高トラフィックのWebサイトが、大規模言語モデル向けに機械可読なガイダンスをどのように公開しているのか、初期実装がどのようなものか、そして採用状況を測るうえで HTTP 200 応答数を数えるだけでは不十分な理由を、クロールベースで調査しました。
- データセット:
data/llms_probe_results_top_10000.csv - Tranco リストのダウンロード日: 2026年5月6日
- 対象範囲: ルート直下の
/llms.txtと/llms-full.txt
主要指標
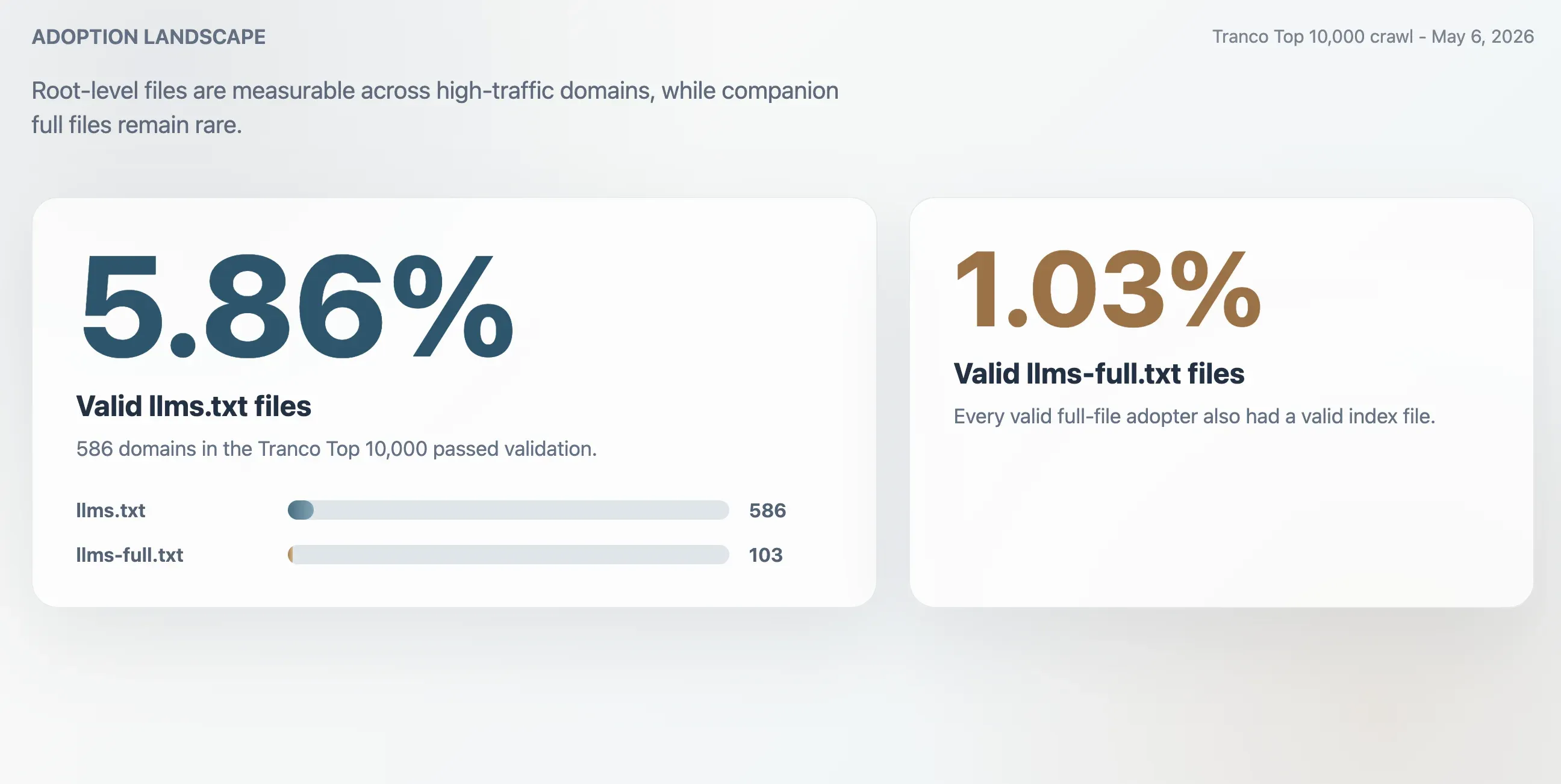
- 5.86%: Tranco Top 10,000 における有効な
llms.txtの採用率。586ドメインに相当します。 - 1.03%: 有効な
llms-full.txtの採用率。103ドメインに相当します。完全版ファイルを有効に公開していたサイトは、すべてインデックスファイルも有効でした。 - 63.51%:
/llms.txtの HTTP 200 応答のうち、検証に失敗した割合。 - 2.74倍: 生の HTTP 200 応答だけで採用率を測った場合のおおよその過大計上率。
要約
llms.txt はまだ初期段階のWeb慣行ですが、もはや周縁的な実験ではありません。2026年5月6日に Tranco Top 10,000 ドメインをクロールした結果、この調査では有効な llms.txt ファイルが 586 件見つかり、観測上の採用率は 5.86% でした。併設される llms-full.txt ははるかに少なく、有効な完全版ファイルがあったのは 103ドメイン、採用率は 1.03% でした。
最も重要な方法論上の発見は、ステータスコードが採用の代理指標としては不十分だという点です。クロールでは /llms.txt に対して 1,606 件の HTTP 200 応答が見つかりましたが、検証を通過したのは 586 件だけでした。残りの 1,020 件は、意図しないリダイレクト、汎用HTMLページ、空の本文、その他の無効な応答が大半でした。HTTP 200 応答をすべて採用とみなす単純なクロールなら、有効な採用数を約 2.74倍も過大評価していたことになります。
有効な採用サイトの中では、実装品質は単なるプレースホルダーという印象よりも高いです。有効ファイルの中央値は約 7.1KB で、61.77% は 5KB を超え、70.82% は 6個以上の Markdown セクションを含み、77.47% は 11本以上の Markdown リンクを含んでいました。初期採用企業には Cloudflare、Azure、GitHub、DigiCert、WordPress.org、Adobe、Dropbox、PayPal、Stripe、Salesforce、Slack、Zendesk、Okta、Datadog、Cloudinary などが含まれます。
llms.txtは、robots.txtの代替ではなく、AI システム向けの説明・ナビゲーション信号として理解するのが最適です。重要なのはファイルが存在することだけではなく、機械が権威ある、簡潔で最新の情報にたどり着けるかどうかです。
背景:Web は AI 向けシグナルを追加している
Webサイトは長年、クロールの方針を示すために robots.txt、URL の発見性を高めるために sitemap.xml、そして検索やプラットフォームのシステムがページを解釈しやすくするために構造化データを使ってきました。生成AIは別の問題をもたらします。コンテンツは学習、検索、要約、エージェント的なブラウジング、コード支援、カスタマーサポート、回答生成などに使われる可能性があります。そこには同時に2つの要件があります。発行者は自動利用に対してより強い制御を求める一方で、AIシステムがサイトとやり取りする際には、適切な正本情報を見つけてほしいという点です。
2024年に Jeremy Howard が提案した は、このファイルをサイトのルートに置く Markdown 文書として位置づけ、推論時に LLM フレンドリーな情報を提供するものだと説明しています。提案では、HTMLページにはナビゲーション、広告、スクリプト、その他のノイズが多く、言語モデルが処理しづらいと論じています。簡潔な Markdown ファイルなら、モデルを最重要ページ、ドキュメント、API、例、ポリシー、製品情報へ誘導できます。
外部のWeb調査は、より広い背景を示しています。 は、robots.txt と利用規約における AI 関連の制限が急増していることを示し、既存のWeb上の同意メカニズムは大規模なAIデータ再利用のために設計されていなかったと論じています。 も、Top 10,000 ドメインレベルで AI クローラーと robots.txt の傾向を可視化しています。そうした環境では、llms.txt は AI シグナリングの建設的な側にあります。つまり「ここはクロールするな」ではなく、「このサイトを理解したいなら、まずここから始めてください」という合図です。
外部エビデンスと採用をめぐる議論
llms.txt をめぐる公開議論は、2つの主張に分かれています。楽観的な主張は、このファイルが AI システムに、権威あるコンテンツへのよりクリーンで効率的な経路を与えるというものです。懐疑的な主張は、主要な LLM プロバイダーのいずれも、それをランキング、クロール、引用のシグナルとして使うと公に約束していないため、発行者はこのファイルだけでトラフィック増を期待すべきではないというものです。今回の更新で確認した3つの外部ソースは、より微妙な結論を支持しています。llms.txt は有用なインフラではあるものの、直接的なトラフィック効果の証拠はまだ限定的で、状況依存です。
外部の採用ベンチマークは急速に変化している
は、2025年6月22日時点で上位1,000サイト全体の採用率を 0.3%、つまり 1,000サイト中3件と報告しています。これは、domain.com/llms.txt を毎月自動スキャンし、リダイレクトとHTML応答を除外する検証を行うものです。この方法論は、本調査の保守的な検証アプローチと方向性が似ています。
結果の差は大きいです。本調査では、2026年5月6日時点の Tranco Top 1,000 において有効な llms.txt を 75件見つけ、採用率は 7.50% でした。とはいえ、順位ソース、実装の詳細、検証ロジック、クロール時点が異なる可能性があるため、この2つの数値を厳密な時系列として扱うべきではありません。それでも、この差は、2025年半ばから2026年5月までの間に、特に開発者向け、SaaS、クラウド、セキュリティ、ドキュメント重視のサイトで採用が大きく進んだことを示唆しています。
| ソース | スナップショット | サンプル | 報告された有効採用率 | 解釈 |
|---|---|---|---|---|
| Rankability | 2025年6月22日 | 上位1,000サイト | 0.3% | 2025年半ば時点では採用がごく少ないことを示す初期の公開ベンチマーク。 |
| 本調査 | 2026年5月6日 | Tranco Top 1,000 | 7.50% | 高トラフィックサイトで可視化できる採用を示す後年のクロール。 |
| 本調査 | 2026年5月6日 | Tranco Top 10,000 | 5.86% | より広いサンプルでは、採用は測定可能だが主流ではないことを示す。 |
トラフィック実験の結果はまだ割れている
は、2026年1月に10サイト分析を公開し、導入前90日と導入後90日を追跡しました。記事によると、2サイトでは AI トラフィックが 12.5% と 25% 増加し、8サイトでは測定可能な改善はなく、1サイトでは 19.7% 減少しました。重要な解釈は因果関係への慎重さです。成功例の2サイトでは、新しいテンプレートの公開、リソースセンターの再構築、抽出しやすい比較表の追加、報道露出の獲得、技術的問題の修正、FAQ形式の新規コンテンツ公開なども同時に行われていました。この枠組みでは、llms.txt はより強いコンテンツや技術改善を文書化したものであり、成長をそれ自体で引き起こしたようには見えません。
は、より小規模なサイト観測から、より前向きな結論に達しています。llms.txt と llms-full.txt の両方を追加した後の、Yandex.Metrica における2つの4か月期間を比較しました。LLM 参照セッションは 75 から 92 に増え、23% の増加でした。ユーザー数は 51 から 64 に増加しました。Perplexity のセッションは 29 から 55 に増えた一方、ChatGPT のセッションは 31 から 26 に減りました。同じ記事では、総参照トラフィックが 160 から 290 セッションへとより速く増えたため、LLM セッション比率は 47% から 32% に低下したとも述べています。
This paragraph contains content that cannot be parsed and has been skipped.
この議論で何が明確になるか
外部エビデンスは、このデータセットの解釈をよりはっきりさせます。よく構造化された llms.txt ファイルは、特に開発者向けドキュメント、API リファレンス、ナレッジベース系コンテンツで、機械による解析の摩擦を下げられます。しかし、最も強いトラフィック効果は、依然として有用で、抽出しやすく、権威があり、ファイルの外でも見つけやすいコンテンツに依存しているようです。したがって、実務上の問いは「llms.txt は単体で意味があるのか?」ではありません。ファイルが、より広い AI 可読コンテンツシステムの一部になっているかどうかです。
更新後の解釈:
llms.txtは、低コストの AI 向けインフラとして実装すべきです。より良いドキュメント、構造化コンテンツ、技術的アクセシビリティ、引用、リンク、ブランドの権威の代替として位置づけるべきではありません。
方法論
この調査では、サンプルとして Tranco Top 10,000 ドメインを使用しました。Tranco は、従来の多くのトップリストよりも安定性が高く、操作耐性を意図した研究向けのトップサイト順位です。Tranco のソースファイルは 2026年5月6日にダウンロードされ、ソースの Last-Modified タイムスタンプは 2026年5月5日 22:17:59 GMT でした。
クローラーは各ドメインに対して、ルート直下の次の2つのパスを確認しました。
https://example.com/llms.txt、必要に応じて HTTP フォールバック。https://example.com/llms-full.txt、必要に応じて HTTP フォールバック。
各プローブについて、クローラーはステータスコード、最終URL、取得方法、応答バイト数、コンテンツタイプ、エラーメッセージ、経過時間、検証結果を記録しました。成功した応答本文は、確認と二次分析のために raw_llms_txt/ に保存しました。
検証ルール
応答は、成功した本文を返し、汎用的なWebフォールバックに見えない場合にのみ有効ファイルとして شمارえました。最終URLのパスは /llms.txt または /llms-full.txt のままである必要がありました。空の本文は除外しました。明らかなHTMLドキュメントとアプリのシェルも除外しました。コンテンツタイプは唯一の判断基準ではなく補助証拠として扱いました。というのも、少数ながら有効なテキスト系ファイルが、通常とは異なるコンテンツタイプで配信されていたからです。
採用状況
クロールでは、Tranco Top 10,000 において有効な llms.txt ファイルが 586件見つかりました。これにより、有効採用率は 5.86% となります。より小さい併設ファイル llms-full.txt は 103ドメインで有効に存在し、サンプル全体の 1.03% でした。
| 指標 | 件数 | Top 10,000 に占める割合 |
|---|---|---|
| クロールしたドメイン数 | 10,000 | 100.00% |
| 有効な llms.txt ファイル | 586 | 5.86% |
| 有効な llms-full.txt ファイル | 103 | 1.03% |
| /llms.txt の HTTP 200 応答 | 1,606 | 16.06% |
| 無効として除外した HTTP 200 応答 | 1,020 | 10.20% |
採用は単純な上位集中ではない
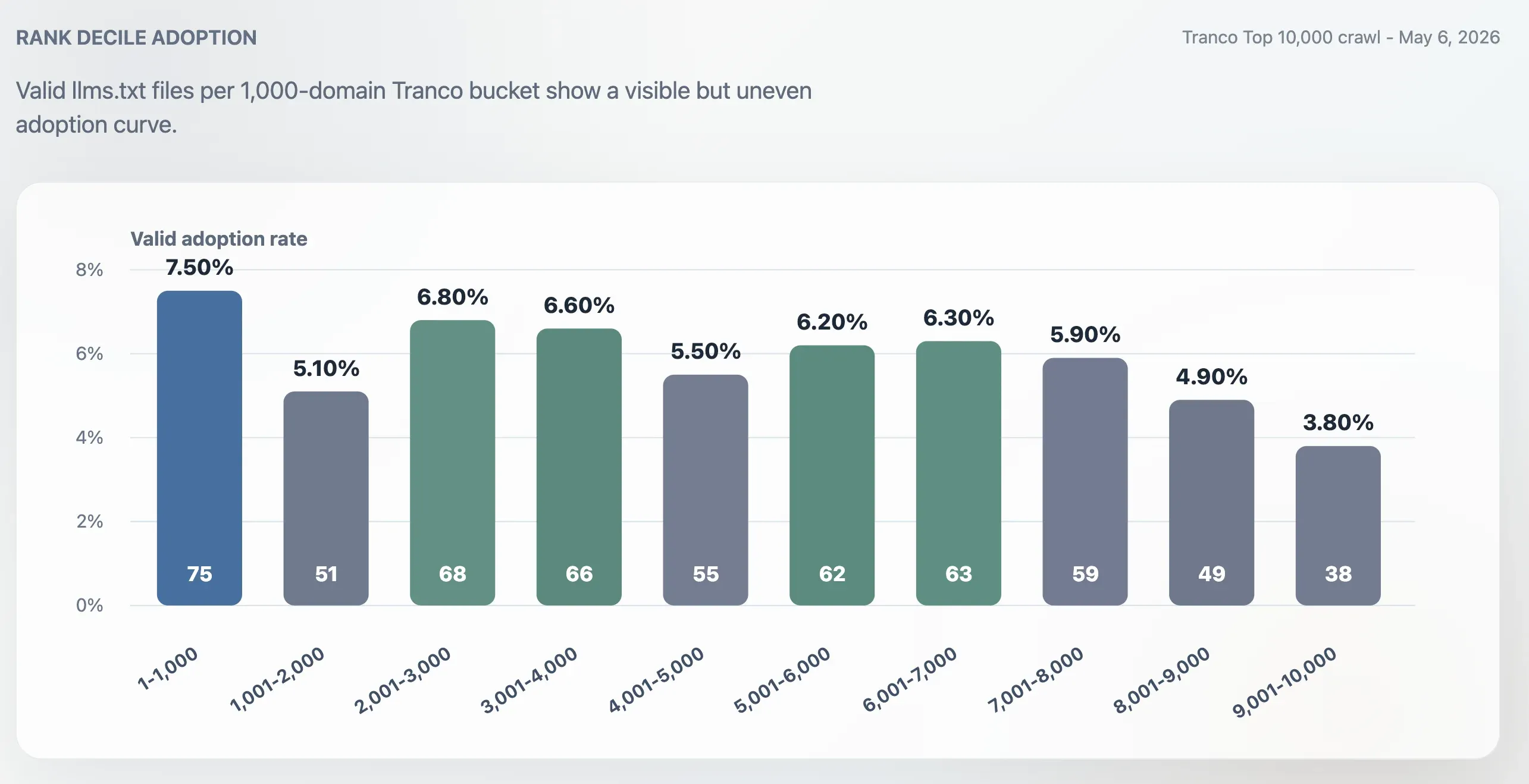
採用率は全体の Top 10,000 より Top 1,000 の方が高いものの、最上位の巨大サイトだけに限定されているわけではありませんでした。Top 1,000 の採用率は 7.50% でした。順位 9,001〜10,000 の最後の 1,000ドメイン帯では 3.80% に下がりました。順位中位でも活動は見られ、2,001〜3,000、3,001〜4,000、5,001〜6,000、6,001〜7,000 の各帯はいずれも約 6% でした。
初期採用サイト
最も順位が高かった有効採用サイトは Tranco 順位 4 位の Cloudflare でした。ほかの上位採用サイトには Azure、GitHub、DigiCert、WordPress.org、Adobe、Sentry、Dropbox、PayPal、Shopify、Taboola、Avast、Weather.com、Oxylabs、SourceForge、Cisco、Stripe、Slack、Dell、NVIDIA、Indeed、Zendesk、Calendly、Palo Alto Networks、Okta、Braze、Klaviyo、Intercom、Datadog、Cloudinary、ClassLink、OneSignal などがありました。
これらの採用サイトは偶然の寄せ集めではありません。ドキュメントの規模が大きい、説明が必要な製品群を持つ、API や開発者エコシステムがある、サポート内容や価格ページがある、セキュリティやプライバシー資料がある、そして AI システムが自社サイトをどう解釈するかを気にするだけのブランド力がある、という傾向があります。
| 順位 | ドメイン | ファイルサイズ | 観測されたパターン |
|---|---|---|---|
| 4 | cloudflare.com | 4,225 B | 製品、開発者、会社、価格のコンパクトなインデックス。 |
| 26 | azure.com | 47,037 B | 開発ツール、AI、計算、ストレージ、セキュリティ、監視、任意リソース。 |
| 28 | github.com | 27,108 B | プログラム的アクセス、Copilot、MCP、REST API、Actions、リポジトリ、CLI へのリンク。 |
| 248 | stripe.com | 64,229 B | 決済、Connect、Checkout、Billing、Tax、Atlas、Radar、開発者ドキュメント。 |
| 265 | salesforce.com | 1.02 MB | Markdown の見出しを持たない、巨大な製品と Agentforce のリンクカタログ。 |
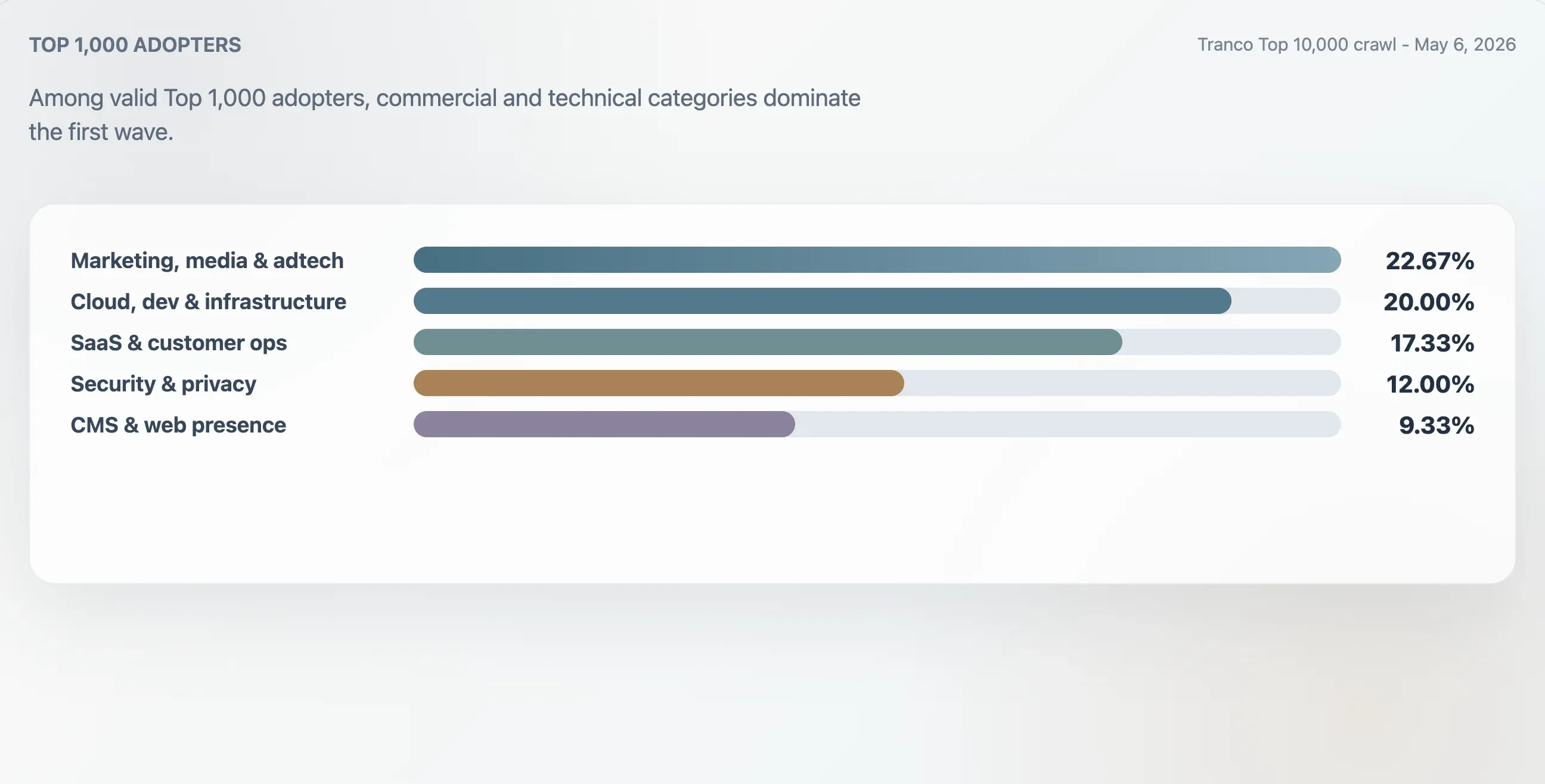
Top 1,000 採用サイトのカテゴリ
本調査では、Tranco Top 1,000 における 75件の有効採用サイトを、ドメインの文脈、最初の見出し、元ファイルの構造、コンテンツキーワードを使って分類しました。最も多かったのはマーケティング、メディア、adtech で 22.67% でした。クラウド、開発、インフラ系サイトは 20.00%。SaaS、生産性、カスタマーオペレーション系は 17.33%。セキュリティ、ID、プライバシー系は 12.00% でした。
| カテゴリ | ドメイン数 | Top 1,000 採用サイトに占める割合 | 品質スコア中央値 | リンク数中央値 |
|---|---|---|---|---|
| マーケティング、メディア、adtech | 17 | 22.67% | 94 | 25 |
| クラウド、開発、インフラ | 15 | 20.00% | 94 | 62 |
| SaaS、生産性、カスタマーオペレーション | 13 | 17.33% | 94 | 46 |
| セキュリティ、ID、プライバシー | 9 | 12.00% | 98 | 78 |
| CMS、ホスティング、Webプレゼンス | 7 | 9.33% | 100 | 24 |
TLD パターン
トップレベルドメインは業界ラベルではありませんが、方向性を示す有用なシグナルです。サンプル内で少なくとも50ドメインあるTLDの中では、.io の有効採用率が 14.44% と最も高く、.com が 8.19% で続きました。.gov、.edu、.net の採用率が低いことは、初期採用層が制度機関よりも商業・技術寄りであることを示唆しています。
実装品質
有効採用は、実装品質が一様であることを意味しません。簡潔で、セクション分けされた良質なインデックスもあれば、ほぼ散文だけのもの、素のリンクカタログ、ほとんど空のプレースホルダー、あるいは完全だが取得や解析にコストのかかる数MB級のコンテンツダンプもあります。
有効な llms.txt ファイルのうち、362件は 5KB を超えており、有効採用サイトの 61.77% に相当しました。ファイルサイズの中央値は約 7.1KB でした。P90 は 156KB、P95 は 356KB、P99 は 2.54MB、最大観測ファイルは 7.97MB でした。
よく見られるコンテンツシグナル
有効ファイルをキーワード単位でスキャンすると、多くのサイトが単なる宣言ではなく、モデルを運用上有用な素材へ誘導していることがわかりました。support や help 系の用語は有効ファイルの 70.31% に現れました。blog、guide、tutorial 系は 67.92%。security、privacy、compliance、terms 系は 61.43%。pricing は 53.92%、documentation は 52.22%、API 系は 33.96%、changelog や release シグナルは 27.30% でした。
品質スコアと類型
存在から成熟度へ進むために、本調査では簡易な実装スコアを作成しました。このスコアは、コンテンツタイプ、ファイルサイズ、Markdown 構造、リンク数、トピック範囲、そして見出し欠如、Markdown リンクなし、異常なコンテンツタイプ、小さすぎるファイル、極端に大きいファイル、リンクダンプのような警告サインを考慮します。これは正式な標準ではなく、観測された実装を比較するための研究用スコアモデルです。
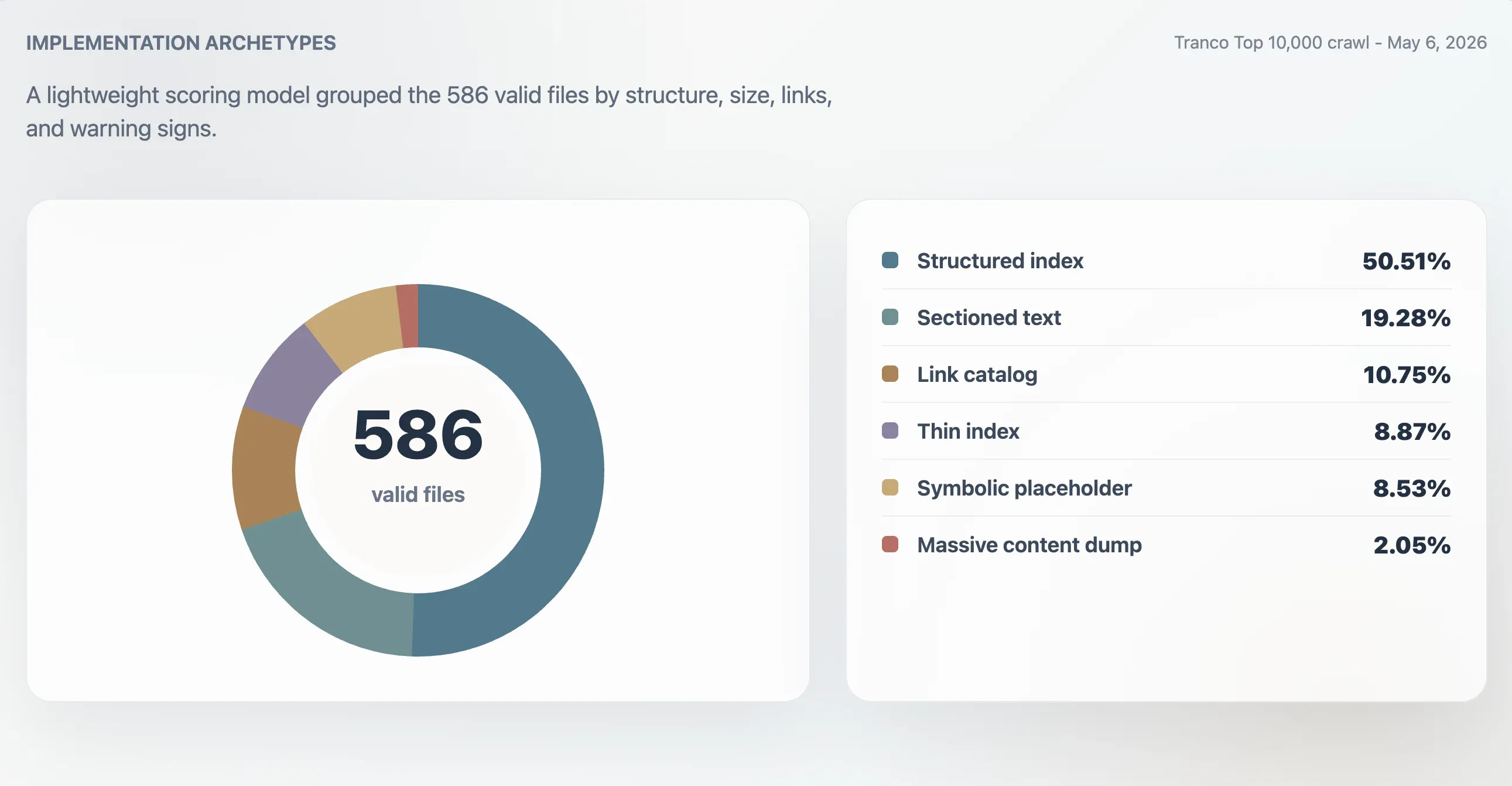
このモデルを使うと、416件の有効ファイルが強い構造化インデックス、107件が実用的なインデックス、24件が薄い・不規則、39件が象徴的または低実用性と分類されました。別の類型分析では、296件の構造化インデックス、113件のセクション付きテキストファイル、63件のリンクカタログ、52件の薄いインデックス、50件の象徴的またはプレースホルダー、12件の巨大コンテンツダンプが見つかりました。
| 類型 | ドメイン数 | 有効ファイルに占める割合 | スコア中央値 | ファイルサイズ中央値 | リンク数中央値 |
|---|---|---|---|---|---|
| 構造化インデックス | 296 | 50.51% | 98 | 11,241 B | 61.5 |
| セクション付きテキスト | 113 | 19.28% | 78 | 4,718 B | 0 |
| リンクカタログ | 63 | 10.75% | 86 | 4,160 B | 23 |
| 薄いインデックス | 52 | 8.87% | 66 | 2,814 B | 0 |
| 象徴的またはプレースホルダー | 50 | 8.53% | 27 | 15 B | 0 |
| 巨大コンテンツダンプ | 12 | 2.05% | 74 | 2.84 MB | 7,259.5 |
上位採用サイトほど実装密度が高い
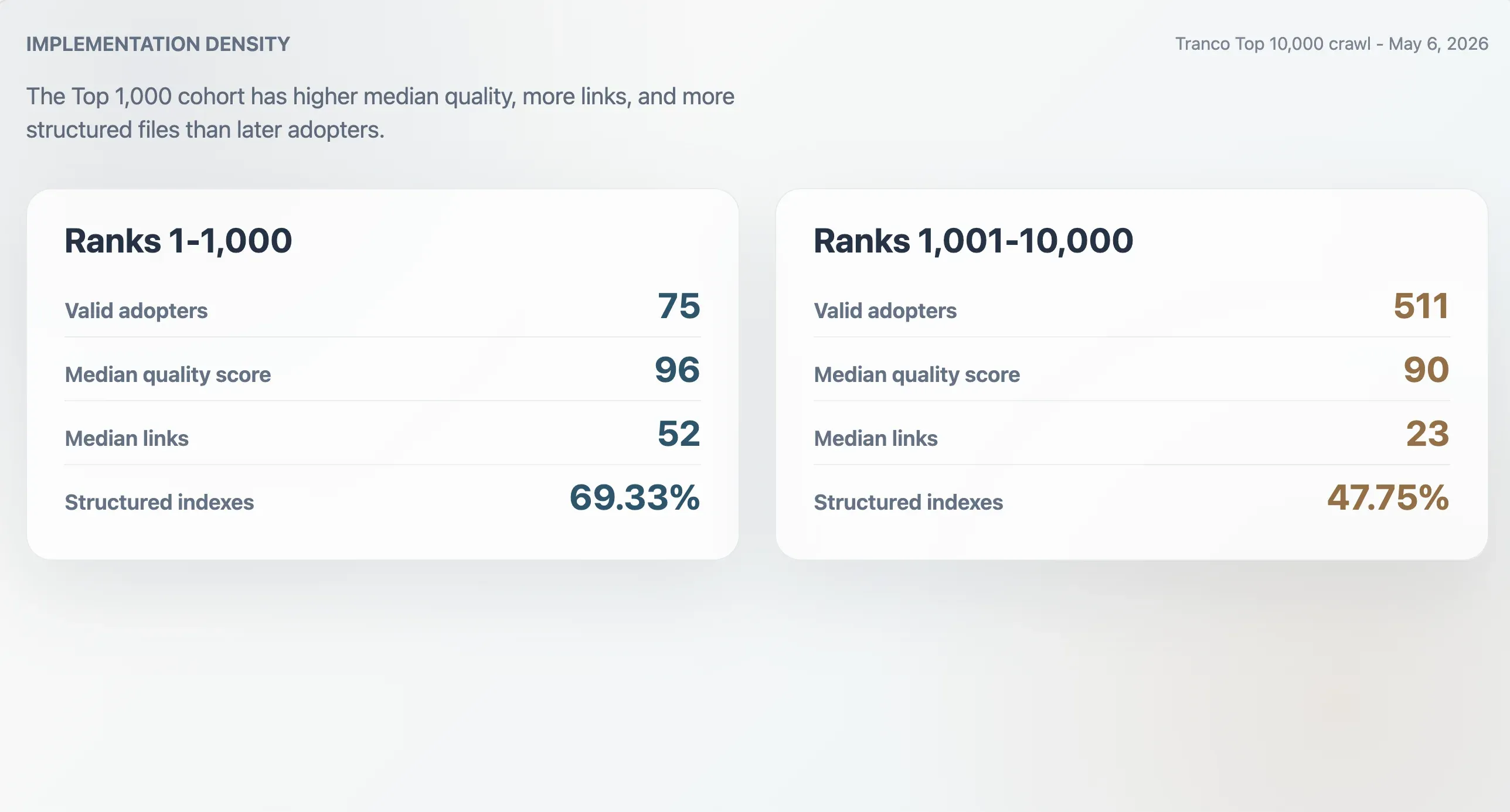
Tranco Top 1,000 における 75件の有効採用サイトの品質スコア中央値は 96、ファイルサイズ中央値は 9,068バイト、Markdown リンク数中央値は 52、セクション数中央値は 11 でした。順位 1,001〜10,000 の 511件の採用サイトは中央値が低く、スコア 90、ファイルサイズ 6,506バイト、Markdown リンク 23本、セクション 9 でした。Top 1,000 採用サイトは構造化インデックスである可能性も高く、69.33% に対して後半コホートでは 47.75% でした。
偽陽性の問題

測定リスクが最も大きいのは偽陽性です。/llms.txt に対して HTTP 200 を返した 1,606ドメインのうち、1,020件が検証に失敗しました。最も多い無効理由は意図しないリダイレクトで、618件でした。次に多かったのは汎用HTML文書で 367件です。29件は空の本文を返し、6件はその他または未分類の無効応答でした。
これは、多くの大規模サイトが未知のパスをログインページ、ホームページ、アプリシェル、地域別ページ、同意画面、マーケティング用フォールバックに振り向けるため重要です。こうした応答はステータスコードだけを見るクロールでは正常に見えても、有効な llms.txt シグナルは含んでいません。
llms-full.txt:より希少で、ばらつきも大きい
併設ファイル llms-full.txt は、llms.txt よりかなり少数でした。クロールでは有効な完全版ファイルが 103件見つかり、これは有効な llms.txt 採用サイトの 17.58% に相当し、Top 10,000 サンプル全体では 1.03% でした。
完全版ファイルの実装はばらつきが大きいです。2ファイルを併用していた 103サイトのうち、57サイトでは llms-full.txt の方がインデックスファイルより大きかった一方で、46サイトは完全版がインデックスと同じかそれ以下、あるいは 100バイト未満でした。完全版対インデックスのサイズ比の中央値は 1.43 でしたが、極端な例はもっと大きいです。Supabase の完全版はインデックスの約 7,139倍の大きさでした。Made-in-China.com では 89.89MB の完全版ファイルがありました。
This paragraph contains content that cannot be parsed and has been skipped.