私がSaaSや自動化の分野に足を踏み入れたばかりの頃、「ウェブクローリング」と聞いても、正直なところ日曜の午後にクモがのんびり歩いているイメージしか浮かびませんでした。でも今や、ウェブクローリングはGoogle検索から価格比較サイトまで、あらゆるサービスの土台になっています。ウェブは毎日変化し続ける膨大な情報の宝庫で、エンジニアはもちろん、営業やマーケの現場でもそのデータを活用したい人がどんどん増えています。ただ、pythonウェブクローラーを作るのは昔より簡単になったとはいえ、みんなが本当に欲しいのは「データ」であって、HTTPヘッダーやJavaScriptレンダリングの小難しい話じゃないんですよね。
ここからが本題です。自分がの共同創業者として日々感じているのは、業界を問わずウェブデータのニーズが爆発的に増えていること。営業チームは新しいリードを探し、EC担当は競合の価格を追いかけ、マーケターはコンテンツ分析に夢中。でも、みんながPythonのプロになりたいわけじゃない。そこで今回は、pythonウェブクローラーの仕組みや重要性、そしてThunderbitのようなAIウェブスクレイパーがビジネスユーザーや開発者の常識をどう変えているのか、分かりやすく紹介します。
Pythonウェブクローラーって何?なぜ大事なの?
まず最初に誤解を解いておきたいのが、ウェブクローラーとウェブスクレイパーは似ているようで全然違うということ。よく混同されがちですが、例えるならルンバとダイソンくらい違います(どっちも掃除はするけど、やり方が全然違う)。
- ウェブクローラーはネットの“偵察部隊”。リンクをたどって次々とウェブページを発見し、インデックス化していきます。Googlebotがウェブ全体を巡回しているイメージですね。
- ウェブスクレイパーは“収集家”。特定のページから価格や連絡先、記事内容など、必要なデータだけをピンポイントで抜き出します。

「web crawler python」と言えば、Pythonでこうした自動化ボットを作ることを指します。Pythonが選ばれる理由は、学びやすさとライブラリの豊富さ、そして何よりアセンブリでクローラーを書きたい人なんていないからです。
ウェブクローリング・スクレイピングのビジネス的な価値
なぜ多くのチームがウェブクローリングやウェブスクレイピングに注目しているのでしょう?ウェブデータは“新しい石油”とも言われますが、掘削機は不要で、ちょっとしたコードやクリックだけで手に入るのが魅力です。
主なビジネス活用例をまとめると:
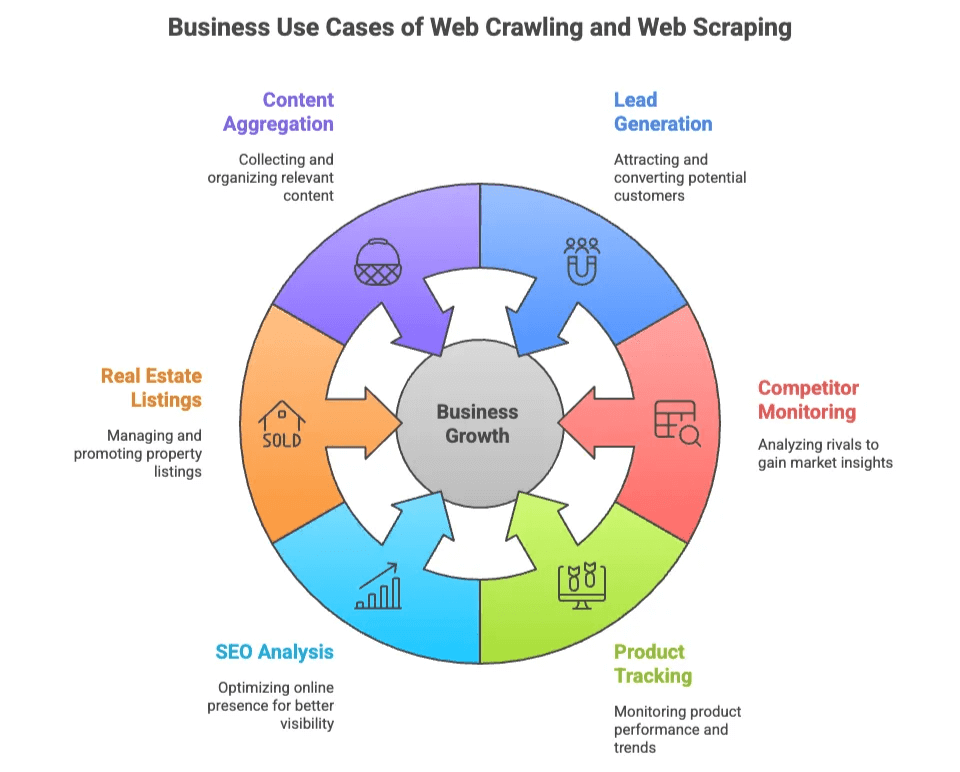
| ユースケース | 主な利用者 | 得られる価値 |
|---|---|---|
| リード獲得 | 営業・マーケ | ディレクトリやSNSからターゲットリストを作成 |
| 競合モニタリング | EC・運用 | 競合サイトの価格・在庫・新商品を追跡 |
| 商品トラッキング | EC・小売 | カタログ変更やレビュー、評価を監視 |
| SEO分析 | マーケ・コンテンツ | キーワードやメタタグ、被リンクを解析 |
| 不動産リスティング | 仲介・投資家 | 複数サイトから物件情報やオーナー連絡先を集約 |
| コンテンツ集約 | 調査・メディア | 記事やニュース、フォーラム投稿を収集 |
技術者だけでなく、非エンジニアのチームでも恩恵を受けられるのがポイント。開発者は大規模なカスタムクローラーを作れますし、ビジネスユーザーは“CSSセレクタ”なんて知らなくても、素早く正確なデータが手に入るのが理想です。
Pythonウェブクローラーの代表的なライブラリ:Scrapy、BeautifulSoup、Selenium
Pythonがウェブクローリングで人気なのは、ただの流行じゃありません。用途や特徴が違う3つの主要ライブラリが揃っているからです。
| ライブラリ | 使いやすさ | 速度 | 動的コンテンツ対応 | 拡張性 | おすすめ用途 |
|---|---|---|---|---|---|
| Scrapy | 中 | 高速 | 限定的 | 高 | 大規模・自動化クローリング |
| BeautifulSoup | 易 | 中 | なし | 低 | 小規模・シンプルな解析 |
| Selenium | 難 | 低速 | 優秀 | 低〜中 | JS多用・操作が必要なサイト |
それぞれの特徴をざっくり見ていきましょう。
Scrapy:本格派のpythonウェブクローラー
Scrapyは“スイスアーミーナイフ”みたいな存在。大規模な自動クローリングに特化したフレームワークで、数千ページの巡回や並列リクエスト、データのパイプライン出力まで一括でこなします。
開発者に人気の理由:
- クローリング、解析、データ出力を一元管理できる
- 並列処理やスケジューリング、パイプライン機能が標準装備
- 大規模なデータ収集や自動化に最適
ただし… Scrapyは学習コストが高め。ある開発者いわく「数ページのスクレイピングならオーバースペック」()。セレクタや非同期処理、時にはプロキシやアンチボット対策も必要です。
Scrapyの基本的な流れ:
- Spider(クローラーのロジック)を定義
- Itemパイプライン(データ処理)を設定
- クローリングを実行してデータを出力
Googleみたいに大規模巡回したいならScrapyが最適。ちょっとメールリストを集めたいだけなら、やや大げさかも。
BeautifulSoup:シンプル&軽量な解析ツール
BeautifulSoupは“Hello World”感覚で使えるHTML/XMLパーサー。初心者や小規模プロジェクトにぴったりの軽量ライブラリです。
人気の理由:
- とにかく簡単で直感的
- 静的ページのデータ抽出に最適
- サクッと書けるスクリプトに向いている
ただし… BeautifulSoup自体は“クローリング”機能を持ちません。ページ取得にはrequestsなどと組み合わせ、リンク巡回や複数ページ対応は自作が必要です()。
まずはウェブ解析を体験したい人におすすめ。ただし、JavaScript対応や大規模運用には向きません。
Selenium:動的・JS多用サイトの強い味方
Seleniumは“ブラウザ自動操作”の王様。ChromeやFirefox、Edgeを操作し、ボタンをクリックしたりフォーム入力したり、JavaScriptで動的に生成されるページもレンダリングできます。

強み:
- 人間と同じようにページを“見て”操作できる
- 動的コンテンツやAJAXデータも取得可能
- ログインやユーザー操作が必要なサイトにも対応
ただし… Seleniumは動作が重く、1ページごとにブラウザを立ち上げるため大量巡回には不向きです()。また、ドライバ管理や動的コンテンツの待機など、メンテナンスも手間がかかります。
普通のスクレイパーでは突破できない“要塞”みたいなサイトに挑むときの切り札です。
Pythonウェブクローラー構築・運用のリアルな課題
ここで、pythonウェブクローリングの“苦労話”も紹介します。自分もセレクタのバグやアンチボット対策に何時間も悩まされた経験があります。主な課題はこんな感じ:
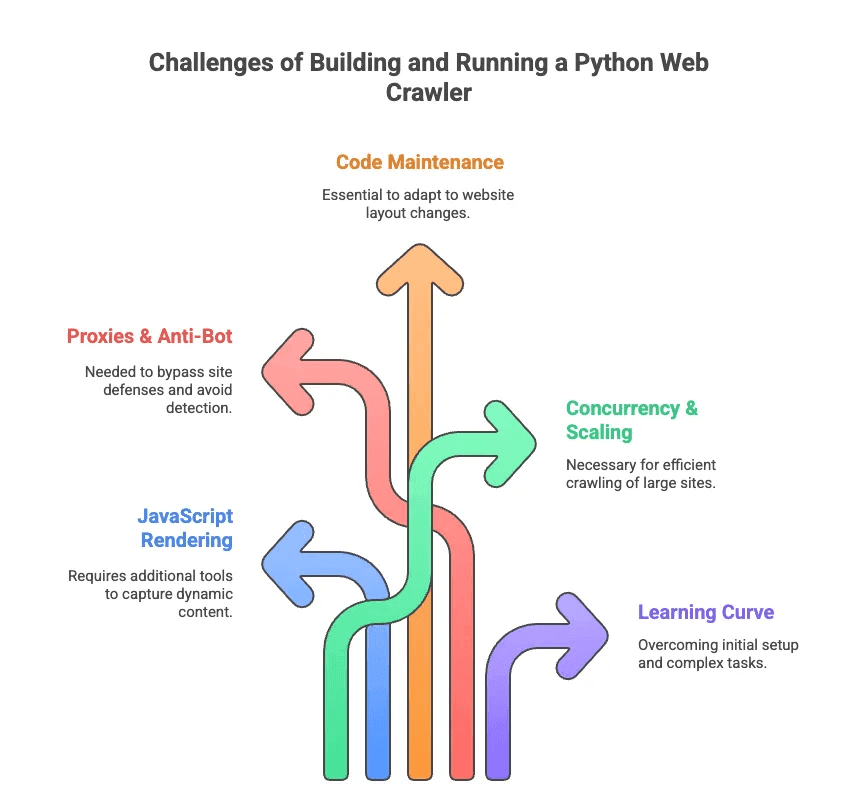
- JavaScriptレンダリング: 最近の多くのサイトは動的にデータを表示。ScrapyやBeautifulSoupだけでは見えない情報も多い。
- プロキシ&アンチボット: サイト側はクローリングを嫌うので、プロキシのローテーションやユーザーエージェント偽装、CAPTCHA対策が必要。
- コード保守: サイト構造が頻繁に変わるため、セレクタやロジックの修正が絶えない。
- 並列処理&拡張性: 数千ページを巡回する場合、非同期リクエストやエラーハンドリング、データパイプラインの管理が不可欠。
- 学習コスト: 非エンジニアにとってはPythonや依存関係のセットアップ自体がハードル。ページネーションやログイン処理はさらに難易度アップ。
あるエンジニアは「カスタムスクレイパーを書くのは“セレクタ設定の博士号”が必要な気分」と語っています()。営業やマーケ担当者が求めているのは、そんな苦労じゃないですよね。
AIウェブスクレイパー vs. pythonウェブクローラー:ビジネスユーザーの新常識
「データは欲しいけど、面倒はごめん」——そんな人にぴったりなのがAIウェブスクレイパーです。Thunderbitのようなツールは、エンジニアじゃなくても使えるように設計されていて、AIがページを読み取り、抽出すべきデータを提案。ページネーションやサブページ巡回、アンチボット対策も自動でやってくれます。
比較表はこちら:
| 機能 | Pythonウェブクローラー | AIウェブスクレイパー(Thunderbit) |
|---|---|---|
| セットアップ | コード・ライブラリ・設定 | 2クリックでChrome拡張導入 |
| メンテナンス | 手動更新・デバッグ | AIが自動でサイト変化に対応 |
| 動的コンテンツ | Seleniumやプラグイン必須 | ブラウザ/クラウドで標準対応 |
| アンチボット対策 | プロキシ・ユーザーエージェント | AI&クラウドで自動回避 |
| 拡張性 | 努力次第で高い | クラウド・並列処理で高い |
| 使いやすさ | 開発者向け | 誰でも簡単 |
| データ出力 | コードやスクリプト | 1クリックでSheets/Airtable/Notion |
Thunderbitなら、HTTPリクエストやJavaScript、プロキシの心配は一切不要。「AIでフィールド提案」をクリックすれば、AIが重要なデータを自動で抽出し、“スクレイピング開始”で完了。まるでデータ専属の執事がいる感覚です。
Thunderbit:誰でも使える次世代AIウェブスクレイパー
Thunderbitはで、ウェブデータ抽出を“出前注文”並みに手軽にしてくれます。主な特徴はこんな感じ:
- AIによるフィールド自動検出: ページをAIが解析し、抽出すべき項目(列)を提案。CSSセレクタの知識は不要()。
- 動的ページ対応: 静的・JavaScript多用ページの両方に対応。ブラウザ&クラウドモードを搭載。
- サブページ・ページネーション: 商品やプロフィールの詳細も自動で巡回・収集()。
- テンプレート適応力: 1つのスクレイパーテンプレートで複数のページ構造に対応。サイト変更時も再構築不要。
- アンチボット回避: AIとクラウド基盤で一般的なスクレイピング防御を突破。
- データ出力: Google Sheets、Airtable、Notionへの直接出力やCSV/Excelダウンロードも無料で可能()。
- AIデータクレンジング: データの要約・分類・翻訳もワンクリック。面倒な表整理から解放されます。
活用例:
- 営業チーム:ディレクトリやLinkedInから数分でリストを抽出
- EC担当者:競合価格や商品変更を自動で監視
- 不動産業者:複数サイトから物件情報やオーナー連絡先を集約
- マーケティング:コンテンツやキーワード、被リンクを分析——コード不要
Thunderbitの操作はとてもシンプル。拡張機能をインストールして、対象サイトを開いて「AIでフィールド提案」をクリックするだけ。AmazonやLinkedInなど人気サイトにはすぐ使えるテンプレートも用意されています()。
PythonウェブクローラーとAIウェブスクレイパー、どっちを選ぶ?
pythonウェブクローラーを自作するか、Thunderbitを使うか。正直なところ、こんな感じで選ぶのがベストです:
| シナリオ | Pythonウェブクローラー | AIウェブスクレイパー(Thunderbit) |
|---|---|---|
| カスタムロジックや大規模巡回が必要 | ✔️ | 場合による(クラウドモード) |
| 他システムとの深い連携が必要 | ✔️(コードで対応) | 限定的(エクスポート経由) |
| 非技術者で素早く結果が欲しい | ❌ | ✔️ |
| サイト構造の頻繁な変化 | ❌(手動更新) | ✔️(AIが自動対応) |
| 動的/JS多用サイト | ✔️(Selenium利用) | ✔️(標準対応) |
| 低予算・小規模プロジェクト | 場合による(無料だが手間) | ✔️(無料プラン・制限なし) |
Pythonウェブクローラーを選ぶべき人:
- 開発者で細かい制御が必要な場合
- 数百万ページの巡回や独自パイプラインが必要な場合
- 継続的な保守やデバッグも苦じゃない場合
Thunderbitを選ぶべき人:
- すぐにデータが欲しい人
- 営業・EC・マーケ・不動産など、結果重視のビジネスユーザー
- プロキシやセレクタ、アンチボット対策に悩みたくない人
迷ったら、次のチェックリストを参考にしてみてください:
- Pythonやウェブ技術に自信がある→ScrapyやSeleniumを試す
- とにかく早く・簡単にデータが欲しい→Thunderbitがおすすめ
まとめ:ウェブデータ活用、あなたに合った最適なツールを
ウェブクローリングやウェブスクレイピングは、今やデータ活用の必須スキル。でも、誰もが“クローリングの達人”になりたいわけじゃありません。ScrapyやBeautifulSoup、Seleniumなどpythonウェブクローラーは強力ですが、学習コストや保守の手間も大きいのが現実です。
だからこそ、のようなAIウェブスクレイパーの登場は本当に画期的。Thunderbitは、AIによるフィールド検出や動的ページ対応、ノーコード操作で、誰でも数分で必要なデータを抽出できるように設計されています。
コードをいじるのが好きな開発者も、結果だけ欲しいビジネスユーザーも、自分に合ったツールを選びましょう。技術力・目的・納期に合わせて最適な方法を選択してください。ウェブデータ抽出の手軽さを体感したい人は、。きっと、未来の自分とスプレッドシートが喜ぶはずです。
さらに詳しく知りたい人は、の他のガイドもぜひチェックしてみてください。やなど、役立つ情報が満載です。快適なクローリング&スクレイピングライフを!
よくある質問
1. Pythonウェブクローラーとウェブスクレイパーの違いは?
Pythonウェブクローラーは、リンクをたどってウェブページを体系的に巡回・インデックス化するためのもの。サイト構造の把握に最適です。一方、ウェブスクレイパーは、そうしたページから価格やメールアドレスなど特定のデータを抽出します。クローラーは“地図を作る”、スクレイパーは“必要な情報を集める”イメージ。Pythonでは両者を組み合わせてデータ抽出ワークフローを構築することが多いです。
2. Pythonでウェブクローラーを作るのにおすすめのライブラリは?
代表的なのはScrapy、BeautifulSoup、Selenium。Scrapyは大規模・高速なプロジェクト向き、BeautifulSoupは初心者や静的ページ向き、SeleniumはJavaScript多用サイトに強いがやや遅め。技術力や対象データ、プロジェクト規模に応じて選びましょう。
3. Pythonウェブクローラーを作らずに簡単にウェブデータを取得する方法は?
はい、Thunderbitなら誰でも2クリックでウェブデータを抽出できます。コードもセットアップも不要。フィールド自動検出、ページネーションやサブページ対応、Sheets/Airtable/Notionへのエクスポートも可能。営業・マーケ・EC・不動産など、すぐにきれいなデータが欲しい方に最適です。
さらに詳しく: