
Apolloのリストクエリ最適化って、ただの技術チューニングで終わる話じゃありません。リアルタイムのニュースデータ、ニュースの自動抽出、あるいはスピード勝負の営業・オペレーションのワークフローに頼ってる人にとっては、まさに「生き残りスキル」そのもの。遅いリストクエリが、見栄えのいいダッシュボードを一瞬でボトルネックに変えて、営業チームは延々と読み込みスピナーを眺め、オペレーション側はスプレッドシートでの代替運用に追い込まれる——そんな現場、何度も見てきました。と言われる今、ミリ秒の差が積み重なって効いてきます。

じゃあ、ニュースのスクレイピング、リード追跡、ミッションクリティカルなダッシュボードの土台として、Apollo Clientのリストクエリを「速く・安定して・スケールする」状態に持っていくにはどうすればいいのか?このガイドでは、クエリ設計からキャッシュ、ページネーション、そしてみたいなノーコードツールを組み合わせてニュース抽出の面倒ごとを自動化する方法まで、僕が学んできたベストプラクティス(たまに痛い目を見て覚えたやつも含めて)をまとめて解説します。開発者でも、PMでも、「ダッシュボード遅いんだけど?」って言われがちな担当者でも、Apollo GraphQLのリスト性能を上げるための実戦ガイドとして使えるはずです。
なぜApolloのリストクエリを最適化するのか? (apollo client list performance, optimize apollo list queries)
ぶっちゃけ、ニュース見出しや営業リードの表示を待ちたい人なんていません。特にやリアルタイムデータに依存する現場だと、Apolloのリストクエリが遅いのは「不快」どころか、コスト増・意思決定の遅れ・手作業への逆戻りを引き起こします。でも、デスクワーカーは1日の約3分の1を低付加価値タスクに使っていて、その背景にツールの遅さや分断があるケースも少なくないとされています。
リストクエリが最適化されてないと、だいたいこうなります:
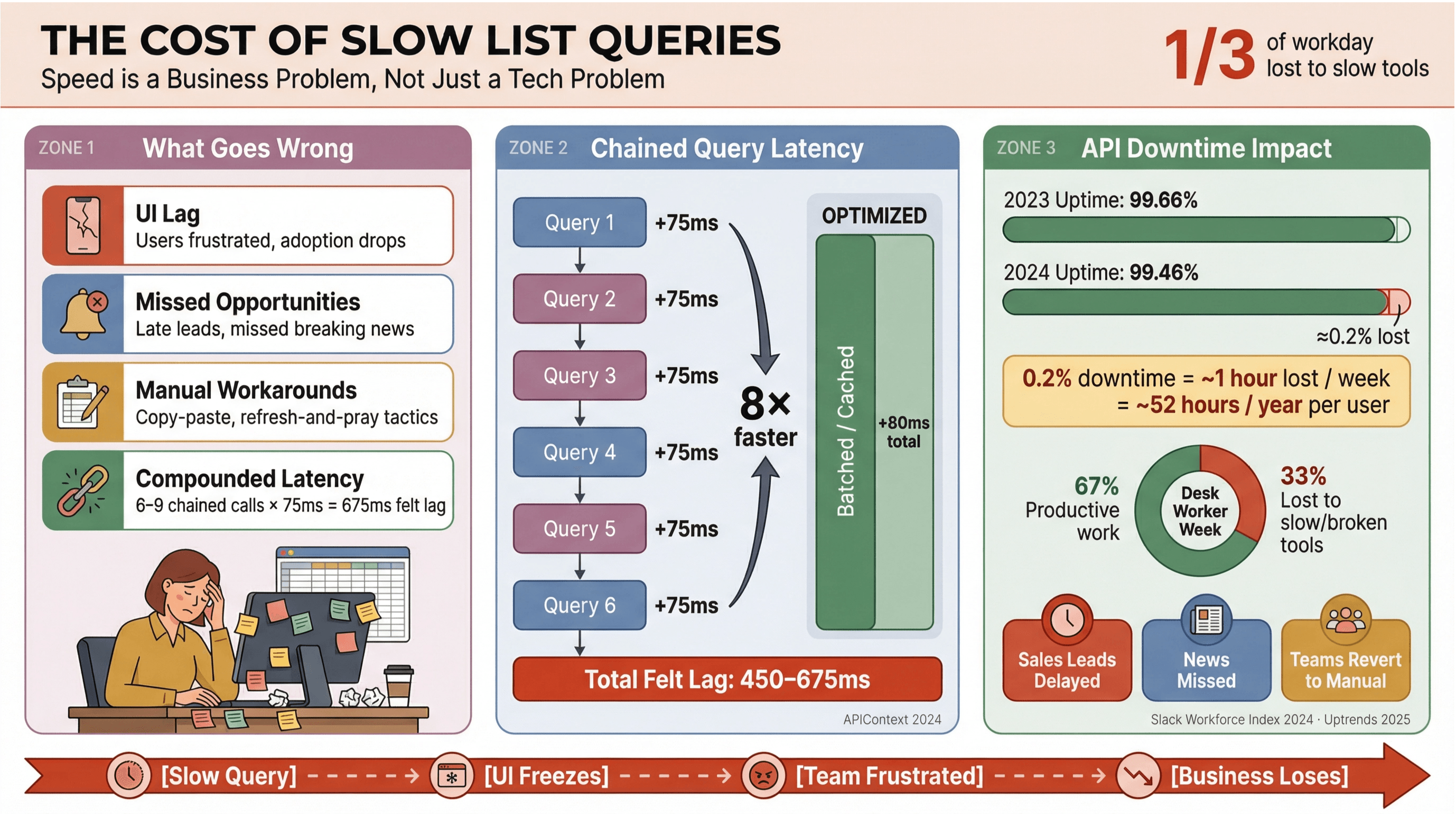
- UIのもたつき: 表示が遅くなってイライラが増え、利用定着率も落ちる。
- 機会損失: 営業やニュース監視だと、数秒の遅れがホットリードや速報の取り逃しに直結。
- 手作業の回帰: コピペ、スプレッドシート、「更新して祈る」運用に戻りがち。
- 遅延の連鎖: 遅いAPI呼び出しが積み上がる。ワークフローで6〜9本の依存クエリが走ると、1回あたり75msの遅れでも体感では450〜675msのラグになり得ます()。
しかも、問題は速度だけじゃありません。で、平均稼働率はたった1年で99.66%から99.46%へ低下。リスト中心のアプリだと、週あたり約1時間の生産性損失に相当します。リアルタイムのニュースデータに依存するビジネスなら、これは見過ごせないリスクです。
適切なデータ構造とフィールド選定 (apollo graphql list best practices)
ありがちな失敗(僕もやりました)は、リストクエリを詳細クエリと同じノリで作っちゃうこと。GraphQLは「必要なものだけ取れる」のが強みなので、そこをちゃんと活かしましょう。特にニューススクレイピングツールやリアルタイムダッシュボードでは、過剰取得(Overfetching)が性能の天敵です。
ニュース自動抽出に合わせてフィールドを絞る
たとえばニュースフィードを作るとして、リスト表示の段階で記事本文、全タグ、コメント、著者プロフィールまで本当に必要?多くの場合、答えはNOです。違いはこんな感じ。
効率的なリストクエリ:
1query NewsFeed($after: String, $first: Int) {
2 newsFeed(after: $after, first: $first) {
3 edges {
4 cursor
5 node {
6 id
7 title
8 url
9 sourceName
10 publishedAt
11 }
12 }
13 pageInfo { endCursor hasNextPage }
14 }
15}非効率なリストクエリ(やらないで):
1query NewsFeedTooHeavy($after: String, $first: Int) {
2 newsFeed(after: $after, first: $first) {
3 edges {
4 node {
5 id title url publishedAt
6 fullText
7 summary
8 entities { ... }
9 relatedArticles { ... }
10 }
11 }
12 }
13}前者は軽くて、ランキング・フィルタ・行レンダリングに向いてます。後者は「リストの顔をした詳細クエリ」で、ペイロードが太って全体を遅くします(、)。
プロのコツ: 2段構えにすること。リストでは軽いフィールドだけ取り、本文やNLPの付加情報みたいな重いデータは、ユーザーがアイテムを開いた時(またはホバー時)に詳細クエリで読み込みます。
Apollo Clientのキャッシュを活用して高速化 (apollo client list performance)
Apollo Clientのキャッシュは、リストクエリをサクサク動かすための切り札です。うまくハマると、こんなメリットが出ます。
- 同じクエリを即表示(ネットワーク往復なし)
- サーバー負荷とAPIコストの削減
- 戻る/進むやフィルタ変更がヌルっと滑らか
ただしキャッシュは魔法じゃないので、最低限の設計と運用は必要です。
効果的なキャッシュポリシーを選ぶ
Apolloには複数のがあります:
| Policy | What It Does | Best Use Case for News Lists |
|---|---|---|
| cache-first | Reads from cache, fetches from network if missing | Revisiting lists, switching filters, back/forward navigation |
| network-only | Always fetches from network | Manual refresh, “latest headlines” |
| cache-and-network | Returns cache first, then updates with network response | Fast initial paint + background update (great for news feeds) |
| no-cache | Always fetches, never stores in cache | One-off sensitive queries (rare for lists) |
リアルタイム性のあるニュースデータなら、僕はcache-and-network推しです。まずキャッシュで即表示して、裏で最新データに更新できる。ただし更新で並び順が変わるとUIがチラつくことがあるので、そこは注意()。
キャッシュ設定のポイント:
- 正規化のために安定したID(
idや_id)を使う()。 - 大きなリストに合わせてキャッシュサイズとGCを調整する()。
ROOT_QUERY配下に巨大な非正規化データを溜めない(アプリが固まりやすい)()。
ページネーションと取得件数の制限 (apollo graphql list best practices)
ニュース記事や営業リードを一気に何百・何千件も読み込むのは、だいたい事故の元。ページネーションはUXのためだけじゃなく、性能面でも必須です。
Apolloはとの両方をサポートしています。比較するとこんな感じ:
| Pagination Type | Pros | Cons | Best For |
|---|---|---|---|
| Offset-based | Simple, easy to implement | Can skip/duplicate items if data shifts | Immutable or small lists |
| Cursor-based | Stable, handles data changes well | Slightly more complex | News feeds, large lists |
リアルタイムのニュースやリード一覧の多くでは、カーソル方式がベストです。新規追加や削除が起きても整合性を保ちやすいから()。
Apolloのページネーション実装のコツ:
- ページング対象フィールドのキャッシュキーをコントロールするために
keyArgsを設定()。 - キャッシュ内でページを結合する
merge関数を実装。 fetchMoreで既存結果を潰さずに追加ページを読み込む。
ニューススクレイピングツールで使える実践パターン
典型的なニューススクレイピングUIは、こんな設計が鉄板です:
- 最新20〜50件の見出しを表示(軽量フィールドのみ)
- スクロールや「次へ」で追加読み込み
- 詳細は必要になった時だけ取得
これならUIは軽いし、APIも安定するし、ユーザーは待ち時間なしで作業できます。
Thunderbitを組み合わせてニュース自動抽出を実現
ここで避けて通れないのが、「そもそも構造化されたニュースデータって、どこから持ってくるの?」問題。そこで効いてくるのがです。
Thunderbitは、ノーコードで使えるAIウェブスクレイパーのChrome拡張機能。ほぼどんなサイトからでも、ニュース見出し、URL、媒体名、著者、公開日、要約、画像などをコードなしで抽出できます。チームがThunderbitでニュース抽出をまるっと自動化して、非構造なWebページをクリーンな構造化データに変換し、DBやGraphQL APIへ直接流し込む運用をしてるのも見てきました。
Thunderbit × Apolloでリアルタイムニュース基盤を作る
営業・オペレーションチーム向けに、僕が特におすすめしたい流れはこれです:
- 抽出レイヤー: Thunderbitので、対象サイトから構造化ニュースデータを定期取得。
- 保存レイヤー: 高速参照に最適化したDBへ保存。
- GraphQLレイヤー: APIで
newsFeed(一覧)とnewsArticle(id)(詳細)を公開。 - クライアントレイヤー: Apollo Clientで一覧は軽量+ページングで取得し、詳細は必要時のみ取得。
この「scrape → store → query」パイプラインなら、Apolloのクエリは常に新鮮で構造化されたデータを相手にできて、手作業のコピペや壊れやすいスクリプトに頼らずに済みます。
おまけ: ThunderbitのAIフィールド提案を使えば、感情(sentiment)やカテゴリみたいな追加項目でリストを拡張できて、ニュースフィードをもっと賢くできます。
手順でわかる:Apolloリストクエリ最適化ガイド
実際に手を動かすための、僕の定番チェックリストです:
-
クエリを軽くする
- リスト描画に必要なフィールドだけを要求(タイトル、URL、時刻など)。
- 重いフィールド(本文、画像、付加情報)は詳細クエリへ分離。
-
ページネーションを入れる
- 大規模・変動のあるリストはカーソル方式を採用。
keyArgsとmergeを正しく設定してキャッシュ整合性を担保。
-
Apolloキャッシュを活用する
- 安定IDでエンティティを正規化。
- 適切なfetch policyを選ぶ(ニュースなら
cache-and-networkが有効)。 - データ量に合わせてキャッシュサイズとGCを調整。
-
抽出を自動化する
- Thunderbitでニューススクレイピングを自動化し、常に最新データに。
- 構造化データをDBやスプレッドシートへ直接エクスポート。
-
監視とトラブルシュート
- でクエリ、キャッシュ、性能を確認。
- 大きすぎるキャッシュ書き込み、watchクエリの過多、UIのカクつきを監視。
- p95/p99のレイテンシとエラー率を追う(、)。
クエリ性能の監視と原因切り分け
ここはApolloのDevtoolsがガチで役立ちます。たとえば:
- 実行中クエリとキャッシュ状態の確認
- 重複クエリやwatcher過多の発見
- 巨大なキャッシュ塊や正規化の問題の特定
UIが重い・更新が遅いときは、まずここを疑いましょう:
- リストクエリがデカすぎる(フィールドを削る)
- キャッシュ正規化が弱い(ID設計を見直す)
- ページネーションのマージが不正(
keyArgsとmergeを監査)
そして平均値だけじゃなく、テールレイテンシ(遅い側の分布)も必ず測ってください。ユーザーの痛みはだいたいそこに潜んでます。
従来型とAI主導のニューススクレイピングを比較
正直、昔のニューススクレイピングって、カスタムスクリプトを書いて、ヘッドレスブラウザを回して、サイトのレイアウト変更にビクビクする世界でした。でも今はThunderbitみたいなAI主導ツールで、ノーコードで一連の作業を自動化できます。
| Approach | Strengths | Limitations for Business Users |
|---|---|---|
| Scripted scraping | Fully customizable, cheap at scale | High maintenance, needs engineering time |
| Managed scraping platforms | Fast to start, offloads anti-bot handling | Still needs config, costs scale with usage |
| AI-driven extraction (Thunderbit) | Handles messy layouts, no code needed | Output needs QA, integration with your schema |
| No-code visual scrapers | Accessible for non-engineers | Can break with UI changes, limited scale |
| Proxy/unlocker infra | Bypasses blocks, supports high throughput | Still needs extraction logic, compliance risks |
法的注意: 公開データのスクレイピングは一般に合法とされることが多い一方で、利用規約やレート制限の遵守は必須です()。
Apollo GraphQLのリスト運用ベストプラクティス:要点まとめ
重要ポイントをまとめると、こんな感じです:
- 速さと分かりやすさを優先: リストは軽量化して、ページングして、キャッシュをガンガン活用。
- 構造がすべて: 必要なものだけ取得し、重いフィールドは詳細クエリへ。
- キャッシュは味方: 正規化とfetch policyで即時表示を実現。
- 抽出を自動化: ならニューススクレイピングやリスト拡張を誰でも回せる。
- 監視して改善: Devtoolsと可観測性でボトルネックを早めに潰す。
営業・オペレーション・ニュースチームにとって、これらの実践は「待ち時間を減らして、行動を増やす」ことに直結します。結果として、「なんでこんなに遅いの?」ってSlackが飛んでくる回数も激減します。
結論:Apolloリストクエリ最適化の次の一手
重い・ページングなし・キャッシュに優しくないリストクエリをまだ使ってるなら、今が棚卸しと改善のタイミングです。まずは小さく始めましょう。フィールドを削って、ページネーションを入れて、キャッシュを調整する。次に、みたいな自動抽出ツールを統合して、データを常に新鮮で使える状態に引き上げます。
さらに深掘りしたいなら、、、またはで実践的な知見やトラブルシュートをチェックしてみてください。ニュース抽出を自動化したいなら、Thunderbitのはぜひ試す価値あり。リアルタイムデータが必要な人にとって、面倒を一気に減らせる強力な選択肢です。
クエリが気持ちよく回って、リストがコーヒーが冷める前に表示されますように。
FAQs
1. リアルタイムのニュースや営業ダッシュボードで、Apolloのリストクエリが遅くなるのはなぜ?
取得データが多すぎる、ページネーションがない、キャッシュが適切に効いていない、といった要因で遅くなります。ニュース監視のように高頻度で回るワークフローでは小さな遅延が積み重なり、UIのもたつきや生産性低下につながります。
2. ニュース自動抽出向けに、Apolloのリストクエリはどう設計するのがベスト?
リスト描画に必要なフィールド(例:タイトル、URL、タイムスタンプ)だけを要求し、本文や画像など重い要素は詳細クエリへ分離します。さらにページネーションでペイロードを小さく保つのが効果的です。
3. Apollo Clientのキャッシュは、リスト性能をどう改善する?
一度取得したデータを保持することで、同じクエリの再表示を即時化できます。正規化と適切なfetch policy(例:cache-and-network)を組み合わせると、リスト表示が大幅に高速化し、サーバー負荷も下げられます。
4. ThunderbitはニューススクレイピングとApollo連携にどう役立つ?
ThunderbitはノーコードのAIウェブスクレイパーで、任意のサイトから構造化ニュースデータを抽出できます。抽出したデータをDBやGraphQL APIへ流し込み、Apollo Clientで利用することで、ニュース抽出から表示までを自動化できます。
5. Apolloのリストクエリ性能を監視・改善するには何を使えばいい?
でクエリ、キャッシュ状態、性能をリアルタイムに確認できます。New RelicやUptrendsのような可観測性ダッシュボードと併用し、レイテンシやエラー率を追いながらクエリ設計を改善すると効果的です。
スクレイピング、自動化、リアルタイムデータ運用のヒントをもっと知りたい人は、で解説記事やチュートリアル、AI活用の最新情報をチェックしてみてください。
Learn More