ネットの世界にはとんでもない量のデータが転がっていて、どの会社もそれをフル活用したいと思ってるよね。でも、何百ページも手作業でコピペするなんて、正直やってられないし、めちゃくちゃ非効率。そこで登場するのがnodeウェブスクレイピング。ここ数年で、営業やオペレーション、市場調査など、いろんなチームがウェブから自動でデータを集めるためにweb scraping node jsを取り入れるようになってきたんだ。実際、世界のウェブスクレイピング市場はが予想されていて、テック大手だけじゃなく、いろんな企業が参入中。ECサイトの価格調査やリード獲得など、nodeウェブスクレイピングは今やビジネスで生き残るための必須スキルになりつつあるよ。
Node.jsでウェブサイトからデータを抜き出す方法や、なぜNode.jsがJavaScriptバリバリの動的サイトに強いのか知りたい人は、このガイドがピッタリ。nodeウェブスクレイピングの基本から、ビジネスで使う理由、実際にスクレイピングの流れをゼロから作る手順まで、わかりやすくまとめてるよ。「とにかく早く結果が欲しい!」って人には、みたいなツールで面倒な作業を自動化して、時間も手間も一気にカットする方法も紹介。ウェブを自分のデータ資産に変えたいなら、ぜひ最後まで読んでみて!
nodeウェブスクレイピングって何?自動データ収集のスタートライン
nodeウェブスクレイピングは、人気のJavaScriptランタイムNode.jsを使って、ウェブサイトから自動で情報をゲットする技術。イメージとしては、超高速なロボットがウェブページを巡回して、必要な情報(商品価格や連絡先、最新ニュースなど)だけをサクッと拾ってきてくれる感じ。
やり方はめちゃシンプル:
- Node.jsのスクリプトでウェブサイトにHTTPリクエスト(ブラウザと同じ動き)
- ページの生HTMLをゲット
- CheerioみたいなライブラリでHTMLを解析して、jQueryっぽくデータを抽出
- JavaScriptで動的にコンテンツが作られるサイト(最近のWebアプリとか)は、Puppeteerで本物のブラウザを裏で動かして、全部のスクリプト実行後にデータを取得
なんでNode.jsなの?っていうと、JavaScriptはウェブの標準語だし、Node.jsならブラウザ外でも同じ言語で処理できる。静的・動的どっちのサイトもOKだし、ログインやボタン操作みたいな複雑な自動化も余裕。しかもNodeの非同期・イベント駆動型アーキテクチャで、たくさんのページを同時にサクサク処理できるのが強み。
nodeウェブスクレイピングでよく使う主なツール:
- Axios: HTTPリクエストでウェブページを取得
- Cheerio: 静的サイトのHTML解析&データ抽出
- Puppeteer: JavaScriptで動的に生成されるサイトやインタラクティブなページの自動操作
「コーヒー飲みながら、ロボットが静かにデータ集めてくれる」——そんなイメージ、意外と現実的!
nodeウェブスクレイピングがビジネスチームに欠かせない理由
今やウェブスクレイピングは、ハッカーやデータサイエンティストだけのものじゃない。ビジネス現場でこそ、そのパワーが発揮されてる。実際、多くの企業がnodeウェブスクレイピングを使って、
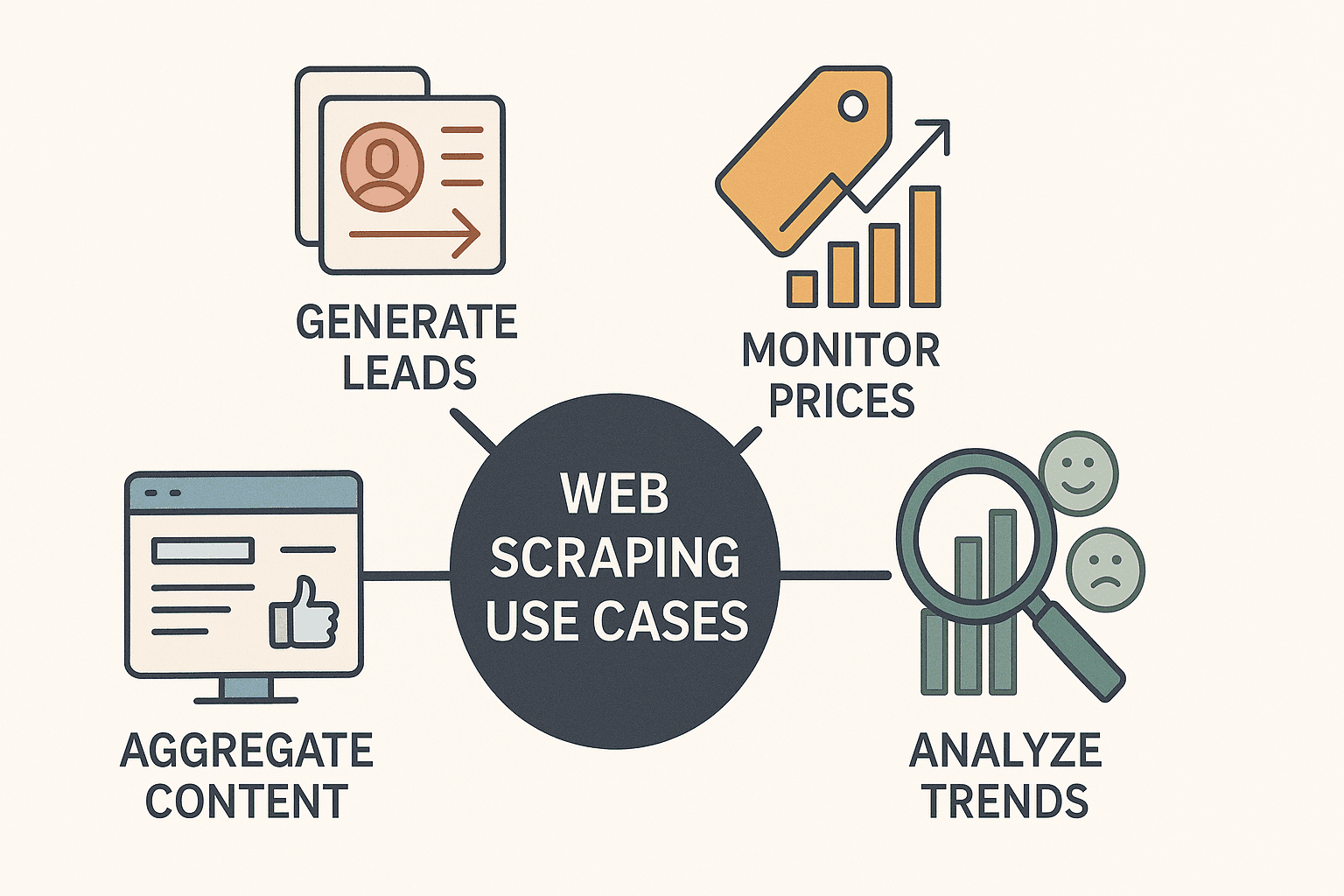
- リード獲得: ディレクトリやLinkedInから営業リストを自動収集
- 競合価格の監視: 商品リストを追いかけて、リアルタイムで価格調整(が毎日競合価格をスクレイピング)
- コンテンツ集約: ニュースやレビュー、SNSの言及をダッシュボード化
- 市場動向分析: レビューやフォーラム、求人情報からトレンドや顧客の声を分析
Node.jsなら、これらの作業が従来より圧倒的に速くて柔軟、しかも自動化しやすい。非同期処理で大量ページを一気に取得できるし、モダンなフレームワークで作られたサイトにも強いのがポイント。
実際の活用例をまとめると:
| ユースケース | 概要・例 | Node.jsの強み |
|---|---|---|
| リード獲得 | 企業ディレクトリからメール・氏名・電話番号を抽出 | 並列スクレイピングが高速、CRMやAPIとの連携も簡単 |
| 価格モニタリング | ECサイトで競合商品の価格を追跡 | 非同期リクエストで大量ページ対応、定期実行も簡単 |
| 市場トレンド調査 | レビューやフォーラム、SNS投稿を集約し分析 | 柔軟なデータ処理、テキスト解析やクリーニングも豊富なエコシステム |
| コンテンツ集約 | ニュース記事やブログ投稿を一元管理 | リアルタイム更新、Slackやメールなど通知ツールとの連携もスムーズ |
| 競合分析 | 競合サイトの商品カタログ・説明・評価を抽出 | 複雑なJavaScript解析も可能、複数ページのクロールもモジュール化しやすい |
特にJavaScript多めのサイトのスクレイピングはNode.jsの得意分野。他の言語だと難しいケースも、Nodeなら「欲しいデータがスプレッドシートに!」があっという間に実現できるよ。
nodeウェブスクレイピングの必須ツール・ライブラリ
実際にコードを書く前に、Node.jsでスクレイピングする時によく使う主要ツールを押さえておこう。
1. Axios(HTTPクライアント)

- 役割: HTTPリクエストでウェブページのHTMLを取得
- 用途: ページの生HTMLが欲しい時
- 特徴: Promiseベースでシンプル、リダイレクトやヘッダー処理も簡単
- インストール:
npm install axios
2. Cheerio(HTMLパーサー)

- 役割: HTMLを解析して、jQuery風のセレクタでデータ抽出
- 用途: 静的サイトで初期HTMLにデータが含まれてる場合
- 特徴: 軽量・高速、jQuery経験者なら直感的に使える
- インストール:
npm install cheerio
3. Puppeteer(ヘッドレスブラウザ自動化)

- 役割: バックグラウンドで本物のChromeブラウザを操作して、ユーザーと同じようにページを扱う
- 用途: JavaScriptで動的に生成されるサイトや、ログイン・無限スクロール・ポップアップ対応が必要な時
- 特徴: ボタン操作やフォーム入力、スクロール、スクリプト実行後のデータ抽出もOK
- インストール:
npm install puppeteer
補足: Playwright(複数ブラウザ対応)やApifyのCrawlee(高度なワークフロー向け)もあるけど、初心者はまずAxios・Cheerio・Puppeteerの3つを押さえればOK。
前提: Node.jsがインストールされてること。新しいプロジェクトはnpm init -yで作って、上記ライブラリをインストールしよう。
ステップバイステップ:nodeウェブスクレイパーを自作してみよう
それじゃ実際に、AxiosとCheerioを使ってデモサイトから本のデータを取ってくる簡単なスクレイパーを作ってみよう。
ステップ1:ページHTMLの取得
1import axios from 'axios';
2import { load } from 'cheerio';
3const startUrl = 'http://books.toscrape.com/';
4async function scrapePage(url) {
5 const resp = await axios.get(url);
6 const html = resp.data;
7 const $ = load(html);
8 // ...次でデータ抽出
9}ステップ2:データの解析・抽出
1$('.product_pod').each((i, element) => {
2 const title = $(element).find('h3').text().trim();
3 const price = $(element).find('.price_color').text().replace('£', '');
4 const stock = $(element).find('.instock').text().trim();
5 const ratingClass = $(element).find('p.star-rating').attr('class') || '';
6 const rating = ratingClass.split(' ')[1];
7 const relativeUrl = $(element).find('h3 a').attr('href');
8 const bookUrl = new URL(relativeUrl, startUrl).href;
9 console.log({ title, price, rating, stock, url: bookUrl });
10});ステップ3:ページ送り(ページネーション)対応
1const nextHref = $('.next > a').attr('href');
2if (nextHref) {
3 const nextUrl = new URL(nextHref, url).href;
4 await scrapePage(nextUrl);
5}ステップ4:データの保存
データを集めたら、NodeのfsモジュールでJSONやCSVファイルに保存できるよ。
1import fs from 'fs';
2// スクレイピング完了後:
3fs.writeFileSync('books_output.json', JSON.stringify(booksList, null, 2));
4console.log(`書籍データ${booksList.length}件を保存しました。`);これで、基本的なNode.jsウェブスクレイパーが完成!静的サイトにはこの方法がベストだけど、JavaScriptで動的にデータが作られるページにはどう対応する?
JavaScript多用サイトの攻略:Node×Puppeteerの活用
一部のウェブサイトは、JavaScriptでデータを隠してることがある。AxiosやCheerioだけだと空っぽのページや情報不足になる時は、Puppeteerの出番。
Puppeteerを使う理由: 本物の(ヘッドレス)ブラウザを起動して、ページを完全に読み込んでからデータを取れるから、人間の操作と同じように情報を抜き出せる。
Puppeteerのサンプルスクリプト
1import puppeteer from 'puppeteer';
2async function scrapeWithPuppeteer(url) {
3 const browser = await puppeteer.launch({ headless: true });
4 const page = await browser.newPage();
5 await page.goto(url, { waitUntil: 'networkidle2' });
6 await page.waitForSelector('.product_pod'); // データの読み込みを待つ
7 const data = await page.evaluate(() => {
8 let items = [];
9 document.querySelectorAll('.product_pod').forEach(elem => {
10 items.push({
11 title: elem.querySelector('h3').innerText,
12 price: elem.querySelector('.price_color').innerText,
13 });
14 });
15 return items;
16 });
17 console.log(data);
18 await browser.close();
19}Cheerio/AxiosとPuppeteerの使い分け:
- Cheerio/Axios: 静的コンテンツ向けで高速・軽量
- Puppeteer: 動的・インタラクティブなページ(ログイン、無限スクロールなど)に必須
ポイント:まずはCheerio/Axiosで試して、データが取れなかったらPuppeteerに切り替えるのが効率的。
nodeウェブスクレイピングの応用:ページネーション・ログイン・データ整形
基礎をマスターしたら、さらに一歩進んだシナリオにも挑戦しよう。
ページネーション対応
「次へ」リンクを見つけてページをループしたり、URLパターンを作って複数ページを巡回。
1let pageNum = 1;
2while (true) {
3 const resp = await axios.get(`https://example.com/products?page=${pageNum}`);
4 // ...データ抽出
5 if (!hasNextPage) break;
6 pageNum++;
7}ログイン自動化
Puppeteerなら、ユーザーと同じようにログインフォームを操作できる。
1await page.type('#username', 'myUser');
2await page.type('#password', 'myPass');
3await page.click('#loginButton');
4await page.waitForNavigation();データ整形・クリーニング
スクレイピング後は、
- 重複データの除去(Setやユニークキーでフィルタ)
- 数値・日付・テキストのフォーマット統一
- 欠損値の処理(nullで埋める、または不完全なレコードを除外)
正規表現やJavaScriptの文字列操作が大活躍。
nodeウェブスクレイピングのベストプラクティス:失敗しないコツ
ウェブスクレイピングは強力だけど、注意点も多い。主なポイントは:
- robots.txtや利用規約の確認: スクレイピングOKか必ずチェック、禁止エリアは避ける
- リクエスト間隔の調整: 一気に大量リクエストせず、遅延やランダム化で人間っぽい動きを再現()
- ユーザーエージェントやIPのローテーション: 大規模なスクレイピングではヘッダーやIPを切り替えてブロック回避
- エラー処理の徹底: 例外キャッチ、リトライ、エラーログの記録
- データのバリデーション: 欠損や不正なフィールドを早めに発見
- モジュール化・保守性の高いコード設計: 取得・解析・保存処理を分けて、セレクタやURLは設定ファイルで管理
そして何より、みんなが気持ちよく使えるように、倫理的なスクレイピングを心がけよう!
Thunderbitと自作nodeウェブスクレイピングの比較:どっちが自分向き?
ここで気になるのが、「自分でスクレイパーを作るべき?それともみたいなツールを使うべき?」ってところ。
自作Node.jsスクレイパー:
- メリット: 完全カスタマイズOK、どんなワークフローにも組み込める
- デメリット: コーディングスキルが必要、作る&保守に時間がかかる、サイト構造が変わると修正必須
Thunderbit AIウェブスクレイパー:
- メリット: コード不要、AIが自動でフィールド検出、サブページやページネーションも自動対応、Excel・Google Sheets・Notionなどに即エクスポート()。AIがサイト変更にも自動対応してくれるから保守いらず。
- デメリット: 超特殊なワークフローには柔軟性が足りない場合も(でも99%のビジネス用途はカバー)
比較表はこちら:
| 項目 | 自作Node.jsスクレイパー | Thunderbit AIウェブスクレイパー |
|---|---|---|
| 技術スキル | コーディング必須 | コード不要、直感的な操作 |
| 構築時間 | 数時間〜数日 | 数分(AIがフィールド提案) |
| 保守性 | サイト変更時に都度修正 | AIが自動対応で手間いらず |
| 動的コンテンツ対応 | Puppeteer等を手動設定 | 標準で対応 |
| サブページ/ページ送り | コードで個別実装 | 1クリックで自動対応 |
| データエクスポート | エクスポート用コードが必要 | Excel・Sheets・Notion等に即出力 |
| コスト | 無料(開発・プロキシ等の工数) | 無料枠あり、従量課金制 |
| おすすめ用途 | 開発者・高度なカスタマイズ | ビジネスユーザー・即効性重視 |
Thunderbitは、営業・マーケ・オペレーション部門が「今すぐデータが欲しい!」って時にピッタリ。開発者にも、プロトタイピングや定型作業の自動化に便利だよ。
まとめ&重要ポイント:nodeウェブスクレイピングの第一歩を踏み出そう
nodeウェブスクレイピングは、ウェブ上の隠れたデータを引き出す強力な武器。リードリスト作成、価格監視、新規ビジネスのアイデア検証など、使い道は無限大。覚えておきたいポイントは:
- Node.js+Cheerio/Axiosは静的サイト向け、Puppeteerは動的・JavaScript多用サイトに最適
- ビジネス効果は絶大: ウェブスクレイピングを活用する企業は、や海外売上倍増など、目に見える成果を出してる
- まずはシンプルに: 基本のスクレイパーから始めて、ページネーションやログイン自動化、データ整形など徐々に機能追加
- 用途に合わせて最適なツールを選ぶ: コード不要ですぐ結果が欲しいならが最適。高度な統合やカスタマイズが必要なら自作Node.jsスクリプトを
- 責任あるスクレイピングを: サイト規約を守って、リクエストを適切に制御し、保守性の高いコードを意識しよう
さあ、Node.jsで自作スクレイパーに挑戦するもよし、で手軽にデータ抽出を体験するもよし。さらに詳しいノウハウや最新情報はでチェックしてみて!
みんなのスクレイピングが、いつも新鮮で整理された、競合より一歩先を行くデータ活用につながりますように!
よくある質問(FAQ)
1. nodeウェブスクレイピングって何?なんでNode.jsが向いてるの?
nodeウェブスクレイピングは、Node.jsを使ってウェブサイトから自動でデータを取る方法。Node.jsは非同期処理が得意で、PuppeteerみたいなツールでJavaScript多めのサイトにも強いのが特徴。
2. Cheerio/AxiosとPuppeteerはどう使い分ける?
CheerioとAxiosは、初期HTMLにデータがある静的サイト向け。Puppeteerは、JavaScriptで動的に作られるコンテンツや、ログイン・無限スクロール対応が必要な時に使う。
3. nodeウェブスクレイピングの主なビジネス活用例は?
リード獲得、競合価格監視、コンテンツ集約、市場トレンド分析、商品カタログ抽出など。Node.jsならこれらの作業を高速&大規模に実行できる。
4. nodeウェブスクレイピングでよくある失敗と対策は?
アンチボット対策でブロックされたり、サイト構造変更への対応、データ品質管理などが課題。リクエスト間隔の調整、ユーザーエージェントやIPのローテーション、データバリデーション、モジュール化設計で回避できる。
5. Thunderbitと自作Node.jsスクレイパーの違いは?
Thunderbitはノーコード・AI搭載でフィールド検出やサブページ・ページネーションも自動対応。ビジネスユーザー向けに即効性が高く、Node.js自作は高度なカスタマイズや他システム連携に最適。
さらに詳しいガイドや最新情報はやでチェック!
関連リンク