

Webサイト上の情報をスプレッドシートへ手入力する作業は、時間がかかるだけでなく、転記ミスや更新漏れも起こりやすい業務です。私は、営業、オペレーション、市場調査の現場で、こうした作業が担当者の負担になっている状況を何度も見てきました。以前は技術者向けと見られがちだったウェブスクレイピングも、現在ではWebデータを業務に取り込むための実用的な選択肢になっています。
背景にはWebデータの増加があります。世界全体のデータ生成量は、2019年から2023年のあいだに約193%も増えました。また、81%もの企業が意思決定の中心にデータを据える一方、95%の組織がHTMLのような非構造化データの扱いを課題として挙げています。
AIであらゆるWebサイトからデータを抽出 Get Started Free
その課題に取り組む入口の一つが、PythonのBeautifulSoupです。本記事では、Python Beautiful Soupの例を順に動かしながら、Webページの取得、HTMLの解析、必要な項目の抽出、CSVやExcelへの保存までを解説します。後半では、AI搭載のウェブスクレイパーであるThunderbitとBeautifulSoupを組み合わせ、抽出作業と後処理を分担する方法も扱います。私自身、力任せの手作業より、再現できる手順として整理することを重視しています。前提となるコーディング経験は要りません。
なお、スクレイピングを実行する前に、対象サイトの利用規約とrobots.txt、著作権、個人情報の取り扱い、アクセス頻度を確かめてください。取得したデータの利用目的を明確にし、対象サイトや第三者へ過度な負荷・不利益を与えない範囲で進めることが重要です。
BeautifulSoupとは何か、なぜウェブスクレイピングに使うのか?
 BeautifulSoupは、HTMLやXMLを解析し、要素を検索・取得・編集できる形に整えるPythonライブラリです。HTMLを木構造として扱えるため、タグ、属性、テキストを条件に、必要なデータを取り出せます。PyPIでは
BeautifulSoupは、HTMLやXMLを解析し、要素を検索・取得・編集できる形に整えるPythonライブラリです。HTMLを木構造として扱えるため、タグ、属性、テキストを条件に、必要なデータを取り出せます。PyPIではbeautifulsoup4 4.14.3が2025年後半に公開されており、本記事では同系統の基本的な解析方法を扱います。商品価格、ニュースの見出し、企業ディレクトリなど、静的HTML内の情報を構造化する場合に候補となります。
BeautifulSoupは記述量が比較的少なく、崩れたHTMLも一定範囲で解析できるため、初学者が基本を学ぶ用途や、小規模な抽出処理に使いやすいライブラリです。利用例や技術情報も多く、問題が起きたときに関連情報を探しやすい点も利点です。
具体的には、次のような場面で使われます。
- ECサイトから商品名、価格、評価を抜き出す
- ニュースサイトから見出し、著者、公開日を取り出す
- 表やディレクトリ(会社一覧や連絡先一覧など)を解析する
- 掲載サイトからメールアドレスや電話番号を集める
- 価格変更や新しい求人情報といった更新を見張る
対象データが取得時点の静的HTMLに含まれている場合、BeautifulSoupは解析と抽出を組み立てやすい選択肢です。JavaScriptの実行後に表示されるデータについては、ブラウザ操作ツールや別の取得方法を検討します。
ウェブスクレイピングにおけるBeautifulSoupの強み
Pythonのスクレイピング関連ライブラリは、対象ページの構造、処理規模、JavaScriptの有無によって使い分けます。BeautifulSoupの主な特徴は次のとおりです。
- シンプルさ: 基本的なHTML解析で必要となる記述が比較的少なく、単発の抽出処理や入門用途に向いています。
- 柔軟性: HTMLが多少崩れている場合でも、使用するパーサーに応じて解析できることがあります。
- 柔軟な構造: 固定されたクロール設計に依存せず、取得済みのHTMLから必要な要素だけを検索できます。
- 連携しやすさ: Webページの取得には
requests、保存にはcsv、表形式の処理にはpandasというように、目的別のライブラリと組み合わせられます。
代表的な選択肢を用途別に整理すると、次のようになります。
| ツール | 得意な用途 | 長所 | 短所 |
|---|---|---|---|
| BeautifulSoup | 静的HTMLの解析、初心者向け | 記述が比較的簡潔で、解析方法を調整しやすい | JavaScript実行後に表示されるデータは直接取得できない |
| Scrapy | 大規模・非同期ジョブ | クロールやデータ処理を一つの構成で管理しやすい | 習得項目が多く、小規模用途では設定が過剰になる場合がある |
| Selenium | JavaScript/動的コンテンツ | ブラウザ操作、フォーム入力、ボタンクリックに対応 | 実行速度が比較的遅く、リソース負荷が高くなりやすい |
静的なページを短いコードで解析したい場合、BeautifulSoupは有力な候補です(medium.com)。JavaScript操作が必要ならSelenium、大規模なクロールを継続運用するならScrapyも含めて比較すると、要件に合う方法を選びやすくなります。
BeautifulSoupを使うためのPython環境の準備
それでは、手を動かす前の環境づくりに移りましょう。手順は以下のとおりです。
-
Pythonをインストールする: python.org から最新版をダウンロードします。
-
仮想環境を作成する(任意ですが推奨):
python -m venv venv source venv/bin/activate # Windowsの場合: venv\Scripts\activate -
BeautifulSoupと依存関係をインストールする:
pip install beautifulsoup4 requests lxml html5libbeautifulsoup4: メインライブラリrequests: Webページ取得用lxmlまたはhtml5lib: 高速で信頼性の高いHTMLパーサー
-
トラブルシューティングのヒント:
- 「pip not found」というエラーが出たら、
pip3かpy -m pipを試してください。 - Mac/Linuxでは、権限の都合で
sudoが要る場合があります。 - Windowsでは、PythonがPATHに登録されているか確かめてください。
- 「pip not found」というエラーが出たら、
セットアップが正しくできたか確かめるには、次の短いテストを実行します。
from bs4 import BeautifulSoup
import requests
html = requests.get("http://example.com").text
soup = BeautifulSoup(html, "html.parser")
print(soup.title)
コンソールに <title>Example Domain</title> と返ってくれば、環境は問題なく整っています(Thunderbit Blog)。
ステップごとのPython Beautiful Soupの実践例
ここからは、Python Beautiful Soupの例を実際に動かしながら見ていきます。例として、公開されているニュースサイトから最新の見出しを集めます。次の手順で進めます。
1. Webページを取得する
import requests
from bs4 import BeautifulSoup
url = "https://www.bbc.com/news"
response = requests.get(url)
html = response.text
2. HTMLを解析する
soup = BeautifulSoup(html, "html.parser")
3. HTML構造を確認する
ページ上で右クリックして「検証」を選び、ブラウザの開発者ツールを開きます。取得したい見出しを選択し、対応するタグ、クラス名、親要素を調べます。ニュースサイトでは見出しがクラス名付きの<h3>タグに入ることがありますが、実際のタグやクラス名はサイトと更新時期によって異なります。
次のマークアップは、セレクタを説明するための例です。実行時には対象ページのHTMLと照合してください。
<h3 class="gs-c-promo-heading__title">見出しタイトル</h3>
4. データを抽出する
headlines = soup.find_all("h3", class_="gs-c-promo-heading__title")
for h in headlines:
print(h.get_text(strip=True))
指定したセレクタが対象ページのHTMLと一致していれば、ニュース見出しが順に出力されます。何も出力されない場合は、手順3に戻り、現在のタグとクラス名に合わせてセレクタを見直します。
5. データをCSVに保存する
あとから分析できるよう、取った見出しをファイルに残しておきます。
import csv
with open("headlines.csv", "w", newline='', encoding="utf-8") as file:
writer = csv.writer(file)
writer.writerow(["headline"])
for h in headlines:
writer.writerow([h.get_text(strip=True)])
これで、ExcelやGoogleスプレッドシートに読み込めるCSVファイルを作成できます。
効果的なデータ抽出のためのHTML構造の理解
セレクタを書く前に、対象ページのHTML構造を把握します。確認する順序は次のとおりです。
- 開発者ツールを開く: ページの上で右クリックし、「検証」を選びます。
- データを見つける: 各要素にマウスを重ねながら、見出し・価格・著者といった情報がどのタグに収まっているかを特定します。
- タグとクラス名を確認する:
class="product-title"やid="main-content"のような識別子を記録します。 - セレクタをテストする: BeautifulSoupの
.find()、.find_all()、.select()を使い、対象要素だけを取得できるか検証します。
HTML全体の階層を読みやすく表示したい場合は、soup.prettify()を使います。Pythonコンソール上で整形結果を見ながら、親子関係や属性を追跡できます。
BeautifulSoupでデータを抽出して構造化する
ブログページから記事のタイトルと著者をまとめて取得する場合は、各article要素を順に処理し、必要な値を辞書として保存します。
articles = soup.find_all("article")
data = []
for article in articles:
title = article.find("h2").get_text(strip=True)
author = article.find("span", class_="author").get_text(strip=True)
data.append({"title": title, "author": author})
実行後のdataは辞書のリストです。この形式にしておくと、CSVへの書き出しや後続の集計処理に渡しやすくなります。
リンクや画像などの属性も、同じ要領で取得できます。
for link in soup.find_all("a"):
print(link.get("href"))
画像のソースを取得する場合は、次のように書きます。
for img in soup.find_all("img"):
print(img.get("src"))
抽出したデータの保存: PythonからExcelやCSVへ
データを辞書のリストとして構造化できたら、標準のcsvモジュールでCSVへ書き出せます。
import csv
with open("articles.csv", "w", newline='', encoding="utf-8") as file:
writer = csv.DictWriter(file, fieldnames=["title", "author"])
writer.writeheader()
for row in data:
writer.writerow(row)
pandasを使用している場合は、DataFrameに変換してCSVまたはExcelへ保存できます。
import pandas as pd
df = pd.DataFrame(data)
df.to_csv("articles.csv", index=False)
df.to_excel("articles.xlsx", index=False)
文字化けや特殊文字の欠落を防ぐため、保存時のエンコーディングはUTF-8に統一します。特に多言語データでは、取得から保存まで同じ文字コードを使うことが重要です。
ケーススタディ: BeautifulSoupでニュースサイトのデータをスクレイピングする
もう一歩踏み込んだPython Beautiful Soupの例として、ニュースサイトから記事タイトル・著者・公開日の3点をまとめて取り出します。
題材として、CNN の記事データを扱います。
import requests
from bs4 import BeautifulSoup
import csv
url = "https://edition.cnn.com/world"
response = requests.get(url)
soup = BeautifulSoup(response.content, "html.parser")
articles = soup.find_all("article")
data = []
for article in articles:
title_tag = article.find("h3")
date_tag = article.find("span", class_="date")
author_tag = article.find("span", class_="author")
title = title_tag.get_text(strip=True) if title_tag else ""
date = date_tag.get_text(strip=True) if date_tag else ""
author = author_tag.get_text(strip=True) if author_tag else ""
data.append({"title": title, "date": date, "author": author})
with open("cnn_articles.csv", "w", newline='', encoding="utf-8") as file:
writer = csv.DictWriter(file, fieldnames=["title", "date", "author"])
writer.writeheader()
for row in data:
writer.writerow(row)
このスクリプトは最新記事を集め、タイトル・日付・著者を抜き出してCSVに落とします。ただし動くのは、CNNの今のマークアップが上のタグ構造と噛み合っている場合に限られます。大手ニュースサイトはクラス名やDOMの作りをしょっちゅう変えるため、本番のデータに当てる前に、もう一度ページを開いて確かめる習慣をつけてください。骨格の部分——<article>コンテナをたどり、その内側でfindしていくやり方——は比較的崩れにくい一方、"date"や"author"といった具体的なクラス名は、そのときのページに合わせて差し替える前提の仮置きだと思っておきましょう。
BeautifulSoupとThunderbitを組み合わせる手順
Thunderbitは、Webページ上の情報を表形式で取得するためのAI搭載ウェブスクレイパーのChrome拡張です。HTMLやセレクタを手作業で調べる工程を減らしたい場合に、次の機能を利用できます。
- 「AIで項目を提案」を使う: Thunderbitがページを読み取り、抽出候補となるデータ項目を提案します。提案結果はページ構成によって異なるため、必要な列とサンプル値を見てから実行します。
- サブページをスクレイピングする: 個別の商品ページや記事ページへのリンクをたどり、追加情報を取得できます。対象ページのリンク構造やアクセス条件によって、取得できる範囲は異なります。
- 即座にエクスポートする: 1クリックでExcel、Googleスプレッドシート、Airtable、Notionへ直接送れます。利用できる出力先や接続条件は、プランと連携先の仕様に左右されます。
- ページネーションに対応する: 複数ページにまたがるデータもスクレイピングできます(無限スクロールも含みます)。ただし、ページの読み込み方式によって設定や結果は異なります。
- 定期実行を設定する: 繰り返しジョブを設定し、定期的なデータ更新に利用できます。実行頻度や上限は利用プランの範囲内で設計します。
私が実務で使っている、両者を組み合わせた手順は次のとおりです。
- 入口はThunderbit: 対象サイトを開いてThunderbitのアイコンを押し、「AIで項目を提案」でタイトル・著者・日付などの候補列を作成します。抽出前に、数件の値が想定した項目と一致しているかを検証します。
- 結果を書き出す: 取得したデータをCSVで保存するか、Googleスプレッドシートへ出力します。
- 仕上げはPython: テキストの整形、重複の除去、別ソースとの結合にはpandasを使います。HTML断片を再解析する必要がある場合はBeautifulSoupを組み合わせます。
この役割分担は、ページ上の項目を短時間で表にした後、Pythonで独自の整形や分析を加えたい場合に向いています。抽出精度や利用できる機能は対象ページとプランによって異なるため、業務へ組み込む前に代表的なページで結果と出力形式を比較します。
ThunderbitとBeautifulSoupを併用する利点と適用範囲
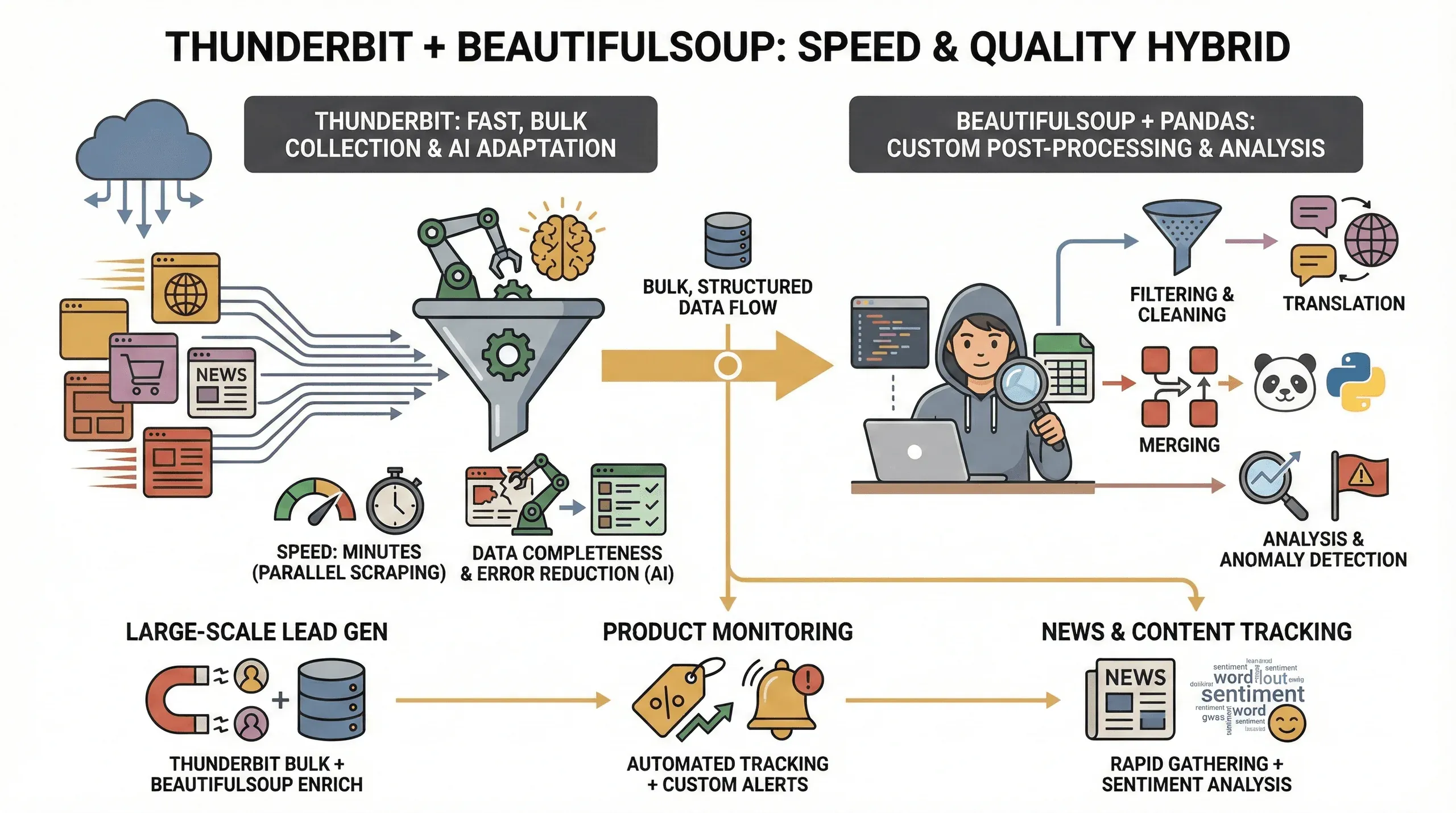 ThunderbitでWebページから表データを取得し、Pythonで後処理する構成には、主に次の利点があります。
ThunderbitでWebページから表データを取得し、Pythonで後処理する構成には、主に次の利点があります。
- スピード: Thunderbitは複数ページを並行処理できます。クラウドモードでは一度に最大50ページという条件が示されており、対象ページの構成や通信条件によっては、手作業で何時間もかかる処理を数分まで短縮できる場合があります。利用可能な同時処理数は現在のプラン条件に従います。
- データの網羅性: AIによる項目検出は、レイアウトが一部異なるページをまとめて処理する際に役立ちます。ただし、必須項目の欠損や誤認識がないか、抽出後の行を検証する必要があります。
- 保守作業の削減: クラス名が変わった場合でも、実行時にページを再解析することで設定変更を減らせることがあります。大幅なDOM変更や認証条件の変更では、抽出設定の見直しが必要です。
- 高度な後処理: 絞り込みや複数データセットの結合はpandasで行い、HTML断片の再解析が必要な場合はBeautifulSoupを使うなど、処理内容に応じて役割を分けられます。
この組み合わせは、たとえば次のような場面で利用できます。
- 大規模なリード獲得: Thunderbitで大量のデータを集め、BeautifulSoupで整形・補完する
- 商品モニタリング: Thunderbitが反復作業を引き受け、BeautifulSoupで傾向分析や異常検知を行う
- ニュースやコンテンツの追跡: Thunderbitで記事を素早く集め、その後Pythonで感情分析やキーワード抽出を行う
運用時は、処理件数だけでなく、必須項目の取得率、重複行、更新頻度、処理時間を記録すると、併用する効果と修正箇所を判断しやすくなります。
BeautifulSoupでよくある問題の対処法
Thunderbit Chrome拡張を試す AIを使って、どんなWebサイトでも2クリックで抽出できます。 Get Started Free
スクレイピングでは、ページの表示方式やアクセス条件によって対応方法が異なります。代表的な問題と対処の考え方を整理します。
- 動的コンテンツ: 無限スクロールやAJAXなど、JavaScriptの実行後に読み込まれるデータはBeautifulSoup単体では直接取得できません。ブラウザ操作が必要な場合はSeleniumやThunderbitのブラウザモードが候補になりますが、ログイン状態やページ構成によって結果は異なります。
- ボット対策・アクセス制限: アクセスが拒否された場合は、回避を試みる前に、対象サイトの利用規約、
robots.txt、許可されている取得方法を見直します。User-Agentはアクセス元を適切に示す目的で設定し、リクエスト間隔と件数を抑えます。Thunderbitのクラウドスクレイピングも、対象サイトが認める範囲で利用します。 - HTML構造の変更: スクリプトが急に動かなくなった場合は、HTMLやクラス名の変更を調べ、セレクタを修正します。ThunderbitのAIで項目候補を作り直す場合も、変更後のページで必須列が取得できるかを検証します。
- データ欠損:
.get_text()に進む前に、対象要素が存在するかを判定します。属性は[]ではなく.get()で取得すると、値がない場合の処理を分岐させやすくなります。 - 文字エンコーディングの問題: 特殊文字を取りこぼさないよう、ファイルはUTF-8で保存します。
実行前には、対象サイトの利用規約とrobots.txtだけでなく、著作権、個人情報、取得データの利用目的、サーバーへの負荷も検討します。許可範囲が不明な場合は、アクセス量を増やさず、サイト運営者への許諾や別の取得方法を検討してください。
まとめと重要ポイント
BeautifulSoupを使ったウェブスクレイピングでは、HTMLの構造を把握し、取得、解析、保存の各工程を分けて組み立てることが重要です。このチュートリアルの要点は次のとおりです。
- BeautifulSoupは、静的HTMLを解析し、Pythonで構造化データを取り出す方法を学ぶ際の有力な選択肢です。
- 環境構築は、Python、pip、必要なライブラリを順に用意すれば進められます。
- HTMLの下見では、タグ、クラス名、親子関係を把握し、セレクタが対象データだけを取得するか検証します。
- CSV/Excelへの書き出しまで実装すると、抽出結果を集計や業務分析へ渡しやすくなります。
- Thunderbitとの併用は、AIによる項目検出、複数ページの取得、対応する出力先へのエクスポートを利用したいビジネスユーザーや非エンジニアにとって候補になります。利用できる範囲は対象ページとプランによって異なります。
- 役割分担型のワークフローでは、Thunderbitでページ上のデータを表にし、Pythonで整形や分析を加えることで、速度、品質、柔軟性を要件に合わせて調整できます。
まずは基本的なBeautifulSoupスクリプトを実行し、取得件数と欠損の有無を記録します。続けて同じ対象ページをThunderbitのAIウェブスクレイパーで試し、抽出精度、処理時間、出力形式を比較すると、併用する価値を判断しやすくなります。実行時は対象サイトの規約とデータの利用目的を守り、段階的に対象範囲を広げてください。関連する実践ガイドはThunderbit Blogで紹介しています。
用途に合う取得方法を選び、再現できる手順として記録しておくことが、安定したデータ収集につながります。
Thunderbit AIウェブスクレイパーを試す Get Started Free
よくある質問
1. BeautifulSoupとは何ですか?何に使いますか?
HTMLやXMLの文書を解析するためのPythonライブラリが、BeautifulSoupです。Webページの中身を取り出し、リストや表といった構造化された形へ整える用途に向いているため、ウェブスクレイピングの定番として広く使われています。
2. BeautifulSoupはSeleniumやScrapyと比べてどうですか?
BeautifulSoupは取得済みの静的HTMLを比較的短いコードで解析したい場合、SeleniumはJavaScriptの実行やブラウザ操作が必要な場合、Scrapyは大規模な非同期クロールを設計・運用する場合に向いています。対象ページの表示方式と処理規模に応じて選びます。
3. BeautifulSoupとThunderbitを一緒に使えますか?
組み合わせて利用できます。ThunderbitでWebページから項目を抽出して表形式で出力し、Pythonで整形、重複除去、結合などを行う構成です。HTML断片を再解析する場合はBeautifulSoup、CSVなどの表データを処理する場合はpandasを使うと役割を分けやすくなります。Thunderbitの抽出結果と利用可能な出力先は、対象ページ、設定、プランによって異なります。
4. BeautifulSoupを使ったウェブスクレイピングでは、どんな課題がよくありますか?
代表的なのは、動的コンテンツ、アクセス制限、HTML構造の変更、データ欠損です。動的ページではSeleniumやThunderbitのブラウザモードが候補になりますが、アクセス制限を回避する目的では使わず、対象サイトの利用規約、robots.txt、著作権、個人情報、アクセス負荷を考慮して取得方法を選びます。
5. BeautifulSoupで抽出したデータをExcelやCSVに書き出すにはどうすればよいですか?
Python標準のcsvモジュール、あるいはpandasライブラリを使えば、抜き出したデータをCSVやExcelとして保存できます。特殊文字を保持しやすくするため、保存時のエンコーディングはUTF-8を基本とします。
まずは対象ページを一つ選び、取得したい列、抽出結果、出力形式を比較してください。ThunderbitのChrome拡張機能 を利用する場合も、同じページで結果を検証してから対象範囲を広げると、BeautifulSoupとの役割を判断しやすくなります。チュートリアルやヒントをさらに探すなら、Thunderbit Blog が役立ちます。
さらに詳しく




