

競合価格の調査や商品情報の更新など、ウェブ上のデータを継続的に集める業務では、JavaScriptで表示されるコンテンツやアンチボット対策への対応が課題になります。自動化ツールを長く作ってきた立場から見ると、ウェブスクレイピングは、こうした情報収集を効率化する有力な手段です。企業の90%がデータ分析を意思決定に活かし、オンラインのデータ量は4年で193%増加したとされるなか、収集した情報を業務で扱えるデータに整える重要性が高まっています。

以前は、Pythonで数行のコードを書くだけで取得できる静的なHTMLが中心でした。現在は、動的コンテンツ、無限スクロール、アンチボット対策など、対象サイトに応じた設計が必要です。本記事では、これから始める方と運用を見直したい方に向けて、Pythonウェブスクレイピングのベストプラクティス、ツール、ワークフローを解説します。あわせて、非定型データをノーコードで試したい場面を例に、ThunderbitのようなAIツールとの使い分けも紹介します。利用時は、対象サイトの利用規約、著作権、個人情報、アクセス頻度を事前に確認してください。
AIであらゆるウェブサイトからデータ抽出 Get Started Free
初心者から実戦まで:Python ウェブスクレイピングの基本
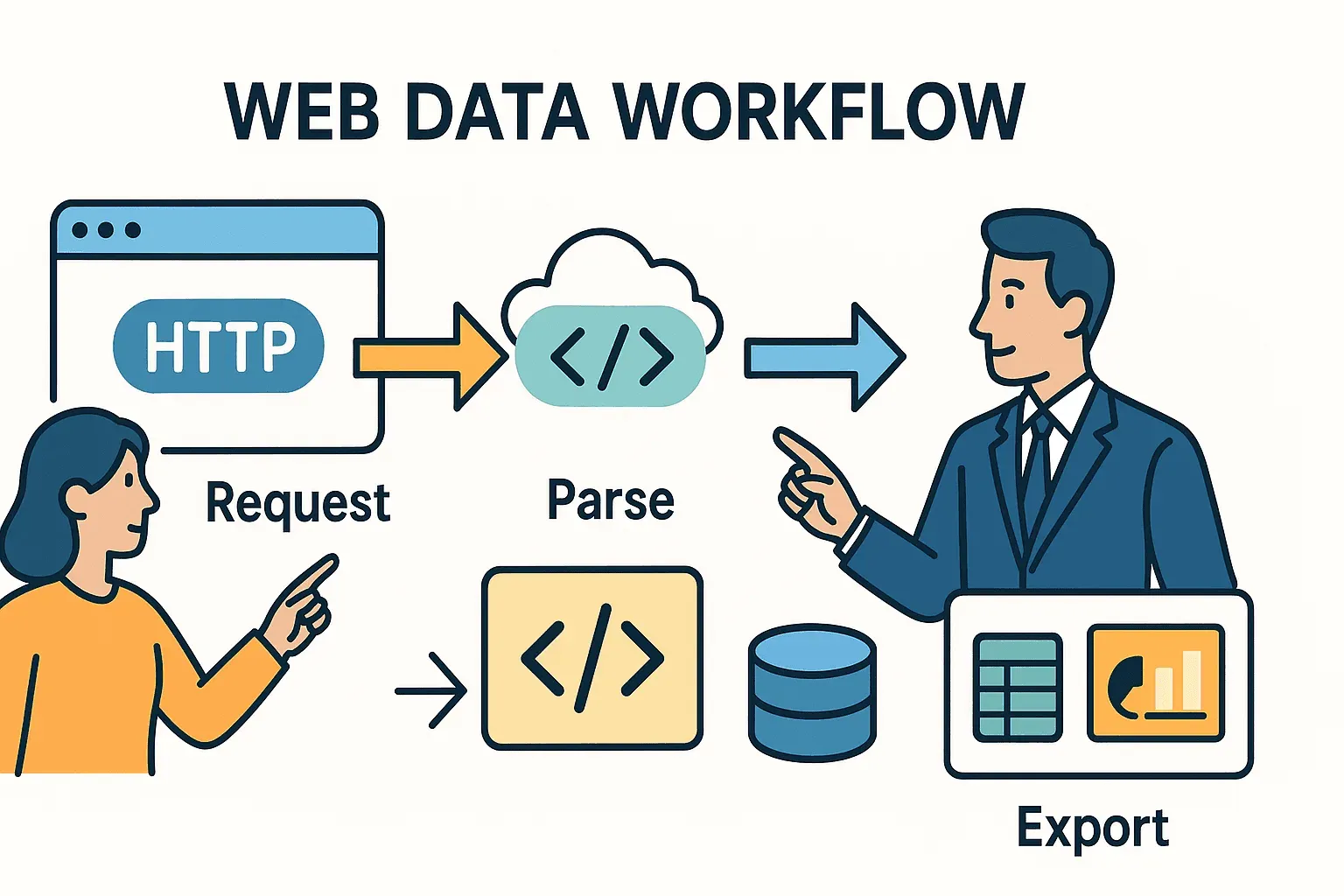
まずは基本から。ウェブスクレイピングとは、ブラウザでの操作(ページを開き、必要なデータを探して保存する)を自動化することです。Python では、おおむね3ステップで進みます。
- HTTP リクエストを送る(ブラウザで URL を開くのと同じ)
- HTML を解析して、欲しいデータを取り出す
- データを出力・加工する(スプレッドシート、DB、ダッシュボードなどへ)
大事なのは、使うツールもぶつかる壁も「サイトの複雑さ」と「目的」で大きく変わる点です。
Python ウェブスクレイピングの原理
Pythonによるウェブスクレイピングでは、まずrequestsでHTMLを取得し、BeautifulSoupで必要な要素を選択して取り出します。静的なページであれば、この組み合わせで基本的な収集処理を構築できます。
一方、データがJavaScriptで読み込まれるページや、情報が複数ページに分かれているサイトでは、ブラウザ自動化、APIの調査、ページネーション処理など、対象の構造に応じた方法が必要です。
主要ツール比較
代表的なPythonツールについて、対象サイトと運用条件に応じた使い分けを整理しました。
| ツール/ライブラリ | こんなときに | メリット | デメリット |
|---|---|---|---|
| Requests + BeautifulSoup | 静的ページや小規模な作業 | 構成がシンプルで処理も軽く、基礎を学びながら細かく制御しやすい。 | JavaScriptや大規模クロールには不向き。 |
| Scrapy | 大規模・多ページ、複数サイト | 非同期処理、パイプライン、エラーハンドリングを備え、大量のURLを扱いやすい。 | 習得と設定にやや学習コスト。 |
| Selenium/Playwright | JavaScript、ログイン、ユーザー操作が必要なページ | ブラウザ上でレンダリングされた情報や操作後のコンテンツを取得しやすい。 | 遅くリソース消費が大きい。運用もやや複雑。 |
| Thunderbit (AI) | 非定型データ、PDF、画像をノーコードで試したいとき | AIによるフィールド提案、サブページ取得、Excel/Sheets出力に対応し、コードを書かずに設定しやすい。 | 高度なカスタム処理には合わない場合があり、利用量はクレジット条件に左右される。 |
静的な小規模サイトで処理を細かく制御したい場合は、まずrequestsとBeautifulSoupが候補になります。多数のページを継続的に扱うならScrapy、ブラウザ操作を再現する必要があるならSeleniumやPlaywrightを比較します。非定型データをコードなしで表にしたい場合は、ThunderbitのようなAIツールも選択肢です。まず1ページで取得項目、精度、出力形式を照合してから、対象範囲を広げると判断しやすくなります。
実戦:複雑なスクレイピングのための段階別ガイド
必要なデータを特定する段階から、安定して運用しやすいスクレイパーを構築するまでの流れを、順に説明します。
1. ターゲットサイトの構造を把握する
まずはブラウザの開発者ツール(F12、または右クリック→検証)で、欲しいデータが HTML のどこにあるか確認します。テーブルか、<div> のかたまりか、隠れた API から JSON が来ているのか。思いがけず簡単な近道が見つかることもあります。
ヒント:ページ送りや「もっと見る」のクリックで JSON リクエストが走るなら、HTML 解析を飛ばして API を直接叩くほうがずっと効率的です。
2. 1ページのプロトタイプから始める
小さく始めましょう。requests で1ページだけ取得し、BeautifulSoup で2〜3項目だけ抜きます。出てこなければ、User-Agent などのヘッダーを足すか、JavaScript で後から読み込まれていないか確認を(その場合は次へ)。
3. 動的コンテンツ/ページネーションへの対応
HTML にデータがなければ、JavaScript で後から読み込まれているケースが多いです。対応策はこうです。
- ブラウザ自動化: Seleniumや Playwrightでページを開き、レンダリング後の HTML を取得する。
- API 呼び出し: Network タブで XHR リクエストを探し、JSON エンドポイントがあれば
requestsで再現する。 - ページネーション: 複数ページならページ番号でループ、無限スクロールなら Selenium でスクロールするか API 呼び出しを模倣。
4. エラー処理とマナー
継続運用では、対象サイトへの負荷を抑え、公開されているルールや利用規約に沿ってアクセスする必要があります。次の項目を実装時の基準にします。
- robots.txt の参照:
example.com/robots.txtで禁止パスやクロールに関する指定を確認する。robots.txtだけでなく、利用規約や取得許可も別途検討する。 - リクエスト間隔:
time.sleep()などで間隔を空ける。Crawl-delay: 5が示されている場合は、その指定と対象サイトの運用条件を踏まえて5秒以上空ける。 - カスタム User-Agent:
"MyScraper/1.0 (your@email.com)"のように、運用主体を識別できる情報を設定する方法がある。連絡先の公開可否は組織の方針に合わせる。 - リトライ処理: try/exceptで失敗を処理し、HTTP 429(リクエスト過多)では待機時間を延ばす。無制限に再試行せず、上限とログを設定する。
5. データの抽出と整形
BeautifulSoup や Scrapy のセレクターで項目を抽出します。空白除去、価格の数値化、日付のパース、完全性チェックも忘れずに。大量データなら pandas で重複除去や並べ替えまで。
6. サブページのスクレイピング
一覧ページだけでは必要な項目がそろわず、詳細ページの取得が必要になる場合があります。まずリンク一覧を抽出し、各ページから追加情報を収集します。PythonではURLリストをループして処理でき、Thunderbitでは「サブページスクレイピング」を設定して、一覧から詳細ページへ移動しながらデータをまとめる方法があります。対象URL、取得件数、重複、失敗時の扱いを記録しておくと、結果を検証しやすくなります。
7. データ出力と自動化
整形したデータは CSV、Excel、Google Sheets、DB へ出力します。定期実行は cron や Airflow で、Thunderbit なら「毎週月曜9時」のように自然な言葉でクラウド実行もできます。
AIでウェブサイトのデータをExcelに抽出する方法 Get Started Free
Thunderbit:Pythonスクレイピングを補完するAIツール
Pythonは細かな処理や大規模なパイプラインを設計しやすい一方、レイアウトが一定しないページ、PDF、画像などでは、抽出ルールの作成に時間がかかる場合があります。Thunderbitは、こうした非定型データを短時間で構造化して試したい場面で、Pythonを補完する選択肢になります。
ThunderbitとPythonの組み合わせ
ThunderbitはAIを搭載したChrome拡張で、ウェブページに加えてPDFや画像からも情報を読み取り、構造化データに変える機能を備えています。コードを使わずに設定できるため、私は次のようにPythonと使い分けています。
- 非定型データへの対応: PDF、画像、HTML構造が統一されていないサイトでは、ThunderbitのAIで表やテキストを抽出し、フィールド候補を作成します。結果は元データと照合し、必要に応じて列や指示を調整します。
- サブページ/多段スクレイピング: 「サブページスクレイピング」機能で一覧ページと詳細ページの情報をまとめます。複雑な分岐や独自の状態管理が必要な場合は、Pythonでの実装も比較します。
- データ出力: Excel、Google Sheets、Notion、Airtableへ出力し、必要に応じてPythonのパイプラインに取り込んで分析やレポート作成につなげます。
実戦例:Python+Thunderbitの活用
不動産の物件情報を集める場合は、PythonとScrapyで複数サイトのURLをクロールし、詳細がPDFでのみ提供される箇所をThunderbitで抽出してCSVへ出力し、最後にPythonで統合する構成が考えられます。運用前に各サイトの利用条件を確認し、PDFから抽出した住所や価格は原資料と照合してから市場分析に使います。
営業リストを作る場合は、Pythonで企業のURLを集め、Thunderbitのメール・電話番号抽出(無料です)を使って、公開されている連絡先を表にまとめる方法があります。抽出結果には誤認識や古い情報が含まれる可能性があるため、用途への適合性を検証し、個人情報や営業連絡に関するルールに沿って扱う必要があります。
継続的なスクレイピングワークフローを作る
単発のスクリプトも便利ですが、ビジネスでは継続的な運用が重要です。おすすめの構成はこうです。
CCCDフレームワーク:Crawl, Collect, Clean, Debug
- Crawl(クロール): ターゲット URL を集める(サイトマップ、検索、リストなど)
- Collect(収集): 各 URL からデータを抽出する(Python、Thunderbit、または両方)
- Clean(整形): 正規化、重複除去、データ検証を行う
- Debug/Monitor(モニタリング): 実行ログ、エラー処理、異常検知アラートを用意する
パイプラインの例:
URLs → [Crawler] → [Scraper] → [Cleaner] → [Exporter] → [Business Platform]
スケジューリングとモニタリング
- Python: cron、Airflow、クラウドスケジューラで定期実行します。ログや、エラー時のメール・Slack 通知も用意しましょう。
- Thunderbit: 内蔵スケジューラで「毎週月曜9時」などを自然な言葉で設定し、クラウドで自動実行してデータ出力まで行えます。
ドキュメント化と引き継ぎ
コードは Git でバージョン管理し、ワークフローは文書に残しましょう。少なくとも1人は運用と更新の方法を把握する必要があります。Python と Thunderbit を併用するなら、どのサイトをどのツールで処理しどこへ出力するかも明確に(「サイトC は Thunderbit で Google Sheets へ、週次の統合は Python で」など)。
倫理と法令への配慮:責任あるスクレイピング
スクレイピングの可否や必要な対応は、取得対象、利用目的、対象サイトの規約、適用法令によって異なります。運用前に整理しておきたい主な観点は次のとおりです。
robots.txtとリクエスト間隔
- robots.txt の参照: 禁止パスやクロールに関する指定を確認し、サイトの利用規約や公開方針とあわせて扱います。Pythonの
robotparserで判定を補助できます。 - 慎重なクロール: Crawl-delayなどの指定がある場合は尊重し、指定がない場合も短時間に大量のリクエストを送らないよう、間隔と同時実行数を調整します。
- User-Agent の明示: 運用主体を識別できるUser-Agentを設定します。他のクローラーやGooglebotなどを名乗る運用は避けます。
データプライバシーと法令遵守
- GDPR/CCPA: 氏名・メール・電話番号などの個人情報を扱う場合は、適用法令、収集目的、必要性、保存期間、削除要請への対応を整理します。地域や用途によって要件が異なるため、必要に応じて専門家へ相談します。
- 利用規約の確認: ログインが必要なページやアクセス制限のあるデータは、明確な許可と利用条件を確認してから扱います。規約違反は、利用停止や紛争につながる可能性があります。
- 権利と公開範囲の確認: 公開ページにある情報でも、著作権、データベース権、個人情報、契約上の制限がなくなるわけではありません。取得対象と二次利用の可否を個別に見直します。
コンプライアンスチェックリスト
- robots.txt でルールと遅延を確認した
- 慎重なリクエスト間隔とカスタム User-Agent を設定した
- 公開・非機密データのみを収集した
- 個人情報を法律に沿って管理した
- サイト利用規約・著作権を侵害していない
よくあるエラーとデバッグのコツ
運用中の問題は、サイト構造の変更、アクセス制限、データ品質、文字コードなど、原因ごとに切り分けると対処しやすくなります。
| エラー種別 | 症状/メッセージ | デバッグのヒント |
|---|---|---|
| HTTP 403/429/500 | ブロック・リクエスト過多・サーバーエラー | ステータスコードとレスポンスを記録し、ヘッダー、認証、利用規約、リクエスト間隔を見直す。429では待機時間を延ばし、500では時間を置いて再試行する。 |
| データ欠落/NoneType | HTMLにデータがない | HTMLを保存し、構造変更、JavaScriptによる読み込み、アクセス制限ページへの遷移を切り分ける。 |
| JavaScriptレンダリングのデータ | 静的HTMLにデータがない | Selenium/Playwrightによるレンダリング、または許可されたAPI呼び出しを調査する。 |
| パース/エンコーディングの問題 | 文字化け、Unicodeエラー | レスポンスヘッダーと実データを照合してエンコーディングを指定し、.textやhtml.unescape()を活用する。 |
| 重複・不整合 | データの重複・不整合 | 一意のIDやURLで重複を除き、必須フィールド、件数、更新日時を検証する。 |
| アンチボット/CAPTCHA | CAPTCHA、ログイン要求 | 自動処理を停止し、利用許可、公式API、手動運用など正規の取得方法を検討する。 |
デバッグの手順:
- 問題が起きた時点のHTML、URL、時刻、ステータスコードを記録する
- ブラウザのDevToolsで、スクリプトのレスポンスと実際の表示を比較する
- 各ステップの入力件数、成功件数、失敗件数をログに残す
- 代表的なページで修正結果を検証してから、対象範囲を段階的に広げる
実戦プロジェクト例:Python ウェブスクレイピングで実力アップ!
ベストプラクティスをすぐ試せる、実戦プロジェクトの例を紹介します。
1. ECサイト価格モニタリングダッシュボード
Amazon、eBay、Walmartから価格・在庫情報を集め、Google Sheetsへ日次で出力して推移を分析する例です。実装前に各サイトの利用条件、公式APIの有無、許可されるアクセス頻度を比較し、動的コンテンツやアクセス制限がある場合は無理に回避しない設計にします。Thunderbit の即時テンプレートを利用する場合も、対象ページで項目と出力結果を検証してから日次運用へ移します。
2. 求人情報アグリゲーター
Indeedや専門の求人サイトから、職種・企業・地域・掲載日を整理し、ページネーションと重複除去を行ってAirtableへ日次出力する例です。対象サイトごとに利用規約、公式フィードやAPIの有無、転載・保存が認められる項目を確認し、取得元URLと更新日時を残しておくとデータを見直しやすくなります。
3. リード獲得用の連絡先抽出ツール
企業のURLリストから、トップページや問い合わせページに公開されているメール・電話番号を抽出します。Pythonの正規表現またはThunderbitの無料抽出を使ってExcelへ出力できますが、会社情報と個人の連絡先を区別し、誤認識や古い情報を照合してから利用します。営業連絡に使う場合は、適用される個人情報・広告・迷惑連絡に関するルールと、各サイトの利用条件も確認が必要です。
4. 不動産物件の比較ツール
ZillowやRealtor.comから特定地域の物件情報を集め、住所・価格を正規化し、推移を比較してGoogle Sheetsで可視化する例です。対象サイトの利用条件とデータ利用許可を確認し、同一物件の重複、価格の更新日時、掲載終了を区別できるようにすると、比較結果の精度を評価しやすくなります。
5. SNS言及トラッカー
Reddit の JSON API でブランドへの言及を追います。投稿数を集計し、感情分析を行い、時系列データとしてマーケティング分析に活用します。
まとめ:Pythonウェブスクレイピングの実務上の要点
要点を整理します。
- ウェブスクレイピングは情報収集を効率化する手段:営業、調査、業務改善など、目的と取得条件が明確な業務で活用できます。
- Pythonは要件に合わせて構成を選べる:
requests+BeautifulSoupで静的ページを扱い、規模が大きい場合はScrapy、ブラウザ操作が必要な場合は自動化ツールを検討します。 - ThunderbitのようなAIツールはPythonを補完できる:非定型データやノーコードでの試行に向いていますが、抽出精度やカスタマイズ要件を比較して選びます。
- 安定運用には工程全体の設計が必要:事前調査、モジュール化、エラー処理、データ整形、自動化、監視を組み合わせます。
- 規約・権利・法令への配慮を組み込む:robots.txtだけで判断せず、利用規約、個人情報、著作権、サーバー負荷を用途ごとに見直します。
- 変化を前提に改善する:サイト構造やデータ品質の変化を監視し、ログと検証結果をもとに処理を更新します。
実務では、Python、ブラウザ自動化、AIツールのどれか一つを万能な方法と考えるのではなく、対象サイト、処理規模、必要な制御、運用担当者に応じて組み合わせることが重要です。まず代表的な1ページで取得精度と出力形式を確かめ、エラー率や更新工数を記録したうえで、定期運用へ広げるか判断してください。
付録:Python ウェブスクレイピング学習リソース&ツール
実装方法やトラブルを調べる際に参照できるリソースです。外部記事については、公開日と対象バージョンもあわせて確認してください。
- Requests 公式ドキュメント – 扱いやすい HTTP クライアント。
- BeautifulSoup ドキュメント – HTML 解析の基本。
- Scrapy ドキュメント – 大規模・実戦向け。
- Selenium with Python / Playwright for Python – ブラウザ自動化、動的コンテンツ対応。
- Thunderbit Chrome 拡張 – ビジネスユーザー向け AI ウェブスクレイパー。
- Thunderbit ブログ – AI スクレイピングのチュートリアルと事例。
- AIMultiple 法律ガイド – 最新の法律・倫理情報。
- Stack Overflow / Reddit r/webscraping** – コミュニティの Q&A、トラブル相談。
Thunderbitの画面や抽出手順を把握したい場合は、YouTube チャンネルのデモや解説を参照し、実際の対象ページで操作と出力結果を確かめてください。
よくある質問(FAQ)
1. おすすめの Python ウェブスクレイピングライブラリは?
静的ページや小規模な処理ではrequests+BeautifulSoupが基本的な候補です。多数のページを継続して扱う場合はScrapy、ブラウザでのレンダリングや操作が必要な場合はSeleniumやPlaywrightを比較します。非定型データをコードなしで試したい場合は、ThunderbitのようなAIツールも候補になります。
2. JavaScript ベースや動的サイトはどう対応する?
SeleniumやPlaywrightなどでページをレンダリングしてから抽出します。またはNetworkタブでJSONを返すAPI呼び出しを調べ、利用が許可され、必要な認証を満たせる場合に直接取得する方法があります。
3. ウェブスクレイピングは合法?
公開ページのデータであっても、常に収集・保存・再利用できるとは限りません。適用法、robots.txt、サイト利用規約、著作権、GDPR/CCPAなどのプライバシー要件を、対象データと利用目的に応じて検討する必要があります。判断が難しい商用案件では、法務・コンプライアンス担当者へ相談してください。
4. スクレイピングの自動化・定期実行はどうする?
Pythonスクリプトはcron、Airflow、クラウドスケジューラで実行できます。ノーコードで試す場合は、Thunderbitの内蔵スケジューラで自然な言葉による指定とクラウド実行を設定できます。運用前に、現在のプランで利用できる頻度、件数、出力先を確認します。
5. スクレイパーが動かないときは?
まず、サイト構造の変更、HTTP 403/429、認証切れ、JavaScriptによる読み込みを切り分けます。HTML、ステータスコード、セレクター、リクエスト間隔を見直し、アクセス制限が原因の場合は回避を試みず、公式APIや許可された取得方法を検討します。非定型ページで抽出ルールの作成が難しい場合は、ThunderbitのAI機能やブラウザ自動化を比較できます。
用途に合う方法を選んだら、まず代表的な1ページで項目、精度、出力形式を検証してください。Thunderbitを試す場合は、Chrome 拡張のダウンロードから小規模な抽出を始められます。関連する手順や活用例はThunderbit ブログでも紹介しています。
Thunderbit AI ウェブスクレイパーを無料で試す Get Started Free




