

2026年を迎えたいま、ウェブ上のデータは「持っていればちょっと得をする」程度のものではなくなりました。事業の屋台骨を支える生命線そのものです。EC大手が競合の価格をその都度追い続けるのも、営業担当が鮮度の高い見込み客でパイプラインを満たしていくのも、もとをたどれば、公開ウェブのデータを貴重な資源として扱っているからにほかなりません。それを裏付ける数字もあります。いまや企業の約65%がウェブスクレイピングやデータ抽出ツールを使用しており、デジタル企業の70%以上が市場インテリジェンスに公開ウェブデータを活用しています。そして、何かと注目を集めがちなのはPythonですが、実のところ規模が大きく停止が許されないスクレイピング案件を、いまなお支えている主役はJavaです。とりわけ、堅牢さと社内システムとの連携が何より問われる企業の現場では、その傾向がいっそう際立ちます。
 SaaSと自動化の分野に長く携わってきたなかで、Javaによるウェブスクレイピングが日々の業務を大きく変えていく場面に、私は何度も立ち会ってきました。その一方で、低レイヤーのコードに足を取られたり、動的サイトやボット対策の壁を前にして手詰まりになったりするチームも、同じだけ見てきています。だからこそ、2026年にJavaのウェブスクレイピングを習得するための、実践的なステップバイステップの手引きを――それもコードとThunderbitのような新世代のAI搭載ツールを組み合わせる視点を軸に据えて――お届けできることを、うれしく思います。開発者の方も、運用を担う担当者の方も、面倒な手間なしにとにかくデータが欲しいだけのビジネスユーザーの方も、この一本はきっとどこかで役に立つはずです。
SaaSと自動化の分野に長く携わってきたなかで、Javaによるウェブスクレイピングが日々の業務を大きく変えていく場面に、私は何度も立ち会ってきました。その一方で、低レイヤーのコードに足を取られたり、動的サイトやボット対策の壁を前にして手詰まりになったりするチームも、同じだけ見てきています。だからこそ、2026年にJavaのウェブスクレイピングを習得するための、実践的なステップバイステップの手引きを――それもコードとThunderbitのような新世代のAI搭載ツールを組み合わせる視点を軸に据えて――お届けできることを、うれしく思います。開発者の方も、運用を担う担当者の方も、面倒な手間なしにとにかくデータが欲しいだけのビジネスユーザーの方も、この一本はきっとどこかで役に立つはずです。
Java ウェブスクレイピングとは? 非技術者向けの概要
まずは言葉の整理から始めましょう。Javaウェブスクレイピングとは、Javaで書いたコードを介して、ウェブサイトから情報を自動で抜き取る手法を指します。非常に速く働く仮想のアシスタントを一人雇った、とイメージしてみてください。何千枚というウェブページに次々と目を通し、欲しいデータだけを抜き出して、整然とスプレッドシートへ書き写してくれる――そんな働き手です。しかもこのアシスタントは音を上げることもなければ打ち間違いをすることもなく、回線の許す速さでひたすら作業し続けます。
仕組みを整理して並べると、おおよそ次の流れです。
- ウェブサイトにリクエストを送る(ブラウザでページをひとつ開くのと、感覚としてはほぼ同じです)。
- HTML コンテンツをダウンロードする(ページの骨組みになっている、加工前の生のコードです)。
- その HTML をパースして、プログラムが筋道立てて読める構造へと組み替えます。
- 必要な特定のデータを抽出する(たとえば商品名、価格、メールアドレスといった項目です)。
- 結果を保存する。受け皿はCSVでもExcelでもデータベースでも、あるいはGoogle Sheetsでも構いません。
この大筋を理解するのに、熟練の開発者である必要はありません。使い慣れたツールと、ほんの少しの手引きさえあれば、ビジネスユーザーでもデータ集めを自動化し、雑然としたウェブページを、業務で使えるインサイトへと変えられます。
2026年に Java ウェブスクレイピングがビジネスで重要な理由
ウェブスクレイピングは、技術好きの趣味にとどまる話ではありません。事業を回すうえで欠かせない一手です。各社がJavaのウェブスクレイピングを活用して、どうやって一歩抜きん出ているのか、そしてなぜそれが机上の空論でない本物のROIにつながるのかを、見ていきましょう。
| ウェブスクレイピングのユースケース | ビジネス上のメリット(ROI) | 代表的な業界 |
|---|---|---|
| 競合価格モニタリング | リアルタイムの価格インテリジェンス。市場変化に素早く反応することで 20%以上 の売上増加 | eコマース、小売 |
| リード獲得・営業インテリジェンス | 自動化された最新の見込み客リスト。手作業によるリサーチ時間を 70%削減 | B2B営業、マーケティング、人材採用 |
| 市場調査・トレンド分析 | トレンドの早期検知。5〜15%の売上増 と 10〜20%高いマーケティングROI | 消費財、マーケティングエージェンシー |
| 金融・投資データ | 取引向けのオルタナティブデータ。ウェブスクレイピング由来の「alt-data」市場は 50億ドル超 | 金融、ヘッジファンド、フィンテック |
| 業務自動化・監視 | 定型的なデータ収集を自動化。73%のコスト削減 と 85%高速な導入 | 不動産、サプライチェーン、政府機関 |
(出典)
では、数あるなかでなぜJavaなのか。理由は、規模への強さ、堅牢さ、そして他システムとの連携のよさに尽きます。企業のデータパイプラインは、その多くがすでにJavaの上で動いている。だとすれば、そこへウェブスクレイパーを組み込むのは、ごく自然な選択です。加えてJavaのマルチスレッド処理と例外への目配りは、大量処理と相性がいい。数ページどころか、一日に何千ページも集めるような仕事でこそ、その地力が活きてきます。
Java ウェブスクレイピングはどう動く? 基本原理と独自の強み
一般的なJavaウェブスクレイパーが、内側でどう動いているのかを見ていきましょう。
- HTTP リクエスト: JavaはJSoupやApache HttpClientといったライブラリを使ってウェブページを取得します。ヘッダーを差し替えたり、プロキシを経由させたり、本物のブラウザを装ったりもできるので、それだけブロックされにくくなります。
- HTML パース: JSoupのようなライブラリが、生のHTMLを「DOM」(枝分かれした木のようなデータ構造)へと組み替え、CSSセレクタを頼りに目当てのデータへたどり着けるようにしてくれます。
- データ抽出: たとえば「
<span class='price'>の要素をすべて取得する」といった具合に取り出しのルールを定めて、欲しい情報だけを抜き出します。 - データ保存: 仕上げに、得られた結果をCSV、Excel、JSON、あるいはデータベースへと保存します。
Java がウェブスクレイピングで特別な理由
- マルチスレッド: Javaは複数のページを並行して取得・処理できるので、大規模なクロールが大幅に速まります。PythonではGILがここでつまずきの原因になりがちですが、Javaのスレッドは実際に並走し、しかも速い。
- 性能: Javaはコンパイル型の言語だけあって、大量処理やメモリを多く使う重めのタスクも、安定してこなします。
- 企業システムとの連携: Javaで組んだスクレイパーは、CRMやERP、データベースといった既存の仕組みへ、回りくどい工夫なしにそのまま接続できます。
- エラーハンドリング: Javaの厳格な型付けと例外まわりの仕組みのおかげで、スクレイパーは安定し、長く稼働させても保守しやすいまま保てます。
停止が許されないデータパイプラインを回している立場であれば、この安定性と拡張性は、何にも代えがたい後ろ盾になります。
Java ウェブスクレイピングに必須のライブラリとフレームワーク:何を選ぶべきか
Javaにはウェブスクレイピング向けのライブラリが数多くありますが、ビジネスの現場でとりわけ存在感があるのは JSoup、HtmlUnit、Selenium の三本柱です。横並びで見比べてみましょう。
| ライブラリ | JavaScript 対応 | 使いやすさ | 性能 | 最適な用途 |
|---|---|---|---|---|
| JSoup | ❌(JS なし) | とても簡単 | 高い | 静的ページ、素早い作業、軽量な処理 |
| HtmlUnit | ⚠️ 一部対応 | 中程度 | 中くらい | 簡単な JS、フォーム送信、ヘッドレススクレイピング |
| Selenium | ✅ 完全対応 | 中程度〜難しい | 低め(1ページあたり) | JS が多いサイト、インタラクティブ/動的ページ |
(詳細はこちら)
JSoup: シンプルな HTML パースの定番
JSoup は、私が多くのスクレイピング作業でまず最初に手に取るツールです。軽量で扱いやすく、ほしいデータがHTMLのなかにそのまま素直に収まっている静的ページが、いちばんの得意分野になります。
例:
Document doc = Jsoup.connect("https://www.scrapingcourse.com/ecommerce/").get();
String bannerTitle = doc.select("div.site-title").text();
System.out.println("Banner: " + bannerTitle);
たったこれだけです。ブログ記事や商品の一覧、JavaScriptに依存していない名簿サイトを相手にするなら、JSoupは安心して使える定番です。
HtmlUnit: より複雑な作業のためのブラウザシミュレーション
HtmlUnit は、すべてJavaで書き上げられたヘッドレスブラウザです。一部のJavaScriptを処理し、フォームへの入力やボタンの押下までこなしてくれます。それも、実際のブラウザの画面をわざわざ開かずに、です。
使う場面: サイトへログインしたいとき、あるいは初歩的な動的コンテンツには対応したいけれど、Seleniumほどの重さは避けたい、というとき。
例:
WebClient webClient = new WebClient();
HtmlPage page = webClient.getPage("https://example.com/login");
// ... フォームに入力して送信 ...
Selenium: JavaScript が多いページやインタラクティブなページの処理
Selenium は、いざというときの切り札です。ChromeやFirefoxといった本物のブラウザを直接操作するため、JavaScriptだけで組み上げられたサイトも含め、人の手で扱えるページならまず取りこぼしません。
使う場面: 最近のWebアプリ、無限スクロールが続くサイト、クリックや待機、ユーザーのひと操作を挟まないと先へ進めないサイトを、相手にするとき。
例:
WebDriver driver = new ChromeDriver();
driver.get("https://www.scrapingcourse.com/ecommerce/");
List<WebElement> products = driver.findElements(By.cssSelector("li.product"));
// ... データを抽出 ...
driver.quit();
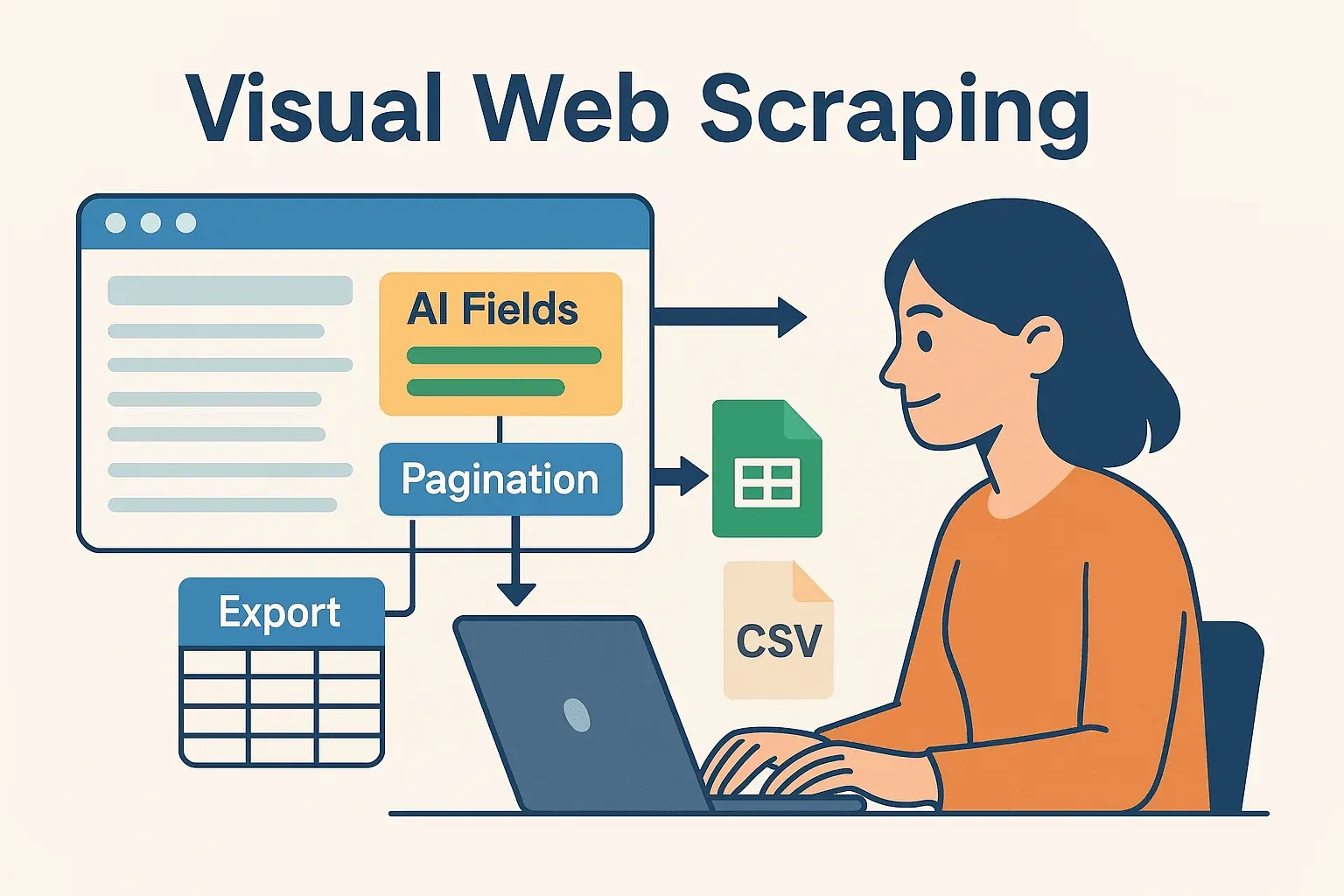
Thunderbit で Java ウェブスクレイピングを加速する:ビジュアル自動化とコードの融合
AI を使ってあらゆるウェブサイトからデータを抽出 Get Started Free
さて、ここからが本題です。とりわけ、一日じゅうコードと向き合っていたいわけではないビジネスユーザーやチームには、見逃せない話になるはずです。Thunderbit はAI搭載のノーコードウェブスクレイパーで、ブラウザの画面上でスクレイピングの設定を目で見ながら組み立て、取得したデータをそのままExcelやGoogle Sheets、Airtable、Notionへ送り出せます。
Java と一緒に Thunderbit を使う理由
- AI による項目提案: Thunderbitの「AI Suggest Fields」がページに目を通し、抜くべき項目を的確に提案してくれます。HTMLの奥を調べたり、セレクタを書き起こしたりする必要は一切ありません。
- サブページスクレイピング: さらに深い情報まで欲しいときは、Thunderbitが各サブページ(商品の詳細ページなど)を自動でめぐり、データセットに厚みを加えてくれます。
- 即使えるテンプレート: Amazon、Zillow、LinkedInといった定番のサイト向けには、Thunderbitのワンクリックテンプレートがそろっています。下準備は不要です。
- 簡単エクスポート: いったん抜き出してしまえば、ほんの数秒でデータを書き出せます。あとはJavaのコードに引き渡し、処理でも分析でも、他システムとの連携でも、自由に回せます。
Thunderbitは、試作の場面、手強いサイトへの対処、あるいは開発者でない人にデータ取りを任せる場面で、目に見えて時間を短縮してくれます。開発者にとっても、スクレイピングのうち繰り返しが多く壊れやすい部分を任せられるぶん、本来力を注ぐべきビジネスロジックに集中できる――これが大きな利点です。
複雑なプロジェクトで Thunderbit と Java を組み合わせる方法
私のお気に入りの手順は、次のとおりです。
- Thunderbit で試作する: Chrome拡張機能を立ち上げ、スクレイピングの設定を目で確かめながら組みます。項目の提案も、ページめくりの処理も、Google SheetsやCSVへの書き出しも、まとめてAIに任せてしまいましょう。
- Java で処理する: 書き出したデータ(Sheets、CSV、Airtableなど)を読み込み、その先の後処理や分析、企業システムとの連携を、Javaの側で受け持ちます。
- 自動化と定期実行: Thunderbit内蔵のスケジューラーでデータを常に最新に保ち、Javaのパイプラインが最新の書き出しを自分から取得しにいくよう設定します。
 この組み合わせなら、AI搭載のノーコードスクレイピングならではの速さと小回り、そして下流の処理を支えるJavaの底力と堅牢さ――その両方を、同時に手にできます。
この組み合わせなら、AI搭載のノーコードスクレイピングならではの速さと小回り、そして下流の処理を支えるJavaの底力と堅牢さ――その両方を、同時に手にできます。
ステップバイステップガイド:最初の Java ウェブスクレイパーを作る
では、いよいよ手を動かしてみましょう。ここからは、シンプルなJavaウェブスクレイパーを、まっさらな状態から組み上げる手順をたどります。
Java 環境のセットアップ
- Java(JDK)をインストールする: 現役のLTSサポートを受けたいなら、Java 21かJava 25を選びましょう。Java 17へのOracleの無償アップデートは2024年9月で終了し、Java 21の無償アップデートも2026年9月で終わる見込みです。となれば、2026年に新しく立ち上げる案件は、既存のJava 21のコードベースに縛られているのでない限り、Java 25(2025年9月公開、LTSは2033年まで)を狙うのが無難です。
- Maven を設定する: 依存関係の管理を、まとめて引き受けてくれます。
- IDE を選ぶ: IntelliJ IDEAでもEclipseでもVSCodeでも、お好みの一本でまったく差し支えありません。
pom.xmlに JSoup を追加する:<dependency> <groupId>org.jsoup</groupId> <artifactId>jsoup</artifactId> <version>1.22.2</version> </dependency>
スクレイパーの作成と実行
デモ用に用意されたECサイトから、商品名と価格を抜き出してみましょう。
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements;
import org.jsoup.nodes.Element;
public class ProductScraper {
public static void main(String[] args) {
String url = "https://www.scrapingcourse.com/ecommerce/";
try {
Document doc = Jsoup.connect(url)
.userAgent("Mozilla/5.0")
.get();
Elements productElements = doc.select("li.product");
for (Element productEl : productElements) {
String name = productEl.selectFirst("h2").text();
String price = productEl.selectFirst("span.price").text();
System.out.println(name + " -> " + price);
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
プロのヒント: user-agentは必ず添えて、本物のブラウザを装っておきましょう。Javaの初期設定のままのuser-agentを、そっけなくはじくサイトもあるからです。
データの書き出しと活用
- CSV 出力:
FileWriterやOpenCSVといったライブラリを使って、結果をCSVファイルへ書き出します。 - Excel 出力: .xlsや.xlsxの形で残したいなら、Apache POIの出番です。
- データベース連携: JDBCを通じて、データベースへそのまま流し込みます。
- Google Sheets: Thunderbitから書き出しておき、JavaのGoogle Sheets APIで読み込みます。
Java ウェブスクレイピングでよくある課題を乗り越える
ウェブスクレイピングも、いいことばかりとはいきません。よく出くわす問題と、その対処法をひととおり見ておきましょう。
- IP ブロックとレート制限: リクエストの間隔をあえて空ける(
Thread.sleep()を挟む)、プロキシを順に回す、待ち時間に揺らぎを持たせる。量が多い処理では、迷わずプロキシサービスを使いましょう。 - CAPTCHA とボット検知: Seleniumで実際のユーザーらしい操作を再現するか、ボット対策のAPIを組み込みます。場合によっては、Thunderbitのクラウドスクレイピングが、この種の関門をうまく回避してくれることもあります。
- 動的コンテンツ: JSoupで何も返ってこないなら、データはJavaScript経由で後から読み込まれている可能性が高いです。SeleniumかHtmlUnitに切り替えるか、サイトの内部APIを探しにいきましょう。
- サイト構造の変更: 手入れのしやすいコードを、柔軟なセレクタで書いておきます。スクレイパーには目を配り、サイトが変わったらすぐ追従できる体制を保ちましょう。Thunderbitなら、レイアウトが変わったときも、多くはXPathを手で書き直す代わりに「AI Suggest Fields」を押し直すだけで済みます。手作業には違いありませんが、セレクタを総取り替えするよりは、はるかに手間がかかりません。
- セッション管理: ログインを挟むスクレイピングでは、Cookieとセッションを丁寧に扱います。Seleniumと(Chromeにログイン済みの状態の)Thunderbitがそろっていれば、認証の先にあるページにも対応できます。
Java ウェブスクレイピング効率を高める上級テクニック
AI を使ったデータスクレイピングをもっと学ぶ Get Started Free
もう一段、上のレベルへ踏み込みたいですか。ここからは、上級者向けのコツをいくつか紹介します。
- マルチスレッド: Javaの
ExecutorServiceを使い、複数ページを並行して集めます。ただし、勢い余ってアカウントを止められないよう、加減は心得ておきましょう。 - スケジューリング: JavaならQuartz Schedulerを使うか、Thunderbitにクラウド上で、話し言葉のままの指定(「毎週月曜の9時」など)でスケジューリングを任せてしまいましょう。
- クラウドスケーリング: 桁外れに大きなジョブでは、ヘッドレスブラウザをクラウドで走らせるか、タスクを複数のマシンへ振り分けます。
- ハイブリッドワークフロー: 手間のかかる難しいサイトはThunderbitに任せ、それ以外はJavaで処理する。仕上がった結果は、データウェアハウスでひとまとめにしましょう。
- 監視とログ記録: Javaのロギングフレームワークでスクレイパーの状態を監視し、エラーを早めに見つけ、何か起きたらすぐ通知が飛ぶようにしておきます。
結論と重要なポイント
ウェブのデータは現代の貴重な資源であり、Javaはいまもなお、ビジネスの現場でそれを掘り起こすための最良の道具のひとつであり続けています。とりわけ、堅牢さと規模、そして連携性を欠かせないチームには、これ以上ないほど合います。土台となる流れ自体はいたってシンプルで、取得し、パースし、抽出し、出力する――それだけです。そこにJSoup、HtmlUnit、Seleniumといったライブラリが加われば、シンプルな名簿サイトから、JavaScriptが幾重にも織り込まれた難関サイトまで、ひととおり対応できます。
とはいえ、何もかもを手作業で抱え込む必要はありません。Thunderbit のようなツールを取り入れれば、AIと目で見える自動化の力を借りて、スクレイピングの案件をこれまで以上の速さで試し、調整し、広げていけます。私からひとつ助言を添えるなら、コードとノーコードを臆せず組み合わせること。設定と保守はThunderbitで手軽に済ませ、重たい処理はJavaのパイプラインに任せる――この役割分担が、いちばん理にかなっています。
Thunderbitが日々の仕事をどこまで速められるか、その目で確かめてみたいですか。まずはChrome 拡張機能をダウンロードして、ほんの数分で最初のサイトを集めてみましょう。さらに深掘りしたい方は、Thunderbit Blog に詳しい解説やチュートリアル、ウェブスクレイピング自動化の最新情報をまとめてあります。
それでは、快適なスクレイピングを。そしてあなたの手元のデータが、いつでも整然と、最新で、すぐ使える状態でありますように。
FAQ
1. 2026年でも Java はウェブスクレイピングに有効ですか?
はい、有効です。素早く書き捨てるスクリプトではPythonが人気を集めますが、企業規模で何年も回し続けるスクレイピングのパイプラインとなると、いまもJavaが手堅い定番です。とりわけ、既存のサービスがすでにJVMの上で動いていて、本物のマルチスレッドと、Mavenやロギング、JDBCを中心に育ってきた成熟したエコシステムの恩恵を受けられる場合には、強みがはっきり出ます。
2. JSoup、HtmlUnit、Selenium はいつ使い分ければよいですか?
静的なページならJSoup、ちょっとした動的コンテンツやフォームの送信ならHtmlUnit、JavaScriptをふんだんに使った動きのあるサイトならSelenium――これが目安です。要は、相手の複雑さに見合ったツールを選ぶ、という一点に尽きます。
3. スクレイピング中にブロックされないようにするには?
リクエストの勢いを抑え、ローテーションプロキシを経由させ、本物らしいuser-agentを名乗り、人の操作を再現する。手強いサイトが相手なら、Thunderbitのクラウドスクレイピングや、ボット対策のAPIを検討するのも手です。
4. Thunderbit と Java は一緒に使えますか?
もちろんです。スクレイピングをThunderbitで目に見える形に組んで定期実行させ、データを書き出したうえで、その先の処理や連携をJavaのコードが引き受ける――そんな分担が組めます。ビジネスユーザーにとっても開発者にとっても、心強い組み合わせです。
5. Java ウェブスクレイピングを始める最速の方法は?
JavaとMavenを整え、JSoupを足して、まずは易しいサイトでスクレイピングを一度試してみましょう。もっと込み入った作業や、手早い試作には、Thunderbit を入れて重たい部分をAIに任せ、その成果物をJavaの工程へ組み込んでいくのがおすすめです。
さらに踏み込んだヒントや、コードの実例、自動化のテクニックが欲しいですか。Thunderbit Blog を読み込むか、YouTube チャンネル を登録して、手を動かしながら学べるチュートリアルと、ウェブスクレイピングの最新の手法に触れてみてください。 さらに詳しく
Java プロジェクト向け AI ウェブスクレイパーを試す Get Started Free




