インターネット上のデータ需要は年々増えていて、2025年にはが、よりスマートで効率的なウェブスクレイピングを目指すチームの定番ツールになりそうです。営業やEC、そして僕みたいなデータ好きな人も、今や「データを取るだけ」じゃなく「どれだけ速く・大規模に、しかもIPブロックを避けながら」スクレイピングできるかが勝負だと実感しているはず。ウェブスクレイピング市場は2025年に74.8億ドル、2034年には384億ドル近くまで拡大する見込みで()、競争もどんどん激しくなっています。
でも現実は、今のウェブは動的コンテンツやボット対策、頻繁なレイアウト変更など、まるで鉄壁の要塞みたいなもの。ベストプラクティスを無視したり、最新の対策を甘く見ていると、スクレイパーが全然動かなくなることも珍しくありません。ここでは、Node.jsを使ったウェブスクレイピングを効率よく進めるための実践ノウハウを、体験談やちょっとしたユーモアも交えて紹介します。
なぜNode.jsがウェブスクレイピングに向いているのか?
何百、何千ページも一気にスクレイピングしたことがある人なら、スピードと並列処理の大切さを痛感しているはず。Node.jsは非同期・ノンブロッキングI/Oモデルを採用していて、大量のネットワークリクエストを同時にさばくのが得意です()。他の言語がリクエストの完了を待っている間も、Node.jsはイベントループでどんどん次の処理に進みます。
特にJavaScriptで動的に生成されるサイトでは、Node.jsはPythonやJavaよりもリアルタイム性や大規模抽出で強みを発揮します。実際、がNode.jsをバックエンドや自動化に使っていて、今や世界で一番人気のウェブ技術です。
Node.jsと他のウェブスクレイピングフレームワークの比較
ちょっと技術寄りの話ですが、Node.jsと他の主要フレームワークの特徴をざっくりまとめると:
| フレームワーク | 強み | 弱み | 最適な用途 |
|---|---|---|---|
| Node.js | 非同期処理・高い並列性・npmエコシステム・動的サイトに強い | メモリ消費が多い場合あり、コールバック地獄(async/await未使用時) | リアルタイム抽出、JS中心のサイト、大規模マイクロサービス |
| Python | 豊富なライブラリ(BeautifulSoup, Scrapy)、簡潔な文法 | 大量並列処理は苦手、JS描画サイトに弱い | 静的HTML、リサーチ、プロトタイピング |
| Java | 型安全・エンタープライズ向けの堅牢性 | 冗長でスクリプト作成に不向き | 大規模・企業向けスクレイピング |
| Go | 高速・効率的な並列処理 | エコシステムが小さい、学習コスト高め | 高パフォーマンス・低遅延スクレイピング |
多くのビジネスユーザーにとって、Node.jsは「速さ・柔軟性・現代的なJSサイト対応」のバランスが抜群です()。
Node.jsウェブスクレイピング環境の作り方
効率のいいスクレイパーは、しっかりした基盤作りから。おすすめのセットアップ例はこんな感じ:
- プロジェクト構成: モジュールごとに
/src、/libs、/configなどで整理。APIキーやプロキシ情報はdotenvで環境変数管理()。 - HTTPクライアント: 、、など。
- HTMLパース: 静的HTMLは、動的コンテンツはやPlaywright。
- ユーティリティ: でデータ整形、やでバリデーション。
- テスト・リント: Mochaでテスト、ESLintでコード品質管理()。
Node.jsウェブスクレイピングで必須のライブラリ
- axios/got/node-fetch: HTTPリクエスト用。axiosはPromiseベースでJSON処理もラク。
- Cheerio: 高速なjQuery風HTMLパーサー。静的ページ向きでパースも約0.5秒()。
- Puppeteer/Playwright: ヘッドレスブラウザ自動化。動的サイト対応でやや遅い(1ページ約4秒)けど、JS描画必須サイトには欠かせません()。
- dotenv: 環境変数管理。
- csv-writer/jsonfile: データ出力用。
Node.jsウェブスクレイピングでよくある落とし穴と対策
スクレイパーがブロックされたり、クラッシュしたり、データがぐちゃぐちゃになるのは「あるある」です。気をつけたいポイントは:
- robots.txtや利用規約の無視: 必ず事前にチェック。違反するとIPブロックや法的リスクも()。
- サーバーへの過負荷: リクエストを連打せず、1〜3秒のランダム遅延や同時実行数制御で「人間っぽさ」を演出()。
- エラー処理の怠り: try/catchで例外処理、HTTPエラーや失敗時のログ記録、リトライは指数バックオフで()。
- リクエストヘッダーの未設定: User-AgentやAccept-Language、Refererなどを本物のブラウザっぽく設定・ローテーション()。
アンチスクレイピング対策の突破法
今のウェブサイトはボット対策がどんどん強化されています。僕がよく使う回避策は:
- プロキシ/IPのローテーション: プールを用意して、IPを定期的に切り替え()。
- ヘッダーのランダム化: User-AgentやAccept-Languageなどを毎回変える。
- ヘッドレスブラウザのステルス化:
puppeteer-extra-plugin-stealthなどで自動化の痕跡を隠す。 - 人間っぽい動作の再現: ランダムな遅延、マウス移動、スクロール、タイプミスまで再現()。
Node.jsスクレイパーでの人間的な挙動のシミュレーション
ここはちょっと遊び心も大事。例えば:
- アクションごとにランダムな待機(
await page.waitForTimeout(randomDelay)) - マウスを細かくジグザグに動かす(
page.mouse.move(x, y)) - タイプ時にランダムな遅延やタイプミスを混ぜる(
page.type(selector, text, {delay: random(100,200)})) - スクロールも一気に下までじゃなく、途中で止めたり不規則に
こうした工夫で、ボット対策が厳しいサイトでも成功率がグッと上がります()。
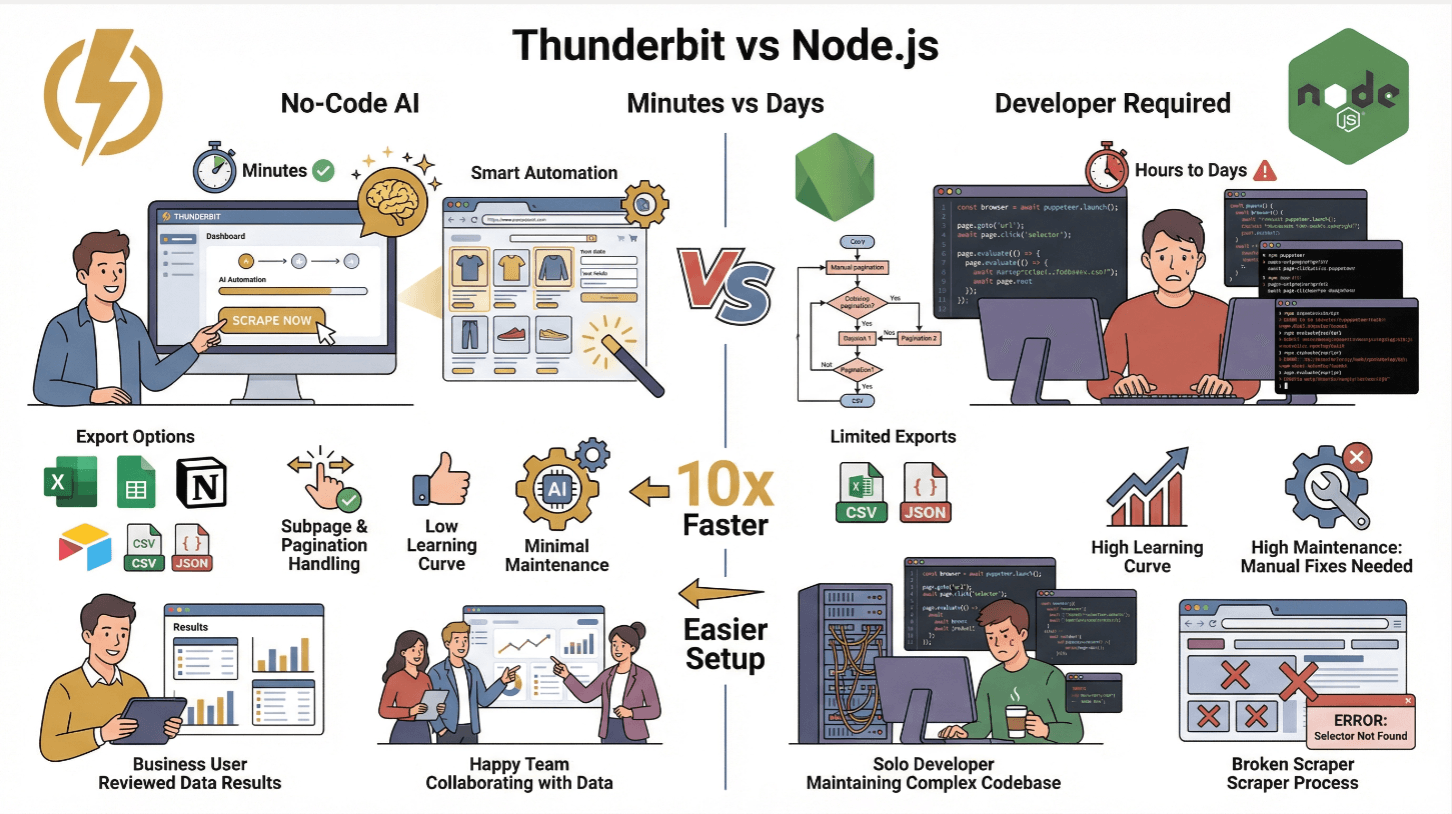
Thunderbitで複雑なデータ抽出もラクラク
正直、スクレイピングは本来めちゃくちゃ大変な作業。でもThunderbitなら、その常識がガラッと変わります。
ThunderbitはAIウェブスクレイパーChrome拡張機能で、英語で指示するだけでどんなウェブサイトからでもデータを抽出できます。「AIでフィールドを提案」をクリックすれば、AIがページ構造を自動で解析し、「スクレイプ」ボタン一発でデータ取得。まるで24時間働く新人エンジニアがいるみたいな感覚です。
さらにThunderbitはAPIも提供しているので、Node.jsのワークフローにも簡単に組み込めます。複雑な動的コンテンツやサブページ、ページネーションもThunderbitが自動で処理。取得したデータはCSVやJSON、Google Sheets、Airtable、Notionなどにそのまま出力できます()。
Thunderbitと従来型Node.jsスクレイパーの違い
| 機能 | Thunderbit | 従来のNode.jsスクレイパー |
|---|---|---|
| セットアップ時間 | 数分(ノーコード) | 数時間〜数日(コーディング・テスト) |
| 動的コンテンツ対応 | あり(AI+ブラウザ) | あり(Puppeteer/Playwright利用時) |
| サブページ・ページネーション | ワンクリック | 手動コーディングが必要 |
| データ出力 | Excel、Sheets、Notion、Airtable、CSV、JSON | CSV/JSON(カスタム実装) |
| 習得コスト | 低(ビジネスユーザー向け) | 高(開発者向け) |
| 保守性 | 最小限(AIが自動適応) | 高(サイト変更ごとに手動修正) |
Thunderbitはエンジニアじゃない人や、手間を省いてインサイトに集中したい人にぴったり。上級者はThunderbitのAPIで大規模自動化もできます()。
CheerioとPuppeteerの合わせ技で動的コンテンツも攻略
僕がよく使うNode.jsスクレイピングの最強コンビを紹介します。
- Puppeteerでページを開き、JavaScriptの実行を待つ(
networkidleまで待機)。 - HTMLを取得(
await page.content())。 - Cheerioでパース:取得したHTMLをCheerioに渡して、jQuery風に高速抽出。
このハイブリッド手法なら、Puppeteerの動的対応力とCheerioのパース速度を両立できます()。
パフォーマンステクニック: 必要な要素だけを選ぶのがコツ。CheerioはDOM全体をメモリに読み込むので、広範なセレクタは避けて。同じページを何度もスクレイプする場合はキャッシュも活用()。
HTMLパースとデータ抽出の最適化ポイント
- セレクタは具体的に:
$('body *')みたいな広範囲指定は避けて、必要な要素だけターゲット。 - 大規模ページはストリーミング: 巨大HTMLは分割やストリーミング処理も検討。
- HTMLのキャッシュ: 再訪問時はHTMLをキャッシュしてリクエスト削減。
- データのバリデーション・クレンジング: バリデータで品質担保し、不要データの混入を防止()。
クラウドでスケーラブルなNode.jsウェブスクレイパーを運用
大規模スクレイピングにはクラウド活用が必須です。
- Docker化:
Dockerfileでコードと依存パッケージをまとめ、エントリーポイントを設定。 - クラウド展開: AWS EC2、Google Cloud Compute、Azure VMなどで運用。大規模ならKubernetesやAWS ECS/EKS、Google Cloud Run、Azure Kubernetes Serviceも()。
- Kubernetesでオーケストレーション: 複数Podで自動スケール、ロードバランサでURL分散。
- ジョブのスケジューリング: CloudWatch EventsやCloud Scheduler、cronで定期実行。
実際、KubernetesのPod数を5→10に増やすだけで、400ページのスクレイピングが数分から1分未満に短縮できた事例もあります()。
スクレイピング基盤の監視と自動スケーリング
- ログ管理: CloudWatch、Stackdriver、Datadogなどでログを集約し、エラーや遅延をアラート。
- ヘルスチェック: PrometheusやGrafanaで「1分あたりのスクレイプ数」「エラー率」「Podの状態」などを可視化。
- 自動スケール: Kubernetes HPA(Horizontal Pod Autoscaler)でCPUやリクエスト数に応じてPod数を自動調整。
ネットワーク障害や一時的なブロックには、指数バックオフ付きのリトライ処理を必ず実装しましょう。
データ保存と後処理のベストプラクティス
データ取得後は、保存とクレンジングも大事です:
- 小規模案件: CSVやJSON出力、Google Sheets、Airtable、Notionへの連携(Thunderbitなら標準対応)。
- 大規模案件: 構造化データはSQL(MySQL/PostgreSQL)、半構造化やスキーマ変化が多い場合はNoSQL(MongoDB、DynamoDB)()。
- クラウドストレージ: S3やGoogle Cloud Storageで生データやバックアップを管理。
- データクレンジング: 各フィールドのバリデーション、日付や数値の正規化、重複排除。スキーマバリデータで品質担保()。
生データとクリーンデータの両方を保存しておくと、再処理やトラブル時にも安心です。
まとめ:Node.jsウェブスクレイピング効率化のポイント
最後にポイントをまとめます:
- Node.jsの非同期処理を活用して、大規模・並列スクレイピングを実現。特にJS中心のサイトで効果大。
- 最適なツールの組み合わせ: axios/gotでリクエスト、Cheerioで静的HTML、Puppeteerで動的コンテンツ、両者のハイブリッドで柔軟性と速度を両立。
- アンチボット対策を回避: プロキシやヘッダーのローテーション、人間的な挙動の再現、robots.txtの遵守。
- Thunderbitでシンプル化: ビジネスユーザーやプロトタイピングにはのAIで複雑なデータも簡単抽出、APIでNode.js連携も可能。
- 大規模運用: Docker化、Kubernetesでオーケストレーション、監視体制も万全に。
- データ保存とクレンジング: 用途に合ったストレージ選択と、利用前のバリデーションを徹底。
ウェブの複雑化は止まりませんが、これらのベストプラクティスを押さえれば、Node.jsスクレイパーは高速・堅牢・そしてアンチボット対策にも負けない存在になります。もし深夜2時にセレクタのバグ修正に疲れたら、ThunderbitのAIが24時間サポートしてくれることも思い出してください。
もっと学びたい人はで最新情報をチェック、またはでスクレイピングの手軽さを体感してみてください。
よくある質問(FAQ)
1. 2025年にNode.jsがウェブスクレイピングに特に強い理由は?
Node.jsは非同期・イベント駆動型の設計で、数千件のリクエストを同時処理できるから、大量データやリアルタイム更新のスクレイピングにぴったり。npmエコシステムやJavaScriptネイティブ対応も、今どきのJS中心サイトに強いです()。
2. Node.jsでスクレイピング時にブロックされないコツは?
プロキシのローテーション、リクエストヘッダーのランダム化、リクエスト間のランダム遅延、Puppeteerなどでマウス移動やスクロール・タイピングの人間的挙動を再現しよう。robots.txtや利用規約の遵守も必須()。
3. Node.jsスクレイパーでCheerioとPuppeteerはどう使い分ける?
静的HTMLの高速パースにはCheerio、JavaScriptで動的に生成されるサイトにはPuppeteerが最適。両者を組み合わせて、Puppeteerでページを描画→CheerioでHTMLパースがベスト()。
4. ThunderbitはNode.jsウェブスクレイピングをどう簡単にする?
ThunderbitはAIと自然言語プロンプトで、コーディング不要で構造化データを抽出できます。動的コンテンツやサブページ、ページネーションも自動対応し、APIでNode.js連携も可能。データはExcel、Google Sheets、Airtable、Notionに直接出力できます()。
5. Node.jsスクレイパーをクラウドでスケール・監視する最適な方法は?
スクレイパーをDocker化し、Kubernetesやクラウドマネージドサービスで運用。自動スケーリングで需要変動に対応し、CloudWatchやPrometheusでログ・メトリクス監視、エラーや遅延時のアラートも設定しよう()。
ウェブスクレイピングをさらに進化させたい人は、ぜひThunderbitを試してみてください。あなたのスクレイパーが高速・ステルス・そして常に一歩先を行く存在になりますように。
さらに詳しく知りたい方へ