

商品ページに並んだ500行の価格を、ひとつずつスプレッドシートに写していく――そんな作業を心待ちにしている人は、まずいないでしょう。(もし楽しめるなら、その忍耐力は本物です。手首のサポーターだけは用意しておいてください。)営業でもオペレーションでも、あるいは競合の一歩先を行きたいだけでも、Webサイトから必要な数字を手作業で集める苦労は、誰しも一度は味わっているはずです。いまやビジネスはWebデータでまわっていますWebデータの自動抽出に対する需要は年々ふくらんでいます。ウェブスクレイピング市場は2032年までに110億ドル超に達すると予測されています。
私はSaaSと自動化の現場に長く身を置いてきて、あらゆるデータ収集のやり方を目にしてきました。執念のかたまりのようなExcelマクロもあれば、深夜2時に応急処置で書き上げたPythonスクリプトもありました。この記事ではまず、PythonのHTMLパーサーで実際のデータをスクレイピングする手順を一緒にたどっていきます(題材はIMDbの映画評価です)。そのうえで2026年のいま、コードを書かずにそのままインサイトへ進めるThunderbitのようなAIツールがなぜ有力なのかもお話しします。
HTMLパーサーとは何か? なぜPythonで使うのか?
最初に、土台となる話を押さえておきましょう。HTMLパーサーは、実際のところ何をしているのでしょうか。たとえるなら、Web専属の司書のような存在です。ページの裏で動いているごちゃごちゃしたHTMLを読み解き、きれいな木構造へと並べ直してくれます。おかげで私たちは、無数の山括弧やdivタグに埋もれることなく、タイトルや価格、リンクといった必要な部分だけを取り出せるわけです。
そしてこの仕事では、Pythonが長く定番の座を守っています。コードが読みやすく、初心者でもとっつきやすいうえに、スクレイピングやパース向けのライブラリがとにかく豊富だからです。ウェブスクレイピングで使われる言語としてPythonが頭ひとつ抜けて人気なのも、学習コストの低さとコミュニティの厚みを考えれば納得です。
PythonのHTMLパーサー主要候補
PythonでHTMLを扱うときによく名前が挙がるライブラリを並べてみます。
- BeautifulSoup: 王道で、初心者にも優しい一本です。保守も続いており、2025年後半には
beautifulsoup44.14.3 がPyPIで公開されました。ここで紹介する内容も、けっして「過去の遺物」向けではありません。 - lxml: 速くて頼もしく、込み入ったクエリにも応えてくれます。
- html5lib: ブラウザさながらに、崩れたHTMLでも寛容に受け止めます。
- PyQuery: PythonでjQuery風のセレクターを書けるのが持ち味です。
- HTMLParser: Pythonに最初から入っているパーサーです。すぐ使える反面、機能は最小限にとどまります。
それぞれ得手不得手はありますが、生のHTMLを構造化データへ変えてくれる点は共通しています。
主な活用例: PythonのHTMLパーサーはビジネスにどう役立つか
Webデータの抽出は、もはやエンジニアやデータサイエンティストだけの領分ではありません。とくに営業やオペレーションの現場では、欠かせない業務として根づいています。その理由を見ていきましょう。
| 活用例(業界) | よく抽出するデータ | ビジネス上の成果 |
|---|---|---|
| 価格モニタリング(小売) | 競合価格、在庫状況 | ダイナミックプライシング、利益率向上 (source) |
| 競合製品インテリジェンス | 商品一覧、レビュー、在庫状況 | ギャップの特定、リード獲得 (source) |
| リード獲得(B2B営業) | 企業名、メールアドレス、連絡先 | 見込み客開拓の自動化、パイプライン拡大 (source) |
| 市場センチメント(マーケティング) | SNS投稿、レビュー、評価 | リアルタイムのフィードバック、トレンド把握 (source) |
| 不動産データ集約 | 物件情報、価格、不動産会社情報 | 市場分析、価格戦略 (source) |
| 採用インテリジェンス | 候補者プロフィール、給与 | 人材ソーシング、給与ベンチマーク (source) |
突き詰めれば、いまだに手作業でデータを写しているなら、それは時間とコストの両方を捨てているのと同じです。
Python HTMLパーサーツールキット:人気ライブラリを比較
では実践へ移りましょう。Python向けの主要なHTMLパーサーを横並びでざっと比べて、用途に合う一本を選べるようにしておきます。
| ライブラリ | 使いやすさ | 速度 | 柔軟性 | 保守の手間 | 向いている用途 |
|---|---|---|---|---|---|
| BeautifulSoup | ⭐⭐⭐⭐⭐ | ⭐⭐ | ⭐⭐⭐ | 中程度 | 初心者、崩れたHTML |
| lxml | ⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | 中程度 | 高速処理、XPath、大規模ドキュメント |
| html5lib | ⭐⭐⭐ | ⭐ | ⭐⭐⭐⭐⭐ | 少ない | ブラウザに近い解析、壊れたHTML |
| PyQuery | ⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ | 中程度 | jQuery経験者、CSSセレクター |
| HTMLParser | ⭐⭐⭐ | ⭐⭐⭐ | ⭐ | 少ない | シンプルな標準機能の作業 |
BeautifulSoup: 初心者にやさしい選択肢
HTMLパースを始めるとき、最初の一本に選ばれやすいのがBeautifulSoupです。構文が素直で、ドキュメントもよく整っており、形の崩れた不完全なHTMLにも文句を言わずに付き合ってくれます(詳しくはこちら)。弱点を挙げるなら、大きなページや複雑なページでは速度が伸びにくいこと、そしてXPathのような高度なセレクターを単体では扱えないことです。
lxml: 高速で強力
スピードを最優先したいとき、あるいはXPathクエリを使いたいときは、lxmlが心強い味方になります(詳細)。Cライブラリを土台にしているため動作が速い一方、インストールに少し手こずることがあり、覚えることもやや多めです。
その他の選択肢: html5lib、PyQuery、HTMLParser
- html5lib: ブラウザと同じ流儀でHTMLを解析します。壊れたマークアップや変則的な書き方に強い反面、速度は控えめです(比較)。
- PyQuery: PythonでjQuery風のセレクターが書けるので、フロントエンドの経験がある人にはなじみやすいはずです(ドキュメント)。
- HTMLParser: Python標準の選択肢です。動作は速く、いつでも使える反面、機能面では物足りなさが残ります。
STEP 1: Python HTMLパーサー環境をセットアップする
何かを解析する前に、まずはPythonの環境を整えるところからです。手順を順に追っていきましょう。
-
Pythonをインストール: 入っていなければ、python.org から取得します。
-
pipをインストール: 通常はPython 3.4以降に同梱されています。ターミナルで
pip --versionを打てば確認できます。 -
ライブラリをインストール(今回はBeautifulSoupとrequestsを使います):
pip install beautifulsoup4 requests lxmlbeautifulsoup4がパーサー本体です。requestsでWebページを取りに行きます。lxmlはBeautifulSoupが内部で使える高速パーサーです。
-
インストールを確認:
python -c "import bs4, requests, lxml; print('All good!')"
つまずいたときのヒント:
- 権限エラーが出たら、
pip install --user ...を試してみてください。 - Mac/Linuxでは
python3とpip3を使う必要がある場合があります。 ModuleNotFoundErrorが出たら、つづりとPython環境をもう一度見直しましょう。
STEP 2: Pythonで最初のWebページをパースする
それでは、IMDbのTop 250映画を実際にスクレイピングしてみます。狙うのは映画タイトル、公開年、評価の3点です。
ページの取得とパース
ステップごとのスクリプトを示します。コピーする前に、ひとつだけ注意があります。IMDbは2023年6月にTop 250ページを刷新しました。そのため、古い記事でいまだに見かける td.titleColumn / td.ratingColumn といったセレクターは、もう何も拾いません。現在のマークアップはコンポーネントシステムが吐き出す ipc- 接頭辞のクラスを使っており、その後もIMDbは2025年半ばを含めて何度か構造を変えています。ですから、この例に戻ってくるたびにDevToolsで現状を確かめる、くらいの心構えでいてください。
import requests
from bs4 import BeautifulSoup
url = "https://www.imdb.com/chart/top/"
headers = {"User-Agent": "Mozilla/5.0"} # ちゃんとしたUAがないとIMDbは簡素なマークアップを返すことがある
resp = requests.get(url, headers=headers)
soup = BeautifulSoup(resp.text, "html.parser")
# 各行はチャートコンテナ配下のリストアイテム
rows = soup.select("li.ipc-metadata-list-summary-item")
for i, row in enumerate(rows[:3], start=1):
title_el = row.select_one("h3.ipc-title__text")
year_el = row.select_one("span.cli-title-metadata-item")
rating_el = row.select_one("span.ipc-rating-star--rating")
title = title_el.get_text(strip=True) if title_el else None
# h3のテキストは「1. ショーシャンクの空に」のように返るので、順位の接頭辞を削除する
if title and ". " in title:
title = title.split(". ", 1)[1]
year = year_el.get_text(strip=True) if year_el else None
rating = rating_el.get_text(strip=True) if rating_el else None
print(f"{i}. {title} ({year}) -- 評価: {rating}")
コードの中で起きていること
requests.get()でページを取得します(自然な見た目のUser-Agentを添えています。IMDbは素のpython-requestsクライアントには簡素なHTMLを返すことがあるためです)。BeautifulSoupがそのHTMLを解析します。li.ipc-metadata-list-summary-itemで各映画の行をつかまえ、その中からselect_one()を使ってh3.ipc-title__textのタイトル、span.cli-title-metadata-itemの年、span.ipc-rating-star--ratingの評価を抜き取ります。- タイトル・年・評価のテキストを取り出し、IMDbがタイトルに付けている順位番号(
"1. ")を取り除きます。
数か月ごとにクラス名の移り変わりを追うのが煩わしければ、別の手もあります。IMDbは同じページに <script type="application/ld+json"> ブロックも置いており、そこに同じデータが構造化された形で入っているのです。json.loads(soup.find("script", type="application/ld+json").string) で読み込み、itemListElement 配列をたどればよいわけです。実運用なら、私はこちらを選びます。先のCSSセレクター版は説明には向いていますが、壊れやすいからです。
出力:
1. ショーシャンクの空に (1994) -- 評価: 9.3
2. ゴッドファーザー (1972) -- 評価: 9.2
3. ダークナイト (2008) -- 評価: 9.0
データの抽出: タイトル、評価、その他を見つける
どのタグやクラスを使うかは、どう見極めたのでしょうか。答えはシンプルで、IMDbページのHTMLを実際にのぞいてみたのです(ブラウザで右クリック > 要素を検証)。あとは規則性を探すだけです。ここでは各映画の行が <li class="ipc-metadata-list-summary-item"> に収まり、タイトルは <h3 class="ipc-title__text">、評価は <span class="ipc-rating-star--rating"> の下にありました。ひとつ忘れてはいけない点があります。IMDbはこのマークアップを何度も入れ替えており、古い解説でおなじみの td.titleColumn レイアウトは2023年6月の刷新を境に使えません。ですから、ここに挙げた正確なクラス文字列はあくまで一例と捉え、実行する前に必ず最新の状態を確かめてください。
プロのヒント: 別のサイトを相手にするときも、最初にHTML構造をのぞいて、固有のクラス名やタグを探すところから始めましょう。
結果の保存とエクスポート
取れたデータをCSVファイルへ書き出してみます。
import csv
movies = []
for i in range(len(title_cells)):
title_cell = title_cells[i]
rating_cell = rating_cells[i]
title = title_cell.a.text
year = title_cell.span.text.strip("()")
rating = rating_cell.strong.text if rating_cell.strong else rating_cell.text
movies.append([title, year, rating])
with open('imdb_top250.csv', 'w', newline='', encoding='utf-8') as f:
writer = csv.writer(f)
writer.writerow(['Title', 'Year', 'Rating'])
writer.writerows(movies)
クレンジングのヒント:
.strip()で余分な空白を落とします。- 欠損データは
ifチェックでさばきます。 - Excelで扱いたいなら、CSVをそのままExcelで開くか、
pandasで.xlsxファイルを書き出します。
STEP 3: HTMLの変更と保守の難しさに対処する
ここからが正念場です。Webサイトはとにかくレイアウトを変えたがります。スクレイパーを困らせるためにわざとやっているのでは、と疑いたくなるほどです。IMDbが class="titleColumn" を class="movieTitle" に変えた瞬間、スクリプトは何も返さなくなります。こうした場面、私も何度も経験しましたし、そのたびにデバッグしてきました。
スクリプトが壊れるとき: 現実のトラブル
よく出くわす問題はこのあたりです。
- セレクターが見つからない: 指定したタグやクラスをコードが拾えない。
- 空の結果: ページ構造が変わったか、コンテンツがJavaScript経由で読み込まれている。
- HTTPエラー: サイト側にボット対策が追加された。
対処の手順:
- 解析しているHTMLが、ブラウザで見えているものと一致しているか確かめます。
- セレクターを新しい構造に合わせて書き直します。
- 動的に読み込まれるコンテンツなら、Seleniumのようなブラウザ自動化に切り替えるか、APIエンドポイントを探す必要があります。
本当の悩みどころは何でしょう? IMDb一つならまだしも、10、50、500ものサイトを相手にすると、データ分析よりスクリプトの修理に時間を取られかねません(開発者の体験談を見る)。
STEP 4: スケールアップ — 手作業のPython HTMLパースに潜むコスト
IMDbにとどまらず、Amazon、Zillow、LinkedIn、さらに十数サイトもスクレイピングしたいとしましょう。サイトごとに専用のスクリプトが要りますし、どこか一つが変わるたびに、またコードエディタに逆戻りです。
見えにくいコスト:
- 保守工数: 初期構築の10倍に達することもあると言われます。
- インフラ: プロキシ、エラーハンドリング、監視がいずれも欠かせません。
- パフォーマンス: 規模を広げるには、並列処理やレート制限への対応が必要になります。
- 品質保証: スクリプトが増えるほど、壊れる箇所も比例して増えていきます。
非技術系のチームにとっては、これがあっという間に立ち行かなくなります。データを一日中コピペするインターンの大群を雇うようなもの、と言えばイメージしやすいでしょうか。しかもそのインターンはPythonスクリプトでできていて、サイトが変わるたびに体調を崩して休むのです。
AIコーディングエージェントについて少しだけ
ノーコードツールへ進む前に、ひとつ寄り道をしておきます。昔ながらの「まずBeautifulSoupを学ぼう」系チュートリアルが書かれた当時には、ほとんど存在しなかった中間の選択肢――AIコーディングエージェントです。Claude CodeやCursorのようなツールは、「IMDbのTop 250を取って、タイトル/年/評価をCSVにまとめて」といった英語の指示をそのまま受け取り、requests + BeautifulSoup の動くスクリプトを一発で下書きしてくれます。先ほど手作業でやったセレクターの整理まで、まとめて面倒を見てくれるのです。ログインやページネーション、クッキーバナーへの対応のように自然言語でブラウザを操作したいなら、Browser Use のようなライブラリを使えば、プロンプトからヘッドレスブラウザを直接動かせます。
とはいえ、難所がそっくり消えてなくなるわけではありません。レート制限、robots.txt、ログイン壁、ボット対策は相変わらずこちらの宿題ですし、IMDbのようにセレクターが静かに壊れたときは、エージェントが何を書いたのかを読み解いて直す必要があります。つまり、エージェントを使うにしても、このチュートリアルで身につけるHTMLパーサーの流れを理解しておくことが、空のリストを前に途方に暮れるのではなく、出力をデバッグできるかどうかの分かれ目になるわけです。
Python HTMLパーサーを超えて: AI搭載の代替案、Thunderbit
ここからが面白いところです。コードを書かず、保守にも煩わされず、サイトが変わっても必要なデータだけがちゃんと取れたら――そんな世界があったらどうでしょう。
それを形にしたのがThunderbitです。2クリックで、どんなWebサイトからでも構造化データを抜き出せるAIウェブスクレイパーのChrome拡張です。Pythonも、スクリプトも、頭痛のタネも要りません。
Python HTMLパーサー vs. Thunderbit: 横並び比較
| 観点 | Python HTMLパーサー | Thunderbit (料金を見る) |
|---|---|---|
| セットアップ時間 | 長い(インストール、実装、デバッグ) | 短い(拡張機能を入れてクリックするだけ) |
| 使いやすさ | コーディングが必要 | コーディング不要。指してクリックするだけ |
| 保守 | 高い(スクリプトが頻繁に壊れる) | 低い(AIが自動で適応) |
| 拡張性 | 複雑(スクリプト、プロキシ、インフラ) | 標準搭載(クラウドスクレイピング、バッチ処理) |
| データ拡張 | 手作業(さらにコードを書く) | 標準搭載(ラベリング、クレンジング、翻訳、サブページ) |
AIで片付くのに、なぜわざわざ自分で組むのでしょう?
なぜWebデータ抽出にAIを使うのか?
ThunderbitのAIエージェントは、ページを読み取り、構造を把握し、変更にも追従します。クラス名が変わっても文句を言わず、眠ることもない、飛び抜けて優秀なインターンが一人いるようなものです。
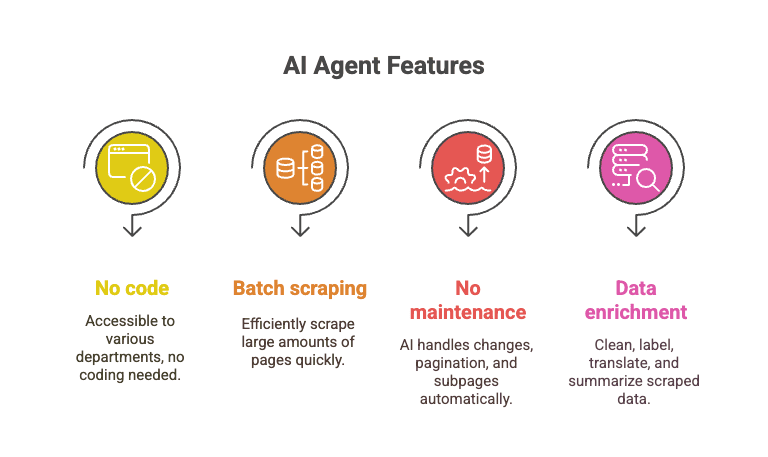
- コード不要: 営業、オペレーション、マーケティングなど、誰でも扱えます。
- バッチスクレイピング: Pythonスクリプト1本をデバッグする間に、10,000ページ超を処理できます。
- 保守不要: レイアウト変更、ページネーション、サブページの対応はAIが引き受けます。
- データ拡張: 抽出と同時に、クレンジング、ラベル付け、翻訳、要約までこなせます。
先ほどのBeautifulSoupの流れの裏側にあるのが、まさに上で触れたIMDbのセレクターの脆さです。ページ構造が変われば、スクリプトは静かに空の結果を返し、こちらは午後いっぱいDevToolsとにらめっこする羽目になります。ノーコードのAIスクレイパーは、その工程を自前の推論レイヤーの奥に隠してくれます。これは正直なところトレードオフでもあります(抽出結果が正しいと、相手を信じることになるからです)。万能の特効薬ではありません。
ステップごとに見る: ThunderbitでIMDbの映画評価をスクレイピングする
先ほどのIMDbの作業を、Thunderbitならどう片付けるのか見てみましょう。
- Thunderbit Chrome拡張機能 をインストールします。
- IMDbのTop 250ページ を開きます。
- Thunderbitアイコンをクリックします。
- 「AIで項目を提案」をクリックします。 Thunderbitがページを読み取り、列(タイトル、年、評価)を提案してくれます。
- 必要に応じて列を確認・調整します。
- 「スクレイプ」をクリックします。 Thunderbitが250行すべてを一瞬で抜き出します。
- Excel、Googleスプレッドシート、Notion、CSVのいずれかへエクスポートします。
以上です。コードも、デバッグも、「どうしてこのリストは空なんだ」と頭を抱える時間もありません。
実際の動きが見たい方は、手順を順に追えるThunderbitのYouTubeチャンネルをのぞいてみてください。別の実例としては、Amazonのスクレイピング手順ガイド もおすすめです。
まとめ: Webデータ需要に合った正しいツールを選ぶ
BeautifulSoupやlxmlといったPythonのHTMLパーサーは、強力で柔軟、しかも無料です。細部まで自分でコントロールしたい開発者で、手を動かすのが苦にならない人には、これ以上ない選択肢でしょう。ただし学習コストは小さくなく、保守の手間もかかり、スクレイピングの規模が大きくなるほど見えないコストもふくらんでいきます。
一方、ビジネスユーザーや営業チーム、そしてコードではなくデータそのものが欲しい人にとっては、Thunderbit のようなAIツールがまさに流れを変える存在になります。コードも保守も要らず、Webデータの抽出・クレンジング・拡張を、大きな規模でこなせるからです。
私のおすすめは? スクリプトを書くのが好きで、隅々までカスタマイズしたいならPythonでいきましょう。でも、時間と心の余裕を大切にするなら、一度Thunderbitを試してみてください。重たい作業はAIに任せられるのに、わざわざ自分でスクリプトを書いて世話を焼く理由が、はたしてどれだけあるでしょうか。
ウェブスクレイピングやデータ抽出、AI自動化をもっと深く知りたい方へ。Thunderbitブログ には、AIでWebサイトのデータをExcelに取り込む方法 や 2025年版ベストなウェブスクレイピングツール&ソフトウェア をはじめ、まだまだ多くのチュートリアルが揃っています。




