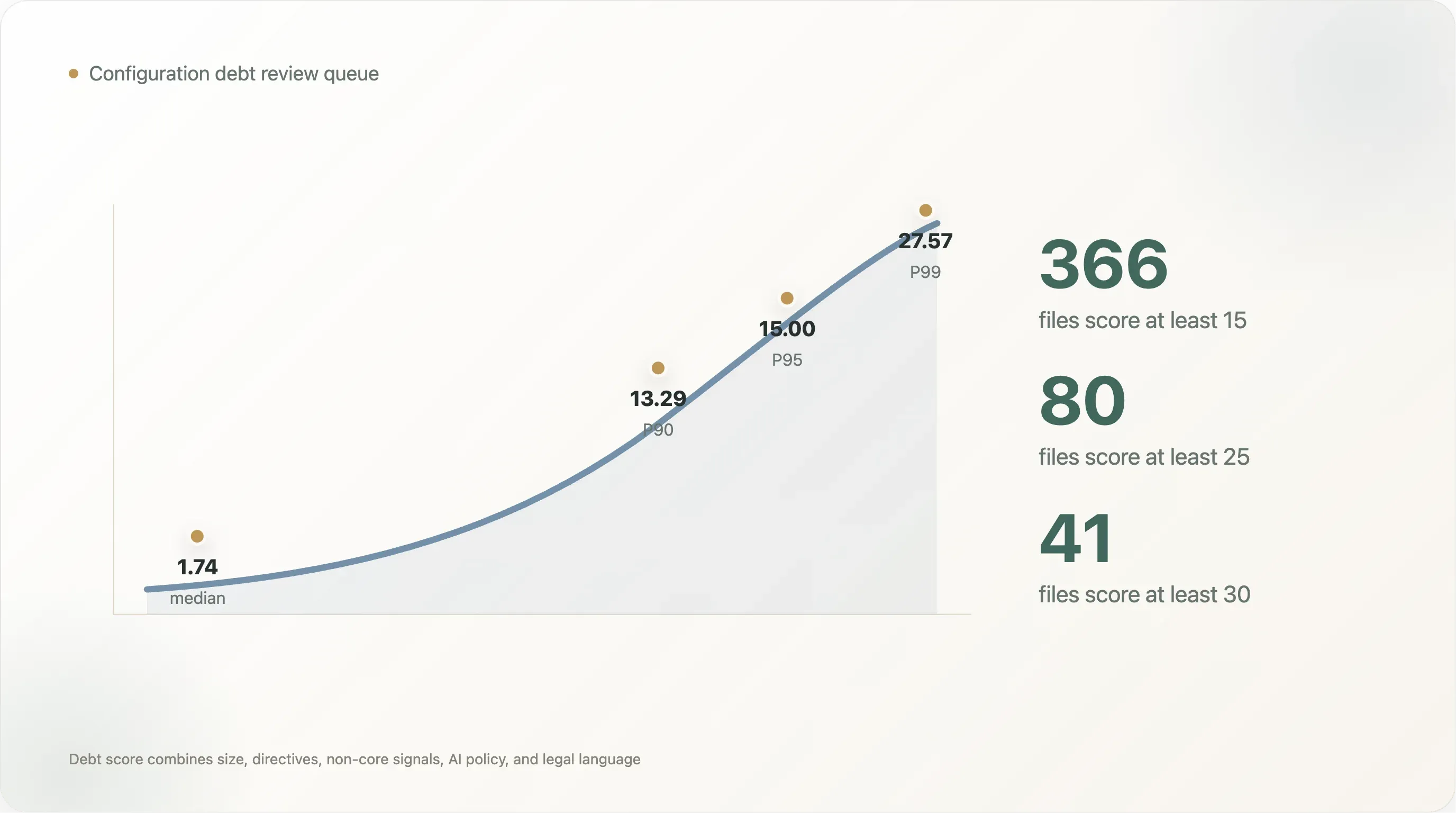
スコア分布は急です。読み取り可能ファイルの中央値スコアは 1.74、P90 は 13.29、P95 は 15.00、P99 は 27.57 です。スコアが 15 以上のファイルは 366 件、25 以上は 80 件、30 以上は 41 件しかありません。これが実際のレビューキューです。すべてのサイトにガバナンスプロジェクトが必要なわけではありませんが、上位裾は必要です。
カテゴリ別に見ても、単一の「AI ブロッカー」というラベルが平板すぎる理由が分かります。
| カテゴリ | 中央値スコア | P90 スコア |
|---|---|---|
| travel | 4.92 | 28.94 |
| search | 2.97 | 24.23 |
| social | 2.25 | 15.00 |
| news | 4.91 | 14.92 |
| finance | 1.67 | 12.61 |
| SaaS | 0.98 | 11.85 |
| ecommerce | 3.88 | 10.87 |
| government | 1.57 | 6.38 |
travel と search は、少数のファイルが非常に大きく、ルールだらけになるため、P90 スコアが最も高くなります。news はカテゴリ全体でポリシー文言とボット固有の扱いが多いため、中央値スコアが最も高い部類に入ります。ecommerce は Disallow の中央値が高いものの、P90 の負債スコアは travel より低いです。複雑さが、混在したポリシー/法務シグナルよりも、パスルールに集中しているからです。
このデータセットで最も高スコアのファイルには、次のようなものがあります。
| ドメイン | 高スコアの理由 |
|---|---|
linkedin.com | 非常に大きいファイル、何千ものパスルール、多数の名前付きユーザーエージェント、明示的な AI ポリシー文言 |
lnkd.in | LinkedIn の短縮リンク基盤と同じポリシー面 |
fragrantica.com | 何百もの名前付きユーザーエージェントブロックと AI ポリシー文言 |
sovcombank.ru | 何百ものユーザーエージェントブロックと法的/ポリシー文言 |
academia.edu | 大規模な allow/disallow マトリクスと明示的な AI ブロックポリシー |
opentable.com | 大規模なパスルールセット、多数のサイトマップディレクティブ、AI 関連ポリシー面 |
etsy.com | 1,600 件超の Disallow ルールを持つ大規模な ecommerce パス制御ファイル |
runescape.com | 1 つのユーザーエージェントグループ下にほぼ 5,000 個の Disallow ディレクティブ |
複雑だからといって、これらのファイルを嘲笑すべきではありません。複雑さはしばしば実際のビジネス上の要請を反映しています。しかし同時に、robots.txt ポリシーにも他の本番設定と同じエンジニアリング規律が必要だということを示しています。
- 所有権を明示すること
- 変更をレビューすること
- 生成セクションにはラベルを付けること
- 可能なら法的コメントを機械ディレクティブから分離すること
- 重要なクローラーについて、期待どおりのボットアクセスをテストで検証すること
- 版履歴を保持すること
- 古いボット名は廃止するか文書化すること
- AI 学習、AI 取得、検索インデックス、アーカイブを別々の目的として扱うこと
最後の点が最も重要です。現在の文法はユーザーエージェント先行です。つまり、サイト運営者にボット名を挙げさせます。AI 時代に必要なのは目的先行です。つまり、どの用途が許可されるかを示させることです。
この 2 つは同じではありません。
その不一致こそが、長いブロックリストが長持ちしない理由です。公開者は今日 GPTBot、ClaudeBot、CCBot、Google-Extended、Bytespider、Applebot-Extended、PerplexityBot を追加できます。しかし次のクローラー名、取得エージェント、データセットブローカーは明日にも現れます。目的ベースのポリシーなら、robots.txt をボットのアドレス帳に変えることなく、「検索インデックスは可、AI 学習は不可、ユーザー起点の取得は場合による」と伝えられます。
AI ガバナンスにとって何を意味するか
公開された議論では、robots.txt は意味があるか、もはや時代遅れか、のどちらかとして語られがちです。データは、より実用的な答えを示しています。
robots.txt は意味がありますが、役割を背負いすぎています。
意味があるのは、主要サイトが実際に使っており、クローラーが解析でき、研究者、記者、ベンダー、裁判所にとってポリシーの選択が可視だからです。元のレポートでは、分析可能な上位サイトの 17.0% が意図的な AI 専用ルールを持っていました。これは象徴的なノイズではありません。
役割を背負いすぎているのは、このファイルがボットのアクセス以上のことを表現しなければならないからです。
- 「このコンテンツで学習しないでください」
- 「このコンテンツは検索インデックスに使ってもよい」
- 「このコンテンツはライブ取得に使ってもよい」
- 「キャッシュ済みデータセットは作成してはいけない」
- 「この法的留保は EU のテキスト・データマイニング法の下で適用される」
- 「この CDN 管理サイトは
Content-Signal: ai-train=noを送る」 - 「このサイトは Googlebot は欲しいが YandexBot は欲しくない」
- 「このサイトには、クロールしないでほしい旧 URL パスが 1,000 本ある」
この文法は、そこまで多くの役割のために設計されていませんでした。
負債を減らすには、3 つの変更が必要です。
-
クローラー識別子にレジストリが必要です。 サイト運営者が、
GPTBot、ClaudeBot、anthropic-ai、CCBot、Google-Extended、Applebot-Extended、Bytespider、OAI-SearchBot、ChatGPT-Userなど増え続ける一覧を自前で管理する必要があってはなりません。レジストリがなければ、ポリシーは常にクローラーの挙動に遅れます。 -
AI 利用には構造化された語彙が必要です。 学習、取得、インデックス、要約、データセット再販、モデル評価、ユーザー起点のブラウジングは、異なる用途です。ベンダー固有のユーザーエージェント名で表現するのは脆弱です。
-
ポリシーには監査可能性が必要です。 ウェブには、権利者が確認した手書きの権利留保と、継承された CDN デフォルト、生成された CMS テンプレート、古いレガシー規則、うっかり入った catch-all ブロックを区別する仕組みが必要です。その違いは、信頼にも訴訟にも関わります。
これは、robots.txt をすぐに置き換えるべきだという意味ではありません。より良い道筋は階層化です。robots.txt は発見と互換性の表面として残しつつ、AI 専用用途向けに隣接する機械可読ポリシーを標準化するのです。
llms.txt はその一つの試みですが、このデータセットでの採用はまだ非常に小さく、読み取り可能ファイルで言及されているのは 83 件 בלבדです。Content-Signal は Cloudflare がインフラ経由で配布できるため、より目立ちます。このスキャンで Content-Signal を含む 271 ファイルは、すべて AI ポリシー文言とも一致していました。それでも、配布されていることと合意されていることは同じではありません。持続的な解決策には、地味な標準化の仕組みが必要でしょう。明確なフィールド、明確な意味、クローラーのコミットメント、公開テストスイートです。
結論
AI クローラーをめぐる争いによって、robots.txt はガバナンスのアーティファクトになりました。それは便利でもあり、危険でもあります。
便利なのは、このファイルが公開されているからです。研究者は監査できます。公開者は変更できます。クローラーは従えます。裁判所は読めます。インフラ提供者は大規模に展開できます。
危険なのは、背負いすぎているからです。
Tranco Top 10K における中央値の robots.txt ファイルは、今でも理解できるほど小さいです。しかし、高トラフィックなウェブの裾には、大きく、古く、多層で、ベンダー固有で、法的含意の強いファイルがあふれています。何百ものサイトが、単純なクローラーヒントというより本番ポリシーシステムとして robots.txt を運用しています。
中心的な教訓は、robots.txt が失敗したということではありません。ウェブがそれをリファクタリングせずに昇格させたということです。
AI アクセス・ポリシーを機械可読な公開宣言に依存させるなら、次に必要なのは、さらに長いブロックリストではありません。より良いポリシー基盤です。目的ベースの許可、安定したクローラー識別、レビュー可能なテンプレート、監査ログです。
それまでは、公開ウェブの AI ガバナンス層は、これほどの重さを運ぶために作られたわけではないテキストファイルの上に置かれ続けるでしょう。
再現性に関する注記
納品フォルダには次のものが含まれます。
source_data/analysis.json— 元の集計指標。source_data/site_meta.csv— 元のサイト別分析テーブル。source_data/bot_status.csv— 元のドメイン×ボットのポリシーテーブル。source_data/fetch_meta.csv— 元のフェッチメタデータ。source_data/sites.csv— 元のドメイン/カテゴリ/状態テーブル。derived_data/robots_complexity_by_site.csv— このレポートのために生成したサイト別複雑度指標。derived_data/search_bot_treatment.csv— 検索クローラーの扱いマトリクス。derived_data/category_complexity_summary.csv— カテゴリ別複雑度サマリー。derived_data/top_config_debt_sites.csv— 上記のトリアージスコアで上位のサイト。derived_data/summary_metrics.json— このレポートで引用したすべての主要指標。
方法論の修正、データセットの問題、追加分析の提案は support@thunderbit.com まで歓迎します。このレポートは Thunderbit が持ついかなる商業的立場からも独立して公開されています。私たちは AI 搭載のウェブスクレイパーを開発しており、公開ウェブ上で robots.txt が意味のある機械可読な契約として存続することに構造的な利害を持っています。本レポートのデータはそれ自体で完結しています。— Thunderbit 研究チーム、2026年5月。