ビジネス向けにオンラインでデータを購入したことがあるなら、あの感じに心当たりがあるはずです。理想のデータセットを探しているうちに、まるでアボカドを選ぶ買い物みたいになって、当たりもあれば、ぐずぐずに熟れすぎたものをつかむこともある。そもそも、自分が正しい売り場にいるのかどうかすら分からなくなることもあります。いまのデータ主導の世界では、公開データセットが、より賢いマーケティングから精度の高い競合分析まで、あらゆるものを支えています。しかし、データを活用して成長を目指す企業が増えるほど、本当の課題は「公開データを見つけること」だけではありません。買ったデータが本当に使えるのか、信頼できるのか、そして自社の業務フローにそのまま組み込めるのかを見極めることが重要なのです。
私は、公開データを成長に活かしたいチームと多く関わってきましたが、隠れたコスト、怪しいベンダー、見た目は良いのに実務では使いものにならないデータに、どれほど簡単に足を取られるかを何度も目の当たりにしてきました。このガイドでは、公開データセットを探し、評価し、活用するための実践的な手順と、そこで得た教訓をお伝えします。生の情報を、実際のビジネス成果へと変えていきましょう。
ビジネス成長のために公開データセットを購入する価値
まずは「なぜ買うのか」から始めましょう。なぜ多くの企業がオンラインでデータを購入したがるのでしょうか。また、有料の公開データは無料データと何が違うのでしょうか。
端的に言えば、公開データセットはいまやビジネス戦略とROIの中核を担う存在です。最近の調査によると、。また、組織のおよそ4分の1は、意思決定のほぼすべてをデータ主導で行っています。その効果は実際に表れており、。
公開データセットは、さまざまな形で成長を後押しします。
- リード獲得: CRMに新しい連絡先や企業プロフィールを追加できます。
- 市場調査: 競合の価格、製品リリース、顧客の声を追跡できます。
- 業務効率化: 手作業のリサーチを自動化し、トレンドを監視し、給与水準をベンチマークできます。
ただし、ここで重要なのは、無料の公開データ(政府ポータルやオープンデータセットなど)は、多くの場合「現状のまま」で提供されるという点です。欠損があったり、雑然としていたり、古かったりします。無料の子犬をもらうようなもので、かわいいけれど、その後の世話にかなり手間がかかる、という感じです。有料データセットはその点、信頼性、完全性、使いやすさを重視して整備されています。ベンダーがクレンジング、更新、構造化まで担ってくれるので、自分でやる必要がありません。多くの企業にとっては、無料データを自力で扱うより、品質の高いデータにお金を払うほうがはるかに費用対効果が高いのです。特に、クレンジングや統合作業に何時間も、場合によっては人件費まで吸い取られるならなおさらです。
オンラインでデータを購入する際の主な課題
データを買うことが、デリバリーを注文するくらい簡単ならいいのですが、現実は違います。どんなに優秀なチームでも、いくつかの壁にぶつかります。
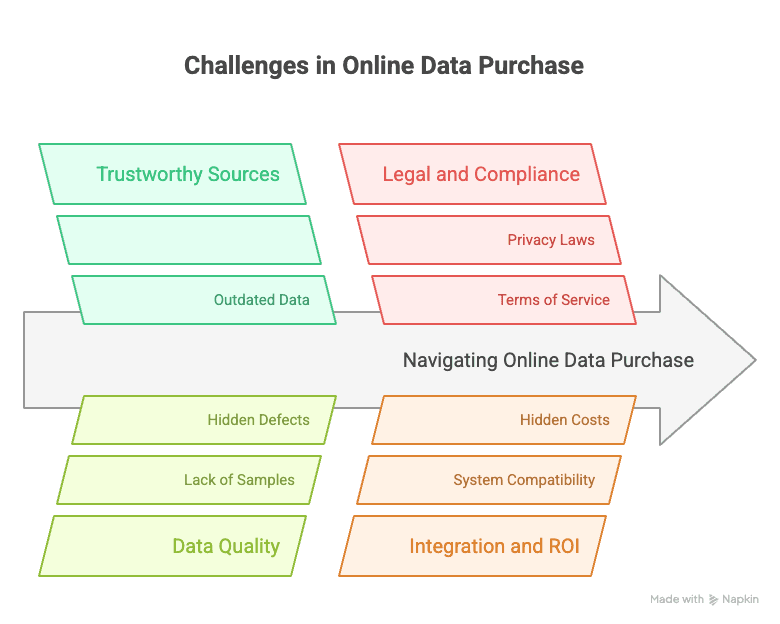
- 信頼できる情報源を見つける: インターネットにはデータマーケットプレイスやベンダーがあふれていますが、どれも同じではありません。古いデータや出所の怪しいデータを売るところもあれば、単純に信用できないところもあります。。
- データ品質を確認する: 多くのデータセットは説明文では魅力的に見えますが、実物を確認できるのは支払い後ということも少なくありません。サンプルを提供しないマーケットプレイスもあり、いわば“ハズレ”を買うリスクがあります。
- 法的・コンプライアンス上のリスク: データが「公開」されているからといって、好きに使ってよいとは限りません。GDPRやCCPAのようなプライバシー法、あるいはサイトの利用規約によって、許される用途が制限されることがあります。ベンダーのすべてがコンプライアンスを保証しているわけではなく、。
- 統合の面倒: データの質が良くても、既存のシステムやワークフローに合わないことがあります。形式変換、クレンジング、マージが必要になり、時間もコストもかかります。
- ROIの不確実性: 表示価格はあくまでスタート地点です。統合、クレンジング、継続的な保守には見えにくいコストがあります。そして、そのデータの価値は実際に使ってみるまで分からないことも多いのです。
私の経験では、本当の課題は単にデータを見つけることではなく、それを本当にビジネス成果につなげられるかどうかです。だから私はいつも、データ評価チェックリストを使うことをおすすめしています。確認項目は、鮮度、範囲、完全性、コンプライアンス、そして統合性です。
信頼できる公開データセットの見つけ方
では、実際にオンラインでデータを購入したいとき、どこへ行けばよいのでしょうか。主な選択肢を、それぞれの特徴とともに見ていきましょう。
データマーケットプレイス
データセットのAmazonのようなものだと考えてください。Snowflake Marketplace、AWS Data Exchange、Oracle Data Marketplaceのようなプラットフォームでは、さまざまな提供元の何千ものデータセットを閲覧できます。消費者属性からB2B企業属性、地理空間データまで、幅広く見つかります。
メリット: 種類が豊富、比較しやすい、クラウドツールと直接連携できることもある。
デメリット: 品質にばらつきがあり、すべてのデータが検証済みとは限らず、結局は統合やクレンジングを自分で行う必要があります。買い手責任の世界です。細則までよく確認しましょう。
政府・オープンデータポータル
や のようなサイトでは、経済から医療まで、幅広い分野の無料で信頼性の高いデータを提供しています。市場調査やベンチマークに最適です。
メリット: 無料で、信頼性が高いことが多く、ライセンス周りの面倒も少ない。
デメリット: データが古い、構造が整っていない、ビジネス用途に最適化されていないことがあります。たいてい多くのクレンジングが必要です。
専門データベンダー
ZoomInfo、Dun & Bradstreet、Experian、S&P Global Market Intelligence のような企業は、B2Bの連絡先、信用情報、財務データなど、整備されたデータセットを販売して生計を立てています。
メリット: 高品質で、カバー範囲が深く、サポートや分析ツールが付くことも多い。
デメリット: 価格が高く、サブスクリプションに縛られることがあります。必要以上のものに払っていないか確認しましょう。
Webスクレイピングサービス、または自分でスクレイピングする方法
必要なデータが見つからなければ、自分で集めることもできます。従来のWebスクレイピングツールを使うか、代行サービスに依頼する方法です。ここから少し面白くなり、同時に少し厄介にもなります。
メリット: 完全にカスタマイズでき、欲しいものをそのまま取れる。
デメリット: 技術的なハードル、法的リスク、保守の手間があります。これについては次のセクションで詳しく見ます。
ワンポイント: 購入前には必ずサンプルかプレビューを依頼しましょう。提供を渋るベンダーは、赤信号だと考えてください。
購入前に公開データセットを評価する方法
いよいよ本番です。1円たりとも払う前に、次のチェックリストを確認しましょう。
| 評価基準 | 確認ポイント |
|---|---|
| 鮮度 | データはいつ更新されたか。定期的に更新されているか。 |
| 範囲と完全性 | 必要な範囲をカバーしているか。メール、価格、所在地などの主要項目は十分に埋まっているか。 |
| 正確性と信頼性 | ベンダーはデータソースを説明しているか。いくつかのレコードを照合できるか。 |
| 形式と統合性 | チームが使える形式か(CSV、JSON、API など)。列名は分かりやすく、データ型は一貫しているか。 |
| 法的コンプライアンス | 利用制限はあるか。GDPR/CCPA に準拠しているか。 |
| ベンダーサポートとSLA | エラーが起きたらどうなるか。問い合わせ先や返金ポリシーはあるか。 |
可能であれば、自分のワークフローでサンプルを試しましょう。CRMや分析ツールに読み込んで、問題なく使えるか確認します。大量のデータセットを買ったのに、レコードの90%が使いものにならない、あるいは重要項目が抜けている、という企業を何度も見てきました。最初に少し丁寧に確認しておけば、あとで大きな痛手を避けられます。
従来のデータ収集方法がうまくいかない理由
ここで、避けて通れない話をしましょう。従来型のWebスクレイピングです。私は、多くのチームが自作スクレイパーを作ろうとして、結局はいたちごっこに終わっているのを見てきました。
なぜ昔ながらの方法は苦戦するのでしょうか。
- 現代のWebサイトは複雑: 動的コンテンツ、JavaScript、無限スクロール、入れ子になったコメントなどがあり、基本的なスクレイパーでは追いつきません。。
- サイトが頻繁に変わる: HTMLを少し変えただけで、スクレイパーが壊れることがあります。保守はもはやフルタイムの仕事です。
- スクレイピング対策: CAPTCHA、IPブロック、ログイン必須などで、作業が止まってしまうことがあります。
- 手動設定が多い: セレクターを一つひとつ探し、ページネーションを組み、サブページも処理しなければなりません。手間がかかるうえ、ミスもしやすいです。
- データが抜けやすい: レビューや画像のような隠れたコンテンツや入れ子のコンテンツは、見落とされがちです。
その結果どうなるか。動いたとしても壊れやすく、維持管理が大変です。多くのビジネスユーザーにとっては、そこまでの手間をかける価値はありません。
Thunderbit: 公開データをより賢く購入・収集する方法
ここからが、私が特にわくわくするところです。 では、これまでとは違うアプローチを採用しています。壊れやすいコードやCSSセレクターに頼るのではなく、**ThunderbitはAIでWebページを意味ベースで「読む」**のです。
仕組みはこうです。
- 意味理解: ThunderbitはWebページをMarkdown風の形式に変換し、構造と意味(見出し、リスト、表など)を保ちます。AIはその構造を解析し、人間のように何が重要かを見つけます。
- レイアウト変更に強い: サイトのデザインが変わっても、意味が変わらない限り、ThunderbitのAIは必要なデータを見つけられます。
- 動的コンテンツに対応: 無限スクロール、「さらに表示」ボタン、JavaScript要素も、Thunderbitが自動で検出して操作します。
- サブページのスクレイピング: 詳細ページへのリンクをたどって、追加項目でデータセットを拡充できます。追加のスクリプトは不要です。
- コーディング不要: ビジネスユーザーは「AIで項目を提案」をクリックし、推奨カラムを確認して、「スクレイプ」を押すだけです。それだけで完了します。
その結果、複雑で変化の激しいサイトからでも、面倒な作業なしで、構造化された信頼できるデータを手に入れられます。
Thunderbitで公開データ収集プロセスを標準化する
私がよく目にする大きな悩みの一つが、やり方のばらつきです。データソースが増えるたびに、毎回ゼロから作り直すことになります。新しい項目、新しい形式、新しいクレンジング工程。Thunderbitは、このプロセス全体を標準化し、自動化するのに役立ちます。
- AIで項目を提案: Thunderbitがページを解析し、適切な列とデータ型を提案するので、何を抽出すべきか迷う必要がありません。
- サブページスクレイピング: さらに詳しい情報が必要ですか。Thunderbitは各リンク先のサブページを自動で訪問し、企業プロフィール、製品仕様、連絡先などの追加情報を取得できます。
- ページネーションと無限スクロール: Thunderbitはこれらのパターンを検出して処理するので、常に完全なデータセットを取得できます。
- 内蔵のデータクレンジング: スクレイピングしながら、カスタムプロンプトでデータの正規化、分類、整形ができます。
- 簡単なエクスポート: データはワンクリックで Excel、Google Sheets、Airtable、Notion にそのまま送れます。もうコピペ作業に時間を取られる必要はありません。
- スケジュールスクレイピング: 毎日、毎週など、必要な頻度で定期取得を自動化できます。
この組み合わせにより、エンジニアチームやWebスクレイピングの博士号がなくても、大規模にデータを収集・拡充・標準化できます。
公開データセット購入のROIを計算する
では、費用対効果の話をしましょう。オンラインでデータを買う価値があるかどうか、どう判断すればいいのでしょうか。
本当のコスト
- 取得費用: データセット本体、またはサブスクリプションの価格。
- 統合費用: データをクレンジングし、整形し、読み込むための時間と労力。
- 保守費用: 継続的な更新、サブスクリプション、スクレイピングツールのコスト。
覚えておきたいのは、ということです。雑然としたデータセットを買うと、その分だけ時間もストレスも増えます。
リターン
- 売上向上: リード増加、ターゲティング精度向上、価格戦略の最適化。
- コスト削減: 手作業のリサーチを自動化し、人件費を減らす。
- より良い意思決定: ミスを避け、機会を早く見つける。
- 市場投入の迅速化: 製品やキャンペーンをより早く展開できる。
シンプルなROIの式は次のとおりです。
(総便益 − 総コスト) / 総コスト × 100%
たとえば、データに1万ドル(すべてのコスト込み)を使い、それによって新規受注が5万ドル増えたなら、ROIは400%です。悪くありません。
ワンポイント: まずは小さく試しましょう。Thunderbitの無料エクスポートを使って少量のサンプルをスクレイピングし、ワークフローでテストしてから、本格導入するのがおすすめです。
ステップバイステップガイド: Thunderbitで公開データセットを購入・活用する方法
実際にやってみましょう。現場で検証してきた、実践的なロードマップをご紹介します。
ステップ1: データ要件を定義する
まずはビジネス目的から始めます。リード獲得が目的ですか。競合監視ですか。給与ベンチマークですか。次の点をできるだけ具体的にしましょう。
- 必要な項目(例: 企業名、メール、価格、所在地)
- 件数(何件必要か)
- 頻度(一回限りか、継続的か)
- 形式(CSV、Excel、Google Sheets など)
書き出しておきましょう。要件が明確なほど、選択肢を評価しやすくなり、無駄な支出も減らせます。
ステップ2: データセットを見つけて評価する
- データマーケットプレイス、ベンダーカタログ、オープンデータポータルを確認する。
- 候補を絞る: 条件に合うデータセットを探します。
- サンプルやプレビューを依頼する: 用意されていない場合は、Thunderbitを使って公開サイトから少量をスクレイピングします。
- 評価チェックリストで確認する: 鮮度、範囲、完全性、正確性、形式、コンプライアンス、サポート。
- 自分のワークフローで試す: サンプルをCRMや分析ツールに読み込んでみましょう。合っていますか。主要項目は埋まっていますか。
合格なら次へ進みましょう。不合格なら、別の候補を探すか、Thunderbitで自分でスクレイピングすることも検討してください。
ステップ3: Thunderbitでデータを収集し、整える
私が を使うときの流れはこんな感じです。もちろん、あなたも同じようにできます。
- をインストールする。
- 対象サイトへ移動する(ディレクトリ、一覧ページ、検索結果など)。
- 「AIで項目を提案」をクリックする。 Thunderbitが列とデータ型を提案してくれます。
- 必要に応じて項目を確認・調整する。 特別な整形や拡充が必要なら、カスタムプロンプトを追加します。
- リンク先ページの詳細が必要なら、サブページスクレイピングを有効にする。
- ページネーションや無限スクロールを処理する。 Thunderbitが通常は自動で検出します。
- 「スクレイプ」をクリックする。 Thunderbitがデータテーブルを埋めていく様子を見られます。
- Excel、Google Sheets、Airtable、Notion にエクスポートする。 すべてワンクリックです。
- データを確認する。 調整が必要なら修正して再実行します。
Thunderbitの無料プランなら、数ページでこの流れを試せるので、拡大する前に結果を確認できます。
ステップ4: テストし、統合し、拡大する
- データ品質とROIをテストする: 新しいデータを使って、小規模なキャンペーンや分析を行います。リードは有効ですか。インサイトは実行可能ですか。
- 業務ツールに統合する: CRM、BIダッシュボード、マーケティングオートメーション基盤に取り込みます。
- 拡大のために自動化する: Thunderbitのスケジュールスクレイピングで、データを新鮮に保ちます。
- 監視して改善する: データ品質を見ながら、必要に応じて手順を調整します。
まとめと重要ポイント
オンラインで公開データセットを購入することは、ビジネス成長の強力な武器になります。ただし、明確な計画と適切なツールがあってこそです。私が学んだことを、少し遠回りも含めてまとめると次のとおりです。
- まず目的を明確にする。 何が必要で、なぜ必要なのかをはっきりさせましょう。
- 情報源を見極める。 購入前にチェックリストでデータセットを評価しましょう。
- 隠れたコストに注意する。 クレンジング、統合、保守も忘れずに見積もりましょう。
- 高度なツールを活用する。 ThunderbitのAI活用アプローチなら、非エンジニアでも、より速く、より信頼性高く、より手軽にデータ収集できます。
- 標準化し、自動化する。 毎回ゼロから作り直さないよう、再現可能なワークフローを作りましょう。
- ROIを測定する。 小さく試して、うまくいくものを大きく伸ばしましょう。
正しいやり方を取れば、面倒な作業なしで公開データを本当の競争優位に変えられます。どれほど簡単か試してみたいなら、 をぜひ使ってみてください。無料プランは、まずは気軽に試すのにぴったりです。
データ探しを楽しんでください。そして、アボカドがいつも完熟でありますように。
FAQ
1. 無料の公開データセットと有料の公開データセットの違いは何ですか?
無料データセット(政府ポータルなど)は、不完全だったり、古かったり、構造が不十分だったりすることが多く、大きなクレンジングが必要です。有料データセットは、信頼性、完全性、統合のしやすさを重視して整備されているため、時間と労力を節約できます。
2. 購入前にデータセットの品質をどう見極めればよいですか?
必ずサンプルやプレビューを依頼しましょう。チェックリストを使って、鮮度、完全性、正確性、形式、コンプライアンスを確認します。サンプルを実際のワークフローで試し、自分の要件に合うか確かめてください。
3. 公開データをオンラインで購入する際の法的リスクは何ですか?
「公開」されているデータでも、制限がないとは限りません。ベンダーがプライバシー法(GDPRやCCPAなど)に準拠しているか、そして自分の利用目的にそのデータを使う権利があるかを確認しましょう。
4. Thunderbitは、従来のスクレイパーと比べてどのようにデータ収集を簡単にしますか?
ThunderbitはAIでWebページを意味ベースで理解し、動的コンテンツやレイアウト変更に対応し、項目選定を自動化し、サブページのスクレイピングもサポートします。しかも、ノーコードの画面で操作でき、よく使うツールへ直接エクスポートできます。
5. 公開データセット購入のROIはどう計算しますか?
すべてのコスト(取得、統合、保守)を合算し、得られる効果(売上増、コスト削減、意思決定の改善)を見積もります。小規模サンプルで試して、実際の効果を確認してから拡大しましょう。式は (総便益 − 総コスト) / 総コスト × 100% です。
さらに詳しく: