
つい先日、私はまる一日を費やして、ログインが要る仕入先ポータルで、AIエージェントに申込フォームを入力させようと悪戦苦闘していました。気づけば3時間が経過。画面には「Connection Refused」の文字が居座り、VPSのメモリは枯れ果て、頭の中では「これ、手で打ち込んだほうが早いのでは」という声がどんどん大きくなっていました。
あの一日は、OpenClawのブラウザ自動化に踏み込む人なら、たいてい一度は味わう“洗礼”です。OpenClawは、ページ間の移動、データの抜き出し、フォーム入力、入り組んだワークフローの連携まで、平易な英語の指示ひとつでこなしてしまう、なかなか骨太なツールです。けれど、「これは面白そうだ」と感じる地点から、「自分の環境で本当に動いた」という地点までの間には、見た目以上に高い壁があり、多くの人がそこで立ち往生します。
私は、この壁の両側をずいぶん長いこと往復してきました。Thunderbitで自動化ツールを作る側でもあり、オープンソースのエコシステムをいじり倒す側でもあるからです。本記事には、あのとき自分が「これがあれば」と切実に欲しかった中身を、余すところなく注ぎ込みました。地に足のついたセットアップ手順、誰もが頭を抱えるブラウザモードの選び方、WSL頼みにしないWindowsネイティブの導入法、bot対策を生き延びる術、実際の出力サンプル、頻出エラーとその処方箋、そしてOpenClawが真価を発揮する場面と、明らかに大げさすぎる場面まで、包み隠さずお伝えします。
手間なくウェブスクレイピングを始めるなら Thunderbit を試す
AIであらゆるサイトからデータを抽出 Get Started Free
OpenClaw ブラウザ自動化とは?
OpenClawは、ブラウザをあなたに代わって操ってくれる、無料のオープンソースAIエージェント基盤です(MITライセンス)。Seleniumのスクリプトや、Puppeteerのコードを一行ずつ書く代わりに、「このページを開いて、商品名と価格を残らず抜き出して」と自然な英語で伝えるだけ。AIが操作の段取りを自分で組み立ててくれます。ページ上の要素を見つけては番号付きの参照を割り当て、その順に手を動かしていく、スナップショット方式が採用されています。
この仕組みは3つのパーツが噛み合ってできているので、拡張機能を1つ入れて終わり、とはいきません。
- Gateway(VPS/サーバー): 指示を処理し、LLMへつなぐ「頭脳」。デフォルトのポートは18789です。
- Node Host(ローカル端末): Gatewayが出すブラウザ指示を、手元のChromeへ取り次ぐ役。Tailscaleのような安全なトンネルを通して接続します。
- Chrome Extension(Browser Relay): 実際のブラウザの内側で、エージェントにタブを直接触らせる橋渡しです。
このほかにも、Control Service(18791)、CDP Relay(18792)、managed browser CDP(18800–18899、最大100件の並列プロファイル対応)といったポートが顔を出します。
率直に言って、登場するパーツの数はなかなかのものです。ただ、それぞれが何を担っているのかが腑に落ちると、セットアップの一手一手に理由があると見えてきます。たとえるなら、ラジコンカーです。Gatewayが手元のコントローラー、Node Hostが飛び交う電波、Chrome Extensionが走り回る車体、というわけです。

なぜ OpenClaw ブラウザ自動化がビジネスチームに重要なのか
ナレッジワーカーは、本来価値を生むはずの仕事ではなく、最大で業務時間の60%を定型的な事務処理に吸い取られています。1日あたり1.8時間も、情報を探し回ることに費やしている、というデータすらあります。Smartsheetの調査でも、働き手の4割超が、週の労働時間の4分の1以上を手作業の繰り返しに割いていると報告されています。ありふれたデータ入力ひとつとっても、米国企業では従業員1人あたり年間およそ8,500ドルもの費用が消えている、との見積もりがあるほどです。
OpenClawのブラウザ自動化は、まさにこの目詰まりを解消するために生まれた道具です。実務に落とし込むと、たとえば次のような業務に、そのまま効いてきます。
| ユースケース | OpenClaw ができること | ビジネス上の効果 |
|---|---|---|
| リード獲得 | ディレクトリや企業ページから連絡先情報を抽出 | 営業案件をより早く積み上げられる |
| 競合価格の監視 | 商品ページを毎日巡回し、価格を取得 | 競争情報をリアルタイムで把握できる |
| フォーム入力 / データ入力 | CRM、ポータル、申請フォームなどの反復入力を自動化 | 毎週の工数を大幅削減 |
| コンテンツ監視 | 競合ブログ、求人ページ、プレスリリースを確認 | 早期に競合の兆候をつかめる |
| QA / テスト | Web フローを実行して正常性を確認 | 画面崩れや動作不良を減らせる |
AIエージェント市場は2025年に73.8億ドルへと膨らみ、2023年の37億ドルからほぼ倍の規模になりました。加えて、組織の88%が、すでに少なくとも1つの業務にAI自動化を取り入れています。もはや一部の物好きだけの世界ではありません。
Sandbox Chromium、Browser Relay、Chrome Remote Debugging:最適なモードの選び方
OpenClawを触り始めた人が、まっさきに足を取られるのが、実はブラウザモードの選択です。私の見てきた範囲でも、接続まわりのトラブルのほとんどは、出だしで別のモードを選んでいれば起きずに済んだものでした。OpenClawには接続の道が3つあり、それぞれに長所と短所が裏表でついて回ります。
- Sandbox Chromium(Managed Profile): OpenClawがサーバー側で、自前のヘッドレスブラウザを立ち上げます。ログインセッションこそ使えませんが、準備が軽く、動きもきびきびしています。半面、bot対策には足がつきやすくなります。
- Browser Relay(Existing-Session): ローカル端末のnode hostが、VPSから来た指示を本物のChromeへ取り次ぎます。ログインセッションやCookieが生き、いつものブラウザ指紋まるごと引き継げます。
- Chrome Remote Debugging(Remote CDP): WebSocket URLを介してリモートブラウザへつなぎます。セッションを丸ごと操れる代わりに、準備のハードルは3つの中で一番高めです。BrowserlessやBrowserbaseのようなクラウドサービスとも手を組めます。
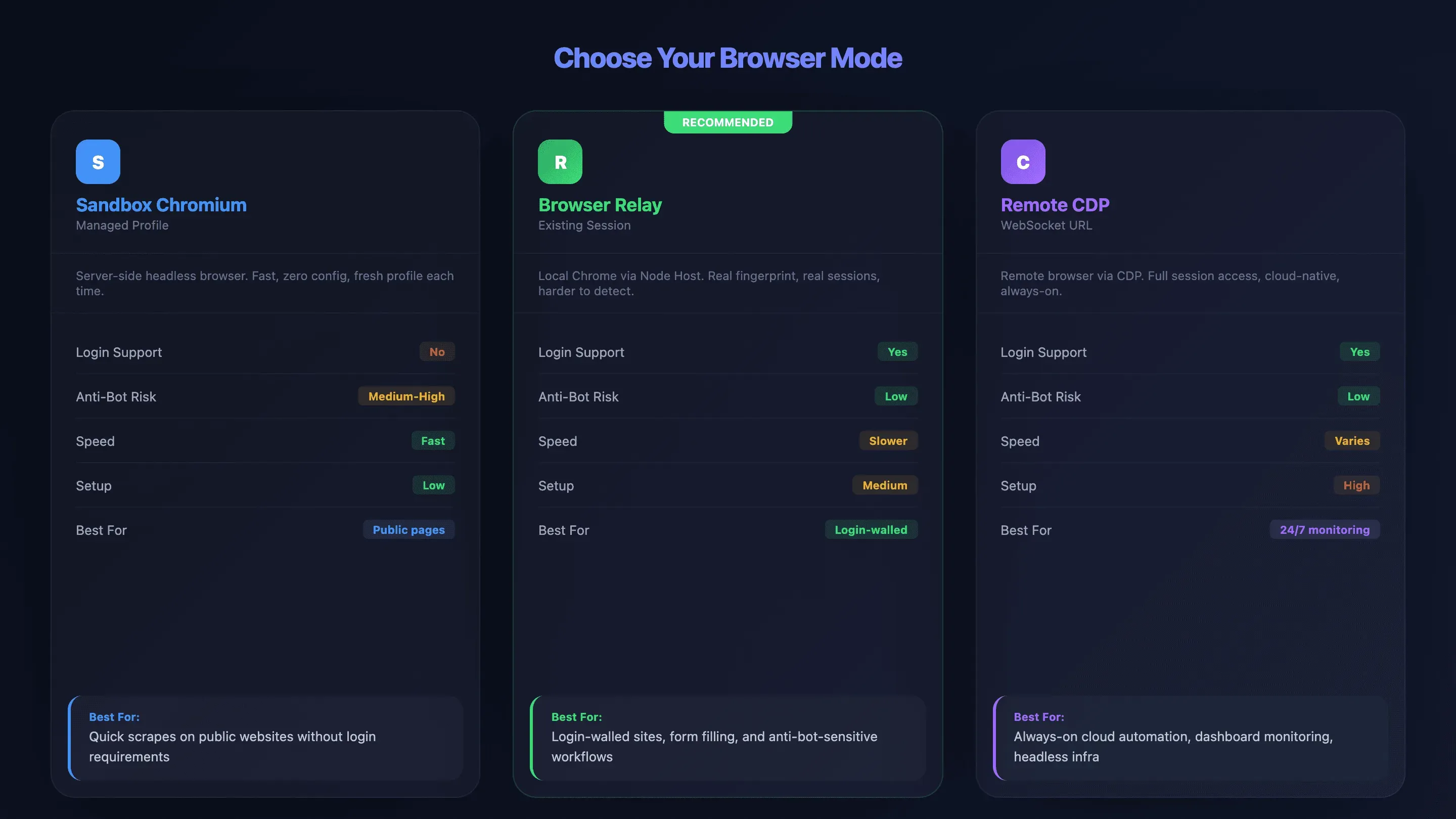
比較表:3つのブラウザモード
| 項目 | Sandbox Chromium | Browser Relay | Remote CDP |
|---|---|---|---|
| ログイン対応 | ❌ なし(新規プロファイル) | ✅ あり(実セッション) | ✅ あり(認証済み) |
| bot 対策リスク | ⚠️ 中〜高 | ✅ 低(実ブラウザの指紋) | ✅ 低(プロバイダー管理) |
| 速度 | ✅ 速い | ⚠️ やや遅い(ネットワーク中継) | ⚠️ 環境による |
| セットアップ難易度 | 低 | 中 | 高 |
| 全機能対応 | ✅ あり(すべて) | ⚠️ 一部制限あり(バッチ不可、ダウンロード介入不可) | プロバイダー次第 |
| 向いている用途 | 公開ページ、手早い抽出 | ログイン必須サイト、フォーム入力 | クラウド運用、常時監視 |
判断フロー:どのモードを選ぶべき?
次の問いを、頭から順にたどってみてください。
- 「ログインが必要ですか?」 — いいえ → Sandbox Chromium。はい → 次へ。
- 「そのサイトは bot 対策がかなり厳しいですか?」 — はい → Browser Relay(本物のブラウザ指紋が検知逃れに効きます)。いいえ → Browser Relay でも Remote CDP でも構いません。
- 「24時間止めずに動かすセッションが要りますか?(ダッシュボード監視など)」 — はい → クラウドプロバイダーと組んだ Remote CDP。いいえ → Browser Relay。
具体的なケースに重ねると、こんな具合です。
- 公開中のAmazon商品一覧を抜き出す → Sandbox Chromium
- ログイン後のCRMフォームを埋める → Browser Relay
- 社内分析ダッシュボードを丸一日見張る → Browserless / Browserbase を絡めた Remote CDP
ここの見極めを最初にきっちり決めておくだけで、後々のデバッグに費やす時間が驚くほど削れます。これは大げさでも何でもありません。
始める前に
- 難易度: 中級(CLIにそこそこ慣れている方向け)
- 所要時間: 全体で45〜75分、各ステップは10〜15分ほど
- 必要なもの: VPS(最低2GB RAM、推奨4GB)、Node.js v22.12.0 以上、Tailscale アカウント(無料)、Chrome ブラウザ、そして少しの忍耐
ステップ1: VPS(またはローカル)で OpenClaw を起動する
VPSは、OpenClawの「頭脳」が腰を据える拠点です。立ち上げの道は2通りあります。
選択肢A: ワンクリック VPS ホスティング
OpenClawをあらかじめ仕込んだイメージを配っているプロバイダーがいくつかあります。
| プロバイダー | 開始価格 | 備考 | |---|---|---|---| | Hostinger | 月額 $6.99 〜 | 事前設定済みイメージ | | Tencent Cloud Lighthouse | 年額約 $0.08 〜(キャンペーン) | 2コア / 4GB 推奨 | | Hetzner | 月額 $4.09 〜(CX22) | コスパ良好、手動インストール | | DigitalOcean | 月額 $4 〜 | 手動インストール | | Vultr | 月額 $3.50 〜 | 手動インストール |
選択肢B: CLI で手動インストール
# npm でインストール(Node.js v22.12.0 以上が必要)
npm install -g openclaw
# セットアップウィザードを起動
openclaw onboard
# Gateway トークンを生成(後で node host に必要なので保存しておく)
openclaw doctor --generate-gateway-token
# 設定を検証
openclaw doctor --fix
最低要件: 2GB RAM(1GBだと途中で落ちることがあります)、できれば4GB。ヘッドレスブラウザは、何もしていないアイドル状態でも1つあたり400〜800MBほど抱え込みます。Dockerで回すなら shm_size: '2gb' を指定しておくこと。これが安定性をぐっと押し上げます。
この段階で、OpenClawが立ち上がり、Gatewayトークンを安全な場所にしまえていれば合格です。(私はパスワードマネージャーに放り込んでいます。くれぐれも紛失しないように。)
ステップ2: VPS とローカル端末を Tailscale でつなぐ
Tailscaleは、VPSと手元の端末の間にプライベートで暗号化されたトンネルを通し、ブラウザへの指示がインターネット上に丸裸でさらされないようにしてくれます。OpenClawには2026年初頭にKasperskyが512件の脆弱性を指摘したという前歴もあるので、この手順を飛ばすのは、はっきり言っておすすめしません。
# VPS 側
curl -fsSL https://tailscale.com/install.sh | sh
sudo tailscale up --ssh=true
# VPS の Tailscale IP(100.x.x.x)を控える
# Gateway を Tailscale ネットワークで待ち受けるよう設定
openclaw config set gateway.listen "100.x.x.x:18789"
ローカル端末のほうには、tailscale.com/downloadからTailscaleを入れてください。両方の端末が、同じTailscaleアカウントにぶら下がっている必要があります。
Tailscale 以外を使いたい場合の代替案:
| 項目 | Tailscale | Cloudflare Tunnel | WireGuard |
|---|---|---|---|
| セットアップ時間 | 5分 | 10〜15分 | 20〜30分 |
| コスト | 無料(個人利用) | 無料 | 無料 |
| NAT 越え | 自動 | 自動 | 手動 |
ここまで進めば、ローカル端末からVPSのTailscale IPへpingが通るはずです。返ってこないなら、両方の端末が同じTailscaleアカウントでログインできているか、まず確かめてください。
ステップ3: ローカル端末に Node Host を入れる
Node Hostは、VPSのGatewayが出すブラウザ指示を、Chromeへ取り次ぐ係です。言い換えれば、サーバーとブラウザの間に立つ通訳のような存在です。
# node host パッケージをインストール
npm install -g @openclaw/node-host
# ステップ1で作成した gateway トークンを設定
export OPENCLAW_GATEWAY_TOKEN="your-token-here"
# VPS の Tailscale IP を指定して node host を起動
openclaw node install --host 100.x.x.x --port 18789
# VPS 側から接続を承認
openclaw node approve <node-id>
nodeが接続され、承認済みになったとの表示が出れば合格です。承認が途中で止まってしまうときは、VPS側のGatewayプロセスを一度再起動してみてください。
ステップ4: OpenClaw の Chrome 拡張機能を入れる
この拡張機能が入ることで、エージェントがブラウザのタブを直に操れるようになります。Chrome Web Storeで「OpenClaw Browser Relay」を探して入れる手もあります。
# 拡張機能ファイルをインストール
openclaw browser extension install
# あるいは手動で:
# 1. chrome://extensions を開く
# 2. 右上の「Developer mode」を有効化
# 3. 「Load unpacked」をクリック → 拡張機能フォルダを選択
# 4. ツールバーに固定
# 5. バッジが「ON」と表示されるか確認
バッジに「ON」が灯れば準備万端です。「OFF」のまま動かないなら、下のトラブルシューティングへ進んでください。
ステップ5: 最初の OpenClaw ブラウザ自動化タスクを実行する
対象のタブを開いたうえで、OpenClawのチャット画面から、まずはこんな素朴な指示を投げてみてください。
https://books.toscrape.com に移動して、ページ内のすべての本のタイトルと価格を抽出して
期待される流れ: 指示送信 → エージェントがスナップショット取得(ページ要素を番号付きで認識) → データ抽出 → JSON または CSV で構造化出力が返る
経験から言える勘どころですが、最初はとにかく素朴なプロンプトから入ってください。あれこれ細かく指定しすぎると、かえってAIが迷子になります。短く伝えて、足りなければ後から付け足す。このやり方のほうが、ずっと打率が上がります。
1ページに20冊並んでいるケースなら、所要時間の目安は30〜60秒ほど。構造化データが返ってきたら、OpenClawのブラウザ自動化セットアップは見事に成功です。
Windows での OpenClaw ブラウザ自動化:ネイティブな導入方法
OpenClawの解説は、その大半がmacOSかLinuxを前提に書かれています。Windowsユーザーなら、もうとっくに気づいているはずです。あるフォーラムの投稿には、こんな一節がありました。「理屈の上ではどれも正しそうに見えた。だが、どれひとつとしてWindowsネイティブを想定して作られてはいなかった」と。
ここでは、現に動くやり方だけを取り上げます。
選択肢A: Windows で Chrome Remote Debugging を使う(推奨のネイティブ方法)
Windowsでもっとも安定が見込めるのが、この方法です。PowerShellを開いて、remote debuggingを有効にしたChromeを起動します。
& "C:\Program Files\Google\Chrome\Application\chrome.exe" --remote-debugging-port=9222
そこにChromeが見当たらないなら、次を試してみてください。
# 別の場所を確認
Get-ChildItem "C:\Program Files*\Google\Chrome\Application\chrome.exe" -Recurse
# あるいは AppData を確認
& "$env:LOCALAPPDATA\Google\Chrome\Application\chrome.exe" --remote-debugging-port=9222
そのうえで、openclaw.json の設定で cdpUrl を ws://localhost:9222 に書き換え、OpenClawがRemote CDP経由で接続するよう仕向けます。
選択肢B: Windows のフォールバックとして Docker Desktop を使う
ネイティブな方法がどうにも噛み合わないときは、WindowsのDocker Desktopでheadless Chromiumコンテナを走らせる手があります。
docker run -d --name openclaw-browser -p 9222:9222 --shm-size=2g browserless/chrome
# OpenClaw 側の設定: cdpUrl: "ws://localhost:9222"
ひと手間増えますが、人によってはこちらのほうが安定します。動くには動く、ただしスマートとは言いがたい——そんな立ち位置の方法です。
Windows 特有のエラー一覧
| エラー | 原因 | 解決策(PowerShell) |
|---|---|---|---|
| Port 9222 already in use | 別の DevTools セッションが開いている | Get-Process -Id (Get-NetTCPConnection -LocalPort 9222).OwningProcess | Stop-Process -Force |
| Chrome binary not found | パスが違う | Get-ChildItem "C:\Program Files*\Google\Chrome\Application\chrome.exe" -Recurse |
| Tailscale connection refused | Windows Firewall がブロックしている | New-NetFirewallRule -DisplayName "OpenClaw" -Direction Inbound -LocalPort 18789 -Protocol TCP -Action Allow |
| npm permission errors | 管理者として実行していない | PowerShell を管理者権限で起動するか、nvm-windows を使う |
上に並べたコマンドは、すべてPowerShell向けです。bashではありません。そのままコピー&ペーストしてお使いください。
OpenClaw ブラウザ自動化のための bot 対策サバイバルガイド
bot検知は、OpenClawユーザーが何よりも頭を悩ませる難所です。OpenClawの標準Chromiumには、気配を消すための仕掛けが備わっていません。だからWebDriverフラグ、画面サイズ、フォント指紋、IP評価といった手がかりから、サイトにあっさり正体を見抜かれます。私自身、ものの数秒でブロックされる場面を、数え切れないほど見てきました。
ただし、対策には段階があります。まずは手軽なところから始め、必要に迫られたら一段ずつ強めていけば、それで十分です。
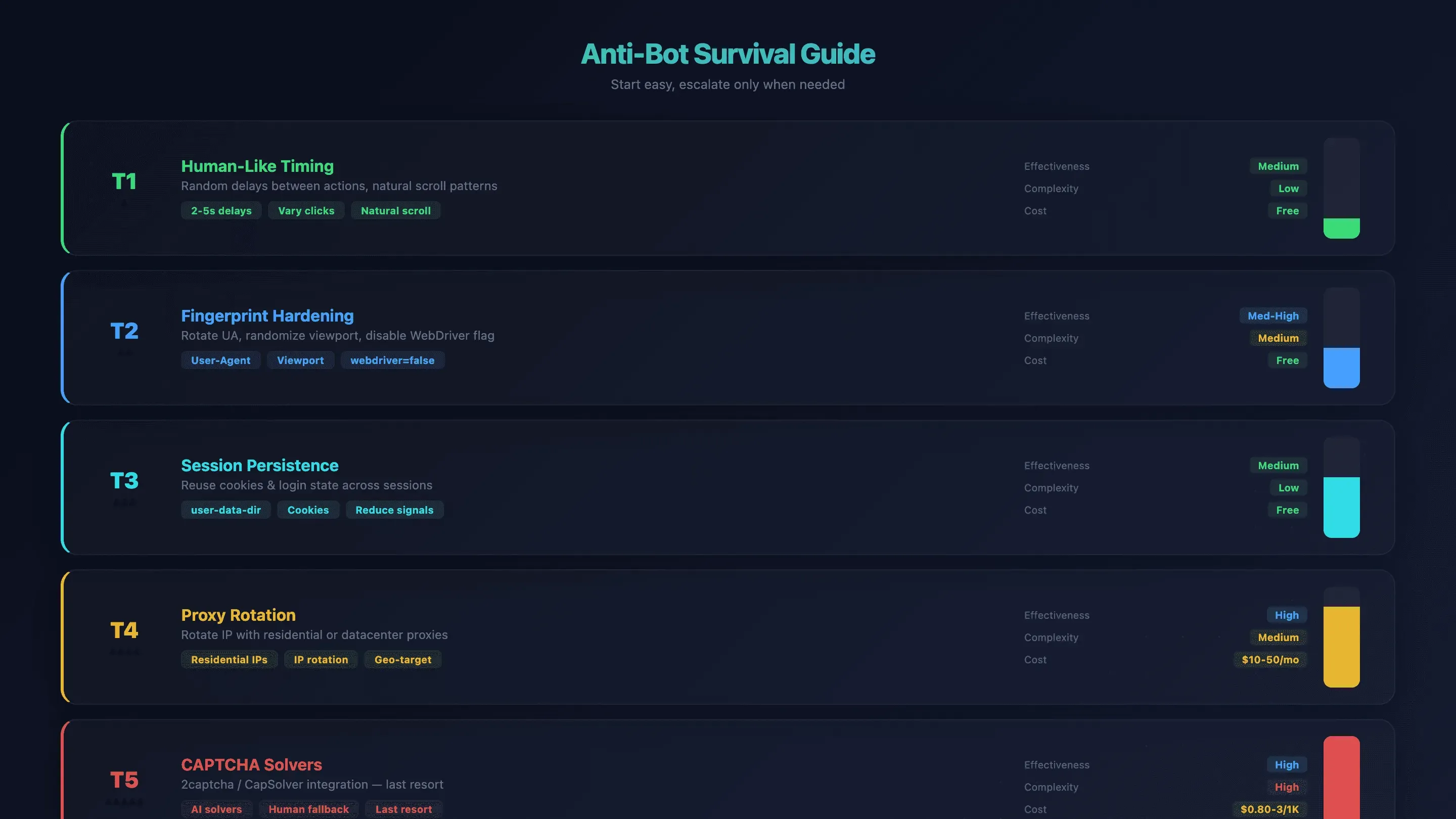
Tier 1: 人間らしい速度と動きにする
プロンプトの中に、操作と操作の合間のランダムな待ちを織り込んでください。機械のように連打させず、「各クリックの間に2〜5秒空けて」と指示します。AIは自前でもある程度はタイミングを散らしてくれますが、こちらから明示すると、さらに人間くさい動きになります。
効果: 中 | 難易度: 低 | コスト: 無料
Tier 2: 指紋を強化する
User-Agentを差し替え、viewportのサイズをランダムに振り、navigator.webdriver フラグをOpenClaw側で勝手に無効化させます(--disable-blink-features=AutomationControlled を使います)。
# カスタムヘッダーを設定
openclaw browser set headers --headers-json '{"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 Chrome/124.0.0.0 Safari/537.36"}'
# viewport をランダム化
openclaw browser set viewport 1366 768
# タイムゾーンとロケールを設定
openclaw browser set timezone America/New_York
openclaw browser set locale en-US
もっと手強い検知をかわす必要があるなら、コミュニティでは Camoufox(Firefoxを土台にしたアンチ検知ブラウザで、C++のレベルでフィンガープリントを偽装するもの)が推されています。
効果: 中〜高 | 難易度: 中 | コスト: 無料
Tier 3: セッションを保持する
user-data-dir を活用して、Cookieやログイン状態をセッションをまたいで持ち越します。こうすると、bot対策がいちばん警戒する「下ろしたての新品ブラウザ」感が和らぎます。
openclaw config set browser.profiles.persistent.userDataDir "/path/to/chrome-profile"
openclaw config set browser.profiles.persistent.cdpPort 18802
効果: 中 | 難易度: 低 | コスト: 無料
Tier 4: プロキシを切り替える
タイミングや指紋の調整だけでは押し切れないなら、IPそのものを切り替えます。住宅回線系のプロキシは検知されにくく、データセンター系は速くて懐に優しいのが持ち味です。
export OPENCLAW_BROWSER_PROXY="http://user:pass@proxy.example.com:8080"
注意: ブラウザ単位でのプロキシ設定は、現状ではまだ要望の段階にとどまっています(GitHub Issue #8079)。当面はOSレベルか、環境変数での指定が必要です。
| プロバイダー | Residential | Datacenter | 向いている用途 |
|---|---|---|---|
| Bright Data | $4–8.40/GB | $0.43–0.60/GB | 企業用途、高品質重視 |
| Oxylabs | $6–8/GB | $0.48–5/GB | 大規模スクレイピング |
| Decodo (Smartproxy) | $4–5.50/GB | $0.70–5/GB | 中程度の予算 |
| IPRoyal | $5–7/GB | -- | 低予算向け |
| DataImpulse | $1/GB | -- | 最安重視 |
効果: 高 | 難易度: 中 | コスト: 月額 $10〜50
Tier 5: CAPTCHA 解決サービスを使う
ここまで来たら最終手段です。2captchaやCapSolverを組み込みます。
| サービス | reCAPTCHA v2 | Cloudflare Turnstile | 待ち時間 |
|---|---|---|---|
| 2Captcha | $2.99/1K | $2.99/1K | 15〜45秒(人力) |
| CapSolver | $0.80–1.50/1K | $0.80/1K | 0.5〜10秒(AI) |
FlareSolverr(オープンソースのCloudflare回避ツール)については、Cloudflare側の防御が一段と固くなった2025〜2026年時点では、当てにしづらくなっているとされています。
効果: 高 | 難易度: 高 | コスト: 解決1,000件あたり $0.80〜3
bot 対策まとめ
| 手法 | 効果 | 難易度 | コスト |
|---|---|---|---|
| 人間らしい速度 | 中 | 低 | 無料 |
| 指紋強化 | 中〜高 | 中 | 無料 |
| セッション保持 | 中 | 低 | 無料 |
| プロキシ切り替え | 高 | 中 | 月額 $10〜50 |
| CAPTCHA 解決 | 高 | 高 | 解決1,000件あたり $0.80〜3 |
botの壁に何度も阻まれ、もう細かいことはいいからデータだけ手に入れたい——そんな心境なら、Thunderbitのクラウドスクレイピングが、公開サイト向けのbot対策を最初から面倒みてくれます。プロキシの設定も、指紋いじりも一切いりません。毎回AIが、管理されたクラウド基盤を経由してサイトを読み取るという、まったく別の発想のアプローチなので、ありふれたデータ抽出なら、bot対策の泥仕合をまるごと素通りできます。
実際の出力:OpenClaw ブラウザ自動化で何ができるのか
45〜75分のセットアップに腰を据える前に、最後にどんな成果が手に入るのか、先に見ておきたいですよね。当然の願いです。ここでは、3つのワークフロー例と、実際に返ってきた出力を紹介します。
例1: Webスクレイピング — 商品データの抽出
プロンプト: 「https://books.toscrape.com に移動して、ページ内のすべての本のタイトルと価格を抽出して」
出力(最初の5行):
| タイトル | 価格 |
|---|---|
| A Light in the Attic | £51.77 |
| Tipping the Velvet | £53.74 |
| Soumission | £50.10 |
| Sharp Objects | £47.82 |
| Sapiens: A Brief History of Humankind | £54.23 |
経過時間: 1ページ20件で約45秒。ページ送りには「Next ボタンをクリックして5ページ分繰り返して」という追加の一言が必要でした。合わせて約100件、所要は約3分です。
例2: フォーム自動化 — 複数項目のWebフォーム入力
シナリオ: 会社名、連絡先、製品への関心などを記入する、仕入先問い合わせフォーム。
エージェントはまずフォームのスナップショットを取り、各入力欄を参照番号で見分けたうえで、上から順に埋めていきます。入力前は空っぽ、入力後はすべて埋まり、確認メッセージが現れます。ドロップダウンやチェックボックスもスナップショットで認識し、当てはまる選択肢をきちんと選び取ります。
経過時間: 6項目のフォームで約30秒。
例3: ページ送り — 複数ページにまたがるスクレイピング
最初の結果: 1ページ目から20件。そこへ「Next をクリックして全ページ繰り返して」と指示すれば、books.toscrape.com の50ページから合計1,000件を回収できます。エージェントはスナップショットで「Next」ボタンを探し当て、ループで押し続けます。
経過時間: 1,000件すべてで約12分。
Thunderbit で同じスクレイピングをした場合
同じbooks.toscrape.comの例をThunderbitでやると、流れはこうなります。
- Thunderbit Chrome 拡張機能 を入れる(約30秒)
- ページを開く
- 「AI Suggest Fields」をクリック → AI が Title、Price、Availability、Rating を検出
- 「Scrape」をクリック → 20件を抽出
- ページ送りを使う → 全ページを抽出
- Google Sheets に無料でエクスポート
合計時間: ゼロからデータ書き出しまで約3分。VPS も CLI も設定も不要です。
肝心なのは、どちらが「優れているか」という勝ち負けではありません。あなたが今やりたいことに、どちらがしっくりはまるか、その一点です。
OpenClaw ブラウザ自動化がやりすぎになるケースと、その代替
OpenClawが本領を発揮するのは、ログイン必須の込み入ったワークフロー、ブラウザ操作とシェルコマンドの連携、VPS上での24時間稼働といった、多段階のエージェント型自動化です。ところが、「一覧ページから商品データを抜きたい」「ディレクトリからメールアドレスを集めたい」程度の目的なら、VPS + Tailscale + node host まで丸ごと組む構成は、いささか仰々しすぎるかもしれません。
私はこれまで、60分以上もかけてセットアップした挙げ句、もっと手軽なツールなら2分で片付くはずの作業に取り組んでいる人を、何度となく見てきました。お世辞にも割のいい取引とは言えません。
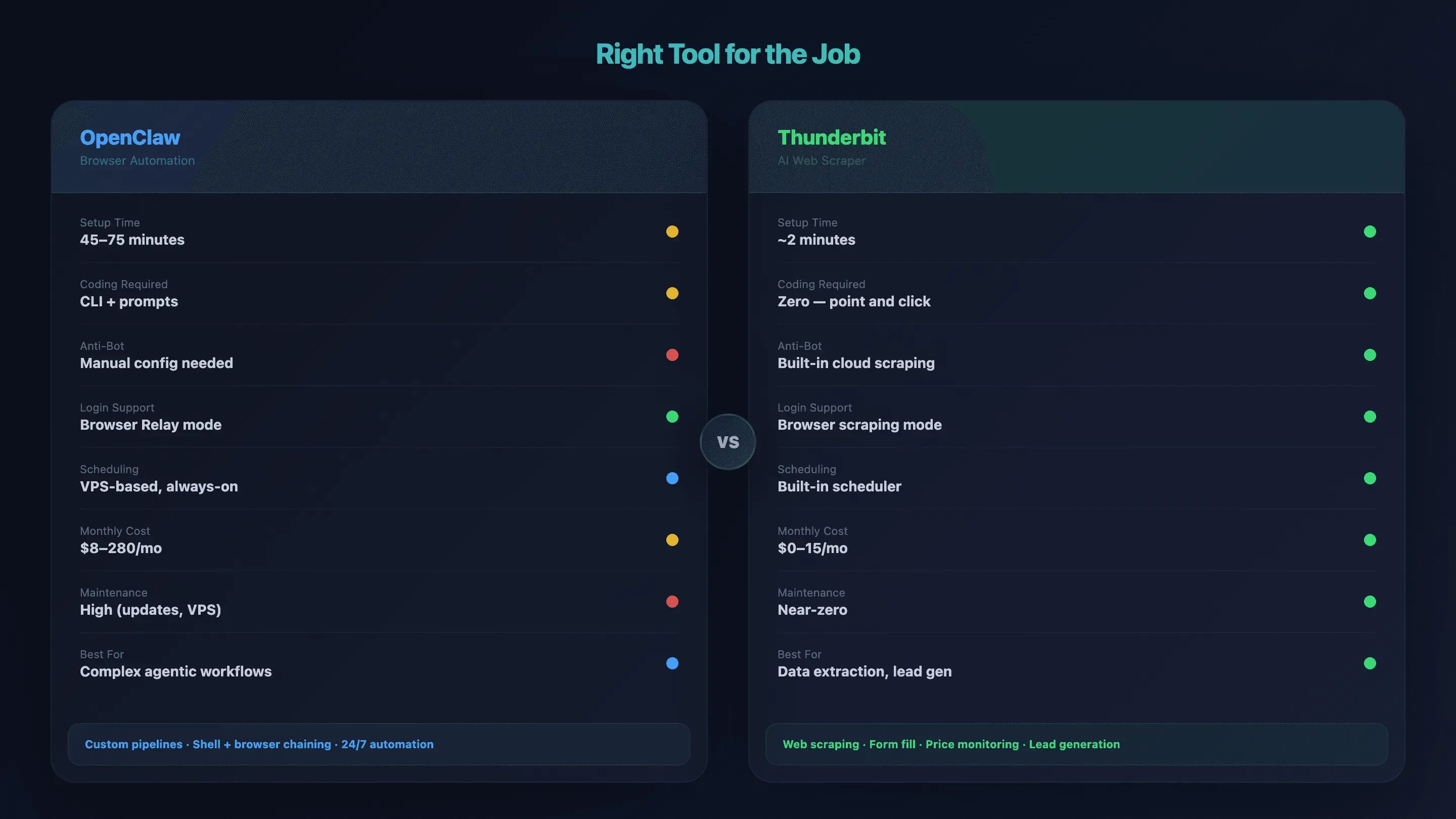
目的に合うツール:比較表
| 項目 | OpenClaw Browser Automation | Thunderbit |
|---|---|---|
| セットアップ時間 | 45〜75分(VPS + Tailscale + node host) | 約2分(Chrome 拡張機能を入れるだけ) |
| コーディングの必要性 | CLI + 自然言語プロンプト | なし — 「AI Suggest Fields」→「Scrape」をクリックするだけ |
| bot 対策対応 | 手動(プロキシ、指紋設定) | クラウドスクレイピングを標準搭載 |
| ログイン壁の処理 | ✅ Browser Relay / リモートデバッグ | ✅ ブラウザスクレイピングモード |
| サブページの拡張取得 | ワークフローごとに自作 | 1クリックでサブページ抽出 |
| 定期実行 / 24時間稼働 | VPS ベースで常時稼働 | 定時スクレイパー を標準搭載 |
| 月額コスト | $8〜14(趣味利用)〜 $110〜280(高負荷) | $0(無料枠)〜 $15/月 |
| 保守負担 | 大(更新、VPS、デバッグ) | ほぼなし — AI がレイアウト変更に追従 |
| 向いている用途 | 複雑なエージェントワークフロー、独自パイプライン | データ抽出、フォーム入力、リード獲得、価格監視 |
ユースケース別の選び方
- ブラウザ操作、メッセージアプリ、データベースをまたぐ多段階のエージェントワークフローが必要 → OpenClaw が向いています。
- ターミナルに一切触れず、Webサイトのデータ抽出、フォーム入力、価格監視を済ませたい → Thunderbit のほうが断然早いです。 手っ取り早いデモは Thunderbit YouTube チャンネル でも見られます。
- 特定の API エンドポイント向けに、軽めのスクリプトが欲しいだけ → 素朴な Python の requests スクリプトで事足りるかもしれません。
チームの誰かに「この作業、どのツールがいい?」と尋ねられたとき、私はいつもこのものさしで答えを出しています。
OpenClaw ブラウザ自動化でよくあるエラーと解決法
このセクションは、ブックマーク推奨です。症状ごとに仕分けてあるので、Ctrl+Fで原因にすぐ飛べます。
「Connection Refused」または Node Host が接続できない
考えられる原因(順番に確認):
- 両方の端末で Tailscale が動いていない → 両方で
tailscale statusを実行 - Gateway が Tailscale ネットワークではなく localhost を見ている →
openclaw config set gateway.listen "100.x.x.x:18789" - IP アドレスの間違い →
tailscale ip -4で確認 - ファイアウォールが 18789 番ポートを遮断している →
sudo ufw allow 18789/tcp(Linux)または Windows Firewall のルールを追加
拡張機能のバッジが「OFF」のまま、またはタブが検出されない
- 拡張機能が Developer mode で読み込まれていない →
chrome://extensionsで Developer mode を有効化し、再読み込み - Node host が起動していない →
openclaw node startで再起動 - Chrome インスタンスが競合している → すべての Chrome を閉じて再起動し、拡張機能を再読み込み
エージェントが空データ、または誤ったデータを返す
- ページがまだ完全に読み込まれていない: 「移動後3秒待ってから抽出して」と指示する。SPA は描画に時間がかかることがあります。
- bot ブロック: 実データではなく CAPTCHA ページを見ていないか確認。Sandbox Chromium から Browser Relay に切り替えます。
- スナップショットが古い: 「新しいスナップショットを取得して」と伝える。ナビゲーション後は参照番号が古くなります。
「Port 9222 Already in Use」
ChromeのDevToolsや、別の自動化ツールが、そのポートを先に握っているときによく起こります。
# macOS/Linux
lsof -i :9222 | grep LISTEN
kill -9 <PID>
# Windows PowerShell
Get-Process -Id (Get-NetTCPConnection -LocalPort 9222).OwningProcess | Stop-Process -Force
VPS のメモリが足りなくなる
ヘッドレスブラウザは、1つあたりRAMを400〜800MB食います。これを何個も同時に走らせれば、小ぶりなVPSはいともたやすく音を上げます。
対策:
- 画像 / CSS / フォントの読み込みを無効化:
openclaw browser network route --abort "**/*.{png,jpg,gif,css,woff2}" - 同時起動数を RAM に合わせて制限する
- Docker 設定で
shm_size: '2gb'を使う - セッション休止を有効化:
OPENCLAW_HIBERNATE_AFTER=300 - 必要に応じて 4GB 以上の VPS にアップグレードする
OpenClaw ブラウザ自動化を安定して動かすコツ
長らく運用してきて、身体に染みついたベストプラクティスをいくつか書き留めておきます。
- データ取得だけが狙いなら、画像・CSS・フォントはきっぱり無効化しましょう。リソースの食い込みが目に見えて軽くなり、速度も上向きます。
- タスクごとにブラウザを起こし直すのではなく、同じインスタンスを使い回しましょう。立ち上げ直すたびにRAMを浪費しますし、bot対策の網にも引っかかりやすくなります。
- 入り口はあくまでシンプルなプロンプトで。AIの解釈がずれたときに限って、細部を補ってください。説明を盛りすぎると、助けるどころか混乱の種になります。
- VPSのリソース(CPU、RAM)には常時目を配り、限界に達する手前でスケールアップを。深夜2時に落ちたVPSの原因究明ほど、しんどい作業はそうありません。
- OpenClawとChrome拡張機能はこまめに更新しつつ、まずはステージング環境で当たりを取りましょう。OpenClawは月におよそ13回もリリースされますが、毎回つつがなく、というわけにはいきません。
- 毎日・毎週こなす定型作業(価格チェック、リード抽出など)は、Thunderbitの定時スクレイパーに任せれば、自然な言葉で実行間隔を決められ、VPSの守りから完全に手を引けます。
倫理面と法的な注意点
短い項目ですが、外せません。robots.txt を尊重し(RFC 9309 としてIETFが標準化しています)、リクエストには間隔を空け、対象サイトの利用規約に目を通し、個人データは個人情報保護法をはじめとする各種プライバシー法の枠内で扱ってください。hiQ v. LinkedIn の判例(2022年)は、公開データのスクレイピングそれ自体がCFAA違反にはならないと示しましたが、だからといって「何でもあり」という免罪符ではありません。自動化を節度を持って扱うことは、結局のところ、自分自身と自社の両方を守る盾になります。このあたりは、web scraping legal implications のガイドも合わせて目を通しておくとよいでしょう。
まとめ
OpenClawのブラウザ自動化は、自然言語で操れる、複雑な多段階Webワークフローにおいて、めっぽう頼れる切り札です。胸に刻んでおきたい要点は、次の5つに集約されます。
- 最初にブラウザモードを正しく選ぶこと(Sandbox、Relay、Remote CDP)。これだけで、後々のデバッグ時間を大きく節約できます。
- Windowsでも道は通っているものの、Windows固有のコマンド、ファイアウォール、パスの食い違いには油断禁物です。
- bot対策は、想像以上に手強いです。まずはタイミング調整や指紋対策といった手軽なものから入り、必要になったら段階的に火力を上げてください。
- 手を動かす前に、出力を見ておくこと。一覧ページから構造化データが取れれば十分なら、Thunderbitのようなノーコードツールのほうが、数分で立ち上がり、保守の手間もほとんどかかりません。
- 保守コストを織り込んでおくこと。OpenClawは月に約13回リリースされ、VPSの費用もじわじわ積み上がり、デバッグもまた運用の一部です。
とりあえず手軽な道から試したいなら、Thunderbitには無料プランが用意されています。拡張機能を入れ、ページを1つスクレイピングして、自分の用途に合うかを見極めてから、VPSを使った本格構成へ歩を進めるのも一案です。OpenClawの道を選ぶなら、このガイドをぜひブックマークしておいてください。いずれエラー一覧のお世話になる日が来ます。そして願わくば、ブラウザインスタンスのRAMが、いつでもたっぷり余っていますように。
よくある質問
OpenClaw の Sandbox Chromium と Browser Relay の違いは何ですか?
Sandbox Chromiumは、サーバー側でヘッドレスブラウザを立ち上げます。速くて準備も軽い反面、毎回まっさらなプロファイルを使うので、ログインセッションは持ち越せず、bot対策にも足がつきやすくなります。一方のBrowser Relayは、ローカル端末にある本物のChromeへ指示を送るため、ログインが効き、実ブラウザの指紋も引き継げて、サイトから自動化だと見破られにくくなります。引き換えに、ネットワーク中継のぶん速度は落ち、機能の制限(バッチ処理不可、ダウンロード介入不可)もついて回ります。
WSL を使わずに Windows で OpenClaw のブラウザ自動化はできますか?
はい、条件付きで可能です。Windowsでもっとも安定が見込めるネイティブの方法は、PowerShellからChrome Remote Debuggingを使うやり方です(chrome.exe --remote-debugging-port=9222)。それでも落ち着かないなら、Docker Desktopが受け皿になります。WindowsでのNode Hostの完全なネイティブ対応には、まだ荒削りな部分が残っているので、最新のドキュメントに目を通し、ファイアウォールやバイナリのパスの食い違いに備えておいてください。なお、このガイドのWindowsセクションのコマンドはすべてPowerShell用です。bashではありません。
OpenClaw のブラウザ自動化で CAPTCHA はどう対処しますか?
入り口は、まず検知されにくくすることです。人間らしい待ちを挟み、ブラウザ指紋を強化し、セッションを保持して「新品ブラウザ」扱いを避けます。それでもCAPTCHAが立ちはだかるなら、2captcha(解決1,000件あたり $2.99)やCapSolver($0.80〜1.50/1K、AIベース)といった解決サービスを組み込みます。公開サイトでただデータが欲しいだけなら、Thunderbitのクラウドスクレイピングが、プロキシやCAPTCHAの設定なしで自動的にさばいてくれます。
OpenClaw のブラウザ自動化は無料で使えますか?
OpenClaw本体は、オープンソース(MITライセンス)で無料です。ただし、動かすにはインフラが欠かせません。VPSが月額 $4〜15 ほど、必要に応じてプロキシ切り替え(月額 $10〜50)やCAPTCHA解決サービス(解決ごとの課金)が上乗せされていきます。月額の合計は、趣味利用なら $8〜14、高負荷の運用なら $110〜280 ほどに落ち着きます。これに対して、Thunderbitの無料プランなら、インフラ費用ゼロで基本的なスクレイピングができます。
OpenClaw のエージェントが空結果ばかり返す場合はどうすればいいですか?
確かめる順番は3つです。まず、ページが読み切れていない可能性。「移動後3秒待ってから抽出して」と指示してみてください。次に、botの壁にぶつかっている可能性。エージェントが本物の中身ではなくCAPTCHAページを眺めているなら、Sandbox ChromiumからBrowser Relayへ切り替えます。最後に、スナップショットが古くなっている可能性。ナビゲーションのあとは「新しいスナップショットを取得して」と伝えてください。どれにも当てはまらないなら、VPSのメモリ使用量を疑いましょう。ブラウザが落ちても、空っぽの結果だけを黙って返してくることがあります。
より速いWebデータ抽出なら Thunderbit を試す Get Started Free




