

「競合サイトの商品情報、まとめて取れたら便利なのに」——ウェブスクレイピングに初めて手を伸ばすきっかけは、たいていこんな素朴な動機です。検索すればBeautifulSoupの名前はすぐ出てきますが、最初は「自分にできるのかな…」と尻込みしてしまう人も多いはず。それでも何度か試し、pip install beautifulsoup4 を打ち込んで、HTMLの見出しをきれいに抜き出せた瞬間の「おっ、取れた!」という手応え——Python初心者なら、ほぼ全員が通る道です。この小さな成功体験が、そのままスクレイピングの世界への入口になることも珍しくありません。
ウェブスクレイピングを始めて最初に名前を聞くツールといえば、やはりBeautifulSoupでしょう。理由はいたってシンプルで、扱いやすくて頼れるうえ、10年以上にわたってPython界隈の定番であり続けているからです。この記事では、pipでのBeautifulSoupインストール手順から、実際に動くPythonコード例、そして今も多くの開発者やデータ分析担当に選ばれ続ける理由まで、ひと通り整理します。あわせて、BeautifulSoupが苦手とする領域や、最近とくに非エンジニア層を中心にAI搭載のThunderbitへ移る動きが広がっている背景についても、包み隠さずお伝えします。
BeautifulSoupとは?なぜ今も選ばれ続けているのか
BeautifulSoupとAIウェブスクレイパー徹底比較 Get Started Free
まずは土台から。BeautifulSoupの正体を一言でいえば、Python用の「とびきり扱いやすいHTMLパーサー」です。HTMLやXMLを渡すと、Pythonコードから検索・抽出・加工が自在にできるツリー構造へと変換してくれます。ウェブページの中身を“透明化”して、入り組んだタグや属性もそのままデータとして触れるようにする——そんなイメージです。
BeautifulSoupが今も人気な理由
新しいスクレイピングフレームワークが次々と現れても、BeautifulSoupはPython初心者の定番という地位を譲りません。実際、PyPIでのダウンロードは月間1億5千万回超に達し、Stack Overflowにも3万2千件を超える質問が積み上がっています。つまり、初心者がつまずいてもすぐ答えにたどり着ける、大きなコミュニティと情報の蓄積があるわけです。
主な活用例:
- ECサイトの商品情報抽出(商品名・価格・評価など)
- ニュースやブログの見出し収集・分析
- テーブルやディレクトリの構造化データ抽出(例:企業リスト)
- リード獲得(メールアドレスや電話番号の抽出)
- 価格変動や新着情報の監視
BeautifulSoupがとくに得意とするのは、データがHTML内にそのまま書き込まれている「静的なウェブページ」のスクレイピングです。多少HTMLが崩れていても柔軟に飲み込んでくれるので、2025年になってもPythonスクレイピングの“最初の一歩”として選ばれ続けているのは、なるほどと納得できる話です(人気の理由はこちら)。
pipでBeautifulSoupをインストールする方法
pipって何?なぜ使うの?
Pythonを触り始めたばかりの方へ。pipはPythonのパッケージ管理ツールで、PyPI(Python Package Index)からライブラリをサクッと取り込めます。いわばPython用の“アプリストア”のような存在。このpipを使えば、BeautifulSoupの導入もほんの一瞬で終わります。
ワンポイント:正しいパッケージ名は「beautifulsoup4」です(「beautifulsoup」ではありません)。末尾の「4」を必ず付けて、最新版を入れましょう。
ステップバイステップ:BeautifulSoupのインストール
1. Pythonのバージョン確認
BeautifulSoupの動作にはPython 3.7以上が必要です。まずはターミナルで確認しましょう:
python --version
または
python3 --version
2. pipでBeautifulSoup4をインストール
ターミナルやコマンドプロンプトで:
pip install beautifulsoup4
Pythonを複数バージョン入れている場合は:
pip3 install beautifulsoup4
Windowsの場合:
py -m pip install beautifulsoup4
3. (推奨)パーサーの追加インストール
BeautifulSoupは標準の"html.parser"でも動きますが、より速く・より正確に処理したいならlxmlやhtml5libも入れておくとよいでしょう:
pip install lxml html5lib
4. (推奨)Requestsのインストール
BeautifulSoupはあくまでHTMLの解析専門で、ウェブページの取得そのものは行いません。そのため、多くの人はRequestsライブラリを組み合わせて使います:
pip install requests
5. インストール確認
Pythonで次のコードを試してみましょう:
from bs4 import BeautifulSoup
import requests
html = requests.get("http://example.com").text
soup = BeautifulSoup(html, "html.parser")
print(soup.title)
<title>Example Domain</title>と表示されれば成功です。
仮想環境でBeautifulSoupをインストールする
Pythonでプロジェクトを進めるなら、仮想環境の活用を強くおすすめします。依存関係がきれいに分離され、他のプロジェクトとぶつかる心配がありません。
仮想環境の作成方法:
python -m venv venv
# Windowsの場合:
venv\Scripts\activate
# macOS/Linuxの場合:
source venv/bin/activate
pip install beautifulsoup4 requests lxml html5lib
こうしておけば、入れたパッケージはこのプロジェクト内だけで有効になり、「パッケージが見つからない」といったトラブルもぐっと減ります。
その他のインストール方法(Condaなど)
Anaconda環境なら、こちらで:
conda install beautifulsoup4
パーサーも同じ要領で:
conda install lxml
事前にconda環境をアクティベートしておくのを忘れずに。
BeautifulSoup Python:基本的な使い方とコード例
ここからは、BeautifulSoupを使った具体的なPythonスクリプトを見ていきましょう。
例1:ウェブページを取得してタイトルを抽出
from bs4 import BeautifulSoup
import requests
url = "https://en.wikipedia.org/wiki/Python_(programming_language)"
response = requests.get(url)
soup = BeautifulSoup(response.content, "html.parser")
# ページタイトルを取得
title_text = soup.title.string
print("Page title:", title_text)
WikipediaのPythonページを読み込み、そのタイトルを表示します。拍子抜けするほどシンプルです。
例2:すべてのリンクを抽出
links = soup.find_all('a')
for link in links[:10]: # 最初の10件を表示
href = link.get('href')
text = link.get_text()
print(f"{text}: {href}")
ページ内の先頭10個分のリンクテキストとURLを並べて表示します。
例3:見出し(h2)を抽出
headings = soup.find_all('h2')
for h in headings:
print(h.get_text().strip())
<h2>タグの見出しをまとめて取り出せます。
例4:CSSセレクタを使う
items = soup.select("ul.menu > li")
for item in items:
print(item.get_text())
select()メソッドを使えば、CSSセレクタでの指定が可能です。
例5:属性やネストしたタグの取得
first_link = soup.find('a')
print(first_link['href']) # 直接アクセス(無いとエラー)
print(first_link.get('href')) # 安全なアクセス(無い場合None)
例6:ページ内の全テキストを取得
text_content = soup.get_text()
print(text_content)
ページ全体のテキストを一括で取得できます。ざっくりした分析をしたいときに重宝します。
BeautifulSoupでよく使う基本操作
-
単一要素の取得:
soup.find('div', class_='price') -
複数要素の取得:
soup.find_all('p', class_='description') -
テキストの取得:
element.get_text() -
属性値の取得:
element.get('href') -
CSSセレクタの利用:
soup.select('table.data > tr') -
要素が無い場合の処理:
price = soup.find('span', class_='price') if price: print(price.get_text())
BeautifulSoupの書き方は直感的で、HTMLが多少崩れていても粘り強く対応してくれます(公式ドキュメントはこちら)。
BeautifulSoupの限界と現代のウェブスクレイピング事情
便利なBeautifulSoupですが、ここで弱点にも正直に触れておきます。静的ページや小規模な用途には文句なしの一方、決して万能というわけではありません。
主な課題点:
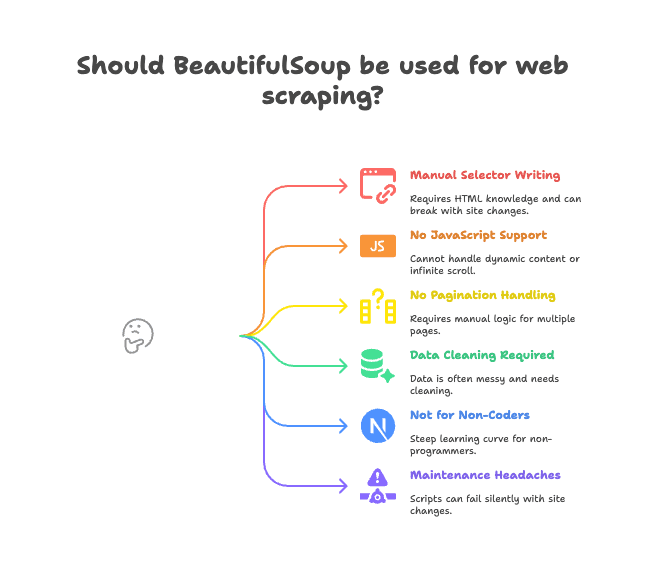
- セレクタを手書きする必要がある: HTML構造を自力で調べてタグやクラスを指定しなければならず、サイトの作りが変わるとスクリプトが途端に動かなくなります。
- JavaScriptに非対応: BeautifulSoupが見られるのはサーバーから返ってきたHTMLだけ。JavaScriptで動的に生成されるデータ(無限スクロールや動的コンテンツ)には手が届きません(詳細はこちら)。
- ページ送りや詳細ページの自動巡回がない: 複数ページや詳細ページをたどりたければ、そのロジックは全部自分で書く必要があります。
- データの整形が前提: 取得したデータは空白・特殊文字・表記ゆれが多く、後処理が欠かせません。
- 非エンジニアにはハードルが高い: コードを書けない営業・マーケ・事務の方には、なかなか手が出しづらいのが正直なところです。
- メンテナンスが重い: サイト構造が変わるたびにスクリプトが壊れ、データが抜け落ちることもあります。
こうした「ちょっとした」つまずきが積み重なると、実務では立派な生産性のボトルネックになります。私自身、スクレイピングスクリプトの修正に追われてプロジェクトが止まる現場を、何度となく見てきました。
いま多くのチームがThunderbitに乗り換える理由
では、ほかに手はないのか。そこで登場するのがThunderbitです。ThunderbitはPythonライブラリではなく、Chrome拡張機能として動くAI搭載のウェブデータ抽出アシスタントです。
Thunderbit AIウェブスクレイパーを試す AIでどんなウェブサイトもノーコードで抽出 Get Started Free
使い方は驚くほど手軽です:
- 抽出したいウェブサイトを開く
- 「AIフィールド提案」をクリックすると、ThunderbitのAIがページを読み取り、「商品名」「価格」「所在地」など最適なカラムを自動で提案
- 必要に応じてカラム名や型を微調整
- 「スクレイプ」ボタンを押せば、データを自動で抽出・整形
- Excel、Googleスプレッドシート、Notion、Airtableなどへワンクリックでエクスポート
コードは書かない。セレクタもいじらない。メンテナンスに追われることもありません。
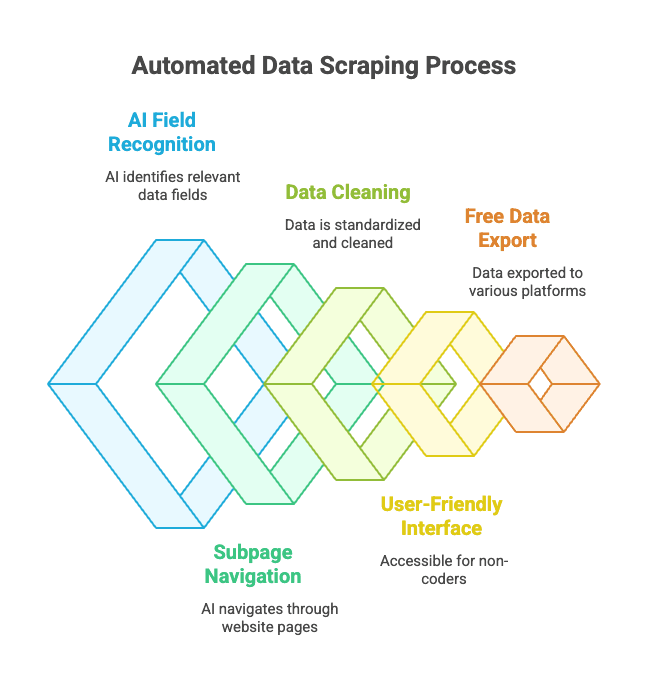
Thunderbitの主な特長:
- AIによるフィールド自動認識: HTMLが複雑でも、AIが欲しいデータを自分で見つけ出してくれます。
- サブページ・ページ送り対応: 商品詳細ページや「次へ」リンクも自動で巡回。
- データの自動整形: 電話番号・メール・画像などを標準化。
- 非エンジニアにやさしい: ブラウザが使えれば、それでOK。
- 無料エクスポート: ExcelやGoogleスプレッドシート、Airtable、Notionなどへ無料で出力。
- 定期スクレイピング: スケジュールを組めば自動実行も可能。
ビジネスユーザーにとっては、ウェブデータ抽出のあたりまえが書き換わる体験です。Pythonスクリプトを組む必要はなく、クリックだけで欲しいデータが手元に集まります。
ThunderbitとBeautifulSoupの比較:どちらが自分に合う?
違いを表で整理してみましょう:
| 機能 | BeautifulSoup(Pythonコーディング) | Thunderbit(ノーコードAI) |
|---|---|---|
| セットアップ | Python・pip・コードが必要 | Chrome拡張、2クリックで開始 |
| データ取得までの速さ | 最初のスクリプト作成に数時間 | サイトごとに数分 |
| JavaScript対応 | 不可(追加ツール必要) | 可能(ブラウザ上で動作) |
| ページ送り・サブページ | 手動でコード記述 | 標準搭載、ワンタッチ切替 |
| データ整形 | 手動でコード記述 | AIが自動で整形 |
| エクスポート方法 | CSV/Excel出力は自作 | SheetsやNotion等にワンクリック |
| おすすめ対象 | 開発者・技術好き | ビジネスユーザー・非エンジニア |
| コスト | 無料(ただし時間が必要) | フリーミアム(小規模は無料) |
BeautifulSoupが向いている人:
- Pythonに慣れていて、細部まで自分で制御したい
- 静的なサイトや、独自ロジックが必要な処理を扱う
- 大きなPythonワークフローの一部として組み込みたい
Thunderbitが向いている人:
- コードを書かずに、すぐ結果を手にしたい
- JavaScriptで動的に生成されるサイトを扱いたい
- 営業・マーケ・事務など、コードを書かない職種
- 取得データをそのまま業務ツールへ流し込みたい
正直に言えば、私自身も開発者ですが、ちょっとしたデータ抽出ならThunderbitで済ませることが増えました。ブラウザだけで完結する手軽さは、やはり大きいですね。
BeautifulSoupのインストール・活用のコツ
BeautifulSoupを使うなら、次のポイントを押さえておくと安心です:
- 仮想環境は必ず使う: 依存関係が整理され、環境周りのトラブルを防げます。
- pipやパッケージは最新に保つ:
pip install --upgrade pipやpip list --outdatedでこまめに更新を。 - 推奨パーサーも入れておく:
pip install lxml html5libでパフォーマンスが向上します。 - コードは役割ごとに分ける: 取得処理と解析処理を切り分けると、デバッグが格段にラクになります。
- robots.txtやアクセス頻度に配慮: サイトに負荷をかけないよう、
time.sleep()で間隔を空けましょう。 - 壊れにくいセレクタを選ぶ: すぐ崩れる細かいパスは避けるのが無難です。
- HTMLを保存してテスト: オフラインで解析を試すと、検証が効率的に進みます。
- コミュニティを頼る: Stack Overflowで疑問はだいたい解決します。
BeautifulSoupインストール時のトラブルシューティング
うまくいかないときは、次のあたりをチェックしてみてください:
- 「ModuleNotFoundError: No module named bs4」
- 正しい環境に
beautifulsoup4を入れたか確認。python -m pip install beautifulsoup4を試す。
- 正しい環境に
- 間違ったパッケージ(beautifulsoup)を入れてしまった
- 古いものをアンインストール:
pip uninstall beautifulsoup - 正しいものをインストール:
pip install beautifulsoup4
- 古いものをアンインストール:
- パーサーやUnicodeの警告が出る
lxmlやhtml5libを入れ、パーサーを明示:BeautifulSoup(html, "lxml")
- 要素が見つからない
- そのデータがJavaScriptで生成されていないか確認。BeautifulSoupはHTMLソースしか見えません。
- pipのエラーや権限まわりの問題
- 仮想環境を使うか、
pip install --user beautifulsoup4を試す。 - pipをアップグレード:
pip install --upgrade pip
- 仮想環境を使うか、
- Conda関連の問題
conda install beautifulsoup4を試すか、conda環境内でpipを使う。
それでも解決しないときは、BeautifulSoup公式ドキュメントやStack Overflowを当たれば、たいていのケースは網羅されています。
まとめ:BeautifulSoupインストール&活用のポイント
-
BeautifulSoupはPythonで最も人気のウェブスクレイピングライブラリ。シンプルで柔軟、初心者にもうってつけ。
-
pipでインストール:
pip install beautifulsoup4 lxml html5lib requests -
仮想環境を使い、環境をクリーンに保つ
-
静的ページや小規模用途には最適だが、JavaScript・ページ送り・メンテナンスには弱い
-
Thunderbitはビジネスユーザーや非エンジニア向けの最新AIツール。コード不要、手間いらず、すぐにデータが手に入る
-
目的に合わせてツールを選ぶ:
- 開発者や技術好き:BeautifulSoupで細部まで制御
- ビジネスユーザーやチーム: Thunderbit ですぐに結果
両方を一度ずつ試し、「いちばんラクに目的を達成できる方法」を選ぶのが、結局いちばんの近道です。
Thunderbit AIウェブスクレイパーを無料で試す Get Started Free
よくある質問:pipでBeautifulSoupをインストールするには?
Q: beautifulsoupとbeautifulsoup4の違いは?
A: 必ずbeautifulsoup4を入れてください。これが最新でサポート対象のバージョンです。古いbeautifulsoupはPython3に非対応で、コード上はfrom bs4 import BeautifulSoupと書きます(詳細はこちら)。
Q: lxmlやhtml5libは必須?
A: 必須ではありませんが、パース速度や安定性が大きく上がるので強くおすすめします。pip install lxml html5libで入れられます(理由はこちら)。
Q: BeautifulSoupでJavaScript生成のサイトは扱える?
A: いいえ。BeautifulSoupが扱えるのは静的HTMLのみです。JavaScriptで生成されるデータには、Seleniumなどのブラウザ自動化ツールや、ThunderbitのようなAI搭載ブラウザツールを使いましょう(詳細はこちら)。
Q: BeautifulSoupのアンインストール方法は?
A: ターミナルでpip uninstall beautifulsoup4を実行してください(手順はこちら)。
Q: Thunderbitは無料で使える?
A: Thunderbitはフリーミアム型で、小規模な用途なら無料で使えます。ブラウザからそのまま試せます(料金詳細はこちら)。
BeautifulSoupとThunderbitの実際の使い勝手を見比べたい方は、詳細な比較記事もどうぞ。さらにウェブスクレイピングの基礎や、データスクレイピングとは、Amazon商品のレビュー抽出方法もあわせて参考にしてみてください。
楽しいスクレイピングを。Pythonの達人でも、スプレッドシートにデータをまとめたいだけの方でも、あなたに合ったツールと支えてくれるコミュニティは、きっと見つかります。




