

いまやインターネットを行き交うトラフィックの半分はボットだと言われています。その裏側で価格調査からAI学習用データの収集まで、ありとあらゆる作業を黙々とこなしているのがオープンソースのウェブクローラーです。SaaSと自動化の現場に何年も身を置いてきて、確信していることがひとつあります。セルフホスト型クローラーの選択を最初に間違えなければ、チームが抱える数か月分の悩み、そして深夜のデバッグ地獄は、かなりの部分を回避できるということです。数ページの商品情報を抜くだけのケースから、研究目的で数百万URLを巡回するケースまで、ここで紹介するオープンソースのFirecrawl代替ツールなら、規模も技術スタックも問わず、どこかに自分たちに合うものが見つかるはずです。
ただ、先に釘を刺しておきます。すべてを解決する万能ツールは存在しません。Scrapyのような生のスループットが要るチームもあれば、Heritrixのアーカイブ精度が必要な現場もある。一方で、オープンソースライブラリの保守コストに耐えられないと感じる人もいます。そこで本記事では、2026年に押さえておきたいオープンソースのFirecrawl代替ツールを9つ厳選し、それぞれの得意分野を整理しました。試行錯誤で消耗する前に、自社に合う一本を見極める材料にしてください。
ビジネスに最適なオープンソースFirecrawl代替ツールの選び方
リストを眺める前に、選定の軸を先に決めておきましょう。オープンソースのクロール環境は年々選択肢が増えており、なんとなくで選ぶと後で後悔します。判断のポイントは次のとおりです。
- 使いやすさ: ポイント&クリックの画面が欲しいですか、それともPython、Go、JavaScriptでコードを書くことに抵抗はありませんか?
- 拡張性: 1つのサイトをスクレイピングしたいだけですか、それとも数百のドメインにまたがって何百万ページもクロールする必要がありますか?
- コンテンツの種類: 対象サイトは静的なHTMLですか、それとも重いJavaScriptや動的読み込みに依存していますか?
- 連携要件: データはどう使いたいですか?Excelに出力する、データベースに送る、分析パイプラインに流し込む、などです。
- 保守性: 自作コードを継続的にメンテナンスする余力がありますか?それとも、サイト変更に自動で追従するツールが必要ですか?
判断の助けになるよう、簡単な早見表を用意しました。
| シナリオ | 最適なツール |
|---|---|
| ノーコード、オフライン閲覧 | HTTrack |
| 大規模・複数ドメインのクロール | Scrapy, Apache Nutch, StormCrawler |
| 動的/JSが多いサイト | Puppeteer |
| フォーム自動化/ログイン必須 | MechanicalSoup |
| 静的サイトのダウンロード/アーカイブ | Wget, HTTrack, Heritrix |
| Go開発者向け、高速処理 | Colly |
ここからは、2026年向けのオープンソースFirecrawl代替ツール9選を順番に見ていきます。
1. Scrapy: 大規模Pythonクロールに最適
オープンソースクローラーの世界で重量級の王者を挙げるなら、まずScrapyです。Python製で、数百万ページ規模、頻繁な更新、込み入ったサイトロジックを相手にする開発者にとって、長年の定番であり続けています。
Scrapyが選ばれる理由
- 圧倒的なスケール: 毎秒数千件のリクエストをさばき、毎月数十億ページを扱う企業の現場でも稼働しています(Zyte)。
- 拡張性とモジュール性: 独自のスパイダーを書き、プロキシ用のミドルウェアを差し込み、ログイン処理を組み込んで、JSON・CSV・データベースへ自在に出力できます。
- 活発なコミュニティ: プラグイン、ドキュメント、Stack Overflowの回答が潤沢にそろっています。
- 実運用で実績あり: EC、ニュース、研究の各チームが世界中で本番運用しています。
注意点: 開発者でない人にとっては学習曲線がやや急で、サイトが変わるたびにスパイダーの保守が発生します。とはいえ、完全な制御性と拡張性を最優先するなら、これ以上頼れる相棒はそういません。
2. Apache Nutch: エンタープライズ検索エンジンに最適
Apache Nutchは、オープンソースクローラーの長老格です。エンタープライズ規模、さらにはインターネット規模のクロールを前提に設計されています。自前の検索エンジンを立ち上げたい、あるいは数百万ドメインを巡回したい。そんなときに真価を発揮します。
Apache Nutchが選ばれる理由
- Hadoopで実現する大規模処理: Hadoop上で動き、サーバークラスタをまたいで数十億ページを処理できます(公開ウェブのクロールにはCommon Crawlも採用しています)。
- バッチクロール: シードURLの一覧を渡して走らせるだけ。定期実行の大規模ジョブとの相性が抜群です。
- 連携性: Solr、Elasticsearch、大規模データパイプラインとつながります。
注意点: HadoopクラスタやJavaの設定ファイルなど、立ち上げまでの道のりが長めです。狙いも構造化データの抽出より生のクロールに寄っています。小さな案件には完全にオーバースペックですが、ウェブ規模となると他を寄せ付けません。
3. Heritrix: ウェブアーカイブとコンプライアンスに最適
Heritrixは、Internet Archiveが自ら開発したクローラーです。ウェブアーカイブとデジタル保存という、はっきりした目的のために作られています。
Heritrixが選ばれる理由
- アーカイブ品質の網羅性: ページ、アセット、リンクまで丸ごと取得するので、法令対応や歴史的スナップショットの保存にうってつけです。
- WARC出力: すべてを標準化されたWeb ARChiveファイルに保存でき、再生や分析にそのまま使えます。
- Webベースの管理画面: ブラウザのUIからクロールの設定や監視ができます。
注意点: 動作は重く、ディスクとメモリをかなり食います。JavaScriptは実行できず、出力されるのは構造化テーブルではなく生のアーカイブです。図書館やアーカイブ機関、規制の厳しい業界に向いています。
4. Colly: 高速なGo開発者に最適
Collyは、Go開発者から厚い支持を集める、軽量で速い並列処理向けのスクレイパーです。
Collyが選ばれる理由
- 驚異的な高速性: Goの並行処理を活かし、CPUやRAMの負荷を抑えながら数千ページを一気にさばけます(Oxylabs)。
- シンプルなAPI: HTML要素ごとにコールバックを定義でき、Cookieやrobots.txtも自動でさばきます。
- 静的サイトに最適: サーバーサイドレンダリングのページやAPI、あるいはGoバックエンドにスクレイピングを組み込みたいときにぴったりです。
注意点: JavaScriptレンダリングは標準では用意されていません。動的サイトではChromedpなどと組み合わせる必要があり、Goの知識も前提になります。
5. MechanicalSoup: シンプルなフォーム自動化に最適

MechanicalSoupは、素朴なHTTPリクエストと本格的なブラウザ自動化のちょうど中間を埋めるPythonライブラリです。
MechanicalSoupが選ばれる理由
- フォーム自動化: ログイン、フォーム入力、セッション維持が手軽にでき、認証後のスクレイピングに向いています。
- 軽量: 内部でRequestsとBeautifulSoupを使っているので動きが軽く、導入もすぐ済みます。
- 対話型サイトに最適: 検索フォームの送信やログイン後のデータ取得が必要なら、有力な選択肢になります(Apify Blog)。
注意点: JavaScriptは動かせないため、JS依存の強いサイトでは力を発揮できません。静的ページやサーバーレンダリングのページで、ちょっとした操作だけ済ませたいケース向けです。
6. Puppeteer: 動的サイト・JavaScriptが多いサイトに最適
Puppeteerは、JavaScript依存の強いモダンなウェブサイトを相手にするときの万能ツールです。ヘッドレスChromeを丸ごと制御できるNode.jsライブラリだと考えてください。
Puppeteerが選ばれる理由
- 動的コンテンツに対応: SPA、無限スクロール、AJAXで後から読み込まれるページもスクレイピングできます(Browserless Guide)。
- ユーザー操作の再現: ボタンのクリック、フォーム入力、スクリーンショット取得、プラグインを使えばCAPTCHA解決までこなします。
- 強力な自動化: テスト、監視、そして実際のユーザーが目にするものすべての取得に向いています。
注意点: フルChromeを動かす以上リソースを多めに消費し、HTTPのみのスクレイパーよりは遅くなります。大規模に回すなら、十分なハードウェアかクラウドオーケストレーションが前提です。
7. Wget: コマンドラインで素早くダウンロードしたいときに最適

Wgetは、静的サイトやファイルをまとめて落とすときの、昔ながらの定番コマンドラインツールです。
Wgetが選ばれる理由
- シンプルさ: コマンド1つでサイト全体やディレクトリを丸ごとダウンロードできます。コーディングは一切要りません。
- 高速: C言語で書かれており、速くて無駄がありません。
- 静的コンテンツに最適: ドキュメントサイト、ブログ、大量ファイルのダウンロードに向いています(HuggingFace Guide)。
注意点: JavaScript実行やフォーム処理には非対応で、生のページをそのまま落とすだけです(構造化データにはなりません)。静的サイト専用の“掃除機”だとイメージするとわかりやすいでしょう。
8. HTTrack: オフライン閲覧に最適なノーコードツール
HTTrackは、Wgetを使いやすくした姉妹版のような存在です。サイトをミラーリングするためのグラフィカルな画面を備えています。
HTTrackが選ばれる理由
- GUIのわかりやすさ: ステップ形式のウィザードがあり、技術職でない人でも迷わず扱えます。
- オフライン閲覧: リンクを自動で書き換えてくれるので、ミラーしたサイトをローカルでそのまま閲覧できます。
- アーカイブ用途に最適: 研究者やマーケター、コードを書かずにサイトのスナップショットを残したい人にぴったりです(Reddit DataHoarder)。
注意点: 動的コンテンツには対応せず、大規模サイトでは動作が遅くなりがちです。構造化データの抽出を目的とした設計でもありません。
9. StormCrawler: リアルタイムの分散クロールに最適

StormCrawlerは、リアルタイムかつ継続的なウェブデータを大規模に扱いたいチーム向けの、現代的な分散クローラーです。
StormCrawlerが選ばれる理由
- リアルタイムクロール: Apache Storm上で動き、データをストリームとして処理します。ニュース監視や検索エンジンとの相性が抜群です(Wikipedia)。
- モジュール性と拡張性: 解析、インデックス作成、独自処理のboltを必要に応じて足していけます。
- Common Crawlで採用: 最大級の公開ウェブアーカイブのひとつで、ニュースデータセットの基盤を支えています。
注意点: Java開発とStormクラスタが前提なので、分散システムに慣れたチーム向けです。小規模な案件には明らかにやりすぎです。
オープンソースのFirecrawl代替ツール比較: どの無料競合が自分に合う?
ここまでの9ツールを、一覧で並べて見比べてみましょう。
| ツール | 最適な用途 | 主な利点 | 欠点 | 言語 / セットアップ |
|---|---|---|---|---|
| Scrapy | 大規模・高頻度のクロール | 高性能、拡張性が高い、コミュニティが大きい | 学習曲線が急、Pythonが必要 | Pythonフレームワーク |
| Apache Nutch | エンタープライズ、ウェブ規模のクロール | Hadoopで大規模対応、実績あり | セットアップが複雑、バッチ向け | Java/Hadoop |
| Heritrix | アーカイブ、コンプライアンス対応のクロール | サイトを完全取得、WARC出力 | 重い、JS非対応、生のアーカイブ | Javaアプリ、Web UI |
| Colly | Go開発者、高性能スクレイピング | 高速、APIがシンプル、並列処理に強い | JS非対応、Goが必要 | Goライブラリ |
| MechanicalSoup | フォーム自動化、ログイン後のスクレイピング | 軽量、セッション管理に対応 | JS非対応、規模に制限あり | Pythonライブラリ |
| Puppeteer | 動的/JSが多いサイト | ブラウザを完全制御、自動化が強い | リソース消費が大きい、Node.jsが必要 | Node.jsライブラリ |
| Wget | 静的サイトのダウンロード、オフライン閲覧 | シンプル、高速、CLI | JS非対応、生のページ | コマンドラインツール |
| HTTrack | 非技術者向け、サイトのアーカイブ | GUI、オフライン閲覧が簡単 | JS非対応、大規模サイトでは遅い | デスクトップアプリ(GUI) |
| StormCrawler | リアルタイム、分散クロール | 拡張性が高い、モジュール式、リアルタイム | Java/Stormの知識が必要 | Java/Stormクラスタ |
自作すべきか、既存のオープンソースFirecrawl代替ツールを使うべきか?
正直なところ、クローラーを自分で一から組むのは、聞こえだけは楽しそうです。ところが現実は、保守、プロキシ、ボット対策に延々と追われる日々が待っています。ここまで挙げたツールには、長年の試行錯誤とコミュニティの知恵がぎっしり詰まっています。業界レポートも、既存のソリューションを使うほうが、成果を早く確実に手に入れられ、車輪の再発明という遠回りを避けられると指摘しています(IveerData)。
- オープンソースを採用すべき場合: 既存ツールで要件を満たせる、開発時間を短縮したい、コミュニティの支援を重視したい。
- 自作すべき場合: 本当に特殊な要件がある、社内に深い専門知識がある、スクレイピングが事業の中核である。
ただし、エンジニアリングの工数、サーバーの保守、アンチスクレイピングへの継続対応まで足し算すると、オープンソースは決して“タダ”ではありません。コードを書かずに高性能クローラーの恩恵だけ受け取りたいなら、もうひとつ別の道があります。
おまけ: オープンソースが複雑すぎるならThunderbitを試そう
ここまで紹介したツールは開発者にとって心強い味方ですが、共通の弱点も抱えています。コーディングの知識が要る、動的なAIベースのボット対策に弱い、そして継続的な保守から逃れられない。この3点です。
Thunderbitは、こうした足かせを背負いたくない人に、私が真っ先に名前を挙げる選択肢です。高性能なスクレイピングと使いやすさの間にあった溝を、きれいに埋めてくれます。
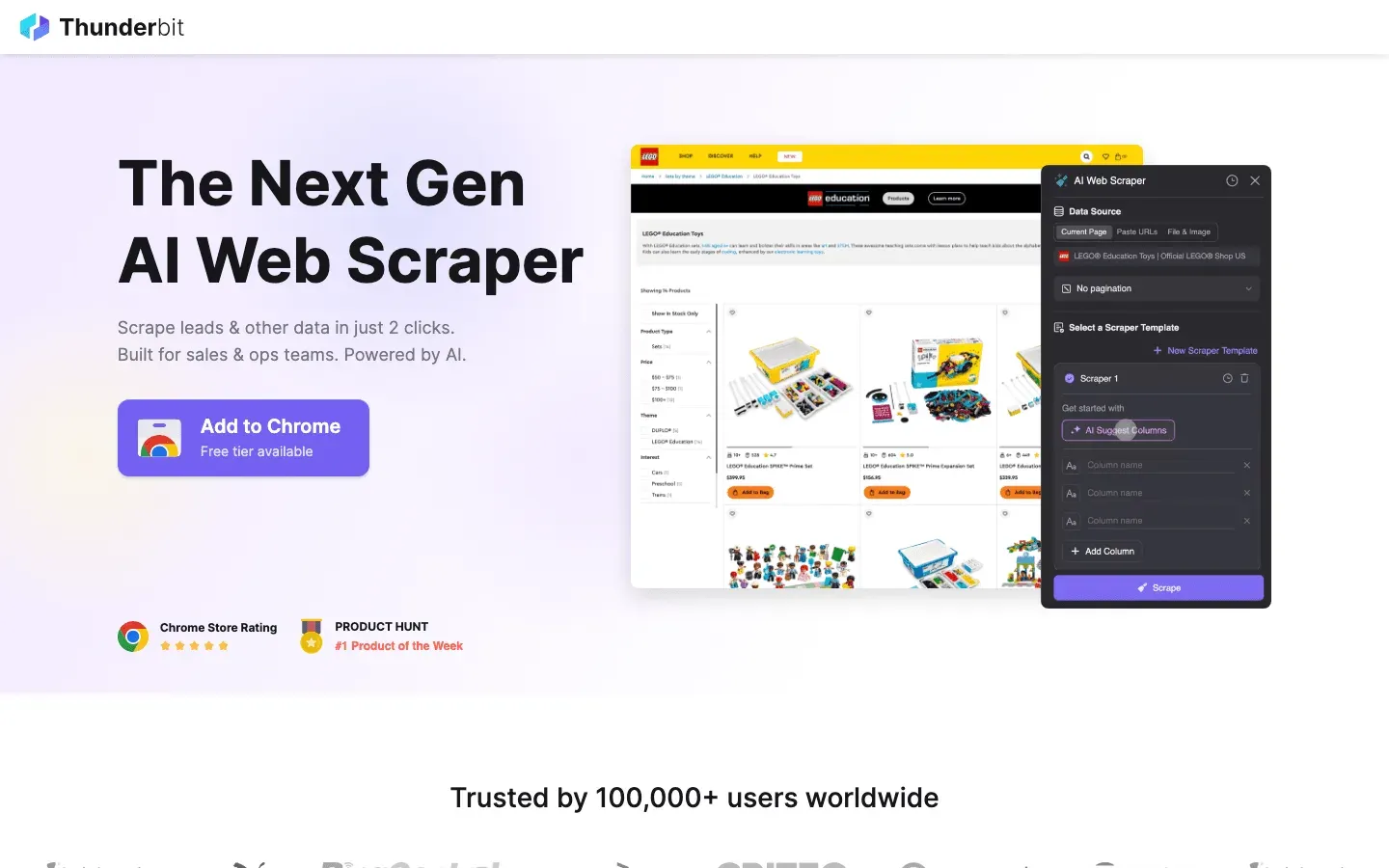
なぜオープンソースよりThunderbitを検討するのか?
- コーディング不要: ScrapyやPuppeteerとは違い、ThunderbitはAI搭載のChrome拡張です。「AIで項目を提案」を押すだけで、スクレイパーができあがります。
- 難しい部分を自動処理: 動的コンテンツも無限スクロールもページ送りもAIが自動でさばくので、カスタムスクリプトを書く手間がぐっと減ります。
- 即時エクスポート: WebページからExcel、Google Sheets、Notionへ、わずか2クリックで書き出せます。
- 保守不要: サイトのレイアウトが変わってもコードを直す必要はありません。ThunderbitのAIが勝手に追従します。
PythonやGoを覚える余裕はないけれど、いますぐデータが欲しい。そんな営業担当やマーケター、リサーチャーにとって、Thunderbitはこのリストのオープンソースツールを補完する、理想的な一枚になります。
実際の動きを見てみたいですか?Chrome拡張をダウンロードして、ぜひ自分の手で試してみてください。
まとめ: 2026年に最適なセルフホスト型ウェブクローラーを見つける
ウェブスクレイピングガイドをもっと読む Get Started Free
オープンソースのFirecrawl代替ツールの選択肢は、いまがかつてないほど充実しています。ScrapyやNutchの大規模性能が欲しいときも、Heritrixのアーカイブ精度が要るときも、用途に合った答えがどこかに必ずあります。肝心なのは、ツールを目的にきっちり合わせること。ちょっとしたデータ取得に過剰な構成を組むのは禁物ですし、逆にインターネット規模のクロールには出し惜しみせず投資すべきです。
そして、オープンソースのやり方が技術的に重すぎる、時間がかかりすぎると感じたら、Thunderbit のようなAIツールがその重荷をまるごと肩代わりしてくれます。
次の大規模データプロジェクトでは、Scrapyを立ち上げて腰を据えるのもいいでしょう。あるいは、シンプルでAI搭載のスクレイピングがいいならThunderbitを試すという手もあります。ウェブスクレイピングのコツをもっと知りたいなら、Thunderbitブログに詳しい解説やチュートリアルをそろえています。
よくある質問
1. オープンソースのFirecrawl代替ツールを使う主な利点は何ですか?
最大の魅力は、柔軟性とコスト削減、そして自分でホストしてクローラーを自由にカスタマイズできる点です。ベンダーロックインを避けられるうえ、活発なコミュニティからサポートやアップデートを受け取れます。
2. 非技術者がすぐに結果を出したい場合、どのツールが最適ですか?
オフライン閲覧が目的なら、HTTrackが手堅いオープンソースの選択肢です。ただし、Excelの表のような構造化データが欲しいなら、AI機能を備えたおまけツールのThunderbitをおすすめします。
3. 動的でJavaScriptが多いウェブサイトはどう扱えばいいですか?
最有力はPuppeteerです。実際のブラウザを操作できるので、SPAやAJAX読み込みのコンテンツも含め、ユーザーが見えるものなら何でもスクレイピングできます。
4. Apache NutchやStormCrawlerのような重量級クローラーは、どんなときに使うべきですか?
複数ドメインにまたがって何百万ページもクロールするときや、検索エンジンやニュース監視のようにリアルタイムで分散クロールしたいときが出番です。いずれも大規模運用と信頼性を見据えて設計されています。
5. クローラーは自作するべきですか、それとも既存のオープンソースを使うべきですか?
多くのチームにとっては、既存のオープンソースを使い、必要なところだけカスタマイズするほうが、速くて安く、信頼性も高くつきます。自作に踏み切るのは、よほど特殊な要件があり、長期保守に回せるリソースもある場合に限るのが賢明です。
快適なクロールを。あなたのデータが、いつも新鮮で、構造化され、すぐ使える状態でありますように。
Thunderbit AIウェブスクレイパーを無料で試す Get Started Free
さらに詳しく




