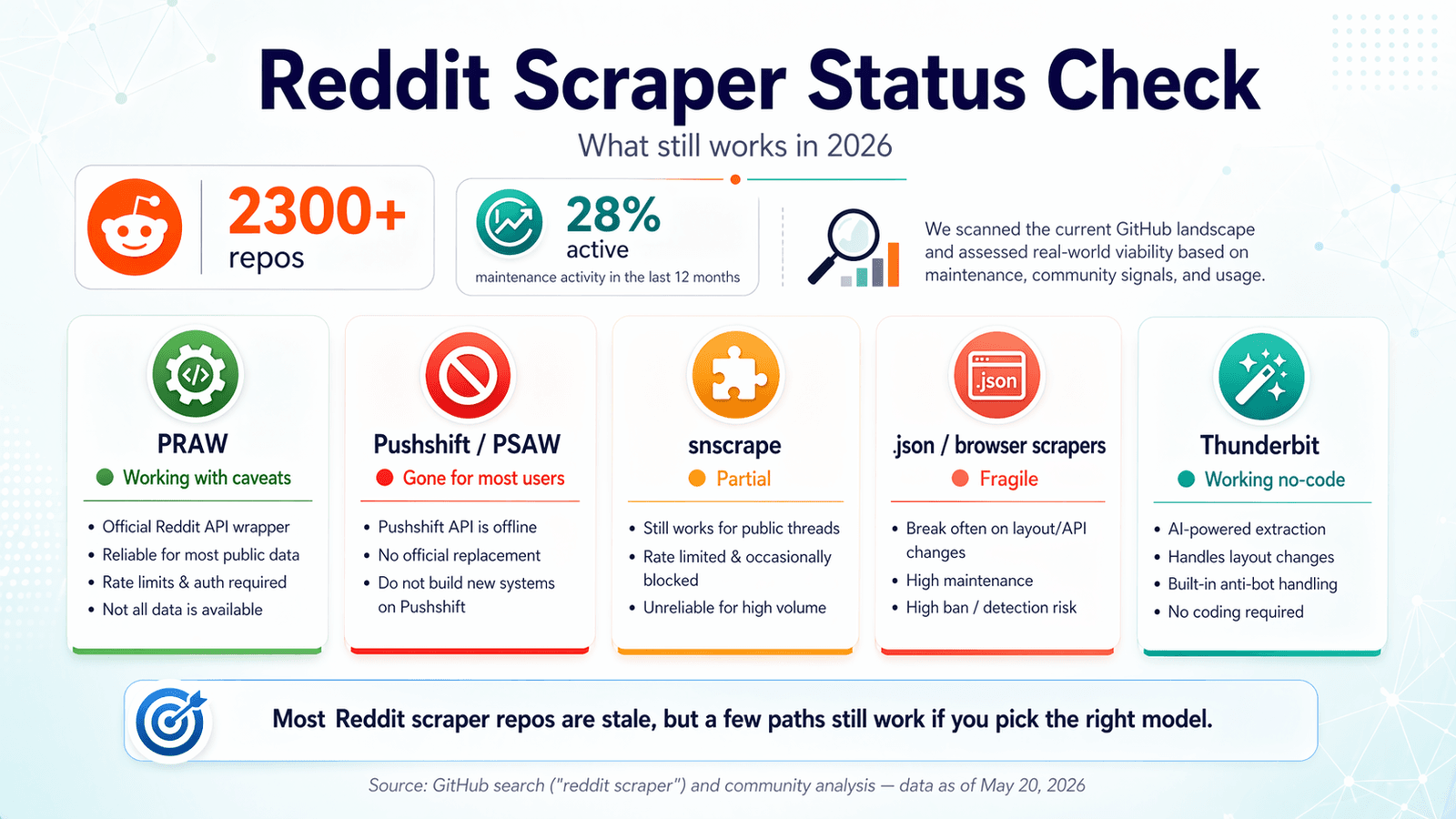
GitHubには今、が並んでいます。まるでビュッフェのようですが、落とし穴があります。直近12か月で何らかのメンテナンスが見られるのは、わずか約28%です。ここ数週間、私はこれらのリポジトリを掘り下げ、エンドポイントをテストし、Issueキューを読み、Reddit自身のポリシー更新と突き合わせてきました。目的は、リポジトリをクローンしてOAuthで苦戦し、真夜中になって「実は2024年にひっそり壊れていた」と気づく、そんな事態を防ぐことです。2026年のRedditスクレイパー GitHub事情は、善意の墓場に、ほんの一握りの本当に役立つツールが混ざっているような状況です。このガイドでは、まだ使えるもの、壊れたもの、コードを完全に見送るべき場面、そしてますます厳しくなるRedditの取り締まりにどう対応するかを解説します。近道を探しているなら、は、まさにこうした課題のために私たちが作ったノーコードの選択肢です。ただし、コードベースの解決策のほうが今でも理にかなう場面についても、率直にお話しします。
RedditスクレイパーのGitHubリポジトリとは何か、そしてなぜこんなに壊れているのか
「reddit scraper github」リポジトリは、通常、Redditから投稿、コメント、ユーザーデータ、メディアを自動取得するオープンソースのPythonプロジェクト(場合によってはJavaScript)です。大きく分けると、次の4系統に分類できます。
- APIラッパー(PRAWなど):Redditの公式APIを使い、OAuthが必要で、Redditのルールに従って動作します。
- Pushshift/PSAWベースのツール:過去データを取得するために、Pushshiftの大規模なRedditアーカイブを利用していました。
- 公開
.jsonエンドポイントのスクレイパー:RedditのURL末尾に.jsonを付けるか、認証なしで公開エンドポイントにアクセスします。 - ブラウザベースのスクレイパー:Playwright、Selenium、ブラウザ拡張機能を使ってRedditページを読み込み、描画済みコンテンツを抽出します。
では、なぜこんなに壊れたのでしょうか。理由は3つあります。
- 2023年半ばのReddit API料金体系の大改定。 無料APIの上限は、に引き下げられました。商用利用が多い場合は、1,000 APIコールごとに0.24ドルかかります。多くのリポジトリは、APIアクセスが実質無制限だった時代を前提に作られていましたが、その時代は終わりました。
- Pushshiftの公開アクセスが停止された。 Pushshiftは、Redditの過去データ研究を支える基盤でした。Redditがこれを制限したことで、多くの「過去データ用スクレイパー」系リポジトリは主要なデータソースを失いました。README上は今も生きているように見えても、一般ユーザーにとっては中身の依存先が消えています。
- Redditがポリシーと取り締まりの両方を強化した。 2024年のrobots.txt更新、2025年の、そして2026年3月のは、Redditがもはや大量スクレイピングを無害な背景ノイズとは見なしていないことを示しています。さらに、こともあります。
要するに、「reddit scraper github」で検索すれば何百件も出てきますが、最終更新日や未解決Issue数を見ると、事情はまったく違って見えます。
2026年版 Redditスクレイパー GitHub 状況チェック:何がまだ動くのか
競合記事の多くは2023年か2024年に書かれ、そのまま更新されていません。フォーラムでは、1年前には動いていたリポジトリで今もエラーに悩まされるユーザーが後を絶ちません。あるユーザーの叫びである「Reddit API limitation error で何度も止まるんだけど、どうすればいい?」は、2026年のRedditスクレイパー体験をほぼそのまま表しています。
私は2026年4月時点で鮮度チェックを行いました。結果は次のとおりです。
PRAW:公式Pythonラッパー
状態:✅ まだ動作、ただし条件付き。
(Python Reddit API Wrapper)は、今でもRedditスクレイピングの最も信頼できるオープンソース基盤です。現在も活発に保守されており、スター数は4,099、最終プッシュは2026年4月20日、未解決Issueは6件のみ、(2024年10月リリース)が掲載されています。
強み: 公式で、ドキュメントが整っており、Reddit APIの複雑さをかなり吸収してくれます。
2026年の制約:
- OAuth要件がさらに厳格化。承認された利用目的の説明を伴う、登録済みのRedditアプリが必要です。
- 2024年以降のレート制限が低下(OAuthありで毎分100クエリ、なしで10クエリ)。
- 約1,000件という一覧取得上限は依然として存在します。r/redditdev や Stack Overflow のコミュニティスレッドでも、各一覧エンドポイントでことが確認されています。
APIの枠内で運用できるなら、PRAWが最も安全です。
ただし、もはや自由形式の大量スクレイパーではありません。
公式APIルートの実践的な手順を知りたいなら、このチュートリアルがこの章にぴったりです。
Pushshift / PSAW:静かになったアーカイブ
状態:❌ 公開アクセスは終了。
は、かつて過去のRedditデータを取得する最も手軽な手段だったPushshift向けの定番Pythonラッパーでした。2026年現在、リポジトリはアーカイブされ、READMEには文字通り「THIS REPOSITORY IS STALE」と書かれています。最近の未解決Issueには、「Pushshift.io UNABLE to connect」や「The code not working. Possibly due to pushshift api.」といったものがあります。
学術アクセスは特定の経路を通じてまだ存在する可能性がありますが、今日「reddit scraper github」を探している一般ユーザーにとって、Pushshift/PSAWは現実的な選択肢ではありません。深い過去データが必要なら、承認済みの学術データアクセスか、ライセンス付きの経路を検討する必要があります。
snscrape(Redditモジュール):部分的・不安定
状態:⚠️ 部分的に動作 — 断続的に壊れ、ほぼ未保守。
は5,337スターありますが、最終プッシュは2023年11月15日です。READMEには今も、Redditスクレイピングは「via Pushshift」で対応していると書かれています。Reddit関連の未解決Issueには「Error reddit scraping」や「Reddit scraper returns no submissions before 2022-11-03」などがあり、最近の有効な修正活動は見られません。
環境によっては、小規模な単発取得なら動くこともありますが、本番運用や定期取得には信頼できません。レガシー扱いにしてください。
Playwright と .json エンドポイントのスクレイパー:うまくいく回避策(ただし時々)
状態:✅ 動作するが、壊れやすい。
考え方は単純です。ヘッドレスブラウザ(Playwright、Puppeteer)でRedditページを開いて描画済みコンテンツをスクレイピングするか、RedditのURLに.jsonを付けて、公式APIを使わずに構造化データを取得します。
強み: APIキー不要、1,000件上限を回避できる、描画済みコンテンツにアクセスできる。
弱み: RedditがフロントエンドのレイアウトやJSON構造を変えると壊れる、ボット対策に引っかかる可能性がある、技術的なセットアップが必要。私自身の今月のテストでは、公開Redditの.jsonエンドポイントへの直接リクエストは403を返しました。だからといって全環境でブロックされるわけではありませんが、.jsonの近道が「そのまま動く」と思い込むのは、もう危険です。
のようなリポジトリは、この点についてかなり正直です。READMEには、「ローテーションプロキシを使ってください。さもないと、RedditからIP banという贈り物が届くかもしれません」と警告があります。まさに2026年4月の状況を、一文で表しています。
ブラウザ自動化による回避策を評価しているなら、以下の章とあわせてこのPlaywrightチュートリアルを見ると理解しやすいです。
Thunderbit:AI搭載のブラウザスクレイピング(ノーコード、APIキー不要)
状態:✅ 動作中 — ページ変更にも自動対応。
は、根本的に異なるアプローチを取ります。これはで、AIがRedditページを読み取り、データ項目(投稿タイトル、著者、アップvotes、時刻、URLなど)を提案し、2クリックで構造化データを抽出します。OAuth設定も、APIキー登録も、Python環境も、依存関係管理も不要です。AIは毎回ページを新しく読み取るため、Redditがレイアウトを変えても、Thunderbitは黙って壊れるのではなく自動で追従します。
CSV、Google Sheets、Airtable、Notionへの無料エクスポートに対応。ページネーションやサブページのスクレイピングも処理できます(例:サブレディット一覧をスクレイピングし、各投稿を開いてコメントを取得する、など)。GitHubリポジトリを保守しながらRedditデータを取りたいわけではない人にとって、これが最も楽な道です。
(完全に開示すると、Thunderbitは私たちが作っているので、私は少し偏りがあります。ただし、コードベースの解決策のほうが今も理にかなう場面については、この後できちんと明確にします。)
状況比較サマリー表
| ツール / 分類 | 2026年4月時点でまだ動く? | APIキーは必要? | 備考 |
|---|---|---|---|
| PRAW | ✅ はい、ただし条件付き | はい(OAuth) | 最も保守されているオープンソース基盤。レート制限と1,000件上限の制約あり。 |
| Pushshift / PSAW | ❌ いいえ(大半のユーザーには) | 該当なし | 公開アクセスは終了。リポジトリはアーカイブ済み。 |
| snscrape(Redditモジュール) | ⚠️ 部分的 / 不安定 | いいえ | Redditを「via Pushshift」と記載したまま。2023年以降、保守が停滞。 |
| .json / 公開エンドポイントのスクレイパー | ⚠️ 部分的 | いいえ | 動くことはあるが、直接リクエストはますますブロックされる。プロキシ依存。 |
| Playwright / ブラウザスクレイパー | ✅ はい、ただし壊れやすい | 通常は不要 | APIなしでやるDIY回避策として最有力。ページ変更とボット対策は依然重要。 |
| Thunderbit | ✅ はい | いいえ | AI / ブラウザワークフロー。OAuthもセレクターも不要。非開発者に最適。 |
レート制限、1,000件上限、そして実際に役立つ対策
これは、reddit scraper githubプロジェクトを使う人にとって、最も大きな悩みです。フォーラムには、「レート制限で途中で終わってしまうのがつらい」「なんで1,000件くらいしか取れないの?」といった不満があふれています。核心となる制約は、RedditのAPIレート制限(1分あたりのリクエスト数)と、約1,000件の一覧上限です(APIは各一覧エンドポイントにつき、直近約1,000件の投稿しか返しません)。
レート制限への対処ベストプラクティス
Redditの現在の公開ベースラインは、です。実務では、次のように扱います。
- 指数バックオフ。 レート制限応答が返ったら待機し、再試行のたびに待ち時間を長くします(1秒、2秒、4秒、8秒…)。エンドポイントを連打しないでください。
X-Ratelimit-Remainingヘッダーを読む。 RedditのAPI応答には、残りリクエスト数とリセット時刻を示すヘッダーが含まれています。勘ではなく、この値に基づいてリクエストを調整します。- ユーザーエージェントのローテーション。 一部のリポジトリでは、検知回避のためにこれを勧めています。役立つことはありますが、倫理的に使ってください。自分が受けた制限を逃れるために使うべきではありません。
- すべてログに残す。 API応答、レート制限ヘッダー、エラーをログ化してください。スクレイパーが午前2時に死んだとき、ログは何よりの味方です。
1,000件の壁を越えるには
APIの約1,000件上限に対する最も信頼できる回避策は、時間ウィンドウの分割です。
beforeとafterのタイムスタンプパラメータを使って、1つの時間帯を取得する。- ウィンドウを前方(または後方)にずらす。
- 繰り返す。
- 投稿IDで重複排除する。
これは美しくはありませんが、1回のリクエストループで一覧エンドポイントから任意の履歴が取れるようなふりをするより、ずっと誠実です。本当に過去データが必要なら、承認済みの学術アクセスか、ライセンス付きの経路が必要になります。Pushshiftはもはや標準回答ではありません。
ブラウザベースのスクレイピング(PlaywrightやThunderbit)は、APIの返却値ではなくページ上に描画された内容を取得するため、この上限を完全に回避できます。Thunderbitのページネーション機能を使えば、必要なだけページをめくってデータを集められます。
重複排除とエラー復旧
多くのreddit scraper githubリポジトリは、最初から重複排除やエラー復旧を備えていません。ユーザーは明確に、「重複排除も、エラー後のレート制限回避も、ファイルが既にダウンロード済みかの確認も、どれにも対応していなかった」と不満を述べています。対策は次のとおりです。
- 重複排除: 各投稿のID(またはID+本文)をハッシュ化します。既に見たハッシュは、SQLiteデータベースや単純なフラットファイルに保存してください。挿入前に、同じハッシュが存在するか確認します。時間ウィンドウを分割するときや、失敗したジョブを再実行するときに特に重要です。
- エラー復旧: N件ごとに進捗をチェックポイントファイルへ保存します。実行に失敗したら、最初からではなく最後のチェックポイントから再開します。これで、2時間目に落ちる3時間の作業が、1時間で再開できる作業に変わります。
各アプローチがこれらの制約をどう扱うか

| アプローチ | レート制限への対応 | 1,000件超えは可能? | 自動重複排除? | エラー復旧? |
|---|---|---|---|---|
| PRAW(素の状態) | 手動(sleep / retry) | ❌(API上限) | ❌ | ❌ |
| PRAW + 時間ウィンドウ分割 | 手動 | ✅(回避策) | ❌ | ❌(自分で追加すれば別) |
| Playwrightによる.jsonスクレイピング | 該当なし(APIなし) | ✅ | ❌ | ❌ |
| Thunderbit(ブラウザスクレイピング) | 内蔵(AIによる調整) | ✅(ページネーション) | 該当なし(目視確認) | 内蔵 |
RedditスクレイパーのGitHubリポジトリが答えではないとき:ノーコードという選択肢
多くのreddit scraper github記事は、Pythonが使えることを前提にしています。しかし、Redditのスクレイピング解決策を探している人の多くは、マーケター、営業、リサーチャー、あるいは毎日Pythonを書くわけではない個人起業家です。その層にとって、GitHubリポジトリには見えにくいコストがあります。
- OAuth認証情報とReddit開発者アプリの設定
- Pythonの仮想環境と依存関係の衝突管理
- PRAWの内部実装が変わったときの不可解なエラーのデバッグ
- Redditが利用目的を承認しない場合のAPIキー失効対応
- Redditの変更のたびにスクリプトを保守する手間
これは仮定ではありません。には2,563スターと107件の未解決Issueがあります。最近の報告には、「インストールに苦戦している」「PRAWモジュールエラー」「認証すらできない例外が出る」などがあります。
GitHubリポジトリが向いている場合
- カスタムなスクレイピングロジックが必要なとき(例:特定のコメントツリーの走査、独自のNLPパイプライン統合)。
- 既存のPythonデータパイプラインに組み込みたいとき。
- 独自の保存先(データベース、データウェアハウス)で、非常に大規模にスクレイピングしたいとき。
- コード保守や破壊的変更への対応に慣れているとき。
ノーコードツールが向いている場合
- Redditデータをすぐに欲しいとき。セットアップに何時間もかけず、数分で済ませたい。
- APIキー、OAuthアプリ、Python環境を管理したくないとき。
- すぐ使えるように、スプレッドシート、Notion、Airtableへ直接エクスポートしたいとき。
- Redditのレイアウト変更に合わせて、ツール側に自動追従してほしいとき。
Thunderbitは、まさにノーコードの領域にぴったりです。ユーザーはでき、AIが提案するフィールドで2クリック、CSV / Google Sheets / Airtable / Notionへ無料エクスポートでき、コードを書かずにページネーションも処理できます。ブラウザベースのスクレイピングなので、OAuth設定もAPIキー登録も不要です。
クイック手順:ThunderbitでRedditをスクレイピングする方法(ステップごと)
- をインストールします。
- スクレイピングしたいRedditページ(サブレディット、検索結果、ユーザープロフィール)へ移動します。
- 「AIでフィールドを提案」をクリックします。 Thunderbitがページを読み取り、投稿タイトル、著者、アップvotes、時刻、URLなどの列を提案します。
- 必要に応じてフィールドを調整し、「スクレイプ」をクリックします。
- データテーブルを確認します。 必要なら「サブページをスクレイプ」をクリックして各投稿を開き、コメントや追加情報を取得します。
- 好みの保存先へエクスポートします。Google Sheets、Excel、Airtable、Notion、CSV、JSONに対応しています。
2分。コードはゼロ。動作を見たいなら、をご覧ください。
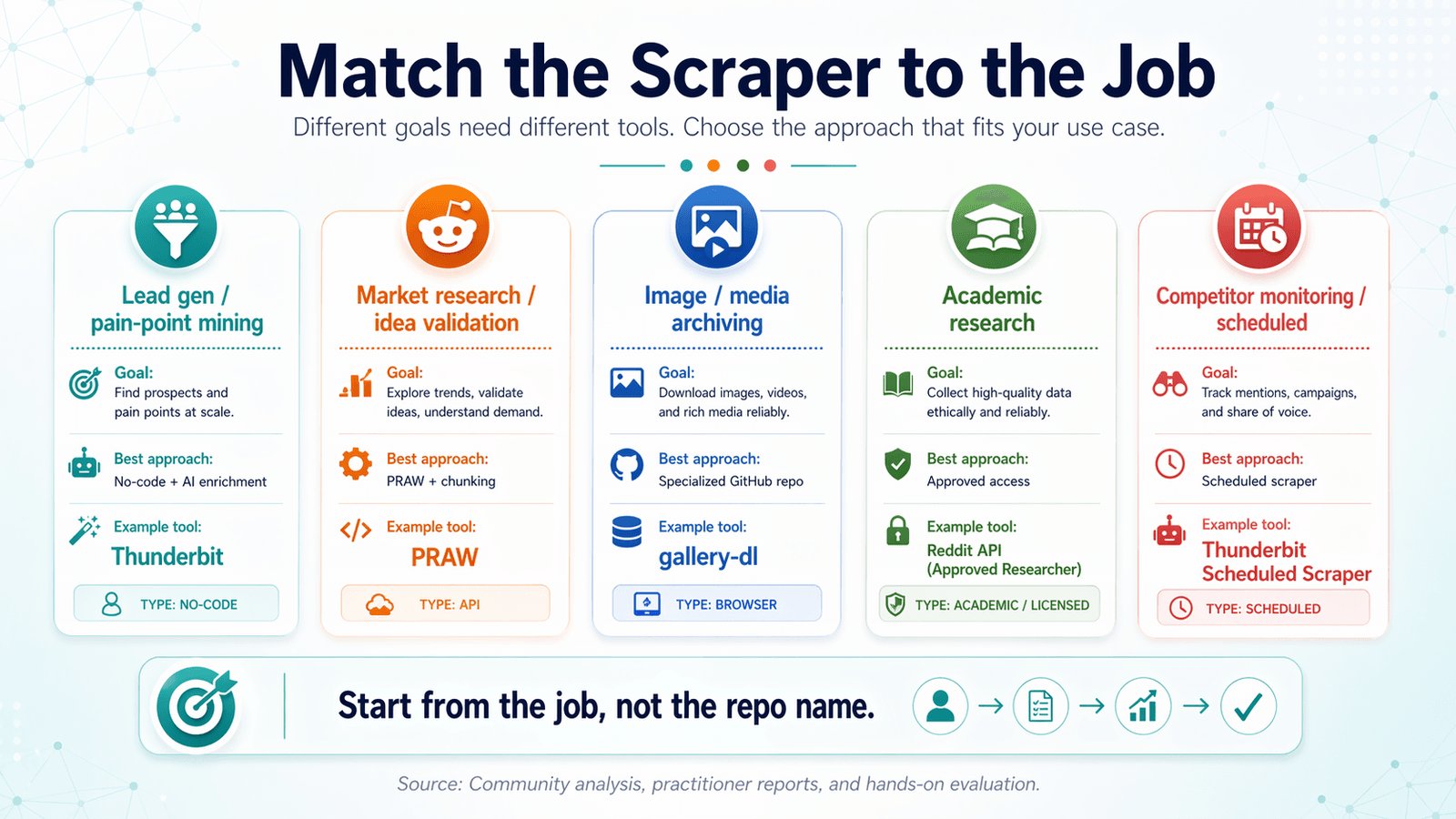
仕事に合ったRedditスクレイパーを選ぶ:ユースケース別の判断マトリクス
多くのreddit scraper github記事は、ツール別に整理しています。でも、それは順序が逆です。
まず目的から考え、そこから最適なツールを逆算してください。
リード獲得と課題発掘
必要なもの: キーワードで絞り込んだ投稿+コメント、AIによるタグ付け、CRM投入しやすい形式へのエクスポート。
最適な方法: AI補強付きのノーコードスクレイパー。
推奨ツール: (AIによるラベリング+Google Sheets/AirtableへエクスポートしてCRMに取り込み)。
例のワークフロー: 特定の課題に言及している投稿をサブレディットからスクレイピング。ThunderbitのField AI Promptで感情分類やトピックタグを付与。営業チームのAirtableやGoogleシートへ出力。
市場調査とアイデア検証
必要なもの: 大量の投稿タイトル+スコア、サブレディット単位のトレンドデータ。
最適な方法: 大量取得ならPRAW+時間ウィンドウ分割、手早く取るならThunderbit。
例: r/SaaS や r/startups をスクレイピングして、過去90日間のトレンドトピックとアップvote傾向を調べる。
画像・メディアのアーカイブ
必要なもの: メディアURL、重複排除、定期実行。
最適な方法: 専用GitHubリポジトリ(例:)+cronジョブ。
注意: ここでは重複排除が重要です。同じ画像が複数のサブレディットに投稿されるのは珍しくありません。
学術研究と過去データ
必要なもの: 過去データ、完全なコメントツリー、大規模データセット。
最適な方法: 承認済みの学術アクセス、またはライセンス付きデータ経路。Pushshiftは、もはや汎用解ではありません。
現実チェック: 2026年は、Pushshiftの制限とRedditの強化されたデータポリシーのため、この用途が最も難しいです。
競合監視と定期スクレイピング
必要なもの: 一定間隔での繰り返し取得、変更検知。
最適な方法: Thunderbitの(時間間隔を普通の英語で記述し、URLを入力してスケジュールをクリック)か、コード派ならcron+スクリプト。
ユースケース判断マトリクス表
| ユースケース | 必要なもの | 最適な方法 | 例のツール |
|---|---|---|---|
| リード獲得 / 課題発掘 | 投稿+コメント、キーワード絞り込み、AIタグ付け | ノーコードスクレイパー+AI補強 | Thunderbit |
| 市場調査 / アイデア検証 | 大量の投稿タイトル+スコア、サブレディット単位データ | PRAW+時間ウィンドウ分割、またはThunderbit | PRAW または Thunderbit |
| 画像 / メディアのアーカイブ | メディアURL、重複排除、定期実行 | 専用GitHubリポジトリ+cron | bulk-downloader-for-reddit |
| 学術研究 | 過去データ、完全なコメントツリー | 承認済みの学術アクセス、またはPlaywright | Pushshift 学術API(利用可能なら) |
| 競合監視 / 定期実行 | 繰り返しスクレイピング、変更検知 | 定期スクレイパー | Thunderbit Scheduled Scraper または cron+スクリプト |
コミットする前に、どのRedditスクレイパーのGitHubリポジトリも評価する方法
リポジトリをクローンしてデバッグを始める前に、この5分チェックを行ってください。数時間の節約になります。
5分でできるリポジトリ健全性チェック
- 最終コミット日。 6か月以上前なら要注意です。RedditのAPIは頻繁に変わります。
- 未解決Issueと解決済みIssueの比率。 未回答Issueが多いのは危険信号です。最近のIssueに認証失敗、403、Pushshift障害が含まれていないか確認してください。
- LICENSEファイル。 存在するか確認します。ライセンスなし = 法的に曖昧です(後述)。
- 依存関係。 必要なライブラリは最新ですか。非推奨パッケージを使っていませんか。2022年固定版だらけの
requirements.txtは警告サインです。 - READMEの質。 セットアップが明確に説明されていますか。使用例はありますか。ドキュメントが弱いほど、あなたのデバッグ時間が増えます。
- スター数 vs フォーク数 vs 最近の活動。 スターが多くても最近の活動が少ない場合、昔は人気だったが今は放置されている可能性があります。スター数だけでなく
pushed_atの日付も見てください。
簡単な例として、は364スターあり、一見すると信頼できそうです。しかし、リポジトリはアーカイブされ、READMEには「THIS REPOSITORY IS STALE」とあります。
スター数だけでは全体像は分かりません。
RedditスクレイパーのGitHub環境を最大限に活かすコツ
コードで進めると決めたなら、頭痛の種を減らす方法があります。
必ず仮想環境を使う
仮想環境を使うと、スクレイパーの依存関係が分離され、他のPythonプロジェクトと衝突しません。コマンドは1つ、python -m venv venv。何かをインストールする前に有効化してください。これは基本中の基本ですが、「module not found」というタイトルのGitHub Issueを十分見てきたので、繰り返す価値があります。
認証情報は安全に保管する
Reddit APIのclient IDやsecretをスクリプトに直書きしないでください。環境変数か.envファイルを使い、.envを.gitignoreに追加します。誤って認証情報をGitHubへプッシュしてしまったら、すぐにローテーションしてください。ボットは公開されたAPIキーを探しています。
すべてログに残す
API応答、レート制限ヘッダー、エラーを必ずログに記録してください。何か壊れたとき、ログがあるかないかで、「何が起きたか正確に分かる」のか、「なぜ止まったのか全然分からない」のかが分かれます。
スケジュールと自動化は慎重に
定期スクレイピングを走らせるなら、cron(Linux/Mac)やTask Scheduler(Windows)を使いましょう。ただし、失敗監視は必須です。2週間黙って失敗し続けるcronジョブは、自動化しないより悪いこともあります。
別案として、Thunderbitのなら、間隔を普通の英語で説明するだけでよく、cron構文は不要です。
Redditスクレイピングの法的・倫理的ベストプラクティス
これは単なる注意書きではありません。Redditは2023年のAPI変更以降、規約の執行を強めており、個人データのスクレイピングには実際の法的リスクがあります。
本当に重要な点だけを挙げます。
Redditの利用規約:実際には何が書かれているのか
Redditの(2026年3月31日までの改定版)は、規約または別途の合意で認められていない限り、自動手段でサービスのデータにアクセス、検索、収集することを明確に禁止しています。とではさらに詳細が示されており、Redditは開発者の利用を監視・監査でき、アクセスを変更または停止でき、過度または濫用的な利用に対して恒久的にアクセスを遮断できます。商用利用には通常、明示的な承認が必要です。
2026年3月のはさらに踏み込み、API経由でRedditデータにアクセスする前に承認が必要であること、未承認の商用化やAI / データマイニング用途は禁止であること、また違反時にはトークンの失効、アプリやアカウントの停止、関連ボットやドメインの停止があり得ることを示しています。
robots.txt への準拠
Redditの現在のは、非常に制限的です。
1User-agent: *
2Disallow: /これは、すべての自動化ユーザーエージェントに対する全面的な拒否です。さらにも参照されています。これは、古いWebスクレイピングの慣習から一部の開発者が今も想定している、緩やかなrobots.txtとは大きく異なります。
ベストプラクティス:ツールが自動で強制しない場合でも、スクレイピング前には必ずrobots.txtを確認してください。
個人データとプライバシー(GDPR/CCPA)
ユーザー名、投稿履歴、その他の個人識別情報をスクレイピングする場合、(EU)やCCPA(カリフォルニア州)が適用される可能性があります。ベストプラクティスは、保存前に個人データを匿名化または集約することです。法的根拠なしに個人ユーザーのプロファイルを作成しないでください。
GitHubリポジトリのライセンス:作る前に確認する
多くのreddit scraper githubリポジトリはMITやApacheライセンス(寛容的)を採用していますが、ライセンスファイルがまったくないものもあります。法的には、それは「全著作権保留」を意味します。フォーク、改変、構築の前には、必ずLICENSEファイルを確認してください。スター数がいくら多くても、ライセンスなしなら法的には曖昧です。
2025〜2026年の執行は本物です
Redditの取り締まりは2023年で終わっていません。2025年には、Redditコンテンツの無断スクレイピング/利用を理由にAnthropicを提訴し、さらに2025年後半にはReddit v. SerpApiにも動きました。これは、Redditが技術的なブロックだけでなく、法的措置も辞さないことを示しています。
2026年に最適なRedditスクレイパー GitHub アプローチを選ぶ
RedditスクレイパーのGitHub事情は、2023年以降で劇的に変わりました。多くのリポジトリは古くなっています。レート制限と1,000件上限は現実の制約です。Pushshiftは一般ユーザー向けではなくなりました。そしてRedditのポリシーは、以前よりも明確で、以前よりも厳しく運用されています。
要点だけまとめると。
- PRAW は、RedditのAPI制限を受け入れつつ、独自ロジックを組みたいなら、今でも最も信頼できるオープンソース基盤です。
- Pushshift/PSAW は、もはや汎用解ではありません。
- snscrapeのRedditモジュール はレガシーで不安定です。
- .json と公開エンドポイントのスクレイパー は壊れやすく、2026年には多くがブロックされます。
- ブラウザベースのツール は、Playwright系リポジトリでも、のようなノーコードでも、多くのユーザー、特に非開発者にとって最も実用的です。
ツールではなく、ユースケースから始めてください。どのGitHubプロジェクトに取り組む前にも、5分のリポジトリ健全性チェックを行いましょう。
セットアップを飛ばして、数分でRedditスクレイピングを始めたいなら、。
FAQ
2026年にGitHubで使える、最も優れたオープンソースのRedditスクレイパーは何ですか?
は、今も最も信頼できるAPIラッパーで、活発に保守され、ドキュメントも充実しています。は、PRAW上に構築された、信頼できる保守済みCLIツールです。PlaywrightベースのスクレイパーはAPIを使わない取得に有効で、snscrapeのRedditモジュールも部分的には機能しますが、ほぼ未保守です。どのリポジトリを使う前にも、最終コミット日と未解決Issueを必ず確認してください。GitHub上のの大半は古いままです。
Redditをスクレイピングするのは合法ですか?
公開データのスクレイピングは法的にグレーゾーンですが、Reddit自身の規約は厳格です。、、、、はいずれも、無断の大量スクレイピングに否定的です。スクレイピングしたデータの商用再配布には、Redditの明示的な許可が必要になる場合があります。個人データをスクレイピングするなら、GDPRやCCPAも関係する可能性があります。
RedditのAPIレート制限をどう回避すればいいですか?
指数バックオフを使い、X-Ratelimit-Remainingヘッダーを監視し、必要なら時間ウィンドウ分割で制限内に収めてください。ブラウザベースのスクレイピング(Playwrightや)は、描画済みページを取得するためAPIレート制限を回避できますが、ページ読み込み速度やボット対策といった別の考慮点があります。レート制限を完全に消す魔法はなく、サーバー側で適用されています。
APIキーなしでRedditをスクレイピングできますか?
はい。Playwrightベースのスクレイパーや.json URLの裏技なら、APIキーは不要です。もブラウザ経由で取得するためAPIキーは不要です。トレードオフとして、.jsonエンドポイントはますますブロックされており(2026年4月時点では多くの環境で403を返す)、ブラウザベースのスクレイピングはAPIコールより遅く、リソースも多く使います。
RedditスクレイピングでPushshiftはどうなったのですか?
2023年以降のRedditのデータライセンス変更に伴い、Pushshiftの公開APIアクセスは削除されました。ラッパーはアーカイブされ、古い状態です。限定的な学術アクセスが承認済みの一部経路で存在する可能性はありますが、今日「reddit scraper github」を探している大半のユーザーにとって、Pushshiftはもはや実用的ではありません。深い過去データが必要なら、Redditが承認する学術データ経路やライセンス付きデータ経路を検討してください。
さらに詳しく